【2023最新超详细】全国建筑市场监管公共服务平台(四库一平台)js逆向
js逆向思路
第一步看请求网址的发起程序都有哪些
接在js文件搜索AES,MD5,等高频加密方式的字段
1 parse
2 decrypt
3 .toString()
4 Base64
5 表单字段
6 url关键字
最后可疑的地方都打上断点,调试,跟踪堆栈
第一步抓包
首先右键打开开发者工具,打开网络界面
接着点击翻页,抓到第二页的包
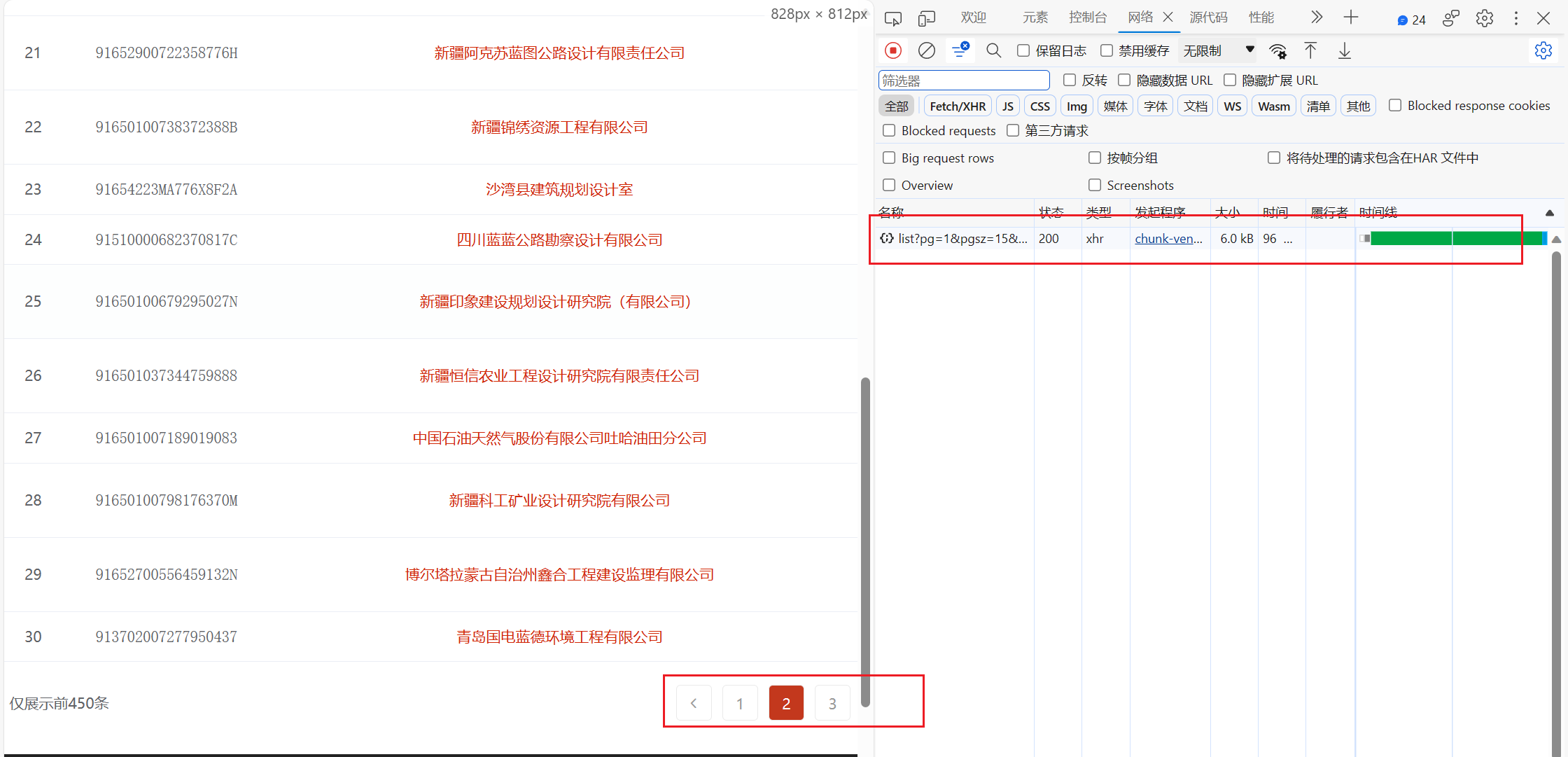
这里可以看到点击第二页后只有一个包,那肯定是他了,接着我们看他返回的数据
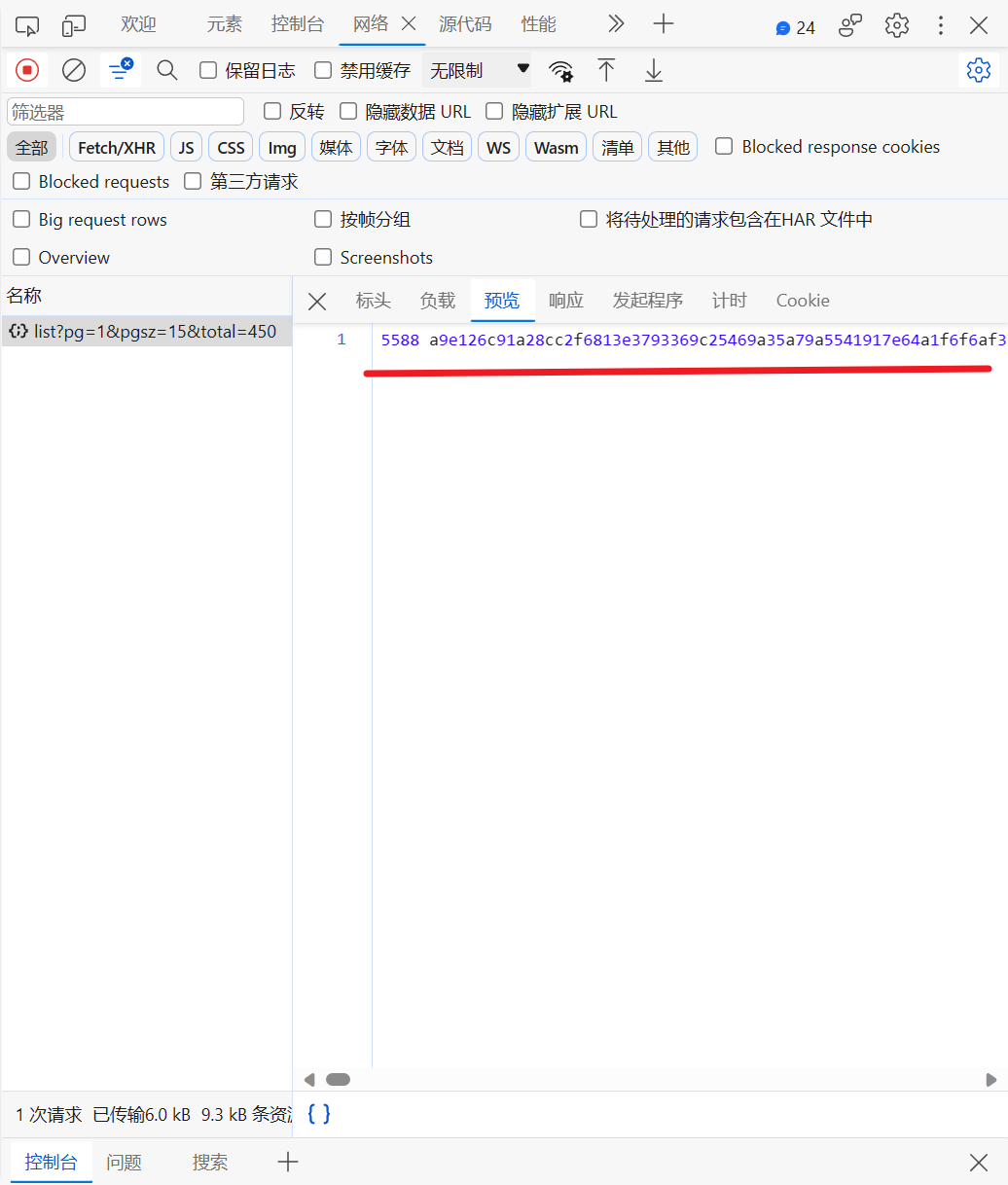
可以很明显的看到被加密了
破解的发法我这里有两种
第一种破解方法,堆栈法
首先打开发起程序
找到app的js文件
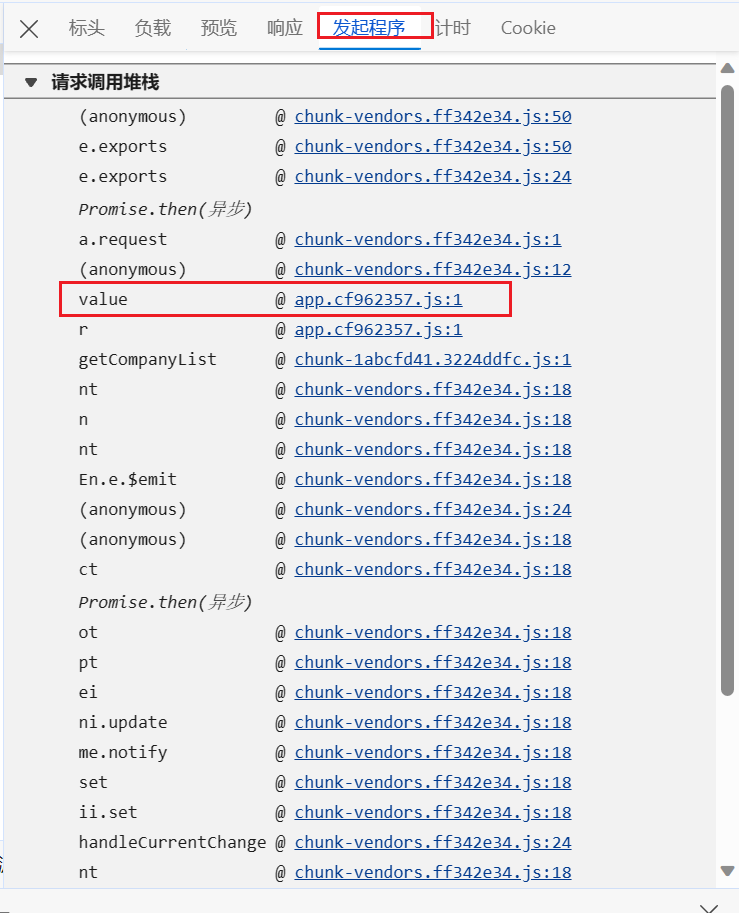
一般的返回值都是这个文件
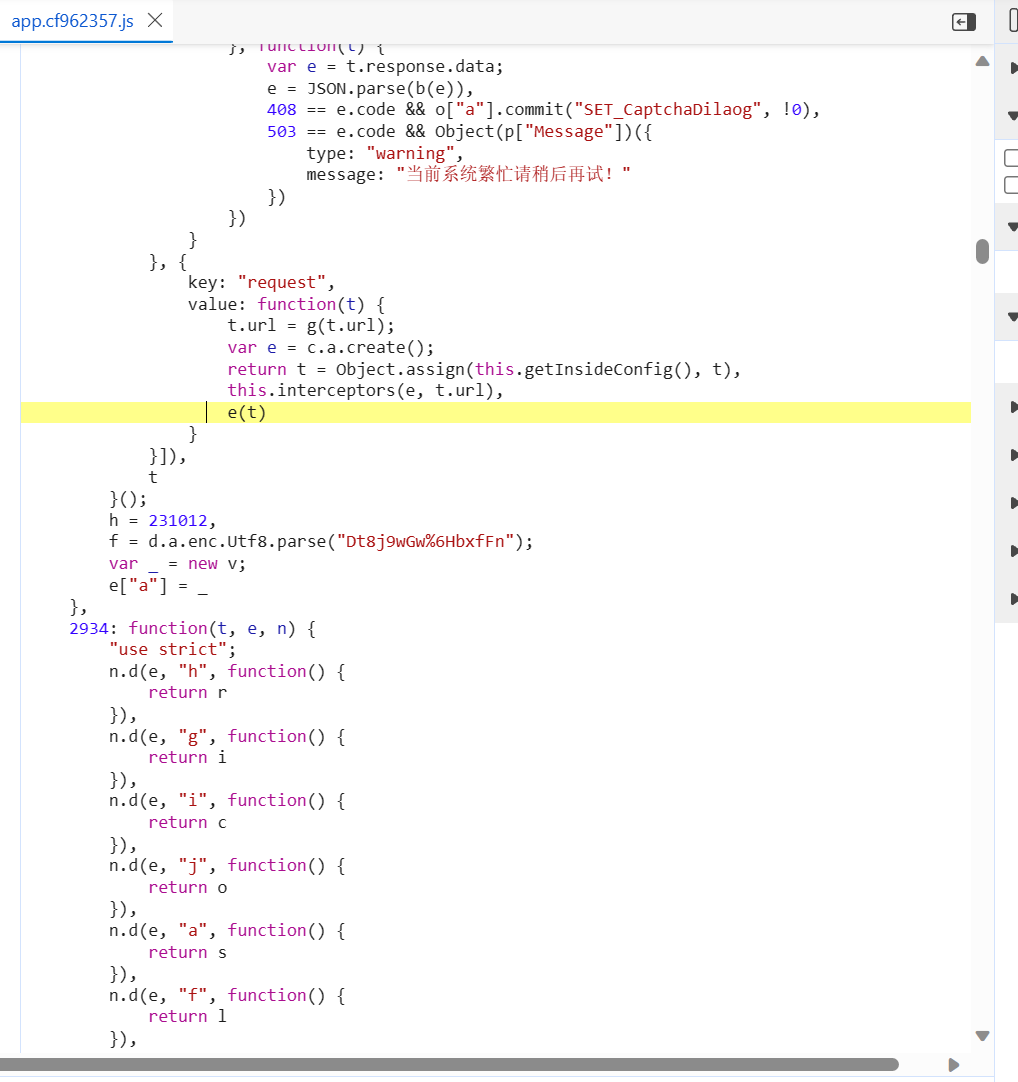
打开之后黄色的这行就是调用的语句
我们这行代码上下部分的return和函数的地方打上断点
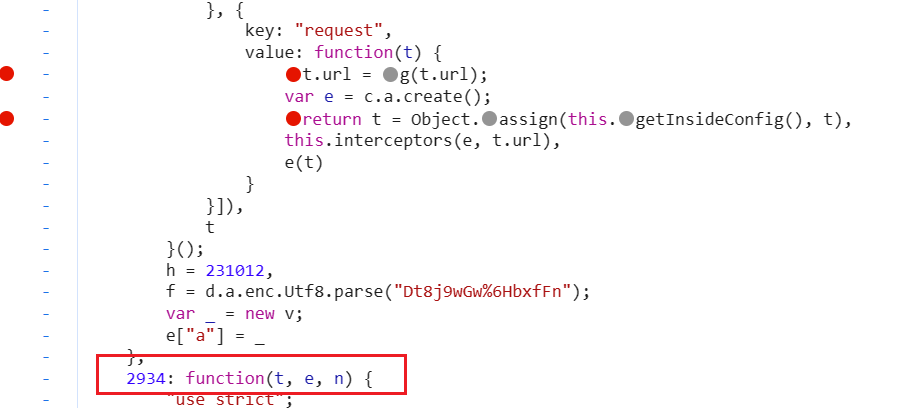
这个是2934,最好把这行代码的整个函数代码的return都打上
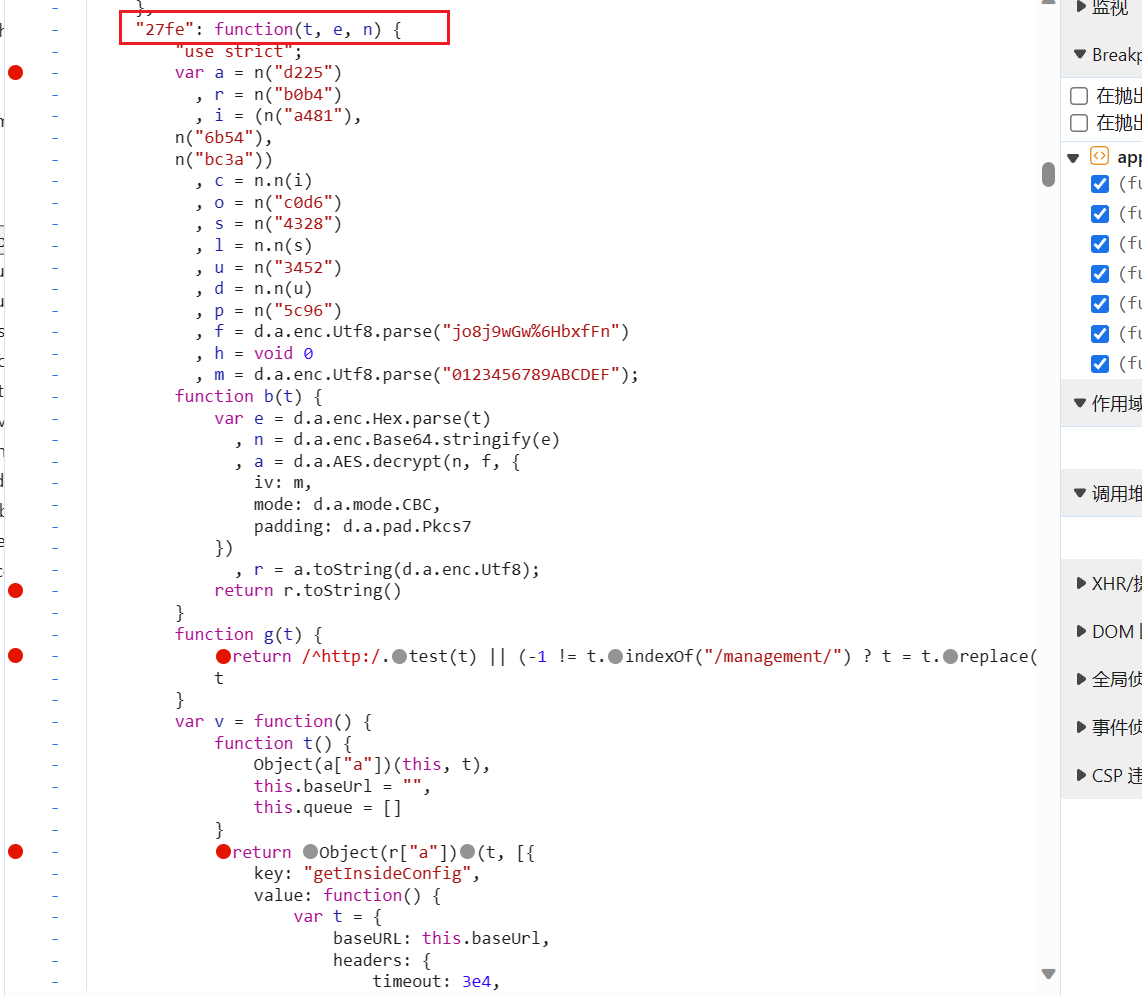
我在这行代码(e(t))的最开始的地方打断点的就发现 函数b 有问题,因为他的关键字,这个在第二种方法会讲。
现在打好断点后再次抓包
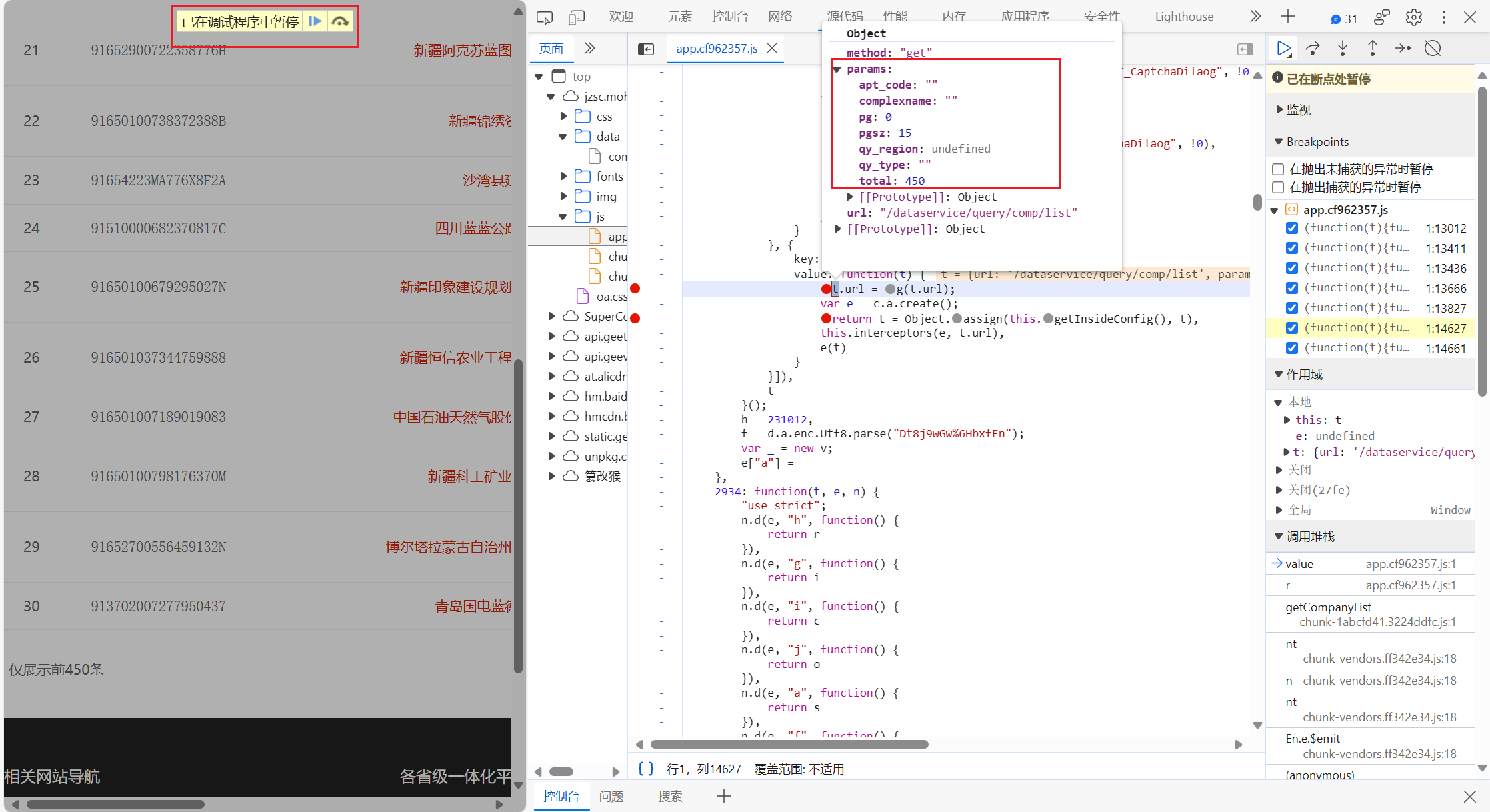
这里也是断上了,先看看这个t是啥,params一看就是表单吧,很可疑
我们继续走
点击抓包工具里的三角形图案往下运行
在运行了几次之后
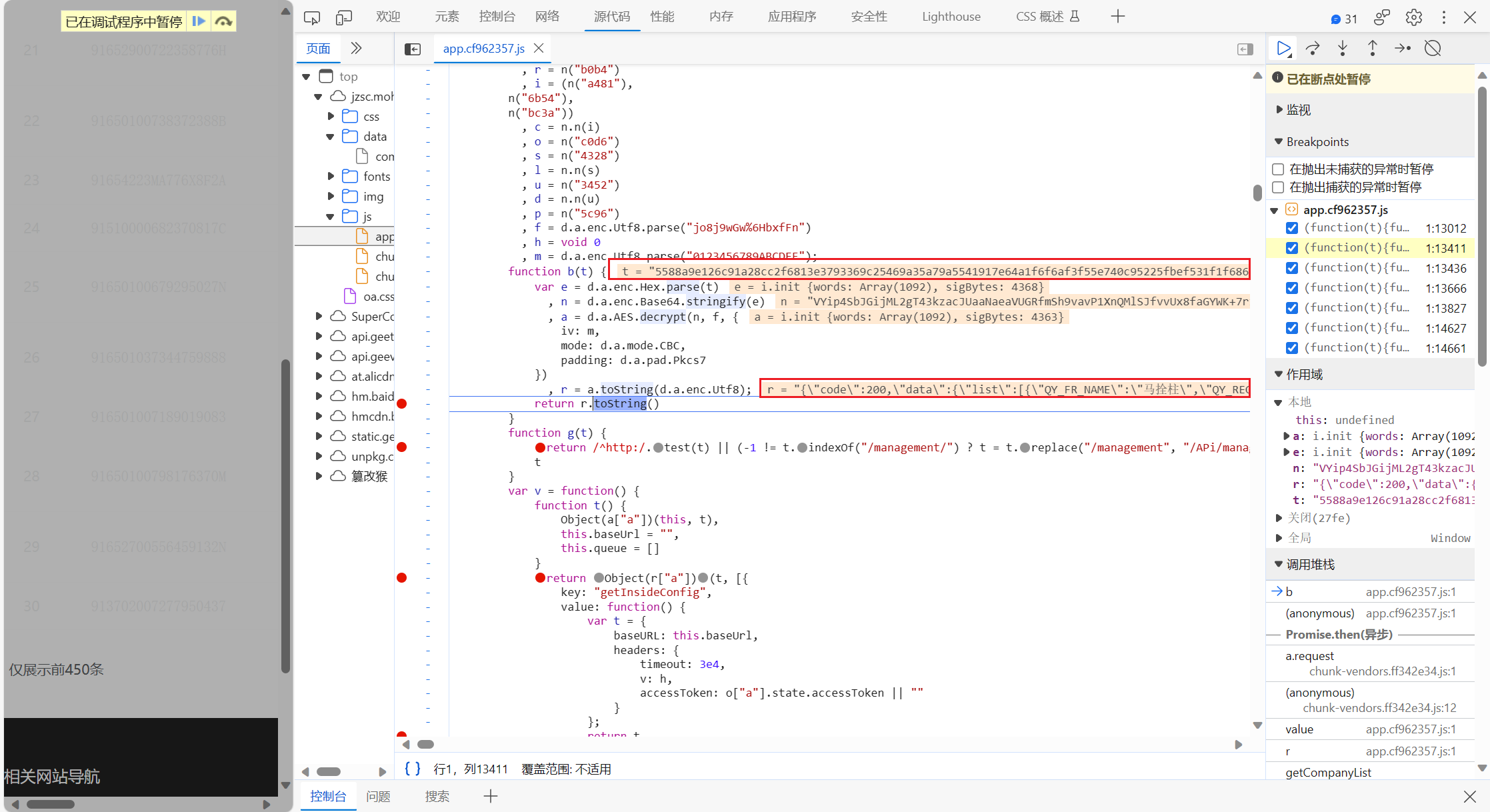
就到了我说的很可疑的那段代码,函数b(t):
t 一看不就是 加密后返回值吗
r 是解密后的返回值
我们细看这段代码
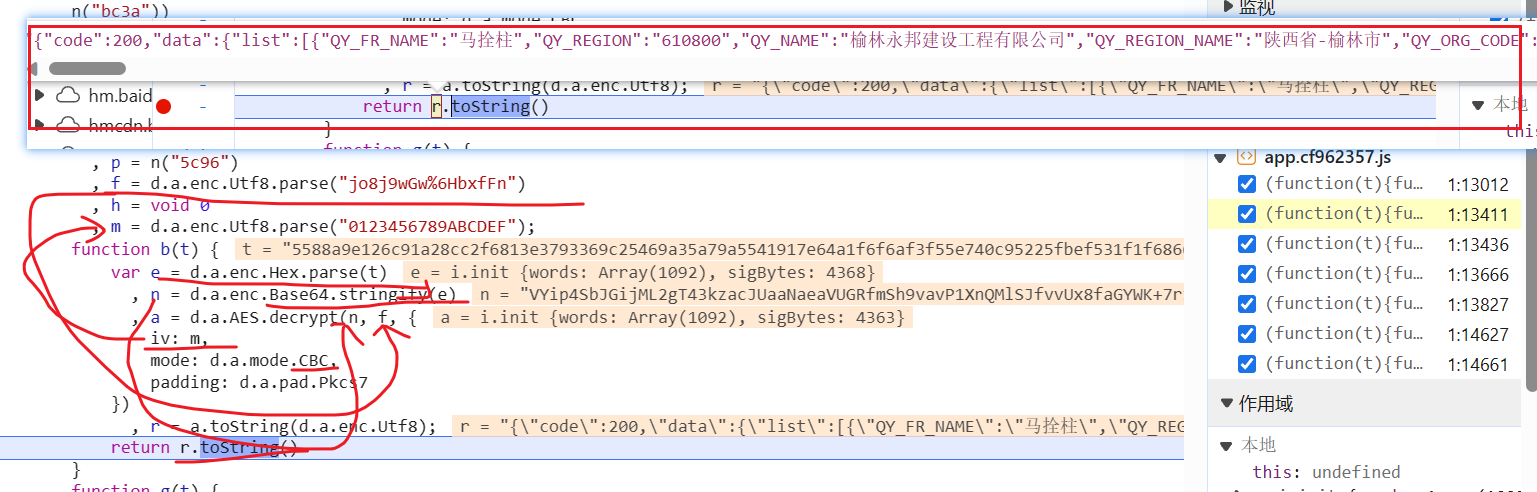
很明显,这是AES加密,CBC模式
先把t,就是加密后的返回值解密赋值给e,
n 是 Base64后的e值
最后在使用密匙和偏移量解密,f和m需要先编码
我们可以扣js代码,也可以使用python还原
python还原
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
import binascii
# python AES解密
def decrypt(data):
KEY = 'jo8j9wGw%6HbxfFn'.encode()
IV = '0123456789ABCDEF'.encode()
cipher = AES.new(key=KEY, mode=AES.MODE_CBC, iv=IV)
decrypted_data = cipher.decrypt(binascii.a2b_hex(data))
result = unpad(decrypted_data, block_size=AES.block_size).decode('utf8')
return result
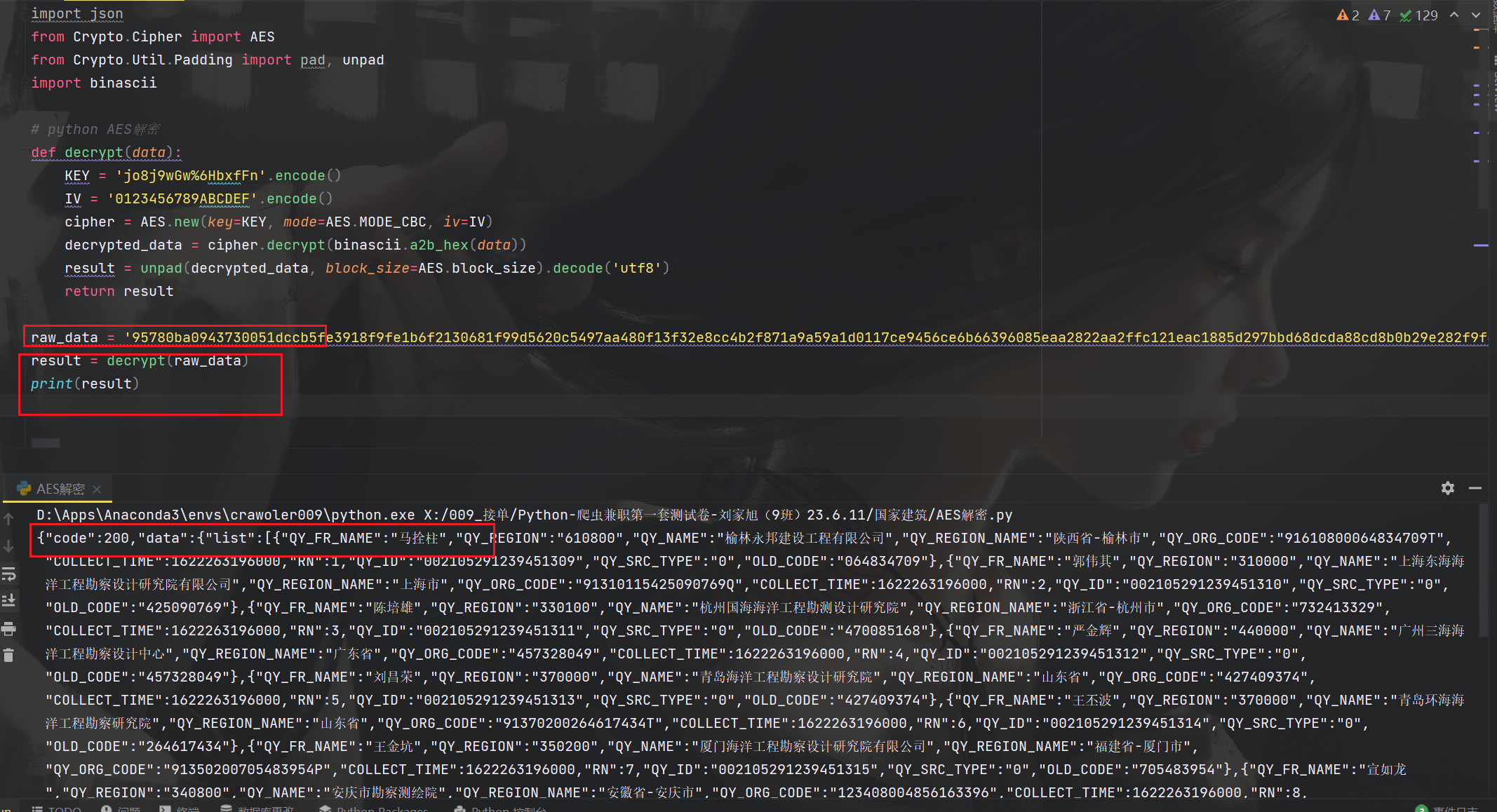
可以看到,我们直接使用加密后的返回值测试python AES解密,这里是成功了
js扣代码还原
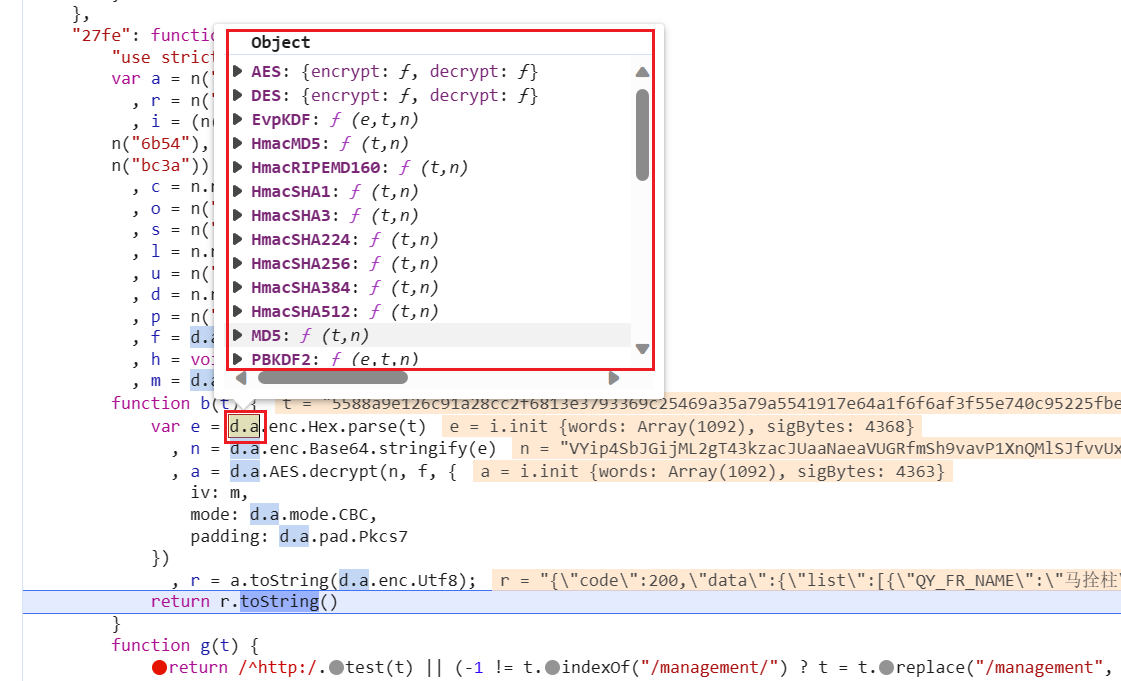
抠代码的时候,我们可以看到d,a就是一个算法包,里面有AES,有MD5等等等
我们也可以扣,不过太麻烦了,我们可以直接导入算法包
# 安装算法加密包
npm install crypto-js
然后把d.a 全换成算法加密包就行
// 导入算法加密包
const CryptoJS = require('crypto-js')
f = CryptoJS.enc.Utf8.parse("jo8j9wGw%6HbxfFn");
m = CryptoJS.enc.Utf8.parse("0123456789ABCDEF");
function b(t) {
var e = CryptoJS.enc.Hex.parse(t)
, n = CryptoJS.enc.Base64.stringify(e)
, a = CryptoJS.AES.decrypt(n, f, {
iv: m,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
})
, r = a.toString(CryptoJS.enc.Utf8);
return r.toString()
}
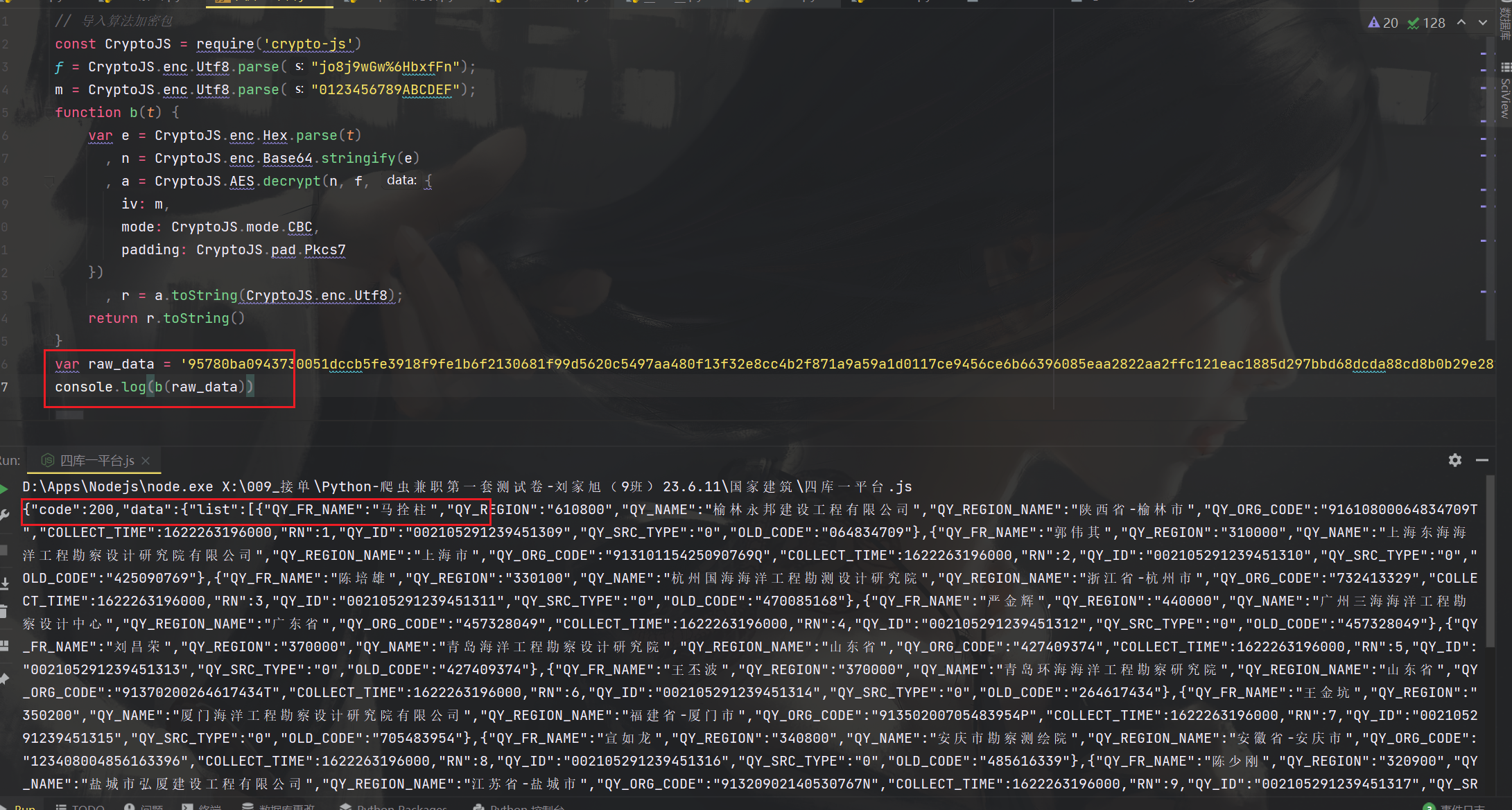
这里通过打印测试,可以看出来,用js扣代码也成功了
接下来使用execjs模块在python中运行js就行
import execjs
f = open('四库一平台.js','r',encoding='utf-8')
text = f.read()
f.close()
js = execjs.compile(text)
raw_data = '957******'
res = js.call('b',raw_data) # call(func,*args) 第一个参数为函数,后面都为参数
print(res)
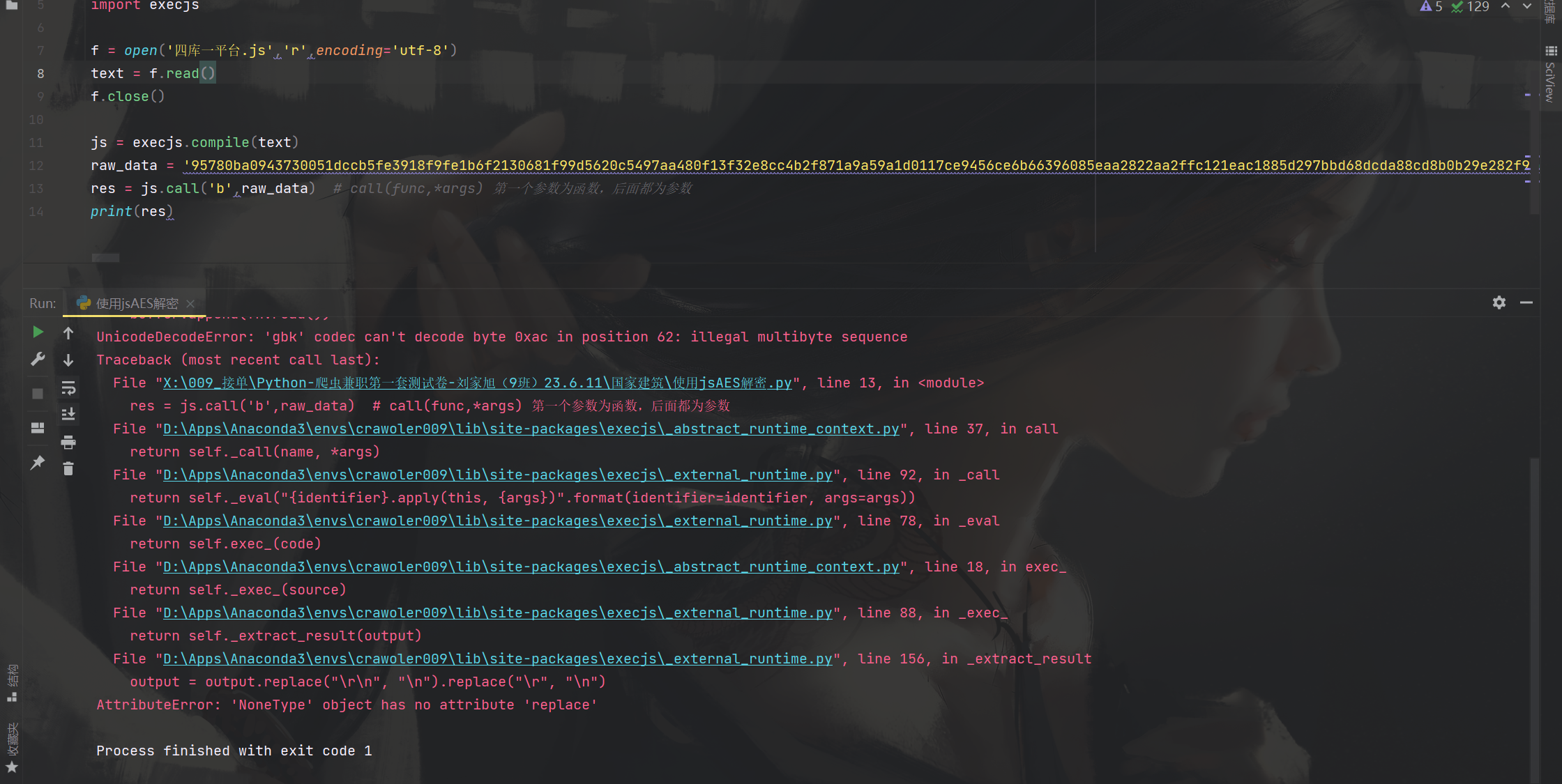
这里运行后如果报错AttributeError: ‘NoneType’ object has no attribute ‘replace’
这里教大家如何解决代码报错问题,一次性教会,看了之后不后悔
【2023最新】超详细!!!python解决代码报错的四个方法保证看完学会并且解决代码报错
具体查看后是因为乱码了
解决方法
在导入execjs之前
加上下面的代码
import subprocess
from functools import partial
subprocess.Popen = partial(subprocess.Popen, encoding='utf-8')
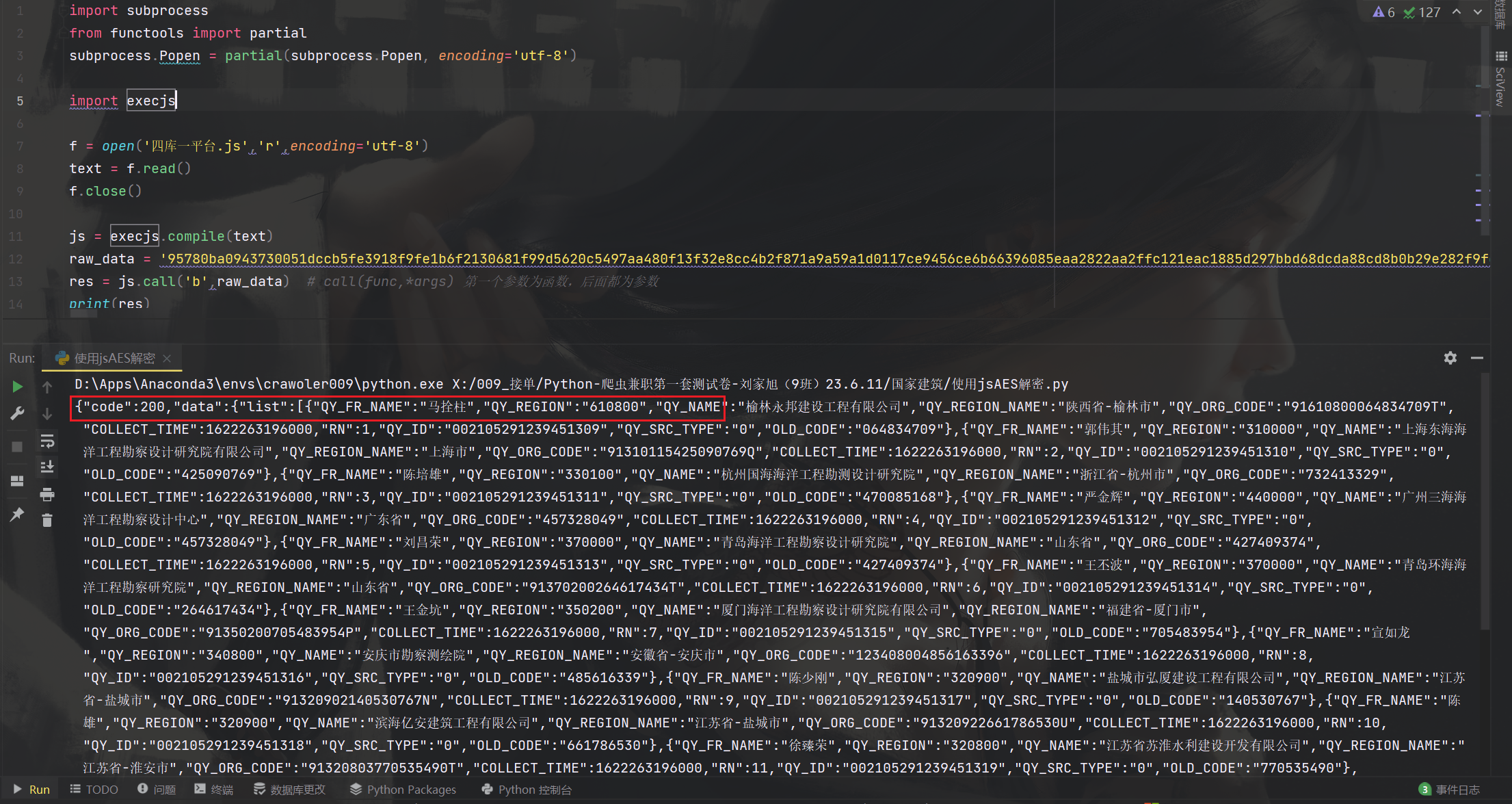
第二种破解方法,搜索法
这种方法不是很好用,因为关键字如果有几十几百就不行了
当我们看到是加密的返回值时,我们第一时间就要想到AES,MD5等加密方式
但是加密一定要解密,如果你js看的多的话,就会发现解密的关键字其实大部分都一样
# 1 parse
# 2 decrypt
# 3 .toString()
# 4 Base64
# 5 表单字段
# 6 url关键字
这些是我自己整理的
我们可以直接点击右上角的搜索进行查看
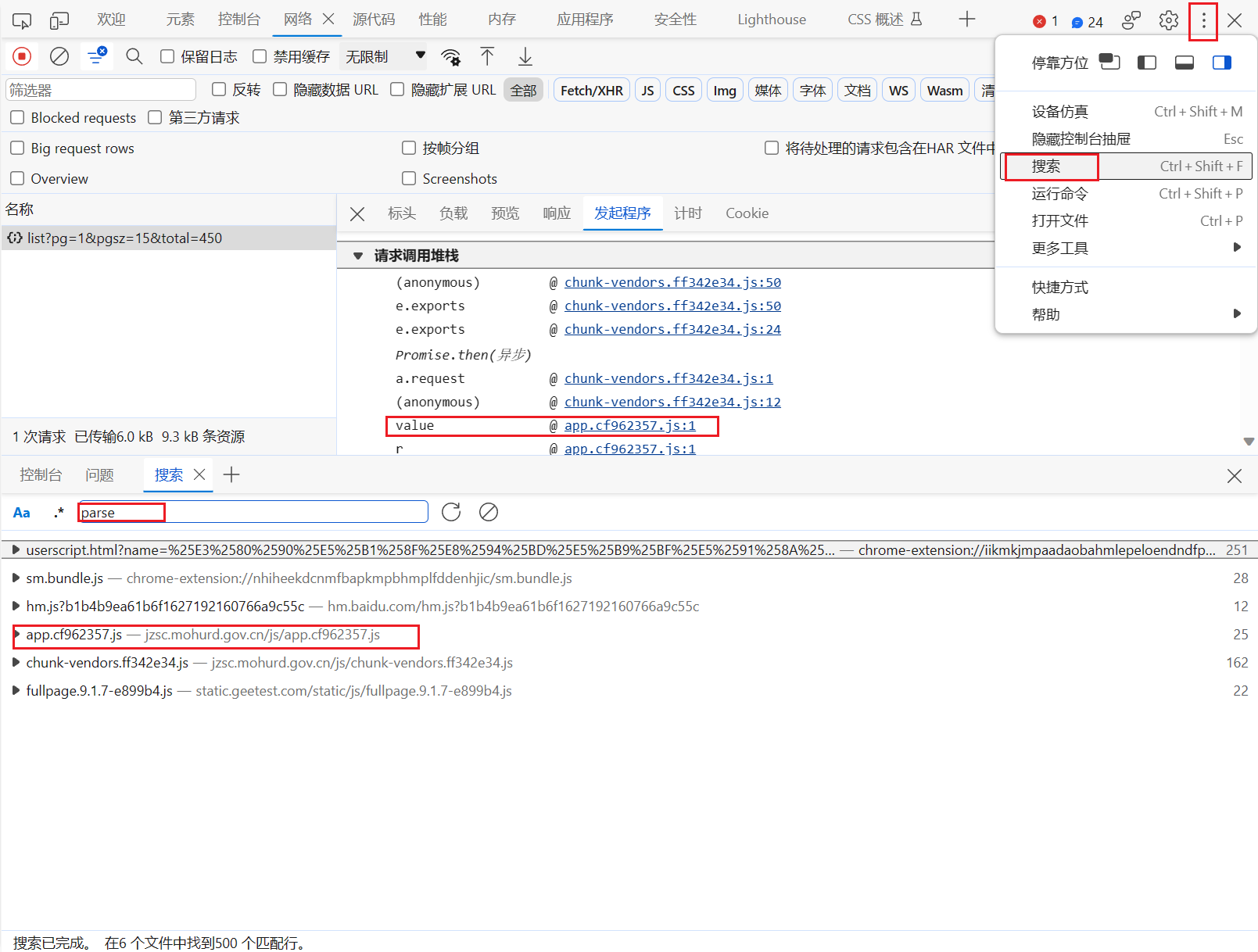
我们这里可以根据发起程序,重点看app这个文件,我们可以看到有25个,我们换一个
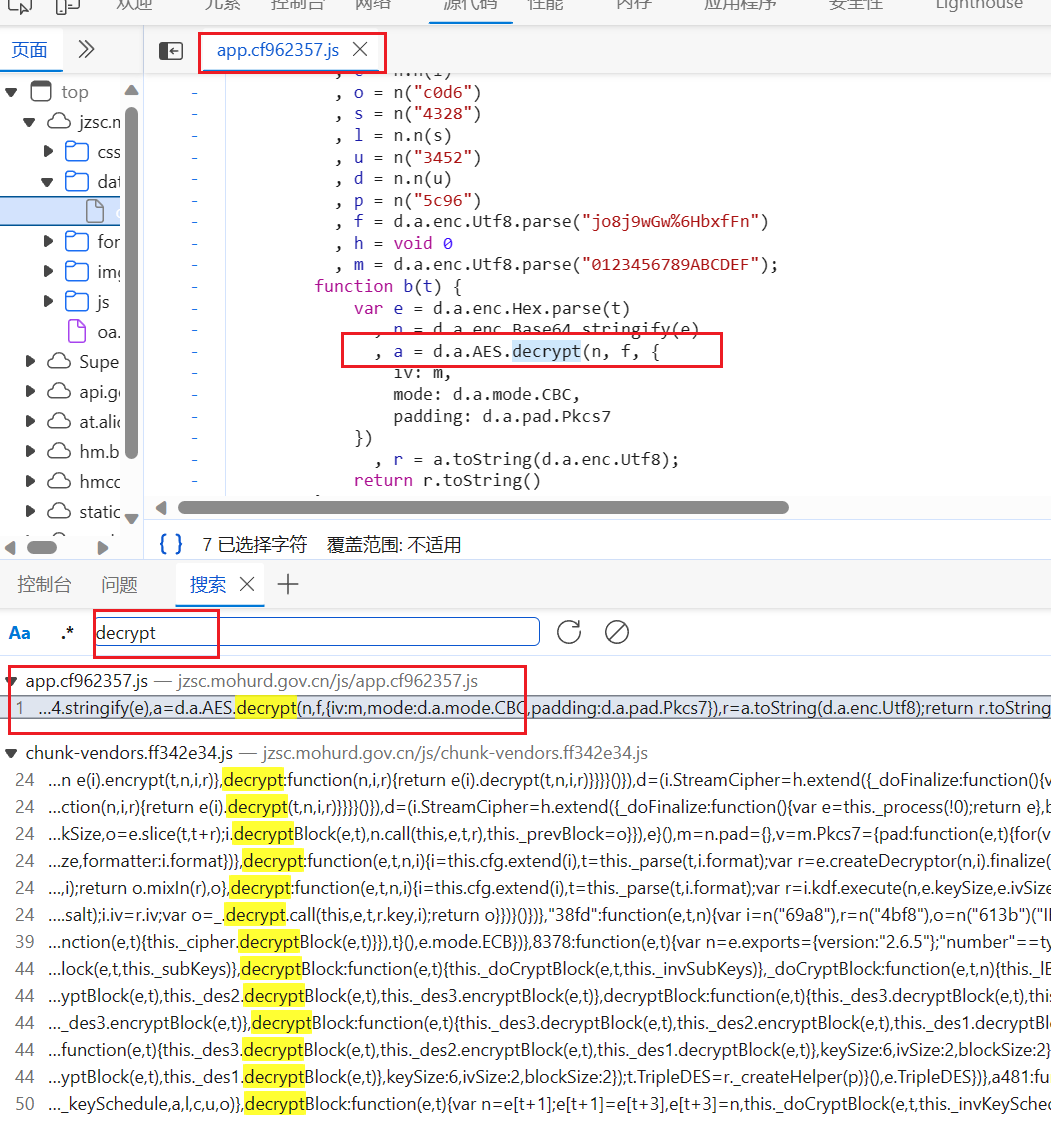
可以看到,换了一个后,就只剩一个了,而且点开一看,就是我们用第一种方法时找到的那段代码
搜索法很好用,你js逆向多了,就知道解密的关键字都有哪些,可以更精准,不用一点点的打断点
或者在关键字那里都打上断点,这样效率也是不慢的
完整代码
import json
import time
import requests
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
import binascii
url = 'https://jzsc.mohurd.gov.cn/APi/webApi/dataservice/query/comp/list'
headers = {
'Referer': 'https://jzsc.mohurd.gov.cn/data/company',
'User-Agent': '你的User-Agent',
'cookie':'你的cookie'
}
params = {
'pg': '1',
'pgsz': '15',
'total': '450',
}
# python AES解密
def decrypt(data):
KEY = 'jo8j9wGw%6HbxfFn'.encode()
IV = '0123456789ABCDEF'.encode()
cipher = AES.new(key=KEY, mode=AES.MODE_CBC, iv=IV)
decrypted_data = cipher.decrypt(binascii.a2b_hex(data))
result = unpad(decrypted_data, block_size=AES.block_size).decode('utf8')
return result
# 翻页
for i in range(30):
params['pg'] = str(i)
response = requests.get(url, headers=headers, params=params)
time.sleep(1.5)
try:
result = decrypt(response.text)
# print(result)
json1 = json.loads(result)
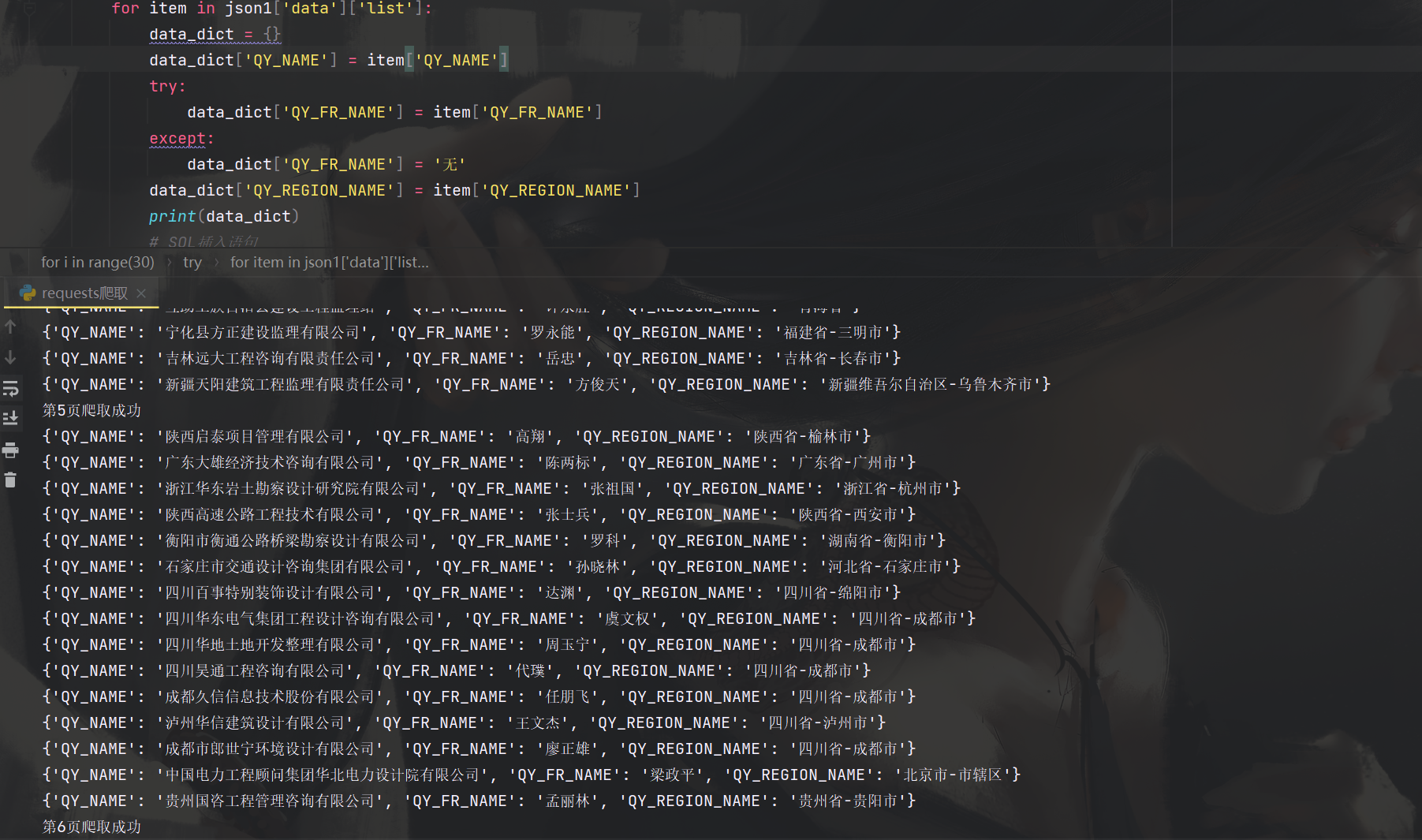
for item in json1['data']['list']:
data_dict = {}
data_dict['QY_NAME'] = item['QY_NAME']
try:
data_dict['QY_FR_NAME'] = item['QY_FR_NAME']
except:
data_dict['QY_FR_NAME'] = '无'
data_dict['QY_REGION_NAME'] = item['QY_REGION_NAME']
print(data_dict)
print(f"第{i+1}页爬取成功")
except Exception as e:
print(e)
print(response.text)
效果展示
你也可以把数据存入Mysql数据库,csv文件,xlsx文件等
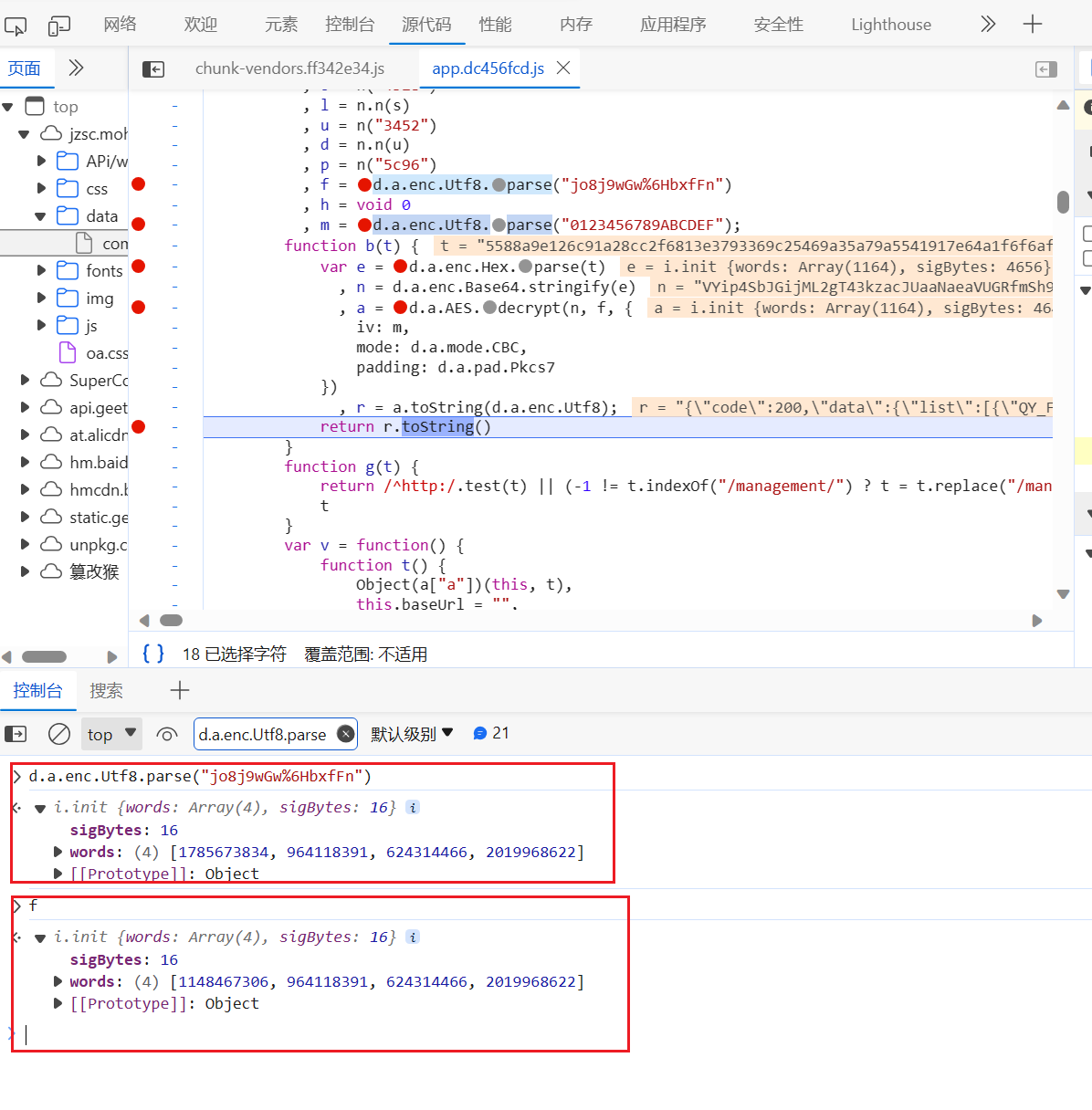
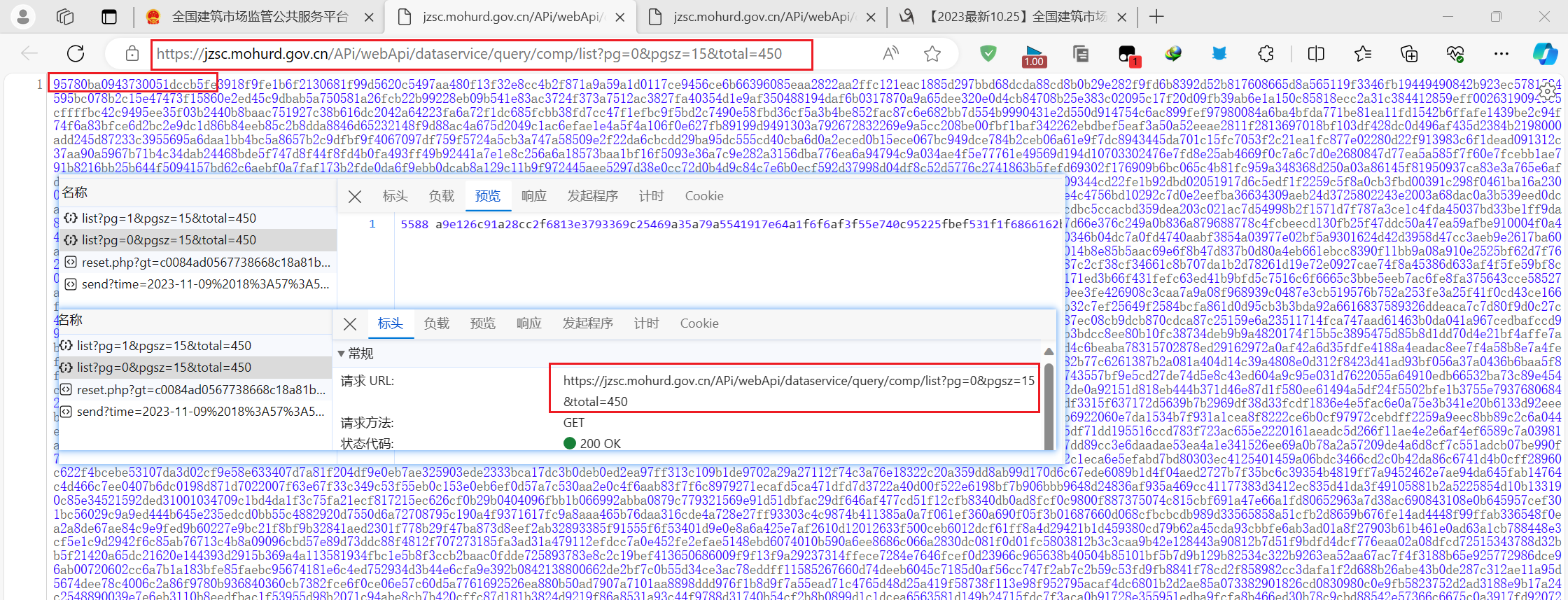
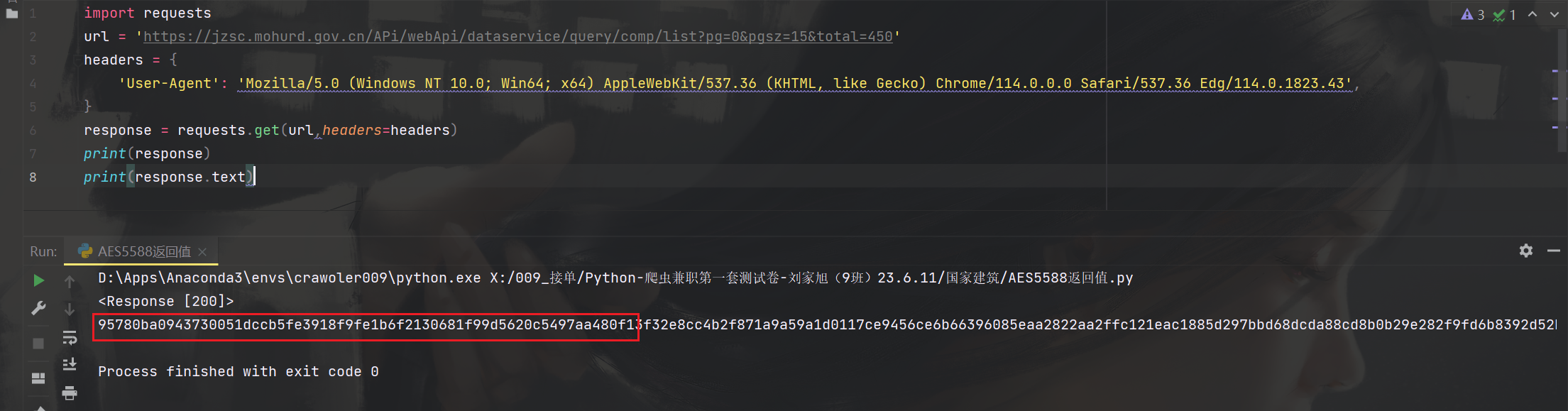
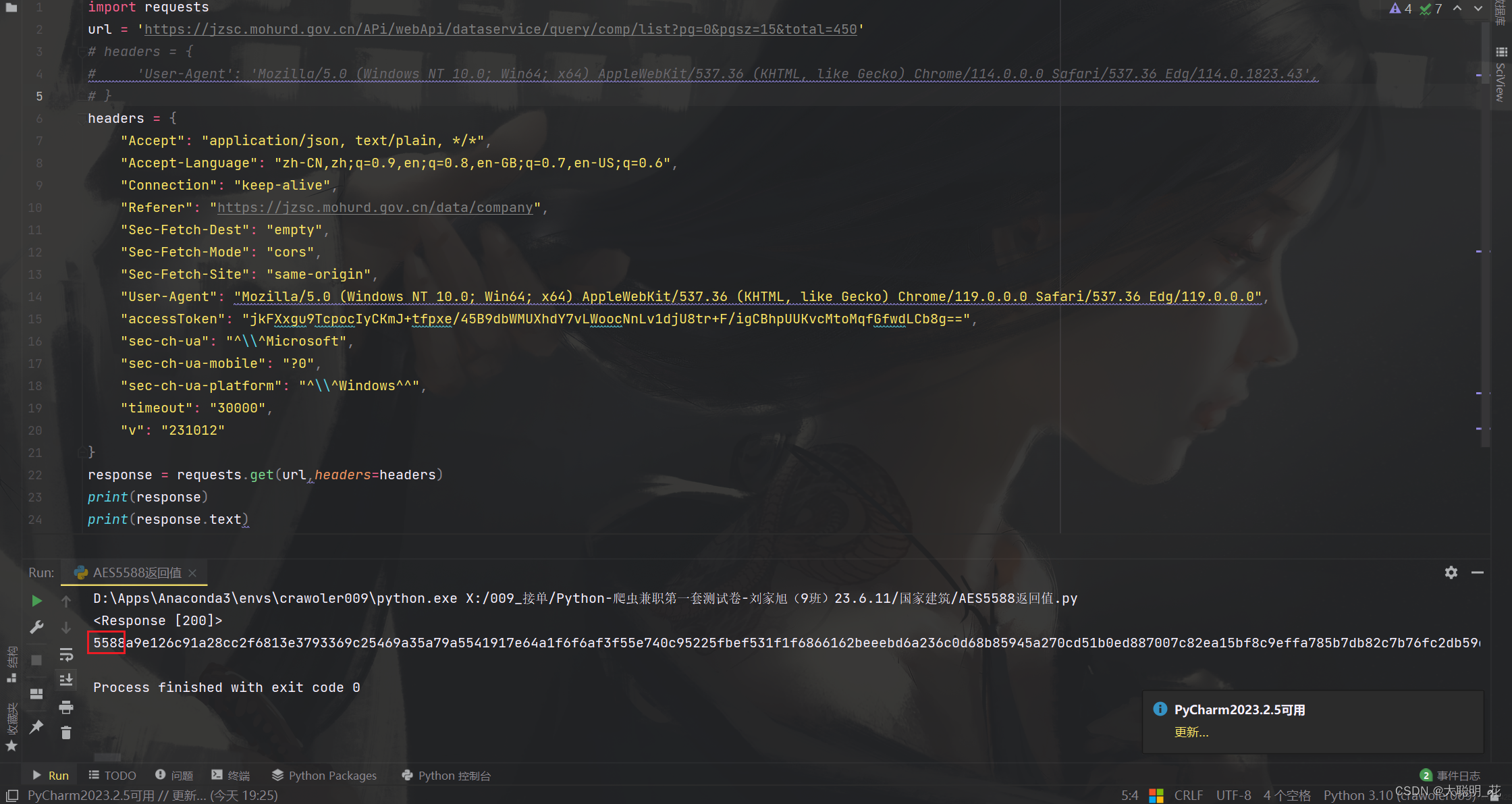
关于5588返回值和95780返回值
好多人问我为浏览器返回的是5588返回值,
但是我测试时使用95780返回值
这是因为请求头的原因,
我请求时只带了ua,所以他给我返回95780
如果我请求时多带几个参数就会返回5588,至于带哪些参数会返回5588你们自己测试
最后!!!
浏览器抓包是95780,但是他返回给浏览器的时候是5588
这是因为他有两个密匙
在调试时输出变量可以看到返回的值不一样
全局搜索后确实发现有两个key
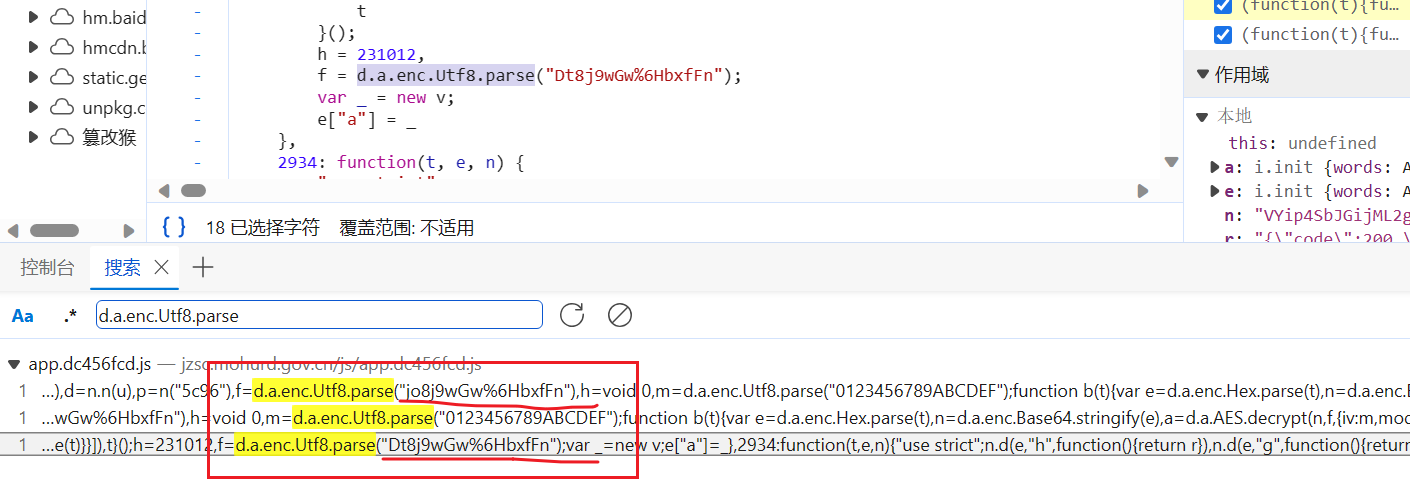
但是!!!
D开头的密匙是解5588的
j开头的密匙是解95780的
但是我们浏览器请求和爬虫请求返回的都是95780,和5588一点关系都没有
而且你使用D开头的密匙解95780会报错,j开头的解5588也会报错
所以我们要根据实际出发,找对我们需要的密匙
关于获取请求头cookies和表单的工具
使用cURL(cmd)获取headers和cookies