不同类型的效度汇总
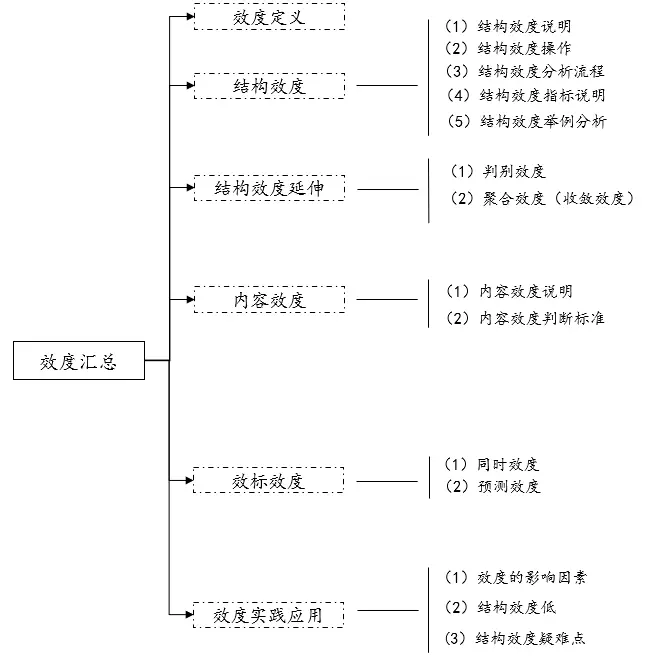
一、效度定义
效度在测量理论中的定义为:在一系列测量中,与测量目的相关的真变异数和总变异数的比。效度反映了测量方法的有效程度或正确性,即测量问卷题是否准确有效,对问卷进行效度检验是实证研究的基本前提,对最终结果的准确性和有效性有重要影响。其一般可以分为四大类:结构效度、内容效度、效标效度以及其它效度(判别效度和聚合效度)。
二、结构效度
1、结构效度说明
结构效度又称构想效度用于测量结果的数据结构与问卷设计是否相符。即研究所测量因子与题项之间的对应关系是否符合预期假设。测量结果的各内在成分是否与设计者打算测量的领域一致。一般可以使用因子分析或者验证因子分析判断结构效度的好坏。
2、结构效度操作
结构效度的分析主要使用因子分析,其通过从量表全部变量中提取一部分公因子分析因子中累积贡献率,共同度等,评价实测指标性质与设计目标是否吻合,如果因子提取的公因子与量表设计时确定的各领域有密切的逻辑关系,则说明有良好结构效度。其操作以SPSSAU为例【进阶方法】→【探索性因子】:

- 因子个数:意为所将分析项划分为几个因子(比如预期共划分4个维度,这里直接选择4即可),如果没有预期维度则无需选择,系统会自动按照特征根大于1的标准进行选择因子个数。
- 相关系数矩阵:提供分析项的相关性情况,相关性若低可能影响KMO值,相关性若过高(比如大于0.8),意味着信息重叠性高没可能存在共线性。
- 因子得分:得到因子得分可以进行后续分析,比如回归分析等。
- 综合得分:综合得分一般用于后续综合对比等。
- 旋转方法:包括最大方差法和最优斜交法。最大方差法的主要目标是找到一个投影方向,使得在该方向上不同类别的样本投影后的方差最大。这种方法假设方差越大,则分类效果越好。最优斜交法通过最小化同类样本之间的距离和最大化不同类别之间的距离来提高分类准确率。一般最大方差法使用较多。
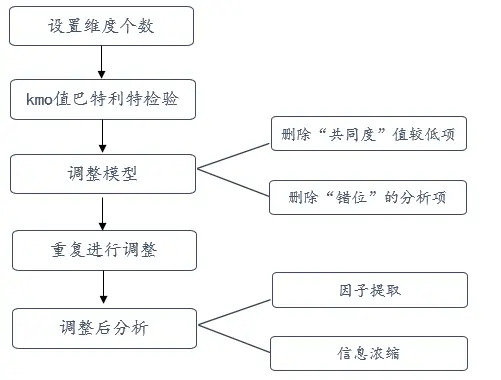
3、结构效度分析流程
在分析前首先进行设置维度个数,当然也可以不进行设置,spssau会默认以特征根大于1为标准进行设置,然后进行查看KMO值和巴特利特检验,目的是为了查看数据是否适合进行因子分析,进行因子分析时大多需要对模型进行调整,其中包括删除“共同度”值较低的项以及“错位”的分析项,什么是错位?比如某分析项本来应该属于因子1但是在结果展示却是因子2,这样的分析项需要考虑删除后在进行分析,重复进行调整直到结构一致,然后在对因子提取和信息浓缩进行简单分析。
4、结构效度指标说明
对于进行结构效度一些常见的指标说明如下:
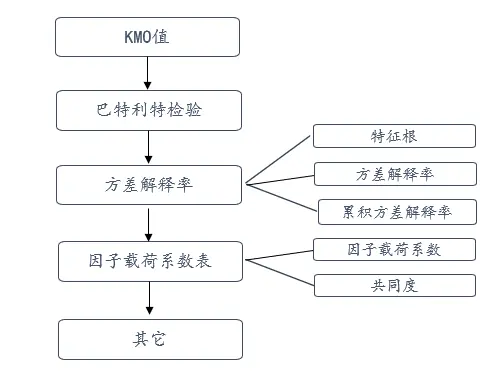
- Kmo值
进行结构效度的正式分析前,第一步需要通过KMO和巴特利特检验进行测量问卷量表进而决定是否适合进行因子分析,KMO值是用来判断所选取变量在因素分析中的可接受程度,考察变量之间相关关系,其计算公式为:
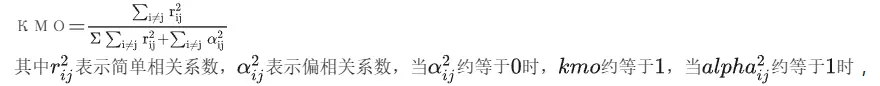
- kmo约等于0,所以kmo取值介于0到1之间。那么kmo值的判断标准是怎么样的呢?
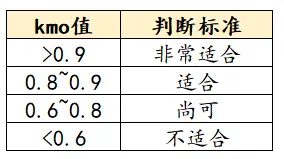
一般进行因子分析需要kmo值大于0.6即可。处理之外还需要关注巴特利特检验。
- 巴特利特检验
巴特利特检验原理上是检验各变量是否独立,确定因素的相关性,如果模型显著(对应的p值小于0.05)说明适合因子分析。 - 特征根
特征根值一个方阵在线性变化下的变化率,指标旋转前每个因子的贡献程度。此值的总和与项目数匹配,此值越大,代表因子贡献越大。 当然因子分析通常需要综合自己的专业知识综合判断,即使是特征根值小于1,也一样可以提取因子。 - 方差解释率
方差解释率表格,主要用于判断提取多少个因子合适。以及每个因子的方差解释率和累计方差解释率情况。方差解释率越大说明因子包含原数据信息的越多。因子分析中,主要关注旋转后的数据部分。 - 累积方差解释率
累积的方差解释率,所有因子提出的信息量,累积方差解释率一般认为大于60%比较合适。 - 因子载荷系数
因子载荷系数用于衡量观测变量与因子之间的相关程度,一般用于反映观测变量在因子中的贡献程度或者权重,其数值范围一般在-1到1之间,绝对值越大说明观测变量和因子的相关程度就越高。当绝对值为1时,说明观测变量与因子之间存在强相关关系。可以利用此指标进行判断因子与观测变量的对应关系。 - 共同度
因子分析中的共同度也称公因子方差,共同度可以衡量变量之间的相关性,从而了解变量之间的关联程度。并且共同度可以筛选出对因子解释度高的变量,进而简化模型提高模型的解释率,共同度可以通过因子载荷矩阵进行计算。在因子分析中一般要求大于0.4。 - 碎石图
结合碎石图辅助判断因子提取个数。当折线由陡峭突然变得平稳时,陡峭到平稳对应的因子个数即为参考提取因子个数。 - MSA指标
MSA(Measure of Sample Adequacy)指标测量某项与其余项的相对相关关系情况,MSA指标=A/(A+B),A为该项与其余项相关系数平方和,B为该项与其余项偏相关系数平方和,MSA指标的意义为某项与其余各项的相关关系情况,该值介于[0,1]之间,如果MSA指标值过低(比如小于0.2),意味着其可能对信息浓缩帮助较小,可以考虑对其进行删除,以提高KMO值表现等。
5、结构效度举列分析
(1)因子适合度分析
KMO值越大越适合进行因子分析,通常认为KMO值≥0.6是进行因子分析的必要条件。Bartlett 球形检验用于测量变量之间的相关性,判断标准为p值 ≤0.05(或者0.1、0.01)。

(3)公因子提取
如果没有预期划分因子个数,一般会以特征根大于1进行提取因子个数,如果有预期划分个数一般在分析前进行选择即可,一般而言,特征根小于1也是可以进行提取因子个数的。
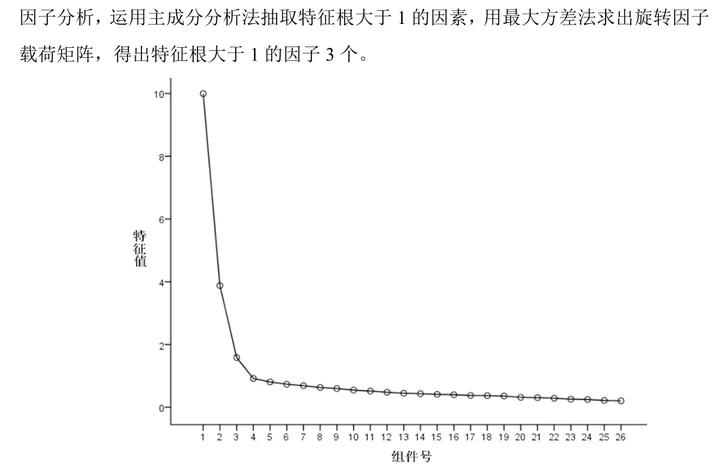
(2)调整因子对应关系
进行筛选分析项的一般标准为:
- 项目的载荷值需要小于0.4需考虑删除;
- 每个因子最少对应两个分析项;
- 删除与因子对应不一致的项,比如分析项A1对应因子1,但是在分析结果中,分析项A1对应因子2,此时考虑将此分析项进行删除后分析;
此过程是多次重复进行的过程,直至分析项与因子对应,此过程结束。最后因子载荷矩阵如图中所示:
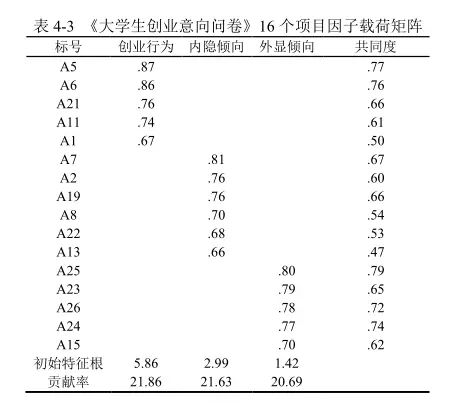
案例来源:疏德明.大学生创业胜任力、创业意向及创业教育的现状与关系[D].苏州大学,2018.
三、结构效度延伸
判别效度和区别效度实质上也是结构效度,具体说明如下。
1、判别效度
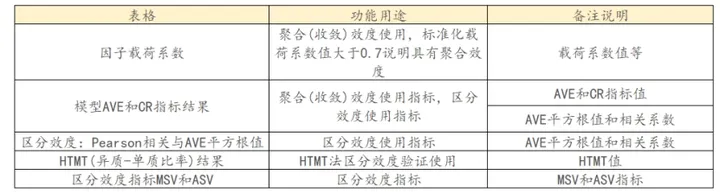
判别效度(又称区分效度、区别效度),其评价指标一般包括因子载荷系数和平均方差抽取值,其一般是指不在同一因子下的题项不会被构成在同一个因子中,判断区分效度的好坏一般有三种:AVE和相关系数结果对比,HTMT法以及MSV和ASV法。接下来一一进行说明。
- AVE和相关分析结果对比
AVE和相关分析结果对比:是使用AVE的平方根值,然后与因子的相关系数进行对比,如果AVE平方根值大于“该因子与其它因子间的相关系数”,此时说明具有良好的区分效度。AVE平方根值可表示该因子的‘聚合性’,而相关系数表示相关关系,如果该因子自己‘聚合性’很强(明显强于与其它因子间的相关系数),则能说明具有区分效度。
- HTMT法
HTMT法也称异质-单质比率:通常情况下使用AVE平方根法较多,HTMT法使用相对较少;如果说HTMT值全部均小于0.9,此时说明数据具有区分效度。
- MSV和ASV法
MSV和ASV法,该2个指标可用于区分效度分析(区分效度还可使用Pearson相关与AVE值对比法),一般情况下MSV和ASV值均小于AVE值则说明具有较好的区分效度。
SPSSAU中提供的分析表格:
2、聚合效度
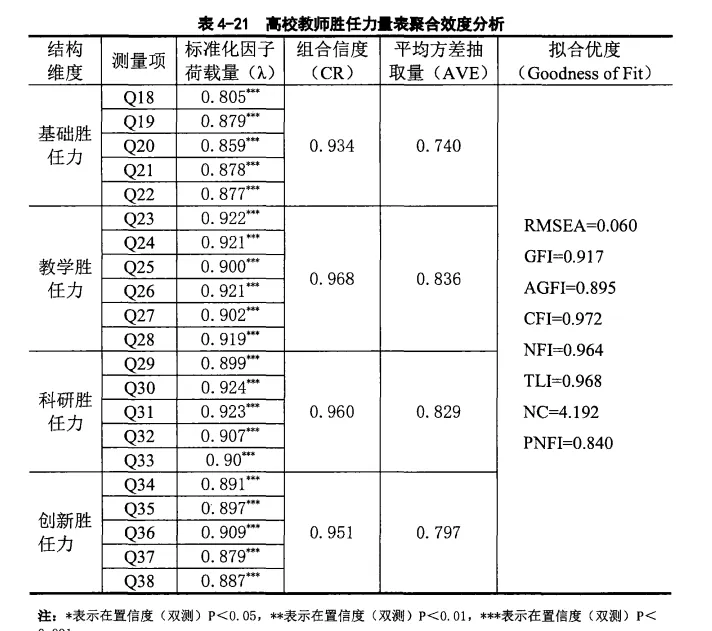
聚合效度也称收敛效度。聚合效度强调本应该在用一个因子下面的测量项,确实在同一个因子下,一般观察AVE和CR指标。AVE反映了每个潜变量所解释的变异量中有多少来自该潜变量中所有题目,加入AVE越高,则表示潜变量(factor)有越高的收敛效度,一般需要大于0.5,不小于0.36,标准化因子载荷大于0.5,CR值是所有测量变量信度的组合,表示潜变量(factor)的内部一致,所以CR值越高,表示内部一致性越好,一般大于0.7。
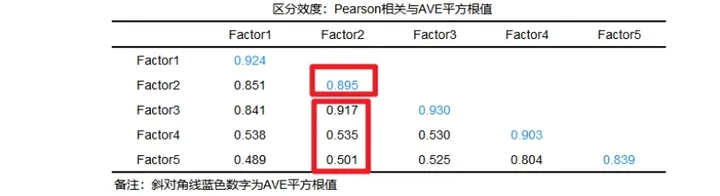
比如以SPSSAU为例,针对Factor1,其AVE平方根值为0.924,大于因子间相关系数绝对值的最大值0.851,意味着其具有良好的区分效度。针对Factor2,其AVE平方根值为0.895,小于因子间相关系数绝对值的最大值0.917,意味着其区分效度欠佳,可考虑移除标准载荷系数值较低项后重新分析。针对Factor3,其AVE平方根值为0.930,大于因子间相关系数绝对值的最大值0.917,意味着其具有良好的区分效度。Factor4、Factor5也同理。一般文献中的表达方式如下:

如果区分效度不好,通常是由于出现‘错位’现象,比如Factor1里面有5个量表题,很可能其中2个题放在Factor2里面更适合。一般是结合载荷系数值判断出此类题,然后删除掉此类题(或者进行移位)即可。
聚合效度不好的原因可能有以下几种:
- 量表设计不合理:量表的设计是影响聚合效度的关键因素之一。如果量表的设计不合理,例如测量项与预期的因子结构不匹配,会导致聚合效度不佳。
- 样本特征不匹配:样本特征也是影响聚合效度的因素之一。如果样本特征与量表设计不匹配,例如样本的年龄、性别、职业等因素与量表中的测量项不相关,会导致聚合效度下降。
- 测量误差大:测量误差是影响聚合效度的另一个因素。如果测量误差大,例如由于环境噪声、仪器误差等原因导致的数据不准确,会导致聚合效度下降。
先进行探索性因子分析后在进行验证性因子分析。
四、内容效度
1、内容效度说明
内容效度(CVI)指的是实际测量得到的内容与索要测量的内容之间的吻合程度,主要测量方法有专家判断法、统计分析法和经验推断法。
专家判断法:就每一条目与相关内容维度的关联程度,认为关联较高的专家人数与总人数之比,即为内容效度;
统计分析法:包括复本信度、折半信度和再测法等;
经验推断法:通常通过实验进行检验效度。
一个测验进行内容效度需要进行具备两个条件,第一测验内容的范围需要明确,第二取样需要具有代表性。
2、内容效度判断标准
内容效度一般分为条目内容效度和量表内容效度,一般认为,条目内容效度大于0.78,量表内容信度大于0.9认为内容效度较好。常用的内容效度的评价方法有两种:
- 专家法
请有关专家对问卷题目与原来的内容范围是否符合进行分析,做出判断。 - 统计分析法
从同一内容总体中抽取两套问卷,分别对同一组答卷者进行测验,两种的相关系数就可以进行估计问卷的内容效度。
文献中参考案例:

五、效标效度
效标效度是指测评得分与外部效标之间的关联,包括同时效度和预测效度。
1、同时效度
同时效度主要用于查明自编测验的效度,方便有效的研究用于新测验等等。比如跳远测验以学生当时的血液成绩为效标,其度量的指标是测验与效标分的相关系数。
2、预测效度
预测效度主要用于评价原测验的预测能力,并且预测效度的效标要在原测验之后隔相当长时间才能获得,常用的效标资料包括专业训练成绩与实际工作成果等。比如设计一种预测学生毕业时学习成绩的量表或者测验,用它来衡量学生毕业时的学生成绩,如果在实际学生毕业时,是假的学习成绩确实与预测值相一致,那么说明这个量表具有预测效度。其度量指标一般是测验分与效标分的相关系数。效标效度的哦暗短标准如下:

六、效度实践应用
1、效度的影响因素
- 受测者样本的特征
其中包括样本的大小,样本的异质性以及干扰变量等,比如受试者在环境干扰的情况下很可能出现评分或者计分出现偏差的情况。 - 测验的构成
当组成实验的试题样本没有较好的代表想要测量的内容或者结构时,测量的内容效度或者结构效度就不会太高。 - 效标的选择
不同的效标其结果可能不同,因此如果效标不合理,其效度就不具有代表性。
2、效度低
1、共线性问题
原理上因子分析要求各个分析项之间有着适中的相关关系(不能过高或过低)。如果分析项之间的相关系数值过高(比如大于0.8),说明共线性太强,无法有效浓缩信息,此种情况可能导致KMO值无法输出。建议在进行因子分析前可先进行相关分析进行查看各分析项间的相关系数情况,移除掉相关系数值过高项之后,再次进行分析即可。
2、样本量问题
样本量过少容易导致相关系数过高,一般希望分析样本量大于5倍分析项个数。
3、选择样本问题
要选择具有代表性的样本,样本越有代表性,在其它相同条件下,其效度就会越高。
4、效标问题
效标是效标效度的先决条件,要根据内容选择合理的效标,如果效标不同,效度也会不同,一般效标不合理,其效度就不具有代表性。
5、问卷设计
问卷设计要合理,问卷的内容需要科学合理设计,题目的难度需要适中,否则会影响问卷的效度。
6、分析处理
效度分析时,需要进行删除题目,比如载荷值小于0.4的项,便于后续的维度和题项相对应。
3、效度疑难点
(1)只有两个题项需要进行效度分析吗?
如果某维度仅对应两个量表题项,此时KMO值一定是0.5,此时可直接针对载荷系数值进行描述说明即可,当载荷系数都大于0.4时则说明有效度。SPSSAU建议需要提前做好预防,除非专业上要求,否则一个维度需要在2个以上(尽量4~7个题)较好。仅两个题项去表示一个维度时,容易出现信度不达标等现象。
(2)结构效度的探索性因子分析中特征根小于1也可以提取因子吗?
分析时通常需要综合自己的专业知识,以及软件结果进行综合判断,即使是特征根值小于1,也一样可以提取因子。
(3)累积方差解释率大于100%怎么样?
正常情况下,累积方差解释率会小于100%,但如果数据的共线性问题太严重,有可能出现方差解释率值大于100%,此时建议进行相关分析,找出相关性太强(比如相关系数大于0.8)的项,然后从分析框中移出后再次分析。与此同时,如果样本量太少也可能出现此问题建议加大样本量即可。
(4)信度或者效度分析删除的项,后续分析是否需要保留呢?
如说已经在信度分析(也或者效度,也或者其它分析)时认为某个分析项不合理需要对其删除处理,那么后续各类分析方法一般均需要同步一致,并不是把数据直接删除,而是在分析时直接不分析该项即可。
参考文献:
[1]罗霄.移动学习情境下学习者对平台正面口碑传播意愿的影响因素研究[D].西南交通大学,2020.DOI:10.27414/d.cnki.gxnju.2020.002876
[2]朱福英.类风湿关节炎患者自我管理能力量表的构建与应用[D].南昌大学,2022.DOI:10.27232/d.cnki.gnchu.2022.000235
[3]刘思玲.网络成瘾量表的系统评价[D].江西师范大学,2020.DOI:10.27178/d.cnki.gjxsu.2020.001093
[4]刘晓佩.学龄前儿童感觉处理测量量表(SPM-P)的汉化及信度、效度研究[D].佳木斯大学,2022.DOI:10.27168/d.cnki.gjmsu.2022.000022