一文讲清楚检索增强生成(RAG)
文章目录
推荐阅读 How do domain-specific chatbots work? An Overview of Retrieval Augmented Generation (RAG),本文是该文章的中译版。
有一个名为LangChain的流行开源库,它可以创建聊天机器人,其中包括用 3 3 3 行代码对任何网站/文档进行问答。这是LangChain文档中的一个示例。
from langchain.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("http://www.paulgraham.com/greatwork.html")
index = VectorstoreIndexCreator().from_loaders([loader])
index.query("What should I work on?")
它输出特定于Paul Graham文章的答案:
The work you choose should ideally have three qualities: it should be something you have a natural aptitude for, something you have a deep interest in, and something that offers scope to do great work. If you’re unsure, you could start by working on your own projects that seem excitingly ambitious to you. It’s also beneficial to be curious, try lots of things, meet lots of people, read lots of books, and ask lots of questions. When in doubt, optimize for interestingness. It’s okay to guess and be wrong sometimes, as this can lead to discovering what you’re truly good at or interested in.
注意:如果您有兴趣,可以尝试根据Paul Graham的文章构建的聊天机器人。
第一次运行它时感觉就像纯粹的魔法。这到底是如何工作的?
答案是一个称为 检索增强生成(Retrieval Augmented Generation) 的过程,简称 RAG。这是一个非常简单的概念,但其实现细节也具有令人难以置信的深度。
这篇文章将提供RAG的深层概述。我们将从正在发生的事情的整体工作流程开始,然后放大所有单独的部分。到最后,您应该对这三行神奇代码的工作原理以及创建这些问答机器人所涉及的所有原理有一个深入的了解。
如果您是一名尝试构建这样的机器人的开发人员,您将学到您可以调整哪些旋钮以及如何调整它们。如果您是一名非开发人员,希望在数据集上使用AI工具,您将获得有助于您充分利用这些工具的知识。而且,如果您只是一个好奇的人,您有望对一些正在颠覆我们生活的技术了解一两件事。
让我们深入了解一下。
什么是检索增强生成?
检索增强生成是用从其他地方检索到的附加信息来补充用户输入到ChatGPT等大语言模型(large language model, LLM)的过程。然后,LLM可以使用该信息来增强其生成的回复。
下图显示了它在实践中的工作原理:
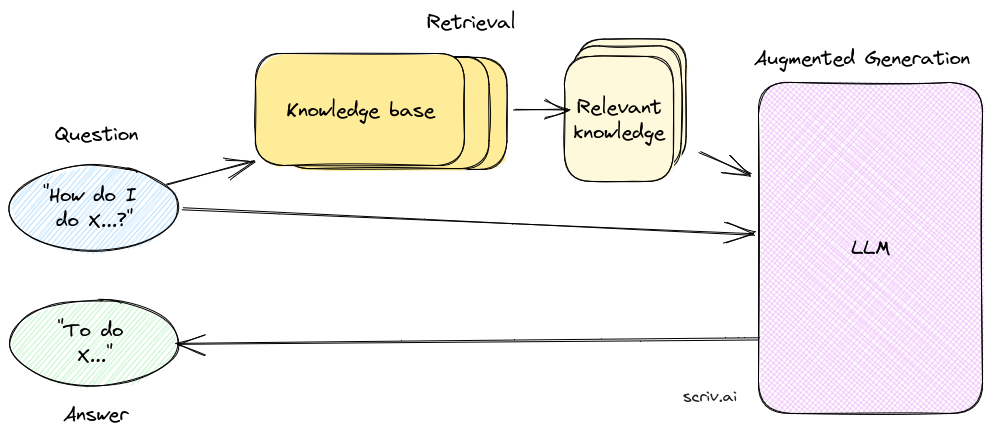
它从用户的问题开始。例如 How do I do <something>?
首先发生的是检索步骤。这是接受用户问题并从知识库中搜索可能回答该问题的最相关内容的过程。检索步骤是迄今为止RAG链中最重要、最复杂的部分。但现在,可以仅仅将其想象成一个知道如何提取与用户查询相关的最佳相关信息块的黑匣子。
难道我们不能只给LLM整个知识库吗?
您可能想知道为什么我们费心检索而不是只将整个知识库发送给LLM。原因之一是模型对一次可以消耗的文本量有内置的限制(尽管这些限制正在迅速增加)。第二个原因是成本——发送大量文本会变得相当昂贵。最后,有证据表明发送少量相关信息会得到更好的答案。
一旦我们从知识库中获取了相关信息,我们就会将其与用户的问题一起发送到大语言模型(LLM)。然后,LLM(最常见的是ChatGPT)“读取”所提供的信息并回答问题。这是增强生成步骤。
非常简单,对吧?
逆向工作:为大语言模型提供额外的知识来回答问题
我们将从最后一步开始:答案生成(answer generation)。也就是说,假设我们已经从知识库中提取了我们认为可以回答问题的相关信息。我们如何使用它来生成答案?
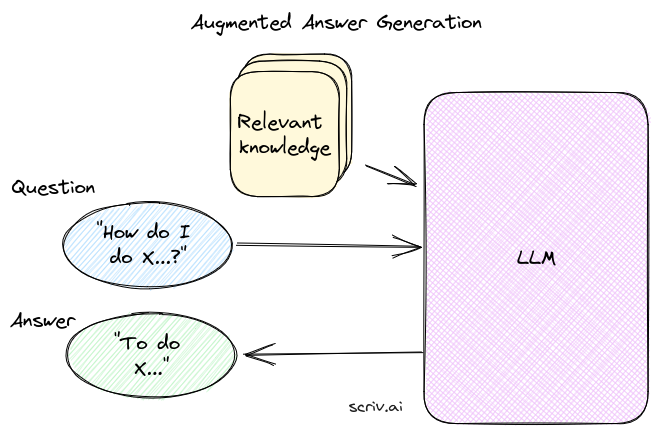
这个过程可能感觉像黑魔法,但在幕后它只是一个语言模型。因此,从广义上讲,答案是“只需询问LLM即可”。我们如何让大语言模型来做这样的事情?
我们将使用ChatGPT作为示例。就像常规ChatGPT一样,这一切都取决于提示和消息。
通过系统提示给出LLM自定义指令
第一个组成部分是系统提示(system prompt)。系统提示给予语言模型整体指导。对于ChatGPT,系统提示类似于 You are a helpful assistant.。
在这种情况下,我们希望它执行更具体的操作。而且,由于它是一个语言模型,我们可以告诉它我们想要它做什么。下面是一个简短的系统提示示例,为LLM提供了更详细的说明:
You are a Knowledge Bot. You will be given the extracted parts of a knowledge base (labeled with DOCUMENT) and a question. Answer the question using information from the knowledge base.
我们基本上是在说 Hey AI, we’re gonna give you some stuff to read. Read it and then answer our question, k? Thx.,而且,因为AI非常善于遵循我们的指示,所以它有点……有效。
为LLM提供特定的知识来源
接下来,我们需要为AI提供阅读材料。再说一遍——最新的AI真的很擅长解决问题。但是,我们可以通过一些结构和格式来帮助它。
以下是您可以用来将文档传递给LLM的示例格式:
------------ DOCUMENT 1 -------------
This document describes the blah blah blah...
------------ DOCUMENT 2 -------------
This document is another example of using x, y and z...
------------ DOCUMENT 3 -------------
[more documents here...]
您需要所有这些格式吗?可能不是,但是让事情尽可能明确是件好事。您还可以使用机器可读的格式,例如JSON或YAML。或者,如果您感觉很活跃,您可以将所有内容转储到一大堆文本中。但是,在更高级的用例中,保持一些一致的格式变得很重要,例如,如果您希望LLM引用其来源。
一旦我们格式化了文档,我们只需将其作为普通聊天消息发送给LLM。请记住,在系统提示中我们告诉它我们要给它一些文件,这就是我们在这里所做的一切。
将所有内容放在一起并提出问题
一旦我们收到系统提示和文档消息,我们只需将用户的问题与它们一起发送给大语言模型。以下是使用 OpenAI ChatCompletion API 在 Python 代码中的样子:
openai_response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "system",
"content": get_system_prompt(), # the system prompt as per above
},
{
"role": "system",
"content": get_sources_prompt(), # the formatted documents as per above
},
{
"role": "user",
"content": user_question, # the question we want to answer
},
],
)
就是这样!一个自定义系统提示、两条消息,您就可以得到特定于上下文的答案!
这是一个简单的用例,可以对其进行扩展和改进。我们还没有做的一件事是告诉AI如果在来源中找不到答案该怎么办。我们可以将这些指令添加到系统提示中,通常是告诉它拒绝回答,或者使用它的常识,具体取决于您的机器人所需的行为。您还可以让大语言模型引用其用于回答问题的具体来源。我们将在以后的帖子中讨论这些策略,但现在,这是答案生成的基础知识。
简单的部分已经完成,是时候回到我们跳过的那个黑匣子了……
检索步骤:从您的知识库中获取正确的信息
上面我们假设我们有正确的知识片段可以发送给大语言模型。但我们如何从用户的问题中真正得到这些呢?这便是检索步骤,它是任何“与数据聊天”系统中基础设施的核心部分。
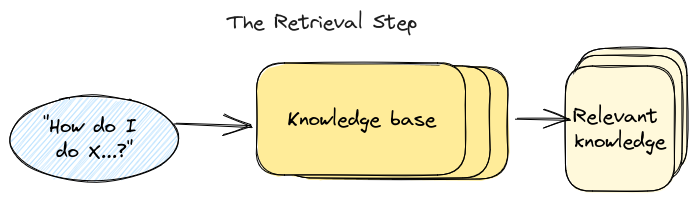
从本质上讲,检索是一种搜索操作——我们希望根据用户的输入查找最相关的信息。就像搜索一样,有两个主要部分:
- 索引(Indexing):将您的知识库变成可以搜索/查询的内容。
- 查询(Querying):从搜索词中提取最相关的知识。
值得注意的是,任何搜索过程都可以用于检索。任何接受用户输入并返回一些结果的东西都可以工作。因此,举例来说,您可以尝试查找与用户问题相匹配的文本并将其发送给大语言模型,或者您可以通过Google搜索该问题并将最重要的结果发送出去——顺便说一句,这大约就是Bing聊天机器人的工作原理。
当今大多数RAG系统都依赖于语义搜索(semantic search),它使用AI技术的另一个核心部分:嵌入(embeddings)。在这里我们将重点关注该用例。
那么……什么是嵌入?
什么是嵌入?它们与知识检索有什么关系?
LLMs很奇怪。它们最奇怪的事情之一是没有人真正知道它们如何理解语言。嵌入是这个故事的重要组成部分。
如果你问一个人如何将单词转化为意义,他们可能会摸索并说出一些模糊且自我指涉的内容,例如“因为我知道它们的意思”。在我们大脑深处的某个地方,有一个复杂的结构,它知道“child”和“kid”基本上是相同的,“red”和“green”都是颜色,“pleased”、“happy”和“elated”代表着相同的情绪,但程度不同。我们无法解释它是如何工作的,我们只是知道它。
语言模型对语言有类似的复杂理解,只不过,因为它们是计算机,所以它不在它们的大脑中,而是由数字组成。在大语言模型的世界中,任何人类语言都可以表示为数字向量(列表)。这个数字向量就是一个嵌入(embedding)。
LLM技术的一个关键部分是从人类的文字语言(word-language)到AI的数字语言(number-language)的翻译器(translator)。我们将这个翻译器称为“嵌入机”(embedding machine),尽管在幕后它只是一个API调用。输入人类语言,输出AI数字。
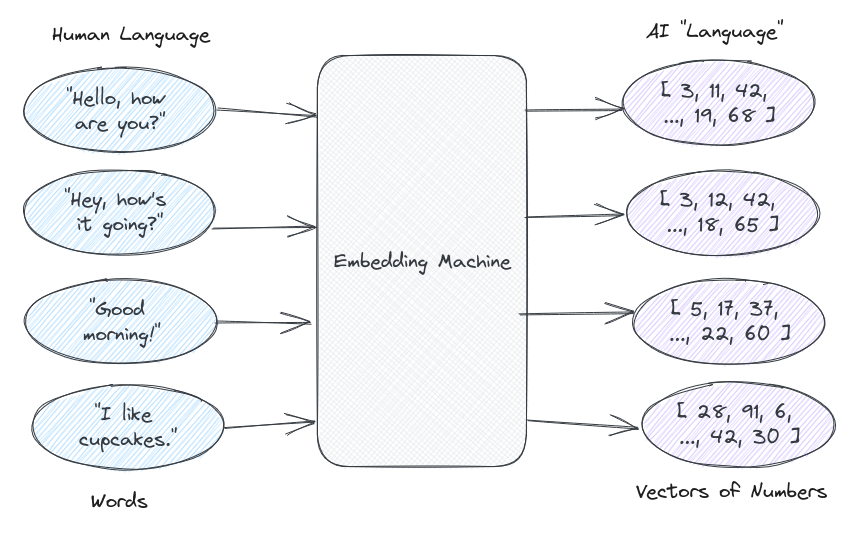
这些数字意味着什么?没有人知道!它们只对AI有意义。但是,我们所知道的是,相似的单词最终会得到相似的数字组。因为在幕后,AI使用这些数字来“阅读”和“说话”。因此,这些数字在AI语言中融入了某种神奇的理解力,即使我们无法理解它。嵌入机就是我们的翻译器。
现在,既然我们有了这些神奇的AI数字,我们就可以绘制它们。上述示例的简化图可能看起来像这样——其中轴只是人类/AI语言的一些抽象表示:
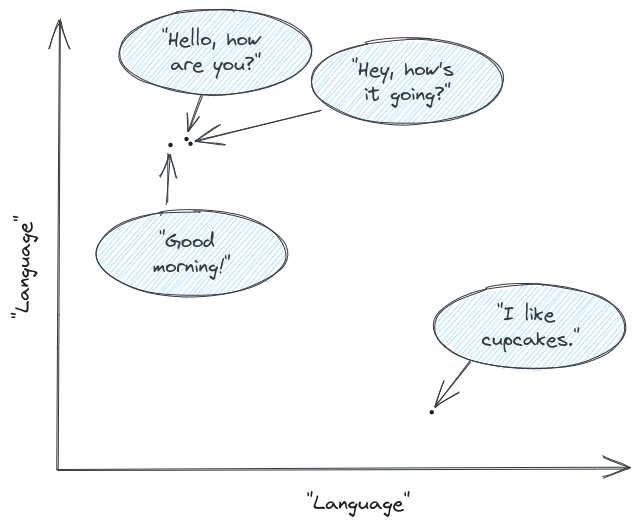
一旦我们绘制了它们,我们就可以看到,在这个假设的语言空间中,两点彼此越接近,它们就越相似。Hello, how are you? 和 Hey, how’s it going? 实际上是互相重叠的。另一种问候语 Good morning! 与这些问候语相距不远。而 I like cupcakes. 则位于一个与其他完全不同的岛屿上。
当然,你无法在二维图上表示整个人类语言,但理论是相同的。实际上,嵌入有更多的坐标(OpenAI当前使用的模型有1536个)。但您仍然可以进行基本数学计算来确定两个嵌入(两段文本)彼此之间的接近程度。
这些嵌入和确定“接近度”(closeness)是语义搜索背后的核心原则,为检索步骤提供动力。
使用嵌入找到最好的知识片段
一旦我们了解了嵌入搜索的工作原理,我们就可以构建检索步骤的高级图像。
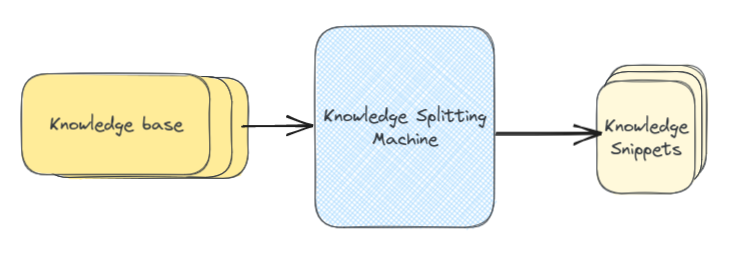
在索引方面,首先我们必须将知识库分解为文本块。这个过程本身就是一个完整的优化问题,我们接下来将介绍它,但现在假设我们知道如何去做。
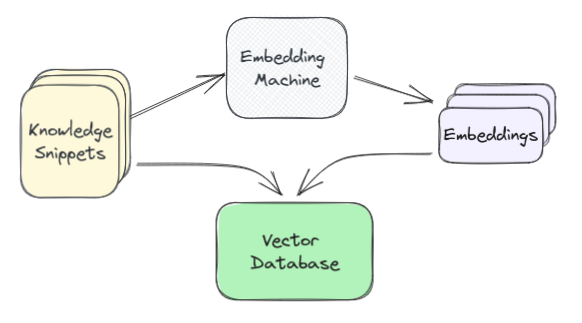
完成此操作后,我们将每个知识片段通过嵌入机(实际上是OpenAI API或类似机制)传递,并返回该文本的嵌入表示。然后,我们保存该片段以及向量数据库(vector database)中的嵌入,该数据库针对数字向量进行了优化。
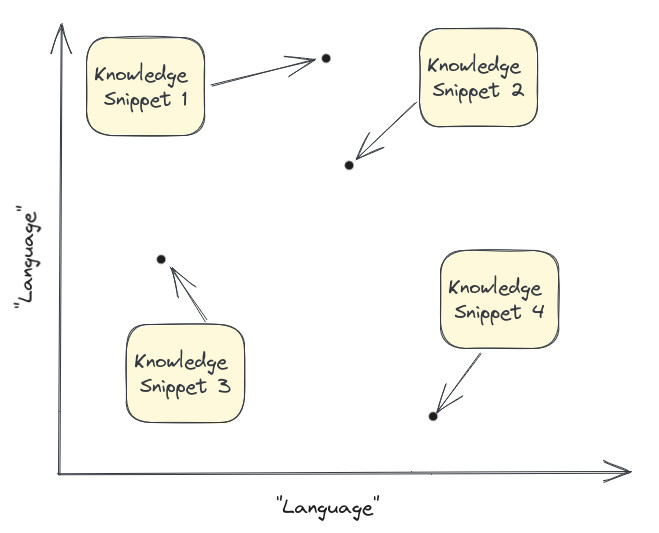
现在我们有了一个数据库,其中嵌入了我们所有的内容。从概念上讲,您可以将其视为我们整个知识库在“语言”图上的图:
一旦我们有了这个图,在查询方面,我们就会执行类似的过程。首先我们获得用户输入的嵌入:
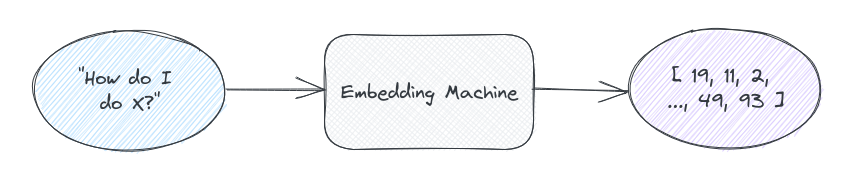
然后我们将其绘制在相同的向量空间中并找到最接近的片段(在本例中为 1 1 1 和 2 2 2):
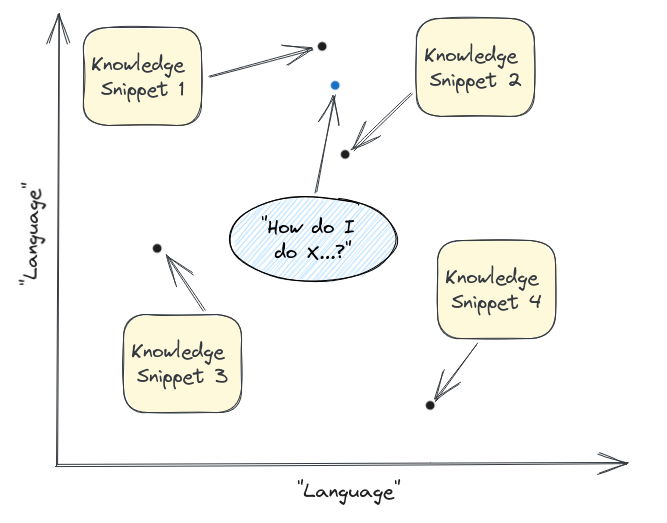
神奇的嵌入机认为这些是与所提出的问题最相关的答案,因此这些是我们提取发送给大语言模型的片段!
实际上,“最近的点是什么”这个问题是通过在我们的向量数据库中查询完成的。所以实际的过程看起来更像是这样的:
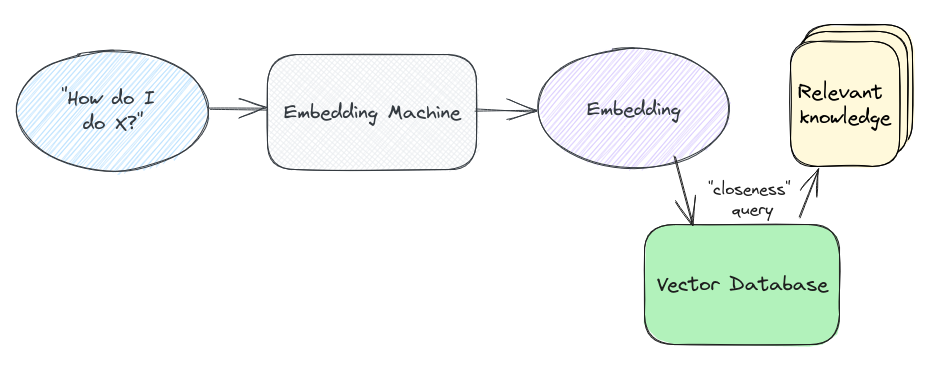
查询本身涉及一些半复杂的数学——通常使用称为余弦距离的东西,尽管还有其他计算方法。数学是您可以进入的整个空间,但超出了本文的范围,并且从实际角度来看,很大程度上可以转移到图书馆或数据库中。
回到LangChain
在我们的LangChain示例中,我们现在已经涵盖了下面这一行代码完成的所有操作。这个小函数调用隐藏了很多复杂性!
index.query("What should I work on?")
为您的知识库建立索引
好吧,我们就快完成了。我们现在了解如何使用嵌入来查找知识库中最相关的部分,将所有内容传递给大语言模型,并获取增强的答案。我们将介绍的最后一步是从您的知识库创建初始索引。换句话说,就是下面这张图中的“知识分片机”(knowledge splitting machine)。
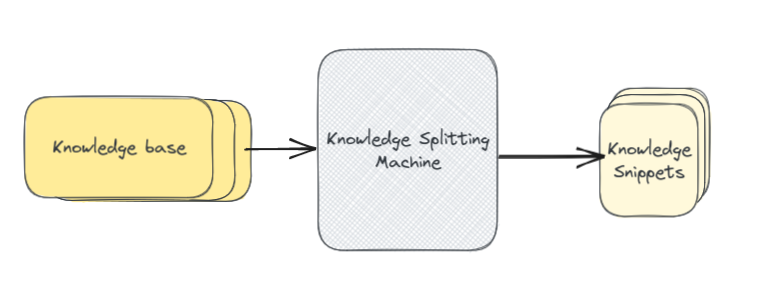
也许令人惊讶的是,索引您的知识库通常是整个事情中最困难和最重要的部分。不幸的是,它更多的是艺术而不是科学,并且涉及大量的试验和错误。总体而言,索引过程可归结为两个高级步骤。
- 加载(Loading):从通常存储的位置获取知识库的内容。
- 分片(Splitting):将知识分割成适合嵌入搜索的片段大小的块。
技术澄清
从技术上讲,“加载器”(loaders)和“分片器”(splitters)之间的区别有些随意。你可以想象一个单一的组件同时完成所有的工作,或者将加载阶段分解为多个子组件。
也就是说,“加载器”和“分片器”是LangChain中的完成方式,它们提供了基本概念之上的有用抽象。
让我们以我自己的用例为例。我想构建一个聊天机器人来回答有关我的 saas boilerplate product, SaaS Pegasus 问题。我想添加到我的知识库中的第一件事是文档站点。加载器是一个基础设施,它可以访问我的文档,找出可用的页面,然后拉取每个页面。加载程序完成后,它将输出单独的文档——网站上的每个页面都有一个文档。
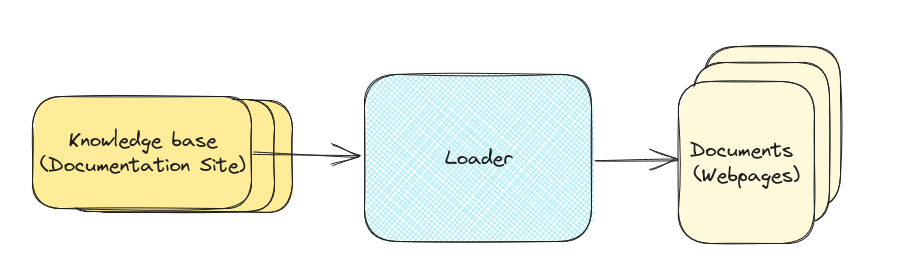
加载器内部发生了很多事情!我们需要抓取所有页面,抓取每个页面的内容,然后将HTML格式化为可用的文本。还有用于其他东西(例如PDF或Google Drive)的加载器有不同的部分。还有并行化、错误处理等等需要解决。再强调一遍,这是一个几乎无限复杂的主题,但出于本文的目的,我们将主要将其转移到一个库中。所以现在,我们再次假设我们有一个神奇的盒子,里面有一个“知识库”(knowledge base),然后出来的是单独的“文档”(documents)。
LangChain中的加载器
内置加载器是LangChain最有用的部件之一。它们提供了一系列的内置加载器,可用于从Microsoft Word文档到整个Notion站点的任何内容中提取内容。
LangChain加载器的界面与上面描述的完全相同。输入一个“知识库”,出来一系列“文档”。
从加载器中出来后,我们将获得与文档站点中每个页面相对应的文档集合。此外,理想情况下,此时额外的标记已被删除,仅保留底层结构和文本。
现在,我们可以将这些整个网页传递到我们的嵌入机并将其用作我们的知识片段。但是,每一页可能涵盖很多内容!而且,页面中的内容越多,该页面的嵌入就越“不具体”(unspecific)。这意味着我们的“接近度”搜索算法可能不太有效。
更有可能的是用户问题的主题与页面内的某些文本相匹配。这就是下图中分片的作用。通过分片,我们将任何单个文档分割成小块的、可嵌入的块,更适合搜索。
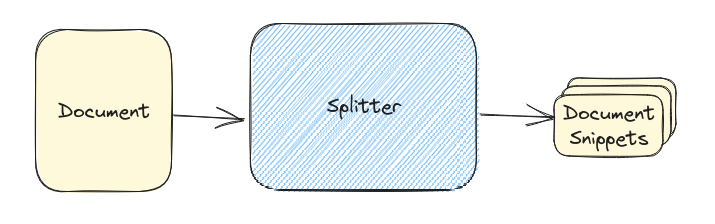
再次注意,分割文档是一门完整的艺术,包括平均片段的大小(太大,它们不能很好地匹配查询;太小,它们没有足够的有用上下文来生成答案),如何拆分内容(通常按标题,如果有的话)等等。但是,一些合理的默认值足以开始使用和完善您的数据。
LangChain中的分片器
在LangChain中,分片器属于一个更大的类别,称为文档转换器(document transformer)。除了提供各种分割文档的策略之外,他们还提供删除冗余内容、翻译、添加元数据等工具。我们在这里只关注分片器,因为它们代表了绝大多数文档转换。
一旦我们有了文档片段,我们就将它们保存到我们的向量数据库中,如上所述,我们终于完成了!
这是索引知识库的完整图片。
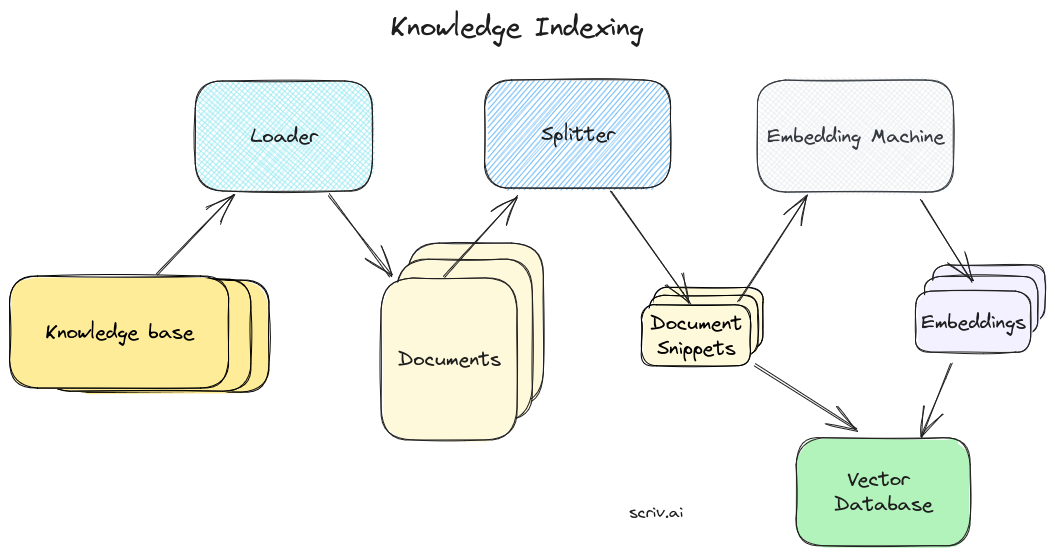
回到LangChain
在LangChain中,整个索引过程都封装在这两行代码中。首先我们初始化网站加载器并告诉它我们要使用什么内容:
loader = WebBaseLoader("http://www.paulgraham.com/greatwork.html")
然后我们从加载器构建整个索引并保存它到我们的向量数据库:
index = VectorstoreIndexCreator().from_loaders([loader])
加载(loading)、分片(splitting)、嵌入(embedding)和保存(saving)都在幕后发生。
回顾整个过程
最后,我们可以得出整个RAG工作流程。它看起来是这样的:
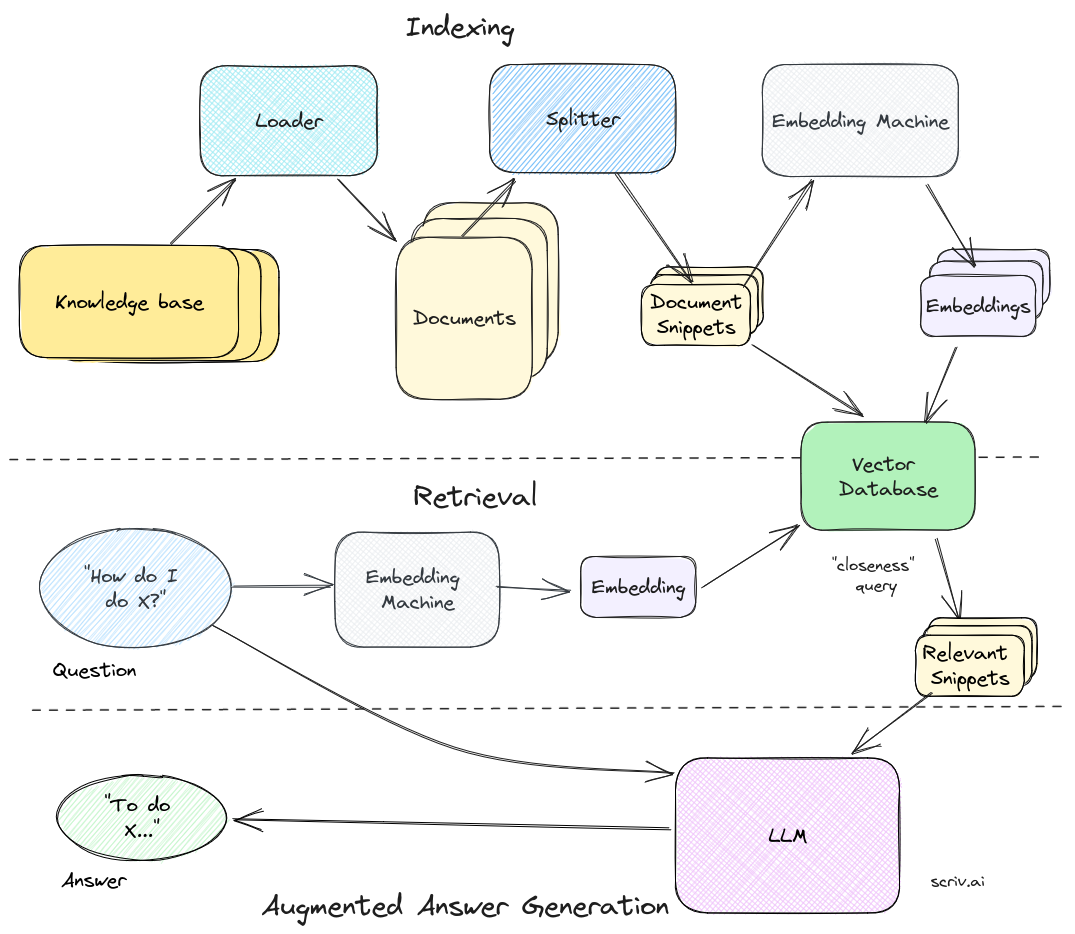
首先,我们索引我们的知识库。我们获取知识并使用加载器将其转换为单独的文档,然后使用分片器将其转换为小块或片段。一旦我们有了这些,我们就把它们传递给嵌入机,嵌入机将它们转换成可用于语义搜索的向量。我们将这些嵌入及其文本片段保存在我们的向量数据库中。
接下来是检索。它从问题开始,然后通过相同的嵌入机发送并传递到我们的向量数据库以确定最接近的匹配片段,我们将用它来回答问题。
最后,增强答案生成。我们获取知识片段,将它们与自定义系统提示和我们的问题一起格式化,最后得到我们上下文特定的答案。
哇!希望您现在对检索增强生成的工作原理有一个基本的了解。如果您想在自己的知识库上尝试一下,而不需要进行所有设置工作,请查看Scriv.ai,它可以让您在短短几分钟内构建特定领域的聊天机器人,而无需任何编码技能。
在以后的文章中,我们将扩展其中许多概念,包括可以改进此处概述的“默认”设置的所有方法。正如我所提到的,这些部分中的每一部分都有几乎无限的深度,将来我们将一次深入地研究这些部分。