learn C++ NO.9——string(2)
引言:
现在是北京时间的2023年6月15日早上的10点14分。时间过得飞快,现在已经大一的最后一个星期了。明天也是大一最后一次课,线下的实训课。线下实训内容为c语言二级的内容,对我来说跟学校的课效率太低下了,我还是比较喜欢按自己的节奏来,一般我是直接带笔记本过去按自己计划学习。可能大多数的同学还是意识不到在人生的无限博弈中,持续学习的重要性吧,兴许今天大家都是在同一个教室里,但是,三年后也许大家的人生就会步入不一样的道路。当然,也恳请看到本篇文章的你,不要放弃学习这则有较大概率改变人生的选项!

operator[]重载
string因为支持了下标访问操作符重载,使得访问string实例化生成的对象可以像访问字符数组那样直接使用下标访问操作符进行指定编译量的访问以及修改。下面简单演示一下string的下标访问操作符的运算符重载。
#include<iostream>
using namespace std;
int main()
{
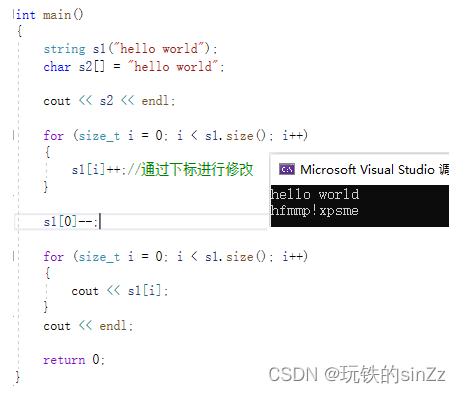
string s1("hello world");
char s2[] = "hello world";
cout << s2 << endl;
for (size_t i = 0; i < s1.size(); i++)
{
s1[i]++;//通过下标进行修改
}
s1[0]--;
for (size_t i = 0; i < s1.size(); i++)
{
cout << s1[i];//进行打印
}
cout << endl;
s1[1]++;//(s1.operator[](1))++
s2[1]++;//->(*(s2+1))++
return 0;
}
虽然两者在使用时是类似的,但这也并不意味着string类对象和char类型字符数组在底层实现上是一样的。string类对象使用下标访问操作符时,编译器会去调用它的运算符重载函数,而字符数组在使用下标访问操作符时,编译器根据数组首元素地址去进行解引用操作来访问。

迭代器的介绍
迭代器(iterator)是一种用于遍历数据集合的对象,可以按照一定顺序依次访问数据中的元素,而无需了解底层数据结构的实现方式。迭代器适用于各种不同类型的数据结构,包括数组、链表、树等等,并且支持可自定义的遍历顺序,例如前序、中序、后序等访问方式。迭代器的使用可以简化代码的编写,提高代码的可读性和可维护性。下面就简单介绍一下string类对象是如何用迭代器的。
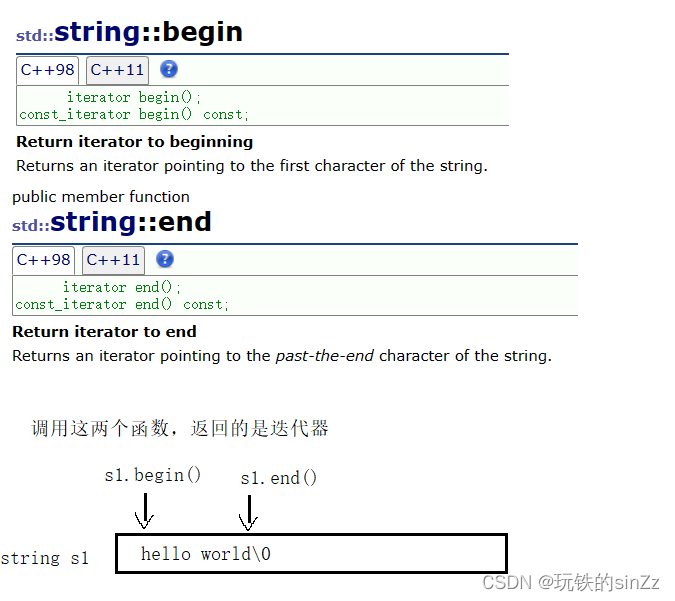
在正式介绍迭代器之前,先介绍两个与迭代器相关的函数,begin()和end()。老规矩我们还是先查看文档,begin()函数返回的是指向string类对象第一个元素的迭代器。end()函数返回的是指向string类对象’\0’前元素的迭代器。
#include<iostream>
using namespace std;
int main()
{
string s1("hello world");
//迭代器简单用法
string::iterator it = s1.begin();
while (it != s1.end())
{
(*it)++;//修改数据
it++;
}
it = s1.begin();
while (it != s1.end())
{
cout << *it;//打印数据
it++;
}
cout << endl;
return 0;
}
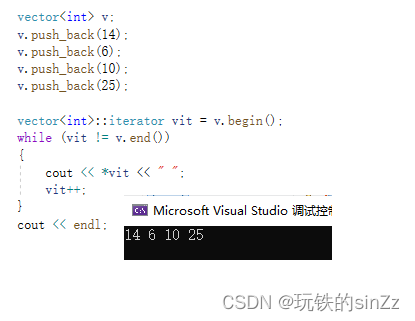
这里我们可以把迭代器简单理解成指针,当然这并不代表所有迭代器都是指针。这里在后面学习中我们会给大家再做介绍。迭代器给我们提供了另一种访问string类容器的方法。由于我们前面在学习c语言的时,最先接触到的访问字符数组的方法使用下标访问操作符进行访问,这也导致了我们会觉得iterator可能用起来并没有那么香。事实上并非如此,因为STL容器中是否都支持下标访问呢?答案并不是所有容器都支持下标访问,比如链表、树形结构、图等都不支持下标访问。但是,它们都支持迭代器进行遍历访问。这也是我们要学习迭代器的原因。下面我就照猫画虎,简单演示下interator遍历别的容器。
迭代器与范围for
在前面初始c++一文中,介绍了c++11的一个语法糖范围for。那么相信你可能就好奇了,范围for跟迭代器有什么关系呢?当然有关系了。因为范围for底层实现其实就是依靠的迭代器。
int main()
{
string s1("hello world");
string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it;//打印数据
it++;
}
cout << endl;
for (auto& e : s1)
{
cout << e;
}
cout << endl;
return 0;
}
迭代器跟算法配合
在类和对象的学习中,我们不难发现c++的类通常都是将数据给私有化,那么我们想要操作那些容器的数据就得使用迭代器加算法进行操作。下面我就简单一个常用的算法并进行实例演示。

#include<iostream>
#include<string>
#include<algorithm>
using namespace std;
int main()
{
string s1("hello world");
string::iterator it = s1.begin();
reverse(s1.begin(),s1.end());
for (auto& e : s1)
{
cout<<e;
}
cout << endl;
return 0;
}
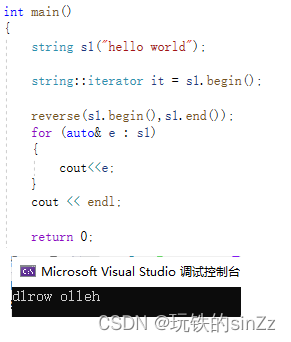
反向迭代器
反向迭代器与上面介绍的正向迭代的用法是一致的。但是区别在于参数以及迭代器的名称不同。
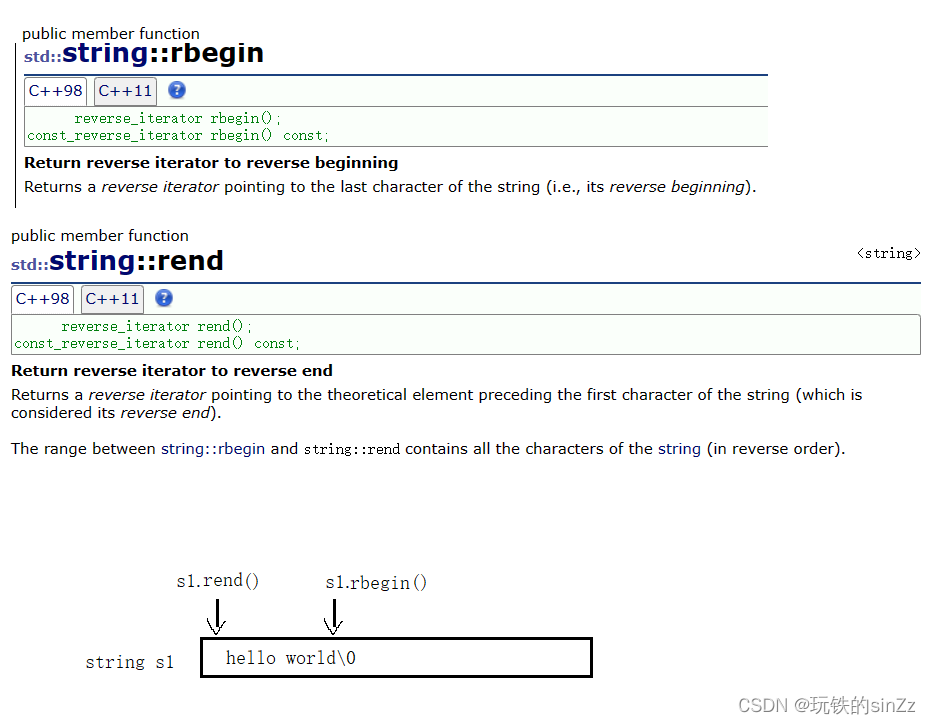
在介绍对应的两个相关的成员函数rbeign()和rend()。rbegin()返回一个指向最后一个string类对象的元素的反向迭代器。rend()返回一个指向string类对象第一个元素的前一个位置的反向迭代器。
当然正向迭代器以及反向迭代器都是支持被const进行修饰的。const修饰迭代器后,迭代器的权限会被缩小,从支持读写到只读。下面就简单上两个案例。
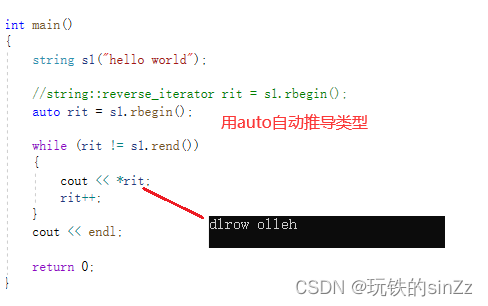
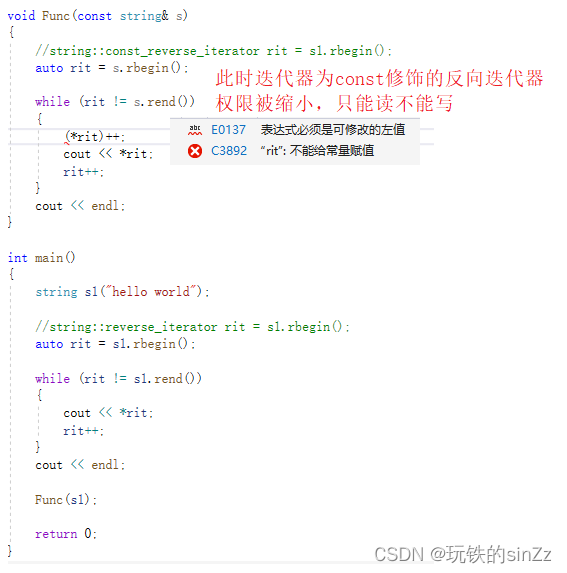
auto自动类型推导还是非常香的,可以让类型的推导交给编译器来进行,极大程度的提升了我们写代码的效率。
容量相关的成员函数

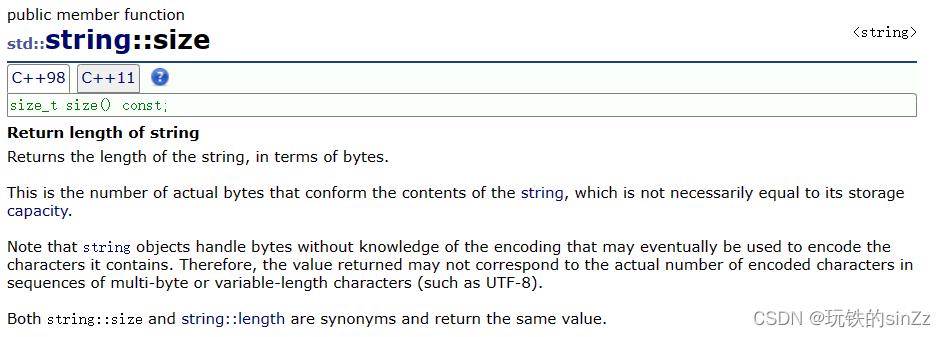
size()和length()两个函数的功能是一样的,就是返回string类对象的长度,即’\0’前的元素个数。那为什么会有两个功能一样的函数呢?这是因为string类在一开始实现的时候,只提供了length接口。但是,随着后面STL标准库横空出世后,string类为了和STL标准库中的容器的用法不做差异,于是又提供了一个size()接口。这也是历史的原因。string类是比STL标准库更早出现的,严格来说string并不属于STL,而是属于c++标准库。

max_size()接口其实不具备太大的意义,因为max_size()接口在不同的平台下的值其实是不同的,这也意味着它的跨平台性是较差的。虽然不同平台下的实现规范是一样的,但是实现的细节方面有所差异。
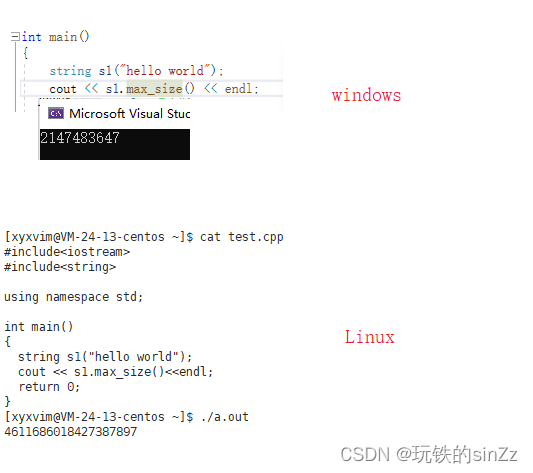
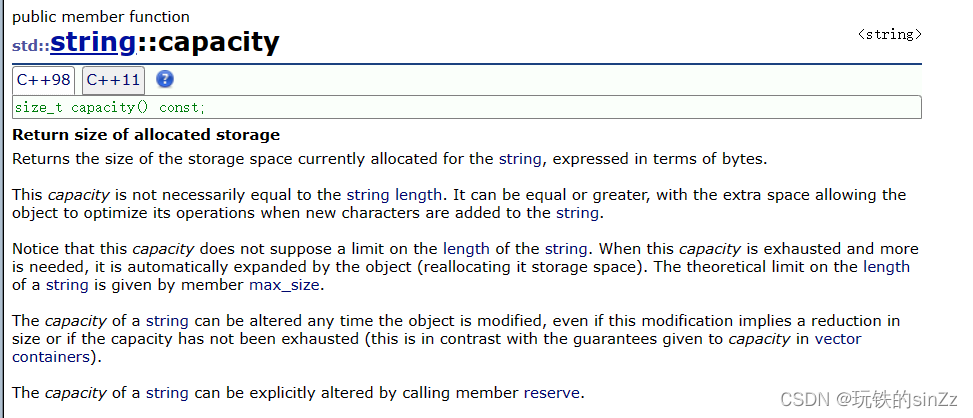
下面我们来看看capacity()接口。capacity接口因为不同的平台下的的实现扩容逻辑有所差异,所以在不同平台下的值也是不同的。
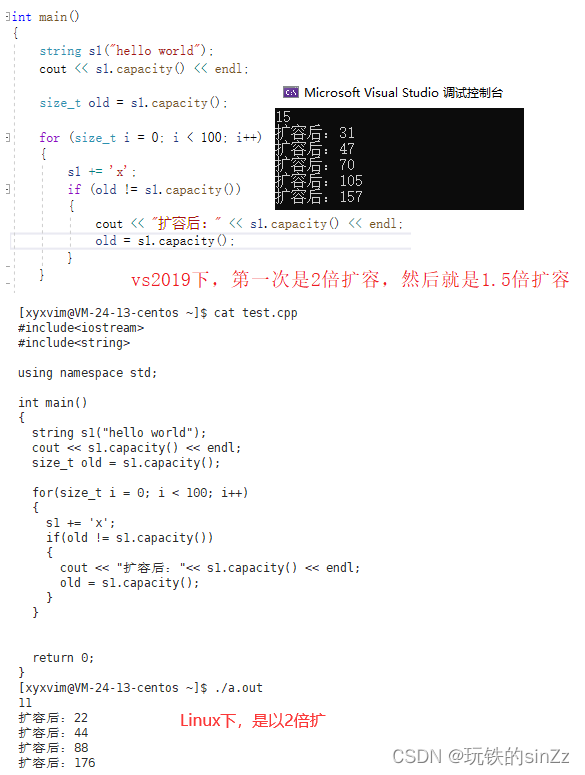
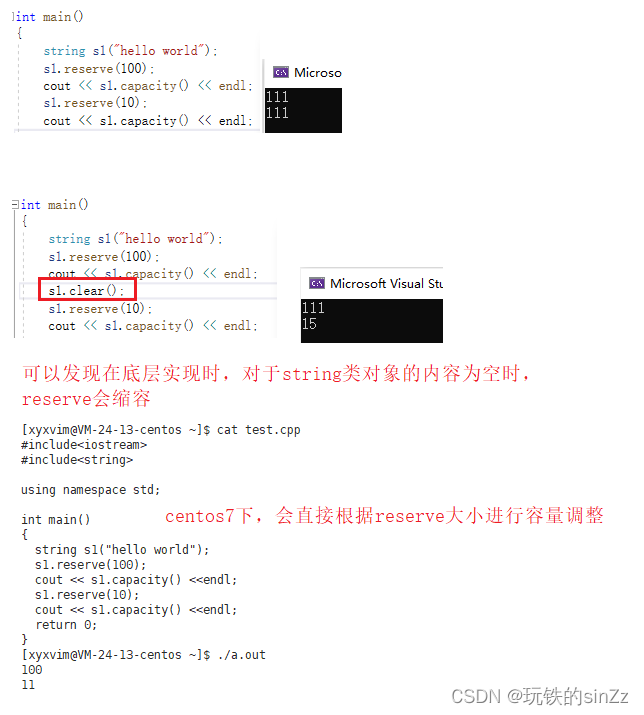
clear()接口,就是将string类对象的内容清空,也就是将数据插入的下标位置给置成0。当然,调用clear()接口并不影响string类的容量。


string的reserve()函数用于为字符串预留空间,以减少需要动态分配内存的次数,提高字符串操作的效率。调用reserve()函数后,字符串对象的容量将至少为指定的参数值,但不会改变字符串的长度(即字符串中字符的数量),也不会初始化新增的容量部分。如果在字符串中添加大量字符概会需要的容量大小,可以使用reserve()函数来避免频繁的重新分配内存造成的开销。注意,使用reserve()函数过度也可能导致浪费内存,因此应该根据实际情况选择合适的调用时机和参数值。

下面简单resize()接口,resize接口可以将string类对象的size(即元素有效个数)调整到n。也支持指定字符来初始化调整的空间。当你缩小size时,会默认给默认值赋予string类对象,这个默认的字符值为’\0’。下面简单演示一下。

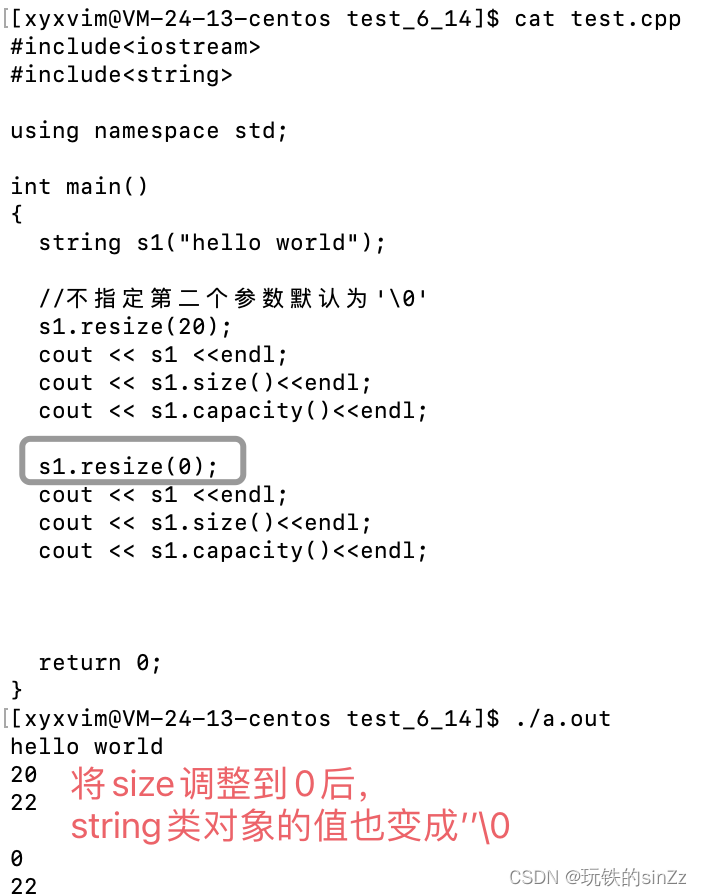
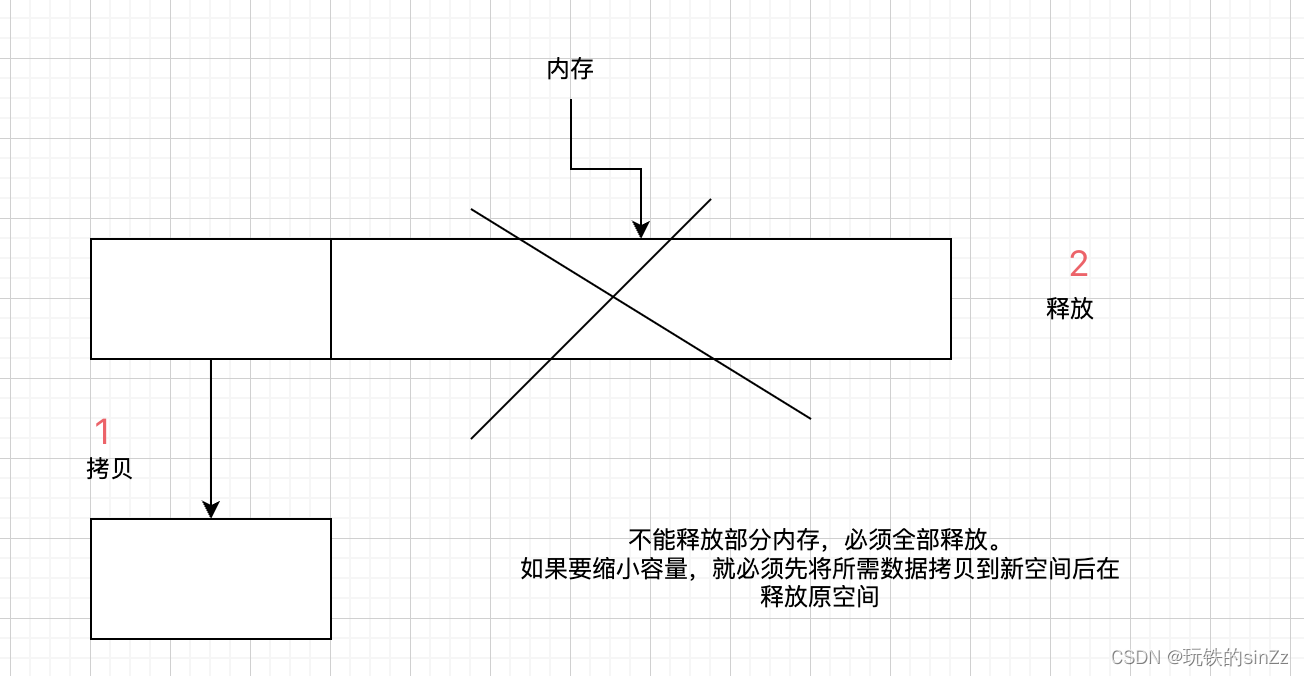
根据对上面的string类capacity相关的成员函数的认识后,我们可以发现,其实string类实现的底层对于string类对象的容量几乎是不会涉及到缩容的。当然也介绍了一个特殊例子(clear后,可能会采取缩容)。根据我们前面对于c/c++内存管理的所学知识,可以大致分析出这是因为系统底层缩容的逻辑并不是向我们想象中的,可以一部分一部分的讲内存还给操作系统。而是还给操作系统就必须全部还给操作系统。这样导致了缩容必须先将一部分数据拷贝到开辟的新空间后,在讲原空间还给操作系统。这样对于程序的性能会有损耗,在内存成本日益降低的现在,这样的行为也显得并不值当了。