深度学习论文分享(八)Learning Event-Driven Video Deblurring and Interpolation
深度学习论文分享(八)Learning Event-Driven Video Deblurring and Interpolation
and Interpolation)
前言
论文原文:https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123530681.pdf
论文代码:暂无
Title:Learning Event-Driven Video Deblurring and Interpolation
Authors:ongnan Lin1?, Jiawei Zhang2 ??, Jinshan Pan3, Zhe Jiang2, Dongqing Zou2,
Yongtian Wang1, Jing Chen1 ??, and Jimmy Ren2
1 Beijing Institute of Technology, Beijing, China
2 SenseTime Research, Shenzhen, China
3 Nanjing University of Science and Technology, Nanjing, China
在此仅做翻译
Abstract
基于事件的传感器在像素强度变化超过触发阈值时具有响应,可以以微秒级精度捕获高速运动。在事件相机的辅助下,我们可以从低帧率的模糊视频中生成高帧率的清晰视频。本文提出了一种有效的基于深度卷积神经网络(cnn)的事件驱动视频去模糊和插值算法。基于模糊图像和锐帧之间的残差是事件积分的物理模型,该网络利用事件来估计锐帧恢复的残差。由于触发阈值的空间变化,我们提出了一种有效的估计动态滤波器的方法来解决这一问题。为了利用时间信息,还考虑了从之前的模糊帧恢复的清晰帧。该算法在合成数据集和真实数据集上都取得了较好的性能。
1 Introduction
快速移动物体的慢动作分析对于许多应用来说是至关重要的,但对于只能捕获低帧率模糊视频的传统强度相机来说是具有挑战性的。为了捕捉高速运动,最近的一些作品,如[10,9],试图通过去模糊[24,26,28]和插值[17,13,1],在低帧率模糊的视频中生成高帧率的视频。尽管它们在某些情况下取得了成功,但它们可能无法处理严重模糊的视频(见图1(e))。
不是纯粹依赖于强度相机(intensity camera),这项工作利用事件为基础的一个高时间分辨率,以弥补在强度帧丢失的信息。事件相机[5,12]是受生物启发的传感器,能够以微秒级精度异步编码像素强度的变化,即事件。大量工作[3,2,15,21]致力于将事件流直接转换为强度视频。然而,从这些事件依赖的解决方案重建的视频往往缺乏纹理,并且在没有强度信息的情况下似乎不逼真(见图1(f))。

图1所示。视频重建的挑战案例。(a)输入模糊图像。(b)相应的事件数据。颜色对(红色,蓝色)代表其极性(1,−1)在整个论文中。©事实。(d)我们的重建结果。(e)基于图像的视频构建结果[9]。(f)基于事件的视频生成结果[15]。(g)传统的BHA结果[18]。(h)基于深度学习的LEMD结果[8]。该方法基于基于物理事件的视频重建模型,通过端到端网络恢复高质量图像。
因此,利用强度传感器和基于事件的传感器的优点进行高速视频生成是可取的。很少有人注意[6,22,23]考虑这两种信息来源。然而,由于没有考虑模糊,生成的视频有时会很模糊。 为了解决这一问题,Pan等[18]对模糊图像、事件和潜在帧之间的关系进行了物理建模,并提出了基于事件的双积分(Event-based Double Integral, EDI)模型。因此,在给定模糊帧和相应的事件流的情况下,可以得到清晰的潜在图像。 在去模糊之后,通过估计事件间的残差,从上述初始去模糊的视频帧中插值出其他潜在视频帧。该方法自然地将强度图像和事件数据连接起来,在高帧率视频生成方面显示出良好的效果。然而,由于事件相机的触发阈值随硬件和场景条件在空间和时间上发生变化[6,4,20],将其视为[18]中的恒定值是不太有效的,这会引入很强的累积噪声(见图1(g))。Jiang等人[8]提出利用深度卷积神经网络(cnn)的大容量对[18]中的估计帧进行细化,恢复更精细的细节。然而,由于去模糊和细化是分开考虑的,他们的方法没有充分利用cnn的模型能力,这使得其在高速视频生成中效果不佳(见图1(h))。此外,上述算法[18,8]在不利用前一帧的附加信息的情况下使一帧模糊帧存活。
在本文中,我们提出了一种有效的基于深度cnn和基于事件的视频重建物理模型的事件驱动视频去模糊和插值算法,以生成清晰的高帧率视频。在[18]估计锐利和模糊图像之间的残差用于去模糊以及锐利帧之间的残差用于插值的启发下,我们提出使用深度CNN来有效地预测它们。此外,由于触发阈值在空间上是不同的,所以不适合采用[18]中统一的触发阈值。因此,我们建议使用动态滤波层[7,17,14]来处理这种空间变化的阈值。此外,该网络在预测残差时还可以帮助去除事件中的噪声。为了更好地利用帧间的附加信息,我们进一步利用之前恢复的帧与之前模糊的帧以及事件流来估计当前帧,这可以增强时间一致性。我们的方法结合了基于事件的视频重建的物理特性,并且可以以端到端方式进行训练。
本文的主要贡献总结如下:
-
我们提出了一个端到端可训练的神经网络,从混合强度和基于事件的传感器生成高速视频。该算法基于基于物理事件的视频重构模型,具有紧凑的网络结构。
-
我们建议使用动态滤波器来处理由空间变量阈值触发的事件。
-
我们在合成视频和真实视频上对我们的网络进行了定量和定性评估,并表明它与最先进的高速视频生成算法相比表现良好。
2 Motivation
给定一个低帧率模糊视频{ B i B_i Bi} i ∈ N _{i∈\mathbb{N}} i∈N,以及在曝光过程中捕获的相应事件流{ E i E_i Ei} i ∈ N _{i∈\mathbb{N}} i∈N,如图2所示,我们的目标是重建一个比原始视频帧率高2n倍的清晰视频。令{ S i , j S_{i,j} Si,j} i , j ∈ N _{i,j∈\mathbb{N}} i,j∈N为恢复后的视频,其中 j ∈ [ − N , N ] j∈[−N, N] j∈[−N,N]为第 i i i帧模糊曝光后的第 j j j帧清晰画面。**提出的基于事件的视频去模糊和插值算法的动机是两个观察。**首先,隐锐图像之间以及锐与模糊图像之间的强度残差都是事件的积分。因此,我们可以使用该网络从噪声事件中估计准确的积分,然后重建高帧率的清晰视频。其次,尽管强度残差可以从事件的积分中估计出来,但触发阈值 c m c_m cm在空间和时间上是可变的。我们建议集成动态过滤器[7]来处理这种空间变化问题。本节将详细讨论上述动机。
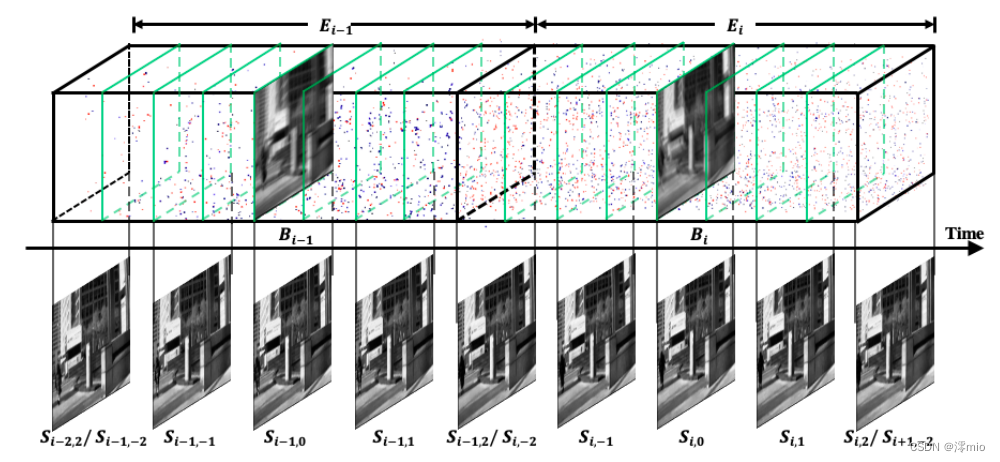
图2所示。基于该方法重构的样本帧。给定曝光时间内的低帧率模糊视频{Bi}和相应的事件流{Ei},该方法以比原始视频高2n时间的帧率恢复出清晰的视频{
S
i
,
j
S_{i,j}
Si,j}
j
∈
[
−
N
,
N
]
_{j∈[−N,N]}
j∈[−N,N]。在本例中N = 2
2.1 Physical Model of Event-based Video Reconstruction
为了更好地激励我们的算法,我们首先回顾了基于事件的视频重建的物理模型。
一旦log强度变化超过预设阈值
c
m
c_m
cm,就会触发事件
e
m
e_m
em(When
t
m
∈
Ω
i
,
−
N
−
>
i
,
N
t_m\in\Omega_{i,-N->i,N}
tm∈Ωi,−N−>i,N,
e
m
e_m
em is in the event stream
E
i
E_i
Ei),表示为
e
m
=
(
x
m
,
y
m
,
t
m
,
p
m
)
(
1
)
e_m=(x_m,y_m,t_m,p_m) \qquad(1)
em=(xm,ym,tm,pm)(1)
其中,
x
m
,
y
m
,
t
m
x_m,y_m,t_m
xm,ym,tm分别表示
m
t
h
m^{th}
mth事件的时空坐标,
p
m
p_m
pm∈{−1,1}表示变化的方向(减小或增大)。无论如何量化,在一个时间间隔内捕获的事件的总和表示强度的比例变化。因此,给定事件
e
m
e_m
em的区间
Ω
i
,
j
→
i
′
,
j
′
=
[
i
T
+
j
2
N
T
,
i
′
T
+
j
′
2
N
T
]
Ω_{i,j→i',j'} = [iT + \frac{j}{2N}T, i'T +\frac{j'}{2N}T]
Ωi,j→i′,j′=[iT+2NjT,i′T+2Nj′T]和潜在锐帧
S
i
,
j
S_{i,j}
Si,j,我们可以在像素(x, y)处重建潜在锐帧
S
i
′
,
j
′
S_{i',j'}
Si′,j′,使用:
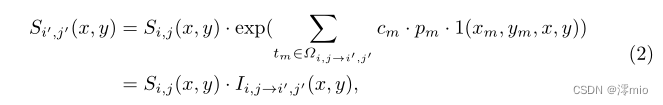
式中,
T
T
T表示模糊帧的曝光时间,
⋅
·
⋅为Hadamard积,当
x
m
=
x
&
y
m
=
y
x_m = x \& y_m = y
xm=x&ym=y时,指示函数1(·)= 1,否则为0。
I
i
,
j
→
i
′
,
j
′
I_{i,j→i',j'}
Ii,j→i′,j′表示
S
i
,
j
S_{i,j}
Si,j与
S
i
′
,
j
′
S_{i',j'}
Si′,j′之间的强度残差
对于模糊图像
B
i
B_i
Bi,可以将其建模为离散潜在锐帧
S
i
,
j
S_{i,j}
Si,j的平均值,公式为:
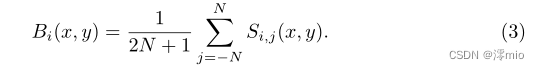
那么,根据式2和式3,我们可以将
B
i
B_i
Bi表示为:
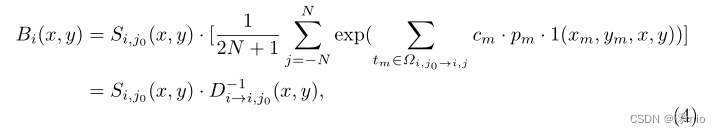
其中
S
i
,
j
0
S_{i,j_0}
Si,j0是与模糊帧
B
i
B_i
Bi相关的关键潜在锐帧,
D
i
→
i
,
j
0
D_{i→i,j_0}
Di→i,j0是
B
i
B_i
Bi和
S
i
,
j
0
S_{i,j_0}
Si,j0之间的强度残差,它实际上是[18]中基于事件的二重积分(Event-based Double Integral, EDI)的离散版本。
因此,在物理上可以首先基于Eq. 4去模糊潜在关键帧 S i , j 0 S_{i,j_0} Si,j0,然后使用Eq. 2插值所有其他视频帧 S i , j S_{i,j} Si,j。同样,Eq. 2可用于从先前估计的潜在帧 S i − 1 , j S_{i−1,j} Si−1,j生成 S i , j S_{i,j} Si,j。在[18]中,他们直接根据Eq. 2和Eq. 4从事件 e e e中估计残差 I I I和 D D D,但由于事件中包含严重的噪声,估计不准确。在本文中,我们提出利用深度神经网络强大的容量和灵活性来预测残差,以弥补事件数据的不完全性。

图3所示。空间变化事件触发阈值的演示。给定两个潜在的尖锐帧(a)(b)和事件相机捕获的事件©的间隔,我们使用Eq. 2估计该间隔中每个像素的平均阈值。事件发生的有效阈值在整个图像平面上是不同的。
2.2 Spatially Variant Triggering Threshold
在以前的工作中,例如[18],他们估计了一个固定的触发阈值,并将其应用于整个帧序列。然而,根据[6,4,20],这个阈值 c m c_m cm在空间和时间上都是不同的。从图3(d)中可以看出,Eq. 2给出的锐利帧和各自事件的估计阈值是不一致的。因此,使用由空间不变的卷积层组成的网络来估计残差 I I I和 D D D是不合适的。我们建议集成动态滤波器[7],在每个位置估计残差 I I I和 D D D,来处理这个空间变化问题。
3 Proposed Methods
3.1 Network Architecture
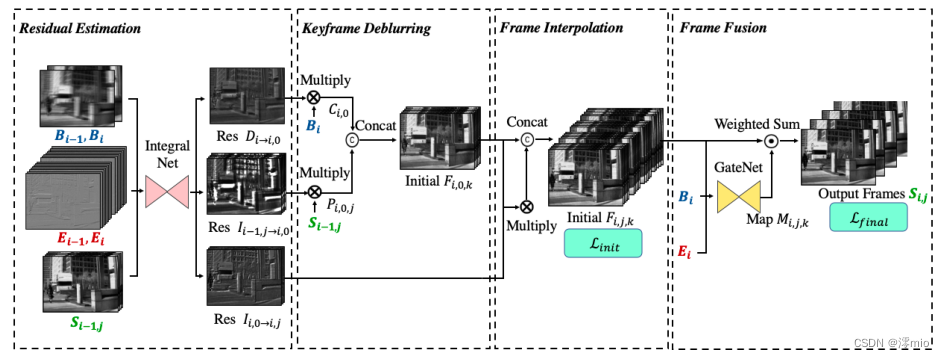
图4所示。框架的概述。对于2N时间帧率的视频重建,将之前和当前的模糊帧
B
i
−
1
,
B
i
B_{i−1},B_i
Bi−1,Bi及其对应的事件流
E
i
−
1
,
E
i
E_{i−1},E_i
Ei−1,Ei和2N先前恢复的清晰帧
S
i
−
1
,
j
S_{i−1,j}
Si−1,j输入到
I
n
t
e
g
r
a
l
N
e
t
IntegralNet
IntegralNet中,预测残差
D
i
→
i
,
0
D_{i→i,0}
Di→i,0,
I
i
−
1
,
j
→
i
,
0
I_{i−1,j→i,0}
Ii−1,j→i,0和
I
i
,
0
→
i
,
j
I_{i,0→i,j}
Ii,0→i,j。给定学习到的残差,通过Eq. 4从模糊帧估计初始去模糊关键帧
C
i
,
0
C_{i,0}
Ci,0。此外,对于先前恢复的2N个锐帧,通过Eq. 2推断出其他初始尖锐关键帧
P
i
,
0
,
j
P_{i,0,j}
Pi,0,j,其中
j
∈
(
−
N
,
N
]
j∈(−N, N]
j∈(−N,N]。因此,通过连接
C
i
,
0
C_{i,0}
Ci,0和
P
i
,
0
,
j
P_{i,0,j}
Pi,0,j ,我们得到2N +1个初始关键帧,记为
F
i
,
0
,
k
F_{i,0,k}
Fi,0,k。然后,通过Eq. 2从
F
i
,
0
,
k
F_{i,0,k}
Fi,0,k插值出其他初始潜在锐帧
F
i
,
j
,
k
F_{i,j,k}
Fi,j,k,其中
j
∈
(
−
N
,
0
)
∪
(
0
,
N
]
j∈(−N, 0)∪(0,N]
j∈(−N,0)∪(0,N]且
k
∈
[
0
,
2
n
]
k∈[0,2n]
k∈[0,2n]。最后,利用
G
a
t
e
N
e
t
GateNet
GateNet预测权重
M
i
、
j
、
k
M_{i、j、k}
Mi、j、k,自适应选择初始重构帧,对初始结果进行权值求和,得到最终结果。详情请参阅原稿。
所提出的视频去模糊和插值算法的总体框架如图4所示。它由四个部分组成:
– Residual Estimation: 目的是估计残差,包括关键帧去模糊的 D i → i , 0 D_{i→i,0} Di→i,0和 I i − 1 , j → i , 0 I_{i−1,j→i,0} Ii−1,j→i,0和视频帧插值的 I i , 0 → i , j I_{i,0→i,j} Ii,0→i,j。
– Keyframe Deblurring: 利用学习到的残差
D
i
→
i
,
0
D_{i→i,0}
Di→i,0和模糊帧
B
i
B_i
Bi,通过Eq. 4估计关键帧
C
i
,
0
C_{i,0}
Ci,0。然后从
I
i
−
1
,
j
→
i
,
0
I_{i−1,j→i,0}
Ii−1,j→i,0和之前恢复的2N个锐帧生成2N个关键帧
P
i
,
0
,
j
P_{i,0,j}
Pi,0,j和2N个先前通过Eq. 2恢复的尖锐帧
S
i
−
1
,
j
S_{i−1,j}
Si−1,j,其中
j
∈
(
−
N
,
N
)
j∈(−N, N)
j∈(−N,N)。总共有2N + 1个初始估计关键帧
F
i
,
0
,
k
F_{i,0,k}
Fi,0,k,它们是
C
i
,
0
C_{i,0}
Ci,0和
P
i
,
0
,
j
P_{i,0,j}
Pi,0,j的串联。
– Frame Interpolation: 根据Eq. 2从每个初始去模糊关键帧
F
i
,
0
,
k
F_{i,0,k}
Fi,0,k和
I
i
,
0
→
i
,
j
I_{i,0→i,j}
Ii,0→i,j中插值潜在的尖锐帧
F
i
,
j
,
k
F_{i,j,k}
Fi,j,k,其中
j
∈
(
−
N
,
0
)
∪
(
0
,
N
)
j∈(−N, 0)∪(0,N)
j∈(−N,0)∪(0,N)。
– Frame Fusion:它以自适应选择的方式融合
(
i
,
j
)
(i, j)
(i,j)处的2N +1个初始锐帧,以更精细的细节还原最终结果
S
i
,
j
S_{i,j}
Si,j。
Residual Estimation
我们估计残差
D
i
→
i
,
0
D_{i→i,0}
Di→i,0,
I
i
−
1
,
j
→
i
,
0
I_{i−1,j→i,0}
Ii−1,j→i,0和
I
i
,
0
→
i
,
j
I_{i,0→i,j}
Ii,0→i,j在Eq. 4和Eq. 2中通过
I
n
t
e
g
r
a
l
n
e
t
Integralnet
Integralnet。如上所述,我们需要处理触发对比度阈值的空间和时间变化。然而,卷积在整个特征平面上是平移不变的,这对解决这个问题的效果较差。我们采用动态滤波[7],其逐像素滤波器由所提出的网络中的动态滤波器生成模块估计。此外,该网络还可以在预测残差时帮助去除事件中的噪声。
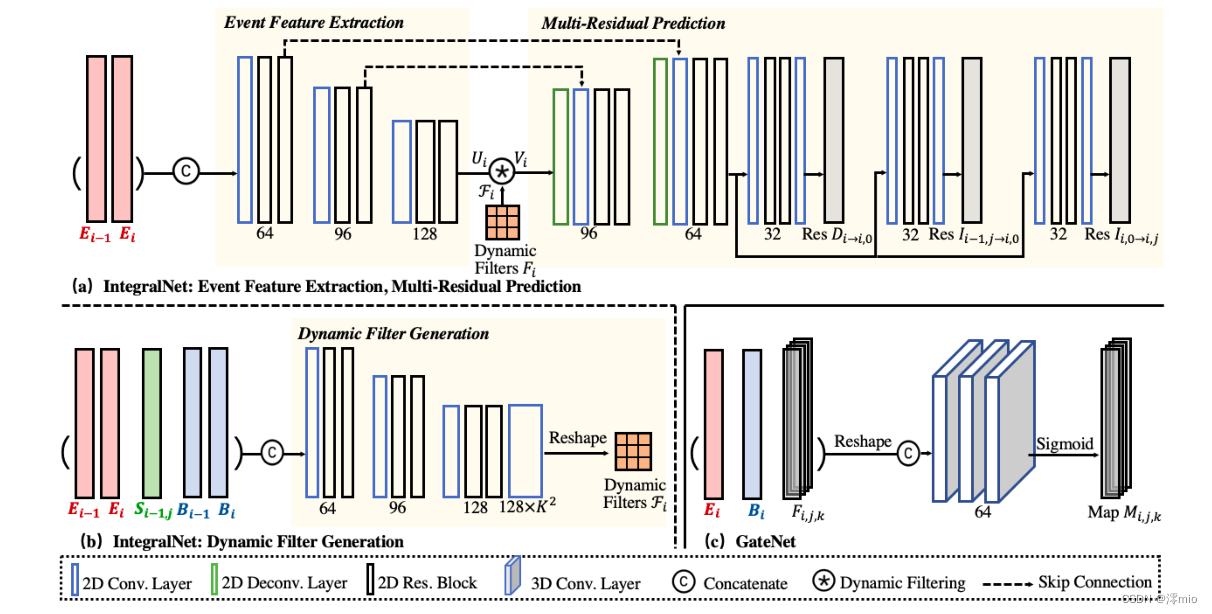
图5所示。子网结构。IntegraltNet包含事件特征提取、动态滤波器生成和多残差预测。GateNet包含三个3D卷积层。详细配置请参见补充资料。
如图5(a)(b)所示, I n t e g r a l N e t IntegralNet IntegralNet由三个模块组成:事件特征提取、动态滤波器生成和多残差预测。
如2.1节所述,残差 D D D和 I I I是事件的积分。因此,事件 E i − 1 E_{i−1} Ei−1和 E i E_i Ei是提取特征 U i U_i Ui的事件特征提取模块的唯一输入。为了将异步事件输入神经网络,我们将每个事件流 E i E_i Ei分成2N个等时间间隔的箱子。为了保存更多的时间信息,我们进一步将每个bin划分为M个大小相等的块,并将其堆叠为M通道输入图像,如[25]所示(例如图2中的N = 2, M = 2)。叠加的事件数据 E i E_i Ei经过三个卷积层,然后是两个残差块。提取的事件特征Ui通过动态过滤器进行转换。
我们为特征映射中的每个位置生成不同的过滤器,并使用过滤器执行空间变化卷积。具体来说,对于提取的特征映射
U
i
∈
R
H
U
×
W
U
×
C
U
U_i∈\mathbb{R}^{H_U ×W_U ×C_U}
Ui∈RHU×WU×CU中的每个位置
(
h
,
w
,
c
)
(h,w,c)
(h,w,c),对以
U
i
(
h
,
w
,
c
)
U_i(h, w,c)
Ui(h,w,c)为中心的区域应用一个特定的局部滤波器
F
i
(
h
,
w
,
c
)
∈
R
K
×
K
×
1
F^{(h,w,c)}_i∈\mathbb{R}^{K×K×1}
Fi(h,w,c)∈RK×K×1作为
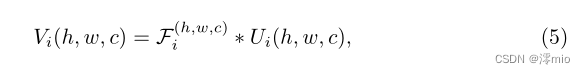
其中
∗
*
∗表示卷积运算。动态滤波器生成模块根据当前和之前的模糊帧
B
i
、
B
i
−
1
B_i、B_{i−1}
Bi、Bi−1、相应的事件流
E
i
、
E
i
−
1
E_i、E_{i−1}
Ei、Ei−1以及之前恢复的清晰帧
S
i
−
1
、
j
S_{i−1、j}
Si−1、j动态生成滤波器.
多残差预测模块对变换后的事件特征 V i V_i Vi进行 D i → i , 0 D_{i→i,0} Di→i,0, I i − 1 , j → i , 0 I_{i−1,j→i,0} Ii−1,j→i,0和 I i , 0 → i , j I_{i,0→i,j} Ii,0→i,j的估计。如图5(a)所示,首先将特征上采样回全分辨率,然后分别生成残差。在IntegralNet中也采用了跳过连接。
Keyframe Deblurring
利用预测的残差,我们可以从当前模糊图像和先前恢复的图像中获得关键帧。具体来说,给定预测的
D
i
→
i
,
0
D_{i→i,0}
Di→i,0,它表示模糊图像与关键帧之间的差值,我们可以根据式4得到关键帧
C
i
,
0
C_{i,0}
Ci,0,使用:
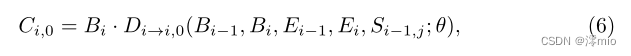
其中θ为
I
n
t
e
g
r
a
l
N
e
t
IntegralNet
IntegralNet的参数。
此外,利用2N个学习残差
I
i
−
1
,
j
→
i
,
0
I_{i−1,j→i,0}
Ii−1,j→i,0表示之前恢复的2N个锐帧与当前锐关键帧之间的差异,我们根据Eq. 2进一步估计2N个关键帧。令
P
i
,
0
,
j
P_{i,0,j}
Pi,0,j表示由前第
j
j
j个锐帧
S
i
−
1
,
j
S_{i−1,j}
Si−1,j推断出的第
j
j
j个估计关键帧,其中
j
∈
(
−
N
,
N
]
j∈(−N, N]
j∈(−N,N],表示为:
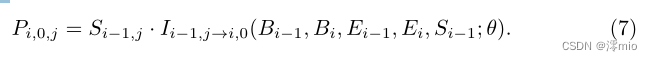
总之,我们从当前模糊的帧中获得一个关键帧
C
i
,
0
C_{i,0}
Ci,0,从之前恢复的帧中获得2N个
P
i
,
0
,
j
P_{i,0,j}
Pi,0,j。为简化起见,将估计的关键帧连接起来,表示为
F
i
,
0
,
k
F_{i,0,k}
Fi,0,k,其中
k
∈
[
0
,
2
n
]
k∈[0,2n]
k∈[0,2n]表示关键帧的索引。
Frame Interpolation
给定潜在关键帧与插值帧之间的2N + 1个初始去模糊关键帧
F
i
,
0
,
k
F_{i,0,k}
Fi,0,k和2N−1个学习残差
I
i
,
0
→
i
,
j
;
j
!
=
0
I_{i,0→i,j;j!=0}
Ii,0→i,j;j!=0,则插值帧可根据式2估计:
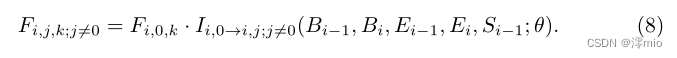
Frame Fusion
帧插值后,每帧有2N + 1幅潜在图像。为了利用所有这些潜在图像
F
i
,
j
,
k
F_{i,j,k}
Fi,j,k的优点和消除缺陷,我们进行了帧融合模块,通过自适应选择方案对它们进行融合。我们将它们输入到GateNet中,生成一个软门映射
M
i
,
j
,
k
M_{i,j,k}
Mi,j,k以及模糊帧
B
i
B_i
Bi和相应的事件流
E
i
E_i
Ei。我们首先将输入转换成四维。初始结果
F
i
,
j
,
k
F_{i,j,k}
Fi,j,k被时间戳j分成2N个块,生成一个大小为(2N + 1)×2N ×H ×W的特征,其中H和W表示视频帧的分辨率。对于事件数据
E
i
E_i
Ei,相邻两帧之间的事件以M × 2N × H × W的形式叠加在一起。模糊输入沿着新的维度扩展为2N倍,为1 × 2N × H × W。之后,将这些变换后的特征馈送到三个三维卷积层中,生成门图
M
i
,
j
,
k
M_{i,j,k}
Mi,j,k,如图5©所示。因此,最终重构帧可由下式估计:
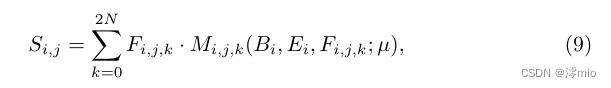
其中µ表示GateNet的参数。
3.2 Loss Function
对于中间估计和最终估计,我们考虑两个损失函数来测量重建帧与真值
G
i
,
j
G_{i,j}
Gi,j之间的差异。具体来说,对于初始恢复帧
F
i
,
j
,
k
F_{i,j,k}
Fi,j,k,我们使用MSE loss约束IntegralNet:
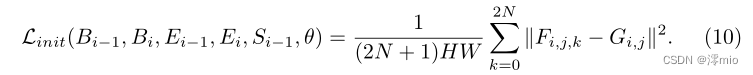
另一个定义在最终结果
S
i
,
j
S_{i,j}
Si,j和真值
G
i
,
j
G_{i,j}
Gi,j之间,以约束IntegralNet和GateNet:
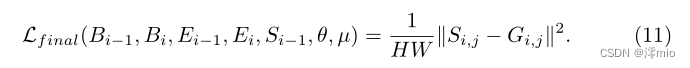
总体损失函数为
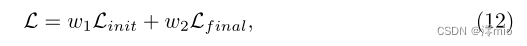
其中w1, w2在我们的实验中分别设为0.01,1。
4 Experiment
4.1 Implementation Details
Training Dataset.
我们在两个合成数据集上训练提出的方法:GoPro[16]和Blur-DVS的合成子集[8]。在训练过程中需要低帧率模糊输入、高帧率清晰视频和事件流。GoPro[16]是一个广泛使用的视频去模糊数据集,它提供了groundtruth sharp视频,我们使用它们来生成模糊帧。我们首先通过高质量的帧插值算法[17]将视频帧速率从240帧/秒提高到960帧/秒来模拟事件数据,然后将事件模拟器ESIM[20]应用于视频。为了增加噪声多样性,我们为来自高斯分布N(0.18, 0.03)的每个像素设置不同的对比度阈值,类似于[21]。我们还使用Blur-DVS的合成子集[8]进行训练,该子集在相对静态的场景中使用缓慢的相机运动来捕获,从而提供真实的锐利视频和事件流。获得模糊图像的方法与GoPro相同。我们按照建议将训练数据集和测试数据集分开。
Experimental Settings.
我们的网络使用Pytorch[19]实现,并在GeForce GTX 1080 GPU上以Eq. 12监督的端到端方式进行训练。对于这两个数据集,我们使用4对训练对的批处理大小和Adam[11]优化器,动量和动量2分别为0.9和0.999。网络训练60个epoch,前10个epoch的学习率初始化为0.0001,然后线性衰减为零。我们将参数M和N在GoPro数据集上设置为4,5,在合成的Blur-DVS上设置为3,3。在初始化方面,我们将图4中的
B
i
−
1
B_{i−1}
Bi−1和
S
i
−
1
,
j
S_{i−1,j}
Si−1,j替换为B0,恢复视频序列的第一帧模糊帧
B
0
B_0
B0。并且,我们反复输入
E
0
E_0
E0来代替
E
i
−
1
E_{i−1}
Ei−1。
4.2 Experimental Results

表1。GoPro[16]数据集上的视频去模糊和重建性能,包括不同网络的平均PSNR、SSIM和参数数(×106)。

图6所示。视频去模糊(上图)和高帧率视频重建(下图)在GoPro[16]数据集上的视觉对比。该方法产生的帧更清晰,噪声和伪影更少。放大看得更清楚。
我们定量和定性地评估我们的视频去模糊网络(即。以原始帧率恢复视频)以及GoPro和Blur-DVS上的同步去模糊和插值网络。
我们与最先进的算法进行了广泛的比较,包括基于图像的视频去模糊方法[28]和高速视频生成方法[9],基于事件的视频生成方法[15,21],基于混合强度和基于事件的传感器的传统视频重建方法[22,18]以及基于深度学习的混合传感器方法[8]。为了证明所提出的框架的有效性,我们还比较了单传感器算法的增强版本。对于基于图像的STFAN[28],我们将额外的事件数据输入到时空滤波自适应网络中,以辅助帧对齐和去模糊(记为“STFAN*”)。TNTT[9]分别为关键帧去模糊网络和帧插值网络(记为“TNTT*”)输入事件和模糊图像。我们还将事件与强度帧一起馈送到基于事件的E2V[21]中,用于其每个循环重建步骤(表示为“E2V*”)。

我们在表1和表2的两个合成数据集上评估视频去模糊任务的PSNR和SSIM。与最先进的方法相比,所提出的网络表现良好。图6和图7显示了测试集中的一些示例。基于图像的方法[28]纯粹依赖于强度图像,因此对于严重模糊的视频效果较差。由于事件数据编码了密集的时间信息,这使得STFAN能够跨帧捕获运动信息,使其在视频去模糊方面更加有效。单纯依赖事件数据的E2V[21]复原了对比度错误的图像。然而,它的增强版本E2V在强度框架的帮助下保持正确的对比度。这些显著的改进表明了每个传感器的固有优势以及利用这两种优势进行视频去模糊的有效性。现有的基于强度和事件的算法中,CIE[22]和BHA[18]采用了简化的物理模型,没有考虑模糊和非均匀阈值,导致结果模糊,并引入了累积的噪声。基于cnn的方法[8]将去模糊和细化分开进行,这使得该方法对去模糊很敏感,导致性能受限。相反,提出的方法依赖于基于物理事件的视频重构模型,通过端到端架构。恢复后的视频帧呈现出更精细的细节和更少的噪音。

图8所示。与最先进的真实模糊视频的视觉比较。该方法的恢复结果具有噪声少、细节多的特点。我们的补充资料提供了更多的结果。放大看得更清楚。
我们还在表1、表2、图6和图7中报告了同步视频去模糊和插值的结果。传统的BHA方法[18]在插值过程中容易产生噪声,特别是在物体边缘。此外,该方法的阈值选择方案鲁棒性较差,在估计错误阈值时会引入无法寻址的模糊。基于深度学习的LEMD和TNTT*忽略了利用两个相邻帧之间的物理约束,从而插值带有不良伪影的模糊帧,特别是在遮挡时。从图6(l)和图7(n)可以看出,本文提出的方法可以恢复清晰且无伪影的帧。
为了验证所提方法的泛化能力,我们在Blur-DVS的真实子集中将所提网络与其他算法在真实模糊视频上进行定性比较[8]。如图8所示,我们的方法比最先进的方法还原了更多视觉上令人愉悦的帧。
5 Ablation Study
我们已经证明,所提出的算法优于最先进的方法。在本节中,我们进一步分析了每个组件在视频去模糊和插值中的有效性。
5.1 Effectiveness of Physical-Based Framework
该算法是基于事件视频重构的物理模型设计的。我们预测残差I和D,并根据Eq. 2和Eq. 4对它们进行乘法运算。为了证明基于物理的框架的有效性,我们比较了将残差和强度图像相加的方法(表示为“加法”),这已经在纯基于图像的算法中使用[28,9,27]。表3中的结果表明,使用乘法可以获得比“加法”更高的性能。如图9©所示,“加法”预测一个模糊的加法残差,从而产生一个平滑的结果,但有更多的伪影(图9(h))。然而,由于该方法基于物理模型,可以很容易地从事件数据中计算乘法残差(图9(b)),因此对于严重模糊的帧具有鲁棒性,并且恢复的图像细节更多,伪影更少(图9(g))。

5.2 Effectiveness of Dynamic Filtering
为了处理由空间变化阈值触发的事件,我们提出在残差估计时集成动态滤波器。为了验证上述讨论,我们删除了动态滤波器生成模块,并将其输入(Bi−1,Bi, Ei−1,Ei, Si−1)直接输入到事件特征提取中,以进行公平比较(表示为“w/o DF”)。表3显示,“w/o DF”的效果较差。由于缺乏对空间变化触发阈值的补偿,与我们的(图9(b))相比,它提供了过于平滑的残差(图9(d))。因此,它无法恢复最终结果中丢失的细节(图9(i)),这表明使用动态滤波有助于最小化非均匀阈值的影响。此外,在所述补充材料中说明了生成的过滤器,以便进行视觉解释。
5.3 Effectiveness of Previous Information
我们注意到,现有的基于事件的视频去模糊和插值算法[18,8]在不考虑相邻帧之间存在的附加信息的情况下,使一个模糊帧存活。为了验证利用先前信息的有效性,我们比较了一种方法,该方法仅从当前模糊输入中估计关键帧Ci,0,而不从先前恢复的帧中估计关键帧Pi,0,j(表示为“w/o Pre”)。最终结果如表3和图9(e)所示,可以看出,加入之前的信息对于视频去模糊和重建更为有效。
5.4 Effectiveness of Frame Fusion
为了以自适应选择的方式对2N + 1个初始恢复结果Fi,j,k进行积分,提出的帧融合步骤利用模糊帧、事件数据和初始结果的信息生成门图,然后通过加权求和得到最终结果。为了证明该设计的有效性,我们比较了一种方法,该方法去除门图的估计,但将初始结果馈送到三个3D卷积层中以直接估计最终结果(表示为“w/o ASF”)。最终结果如表3和图9(j)所示,表明所提出的帧融合模块能够以自适应选择方案整合初始结果,并保留更多细节,对视频去模糊和插值更有效。
6 Concluding Remarks
在本文中,我们提出学习事件驱动的视频帧去模糊和插值来解决高帧率的视频生成。整个框架依赖于基于事件的视频重建的物理模型,该模型估计潜在锐帧之间以及锐帧和模糊帧之间的残差,并将模型集成到一个紧凑的体系结构中。利用这种设计,该方法可以生成物理正确的结果,并能处理严重模糊的视频。此外,我们还表明,在预测残差时使用动态滤波器可以处理由空间变化阈值触发的事件数据。通过端到端训练所提出的网络,所提出的算法能够重建高质量和高帧率的视频。在合成数据集和真实图像上的实验表明,与现有的基于图像和事件的方法相比,该方法具有更好的性能。
我们注意到,所提出的方法的一个限制是,如果我们的目标是进一步提高帧率,网络需要重新训练。然而,我们可以通过在恢复的锐利帧对之间递归地应用一个额外的插值网络来解决它。进一步的研究将致力于任意帧率的视频重建。
References
- Bao, W., Lai, W., Zhang, X., Gao, Z., Yang, M.: Memc-net: Motion estimation
and motion compensation driven neural network for video interpolation and en-
hancement. TPAMI (2019) 1 - Bardow, P., Davison, A.J., Leutenegger, S.: Simultaneous optical flow and intensity
estimation from an event camera. In: CVPR (2016) 1 - Barua, S., Yoshitaka, M., Ashok, V.: Direct face detection and video reconstruction
from event cameras. In: W ACV (2016) 1 - Brandli, C.: Event-Based Machine Vision. Ph.D. thesis, ETH Zurich (2015) 2, 5
- Brandli, C., Berner, R., Yang, M., Liu, S.C., Delbruck, T.: A 240× 180 130 db 3
µs latency global shutter spatiotemporal vision sensor (2014) 1 - Brandli, C., Muller, L., Delbruck, T.: Real-time, high-speed video decompression
using a frame-and event-based davis sensor. In: ISCAS (2014) 2, 5 - Jia, X., De Brabandere, B., Tuytelaars, T., Gool, L.V.: Dynamic filter networks.
In: NIPS (2016) 3, 4, 5, 6 - Jiang, Z., Zhang, Y., Zou, D., Ren, J., Lv, J., Liu, Y.: Learning event-based motion
deblurring. In: CVPR (2020) 2, 9, 10, 11, 12, 13 - Jin, M., Hu, Z., Favaro, P.: Learning to extract flawless slow motion from blurry
videos. In: CVPR (2019) 1, 2, 10, 11, 12 - Jin, M., Meishvili, G., Favaro, P.: Learning to extract a video sequence from a
single motion-blurred image. In: CVPR (2018) 1 - Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization (2014) 9
- Lichtsteiner, P., Christoph, P., Tobi, D.: A 128×128 120 db 15 µs latency asyn-
chronous temporal contrast vision sensor. (2008) 1 - Meyer, S., Djelouah, A., McWilliams, B., Sorkine-Hornung, A., Gross, M., Schroers,
C.: Phasenet for video frame interpolation. In: CVPR (2018) 1 - Mildenhall, B., Barron, J.T., Chen, J., Sharlet, D., Ng, R., Carroll, R.: Burst
denoising with kernel prediction networks. In: CVPR (2018) 3 - Munda, G., Reinbacher, C., Pock, T.: Real-time intensity-image reconstruction for
event cameras using manifold regularisation (2018) 1, 2, 10, 11 - Nah, S., Hyun Kim, T., Mu Lee, K.: Deep multi-scale convolutional neural network
for dynamic scene deblurring. In: CVPR (2017) 9, 10 - Niklaus, S., Mai, L., Liu, F.: Video frame interpolation via adaptive separable
convolution. In: ICCV (2017) 1, 3, 9 - Pan, L., Scheerlinck, C., Yu, X., Hartley, R., Liu, M., Dai, Y.: Bringing a blurry
frame alive at high frame-rate with an event camera. In: CVPR (2019) 2, 3, 5, 10,
11, 12, 13 - Paszke, A., Gross, S., Chintala, S., Chanan, G., Yang, E., DeVito, Z., Lin, Z.,
Desmaison, A., Antiga, L., Lerer, A.: Automatic differentiation in pytorch (2017)
9 - Rebecq, H., Gehrig, D., Scaramuzza, D.: Esim: an open event camera simulator.
In: Conference on Robot Learning (2018) 2, 5, 9 - Rebecq, H., Ranftl, R., Koltun, V., Scaramuzza, D.: Events-to-video: Bringing
modern computer vision to event cameras. In: CVPR. pp. 3857–3866 (2019) 1, 9,
10, 11 - Scheerlinck, C., Barnes, N., Mahony, R.: Continuous-time intensity estimation us-
ing event cameras. In: ACCV (2018) 2, 10, 11 - Shedligeri, P., Mitra, K.: Photorealistic image reconstruction from hybrid intensity
and event-based sensor (2019) 2 - Su, S., Delbracio, M., Wang, J., Sapiro, G., Heidrich, W., Wang, O.: Deep video
deblurring for hand-held cameras. In: CVPR (2017) 1 - Wang, L., Ho, Y.S., Yoon, K.J., et al.: Event-based high dynamic range image
and very high frame rate video generation using conditional generative adversarial
networks. In: CVPR (2019) 7 - Wang, X., Chan, K.C., Yu, K., Dong, C., Change Loy, C.: Edvr: Video restoration
with enhanced deformable convolutional networks. In: CVPR (2019) 1 - Zhang, H., Dai, Y., Li, H., Koniusz, P.: Deep stacked hierarchical multi-patch
network for image deblurring. In: CVPR (2019) 12 - Zhou, S., Zhang, J., Pan, J., Xie, H., Zuo, W., Ren, J.: Spatio-temporal filter
adaptive network for video deblurring. In: ICCV (2019) 1, 10, 11, 12