开源预训练框架 MMPRETRAIN官方文档(概览、环境安装与验证、基础用户指南)
MMPretrain是全新升级的开源预训练框架。它已着手提供多个强大的预训练骨干网并支持不同的预训练策略。MMPretrain 源自著名的开源项目 MMClassification 和MMSelfSup,并开发了许多令人兴奋的新功能。目前,预训练阶段对于视觉识别至关重要。凭借丰富而强大的预训练模型,我们目前有能力改进各种下游视觉任务。
我们代码库的主要目标是成为一个易于访问且用户友好的库,并简化研究和工程。我们详细介绍了 MMPretrain 不同部分的属性和设计。
1、MMPretrain 实践路线图

为了帮助用户快速使用 MMPretrain,我们建议遵循我们为库创建的实践路线图:
(1)对于想要尝试 MMPretrain 的用户,我们建议阅读入门 部分以了解环境设置。
(2)对于基本使用,我们建议用户参考用户指南,以利用各种算法来获取预训练模型并评估其在下游任务中的性能。
(3)对于那些希望自定义自己的算法的人,我们提供了 高级指南,其中包括修改代码的提示和规则。
(4)要找到您想要的预训练模型,用户可以查看ModelZoo,它总结了各种主干和预训练方法以及不同算法的介绍。
(5)此外,我们还提供分析和可视化工具来帮助诊断算法。
2、环境配置安装
1、 先决条件
在本节中,我们将演示如何使用 PyTorch 准备环境。
MMPretrain 适用于 Linux、Windows 和 macOS。它需要 Python 3.7+、CUDA 10.2+ 和 PyTorch 1.8+。
2、安装
创建conda环境并激活。
conda create --name mmpretrain python=3.8 -y #创建环境
conda activate mmpretrain #激活环境
conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch #安装 PyTorch and torchvision (官方)
#如果网不好,可以这样安装
pip3 install torch==1.8.2+cu102 torchvision==0.9.2+cu102 torchaudio===0.8.2 -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
#验证是否安装成功
>>> import torchvision
>>> import torch
>>> import.__version__
File "<stdin>", line 1
import.__version__
^
SyntaxError: invalid syntax
>>> torch.__version__
'1.8.2+cu102'
3、从源安装 mmpretrain
在这种情况下,从源安装 mmpretrain:
git clone https://github.com/open-mmlab/mmpretrain.git
cd mmpretrain
pip install -U openmim && mim install -e . -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
git clone https://github.com/open-mmlab/mmpretrain.git
cd mmpretrain
pip install -U openmim -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
mim install -e .
"-e"意味着以可编辑模式安装项目,因此对代码所做的任何本地修改都会生效,无需重新安装。
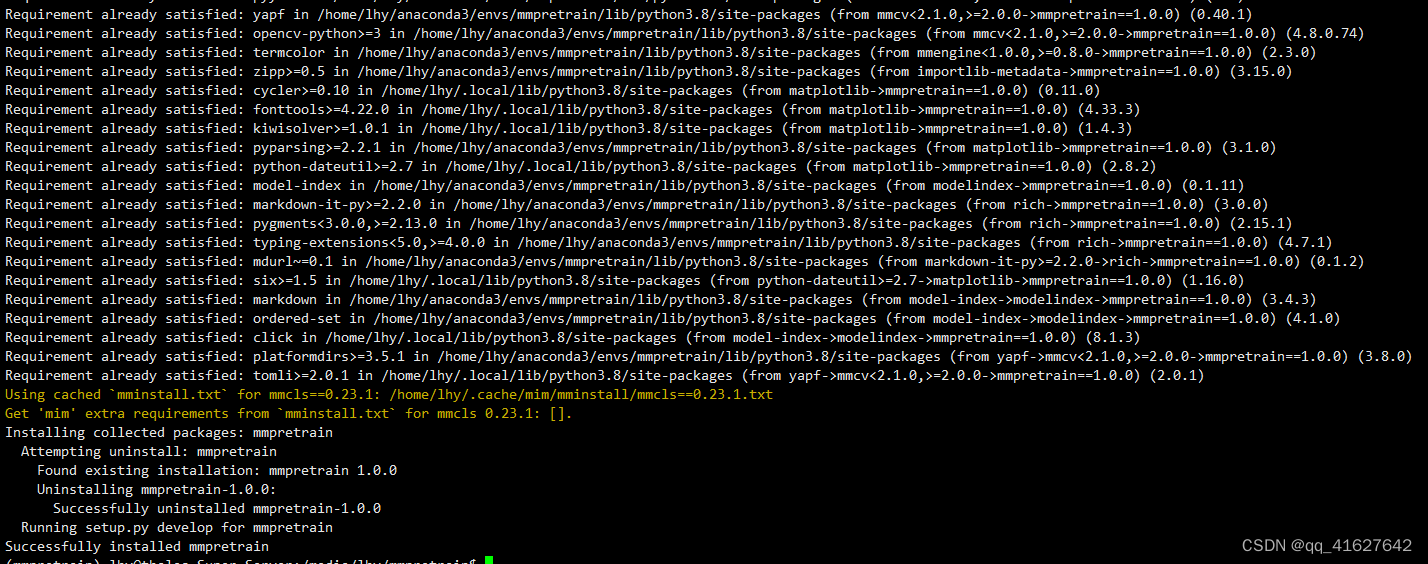
安装多模态支持(可选)
MMPretrain 中的多模态模型需要额外的依赖项。要安装这些依赖项,您可以[multimodal]在安装过程中添加。例如:
# Install from source
mim install -e ".[multimodal]"
# Install as a Python package
mim install "mmpretrain[multimodal]>=1.0.0rc8"
3、验证安装
为了验证 MMPretrain 是否安装正确,我们提供了一些示例代码来运行推理演示。
选项(a)。如果从源安装 mmpretrain,只需运行以下命令:
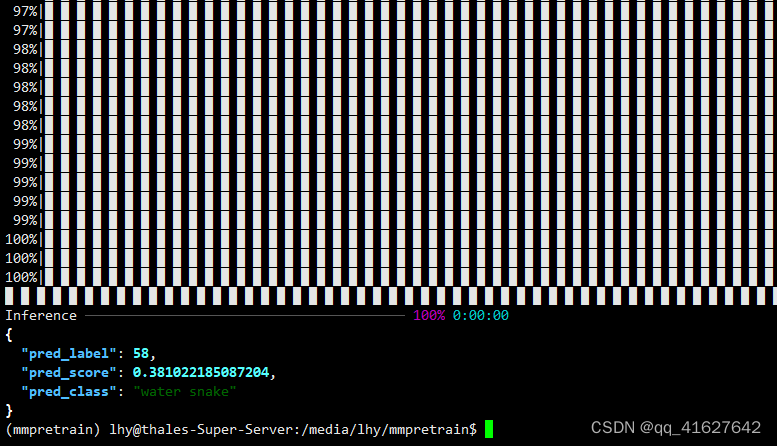
python demo/image_demo.py demo/demo.JPEG resnet18_8xb32_in1k --device cpu
您将在终端中看到输出结果字典,包括pred_label,pred_score和pred_class
选项(b)。如果将 mmpretrain 安装为 python 包,请打开 python 解释器并复制并粘贴以下代码。
from mmpretrain import get_model, inference_model
model = get_model('resnet18_8xb32_in1k', device='cpu') # or device='cuda:0'
inference_model(model, 'demo/demo.JPEG')
您将看到打印的字典,包括预测的标签、分数和类别名称。
注意
这resnet18_8xb32_in1k是模型名称,您可以使用它mmpretrain.list_models来探索所有模型,或在模型动物园摘要中搜索它们。
3、了解配置
为了管理深度学习实验中的各种配置,我们使用一种配置文件来记录所有这些配置。该配置系统采用模块化和继承设计,更多详细信息可以参考 MMEngine 的教程。
通常,我们使用Python文件作为配置文件。所有的配置文件都放在该configs文件夹下,目录结构如下:
MMPretrain/
├── configs/
│ ├── _base_/ # primitive configuration folder,基本配置文件夹
│ │ ├── datasets/ # primitive datasets,基本数据集
│ │ ├── models/ # primitive models,基本模型
│ │ ├── schedules/ # primitive schedules,基本学习率
│ │ └── default_runtime.py # primitive runtime setting,基本运行设置
│ ├── beit/ # BEiT Algorithms Folder,BEiT
│ ├── mae/ # MAE Algorithms Folder,MAE 算法文件夹
│ ├── mocov2/ # MoCoV2 Algorithms Folder,MoCoV2算法文件夹
│ ├── resnet/ # ResNet Algorithms Folder
│ ├── swin_transformer/ # Swin Algorithms Folder
│ ├── vision_transformer/ # ViT Algorithms Folder
│ ├── ...
└── ...
如果您想检查配置文件,可以运行以查看完整的配置。
python tools/misc/print_config.py /PATH/TO/CONFIG
本文主要讲解配置文件的结构,以及如何在现有配置文件的基础上进行修改。我们以ResNet50配置文件为例,逐行解释。
1、配置结构
文件夹中有四种基本组件文件configs/base,分别是:
models
datasets
schedules
runtime
我们将文件夹中的所有配置文件_base_称为原始配置文件。您可以通过继承一些原始配置文件轻松构建训练配置文件。
为了便于理解,我们以ResNet50 配置文件为例,并对每一行进行注释。
_base_ = [ # This config file will inherit all config files in `_base_`.
'../_base_/models/resnet50.py', # model settings
'../_base_/datasets/imagenet_bs32.py', # data settings
'../_base_/schedules/imagenet_bs256.py', # schedule settings
'../_base_/default_runtime.py' # runtime settings
]
1、模型设置
这个原始配置文件包含一个 dict 变量model,主要包含网络结构和损失函数等信息:
type:
要构建的模型类型,我们支持多种任务。
对于图像分类任务,通常ImageClassifier可以在API 文档中找到更多详细信息。
对于自监督学习,有好几种SelfSupervisors,比如such as MoCoV2, BEiT, MAE,等等,你可以在API文档中找到更多详细信息。
对于图像检索任务,通常ImageToImageRetriever,可以在API 文档中找到更多详细信息。
通常,我们使用该type字段来指定组件的类,并使用其他字段来传递该类的初始化参数。注册表教程对此进行了详细描述。
这里我们以 的 config 字段ImageClassifier为例,对初始化参数进行说明如下:
backbone:
主干的设置。主干网络是提取输入特征的主要网络,如ResNet、Swin Transformer、Vision Transformer等。所有可用的主干网络都可以在API 文档中找到。
对于自监督学习,一些主干被重新实现,您可以在API 文档中找到更多详细信息。
neck:
颈部的设置。颈部是连接backbone和头部的中间模块,就像GlobalAveragePooling。所有可用的颈部都可以在API 文档中找到。
head:
任务头的设置。头部是执行指定任务的与任务相关的组件,例如图像分类或自监督训练。所有可用的头都可以在API 文档中找到。
loss:
要优化的损失函数,如CrossEntropyLoss、LabelSmoothLoss等。所有可用的损失都可以在API 文档PixelReconstructionLoss中找到。
data_preprocessor:
模型前向处理的组件,用于预处理输入。请参阅文档了解更多详细信息。
train_cfg ImageClassifier:
训练时的额外设置。在 中ImageClassifier,我们主要使用它来指定批量增强设置,例如Mixup和CutMix。。请参阅文档了解更多详细信息
以下是 ResNet50 配置文件的模型原始配置configs/base/models/resnet50.py:
model = dict(
type='ImageClassifier', # The type of the main model (here is for image classification task).主要模型的类型(这里是针对图像分类任务的)。
backbone=dict(
type='ResNet', # The type of the backbone module.
# All fields except `type` come from the __init__ method of class `ResNet`
# and you can find them from https://mmpretrain.readthedocs.io/en/latest/api/generated/mmpretrain.models.backbones.ResNet.html,#除了' type '之外的所有字段都来自' ResNet '类的__init__方法,你可以从
depth=50,
num_stages=4,
out_indices=(3, ),
frozen_stages=-1,
style='pytorch'),
neck=dict(type='GlobalAveragePooling'), # The type of the neck module.
head=dict(
type='LinearClsHead', # The type of the classification head module.
# All fields except `type` come from the __init__ method of class `LinearClsHead`除了' type '之外的所有字段都来自' linearclhead '类的__init__方法
# and you can find them from https://mmpretrain.readthedocs.io/en/latest/api/generated/mmpretrain.models.heads.LinearClsHead.html
num_classes=1000,
in_channels=2048,
loss=dict(type='CrossEntropyLoss', loss_weight=1.0),
))
CLASSmmpretrain.models.backbones.ResNet(depth, in_channels=3, stem_channels=64, base_channels=64, expansion=None, num_stages=4, strides=(1, 2, 2, 2), dilations=(1, 1, 1, 1), out_indices=(3,), style='pytorch', deep_stem=False, avg_down=False, frozen_stages=-1, conv_cfg=None, norm_cfg={'requires_grad': True, 'type': 'BN'}, norm_eval=False, with_cp=False, zero_init_residual=True, init_cfg=[{'type': 'Kaiming', 'layer': ['Conv2d']}, {'type': 'Constant', 'val': 1, 'layer': ['_BatchNorm', 'GroupNorm']}], drop_path_rate=0.0)
CLASSmmpretrain.models.heads.LinearClsHead(num_classes, in_channels, init_cfg={'layer': 'Linear', 'std': 0.01, 'type': 'Normal'}, **kwargs)
2、数据设置
这个原始配置文件包含构建数据加载器和评估器的信息:
data_preprocessor:
模型输入预处理配置,与此相同,model.data_preprocessor但优先级较低。
train_evaluator | val_evaluator | test_evaluator:
要构建评估器或指标,请参阅教程。
train_dataloader | val_dataloader | test_dataloader:
数据加载器的设置
batch_size:每个GPU的批量大小。
num_workers:每个GPU获取数据的worker数量。
sampler:采样器的设置。
persistent_workers:完成一个纪元后是否继续工作。
dataset:数据集的设置。
####### type:数据集的类型,我们支持CustomDataset,ImageNet还有很多其他数据集,参考文档。
####### pipeline:数据转换管道。您可以在本教程中了解如何设计管道。
以下是ResNet50配置中的数据原语配置configs/base/datasets/imagenet_bs32.py:
dataset_type = 'ImageNet',训练样本的数据类型
# preprocessing configuration
data_preprocessor = dict(
# Input image data channels in 'RGB' order
mean=[123.675, 116.28, 103.53], # Input image normalized channel mean in RGB order
std=[58.395, 57.12, 57.375], # Input image normalized channel std in RGB order
to_rgb=True, # Whether to flip the channel from BGR to RGB or RGB to BGR
)
train_pipeline = [
dict(type='LoadImageFromFile'), # read image
dict(type='RandomResizedCrop', scale=224), # Random scaling and cropping,随机缩放和裁剪
dict(type='RandomFlip', prob=0.5, direction='horizontal'), # random horizontal flip
dict(type='PackInputs'), # prepare images and labels,准备图片和标签
]
test_pipeline = [
dict(type='LoadImageFromFile'), # read image
dict(type='ResizeEdge', scale=256, edge='short'), # Scale the short side to 256,将短边缩放到256
dict(type='CenterCrop', crop_size=224), # center crop
dict(type='PackInputs'), # prepare images and labels
]
# Construct training set dataloader
train_dataloader = dict(
batch_size=32, # batchsize per GPU
num_workers=5, # Number of workers to fetch data per GPU,每个GPU获取数据的工作线程数
dataset=dict( # training dataset
type=dataset_type,
data_root='data/imagenet',
ann_file='meta/train.txt',
data_prefix='train',
pipeline=train_pipeline),
sampler=dict(type='DefaultSampler', shuffle=True), # default sampler,默认的取样器
persistent_workers=True, # Whether to keep the process, can shorten the preparation time of each epoch,是否保留流程,可以缩短每个epoch的准备时间
)
# Construct the validation set dataloader
val_dataloader = dict(
batch_size=32,
num_workers=5,
dataset=dict(
type=dataset_type,
data_root='data/imagenet',
ann_file='meta/val.txt',
data_prefix='val',
pipeline=test_pipeline),
sampler=dict(type='DefaultSampler', shuffle=False),
persistent_workers=True,
)
# The settings of the evaluation metrics for validation. We use the top1 and top5 accuracy here.用于验证的评估度量的设置。我们在这里使用top1和top5的精度
val_evaluator = dict(type='Accuracy', topk=(1, 5))
test_dataloader = val_dataloader # The settings of the dataloader for the test dataset, which is the same as val_dataloader
test_evaluator = val_evaluator # The settings of the evaluation metrics for test, which is the same as val_evaluator
3、日程设置
这个原始配置文件主要包含训练策略设置以及训练、验证和测试循环的设置:
optim_wrapper:优化器包装器的设置。我们使用优化器包装器来定制优化过程。
optimizer:支持所有pytorch优化器,参考相关MMEngine文档。
paramwise_cfg:根据参数类型或名称设置不同的优化参数,请参考相关学习策略文档。
accumulative_counts:经过多次后退而不是一次后退来优化参数。您可以使用它通过小批量来模拟大批量。
param_scheduler:优化器参数策略。
您可以使用它来指定训练期间的学习率和动量曲线。有关更多详细信息,请参阅MMEngine 中的文档。
train_cfg | val_cfg | test_cfg:训练、验证和测试循环的设置,请参考相关MMEngine文档。
以下是ResNet50配置中的schedule原语配置configs/base/datasets/imagenet_bs32.py:
optim_wrapper = dict(
# Use SGD optimizer to optimize parameters.
optimizer=dict(type='SGD', lr=0.1, momentum=0.9, weight_decay=0.0001))
# The tuning strategy of the learning rate.学习率的调整策略
# The 'MultiStepLR' means to use multiple steps policy to schedule the learning rate (LR).“MultiStepLR”是指使用多步策略来调度学习率
param_scheduler = dict(
type='MultiStepLR', by_epoch=True, milestones=[30, 60, 90], gamma=0.1)
# Training configuration, iterate 100 epochs, and perform validation after every training epoch.
# 'by_epoch=True' means to use `EpochBaseTrainLoop`, 'by_epoch=False' means to use IterBaseTrainLoop.
train_cfg = dict(by_epoch=True, max_epochs=100, val_interval=1)
# Use the default val loop settings.
val_cfg = dict()
# Use the default test loop settings.
test_cfg = dict()
# This schedule is for the total batch size 256.此计划适用于总批大小为256的批
# If you use a different total batch size, like 512 and enable auto learning rate scaling.如果您使用不同的总批大小,如512,并启用自动学习率缩放。
# We will scale up the learning rate to 2 times.我们将把学习率提高到2倍。
auto_scale_lr = dict(base_batch_size=256)
4、运行时设置
这部分主要包括保存检查点策略、日志配置、训练参数、断点权重路径、工作目录等。
这是几乎所有配置都使用的运行时原始配置文件“configs/ base /default_runtime.py” :
# defaults to use registries in mmpretrain,默认在mmpretrain中使用注册表
default_scope = 'mmpretrain'
# configure default hooks
default_hooks = dict(
# record the time of every iteration.,记录每次迭代的时间
timer=dict(type='IterTimerHook'),
# print log every 100 iterations.
logger=dict(type='LoggerHook', interval=100),
# enable the parameter scheduler.启用参数调度程序
param_scheduler=dict(type='ParamSchedulerHook'),
# save checkpoint per epoch.
checkpoint=dict(type='CheckpointHook', interval=1),
# set sampler seed in a distributed environment.在分布式环境中设置采样器种子
sampler_seed=dict(type='DistSamplerSeedHook'),
# validation results visualization, set True to enable it.
visualization=dict(type='VisualizationHook', enable=False),
)
# configure environment
env_cfg = dict(
# whether to enable cudnn benchmark,是否开启cudnn基准
cudnn_benchmark=False,
# set multi-process parameters,设置多进程参数
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
# set distributed parameters,设置分布参数
dist_cfg=dict(backend='nccl'),
)
# set visualizer
vis_backends = [dict(type='LocalVisBackend')] # use local HDD backend
visualizer = dict(
type='UniversalVisualizer', vis_backends=vis_backends, name='visualizer')
# set log level
log_level = 'INFO'
# load from which checkpoint
load_from = None
# whether to resume training from the loaded checkpoint
resume = False
2、继承和修改配置文件
为了便于理解,我们建议贡献者继承现有的配置文件。但不要滥用继承权。通常,对于所有配置文件,我们建议最大继承级别为 3。
例如,如果您的配置文件是基于ResNet并进行了一些其他修改,您可以首先通过指定_base_ =‘./resnet50_8xb32_in1k.py’(相对于您的配置文件的路径)来继承基本的ResNet结构、数据集和其他训练设置,然后修改配置文件。一个更具体的例子,现在我们想要使用configs/resnet/resnet50_8xb32_in1k.py中的几乎所有配置,但是使用CutMix训练批次增强并将训练时期数从100 更改为 300,修改何时衰减学习率,并修改数据集路径,您可以创建一个新的configs/resnet/resnet50_8xb32-300e_in1k.py配置文件 ,内容如下:
# create this file under 'configs/resnet/' folder
_base_ = './resnet50_8xb32_in1k.py'
# using CutMix batch augment
model = dict(
train_cfg=dict(
augments=dict(type='CutMix', alpha=1.0)#增加了数据增强
)
)
# trains more epochs
train_cfg = dict(max_epochs=300, val_interval=10) # Train for 300 epochs, evaluate every 10 epochs
param_scheduler = dict(step=[150, 200, 250]) # The learning rate adjustment has also changed
# Use your own dataset directory
train_dataloader = dict(
dataset=dict(data_root='mydata/imagenet/train'),
)
val_dataloader = dict(
batch_size=64, # No back-propagation during validation, larger batch size can be used
dataset=dict(data_root='mydata/imagenet/val'),
)
test_dataloader = dict(
batch_size=64, # No back-propagation during test, larger batch size can be used
dataset=dict(data_root='mydata/imagenet/val'),
)
3、修改命令中的配置
当您使用脚本“tools/train.py”或“tools/test.py”提交任务或使用其他一些工具时,它们可以通过指定参数直接修改所使用的配置文件的内容–cfg-options。
更新字典链的配置键。
可以按照原始配置中字典键的顺序指定配置选项。例如,将模型主干中的所有 BN 模块更改为模式。
--cfg-options model.backbone.norm_eval=False
更新配置列表中的密钥。
一些配置字典在您的配置中组成一个列表。例如,训练管道data.train.pipeline通常是一个列表,例如。如果您想在管道中更改为,您可以指定。
[dict(type='LoadImageFromFile'), dict(type='TopDownRandomFlip', flip_prob=0.5), ...]
更新列表/元组的值。
如果要更新的值是列表或元组。例如,配置文件通常设置. 如果您想更改该字段,您可以指定。请注意,引号“对于支持列表/元组数据类型是必需的,并且指定值的引号内不允许有空格。
val_evaluator = dict(type='Accuracy', topk=(1, 5))
--cfg-options val_evaluator.topk="(1,3)"
4、现有模型的推理
本教程将展示如何使用以下API:
list_models:列出 MMPreTrain 中可用的模型名称。
get_model:从模型名称或模型配置中获取模型。
inference_model:用相应的推理器推理模型。
这是快速入门的快捷方式,对于高级用法,请直接使用下面的推理器。
推理者:
ImageClassificationInferencer:对给定图像进行图像分类。
ImageRetrievalInferencer:从给定图像集上的给定图像执行图像到图像检索。
ImageCaptionInferencer:在给定图像上生成标题。
VisualQuestionAnsweringInferencer:根据给定的图片回答问题。
VisualGroundingInferencer:从给定图像的描述中找到一个对象。
TextToImageRetrievalInferencer:根据给定图像集的给定描述执行文本到图像检索。
ImageToTextRetrievalInferencer:从给定图像对一系列文本执行图像到文本检索。
NLVRInferencer:对给定的图像对和文本执行自然语言视觉推理。
FeatureExtractor:通过视觉主干从图像文件中提取特征。
列出可用型号
列出 MMPreTrain 中的所有模型。
from mmpretrain import list_models
list_models()
list_models支持Unix文件名模式匹配,可以使用*** * **来匹配任何字符。
from mmpretrain import list_models
list_models("*convnext-b*21k")
您可以使用list_models推理器的方法来获取相应任务的可用模型。
from mmpretrain import ImageCaptionInferencer
ImageCaptionInferencer.list_models()
Get a model
you can use get_model get the model.
from mmpretrain import get_model
model = get_model("convnext-base_in21k-pre_3rdparty_in1k")
model = get_model("convnext-base_in21k-pre_3rdparty_in1k", pretrained=True)
model = get_model("convnext-base_in21k-pre_3rdparty_in1k", pretrained="your_local_checkpoint_path")
model = get_model("convnext-base_in21k-pre_3rdparty_in1k", head=dict(num_classes=10))
model_headless = get_model("resnet18_8xb32_in1k", head=None, neck=None, backbone=dict(out_indices=(1, 2, 3)))
import torch
from mmpretrain import get_model
model = get_model('convnext-base_in21k-pre_3rdparty_in1k', pretrained=True)
x = torch.rand((1, 3, 224, 224))
y = model(x)
print(type(y), y.shape)
对给定图像的推理
以下是通过 ResNet-50 预训练分类模型推断图像的示例。
from mmpretrain import inference_model
image = 'https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'
# If you have no graphical interface, please set `show=False`
result = inference_model('resnet50_8xb32_in1k', image, show=True)
print(result['pred_class'])
该inference_modelAPI仅用于演示,不能保留模型实例或对多个样本进行推理。您可以使用推理器进行多次调用。
from mmpretrain import ImageClassificationInferencer
image = 'https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'
inferencer = ImageClassificationInferencer('resnet50_8xb32_in1k')
# Note that the inferencer output is a list of result even if the input is a single sample.
result = inferencer('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')[0]
print(result['pred_class'])
# You can also use is for multiple images.
image_list = ['demo/demo.JPEG', 'demo/bird.JPEG'] * 16
results = inferencer(image_list, batch_size=8)
print(len(results))
print(results[1]['pred_class'])
通常,每个样本的结果都是一个字典。例如,图像分类结果是一个包含pred_label、pred_score、的字典,pred_scores如下pred_class
{
"pred_label": 65,
"pred_score": 0.6649366617202759,
"pred_class":"sea snake",
"pred_scores": array([..., 0.6649366617202759, ...], dtype=float32)
}
您可以通过参数配置推理器,例如,使用您自己的配置文件和检查点通过 CUDA 推理图像。
from mmpretrain import ImageClassificationInferencer
image = 'https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG'
config = 'configs/resnet/resnet50_8xb32_in1k.py'
checkpoint = 'https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth'
inferencer = ImageClassificationInferencer(model=config, pretrained=checkpoint, device='cuda')
result = inferencer(image)[0]
print(result['pred_class'])
通过 Gradio 演示进行推理
我们还为所有支持的任务提供了渐变演示,您可以在projects/gradio_demo/launch.py 中找到它。
gradio请先安装。pip install -U gradio
pip install "gradio>=3.31.0"
从图像中提取特征
FeatureExtractor与model.extract_feat 相比,是直接从图像文件中提取特征,而不是使用一批张量。总之, model.extract_feat的输入是torch.Tensor, FeatureExtractor的输入是图像。
from mmpretrain import FeatureExtractor, get_model
model = get_model('resnet50_8xb32_in1k', backbone=dict(out_indices=(0, 1, 2, 3)))
extractor = FeatureExtractor(model)
features = extractor('https://github.com/open-mmlab/mmpretrain/raw/main/demo/demo.JPEG')[0]
features[0].shape, features[1].shape, features[2].shape, features[3].shape
5、模型训练
在本教程中,我们将介绍如何使用 MMPretrain 中提供的脚本来启动训练任务。如果您需要,我们还提供了一些有关如何使用自定义数据集进行预训练 以及如何使用自定义数据集进行微调的练习示例。
使用您的电脑进行训练
您可以使用tools/train.py它在具有 CPU 和可选 GPU 的单台机器上训练模型。
以下是该脚本的完整用法:
python tools/train.py ${CONFIG_FILE} [ARGS]
默认情况下,MMPretrain 更喜欢 GPU 而不是 CPU。如果你想在CPU上训练模型,请将CUDA_VISIBLE_DEVICES其清空或设置为-1以使GPU对程序不可见。
CUDA_VISIBLE_DEVICES=-1 python tools/train.py ${CONFIG_FILE} [ARGS]
CONFIG_FILE 配置文件的路径。
–work-dir WORK_DIR 保存日志和检查点的目标文件夹。默认为 .config 下的配置文件同名的文件夹./work_dirs。
–resume [RESUME] 恢复训练。如果指定路径,则从该路径恢复,如果不指定,则尝试从最新的检查点自动恢复。
–amp 启用自动混合精度训练。
–no-validate 不建议。在训练期间禁用检查点评估。
–auto-scale-lr 根据实际批量大小和原始批量大小自动缩放学习率。
–no-pin-memory 是否禁用pin_memory数据加载器中的选项。
–no-persistent-workers 是否禁用persistent_workers数据加载器中的选项。
–cfg-options CFG_OPTIONS 覆盖已使用配置中的一些设置,xxx=yyy 格式的键值对将合并到配置文件中。如果要覆盖的值是列表,则其形式应为key=“[a,b]“或key=a,b。该参数还允许嵌套列表/元组值,例如key=”[(a,b),(c,d)]”。请注意,引号是必需的,并且不允许有空格。
–launcher {none,pytorch,slurm,mpi},作业启动器的选项。
使用多个 GPU 进行训练
我们提供了一个 shell 脚本来启动多 GPU 任务torch.distributed.launch。
bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
您还可以通过环境变量指定启动器的额外参数。例如,通过以下命令将启动器的通信端口更改为29666:
PORT=29666 bash ./tools/dist_train.sh ${CONFIG_FILE} ${GPU_NUM} [PY_ARGS]
如果您想启动多个训练作业并使用不同的GPU,您可以通过指定不同的端口和可见设备来启动它们。
CUDA_VISIBLE_DEVICES=0,1,2,3 PORT=29500 bash ./tools/dist_train.sh ${CONFIG_FILE1} 4 [PY_ARGS]
CUDA_VISIBLE_DEVICES=4,5,6,7 PORT=29501 bash ./tools/dist_train.sh ${CONFIG_FILE2} 4 [PY_ARGS]
如何使用自定义数据集进行预训练
在本教程中,我们提供了一个练习示例以及一些有关如何在您自己的数据集上进行训练的技巧。
在 MMPretrain 中,我们支持CustomDataset(类似于ImageFolderin torchvision),可以直接读取指定文件夹内的图像。您只需准备自定义数据集的路径信息并编辑config即可。
第 1 步:准备数据集
按照准备数据集准备数据集。数据集的根文件夹可以是这样的data/custom_dataset/。
在这里,我们假设您想要进行无监督训练,并使用子文件夹格式CustomDataset将数据集组织为:
data/custom_dataset/
├── sample1.png
├── sample2.png
├── sample3.png
├── sample4.png
└── …
步骤 2:选择一个配置作为模板
在这里,我们想以此configs/mae/mae_vit-base-p16_8xb512-amp-coslr-300e_in1k.py为例。我们首先将此配置文件复制到同一文件夹并将其重命名为 mae_vit-base-p16_8xb512-amp-coslr-300e_custom.py.
该配置的内容是:
_base_ = [
'../_base_/models/mae_vit-base-p16.py',
'../_base_/datasets/imagenet_bs512_mae.py',
'../_base_/default_runtime.py',
]
# optimizer wrapper
optim_wrapper = dict(
type='AmpOptimWrapper',
loss_scale='dynamic',
optimizer=dict(
type='AdamW',
lr=1.5e-4 * 4096 / 256,
betas=(0.9, 0.95),
weight_decay=0.05),
paramwise_cfg=dict(
custom_keys={
'ln': dict(decay_mult=0.0),
'bias': dict(decay_mult=0.0),
'pos_embed': dict(decay_mult=0.),
'mask_token': dict(decay_mult=0.),
'cls_token': dict(decay_mult=0.)
}))
# learning rate scheduler
param_scheduler = [
dict(
type='LinearLR',
start_factor=0.0001,
by_epoch=True,
begin=0,
end=40,
convert_to_iter_based=True),
dict(
type='CosineAnnealingLR',
T_max=260,
by_epoch=True,
begin=40,
end=300,
convert_to_iter_based=True)
]
# runtime settings
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=300)
default_hooks = dict(
# only keeps the latest 3 checkpoints
checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
randomness = dict(seed=0, diff_rank_seed=True)
# auto resume
resume = True
# NOTE: `auto_scale_lr` is for automatically scaling LR
# based on the actual training batch size.
auto_scale_lr = dict(base_batch_size=4096)
步骤3:编辑数据集相关配置
将type数据集设置覆盖为’CustomDataset’
data_root将数据集设置覆盖为data/custom_dataset.
将数据集设置覆盖ann_file为空字符串,因为我们假设您使用的是子文件夹格式CustomDataset。
将数据集设置覆盖data_prefix为空字符串,因为我们在 下使用整个数据集data_root,并且您不需要将样本拆分为不同的子集并设置data_prefix.
修改后的配置将类似于:
_base_ = [
'../_base_/models/mae_vit-base-p16.py',
'../_base_/datasets/imagenet_bs512_mae.py',
'../_base_/default_runtime.py',
]
# >>>>>>>>>>>>>>> Override dataset settings here >>>>>>>>>>>>>>>>>>>
train_dataloader = dict(
dataset=dict(
type='CustomDataset',
data_root='data/custom_dataset/',
ann_file='', # We assume you are using the sub-folder format without ann_file,我们假设您使用的是没有ann_file的子文件夹格式
data_prefix='', # The `data_root` is the data_prefix directly.
with_label=False,
)
)
# <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
# optimizer wrapper
optim_wrapper = dict(
type='AmpOptimWrapper',
loss_scale='dynamic',
optimizer=dict(
type='AdamW',
lr=1.5e-4 * 4096 / 256,
betas=(0.9, 0.95),
weight_decay=0.05),
paramwise_cfg=dict(
custom_keys={
'ln': dict(decay_mult=0.0),
'bias': dict(decay_mult=0.0),
'pos_embed': dict(decay_mult=0.),
'mask_token': dict(decay_mult=0.),
'cls_token': dict(decay_mult=0.)
}))
# learning rate scheduler
param_scheduler = [
dict(
type='LinearLR',
start_factor=0.0001,
by_epoch=True,
begin=0,
end=40,
convert_to_iter_based=True),
dict(
type='CosineAnnealingLR',
T_max=260,
by_epoch=True,
begin=40,
end=300,
convert_to_iter_based=True)
]
# runtime settings
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=300)
default_hooks = dict(
# only keeps the latest 3 checkpoints
checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
randomness = dict(seed=0, diff_rank_seed=True)
# auto resume
resume = True
# NOTE: `auto_scale_lr` is for automatically scaling LR
# based on the actual training batch size.
auto_scale_lr = dict(base_batch_size=4096)
通过使用编辑后的配置文件,您可以在自定义数据集上使用 MAE 算法训练自监督模型。
遵循上述想法,我们还提供了如何在 COCO 数据集上训练 MAE 的示例。编辑后的文件将是这样的
_base_ = [
'../_base_/models/mae_vit-base-p16.py',
'../_base_/datasets/imagenet_mae.py',
'../_base_/default_runtime.py',
]
# >>>>>>>>>>>>>>> Override dataset settings here >>>>>>>>>>>>>>>>>>>
train_dataloader = dict(
dataset=dict(
type='mmdet.CocoDataset',
data_root='data/coco/',
ann_file='annotations/instances_train2017.json', # Only for loading images, and the labels won't be used.
data_prefix=dict(img='train2017/'),
)
)
# <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
# optimizer wrapper
optim_wrapper = dict(
type='AmpOptimWrapper',
loss_scale='dynamic',
optimizer=dict(
type='AdamW',
lr=1.5e-4 * 4096 / 256,
betas=(0.9, 0.95),
weight_decay=0.05),
paramwise_cfg=dict(
custom_keys={
'ln': dict(decay_mult=0.0),
'bias': dict(decay_mult=0.0),
'pos_embed': dict(decay_mult=0.),
'mask_token': dict(decay_mult=0.),
'cls_token': dict(decay_mult=0.)
}))
# learning rate scheduler
param_scheduler = [
dict(
type='LinearLR',
start_factor=0.0001,
by_epoch=True,
begin=0,
end=40,
convert_to_iter_based=True),
dict(
type='CosineAnnealingLR',
T_max=260,
by_epoch=True,
begin=40,
end=300,
convert_to_iter_based=True)
]
# runtime settings
train_cfg = dict(type='EpochBasedTrainLoop', max_epochs=300)
default_hooks = dict(
# only keeps the latest 3 checkpoints
checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
randomness = dict(seed=0, diff_rank_seed=True)
# auto resume
resume = True
# NOTE: `auto_scale_lr` is for automatically scaling LR
# based on the actual training batch size.
auto_scale_lr = dict(base_batch_size=4096)
如何使用自定义数据集进行预训练
第 1 步:准备数据集
按照准备数据集准备数据集。数据集的根文件夹可以是这样的data/custom_dataset/。
在这里,我们假设您想要进行监督图像分类训练,并使用子文件夹格式 CustomDataset将数据集组织为
data/custom_dataset/
├── train
│ ├── class_x
│ │ ├── x_1.png
│ │ ├── x_2.png
│ │ ├── x_3.png
│ │ └── …
│ ├── class_y
│ └── …
└── test
├── class_x
│ ├── test_x_1.png
│ ├── test_x_2.png
│ ├── test_x_3.png
│ └── …
├── class_y
└── …
步骤 2:选择一个配置作为模板
在这里,我们想以此configs/resnet/resnet50_8xb32_in1k.py为例。我们首先将此配置文件复制到同一文件夹并将其重命名为resnet50_8xb32-ft_custom.py.
_base_ = [
'../_base_/models/resnet50.py', # model settings
'../_base_/datasets/imagenet_bs32.py', # data settings
'../_base_/schedules/imagenet_bs256.py', # schedule settings
'../_base_/default_runtime.py', # runtime settings
]
步骤 3:编辑模型设置
在微调模型时,通常我们希望加载预先训练的主干权重并从头开始训练新的分类头。
要加载预训练的主干网,我们需要更改主干网的初始化配置并使用Pretrained初始化函数。此外,在init_cfg 中 ,我们用来prefix='backbone’告诉初始化函数检查点中需要加载的子模块的前缀。
例如,backbone这里的意思是加载backbone子模块。这里我们使用在线检查点,它会在训练期间自动下载,您也可以手动下载模型并使用本地路径。然后我们需要根据新数据集的类号来修改头部,只需更改num_classes头部即可。
当新数据集很小并且与预训练数据集共享域时,我们可能希望冻结主干的前几个阶段的参数,这将有助于网络保持从预训练数据集中提取低级信息的能力模型。在 MMPretrain 中,**您可以简单地通过参数指定要冻结的阶段数frozen_stages。**例如,要冻结前两个阶段的参数,只需使用以下配置:
frozen_stages到目前为止,并非所有骨干都支持这一论点。请检查 文档 以确认您的主干是否支持它。
_base_ = [
'../_base_/models/resnet50.py', # model settings
'../_base_/datasets/imagenet_bs32.py', # data settings
'../_base_/schedules/imagenet_bs256.py', # schedule settings
'../_base_/default_runtime.py', # runtime settings
]
# >>>>>>>>>>>>>>> Override model settings here >>>>>>>>>>>>>>>>>>>
model = dict(
backbone=dict(
frozen_stages=2,
init_cfg=dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',
prefix='backbone',
)),
head=dict(num_classes=10),
)
# <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
这里我们只需要设置我们想要修改的部分配置,因为继承的配置将被合并并得到整个配置。
步骤 4:编辑数据集设置
为了对新数据集进行微调,我们需要覆盖一些数据集设置,例如数据集类型、数据管道等。
_base_ = [
'../_base_/models/resnet50.py', # model settings
'../_base_/datasets/imagenet_bs32.py', # data settings
'../_base_/schedules/imagenet_bs256.py', # schedule settings
'../_base_/default_runtime.py', # runtime settings
]
# model settings
model = dict(
backbone=dict(
frozen_stages=2,
init_cfg=dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',
prefix='backbone',
)),
head=dict(num_classes=10),
)
# >>>>>>>>>>>>>>> Override data settings here >>>>>>>>>>>>>>>>>>>
data_root = 'data/custom_dataset'
train_dataloader = dict(
dataset=dict(
type='CustomDataset',
data_root=data_root,
ann_file='', # We assume you are using the sub-folder format without ann_file
data_prefix='train',
))
val_dataloader = dict(
dataset=dict(
type='CustomDataset',
data_root=data_root,
ann_file='', # We assume you are using the sub-folder format without ann_file
data_prefix='test',
))
test_dataloader = val_dataloader
# <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
步骤 5:编辑计划设置(可选)
微调超参数与默认计划不同。它通常需要较小的学习率和更快的衰减调度器时期。
_base_ = [
'../_base_/models/resnet50.py', # model settings
'../_base_/datasets/imagenet_bs32.py', # data settings
'../_base_/schedules/imagenet_bs256.py', # schedule settings
'../_base_/default_runtime.py', # runtime settings
]
# model settings
model = dict(
backbone=dict(
frozen_stages=2,
init_cfg=dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',
prefix='backbone',
)),
head=dict(num_classes=10),
)
# data settings
data_root = 'data/custom_dataset'
train_dataloader = dict(
dataset=dict(
type='CustomDataset',
data_root=data_root,
ann_file='', # We assume you are using the sub-folder format without ann_file
data_prefix='train',
))
val_dataloader = dict(
dataset=dict(
type='CustomDataset',
data_root=data_root,
ann_file='', # We assume you are using the sub-folder format without ann_file
data_prefix='test',
))
test_dataloader = val_dataloader
# >>>>>>>>>>>>>>> Override schedule settings here >>>>>>>>>>>>>>>>>>>
# optimizer hyper-parameters
optim_wrapper = dict(
optimizer=dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001))
# learning policy
param_scheduler = dict(
type='MultiStepLR', by_epoch=True, milestones=[15], gamma=0.1)
# <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
步骤 6 开始训练
现在,我们已经完成了配置文件的微调,如下:
_base_ = [
'../_base_/models/resnet50.py', # model settings
'../_base_/datasets/imagenet_bs32.py', # data settings
'../_base_/schedules/imagenet_bs256.py', # schedule settings
'../_base_/default_runtime.py', # runtime settings
]
# model settings
model = dict(
backbone=dict(
frozen_stages=2,
init_cfg=dict(
type='Pretrained',
checkpoint='https://download.openmmlab.com/mmclassification/v0/resnet/resnet50_8xb32_in1k_20210831-ea4938fc.pth',
prefix='backbone',
)),
head=dict(num_classes=10),
)
# data settings
data_root = 'data/custom_dataset'
train_dataloader = dict(
dataset=dict(
type='CustomDataset',
data_root=data_root,
ann_file='', # We assume you are using the sub-folder format without ann_file
data_prefix='train',
))
val_dataloader = dict(
dataset=dict(
type='CustomDataset',
data_root=data_root,
ann_file='', # We assume you are using the sub-folder format without ann_file
data_prefix='test',
))
test_dataloader = val_dataloader
# schedule settings
optim_wrapper = dict(
optimizer=dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001))
param_scheduler = dict(
type='MultiStepLR', by_epoch=True, milestones=[15], gamma=0.1)
这里我们使用计算机上的 8 个 GPU 通过以下命令来训练模型:
bash tools/dist_train.sh configs/resnet/resnet50_8xb32-ft_custom.py 8
此外,您可以仅使用一个 GPU 通过以下命令来训练模型:
python tools/train.py configs/resnet/resnet50_8xb32-ft_custom.py
但是等等,如果使用一个 GPU,则需要更改一个重要的配置。我们需要更改数据集配置如下:
data_root = 'data/custom_dataset'
train_dataloader = dict(
batch_size=256,
dataset=dict(
type='CustomDataset',
data_root=data_root,
ann_file='', # We assume you are using the sub-folder format without ann_file
data_prefix='train',
))
val_dataloader = dict(
dataset=dict(
type='CustomDataset',
data_root=data_root,
ann_file='', # We assume you are using the sub-folder format without ann_file
data_prefix='test',
))
test_dataloader = val_dataloader
这是因为我们的训练计划的批量大小为 256。如果使用 8 个 GPU,只需batch_size=32在每个 GPU 的基本配置文件中使用配置,总批量大小将为 256。但是如果使用 1 个 GPU,则需要更改它手动调整至 256 以匹配训练计划。
然而,更大的批量大小需要更大的 GPU 内存,这里有几个简单的技巧来节省 GPU 内存:
启用自动混合精度训练。
python tools/train.py configs/resnet/resnet50_8xb32-ft_custom.py --amp
使用较小的批量大小(例如batch_size=32代替 256),并启用自动学习率缩放。
python tools/train.py configs/resnet/resnet50_8xb32-ft_custom.py --auto-scale-lr
auto_scale_lr.base_batch_size自动学习率缩放将根据实际批量大小和(您可以在基本配置中找到它 configs/base/schedules/imagenet_bs256.py)调整学习率
6、模型测试
对于图像分类任务和图像检索任务,您可以在训练后测试您的模型。
使用您的电脑进行测试
您可以tools/test.py在具有 CPU 和可选 GPU 的单台计算机上测试模型。
以下是该脚本的完整用法:
python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
默认情况下,MMPretrain 更喜欢 GPU 而不是 CPU。如果你想在CPU上测试模型,请将CUDA_VISIBLE_DEVICES其清空或设置为-1以使GPU对程序不可见。
CUDA_VISIBLE_DEVICES=-1 python tools/test.py ${CONFIG_FILE} ${CHECKPOINT_FILE} [ARGS]
CONFIG_FILE 配置文件的路径。
CHECKPOINT_FILE 检查点文件的路径(可以是http链接,您可以在此处找到检查点)。
–work-dir WORK_DIR 保存包含评估指标的文件的目录。
–out OUT 包含测试结果的文件的保存路径。
–out-item OUT_ITEM 指定测试结果文件的内容,可以是“pred”或“metrics”。如果是“pred”,则保存模型的输出以供离线评估。如果是“metrics”,则保存评估指标。默认为“pred”。
–cfg-options CFG_OPTIONS 覆盖已使用配置中的一些设置,xxx=yyy 格式的键值对将合并到配置文件中。如果要覆盖的值是列表,则其形式应为key=“[a,b]“或key=a,b。该参数还允许嵌套列表/元组值,例如key=”[(a,b),(c,d)]”。请注意,引号是必需的,并且不允许有空格。
–show-dir SHOW_DIR 保存结果可视化图像的目录。
–show 在窗口中可视化预测结果。
–interval INTERVAL 要可视化的样本间隔。
–wait-time WAIT_TIME 每个窗口的显示时间(以秒为单位)。默认为 1。
–no-pin-memory 是否禁用pin_memory数据加载器中的选项。
–tta 是否启用(TTA)。如果配置文件具有tta_pipeline和tta_model字段,请使用它们来确定 TTA 转换以及如何合并 TTA 结果。否则,通过平均分类分数来使用翻转 TTA。
–launcher {none,pytorch,slurm,mpi},作业启动器的选项。
使用多个 GPU 进行测试
bash ./tools/dist_test.sh ${CONFIG_FILE} ${CHECKPOINT_FILE} ${GPU_NUM} [PY_ARGS]
7、下游任务
检测
对于检测任务,请使用 MMDetection。首先,确保你已经安装了MIM,它也是 OpenMMLab 的一个项目。
pip install openmim
mim install 'mmdet>=3.0.0rc0'
训练
安装后,您可以通过简单的命令运行MMDetection。
# distributed version
bash tools/benchmarks/mmdetection/mim_dist_train_c4.sh ${CONFIG} ${PRETRAIN} ${GPUS}
bash tools/benchmarks/mmdetection/mim_dist_train_fpn.sh ${CONFIG} ${PRETRAIN} ${GPUS}
# slurm version
bash tools/benchmarks/mmdetection/mim_slurm_train_c4.sh ${PARTITION} ${CONFIG} ${PRETRAIN}
bash tools/benchmarks/mmdetection/mim_slurm_train_fpn.sh ${PARTITION} ${CONFIG} ${PRETRAIN}
${CONFIG}:直接使用MMDetection中的配置文件路径。对于某些算法,我们还有一些修改过的配置文件,可以在benchmarks相应算法文件夹下的文件夹中找到。您还可以从头开始编写配置文件。
${PRETRAIN}:预训练的模型文件。
${GPUS}:您要用于训练的 GPU 数量。我们默认采用 8 个 GPU 来执行检测任务。
bash ./tools/benchmarks/mmdetection/mim_dist_train_c4.sh \
configs/byol/benchmarks/mask-rcnn_r50-c4_ms-1x_coco.py \
https://download.openmmlab.com/mmselfsup/1.x/byol/byol_resnet50_16xb256-coslr-200e_in1k/byol_resnet50_16xb256-coslr-200e_in1k_20220825-de817331.pth 8
测试
训练后,您还可以运行以下命令来测试您的模型。
# distributed version
bash tools/benchmarks/mmdetection/mim_dist_test.sh ${CONFIG} ${CHECKPOINT} ${GPUS}
# slurm version
bash tools/benchmarks/mmdetection/mim_slurm_test.sh ${PARTITION} ${CONFIG} ${CHECKPOINT}
${CONFIG}:直接使用MMDetection中的配置文件名。对于某些算法,我们还有一些修改过的配置文件,可以在benchmarks相应算法文件夹下的文件夹中找到。您还可以从头开始编写配置文件。
${CHECKPOINT}:您要测试的微调检测模型。
${GPUS}:您要用于测试的 GPU 数量。我们默认采用 8 个 GPU 来执行检测任务。
bash ./tools/benchmarks/mmdetection/mim_dist_test.sh \
configs/byol/benchmarks/mask-rcnn_r50_fpn_ms-1x_coco.py \
https://download.openmmlab.com/mmselfsup/1.x/byol/byol_resnet50_16xb256-coslr-200e_in1k/byol_resnet50_16xb256-coslr-200e_in1k_20220825-de817331.pth 8
分割
对于语义分割任务,我们使用 MMSegmentation。首先,确保你已经安装了MIM,它也是 OpenMMLab 的一个项目。
pip install openmim
mim install 'mmsegmentation>=1.0.0rc0'
模型训练
安装后,您可以使用简单的命令运行 MMSegmentation。
# distributed version
bash tools/benchmarks/mmsegmentation/mim_dist_train.sh ${CONFIG} ${PRETRAIN} ${GPUS}
# slurm version
bash tools/benchmarks/mmsegmentation/mim_slurm_train.sh ${PARTITION} ${CONFIG} ${PRETRAIN}
${CONFIG}:直接使用MMSegmentation中的配置文件路径。对于某些算法,我们还有一些修改过的配置文件,可以在benchmarks相应算法文件夹下的文件夹中找到。您还可以从头开始编写配置文件。
${PRETRAIN}:预训练的模型文件。
${GPUS}:您要用于训练的 GPU 数量。我们默认采用 4 个 GPU 来执行分割任务。
bash ./tools/benchmarks/mmsegmentation/mim_dist_train.sh \
configs/benchmarks/mmsegmentation/voc12aug/fcn_r50-d8_4xb4-20k_voc12aug-512x512.py \
https://download.openmmlab.com/mmselfsup/1.x/byol/byol_resnet50_16xb256-coslr-200e_in1k/byol_resnet50_16xb256-coslr-200e_in1k_20220825-de817331.pth 4
模型测试
训练后,您还可以运行以下命令来测试您的模型。
# distributed version
bash tools/benchmarks/mmsegmentation/mim_dist_test.sh ${CONFIG} ${CHECKPOINT} ${GPUS}
# slurm version
bash tools/benchmarks/mmsegmentation/mim_slurm_test.sh ${PARTITION} ${CONFIG} ${CHECKPOINT}
${CONFIG}:直接使用MMSegmentation中的配置文件名。对于某些算法,我们还有一些修改过的配置文件,可以在benchmarks相应算法文件夹下的文件夹中找到。您还可以从头开始编写配置文件。
${CHECKPOINT}:您要测试的微调分割模型。
${GPUS}:您要用于测试的 GPU 数量。我们默认采用 4 个 GPU 来执行分割任务。
bash ./tools/benchmarks/mmsegmentation/mim_dist_test.sh fcn_r50-d8_4xb4-20k_voc12aug-512x512.py \
https://download.openmmlab.com/mmselfsup/1.x/byol/byol_resnet50_16xb256-coslr-200e_in1k/byol_resnet50_16xb256-coslr-200e_in1k_20220825-de817331.pth 4