图文—神经网络组成(卷积层、池化层、全链接层、激活函数)与发展史(LeNet、AlexNet、VGG、ResNet、GAN)
目录
说明:建议神经网络初学者食用。因为介绍的比较系统,所以文字很多,请耐心通读,相信你会有不同的收获。
先有个全面的了解,再进行后面细节学习
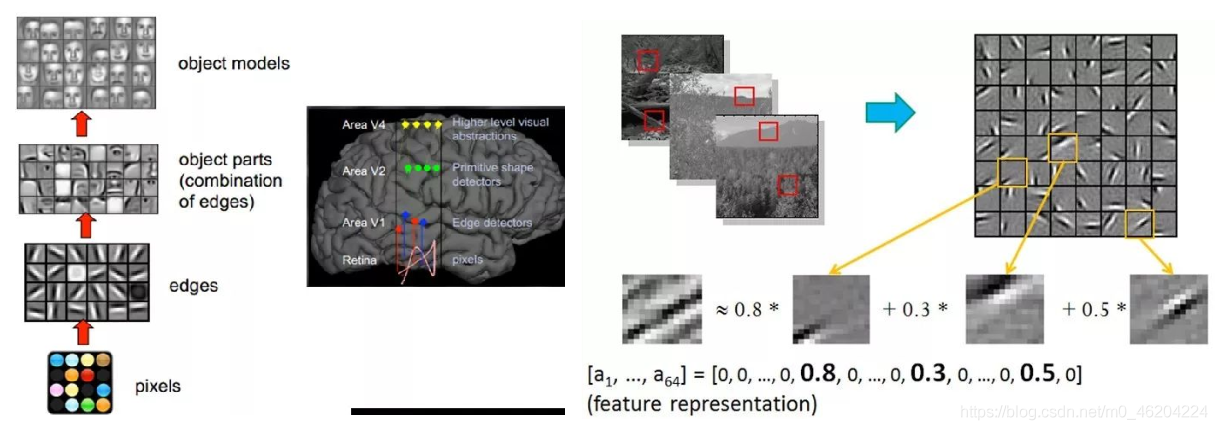
神经网络的组成
单个神经元的构成
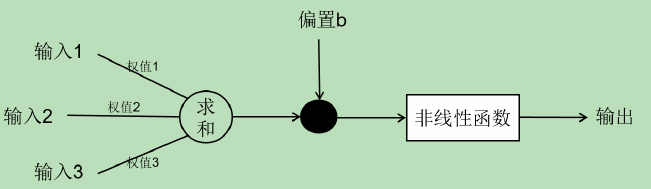
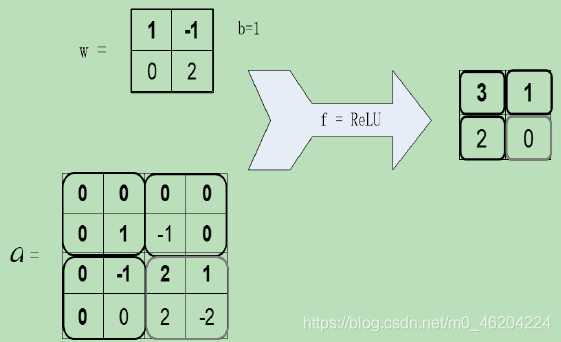
一个神经元接收多方输入的特征值(拟合神经元细胞),然后分别对特征值进行相应的加权求和,以及加上偏置量,最后通过非线性函数变换得到输出结果。多个简单的神经元之间相互连接就组成了一套完整的神经网络系统。
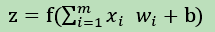
由于输入的特征包含许多干扰因素,所以我们将低维空间映射到高维空间,将线性不可变的部分变成线性可分(即激活函数的方式)降低干扰因素。为了降低无关因素所对应的权值和增大具有差异性特征的权值,我们根据输出结果计算误差,反向修改各个参数,尽量降低甚至排除无关因素或是噪音对识别结果造成的影响。
卷积层
卷积层:主要功能是对输入的图像进行特征提取和整合
- 卷积层的多少就会得到不同的特征
low/high-level feature map:即低阶/高阶特征。这是随着卷积网络的加深对不同深度的 feature map的取名。低阶特征可以理解为颜色、边缘等特征,就好比是一个图片中车的轮廓。高阶特征可以理解为是更加抽象的特征,相当于更加细化的,比如说车中车轮,以及车轮中的车胎等。而通过卷积网络深度的增加,提取到的最后的高阶特征就是组成元素的基本组成单位:比如点、线、弧等。而最后的全连接层的目的其实就是进行这些高阶特征的特征组合。 - 对于使用梯度下降,反向传播的描述
由于每次面对识别图像的不确定性,我们不能对参数进行指定性的初始化,只能采取随机生成的方式(梯度下降时,随机初始化参数)。同样,卷积核取多大值以及梯度下降算法选择怎样的起始点都是不确定的。要想修改参数,我们需要用 BP 算法不断进行反向迭代。伴随着迭代次数的不断增加梯度下降算法会逐渐减小,网络模型慢慢的达到最优化的状态,这也意味着一个高效的卷积神经网络就此生成了。因为神经网络每次训练的参数都是随机生成而不是指定的,产生最优网络模型时的迭代次数也不是一个定值,需要进行大量的实验,从而确定迭代次数的值使得网络模型性能最优。由于迭代次数是不确定的,这就给问题的解决带来很多障碍。
池化层
最大池化:其实就是降低维度,提取图像的主要特征纹理信息。
平均池化:取一个区域的平均值,用来保留图像的背景信息。
- 池化层(pooling layer)和卷积层之间是紧密相连的,一般卷积层之后会紧跟一个池化层。池化层的本质是一种形式的降采样,本身并不会改变三维矩阵的深度。池化层可以有效的缩减数据空间的大小,减小参数的运算量。最大池化层(max pooling)和平均池化层(average pooling)是常用的池化操作。
池化层不仅可以加快计算速度而且可以防止过拟合。池化层的过滤器(卷积核)是需要人工进行设定的,我们需要人工设置过滤器的尺寸、移动的步长和填充方式等 。Pool1 选用的最大池化,可以减小卷积层参数误差所造成的估计均值的偏移,更多的保留纹理信息。经过多轮卷积之后,Pool5 中选用平均池化,可以减小领域大小受限造成的估计值方差增大,更多的保留图像的背景信息。
1优点++2存在问题++GAP - Global Average Pooling
主要是用来解决全连接的问题,其主要是是将最后一层的特征图进行整张图的一个均值池化,每个通道压缩成一个实数(特征点),将这些特征点组成最后的特征向量,最后进行softmax中进行计算, 这样计算的话,也就是用GAP代替了原来的FC(红绿线压缩时会丢失空间信息),global average pooling层是没有参数的,可以减少过拟合,也可保留一定的空间信息。
虽然全连接层的删除使得模型变得更加稳定,但是却大大降低了收敛速度。
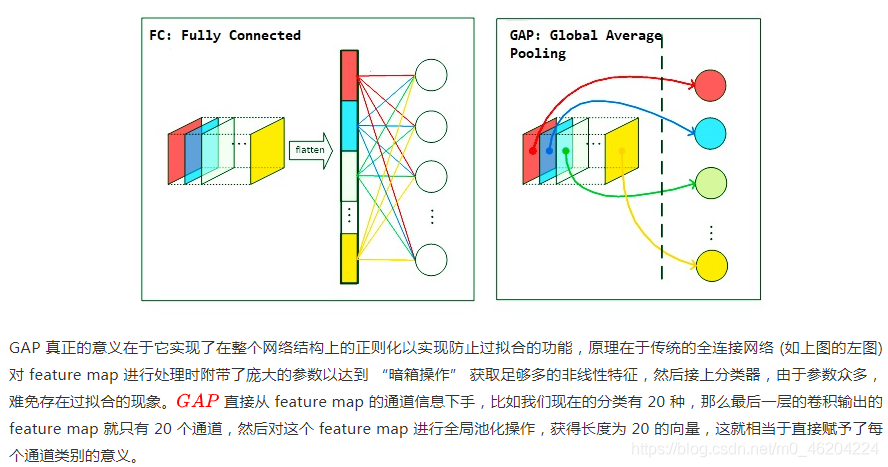
- GAP和GMP—全局平均池化和全局最大池化
GAP和GMP都是将参数的数量进行缩减,这样一方面可以避免过拟合,另一方面这也更符合CNN的工作结构,把每个feature map和类别输出进行了关联,而不是feature map的整合直接和类别输出进行关联。
差别在于,GMP只取每个feature map中的最重要的region,这样会导致,一个feature map中哪怕只有一个region是和某个类相关的,这个feature map都会对最终的预测产生很大的影响。而GAP则是每个region都进行了考虑,这样可以保证不会被一两个很特殊的region干扰。 GAP1++GAP2++可能导致特征不稳定+GAP强 - 《Learning Deep Features for Discriminative Localization》+2
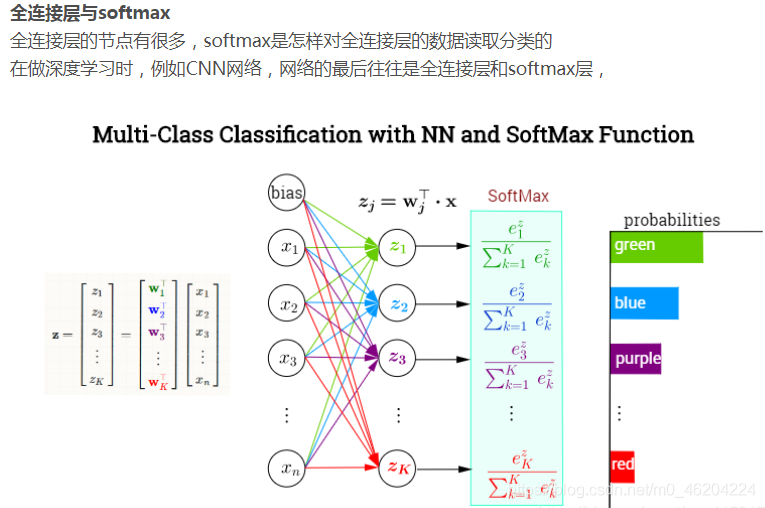
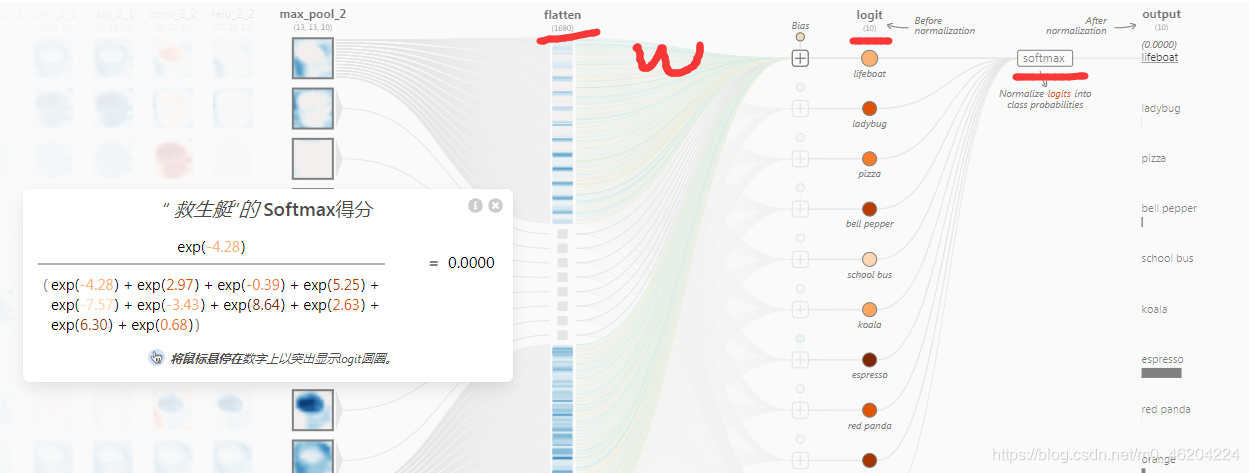
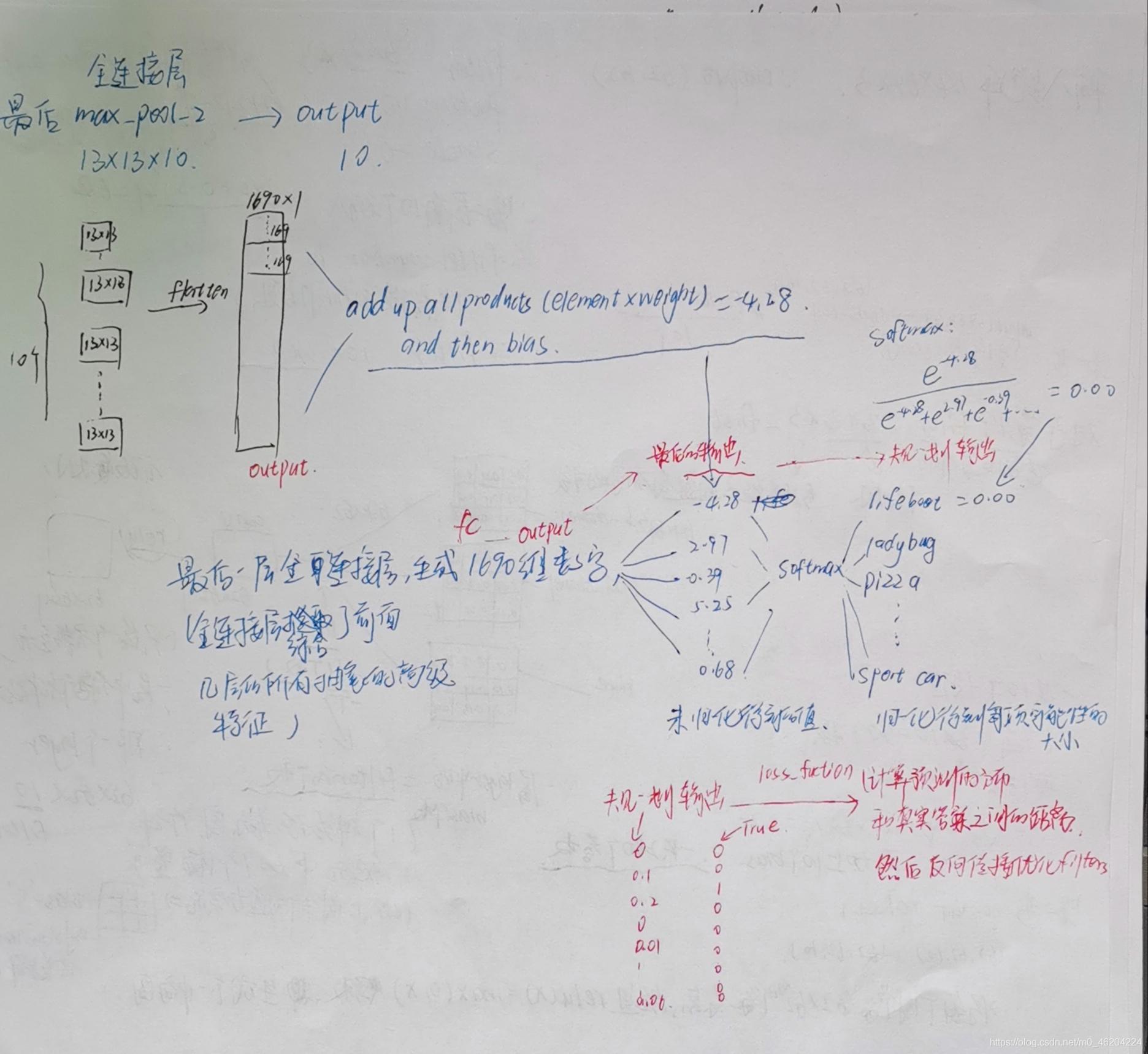
全连接层
FC层:在进行信息整合的过程中,会丢失空间信息
C5 层和 F6 层都是全连接层,在样本空间中映射前面池化层和卷积层学习到的特征。全连接层的主要作用是将学到的“分布式特征表示”映射到样本标记空间。全连接层的神经元与其上一层的所有神经元进行全连接,全连接层在整个卷积神经网络整合最具有区分性的信息,整个网络模型中最后一层的全连接层的输出一般会被输入到 softmax 层对特征进行分类。我们可以将卷积层和池化层看成自动图像特征提取的过程。在特征提取完成之后,仍然需要使用全连接层来完成分类任务。
输出层
我们一般认为它是用来感知隐藏层的,通常被视为隐藏层上的一个感知器,主要用来识别输出的结果。根据分类方式的不同分为二分类和多分类,分别对应采用的分类器为 Logistic Regression 和 Softmax Regression 的分类器。
损失函数
损失函数:约束网络,让网络向健康的方向发展,提取出更好的特征
描述了你的真实值和预测值不一致的程度。如何判断一个输出向量和期望的向量的接近程度,交叉熵(cross entropy)是分类问题中使用比较广的一种损失函数。它描述了两个概率分布之间的距离问题,是常用的评判方法之一。 当我们的样本类别较少时,可以使用交叉熵来训练网络,但是当样本类别较大时,比如判断两个行人是否为同一个人,标签集较大,Triplet Loss就比较合适。
四种激活函数
激活函数:原本前面经过y=wx+b的神经元是线性的,经过激活函数后便引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络更符合现实情况。
加权求和是线性的,加上激活函数就是非线性的
激活函数(Activation functions)对于人工神经网络模型去学习、理解非常复杂和非线性的函数来说具有十分重要的作用,它们将非线性特性引入到我们的网络中。如果神经网络没有激活函数,那么无论神经网络有多少层,每一层输出都是上层输入的线性函数,输出始终都是输入的线性组合。这种情况就是最原始的感知机。
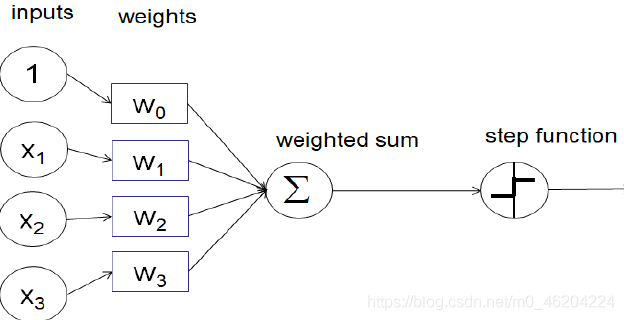
- Sigmoid
Sigmoid 函数(被称为 S 型生长曲线)是一个在生物学中常见的 S 型函数。Sigmoid 函数因其单增以及反函数单增等性质常被用作神经网络的阈值函数,可以将变量映射到 0-1 之间
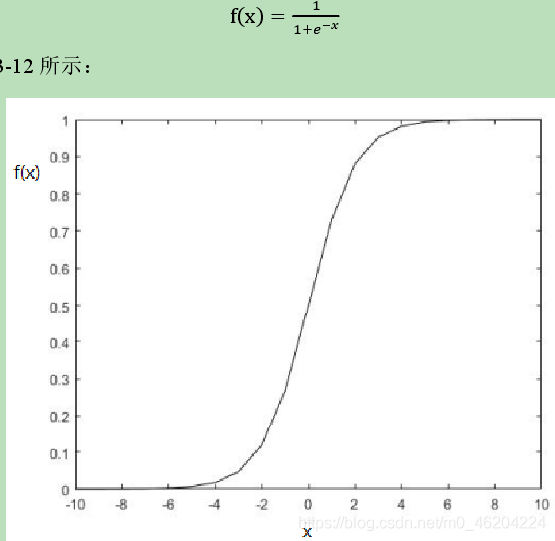
- Tanh 函数
Tanh 是双曲函数中的一个,Tanh()为双曲正切。在数学中,双曲正切“Tanh”是由基本双曲函数双曲正弦和双曲余弦推导而来。
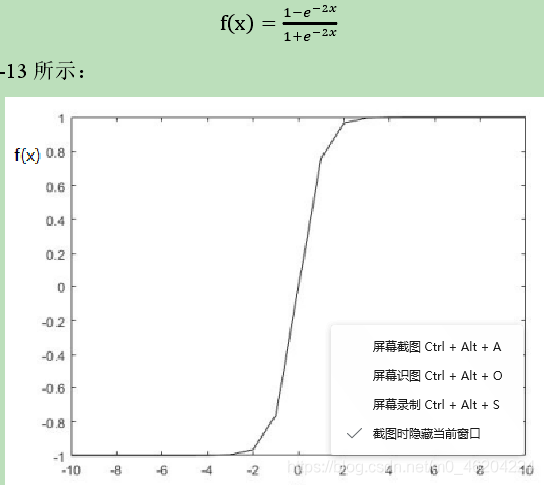
- ReLU
- LeakyReLU
以上三种常用的激活函数之后,ReLU 最为常用,也往往具备较好的性能。 LeakyReLU,它作为 ReLU 的变种,ReLU 是将所有的负值都设为零,而LeakyReLU 是给所有的负值赋予一个非零斜率。当提取特征时产生较多负值时,由于 ReLU忽略了负值所携带的特征,直接将负值设为零,对特征提取结果往往会造成一定的影响,而LeakyReLU 则是对 ReLU 的有效补充,相对而言具有较好的性能。
神经网络的发展
Imagenet比赛
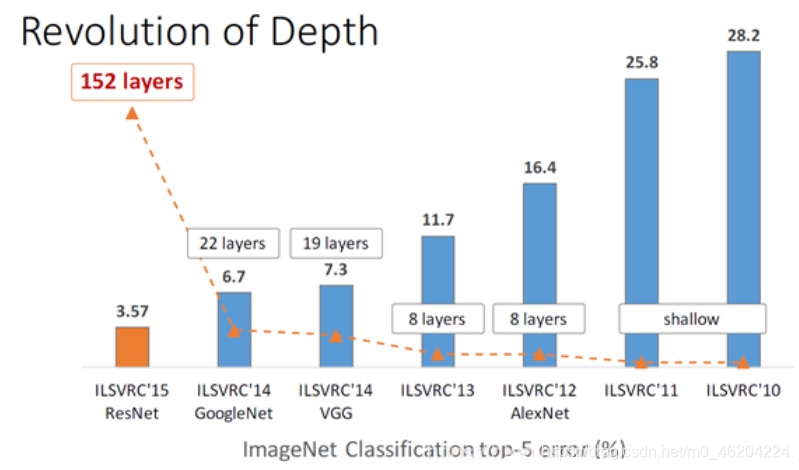
上图的Imagenet的比赛上我们可以看到我们前面讲的hintion带领的团队使用深度卷积神经网络AlexNet赢得了2012年的比赛冠军,此时网络8层,2014年的比赛中Googlenet获得冠军,而VGG获得亚军,但是在后面的商用中,VGG被使用的更广而Googlenet就没有被使用的很广,原因是Googlenet的网络复杂,他们设计的是针对这个比赛的,而VGG更通用,可以直接移植使用,稍后大家会看到他们的区别,我们发现二者网络层很接近20多层,错误率也很接近,比AlexNet的网络要好很多。15年的比赛获得冠军的就是何凯明带领的微软研究院发明的RESNET获得冠军,此时我们看到网络层数达到惊人的152层,同时错误率也创下了惊人的3.57记录。
参考:深度残差网络详解ResNet
1. 1998—LeNet-5
最早有最具代表性的卷积神经网络模型非 LeNet-5 莫属了,LeNet-5不仅给人们对卷积神经网络的认识提供了便捷而且对卷积神经网络的发展起到了巨大的推动作用。
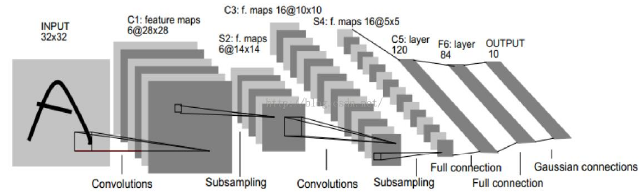
2. 2012—AlexNet
AlexNet是 2012 年 ImageNet 竞赛冠军获得者 Hinton 和他的学生 Alex Krizhevsky 设计的,AlexNet 将 LeNet 的思想发扬光大,把 CNN 的基本原理应用到了很深很宽的网络中,使用ReLU 作为 CNN 的激活函数,成功解决了 Sigmoid 在网络较深时的梯度弥散问题;通过训练时使用 Dropout 随机忽略一部分神经元,避免了神经网络模型过拟合的问题;利用 GPU 强大的并行计算能力,使用 CUDA 加速深度卷积神经网络的训练,大大加快了训练速度。
3. 2013—OverFeat
2013 年,LeNet-5 的发明者 Lecun 基于 AlexNet 提出了 OverFeat,提出了学习边框的概念。
4. 2014—VGG
2014 年,英国牛津大学的 VGG模型选用了小卷积核,将卷积核全部替换成了 3×3,相比于 AlexNet3×3 的池化核,VGG 全部选用 2×2 的池化核,取得了不俗的成绩。该网络结构越来越倾向于构建更多的层数,但是伴随着层数的增多往往会导致计算效率降低。
在赢得其中一届ImageNet比赛里VGG网络的文章中,他最大的贡献并不是VGG网络本身,而是他对于卷积叠加的一个巧妙观察。7 x 7 的卷积层的正则等效于 3 个 3 x 3 的卷积层的叠加。而这样的设计不仅可以大幅度的减少参数,其本身带有正则性质的 convolution map 能够更容易学一个 generlisable, expressive feature space。这也是现在绝大部分基于卷积的深层网络都在用小卷积核的原因。
5. 2015— ResNet
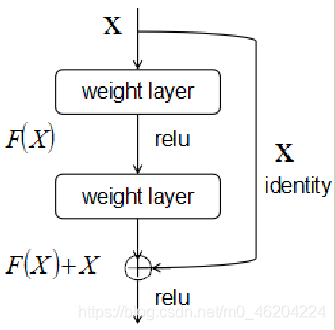
深度网络难以训练的原因在于直接拟合一个潜在的恒等映射函数 H(x)=x。因此,将网络设计为 H(x)=F(x)+x 的方式,如上图所示。然后通过恒等变换将公式变换为一个残差函
数 F(x)= H(x)-x,令 F(x)=0,则形成了 H(x)=x 的恒等映射函数,通过该方式可以大大降低拟合残差的难度。
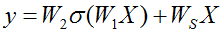
F(x)+x 表示逐元素相加,相加之前需要通过线性映射保证两个元素具有相同的维度,Ws为一个线性变换
-
RestNet 解决的问题
深度卷积神经网络的出现和使用为图像分类带来了巨大的突破。其中网络的深度是非常重要的参数,以人们在不断的探索更加深层次的网络模型。
然而,更加深层次有效的网络模型并非是多个层次的简单逻辑堆积,同时由于全连接网络或传统卷积网络在消息传递过程中所产生的信息丢失、损耗以及出现梯度消息/爆炸等现象,导致深度卷积神经网络的网络层次无法得到准确和有效的训练。在网络训练过程中并非网络层次越深越好,过度的拟合会提高训练的错误概率,实验结果证明随着网络深度的不断增加,其准确度就会随之达到饱和,然后出现断崖式下降的现象。 -
ResNet则有效的解决了层数的增多往往会导致计算效率降低这个问题,使得较多的层数下的网络依然可以
保持较好的性能和识别效率。网络采用了 shortcut 或者 skip connections 的结构(即通过直连通道的方式将输入直接转接到输出)同时 ResNet 网络具备更加优秀的的推广性,甚至可以直接用到 InceptionNet 网络中。 -
ResNet 网络通过将输入的消息直接输出到输出层的方式保证了信息的完整性,同时使得网络学习只关注输入和输出之间的差别从而简化学习的目标和难度。
-
ResNet 模块的使用主要有以下两种方式
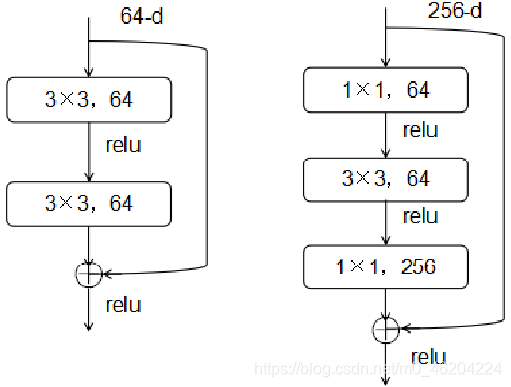
一种 bottleneck 的结构块来代替常规的 Residual block,它像 Inception 网络那样通过使用1×1 卷积来巧妙的缩减或扩张 feature map 维度从而使得我们的 3×3 卷积的 filters 数目不受外界即上一层输入的影响,自然它的输出也不会影响下一层的 module。 -
ResNet-50
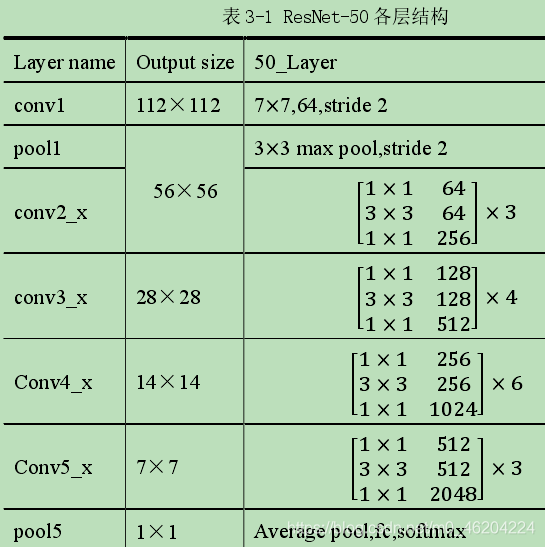
残差学习结构采用瓶颈结构(一个瓶颈结构由三个卷积层组成),如上表 所示,因此首端和末端采用 1×1 的卷积核用来削减和恢复维度,中间的卷积层采用 3×3 的卷积核。相比于由两层卷积核为 3×3 的卷积层组成的残差学习结构,该结构有效的减少了参数量和计算复杂度,同时也可以增加结构的数量,网络深度得以增加。
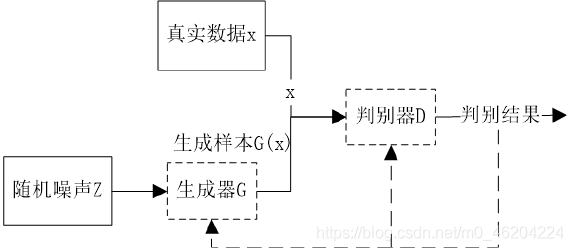
6. 2018—GAN 生成式对抗网络
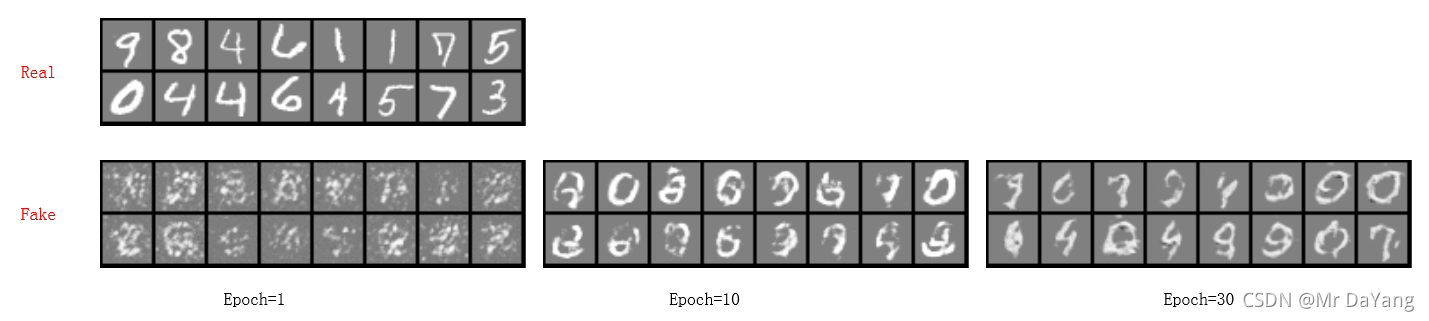
GAN 主要包括了两个部分,即生成器 generator和判别器 discriminator,主要是通过两个网络的相互对抗来达到最好的效果。生成器主要任务是学习真实图像分布,生成与原图片相似度高的图片,来让判别器通过。判别器需要对接受的图片进行真假判断,最终判别器无法识别出生成器生成的图片。博弈双方不断地进行学习、对抗、再学习,最终两个网络完成拟合。通过对于给定图像的预测为真的概率基本接近百分之五十来估测数据样本特征的布局。
例
生成器生成的10张照片,判别器判断出9张有误,所以说生成器的性能不好,在生成器性能不断提升情况下,判别器只能判出3张有误,所以判别器也要提升自己,就这样一直互相攀比着上升。最后进化后的两网络再次较真,判别器发现10个有5个有问题,就这样不分胜负的完成拟合。
最终判别器能够达到无法正确判别数据来源,则可以认为卷积神经网络完成拟合,同时生成器 G 完成了对真实数据的分布的学习。
原理方法
模型的训练一般采用固定参数法,即先固定生成器或者判别器,然后对另外一个进行不断优化使得其准确率达到最优状态,然后再固定判别器,从而对生成器进行优化以至其达到最优,有且仅当𝑃_data=𝑃_g时达到全局最优解。最终完成生成器和判别器的优化工作。
6.1描述无聊,直接上项目
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
from torchvision.utils import save_image
import os
if not os.path.exists('dc_img'):
os.mkdir('dc_img')
def to_img(x):
out = 0.5 * (x + 1)
out = out.clamp(0, 1)
out = out.view(-1, 1, 28, 28)
return out
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1, 32, 5, padding=2), # batch, 32, 28, 28
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2, True),
nn.AvgPool2d(2, stride=2), # batch, 32, 14, 14
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, 5, padding=2), # batch, 64, 14, 14
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, True),
nn.AvgPool2d(2, stride=2) # batch, 64, 7, 7
)
self.fc = nn.Sequential(
nn.Linear(64 * 7 * 7, 1024),
nn.LeakyReLU(0.2, True),
nn.Linear(1024, 1),
nn.Sigmoid()
)
def forward(self, x):
'''
x: batch, width, height, channel=1
'''
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
class generator(nn.Module):
def __init__(self, input_size, num_feature):
super(generator, self).__init__()
self.fc = nn.Linear(input_size, num_feature) # batch, 3136=1x56x56
self.br = nn.Sequential(
nn.BatchNorm2d(1),
nn.ReLU(True)
)
self.downsample1 = nn.Sequential(
nn.Conv2d(1, 50, 3, stride=1, padding=1), # batch, 50, 56, 56
nn.BatchNorm2d(50),
nn.ReLU(True)
)
self.downsample2 = nn.Sequential(
nn.Conv2d(50, 25, 3, stride=1, padding=1), # batch, 25, 56, 56
nn.BatchNorm2d(25),
nn.ReLU(True)
)
self.downsample3 = nn.Sequential(
nn.Conv2d(25, 1, 2, stride=2), # batch, 1, 28, 28
nn.Tanh()
)
def forward(self, x):
x = self.fc(x)
x = x.view(x.size(0), 1, 56, 56)
x = self.br(x)
x = self.downsample1(x)
x = self.downsample2(x)
x = self.downsample3(x)
return x
if __name__ == '__main__':
batch_size = 128
num_epoch = 60
z_dimension = 100 # noise dimension
print_loss_fre=5
img_transform = transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize(mean=0.5,std=0.5)
])
mnist = datasets.MNIST('./data', transform=img_transform,train=False)
# print(mnist)
dataloader = DataLoader(mnist, batch_size=batch_size, shuffle=True,
num_workers=0)
D = discriminator() # discriminator model
G = generator(z_dimension, 3136) # generator model
criterion = nn.BCELoss() # binary cross entropy
d_optimizer = torch.optim.Adam(D.parameters(), lr=0.0003)
g_optimizer = torch.optim.Adam(G.parameters(), lr=0.0003)
# train
for epoch in range(num_epoch):
for i, (img, _) in enumerate(dataloader):#img torch.Size([128, 1, 28, 28])
num_img = img.size(0)
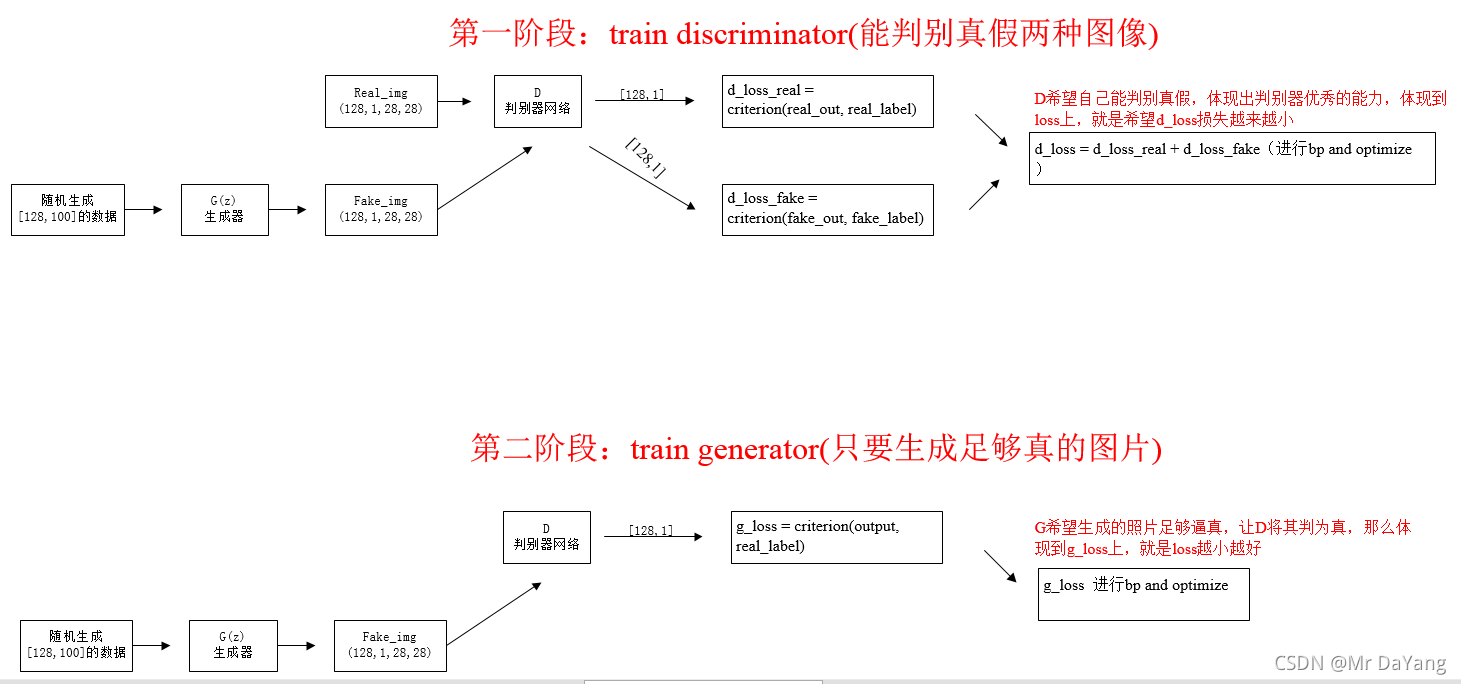
# =================train discriminator
real_img = Variable(img)#torch.Size([128, 1, 28, 28])
real_label = Variable(torch.ones(num_img))#128 全1
fake_label = Variable(torch.zeros(num_img))#128 全0
# compute loss of real_img
real_out = D(real_img)#torch.Size([128, 1])每个图片都有一个判别的结果
d_loss_real = criterion(real_out, real_label)#得到一个L2数值
real_scores = real_out # closer to 1 means better,这样loss最小
# compute loss of fake_img
z = Variable(torch.randn(num_img, z_dimension))#torch.Size([128, 100])一个噪声数据
fake_img = G(z)#torch.Size([128, 1, 28, 28])将噪声数据变成一张假的图片
fake_out = D(fake_img)#torch.Size([128, 1])对于这个假的图片,D进行判断,并得出结果
d_loss_fake = criterion(fake_out, fake_label)#与标签对比,生成loss
fake_scores = fake_out # closer to 0 means better,这样损失最下
# bp and optimize
d_loss = d_loss_real + d_loss_fake#损失是公正的,希望其越来越小,
d_optimizer.zero_grad()# 归0梯度
d_loss.backward()# 反向传播
d_optimizer.step()# 更新生成网络的参数
# ===============train generator
# compute loss of fake_img
z = Variable(torch.randn(num_img, z_dimension))#torch.Size([128, 100])
fake_img = G(z)#torch.Size([128, 1, 28, 28])生成假照片
output = D(fake_img)#torch.Size([128, 1])
g_loss = criterion(output, real_label)#生成器希望生成的照片也是真的,即loss越小越好
# bp and optimize
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
if (i + 1) % print_loss_fre == 0:
print('Epoch [{}/{}], d_loss: {:.6f}, '
'D 标准=1: {:.3f}, D 标准=0: {:.3f},g_loss: {:.6f}'
.format(epoch, num_epoch, d_loss.data[0],
real_scores.data.mean(), fake_scores.data.mean(),g_loss.data[0],))
if epoch == num_epoch:
real_images = to_img(real_img.cpu().data)
save_image(real_images, 'dc_img/real_images.png')
fake_images = to_img(fake_img.cpu().data)
save_image(fake_images, './dc_img/fake_images-{}.png'.format(epoch + 1))
# torch.save(G.state_dict(), './generator.pth')
# torch.save(D.state_dict(), './discriminator.pth')
7. DCGAN深度卷积生成对抗网络
DCGAN :结合了GAN 的优点和卷积层强大的特征提取能力。
深度卷积生成对抗网络(Deep Convolutional Generative Adversarial Networks,DCGAN)是在 GAN 基础上的改进,它利用深度卷积网络进生成对抗网络的建模,同时通过判别网络提取的图片特征具有普适性,不管是简单场景的还是复杂场景下图片的识别与分类均能有较好的适应性高于 GAN 的效果。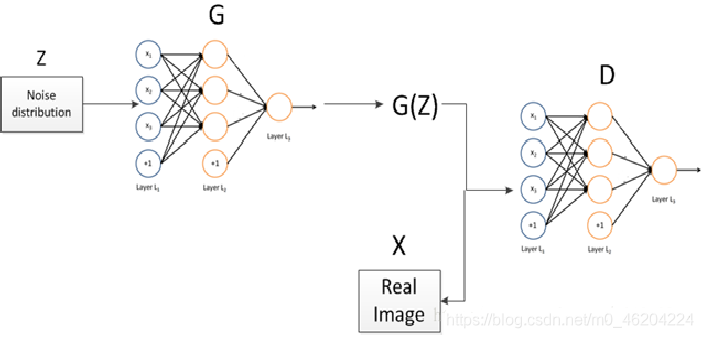

网络结构特点
1)删除网络中的全连接层;2)将批归一化层引入到生成模型和判别模型中;3)使用相应步长的卷积层来代替卷积网络中的池化层;4)在判别模型中采用 LeakyReLU 激活函
数;5)在生成模型中采用 ReLU 激活函数。与一般的生成对抗网路相比,深度卷积神经网络拥有更优的性能和更加强大的生命力,而且相比较而言更加容易训练,模型也相对更加稳定,适用的范围也更加多元化。
传统 GAN 比较,DCGAN 具有以下优点
1)将 Four fractionally-strided convolution 应用于生成器模型中,实现图片的生成过程,将随机噪声生成成为图片,在判别器模型中使用带步幅的卷积代替池化层。
2)该网络模型中加入了 Batch Normalization 层,使用了批量归一化方法,除了生成器模型的输出层和相对应的判别器模型的输入层。
3)使用卷积层连接生成器和判别器的输入层和输出层,删除了全连接层。虽然全连接层的删除使得模型变得更加稳定,但是却大大降低了收敛速度。
4)Leaky ReLU(Leaky rectified linear unit)被使用于判别器的所有层,Tanh(双切正切函数)激活函数被使用于生成器的输出层,ReLU(Rectified linear unit)则被使用于这些之外的所有层。

声明:本文非商业使用,侵权必删!