opencv dnn模块 示例(23) 目标检测 object_detection 之 yolov8
文章目录
1、YOLOv8介绍
YOLOv3之前的所有YOLO对象检测模型都是用C语言编写的,并使用了Darknet框架,Ultralytics发布了第一个使用PyTorch框架实现的YOLO (YOLOv3);YOLOv3之后,Ultralytics发布了YOLOv5,在2023年1月,Ultralytics发布了YOLOv8,包含五个模型,用于检测、分割和分类。 YOLOv8 Nano是其中最快和最小的,而YOLOv8 Extra Large (YOLOv8x)是其中最准确但最慢的,具体模型见后续的图。
YOLOv8附带以下预训练模型:
- 目标检测在图像分辨率为640的COCO检测数据集上进行训练。
- 实例分割在图像分辨率为640的COCO分割数据集上训练。
- 图像分类模型在ImageNet数据集上预训练,图像分辨率为224。
1.1、概述
心特性和改动可以归结为如下:
- 提供了一个全新的SOTA模型(state-of-the-art model),包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于YOLACT的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
- 骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是一套参数应用所有模型,大幅提升了模型性能。
- Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从Anchor-Based 换成了 Anchor-Free
- Loss 计算方面采用了TaskAlignedAssigner正样本分配策略,并引入了Distribution Focal Loss
- 训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
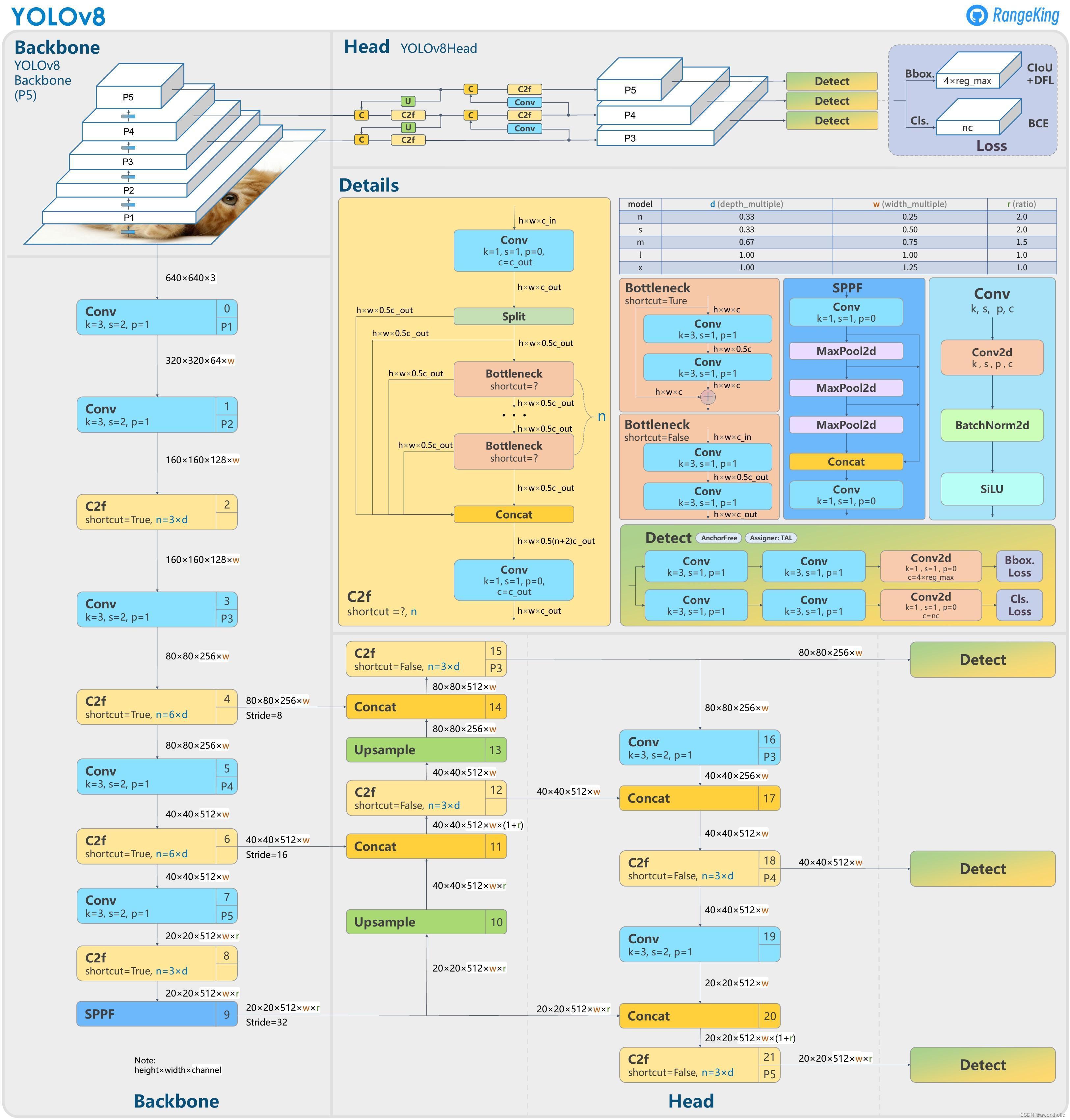
1.2、骨干网络和 Neck
骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是一套参数应用所有模型,大幅提升了模型性能。 具体改动为:
-
第一个卷积层的 kernel 从 6x6 变成了 3x3
-
所有的 C3 模块换成 C2f,可以发现多了更多的跳层连接和额外的 Split 操作
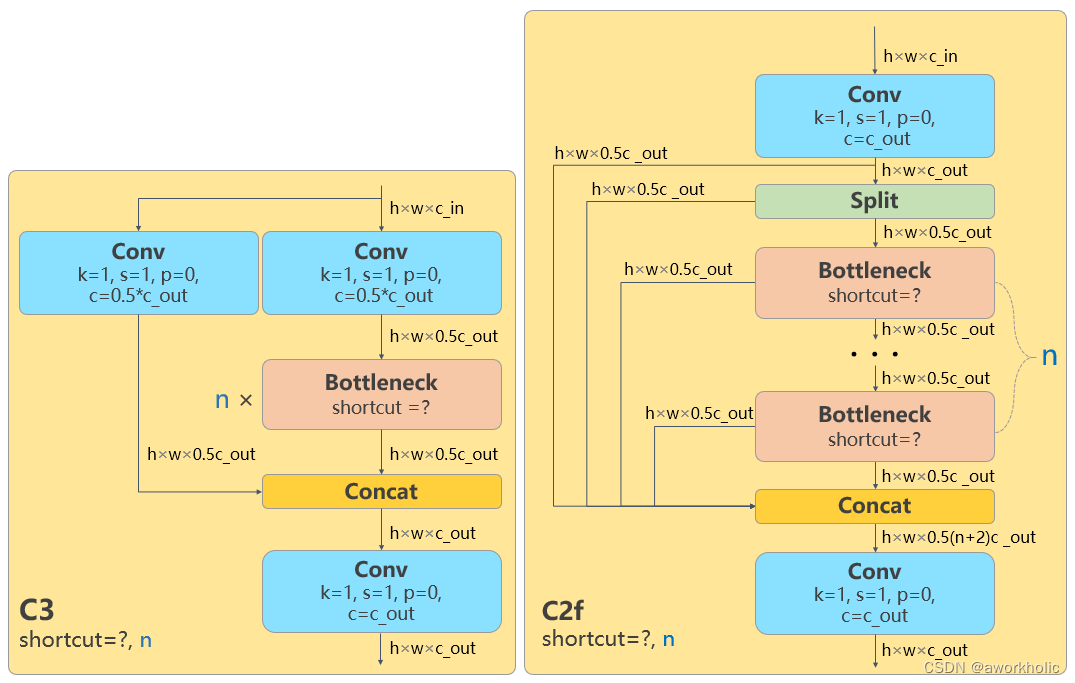
-
去掉了 Neck 模块中的 2 个卷积连接层
-
Backbone 中 C2f 的block 数从 3-6-9-3 改成了 3-6-6-3
-
查看 N/S/M/L/X 等不同大小模型,可以发现 N/S 和 L/X 两组模型只是改了缩放系数,但是 S/M/L 等骨干网络的通道数设置不一样,没有遵循同一套缩放系数。如此设计的原因应该是同一套缩放系数下的通道设置不是最优设计,YOLOv7 网络设计时也没有遵循一套缩放系数作用于所有模型
Head 部分变化最大,从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。其结构如下所示:
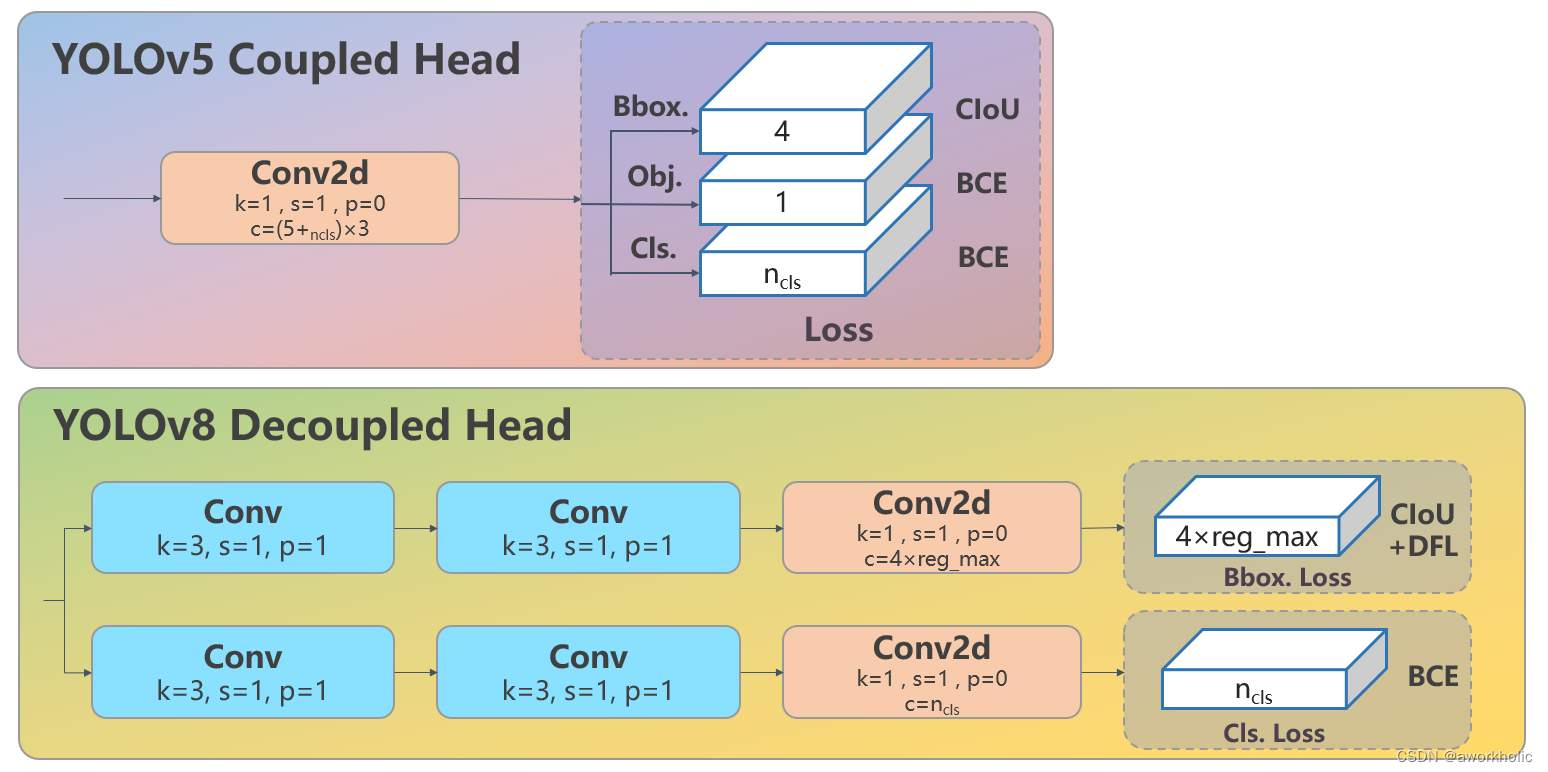
可以看出,不再有之前的 objectness 分支,只有解耦的分类和回归分支,并且其回归分支使用了 Distribution Focal Loss 中提出的积分形式表示法,
1.3、Loss 计算
Loss 计算过程包括 2 个部分: 正负样本分配策略和 Loss 计算。
现代目标检测器大部分都会在正负样本分配策略上面做文章,典型的如 YOLOX 的 simOTA、TOOD 的 TaskAlignedAssigner 和 RTMDet 的 DynamicSoftLabelAssigner,这类 Assigner 大都是动态分配策略,而 YOLOv5 采用的依然是静态分配策略。考虑到动态分配策略的优异性,YOLOv8 算法中则直接引用了 TOOD 的 TaskAlignedAssigner。
TaskAlignedAssigner 的匹配策略简单总结为: 根据分类与回归的分数加权的分数选择正样本。
s 是标注类别对应的预测分值,u 是预测框和 gt 框的 iou,两者相乘就可以衡量对齐程度。
- 对于每一个 GT,对所有的预测框基于 GT 类别对应分类分数,预测框与 GT 的 IoU 的加权得到一个关联分类以及回归的对齐分数 alignment_metrics
- 对于每一个 GT,直接基于 alignment_metrics 对齐分数选取 topK 大的作为正样本
Loss 计算包括 2 个分支: 分类和回归分支,没有了之前的 objectness 分支。
- 分类分支依然采用 BCE Loss
- 回归分支需要和 Distribution Focal Loss 中提出的积分形式表示法绑定,因此使用了 Distribution Focal Loss, 同时还使用了 CIoU Loss
- 3 个 Loss 采用一定权重比例加权即可。
1.4、数据增强
数据增强方面和 YOLOv5 差距不大,只不过引入了 YOLOX 中提出的最后 10 个 epoch 关闭 Mosaic 的操作。假设训练 epoch 是 500,其示意图如下左所示:
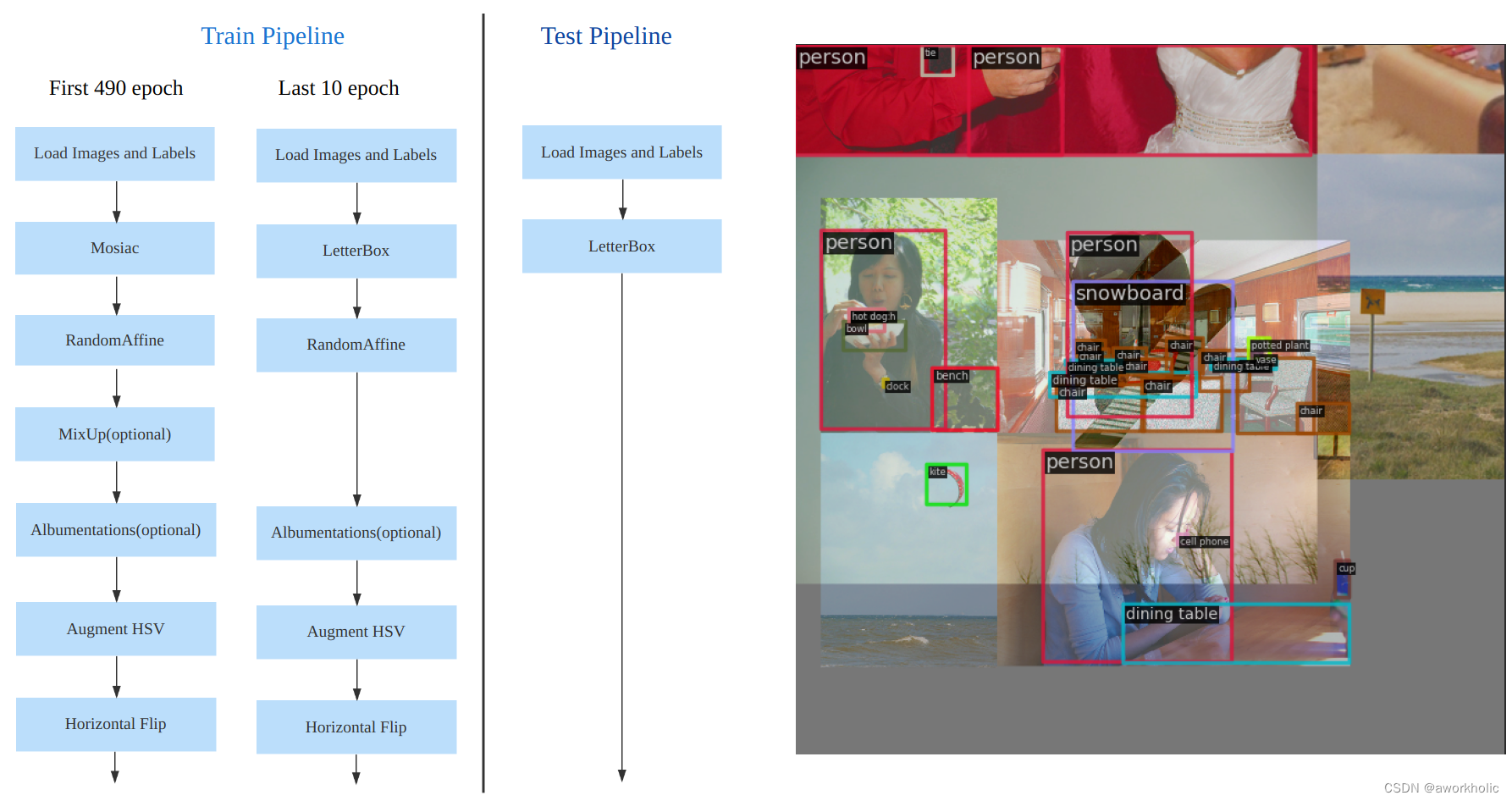
数据增强后典型效果上右所示:考虑到不同模型应该采用的数据增强强度不一样,因此对于不同大小模型,有部分超参会进行修改,典型的如大模型会开启 MixUp 和 CopyPaste。
1.5、训练策略
YOLOv8 的训练策略和 YOLOv5 没有啥区别,最大区别就是模型的 训练总 epoch 数从 300 提升到了 500,这也导致训练时间急剧增加。
1.6、推理过程
YOLOv8 的推理过程和 YOLOv5 几乎一样,唯一差别在于前面需要对 Distribution Focal Loss 中的积分表示 bbox 形式进行解码,变成常规的 4 维度 bbox,后续计算过程就和 YOLOv5 一样了。
以 COCO 80 类为例,假设输入图片大小为 640x640,MMYOLO 中实现的推理过程示意图如下所示:
暂时无法在飞书文档外展示此内容
其推理和后处理过程为:
(1) bbox 积分形式转换为 4d bbox 格式
对 Head 输出的 bbox 分支进行转换,利用 Softmax 和 Conv 计算将积分形式转换为 4 维 bbox 格式
(2) 维度变换
YOLOv8 输出特征图尺度为 80x80、40x40 和 20x20 的三个特征图。Head 部分输出分类和回归共 6 个尺度的特征图。
将 3 个不同尺度的类别预测分支、bbox 预测分支进行拼接,并进行维度变换。为了后续方便处理,会将原先的通道维度置换到最后,类别预测分支 和 bbox 预测分支 shape 分别为 (b, 80x80+40x40+20x20, 80)=(b,8400,80),(b,8400,4)。
(3) 解码还原到原图尺度
分类预测分支进行 Sigmoid 计算,而 bbox 预测分支需要进行解码,还原为真实的原图解码后 xyxy 格式。
(4) 阈值过滤
遍历 batch 中的每张图,采用 score_thr 进行阈值过滤。在这过程中还需要考虑 multi_label 和 nms_pre,确保过滤后的检测框数目不会多于 nms_pre。
(5) 还原到原图尺度和 nms
基于前处理过程,将剩下的检测框还原到网络输出前的原图尺度,然后进行 nms 即可。最终输出的检测框不能多于 max_per_img。
有一个特别注意的点:YOLOv5 中采用的 Batch shape 推理策略,在 YOLOv8 推理中暂时没有开启,不清楚后面是否会开启,在 MMYOLO 中快速测试了下,如果开启 Batch shape 会涨大概 0.1~0.2。
2、测试
使用Pip在一个Python>=3.8环境中安装ultralytics包,此环境还需包含PyTorch>=1.8。这也会安装所有必要的依赖项。
pip install ultralytics
2.1、官方Python测试
YOLOv8 可以在命令行界面(CLI)中直接使用,只需输入 yolo 命令:
yolo predict model=yolov8n.pt source='https://ultralytics.com/images/bus.jpg'
以 coco数据集训练的 yolov8m.pt 进行测试为例,执行脚本为 yolo predict model=yolov8m.pt source=bus.jpg device=0,运行输出如下
(yolo_pytorch) E:\yolov8-ultralytics>yolo predict model=yolov8m.pt source='https://ultralytics.com/images/bus.jpg' device=0
Ultralytics YOLOv8.0.154 Python-3.9.16 torch-1.13.1+cu117 CUDA:0 (NVIDIA GeForce GTX 1080 Ti, 11264MiB)
YOLOv8m summary (fused): 218 layers, 25886080 parameters, 0 gradients, 78.9 GFLOPs
Found https://ultralytics.com/images/bus.jpg locally at bus.jpg
image 1/1 E:\DeepLearning\yolov8-ultralytics\bus.jpg: 640x480 4 persons, 1 bus, 19.0ms
Speed: 3.0ms preprocess, 19.0ms inference, 4.0ms postprocess per image at shape (1, 3, 640, 480)
Results saved to runs\detect\predict9
首次运行时,会自动下载最新的模型文件。
cpu 和 gpu的时间
CPU 3.0ms preprocess, 447.6ms inference, 1.0ms postprocess
GPU 3.0ms preprocess, 19.0ms inference, 4.0ms postprocess
2.2、Opencv dnn测试
按照惯例将pt转换为onnx模型
yolo detect export model=yolov8m.pt format=onnx imgsz=640,640
输出如下:
(yolo_pytorch) E:\DeepLearning\yolov8-ultralytics>yolo detect export model=yolov8m.pt format=onnx imgsz=640,640
Ultralytics YOLOv8.0.154 Python-3.9.16 torch-1.13.1+cu117 CPU (Intel Core(TM) i7-7700K 4.20GHz)
YOLOv8m summary (fused): 218 layers, 25886080 parameters, 0 gradients, 78.9 GFLOPs
PyTorch: starting from 'yolov8m.pt' with input shape (1, 3, 640, 640) BCHW and output shape(s) (1, 84, 8400) (49.7 MB)
ONNX: starting export with onnx 1.14.0 opset 16...
ONNX: export success 3.3s, saved as 'yolov8m.onnx' (99.0 MB)
Export complete (7.4s)
Results saved to E:\DeepLearning\yolov8-ultralytics
Predict: yolo predict task=detect model=yolov8m.onnx imgsz=640
Validate: yolo val task=detect model=yolov8m.onnx imgsz=640 data=coco.yaml
Visualize: https://netron.app
注意,模型输出和前面版本的维度、顺序不一致,这里为 [84, 8400],因此,依然沿用之前的代码,对后处理的解码部分略作修改。
#include "opencv2/opencv.hpp"
#include <fstream>
#include <sstream>
#include <random>
using namespace cv;
using namespace dnn;
float inpWidth;
float inpHeight;
float confThreshold, scoreThreshold, nmsThreshold;
std::vector<std::string> classes;
std::vector<cv::Scalar> colors;
bool letterBoxForSquare = true;
cv::Mat formatToSquare(const cv::Mat &source);
void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& out, Net& net);
void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame);
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<int> dis(100, 255);
int test()
{
// 根据选择的检测模型文件进行配置
confThreshold = 0.25;
scoreThreshold = 0.45;
nmsThreshold = 0.5;
float scale = 1 / 255.0; //0.00392
Scalar mean = {0,0,0};
bool swapRB = true;
inpWidth = 640;
inpHeight = 640;
String modelPath = R"(E:\DeepLearning\yolov8-ultralytics\yolov8m.onnx)";
String configPath;
String framework = "";
//int backendId = cv::dnn::DNN_BACKEND_OPENCV;
//int targetId = cv::dnn::DNN_TARGET_CPU; //cpu 350ms, opencl 310
int backendId = cv::dnn::DNN_BACKEND_CUDA;
int targetId = cv::dnn::DNN_TARGET_CUDA; // cuda 15ms
String classesFile = R"(\data\coco.names)";
// Open file with classes names.
if(!classesFile.empty()) {
const std::string& file = classesFile;
std::ifstream ifs(file.c_str());
if(!ifs.is_open())
CV_Error(Error::StsError, "File " + file + " not found");
std::string line;
while(std::getline(ifs, line)) {
classes.push_back(line);
colors.push_back(cv::Scalar(dis(gen), dis(gen), dis(gen)));
}
}
// Load a model.
Net net = readNet(modelPath, configPath, framework);
net.setPreferableBackend(backendId);
net.setPreferableTarget(targetId);
std::vector<String> outNames = net.getUnconnectedOutLayersNames();
//std::vector<String> outNames{"output"};
if(backendId == cv::dnn::DNN_BACKEND_CUDA){
int dims[] = {1,3,inpHeight,inpWidth};
cv::Mat tmp = cv::Mat::zeros(4, dims, CV_32F);
std::vector<cv::Mat> outs;
net.setInput(tmp);
for(int i = 0; i < 10; i++)
net.forward(outs, outNames); // warmup
}
// Create a window
static const std::string kWinName = "Deep learning object detection in OpenCV";
cv::namedWindow(kWinName, 0);
// Open a video file or an image file or a camera stream.
VideoCapture cap;
cap.open(R"(E:\DeepLearning\yolov5\data\images\bus.jpg)");
cv::TickMeter tk;
// Process frames.
Mat frame, blob;
while(waitKey(1) < 0) {
//tk.reset();
//tk.start();
cap >> frame;
if(frame.empty()) {
waitKey();
break;
}
// Create a 4D blob from a frame.
cv::Mat modelInput = frame;
if(letterBoxForSquare && inpWidth == inpHeight)
modelInput = formatToSquare(modelInput);
blobFromImage(modelInput, blob, scale, cv::Size2f(inpWidth, inpHeight), mean, swapRB, false);
// Run a model.
net.setInput(blob);
std::vector<Mat> outs;
//tk.reset();
//tk.start();
auto tt1 = cv::getTickCount();
net.forward(outs, outNames);
auto tt2 = cv::getTickCount();
tk.stop();
postprocess(frame, modelInput.size(), outs, net);
//tk.stop();
Put efficiency information.
//std::vector<double> layersTimes;
//double freq = getTickFrequency() / 1000;
//double t = net.getPerfProfile(layersTimes) / freq;
//std::string label = format("Inference time: %.2f ms (%.2f ms)", t, /*tk.getTimeMilli()*/ (tt2 - tt1) / cv::getTickFrequency() * 1000);
std::string label = format("Inference time: %.2f ms", (tt2 - tt1) / cv::getTickFrequency() * 1000);
cv::putText(frame, label, Point(0, 15), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 255, 0));
//printf("\r%s\t", label.c_str());
cv::imshow(kWinName, frame);
}
return 0;
}
cv::Mat formatToSquare(const cv::Mat &source)
{
int col = source.cols;
int row = source.rows;
int _max = MAX(col, row);
cv::Mat result = cv::Mat::zeros(_max, _max, CV_8UC3);
source.copyTo(result(cv::Rect(0, 0, col, row)));
return result;
}
void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& outs, Net& net)
{
// yolov8 has an output of shape (batchSize, 84, 8400) (Num classes + box[x,y,w,h] + confidence[c])
auto tt1 = cv::getTickCount();
float x_factor = inputSz.width / inpWidth;
float y_factor = inputSz.height / inpHeight;
std::vector<int> class_ids;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
//int rows = outs[0].size[1];
//int dimensions = outs[0].size[2];
// [1, 84, 8400] -> [8400,84]
int rows = outs[0].size[2];
int dimensions = outs[0].size[1];
auto tmp = outs[0].reshape(1, dimensions);
cv::transpose(tmp, tmp);
float *data = (float *)tmp.data;
for(int i = 0; i < rows; ++i) {
//float confidence = data[4];
//if(confidence >= confThreshold) {
float *classes_scores = data + 4;
cv::Mat scores(1, classes.size(), CV_32FC1, classes_scores);
cv::Point class_id;
double max_class_score;
minMaxLoc(scores, 0, &max_class_score, 0, &class_id);
if(max_class_score > scoreThreshold) {
confidences.push_back(max_class_score);
class_ids.push_back(class_id.x);
float x = data[0];
float y = data[1];
float w = data[2];
float h = data[3];
int left = int((x - 0.5 * w) * x_factor);
int top = int((y - 0.5 * h) * y_factor);
int width = int(w * x_factor);
int height = int(h * y_factor);
boxes.push_back(cv::Rect(left, top, width, height));
}
//}
data += dimensions;
}
std::vector<int> indices;
NMSBoxes(boxes, confidences, scoreThreshold, nmsThreshold, indices);
auto tt2 = cv::getTickCount();
std::string label = format("NMS time: %.2f ms", (tt2 - tt1) / cv::getTickFrequency() * 1000);
cv::putText(frame, label, Point(0, 30), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 255, 0));
for(size_t i = 0; i < indices.size(); ++i) {
int idx = indices[i];
Rect box = boxes[idx];
drawPred(class_ids[idx], confidences[idx], box.x, box.y,
box.x + box.width, box.y + box.height, frame);
}
}
void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame)
{
rectangle(frame, Point(left, top), Point(right, bottom), Scalar(0, 255, 0));
std::string label = format("%.2f", conf);
Scalar color = Scalar::all(255);
if(!classes.empty()) {
CV_Assert(classId < (int)classes.size());
label = classes[classId] + ": " + label;
color = colors[classId];
}
int baseLine;
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
top = max(top, labelSize.height);
rectangle(frame, Point(left, top - labelSize.height),
Point(left + labelSize.width, top + baseLine), color, FILLED);
cv::putText(frame, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 0.5, Scalar());
}
2.3、测试统计
python (CPU):447ms
python (GPU):19ms
opencv dnn(CPU):
opencv dnn(GPU):
以下包含 预处理+推理+后处理:
openvino(CPU):217ms
onnxruntime(GPU):21ms
TensorRT:14ms
3、训练
这里基本和yolov5的训练一样,直接使用yolov5的数据集(跳转yolov5训练的链接),调整 train.txt、val.txt 和 myvoc.txt 中的路径。
以 yolov8m 为例,训练脚本如下:
yolo detect train data=custom-data\vehicle\myvoc.yaml model=yolov8m.pt epochs=20
输出界面如下:
(yolo_pytorch) E:\DeepLearning\yolov8-ultralytics>yolo detect train data=custom-data\vehicle\myvoc.yaml model=yolov8m.pt epochs=20
Ultralytics YOLOv8.0.154 Python-3.9.16 torch-1.13.1+cu117 CUDA:0 (NVIDIA GeForce GTX 1080 Ti, 11264MiB)
WARNING Upgrade to torch>=2.0.0 for deterministic training.
engine\trainer: task=detect, mode=train, model=yolov8m.pt, data=custom-data\vehicle\myvoc.yaml, epochs=20, patience=50, batch=16, imgsz=640, save=True, save_period=-1, cache=False, device=None, workers=8, project=None, name=None, exist_ok=False, pretrained=True, optimizer=auto, verbose=True, seed=0, deterministic=True, single_cls=False, rect=False, cos_lr=False, close_mosaic=10, resume=False, amp=True, fraction=1.0, profile=False, freeze=None, overlap_mask=True, mask_ratio=4, dropout=0.0, val=True, split=val, save_json=False, save_hybrid=False, conf=None, iou=0.7, max_det=300, half=False, dnn=False, plots=True, source=None, show=False, save_txt=False, save_conf=False, save_crop=False, show_labels=True, show_conf=True, vid_stride=1, line_width=None, visualize=False, augment=False, agnostic_nms=False, classes=None, retina_masks=False, boxes=True, format=torchscript, keras=False, optimize=False, int8=False, dynamic=False, simplify=False, opset=None, workspace=4, nms=False, lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=7.5, cls=0.5, dfl=1.5, pose=12.0, kobj=1.0, label_smoothing=0.0, nbs=64, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0, cfg=None, tracker=botsort.yaml, save_dir=runs\detect\train4
Overriding model.yaml nc=80 with nc=4
from n params module arguments
0 -1 1 1392 ultralytics.nn.modules.conv.Conv [3, 48, 3, 2]
1 -1 1 41664 ultralytics.nn.modules.conv.Conv [48, 96, 3, 2]
2 -1 2 111360 ultralytics.nn.modules.block.C2f [96, 96, 2, True]
3 -1 1 166272 ultralytics.nn.modules.conv.Conv [96, 192, 3, 2]
4 -1 4 813312 ultralytics.nn.modules.block.C2f [192, 192, 4, True]
5 -1 1 664320 ultralytics.nn.modules.conv.Conv [192, 384, 3, 2]
6 -1 4 3248640 ultralytics.nn.modules.block.C2f [384, 384, 4, True]
7 -1 1 1991808 ultralytics.nn.modules.conv.Conv [384, 576, 3, 2]
8 -1 2 3985920 ultralytics.nn.modules.block.C2f [576, 576, 2, True]
9 -1 1 831168 ultralytics.nn.modules.block.SPPF [576, 576, 5]
10 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
11 [-1, 6] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 2 1993728 ultralytics.nn.modules.block.C2f [960, 384, 2]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 [-1, 4] 1 0 ultralytics.nn.modules.conv.Concat [1]
15 -1 2 517632 ultralytics.nn.modules.block.C2f [576, 192, 2]
16 -1 1 332160 ultralytics.nn.modules.conv.Conv [192, 192, 3, 2]
17 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
18 -1 2 1846272 ultralytics.nn.modules.block.C2f [576, 384, 2]
19 -1 1 1327872 ultralytics.nn.modules.conv.Conv [384, 384, 3, 2]
20 [-1, 9] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 2 4207104 ultralytics.nn.modules.block.C2f [960, 576, 2]
22 [15, 18, 21] 1 3778012 ultralytics.nn.modules.head.Detect [4, [192, 384, 576]]
Model summary: 295 layers, 25858636 parameters, 25858620 gradients, 79.1 GFLOPs
Transferred 469/475 items from pretrained weights
TensorBoard: Start with 'tensorboard --logdir runs\detect\train4', view at http://localhost:6006/
Freezing layer 'model.22.dfl.conv.weight'
AMP: running Automatic Mixed Precision (AMP) checks with YOLOv8n...
AMP: checks passed
train: Scanning E:\DeepLearning\yolov8-ultralytics\custom-data\vehicle\labels.cache... 998 images, 0 backgrounds, 0 corrupt: 100%|█████████
val: Scanning E:\DeepLearning\yolov8-ultralytics\custom-data\vehicle\labels.cache... 998 images, 0 backgrounds, 0 corrupt: 100%|██████████|
Plotting labels to runs\detect\train4\labels.jpg...
optimizer: AdamW(lr=0.00125, momentum=0.9) with parameter groups 77 weight(decay=0.0), 84 weight(decay=0.0005), 83 bias(decay=0.0)
Image sizes 640 train, 640 val
Using 8 dataloader workers
Logging results to runs\detect\train4
Starting training for 20 epochs...
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
1/20 8.54G 0.7725 1.499 1.019 28 640: 100%|██████████| 63/63 [00:47<00:00, 1.34it/s]
Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 32/32 [00:13<00:00, 2.31it/s]
all 998 2353 0.876 0.857 0.925 0.774
Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size
2/20 8.62G 0.6806 0.7755 0.9495 83 640: 46%|████▌ | 29/63 [00:17<00:20, 1.65it/s]
4、Yolov8-pose 简单使用
人体姿态估计,使用coco数据集标注格式,17个关键点。
对 yolov8m-pose.pt 转换得到onnx如下,
(yolo_pytorch) E:\DeepLearning\yolov8-ultralytics>yolo pose export model=yolov8m-pose.pt format=onnx batch=1 imgsz=640
Ultralytics YOLOv8.0.154 Python-3.9.16 torch-1.13.1+cu117 CPU (Intel Core(TM) i7-7700K 4.20GHz)
YOLOv8m-pose summary (fused): 237 layers, 26447596 parameters, 0 gradients, 81.0 GFLOPs
PyTorch: starting from 'yolov8m-pose.pt' with input shape (1, 3, 640, 640) BCHW and output shape(s) (1, 56, 8400) (50.8 MB)
ONNX: starting export with onnx 1.14.0 opset 16...
ONNX: export success 3.3s, saved as 'yolov8m-pose.onnx' (101.2 MB)
Export complete (7.1s)
Results saved to E:\DeepLearning\yolov8-ultralytics
Predict: yolo predict task=pose model=yolov8m-pose.onnx imgsz=640
Validate: yolo val task=pose model=yolov8m-pose.onnx imgsz=640 data=/usr/src/app/ultralytics/datasets/coco-pose.yaml
Visualize: https://netron.app
输入为640时输出纬度为 (56,8400),56维数据格式定义为 4 + 1 + 17*3:
矩形框box[x,y,w,h],目标置信度conf, 17组关键点 (x, y, conf)。
在后处理中,添加一个保存关键点的数据,一个显示关键点的函数
void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& outs, Net& net)
{
// yolov8-pose has an output of shape (batchSize, 56, 8400) ( box[x,y,w,h] + conf + 17*(x,y,conf) )
...
std::vector<cv::Mat> keypoints;
for(int i = 0; i < rows; ++i) {
float confidence = data[4];
if(confidence >= confThreshold) {
...
boxes.push_back(cv::Rect(left, top, width, height));
cv::Mat keypoint(1, dimensions - 5, CV_32F, tmp.ptr<float>(i, 5));
for(int i = 0; i < 17; i++) {
keypoint.at<float>(i * 3 + 0) *= x_factor;
keypoint.at<float>(i * 3 + 1) *= y_factor;
}
keypoints.push_back(keypoint);
}
data += dimensions;
}
std::vector<int> indices;
NMSBoxes(boxes, confidences, scoreThreshold, nmsThreshold, indices);
for(size_t i = 0; i < indices.size(); ++i) {
...
drawSkelton(keypoints[idx], frame);
}
}
std::vector<cv::Scalar> kptcolors = {
{255, 0, 0}, {255, 85, 0}, {255, 170, 0}, {255, 255, 0}, {170, 255, 0}, {85, 255, 0},
{0, 255, 0}, {0, 255, 85}, {0, 255, 170}, {0, 255, 255}, {0, 170, 255}, {0, 85, 255},
{0, 0, 255}, {255, 0, 170}, {170, 0, 255}, {255, 0, 255}, {85, 0, 255},
};
std::vector<std::vector<int>> keypairs = {
{15, 13},{13, 11},{16, 14},{14, 12},{11, 12},{5, 11},
{6, 12},{5, 6},{5, 7},{6, 8},{7, 9},{8, 10},{1, 2},
{0, 1},{0, 2},{1, 3},{2, 4},{3, 5},{4, 6}
};
std::vector<std::vector<int>> keypairs = {
{15, 13},{13, 11},{16, 14},{14, 12},{11, 12},{5, 11},
{6, 12},{5, 6},{5, 7},{6, 8},{7, 9},{8, 10},{1, 2},
{0, 1},{0, 2},{1, 3},{2, 4},{3, 5},{4, 6}
};
void drawSkelton(const Mat& keypoints , Mat& frame)
{
for(auto& pair : keypairs) {
auto& pt1 = keypoints.at<cv::Point3f>(pair[0]);
auto& pt2 = keypoints.at<cv::Point3f>(pair[1]);
if(pt1.z > 0.5 && pt2.z > 0.5) {
cv::line(frame, cv::Point(pt1.x, pt1.y), cv::Point(pt2.x, pt2.y), {255,255,0}, 2);
}
}
for(int i = 0; i < 17; i++) {
Point3f pt = keypoints.at<cv::Point3f>(i);
if(pt.z < 0.5)
continue;
cv::circle(frame, cv::Point(pt.x, pt.y), 3, kptcolors[i], -1);
cv::putText(frame, cv::format("%d", i), cv::Point(pt.x, pt.y), 1, 1, {255,0,0});
}
}
结果如下:
