ServletContext,Response详解
ServletContext
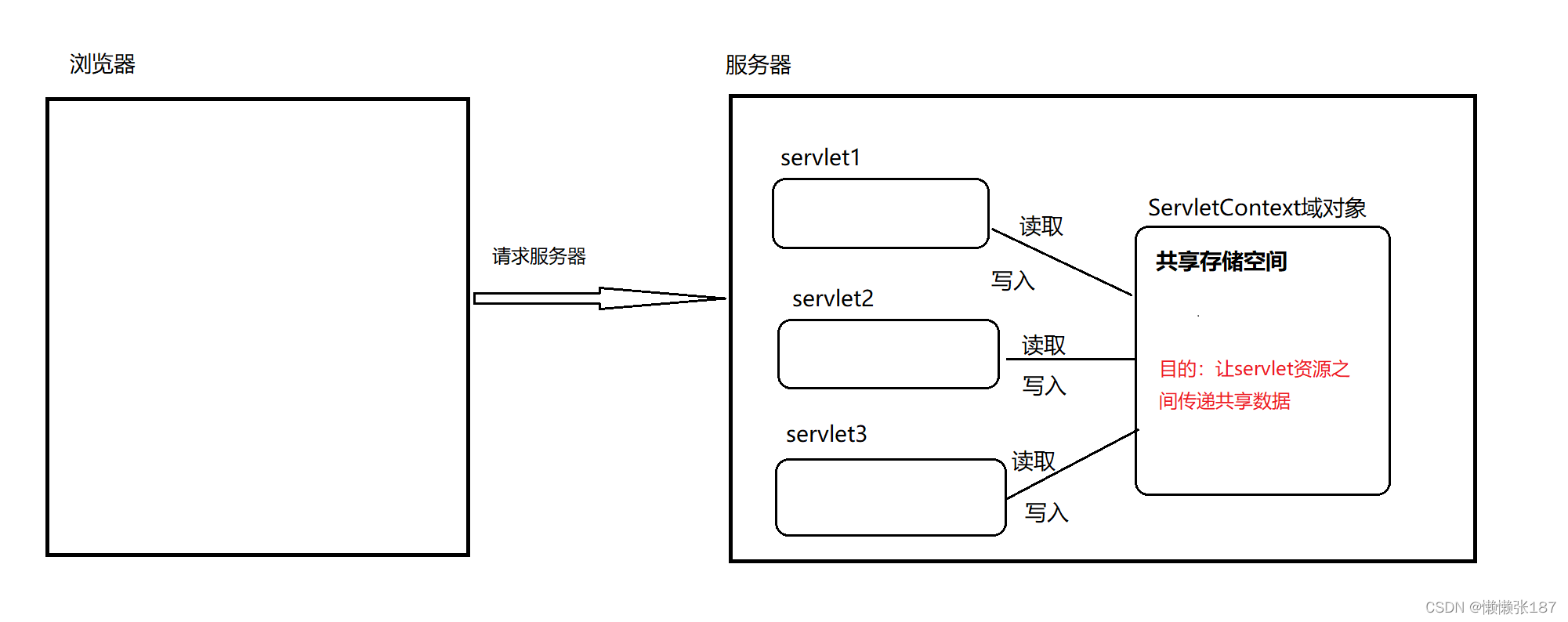
ServletContext官方叫servlet上下文。服务器会为每一个工程创建一个对象,这个对象就是ServletContext对象。这个对象全局唯一,而且工程内部的所有servlet都共享这个对象。所以叫全局应用程序共享对象。(项目一启动,servletcontext初始化)
ServletContext :
1.获得项目下的资源 获得get 赋值set
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//获得项目下的资源
//目的:获得 web/img/logo.jpg
//1.先拿到servletContext
//ServletContext sc = getServletContext();
ServletContext sc1 = this.getServletContext();
//2.通过ServletContext去获得项目下的资源
//Resource 资源
//sc1.getResource("");//获得 文件的地址
// 获得文件在磁盘下的绝对物理位置 返回值是字符串
//参数是: 文件的名称 , 获得路径的时候 从 项目的发布路径下开始
//D:\ideaProject\web\out\artifacts\day03_war_exploded
String realPath = sc1.getRealPath("/img/logo.jpg");
//System.out.println(realPath); File file =new File () InputOutput.....
//从 项目的发布路径下开始
InputStream is = sc1.getResourceAsStream("/img/logo.jpg");//直接获得文件的流
System.out.println(is);
}
2.在项目下不同资源中共享数据
2.1准备两个servlet
2.2一个servlet存数据、另一个servlet取数据
api:
getAttribute( String key) 取数据
setAttribute( String key , Object value) 存数据
removeAttribute( String key ) 删除数据
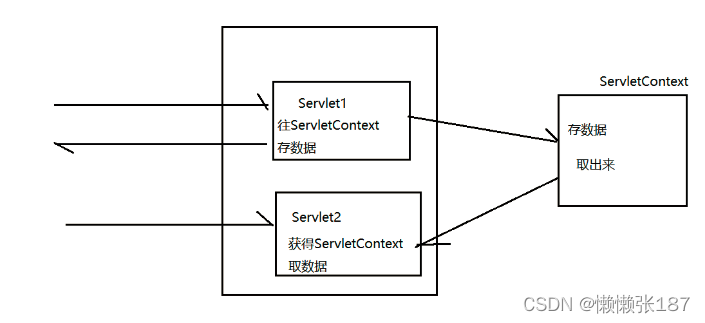
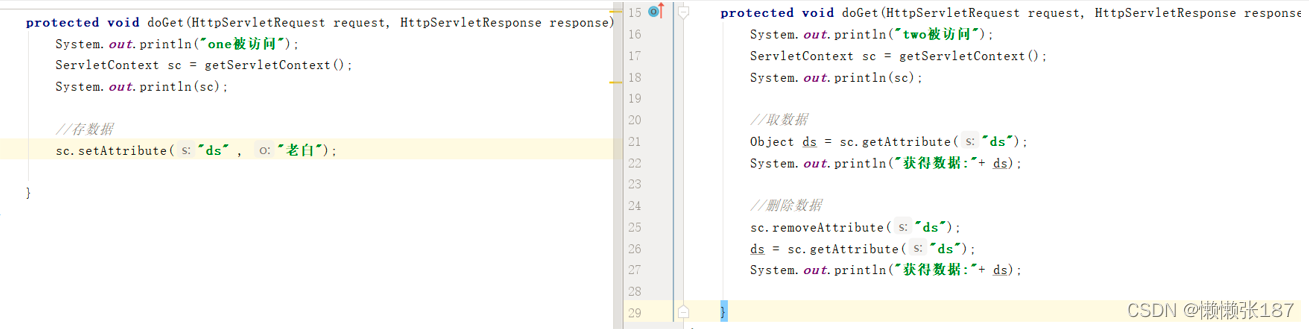
在不同的servlet中可以共享数据的对象,我们称之为域对象。
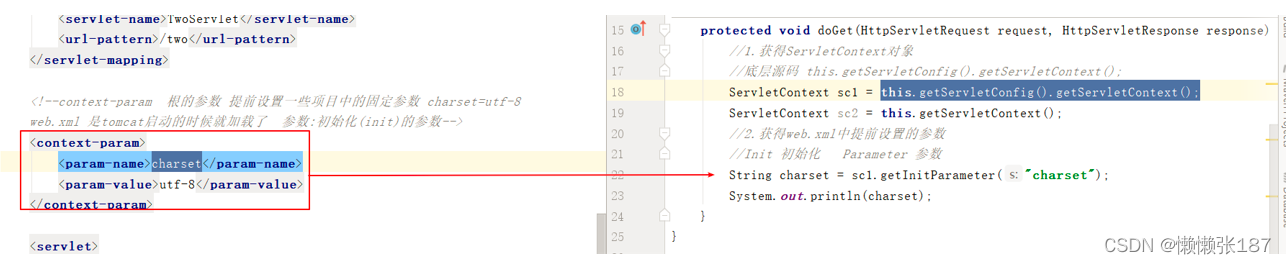
其他api(servletContext是个根对象,在初始化时可获得初始化数据)
getInitParameter(“key”):获得在web.xml中提前定义的数据
获得servletContext的方式:
this.getServletContext();
this.getServletConfig().getServletConetxt();
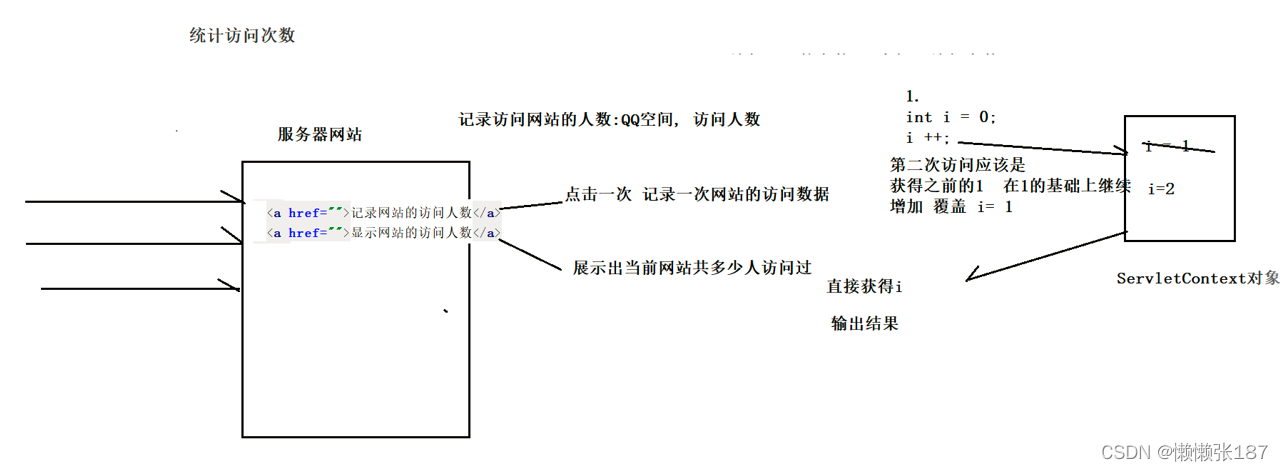
使用ServletContext统计访问次数
代码实现:
/**
* 记录访问人数
* @param request
* @param response
* @throws ServletException
* @throws IOException
*/
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//1.第一次访问(初始化) 还是第N次访问(拿到之前的值 开始增加)
//2.获得ServletContext对象
ServletContext sc = this.getServletContext();
//3.获得ServletContext中的存储的访问次数
Object count = sc.getAttribute("count");
if(count == null){ //没有赋值过 第一次访问
//4.如果没有 肯定是第一次访问
int i = 0 ;
i ++; //增加了访问的次数
sc.setAttribute( "count" , i); //重新赋值count数据
System.out.println("第一次访问:" +i );
}else{
//5.如果有 肯定是第N次访问
//拿出来原来的值 原来的值是Object 必须强转
int i = Integer.valueOf( count.toString() );
//Integer.parseInt( count.toString() );
i ++ ;
sc.setAttribute( "count" , i); //重新赋值count数据
System.out.println("第N次访问:" +i);
}
}
Response
行
HTTP/1.1 200
格式:协议版本 状态码
1xx 2xx 3xx 4xx 5xx
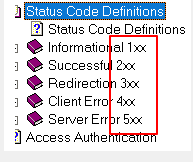
200:响应成功
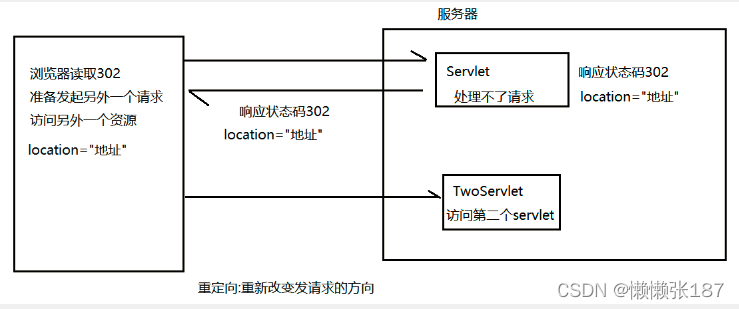
302:重定向
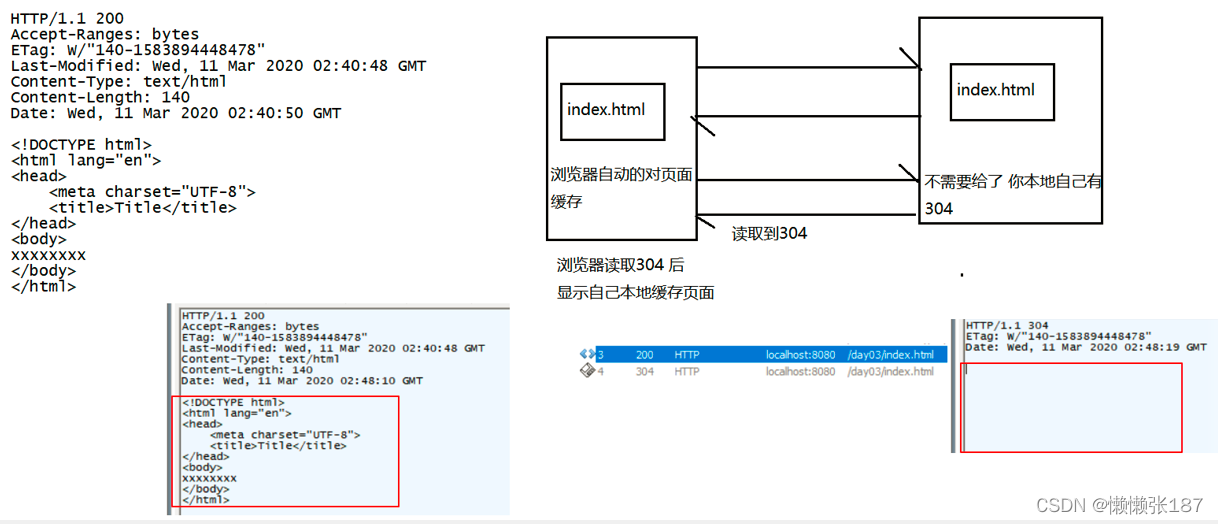
304:浏览器缓存
404:资源没有找到
405:doget或dopost方法丢失
500:服务器端代码错误
头
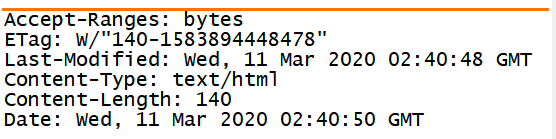
响应会自带响应头给浏览器
response.setHeader(String , Object) 赋值响应头
1.location
重定向操作:通常告知浏览器马上向该地址发送请求,通常和响应码302一起使用
2.refresh
定时刷新操作,指定时间后跳转到指定页面
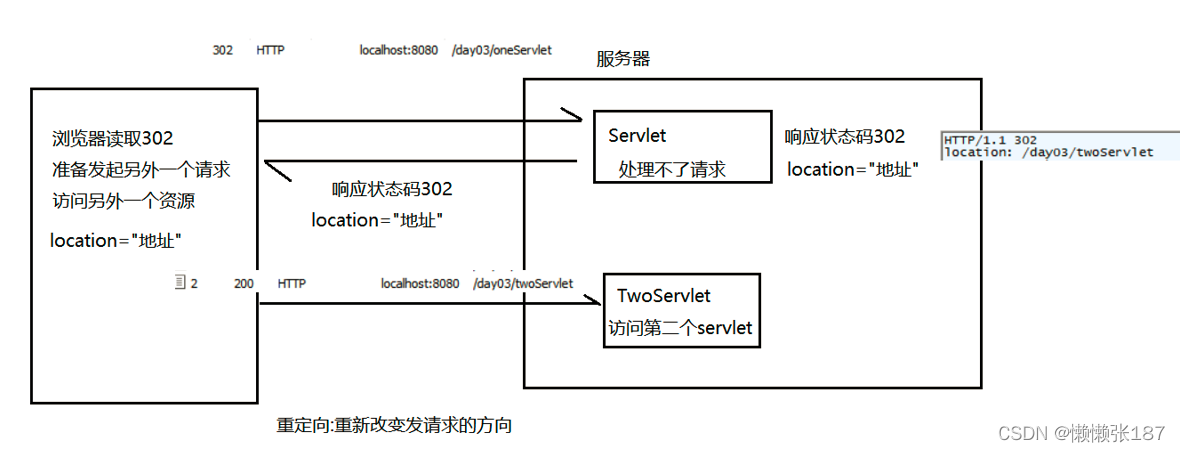
重定向代码:
OneServlet
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.out.println("OneServlet被访问了");
response.setStatus(302);//设置状态码
response.setHeader("location" , "/day03/twoServlet");//设置路径
//web中简化api 也表示重定向 好处在于 不需要记忆状态码 只需要设置路径即可
//System.out.println("这是简化api的效果");
response.sendRedirect("/day03/twoServlet");
}
TwoServlet
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.out.println("twoServlet被访问了");
}
refresh定时刷新
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
/**
* 定时刷新 refresh
* 参数1:refresh 响应头
* 参数2:
* 方式1: 秒 定时刷新
* 方式2: 秒;url=地址 定时多少秒后跳转某个地址
*/
//定时刷新的代码
//response.setHeader("refresh" , "1");
response.setHeader("refresh" , "3;url=https://www.baidu.com/");
//往页面输出一个当前时间(下午)
response.getWriter().print(new Date().toLocaleString());
}
3.content-encoding:设置当前数据的压缩格式,告知浏览器以何种压缩格式解压数据
4.content-disposition:通知浏览器以何种方式获取数据(直接解析数据(网页、图片),或者以附件方式(下载文件))
5.content-type:实体头部用于指示资源的MIME类型(MIME类型:用于提示当前文件的媒体类型,例如图片为:image/png、音频为:audio/ogg)。它的作用与传统上windows上的文件扩展名相同。该名称源于最初电子邮件的MIME标准。
体
响应行- > 状态码
响应头 - > 重定向 , 定时刷新
响应体其实就是流数据
字符流
字节流
流数据说明
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
//响应数据
/**
* 字节流: 用于输出 视频 图片 音频 文件....
* ServletOutputStream outputStream = response.getOutputStream();
* response.getOutputStream().print();
* response.getOutputStream().write();
* 字符流:
* response.getWriter() 打印流 一般用于输出字符
* PrintWriter writer = response.getWriter();
* writer.print("hello world");
* writer.write("hello world");
* print 和 write
* print的底层用的其实就是 write
* print 将数据进行特殊转换 如果使用write 都需要自己转换
* 总结: 建议使用print
*/
//所有的浏览器的效果必须同步 , 中文在传输的时候 乱码了
//特殊设置响应头 content 内容 type类型
//很重要且必须放在方法代码第一行 500指的是服务器的代码错误
response.setContentType("text/html;charset=utf-8");//简化api
response.setHeader("content-type" , "text/html;charset=utf-8");
//响应的数据最终是浏览器解析的, 而我们需要告诉浏览器 以什么样的方式解析我们的数据
//text/html;charset=utf-8 text/javascript texts
//text/html 表示响应的数据都是html格式 charset=utf-8 编码是utf-8
response.getWriter().print("a<a href=''>我是一个标签</a>");
}
案例—下载文件
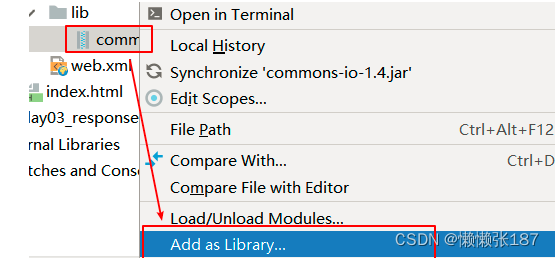
引入jar包过程
1.在WEB-INF下创建lib的文件夹
2.将jar包复制进去
3.右键jar包 add lib… 添加jar包
public class DownLoadServlet extends HttpServlet {
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
System.out.println("say hello");
/**
* 我需要的效果是下载图片
* 如果我们希望浏览器特殊处理 只需要告诉浏览器 我当前的问下 需要下载 而不是直接打开
* 文件下载的标准写法:2个头 一个流(字节输出流)
* content-disposition : (必须需要) content-disposition 响应内容的设置
* 值: attachment;filename=文件名.后缀 attachment 附件 filename 文件名称 = 文件名称.后缀
* content-type : 可有可无
*/
//通知浏览器 ,我们响应的数据 需要以附件的形式下载 文件的名称叫 abc.jpg
response.setHeader("content-disposition" , "attachment;filename=abc.jpg");
//输出图片 借助的是一个 字节流
//1.获得到图片
//获得项目下的资源文件流 输入流
InputStream is = getServletContext().getResourceAsStream("/jar/logo.jpg");
//2.目的输出图片 - 借助字节流 输出流 (空)
ServletOutputStream os = response.getOutputStream();
//3.将输入流转换成输出流 (流转换)
IOUtils.copy(is , os);//流转换完成
//4.释放资源
os.close();
is.close();
}
}