url、域名、IP、爬虫

(图片来自b站up主——编程八点档)
':' : 分隔主机域名
'/' :分隔主机域名和路径
'?' : 分隔路径和查询参数
'=' : 设定参数的值
'&' : 分隔不同的查询参数对
我们用浏览器搜索的时候,用的是关键字(查询参数)

我们可以通过修改查询参数,实现在同一个IP域名下,快速爬取不同的元素
IP地址:192.168.1.xx
域名:www.baidu.com(用字符化的形式来对计算机网络中的主机进行网络标识)
域名是为了保证每个网站服务器的访问地址是独一无二的,它需要向统一管理域名的集构或组织注册或备档
所有主机设备上网都需要IP地址,但并不是所有主机设备都需要申请域名
我们来找一下百度的ip地址
在cmd中输入ping www.baidu.com , 就可以看到查询到这个域名的ip地址 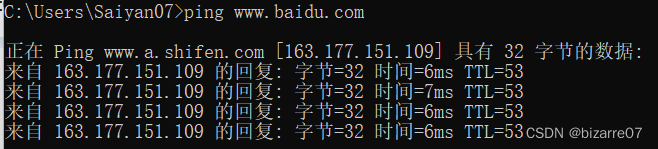
我们试试用IP访问:
url采用的是ASCII编码方式,不是Unicode,所以url网址中不能有非ASCII的字符
我们在浏览器中输入关键字是中文啊?——因为浏览器已经对url里的中文进行了编码
我将网址复制下来之后其实是这样的:
https://www.baidu.com/s?ie=UTF-8&wd=%E6%88%91%E5%9C%A8%E5%8A%AA%E5%8A%9B%E5%AD%A6%E4%B9%A0编码 quote()
解码 unquote()
from urllib import parse
key_word = '我在努力学习'
key_word_ascii = parse.quote(key_word)
print(key_word_ascii)会打印出一串ASCII字符:%E6%88%91%E5%9C%A8%E5%8A%AA%E5%8A%9B%E5%AD%A6%E4%B9%A0
如果要爬虫的话
涉及的代码:
from urllib import parse, response
from urllib import request
key_word = '我在努力学习'
key_word_ascii = parse.quote(key_word)
print(key_word_ascii)
response = request.urlopen("http://www.baidu.com/s?ie=UTF-8&wd{0}".format(key_word_ascii))
result = response.read().decode('utf-8')
print(result)另一种方式:
import requests
url = "http://www.baidu.com/s?ie=UTF-8&wd=我在努力学习"
response = requests.get(url)
response.encoding = 'UTF-8'
print(response.text)