ovs+dpdk 三级流表(microflow/megaflow/openflow)
本文介绍在ovs+dpdk下,三级流表的原理及其源码实现。普通模式ovs的第一和二级流表原理和ovs+dpdk下的大同小异,三级流表完全一样。
基本概念
microflow
最开始openflow流表是在kernel中实现的,但是因为在kernel中开发和更新代码相对困难,并且这种方式不被认可。
所以将openflow流表实现移到userspace中,同时kernel中改成microflow cache,此缓存是一个hash表,需要精确匹配报文的所有字段。
megaflow
microflow的问题是如果报文任何字段发生改变,都会导致查找microflow失败,然后将报文上送userspace查找openflow流表来决定如何处理。
这意味着转发性能依赖于microflow流表建立时间,这段时间包括kernel上送miss事件userspace,以及userspace查找openflow流表并下发microflow流表的时间总和。
如果在短连接很多的场景下,microflow cache就会遇到很严重的性能问题,因为不仅要将miss事件上报userspace,还要在userspace查找openflow的多个table。所以就有了megaflow,用来替换microflow。megaflow cache采用模糊匹配的方法,这样就能大大减少miss事件。megaflow流表和openflow流表很类似,因为megaflow也支持根据报文任意字段匹配。但是megaflow相比openflow流表更简单,更轻量,
有两个原因:
a. megaflow不支持优先级,这样在查到megaflow流表后,就能立即停止查找,而不用担心错过更高优先级的流表而查找所有流表。
b. megaflow只使用一个流分类器,而不像openflow支持最多255个分类器。userspace下发megaflow流表时,需要将查找255个分类器用到的所有字段全部下发到megaflow。
尽管megaflow只有一个分类器,但是它需要为每个mask生成一个subtable,报文查找megaflow流表时,也需要查找多个subtable才能匹配到。如果有n个subtable表,最坏的情况下需要查找n次,这样看来基于分类器的megaflow相比于microflow,需要查找更多hash表。
ovs解决这个问题的方法是使用microflow作为第一级缓存,用来保存到megaflow流表的映射。这样的话,第一个报文查找microflow和megaflow失败后,上送miss事件到userspace查找openflow流表,然后下发megaflow流表,并在microflow建立映射,后续的报文就能在microflow命中,根据映射关系直接找到megaflow进行处理。
openflow
第三级流表,由最多255个table组成,每个table包含一个分类器,所有流表都插入到分类器中,具体实现可参考这里
三级流表的查找顺序
microflow在ovs+dpdk代码中,又被称为EMC(exact match cache)。
megaflow在ovs+dpdk代码中,又被称为dpcls(datapath classifer)。
从网卡接收到报文后,首先查找EMC表项,如果命中则直接执行action,如果miss则查找dpcls。
如果查找dpcls命中,则将规则插入EMC,并且执行action。还是miss的话,就查找openflow流表。
如果查找openflow命中,则将规则插入dpcls和EMC,并且执行action。还是miss的话,就丢包或者发给controller。
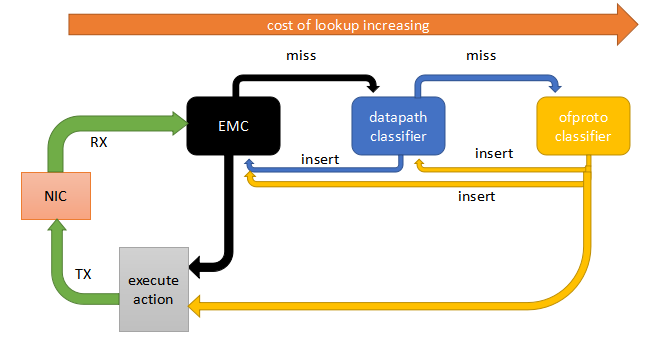
image.png
数据结构
主要看一下第一级和第二级流表的数据结构。
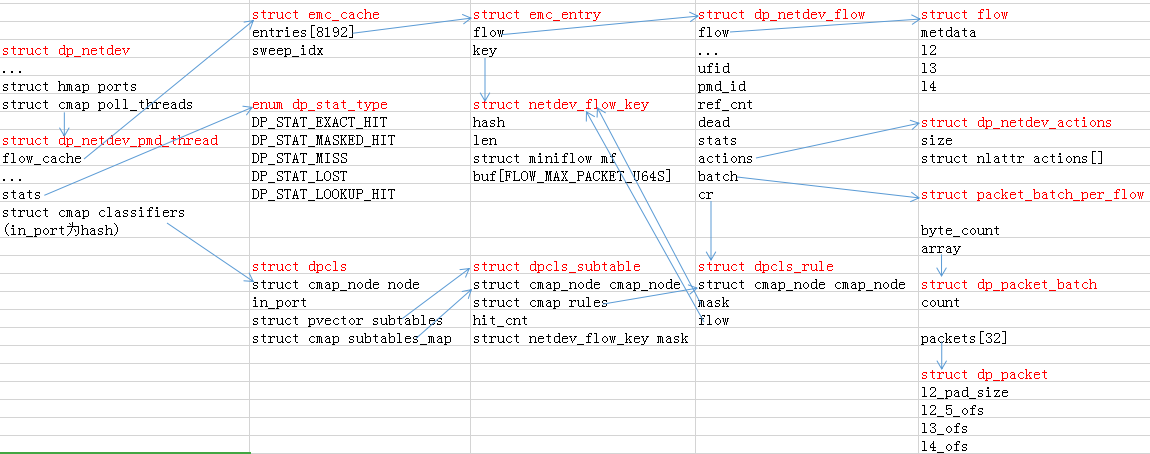
image.png
struct dp_netdev
代表一个datapath。在ovs+dpdk下,datapath也位于用户空间,所有netdev类型的网桥共享同一个datapath。
ports: 用于保存datapath下的所有端口,包括网桥的所有物理端口(不包含patch口)。
poll_threads: 用于保存datapath下的所有pmd线程相关信息。pmd线程的个数由如下逻辑决定:
//如果没有 pmd 类型的port,则pmd_cores为空
if (!has_pmd_port(dp)) {
pmd_cores = ovs_numa_dump_n_cores_per_numa(0);
//如果有pmd类型的port,并且指定了 pmd-cpu-mask,则按照指定的maks启动pmd线程
} else if (dp->pmd_cmask && dp->pmd_cmask[0]) {
pmd_cores = ovs_numa_dump_cores_with_cmask(dp->pmd_cmask);
//如果没指定 pmd-cpu-mask,则默认每个numa节点上启动一个pmd线程
} else {
pmd_cores = ovs_numa_dump_n_cores_per_numa(NR_PMD_THREADS);
}
struct dp_netdev_pmd_thread
表示一个pmd线程相关信息。
flow_cache: 这个就是EMC流表,每个pmd线程有一个EMC。
stats: 用来统计EMC和dpcls的命中和miss情况。
enum dp_stat_type {
//命中EMC流表次数
DP_STAT_EXACT_HIT, /* Packets that had an exact match (emc). */
//命中dpcls流表次数
DP_STAT_MASKED_HIT, /* Packets that matched in the flow table. */
//miss dpcls流表次数
DP_STAT_MISS, /* Packets that did not match. */
//查找dpcls过程中丢包个数,包括查找openflow流表后下发megaflow时超出流表最大限制的丢包
DP_STAT_LOST, /* Packets not passed up to the client. */
//查找dpcls时,查了subtable的个数
DP_STAT_LOOKUP_HIT, /* Number of subtable lookups for flow table
hits */
DP_N_STATS
};
struct cmap classifiers: 用来保存dpcls。每个port都对应一个dpcls。
struct emc_cache
用来保存8k个emc表项。
flow: 类型struct dp_netdev_flow,主要包含流表的action。
key: 类型struct netdev_flow_key,主要包含匹配项。key是从报文提取出来的内容,精确表示一条数据流。
struct dpcls
表示一个datapath分类器,使用TSS查找算法,将相同mask的流表插入同一个subtable。
in_port: 此分类器所属端口。
subtables: subtable数组,用于查找时遍历subtable。
struct dpcls_subtable
具体相同mask的流表集合。
rules: 保存流表。
mask: 类型struct netdev_flow_key,subtable的mask。
struct dpcls_rule
表示一个dpcls流表的匹配域。
struct dp_netdev_flow
表示一条datapath流表,包含匹配域和动作。
actions: 指向此流表的动作。
cr: 指向struct dpcls_rule,表示此流表的匹配域。
batch: 类型struct packet_batch_per_flow,将匹配的此流表的报文插入batch,用于批量处理报文,这也是dpcls的一个优化。
源码分析
从网卡收包
//主线程从非pmd类型端口收包
dpif_netdev_run
//pmd线程中从pmd类型端口收包
pmd_thread_main
dp_netdev_process_rxq_port ->dp_netdev_input -> dp_netdev_input__
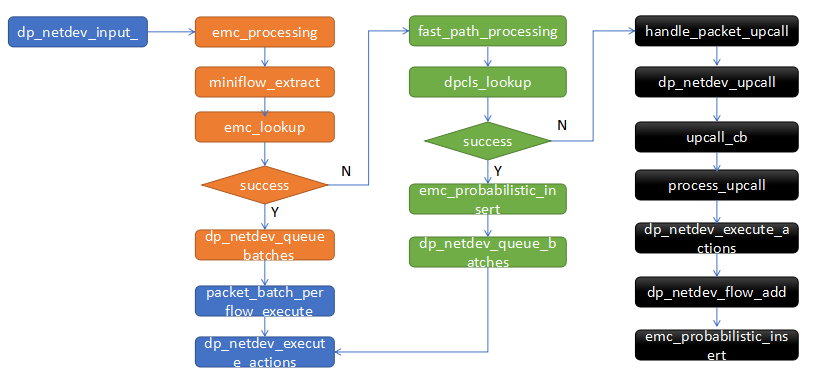
收包后,从dp_netdev_input__开始流程如下
microflow && EMC
emc_insert
在EMC中插入表项,注意这里不是无条件插入的,原因会在下面说明。
static inline void
emc_probabilistic_insert(struct dp_netdev_pmd_thread *pmd,
const struct netdev_flow_key *key,
struct dp_netdev_flow *flow)
{
/* Insert an entry into the EMC based on probability value 'min'. By
* default the value is UINT32_MAX / 100 which yields an insertion
* probability of 1/100 ie. 1% */
uint32_t min;
atomic_read_relaxed(&pmd->dp->emc_insert_min, &min);
if (min && random_uint32() <= min) {
emc_insert(&pmd->flow_cache, key, flow);
}
}
emc_insert将表项插入emc,为了解决hash冲突,一个emc表项可能会存在两个位置,首先根据hash值计算一个位置,如果这个位置已经有其他表项了,则将hash值右移13位计算第二个位置,如果第二个位置也被占领了,但是第二个位置所在表项hash值小于第一个位置hash的话,就将emc表项插入第二个位置,否则将emc表项插入第一个位置。
static inline void
emc_insert(struct emc_cache *cache, const struct netdev_flow_key *key,
struct dp_netdev_flow *flow)
{
struct emc_entry *to_be_replaced = NULL;
struct emc_entry *current_entry;
//遍历可能的两个位置,找个合适的
EMC_FOR_EACH_POS_WITH_HASH(cache, current_entry, key->hash) {
if (netdev_flow_key_equal(¤t_entry->key, key)) {
/* We found the entry with the 'mf' miniflow */
emc_change_entry(current_entry, flow, NULL);
return;
}
/* Replacement policy: put the flow in an empty (not alive) entry, or
* in the first entry where it can be */
if (!to_be_replaced
|| (emc_entry_alive(to_be_replaced)
&& !emc_entry_alive(current_entry))
|| current_entry->key.hash < to_be_replaced->key.hash) {
to_be_replaced = current_entry;
}
}
/* We didn't find the miniflow in the cache.
* The 'to_be_replaced' entry is where the new flow will be stored */
emc_change_entry(to_be_replaced, flow, key);
}
static inline void
emc_change_entry(struct emc_entry *ce, struct dp_netdev_flow *flow,
const struct netdev_flow_key *key)
{
if (ce->flow != flow) {
if (ce->flow) {
dp_netdev_flow_unref(ce->flow);
}
if (dp_netdev_flow_ref(flow)) {
ce->flow = flow;
} else {
ce->flow = NULL;
}
}
if (key) {
netdev_flow_key_clone(&ce->key, key);
}
}
为什么不能无条件的插入emc表项,可参考下面提交代码时的说明
https://mail.openvswitch.org/pipermail/ovs-dev/2017-February/328697.html
Unconditional insertion of EMC entries results in EMC thrashing at high
numbers of parallel flows. When this occurs, the performance of the EMC
often falls below that of the dpcls classifier, rendering the EMC
practically useless.
Instead of unconditionally inserting entries into the EMC when a miss
occurs, use a 1% probability of insertion. This ensures that the most
frequent flows have the highest chance of creating an entry in the EMC,
and the probability of thrashing the EMC is also greatly reduced.
The probability of insertion is configurable, via the
other_config:emc-insert-prob option. For example the following command
increases the insertion probability to 10%.
ovs-vsctl set Open_vSwitch . other_config:emc-insert-prob=10
emc-insert-prob 值越小,代表插入可能性越高。如果设置为1,则会百分百插入emc表项,如果设置为0,则关闭emc功能。
emc_lookup
emc_lookup查找emc表项。
//遍历emc表项
/* Iterate in the exact match cache through every entry that might contain a
* miniflow with hash 'HASH'. */
#define EMC_FOR_EACH_POS_WITH_HASH(EMC, CURRENT_ENTRY, HASH) \
for (uint32_t i__ = 0, srch_hash__ = (HASH); \
(CURRENT_ENTRY) = &(EMC)->entries[srch_hash__ & EM_FLOW_HASH_MASK], \
i__ < EM_FLOW_HASH_SEGS; \
i__++, srch_hash__ >>= EM_FLOW_HASH_SHIFT)
static inline struct dp_netdev_flow *
emc_lookup(struct emc_cache *cache, const struct netdev_flow_key *key)
{
struct emc_entry *current_entry;
//一个emc表项只可能在两个位置,所以最多遍历两次
EMC_FOR_EACH_POS_WITH_HASH(cache, current_entry, key->hash) {
//表项hash值相等,并且是alive状态,并且key相等,说明命中了emc表项
if (current_entry->key.hash == key->hash
&& emc_entry_alive(current_entry)
&& netdev_flow_key_equal_mf(¤t_entry->key, &key->mf)) {
/* We found the entry with the 'key->mf' miniflow */
return current_entry->flow;
}
}
return NULL;
}
emc表项删除
emc表项的删除一种是在插入时,直接被替换。
另一种是pmd线程中周期性的清理emc表项。
pmd_thread_main -> emc_cache_slow_sweep
/* Check and clear dead flow references slowly (one entry at each
* invocation). */
static void
emc_cache_slow_sweep(struct emc_cache *flow_cache)
{
struct emc_entry *entry = &flow_cache->entries[flow_cache->sweep_idx];
if (!emc_entry_alive(entry)) {
emc_clear_entry(entry);
}
flow_cache->sweep_idx = (flow_cache->sweep_idx + 1) & EM_FLOW_HASH_MASK;
}
emc_processing
收到报文后,首先调用emc_processing查询emc流表。
/* Try to process all ('cnt') the 'packets' using only the exact match cache
* 'pmd->flow_cache'. If a flow is not found for a packet 'packets[i]', the
* miniflow is copied into 'keys' and the packet pointer is moved at the
* beginning of the 'packets' array.
*
* The function returns the number of packets that needs to be processed in the
* 'packets' array (they have been moved to the beginning of the vector).
*
* If 'md_is_valid' is false, the metadata in 'packets' is not valid and must
* be initialized by this function using 'port_no'.
*/
static inline size_t
emc_processing(struct dp_netdev_pmd_thread *pmd,
struct dp_packet_batch *packets_,
struct netdev_flow_key *keys,
struct packet_batch_per_flow batches[], size_t *n_batches,
bool md_is_valid, odp_port_t port_no)
{
struct emc_cache *flow_cache = &pmd->flow_cache;
struct netdev_flow_key *key = &keys[0];
size_t n_missed = 0, n_dropped = 0;
struct dp_packet *packet;
const size_t size = dp_packet_batch_size(packets_);
uint32_t cur_min;
int i;
//获取插入emc的可能性,如果为0,说明emc流表被关闭
atomic_read_relaxed(&pmd->dp->emc_insert_min, &cur_min);
//遍历报文
DP_PACKET_BATCH_REFILL_FOR_EACH (i, size, packet, packets_) {
struct dp_netdev_flow *flow;
//报文长度太小,丢包
if (OVS_UNLIKELY(dp_packet_size(packet) < ETH_HEADER_LEN)) {
dp_packet_delete(packet);
n_dropped++;
continue;
}
if (i != size - 1) {
struct dp_packet **packets = packets_->packets;
/* Prefetch next packet data and metadata. */
OVS_PREFETCH(dp_packet_data(packets[i+1]));
pkt_metadata_prefetch_init(&packets[i+1]->md);
}
//初始化metadata
if (!md_is_valid) {
pkt_metadata_init(&packet->md, port_no);
}
//从报文提前flow信息,保存到key->mf
miniflow_extract(packet, &key->mf);
key->len = 0; /* Not computed yet. */
//获取hash值,如果通过网卡的RSS收包则直接从mbuf获取hash值,否则需要软件计算hash
key->hash = dpif_netdev_packet_get_rss_hash(packet, &key->mf);
//cur_min为0,说明EMC是关闭的,不用查询
/* If EMC is disabled skip emc_lookup */
flow = (cur_min == 0) ? NULL: emc_lookup(flow_cache, key);
if (OVS_LIKELY(flow)) {
//查到了EMC表项,将报文插入flow的batch,方便后面批量处理
dp_netdev_queue_batches(packet, flow, &key->mf, batches,
n_batches);
} else {
/* Exact match cache missed. Group missed packets together at
* the beginning of the 'packets' array. */
//没查到emc,将报文重新插入packets_
dp_packet_batch_refill(packets_, packet, i);
/* 'key[n_missed]' contains the key of the current packet and it
* must be returned to the caller. The next key should be extracted
* to 'keys[n_missed + 1]'. */
key = &keys[++n_missed];
}
}
//增加命中emc的计数
dp_netdev_count_packet(pmd, DP_STAT_EXACT_HIT,
size - n_dropped - n_missed);
//返回未命中emc并且没有被丢弃的报文个数
return dp_packet_batch_size(packets_);
}
megaflow && dpcls
dpcls_insert
将一条rule插入dpcls中,首先根据流表的mask(查完openflow后的通配符)查找是否已经有subtable,没有的话创建一个新的subtable,以后有相同mask的rule可以插入到相同的subtable。
/* Insert 'rule' into 'cls'. */
static void
dpcls_insert(struct dpcls *cls, struct dpcls_rule *rule,
const struct netdev_flow_key *mask)
{
struct dpcls_subtable *subtable = dpcls_find_subtable(cls, mask);
/* Refer to subtable's mask, also for later removal. */
rule->mask = &subtable->mask;
cmap_insert(&subtable->rules, &rule->cmap_node, rule->flow.hash);
}
dpcls_lookup
查找keys在dpcls中的流表,并保存到对应的rules中。最后一个参数num_lookups_p用来保存查找了几个subtable。返回值为true说明全部匹配上了,为false说明有部分没有匹配上,需要继续查找openflow流表。
/* For each miniflow in 'keys' performs a classifier lookup writing the result
* into the corresponding slot in 'rules'. If a particular entry in 'keys' is
* NULL it is skipped.
*
* This function is optimized for use in the userspace datapath and therefore
* does not implement a lot of features available in the standard
* classifier_lookup() function. Specifically, it does not implement
* priorities, instead returning any rule which matches the flow.
*
* Returns true if all miniflows found a corresponding rule. */
static bool
dpcls_lookup(struct dpcls *cls, const struct netdev_flow_key keys[],
struct dpcls_rule **rules, const size_t cnt,
int *num_lookups_p)
{
/* The received 'cnt' miniflows are the search-keys that will be processed
* to find a matching entry into the available subtables.
* The number of bits in map_type is equal to NETDEV_MAX_BURST. */
typedef uint32_t map_type;
#define MAP_BITS (sizeof(map_type) * CHAR_BIT)
BUILD_ASSERT_DECL(MAP_BITS >= NETDEV_MAX_BURST);
struct dpcls_subtable *subtable;
//初始化keys_map为全1
map_type keys_map = TYPE_MAXIMUM(map_type); /* Set all bits. */
map_type found_map;
uint32_t hashes[MAP_BITS];
const struct cmap_node *nodes[MAP_BITS];
//cnt是报文个数,如果不为MAP_BITS,即不是32的话,就要将keys_map中多余的1清除掉。
if (cnt != MAP_BITS) {
keys_map >>= MAP_BITS - cnt; /* Clear extra bits. */
}
memset(rules, 0, cnt * sizeof *rules);
int lookups_match = 0, subtable_pos = 1;
/* The Datapath classifier - aka dpcls - is composed of subtables.
* Subtables are dynamically created as needed when new rules are inserted.
* Each subtable collects rules with matches on a specific subset of packet
* fields as defined by the subtable's mask. We proceed to process every
* search-key against each subtable, but when a match is found for a
* search-key, the search for that key can stop because the rules are
* non-overlapping. */
//遍历subtable
PVECTOR_FOR_EACH (subtable, &cls->subtables) {
int i;
/* Compute hashes for the remaining keys. Each search-key is
* masked with the subtable's mask to avoid hashing the wildcarded
* bits. */
//遍历keys_map,根据subtable的mask计算hash值
ULLONG_FOR_EACH_1(i, keys_map) {
hashes[i] = netdev_flow_key_hash_in_mask(&keys[i],
&subtable->mask);
}
/* Lookup. */
//根据hash值批量查找,如果找到了则将对应位置1,返回到found_map
found_map = cmap_find_batch(&subtable->rules, keys_map, hashes, nodes);
/* Check results. When the i-th bit of found_map is set, it means
* that a set of nodes with a matching hash value was found for the
* i-th search-key. Due to possible hash collisions we need to check
* which of the found rules, if any, really matches our masked
* search-key. */
//遍历found_map
ULLONG_FOR_EACH_1(i, found_map) {
struct dpcls_rule *rule;
//上面只是根据hash查找,返回值nodes可能是匹配hash值的一个集合,这里遍历nodes[i]找到真正匹配的流表
CMAP_NODE_FOR_EACH (rule, cmap_node, nodes[i]) {
if (OVS_LIKELY(dpcls_rule_matches_key(rule, &keys[i]))) {
//找到了rule,保存到rules[i]
rules[i] = rule;
/* Even at 20 Mpps the 32-bit hit_cnt cannot wrap
* within one second optimization interval. */
subtable->hit_cnt++;
lookups_match += subtable_pos;
goto next;
}
}
/* None of the found rules was a match. Reset the i-th bit to
* keep searching this key in the next subtable. */
//hash匹配,但是key不匹配,还需要继续查找下一个subtable,将对应bit设置为0
ULLONG_SET0(found_map, i); /* Did not match. */
next:
; /* Keep Sparse happy. */
}
//清除找到rule的位
keys_map &= ~found_map; /* Clear the found rules. */
//如果keys_map为0,说明全部都匹配到rule,可以返回了
if (!keys_map) {
//返回查找subtable次数
if (num_lookups_p) {
*num_lookups_p = lookups_match;
}
//全部匹配了返回true
return true; /* All found. */
}
//仍然需要继续查找下一个subtable
subtable_pos++;
}
if (num_lookups_p) {
*num_lookups_p = lookups_match;
}
//有一些没有匹配上返回false,告诉调用者需要继续查找openflow流表
return false; /* Some misses. */
}
dpcls_remove
dpcls的流表删除可以参考这篇文章,通过revalidator线程完成,超时后删除或者响应openflow变动被删除。
fast_path_processing
emc_processing查找emc失败后,就开始调用fast_path_processing查找dpcls。
static inline void
fast_path_processing(struct dp_netdev_pmd_thread *pmd,
struct dp_packet_batch *packets_,
struct netdev_flow_key *keys,
struct packet_batch_per_flow batches[], size_t *n_batches,
odp_port_t in_port,
long long now)
{
int cnt = packets_->count;
#if !defined(__CHECKER__) && !defined(_WIN32)
const size_t PKT_ARRAY_SIZE = cnt;
#else
/* Sparse or MSVC doesn't like variable length array. */
enum { PKT_ARRAY_SIZE = NETDEV_MAX_BURST };
#endif
struct dp_packet **packets = packets_->packets;
struct dpcls *cls;
struct dpcls_rule *rules[PKT_ARRAY_SIZE];
struct dp_netdev *dp = pmd->dp;
int miss_cnt = 0, lost_cnt = 0;
int lookup_cnt = 0, add_lookup_cnt;
bool any_miss;
size_t i;
for (i = 0; i < cnt; i++) {
/* Key length is needed in all the cases, hash computed on demand. */
keys[i].len = netdev_flow_key_size(miniflow_n_values(&keys[i].mf));
}
/* Get the classifier for the in_port */
//根据入端口找到它的dpcls
cls = dp_netdev_pmd_lookup_dpcls(pmd, in_port);
if (OVS_LIKELY(cls)) {
//调用dpcls_lookup进行匹配
any_miss = !dpcls_lookup(cls, keys, rules, cnt, &lookup_cnt);
} else {
any_miss = true;
memset(rules, 0, sizeof(rules));
}
//如果有miss的,则需要进行openflow流表查询
if (OVS_UNLIKELY(any_miss) && !fat_rwlock_tryrdlock(&dp->upcall_rwlock)) {
uint64_t actions_stub[512 / 8], slow_stub[512 / 8];
struct ofpbuf actions, put_actions;
ofpbuf_use_stub(&actions, actions_stub, sizeof actions_stub);
ofpbuf_use_stub(&put_actions, slow_stub, sizeof slow_stub);
for (i = 0; i < cnt; i++) {
struct dp_netdev_flow *netdev_flow;
if (OVS_LIKELY(rules[i])) {
continue;
}
/* It's possible that an earlier slow path execution installed
* a rule covering this flow. In this case, it's a lot cheaper
* to catch it here than execute a miss. */
netdev_flow = dp_netdev_pmd_lookup_flow(pmd, &keys[i],
&add_lookup_cnt);
if (netdev_flow) {
lookup_cnt += add_lookup_cnt;
rules[i] = &netdev_flow->cr;
continue;
}
miss_cnt++;
//开始查找openflow流表。
如果查找openflow流表成功并需要下发到dpcls时,需要判断是否超出最大流表限制
handle_packet_upcall(pmd, packets[i], &keys[i], &actions,
&put_actions, &lost_cnt, now);
}
ofpbuf_uninit(&actions);
ofpbuf_uninit(&put_actions);
fat_rwlock_unlock(&dp->upcall_rwlock);
} else if (OVS_UNLIKELY(any_miss)) {
for (i = 0; i < cnt; i++) {
if (OVS_UNLIKELY(!rules[i])) {
dp_packet_delete(packets[i]);
lost_cnt++;
miss_cnt++;
}
}
}
for (i = 0; i < cnt; i++) {
struct dp_packet *packet = packets[i];
struct dp_netdev_flow *flow;
if (OVS_UNLIKELY(!rules[i])) {
continue;
}
flow = dp_netdev_flow_cast(rules[i]);
//查找dpcls成功的,需要将相关rule下发到emc表项
emc_probabilistic_insert(pmd, &keys[i], flow);
dp_netdev_queue_batches(packet, flow, &keys[i].mf, batches, n_batches);
}
//统计信息
dp_netdev_count_packet(pmd, DP_STAT_MASKED_HIT, cnt - miss_cnt);
dp_netdev_count_packet(pmd, DP_STAT_LOOKUP_HIT, lookup_cnt);
dp_netdev_count_packet(pmd, DP_STAT_MISS, miss_cnt);
dp_netdev_count_packet(pmd, DP_STAT_LOST, lost_cnt);
}
openflow流表
第一级和第二级流表查找失败后,就要查找第三级流表了,即openflow流表,这也称为upcall调用,在普通ovs下是通过netlink实现的,在ovs+dpdk下,直接在pmd线程中调用upcall_cb即可。
static int
upcall_cb(const struct dp_packet *packet, const struct flow *flow, ovs_u128 *ufid,
unsigned pmd_id, enum dpif_upcall_type type,
const struct nlattr *userdata, struct ofpbuf *actions,
struct flow_wildcards *wc, struct ofpbuf *put_actions, void *aux)
{
static struct vlog_rate_limit rl = VLOG_RATE_LIMIT_INIT(1, 1);
struct udpif *udpif = aux;
struct upcall upcall;
bool megaflow;
int error;
//读取enable_megaflows,用来控制是否开启megaflow。
//可以通过命令开启 "ovs-appctl upcall/enable-megaflows"
atomic_read_relaxed(&enable_megaflows, &megaflow);
error = upcall_receive(&upcall, udpif->backer, packet, type, userdata,
flow, 0, ufid, pmd_id);
if (error) {
return error;
}
//查找openflow流表,又是很长的函数调用
error = process_upcall(udpif, &upcall, actions, wc);
if (error) {
goto out;
}
if (upcall.xout.slow && put_actions) {
ofpbuf_put(put_actions, upcall.put_actions.data,
upcall.put_actions.size);
}
//如果关闭了megaflow,则将flow信息转换到wc,即megaflow也将变成精确匹配。
//如果开启megaflow,则wc查找openflow流表的通配符集合,小于等于flow信息。
if (OVS_UNLIKELY(!megaflow && wc)) {
flow_wildcards_init_for_packet(wc, flow);
}
//如果超过了最大流表限制,则返回ENOSPC
if (!should_install_flow(udpif, &upcall)) {
error = ENOSPC;
goto out;
}
if (upcall.ukey && !ukey_install(udpif, upcall.ukey)) {
VLOG_WARN_RL(&rl, "upcall_cb failure: ukey installation fails");
error = ENOSPC;
}
out:
if (!error) {
upcall.ukey_persists = true;
}
upcall_uninit(&upcall);
return error;
}
查找openflow流表
process_upcall -> upcall_xlate -> xlate_actions -> rule_dpif_lookup_from_table
miss_config = OFPUTIL_TABLE_MISS_CONTINUE;
//从指定的table_id开始查找
for (next_id = *table_id;
next_id < ofproto->up.n_tables;
next_id++, next_id += (next_id == TBL_INTERNAL))
{
*table_id = next_id;
//到table的分类器中查找流表,并设置wc
rule = rule_dpif_lookup_in_table(ofproto, version, next_id, flow, wc);
//如果查找到了,则返回
if (rule) {
goto out; /* Match. */
}
//如果没有查找,则根据配置选择继续查找下一个table还是结束查找
if (honor_table_miss) {
miss_config = ofproto_table_get_miss_config(&ofproto->up,
*table_id);
if (miss_config == OFPUTIL_TABLE_MISS_CONTINUE) {
continue;
}
}
break;
}也可参考:ovs+dpdk 三级流表(microflow/megaflow/openflow) - 简书 (jianshu.com)