MongoDB生产部署方案
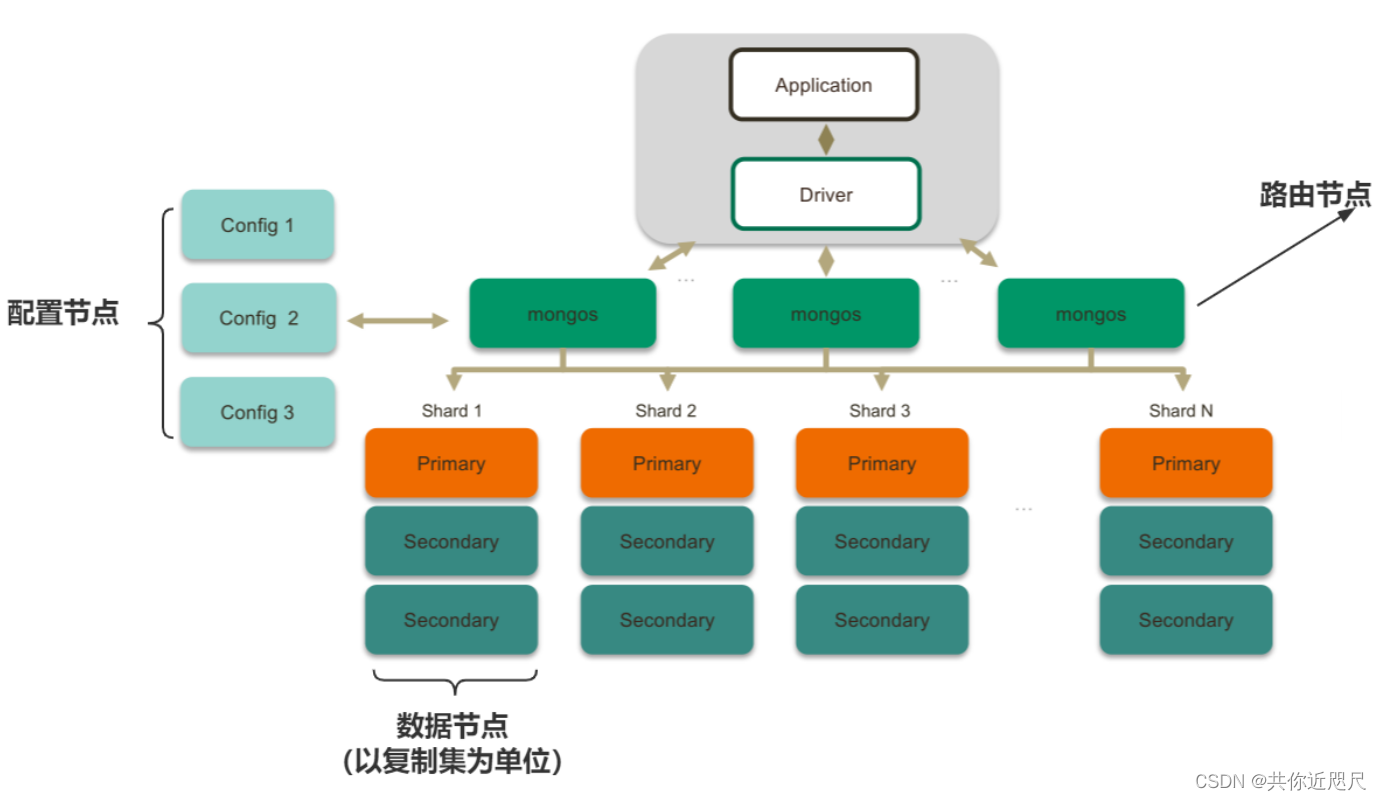
一、分片集群三种角色
- 路由节点——Router Service
提供集群单一入口,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用,router不存储数据。
搭建:可以有多个,理论上只需要使用一个,建议至少2个达到高可用。
功能:转发应用端请求,选择合适数据节点进行读写,合并多个数据节点的返回。
- 配置节点——Config Server
提供集群元数据存储目录,分片数据分布的映射(哪些数据放在哪个分片集群)
搭建:就是普通的复制集架构,一般1主2从提供高可用。
配置节点中比较重要的就是Shared这张表,里面存储分片中数据的范围。
(路由节点在启动的时候会把配置节点的数据加载到自己的内存当中,方便快的进行数据的比对,完成数据的分发处理)
- 数据节点(mongod)
以复制集为单位(避免单点故障)
分片之间数据不重复
横向扩展
最大1024分片
所有分片在一起才可完整工作
二、部署步骤
在生产集群中使用6台物理机,确保数据冗余并且您的系统具有高可用性。对于生产分片集群部署:
- 将配置服务器部署为 3 成员副本集
- 将每个分片部署为 2 个成员的副本集
- 部署3台mongos台路由器
| 机器 | 端口 | 服务 | 备注 |
| 0.0.0.1 | 7017 | router service | 路由节点 |
| 7019 | shard service | 主(rs01) | |
| 0.0.0.2 | 7017 | router service | 路由节点 |
| 7019 | shard service | 主(rs02) | |
| 0.0.0.3 | 7017 | router service | 路由节点 |
| 7019 | shard service | 主(rs03) | |
| 0.0.0.4 | 7018 | config service | 配置服务 |
| 7019 | shard service | 从(rs01) | |
| 0.0.0.5 | 7018 | config service | 配置服务 |
| 7019 | shard service | 从(rs02) | |
| 0.0.0.6 | 7018 | config service | 配置服务 |
| 7019 | shard service | 从(rs03) |
操作1:上传MongoDB包并解压、放到规划的目录下、创建文件
官网下载地址:Download MongoDB Community Server | MongoDB
执行命令查看Linux适合的Mongodb包
cat /etc/os-release
每台机器都要执行的脚本
# 解压
tar -zxvf mongodb-linux-x86_64-4.0.24.tgz
# 修改文件名
rm mongodb-linux-x86_64-4.0.24 mongodb
# 在mongodb文件中创建文件夹
mkdir -p mongodb/{router,config,shard,key}操作2:配置节点部署(config server )
在4、5、6机器上面执行的部署
#创建日志文件
touch mongodb/config/config.log
#创建配置文件
touch mongodb/config/config.conf
#创建存储数据目录
mkdir mongodb/config/data -p配置文件(config.conf )内容(配置中文件路径根据实际路径修改)
systemLog:
destination: file
logAppend: true
path: /data/mongodb/config/config.log
storage:
dbPath: /data/mongodb/config/data
journal:
enabled: true
processManagement:
fork: true
timeZoneInfo: /usr/share/zoneinfo
net:
port: 7018
bindIp: 0.0.0.0
replication:
replSetName: clustersvr
sharding:
clusterRole: configsvr
security:
authorization: enabled
keyFile: /data/mongodb/key/mongo.keyfile注:上面配置在没有设置mongodb密码的情况下,请注释掉security对应的配置。
启动mongodb config Service(4、5、6机器)
#启 mongodb config service
mongodb/bin/mongod -f mongodb/config/config.conf
#检查是否启动成功
netstat -antup | grep mongod登录客户端,配置configsvr
#新版 使用 mongosh ,老板 使用 mongo ,在文件mongodb/bin目录下面
mongo --port 7018
mongosh --port 7018
#切换到 admin 库下
use admin
#添加副本集群关系 127.0.0.1(生产换成对应的内网IP)注意:测试环境使用 0.0.0.0:port 或报错
rs.initiate({ _id:"clustersvr",
configsvr: true,
members:[
{_id:0,host:"127.0.0.1:7018"},
{_id:1,host:"127.0.0.1:8018"},
{_id:2,host:"127.0.0.1:9018"}
]
})
#查看状态
rs.status();操作3:路由节点mongos部署(router server )
在1、2、3机器上执行以下操作
#创建配置文件 -- 是在解压的mongodb目录下
touch mongodb/router/router.conf
#创建日志文件
touch mongodb/router/router.log在mongodb/router/router.conf文件配置
systemLog:
destination: file
logAppend: true
path: /data/mongodb/router/router.log
processManagement:
fork: true
timeZoneInfo: /usr/share/zoneinfo
net:
port: 7018
bindIp: 0.0.0.0
sharding:
configDB: clustersvr/0.0.0.4:7018,0.0.0.5:7018,0.0.0.6:7018注意:配置文件里面的路径是否正确,不然可能会导致启动失败
#启动,注意是mongos,不是mongod了
mongodb/bin/mongos -f mongodb/router/router.conf
netstat -antup | grep mongod操作4:数据节点部署(shard server )
每一台机器上都需要的操作,每两个机器做一个副本集群 rs01、rs02、rs03
# 存放数据目录
mkdir -p mongodb/shard/data
#创建配置文件
touch mongodb/shard/shard.conf
#创建日志文件
touch mongodb/shard/shard.log
systemLog:
destination: file
logAppend: true
path: /data/mongodb/shard/shard.log
storage:
dbPath: /data/mongodb/shard/data
journal:
enabled: true
processManagement:
fork: true
timeZoneInfo: /usr/share/zoneinfo
net:
port: 7019
bindIp: 0.0.0.0
replication:
replSetName: rs01
sharding:
clusterRole: shardsvr
#启动 使用 mongod 不是 mongos
mongodb/bin/mongod -f mongodb/shard/shard4.conf
netstat -antup | grep mongod
副本集群 rs01
mongodb/bin/mongo --port 7019
use admin
rs.initiate({ _id:"rs01",
members:[
{_id:0,host:"0.0.0.1:7019"},
{_id:1,host:"0.0.0.2:7019"}
]
})
rs.status()副本集群 rs02
mongo --port 7019
use admin
config = { _id:"rs01",
members:[
{_id:0,host:"0.0.0.3:7019"},
{_id:1,host:"0.0.0.4:7019"}
]
}
rs.initiate(config)
rs.status()副本集群 rs03
mongo --port 7019
use admin
config = { _id:"rs01",
members:[
{_id:0,host:"0.0.0.5:7019"},
{_id:1,host:"0.0.0.6:7019"}
]
}
rs.initiate(config)
#查看状态
rs.status()操作5:Router Service中填加Shard Service
mongosh IP:7017
use admin
sh.addShard("rs01/IP:7021,IP:7022");
sh.addShard("rs02/IP:7023,IP:7024");
sh.addShard("rs03/IP:7025,IP:7025");
# 注意使用的是 sh 不是 rs
sh.status();sh.status() 命令 查看 MongoDB 数据库中的 sharding (分片) 状态信息
- sharding version:展示了当前系统使用的分片版本信息以及集群 ID。
- _id:分片集群的版本号,在同一个集群中必须唯一。
- minCompatibleVersion:该版本所兼容的最小版本号,如果某个分片服务器的版本低于此值,则不能加入到该集群中。
- currentVersion:当前使用的版本号。
- clusterId:集群的唯一标识符,由 ObjectId 类型表示。
- shards:列出了所有的分片服务器,包括它们的 _id、host 和状态(1 表示启用)等信息。
- active mongoses:显示当前激活的 mongos 实例的版本信息和数量。
- autosplit:表示是否启用自动分片功能。
- balancer:表示均衡器的状态,包括是否启用、是否正在运行、最近 5 次均衡尝试的失败次数以及最近 24 小时内迁移的结果。
- Currently enabled:表示均衡器是否启用。
- Currently running:表示均衡器当前是否正在运行。
- Failed balancer rounds in last 5 attempts:表示最近 5 次均衡尝试中失败的次数。
- Migration Results for the last 24 hours:列出了最近 24 小时内迁移的结果。具体来说,它展示了统计周期内已完成的迁移数量和状态(Success 表示成功,其他状态可能包括 InProgress、Failed 等)。在本例中,共有 120 次迁移成功。
- databases:列出了所有分片的数据库,包括每个数据库所在的 primary 分片、是否被分片(partitioned)以及具体的分片情况,如 chunks 数量等。其中 config 数据库保存了整个集群的元数据信息。
- _id:文档的唯一标识符,此处为 "config"
- primary:该分片集群中被指定为主节点的副本集名称,也是 config 数据库的主分片
- partitioned:一个布尔值,指示此数据库是否已经被分片(即将数据划分到多个物理节点上)
- config.system.sessions:config 数据库中名为 "system.sessions" 的集合,用于存储会话信息
- shard key:用于划分数据的键,此处是 "_id",表示数据将根据其 "_id" 值分配到不同的物理节点上
- unique:一个布尔值,指示 shard key 是否唯一
- balancing:一个布尔值,指示是否启用了自动均衡机制,该机制可确保每个分片上的数据量大致相同
- chunks:一个包含各个分片上数据块数量的对象,其中键是分片副本集的名称,值是该副本集上的数据块数量。
三、测试
插入数据
mongosh IP:7017
#创建数据库
use mydb
#插入数据
for(i=1; i<=500;i++){
db.myuser.insert( {name:'mytest'+i, age:i} )
}
#查看状态
sh.status()
#查看文档数量
db.myuser.count();
db.myuser.countDocuments()
db.myuser.estimatedDocumentCount()切换到rs01节点: 可见在从分片上并没有数据,注意:默认情况下所有数据未分片存储,只存在主集群中。
./mongosh 192.168.178.134:29019
use mydb
db.myuser.estimatedDocumentCount()
db.myuser.find({"name":"mytest400"});数据分片存储
mongosh 192.168.178.134:27017
use mydb
db.dropDatabase()
use admin
db.runCommand( { enablesharding :"mydb"});
db.runCommand( { shardcollection : "mydb.myuser",key : {_id: "hashed"} } )
use mydb
for(i=1; i<=500;i++){
db.myuser.insert( {name:'mytest'+i, age:i} )
}