流媒体弱网优化之路(BBR应用)——GCC与BBR的算法思想分析
流媒体弱网优化之路(WebRTC)——GCC与BBR的算法思想分析
——
我正在的github给大家开发一个用于做实验的项目 —— github.com/qw225967/Bifrost
目标:可以让大家熟悉各类Qos能力、带宽估计能力,提供每个环节关键参数调节接口并实现一个json全配置,提供全面的可视化算法观察能力。
欢迎大家使用
——
文章目录
一、GCC算法思想解析
1.1 小心翼翼的TrendLine
GCC算法的核心拥塞检测模块,就是TrendlineEstimator。很多小伙伴在集成、使用GCC带宽估计算法时会对TrendLine的拥塞检测可靠性存在质疑,甚至无法理解该模块参数细节的意义。我给大家讲一些我个人的理解,以及对其特性做一下简单的佐证。
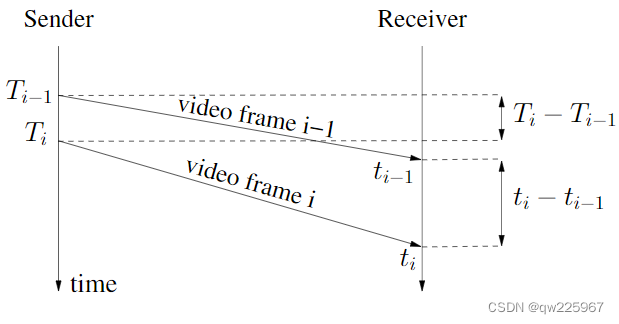
说到Trendline我还是需要再次提一下它的原理,简单来说:
1.相邻接收包与相邻发送包之间的间隔差可以有效反馈网络延迟;
d
(
i
)
=
(
t
i
−
T
i
)
−
(
t
i
−
1
−
T
i
−
1
)
=
(
t
i
−
t
i
−
1
)
−
(
T
i
−
T
i
−
1
)
d(i) = (t_i - T_i) - (t_{i-1} - T_{i-1}) = (t_i - t_{i-1}) - (T_i - T_{i-1})
d(i)=(ti−Ti)−(ti−1−Ti−1)=(ti−ti−1)−(Ti−Ti−1)
上面的图和公式大家应该都比较熟悉了,里面有几个有意思的细节:
Q:接收间隔和发送间隔这两个值能否保证极限接近呢?
A:解答此问题需要先明白WebRTC在发送包之前都做了什么。首先为了保证这个发送间隔不被pacer干扰,它是分出来两个函数——OnAddPacket、OnSentPacket——前者是在发送前记录到发送信息统计模块的,后者是在最终发送时记录所有信息的函数——他们之间隔着一个PostTask,发送前最终调用的是OnSentPacket。因此发送时间记录的是数据包在该进程发送到网卡前的最终时间,而对端的接收时间也会是从网卡到进程中第一时间,目的是保证更准确的反馈出数据在网络传输时任何一点微小的变化。因此可以理解为:从离开该进程开始,组网络存在网络异常、发送端网卡性能问题、发送端多应用竞争、接收端处理性能问题等等,都会被计入到这个变化之中。
这个时间的变化值怎么判定为异常?在WebRTC中也是考虑了经验值,代码中有几个比较关键的值:
// 阈值最小 6
threshold_ = rtc::SafeClamp(threshold_, 6.f, 600.f);
// 增益值 4
constexpr double kDefaultTrendlineThresholdGain = 4.0;
// 最大delta计算值
constexpr int kMinNumDeltas = 60;
// 可能是经验值,放大对比阈值
const double modified_trend = std::min(num_of_deltas_, kMinNumDeltas) * trend * threshold_gain_;
由此计算得:出现overuse情况时,trend > 6 / (60 * 4) ≈ 0.016。也就是60个包,增长了大概 0.016 x 60 ≈ 1 ms 时就会触发下降。而触发detect函数时,原生WebRTC是用的是20个delta就进行一次计算,那么这个值在发送的最初阶段就是 trend > 6 / (20 * 4) ≈ 0.075,也就是在初始增长阶段,很容易就会触发带宽下降,但是在60个包之后就稳定在了接近0.016这个阈值上。而trend这个值大概率是在正负小数点4位以后:
也就是只有在trend这个值迅速增大了大概 30 ~ 40 倍时(也许其他终端会得到不同的值),就会触发该逻辑。
2.动态阈值的公平性
GCC为了保证对TCP流的公平性,阈值设计成了一个可变的动态阈值,区间在 6 ~ 600 之间。更新阈值需要使用到这几个关键值:
// 最大跳变15
constexpr double kMaxAdaptOffsetMs = 15.0;
// 上升、下降 因子
k_up_(0.0087)
k_down_(0.039)
// 阈值更新值
const int64_t kMaxTimeDeltaMs = 100;
这个逻辑中,100ms会计算一次阈值,而阈值上涨因子是远小于下降因子的。
Q:动态阈值是怎么保证跟TCP流竞争的公平性的?
A:假设TCP流与GCC控制的UDP流同时在瓶颈带宽超过发送码率的链路中传输,在跟TCP的竞争过程中如果使用固定的阈值:
- 由于阈值设置的过低会导致GCC经常触发拥塞逻辑;
- 当阈值设置的过高,我们GCC算法会一直无法检测出拥塞;
- 同时,TCP流会以一个持续的快恢复来维持码率增长,那么在该阶段我们GCC阈值设置为较小的固定值就会导致完全无法抢占到带宽,阈值设置过大则会导致TCP完全无法抢占。
动态阈值的竞争过程则会在每次拥塞发生时都会再次寻求动态的平衡。当拥塞发生时,较小的阈值使得GCC触发下调码率的同时把阈值放大,这个时间GCC流大概率就会进入上涨通道持续到100ms之后计算出来的新的阈值后再变化。
void TrendlineEstimator::UpdateThreshold(double modified_trend,
int64_t now_ms) {
if (last_update_ms_ == -1)
last_update_ms_ = now_ms;
if (fabs(modified_trend) > threshold_ + kMaxAdaptOffsetMs) {
// Avoid adapting the threshold to big latency spikes, caused e.g.,
// by a sudden capacity drop.
last_update_ms_ = now_ms;
return;
}
const double k = fabs(modified_trend) < threshold_ ? k_down_ : k_up_;
const int64_t kMaxTimeDeltaMs = 100;
int64_t time_delta_ms = std::min(now_ms - last_update_ms_, kMaxTimeDeltaMs);
threshold_ += k * (fabs(modified_trend) - threshold_) * time_delta_ms;
threshold_ = rtc::SafeClamp(threshold_, 6.f, 600.f);
last_update_ms_ = now_ms;
}
上面的代码还标明,在出现尖峰级的拥塞时,会立刻更新阈值使得它快速适应带宽变化。其中还有一个有意思的点就是前面提到的上涨因子远比下降因子小,这是因为我后面提到的GCC码率控制同样是为了追求稳定而使得整个目标带宽输出是低于ack值的,这样大概率可以让队列迅速排空并进入增长状态,因此我们阈值要快速的收敛到一个敏感的范围以保证我们在增长阶段的敏感性。
1.2 稳定的AimdRateControl
上文提到了GCC拥塞检测的小心翼翼,这个思想其实也延续到了码率计算模块。我们获得了是否拥塞的事件后,就需要决定降码率?升码率?降多少?升多少?
Q:降码率是怎么触发的?降了多少?
A:首先,降码率事件是跟随者overusing状态来的。当进入降码率阶段,GCC会使用经过卡尔曼滤波器后的ack采样来计算得出网络吞吐量,随后根据网络吞吐量 * 0.85得出一个低于吞吐量的值作为目标码率。另一方面链路容量计算中,WebRTC还给出了计算采样最小、最大限制的经验值:
deviation_kbps_ =
(1 - alpha) * deviation_kbps_ + alpha * error_kbps * error_kbps / norm;
// 0.4 ~= 14 kbit/s at 500 kbit/s
// 2.5f ~= 35 kbit/s at 500 kbit/s
deviation_kbps_ = rtc::SafeClamp(deviation_kbps_, 0.4f, 2.5f);
// 计算采样
DataRate LinkCapacityEstimator::UpperBound() const {
if (estimate_kbps_.has_value())
return DataRate::kbps(estimate_kbps_.value() +
3 * deviation_estimate_kbps());
return DataRate::Infinity();
}
DataRate LinkCapacityEstimator::LowerBound() const {
if (estimate_kbps_.has_value())
return DataRate::kbps(
std::max(0.0, estimate_kbps_.value() - 3 * deviation_estimate_kbps()));
return DataRate::Zero();
}
而这个上下浮动的最大限制值就是 3 倍的采样偏差,计算出来就恰好是很有意思的0.85。也就是说GCC在进行码率下降时使用的是网络中可能产生的最坏结果,这也是符合GCC的小心翼翼思想的。当吞吐量和容量估计相去甚远,这个估计值就会被迅速重置因为此时认为该系统没有完成收敛。
Q:升码率是怎么样的?以什么方式升?
A:GCC中码率上涨分了两种情况:additive_increase、multiplicative_increase,加性增和乘性增两种情况。当我们的链路存在可以统计到的容量时,GCC就会进入加性增的状态(意味着整个传输已经进入稳定/瓶颈)反之进入加性增的状态(意味着需要更多码率去探索新的带宽)。
// 加性增
DataRate AimdRateControl::AdditiveRateIncrease(Timestamp at_time,
Timestamp last_time) const {
double time_period_seconds = (at_time - last_time).seconds<double>();
double data_rate_increase_bps =
GetNearMaxIncreaseRateBpsPerSecond() * time_period_seconds;
return DataRate::bps(data_rate_increase_bps);
}
double AimdRateControl::GetNearMaxIncreaseRateBpsPerSecond() const {
// RTC_DCHECK(!current_bitrate_.IsZero());
const TimeDelta kFrameInterval = TimeDelta::seconds(1) / 30;
DataSize frame_size = current_bitrate_ * kFrameInterval;
const DataSize kPacketSize = DataSize::bytes(1200);
double packets_per_frame = std::ceil(frame_size / kPacketSize); // 向上取整
DataSize avg_packet_size = frame_size / packets_per_frame;
// Approximate the over-use estimator delay to 100 ms.
TimeDelta response_time = rtt_ + TimeDelta::ms(100);
if (in_experiment_) response_time = response_time * 2;
double increase_rate_bps_per_second =
(avg_packet_size / response_time).bps<double>();
double kMinIncreaseRateBpsPerSecond = 4000;
return std::max(kMinIncreaseRateBpsPerSecond, increase_rate_bps_per_second);
}
加性增的逻辑是基于 增长间隔 * 速率 来获得当前间隔所需的码率。其中WebRTC按30帧计算帧间隔、1200作为包大小计算得到大概的平均包大小,再根据平均包大小换算在响应过程中需要增加的码率——这个码率在论文中被设定为半个包的大小。

加性增的过程可以理解为趋势似乎进入了反转的情况,但还无法完全收敛,所以我们不能使用过于激进的增长方式。排空一旦完成我们才能进行较为激进的增长,这个标志就在于上涨的码率超过了原先容量的3倍标准差,于是乎增长切换成了乘性增的状态。
// 乘性增
DataRate AimdRateControl::MultiplicativeRateIncrease(
Timestamp at_time, Timestamp last_time, DataRate current_bitrate) const {
double alpha = 1.08;
if (last_time.IsFinite()) {
auto time_since_last_update = at_time - last_time;
alpha = pow(alpha, std::min(time_since_last_update.seconds<double>(), 1.0));
}
DataRate multiplicative_increase =
std::max(current_bitrate * (alpha - 1.0), DataRate::bps(1000));
return multiplicative_increase;
}
乘性增更加简单直接,它会使用复数的形式去增长,最大是每秒增长8%。这个不分的逻辑其实和丢包带宽估计的增长速度是接近的。但是8%这个换算来看,假设从500kbps 涨到 1000kbps,也需要 9 s的时间。因此,总的来看GCC的码率策略是降的飞快,涨的巨慢,也只能用稳来形容了。
二、BBR的算法思想
2.1 BDP的粗犷
BBR算法的思想在于对BDP的合理计算,理论上用BDP去计算可发送码率是合理的,但在真正实现的过程中BBR时常表现得过于粗狂从而导致竞争上过于强力的表现。相比于GCC与TCP的竞争弱势表现,BBR是过于强硬的抢占了带宽,导致buffer出现大量的堆积。
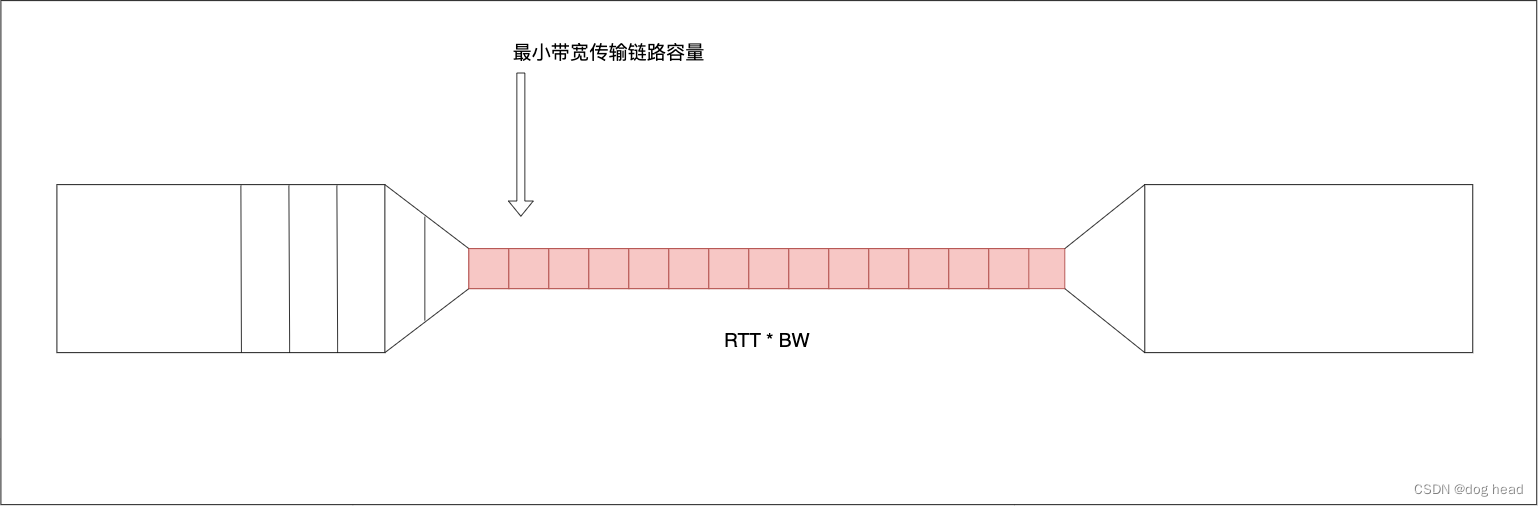
Q:那么这个过程是怎么产生的呢?
A:从上图展示的图片中,我们需要使用最小的RTT和最大的BW来计算整个窄链路的传输容量,目的就是对比可飞行的数据来获得当前可发送的数据量。获取最小RTT和最大BW是需要足够的采样测量的,BBR使用两个状态来确定最小RTT(ProbeRTT)和最大BW(probeBW)。下图给出论文中填充的示意图:
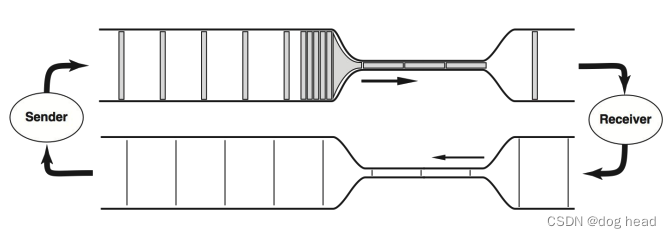
最小RTT的探测与最大BW的探测无法同时进行,这是因为最小的RTT需要控制拥塞,避免拥塞引入延迟的干扰,因此最大带宽和最小RTT都在BBR中是分开统计的。
ProbeRTT:每10s进入ProbeRTT状态,并且最低维持200ms进行检测;
ProbeBW:该状态下循环8次增加发送码率25%,用来提供探测最大码率;
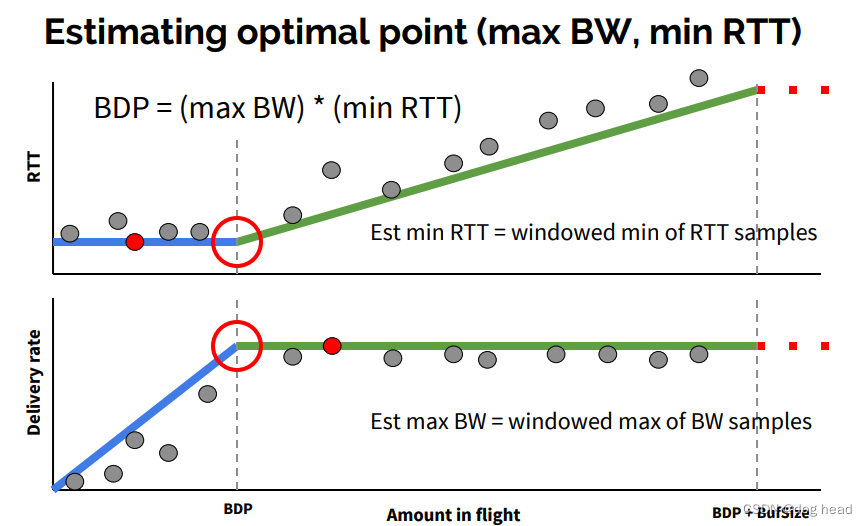
检测方式有了,什么时候去调控网络?这也是BBR要解决的重点问题。而整个收敛过程在上图中展示了,BBR认为在以上两个拐点中是最佳的拥塞控制点。其中有一个很重要的问题,就是RTT统计的上涨往往是网络队列已经出现了排队才会触发的,这个滞后是无法避免的。并且,RTT和BW的采样不会和理论一样持续保持线性增长的态势,而是一个动态变化且带有指数特征的曲线,那么调控点的位置我们就很难去完全确定(很多大佬都详细论述、证明,并尝试提出较优的调控点位置:知乎搜索——anonymous)。在本文想表达的是,BBR基于BDP的带宽策略从各种角度来看都是更为粗狂的,而且这种粗狂往往伴随着数据超发。
2.2 PacingRate的低粒度
在GCC篇中,我们详细解释GCC的发送是强依赖pacing_rate这个值的,但是该值在BBR中并不足以支持我们发送控制的需求,或者说它还不够精细。这是为什么呢?因为在实际的带宽限制测试中,我们发现Pacing_rate的滞后性比RTT还要严重不少。往往最小RTT已经被检测到但是Pacing_rate并没有发生明显的变化。因为在连续三个带宽无责增长后会先进入 is_at_full_bandwidth_ = true 的状态。
void BbrSender::CheckIfFullBandwidthReached(
const SendTimeState& last_packet_send_state) {
if (last_sample_is_app_limited_) {
return;
}
QuicBandwidth target = bandwidth_at_last_round_ * kStartupGrowthTarget;
if (BandwidthEstimate() >= target) {
bandwidth_at_last_round_ = BandwidthEstimate();
rounds_without_bandwidth_gain_ = 0;
if (expire_ack_aggregation_in_startup_) {
// Expire old excess delivery measurements now that bandwidth increased.
sampler_.ResetMaxAckHeightTracker(0, round_trip_count_);
}
return;
}
rounds_without_bandwidth_gain_++;
if ((rounds_without_bandwidth_gain_ >= num_startup_rtts_) ||
ShouldExitStartupDueToLoss(last_packet_send_state)) {
// QUICHE_DCHECK(has_non_app_limited_sample_);
is_at_full_bandwidth_ = true;
}
}
而在这个状态下,pacing_rate就会直接使用的 最大带宽 x 系数 这种方式,而不是使用 拥塞窗口 / 最小RTT 的方式,于是也引发了码率调控的滞后。
事实上,pacing_rate是不适合完全用于码率控制的,我们应该将它作为发送间隔计算的一个依据,真正使用来做控制的应该是 congestion_windows 与 bytes_in_flight。
三、GCC与BBR瓶颈竞争
那么基于上述两个算法的理论分析,我们对两条流(分别为GCC和BBR流)进行一次竞争分析。环境如下:带宽瓶颈 900kbps,两条流最大发送码率 1.25 mbps。在两条流达到最大带宽一定时间后开始码率限制,观察两条流的竞争表现和收敛情况(本次实验BBR使用了congestion_windows 和 bytes_in_flight 进行比较做码率控制,pacing_rate没有参与计算)。
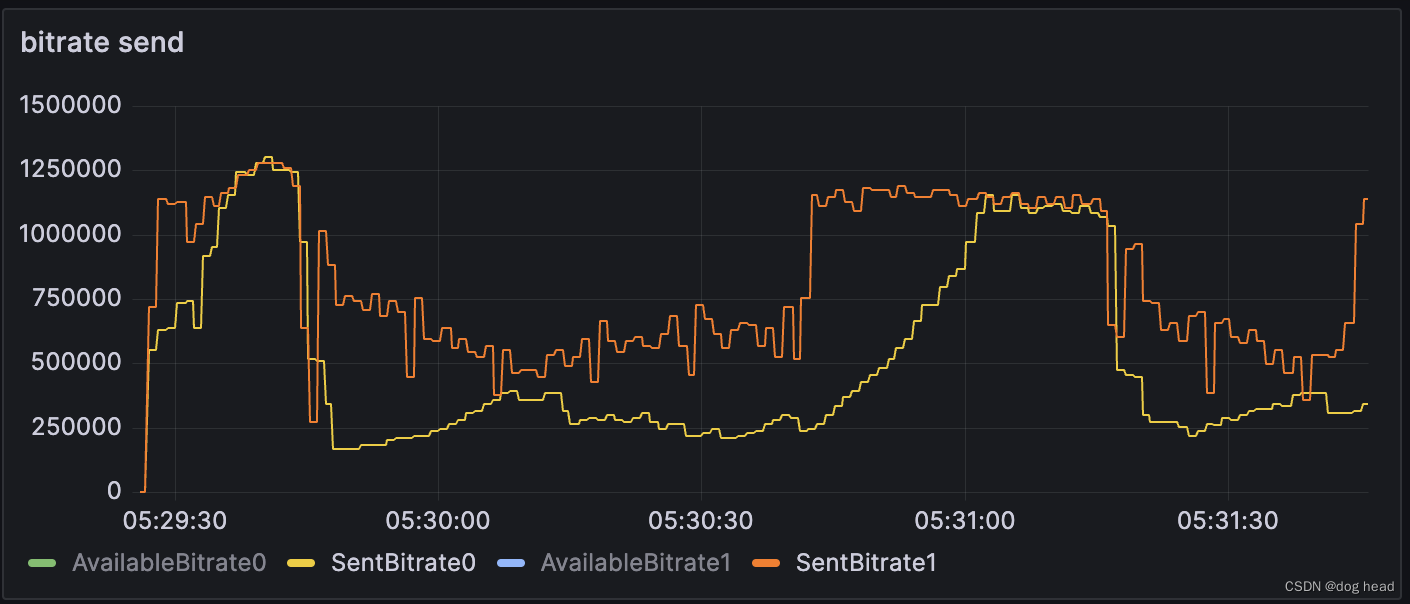
上图中,橘色为BBR流的发送码率记录,黄色位GCC的发送码率记录。
GCC竞争分析:GCC在弱网产生的瞬间,按它自身的敏感特性立刻下调到了最低的状态,随后动态阈值生效,进入上涨的周期,直到与BBR平衡后可以基本维持竞争能力。
BBR竞争分析 :BBR在弱网产生的瞬间,利用congestion_windows 和 bytes_in_flight判定了网络拥塞,限制了发送。随后由于网络竞争方GCC下调码率,飞行数据大量降低,于是立刻恢复了带宽利用。随后在于GCC的竞争中逐渐趋于平衡。