postgresql
pg中提取字符串中字段
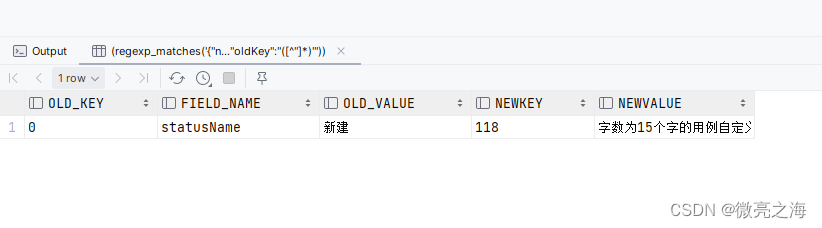
SELECT
(regexp_matches('{"newValue":"字数为15个字的用例自定义状态","oldKey":"0","fieldName":"statusName","newKey":"118","oldValue":"新建"}', '"oldKey":"([^"]*)"'))[1] AS old_key,
(regexp_matches('{"newValue":"字数为15个字的用例自定义状态","oldKey":"0","fieldName":"statusName","newKey":"118","oldValue":"新建"}', '"fieldName":"([^"]*)"'))[1] AS field_name,
(regexp_matches('{"newValue":"字数为15个字的用例自定义状态","oldKey":"0","fieldName":"statusName","newKey":"118","oldValue":"新建"}', '"oldValue":"([^"]*)"'))[1] AS old_value,
(regexp_matches('{"newValue":"字数为15个字的用例自定义状态","oldKey":"0","fieldName":"statusName","newKey":"118","oldValue":"新建"}', '"newKey":"([^"]*)"'))[1] AS newKey,
(regexp_matches('{"newValue":"字数为15个字的用例自定义状态","oldKey":"0","fieldName":"statusName","newKey":"118","oldValue":"新建"}', '"newValue":"([^"]*)"'))[1] AS newValue
查看进程
SELECT *
FROM pg_stat_activity
WHERE state = 'active'
;
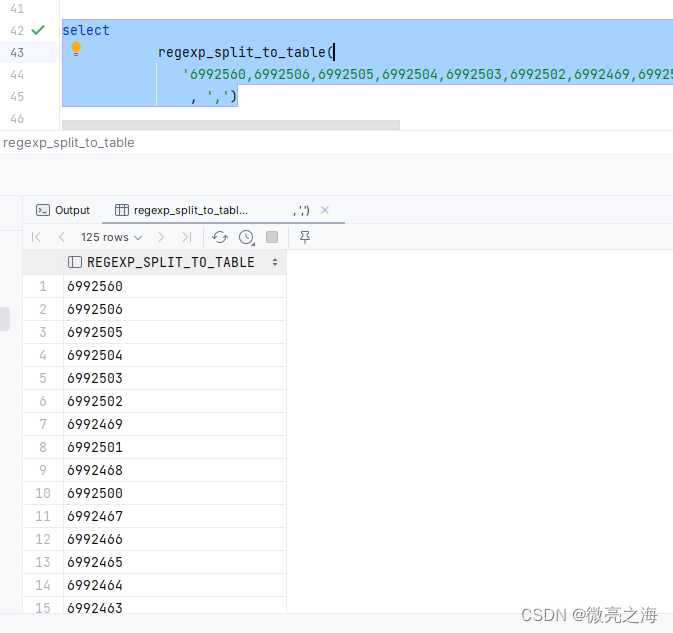
一行转一列,类似侧视图功能
select
regexp_split_to_table(
'6992560,6992506,6992505,6992504,6992503,6992502,6992469,6992501,6992468,6992500,6992467,6992466,6992465,6992464,6992463,6992462,6992461,6992509,6992508,6992507,6992517,6992516,6992515,6992119,6992514,6992118,6992513,6992117,6992512,6992116,6992479,6992511,6992115,6992478,6992510,6992114,6992477,6992113,6992476,6992112,6992475,6992111,6992474,6992473,6992472,6992471,6992470,6992519,6992518,6992528,6992527,6992526,6992525,6992129,6992524,6992128,6992523,6992127,6992489,6992522,6992126,6992488,6992521,6992125,6992487,6992520,6992124,6992486,6992123,6992122,6992485,6992121,6992484,6992120,6992483,6992482,6992481,6992480,6992490,6992529,6992539,6992538,6992537,6992536,6992535,6992534,6992533,6992499,6992532,6992498,6992531,6992135,6992497,6992530,6992134,6992496,6992133,6992495,6992132,6992494,6992131,6992493,6992130,6992492,6992491,6992549,6992548,6992547,6992546,6992545,6992544,6992543,6992542,6992541,6992540,6992559,6992558,6992557,6992556,6992555,6992554,6992553,6992552,6992551,6992550'
, ',')
一列转一行,需要分组(组内 一列转一行),不分组就是整列数据
类似hive中
select id,concat_ws(',',collect_list(name)) names from ts group by id;
pg
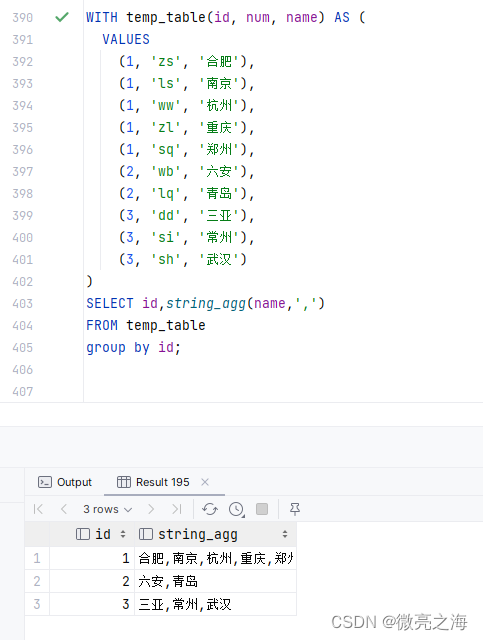
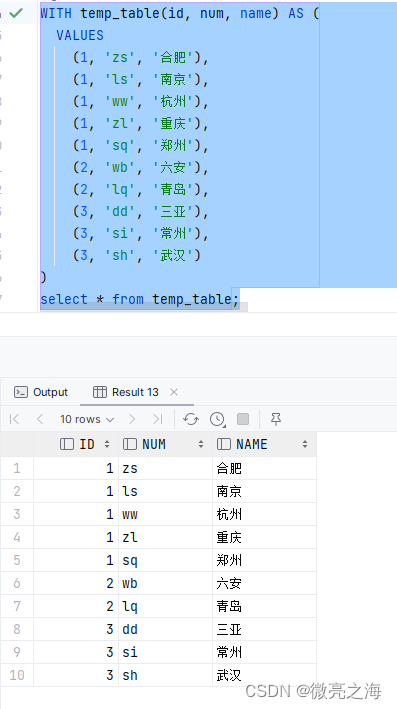
WITH temp_table(id, num, name) AS (
VALUES
(1, 'zs', '合肥'),
(1, 'ls', '南京'),
(1, 'ww', '杭州'),
(1, 'zl', '重庆'),
(1, 'sq', '郑州'),
(2, 'wb', '六安'),
(2, 'lq', '青岛'),
(3, 'dd', '三亚'),
(3, 'si', '常州'),
(3, 'sh', '武汉')
)
SELECT id,string_agg(name,',')
FROM temp_table
group by id;
filter函数
select
count(*) filter ( where date >= to_date('2019-01-01','yyyy-MM-dd') and date < to_date('2020-01-01','yyyy-MM-dd') )
,count(*) filter (where date >= to_date('2020-01-01','yyyy-MM-dd') and date < to_date('2021-01-01','yyyy-MM-dd') )
,count(*) filter (where date >= to_date('2021-01-01','yyyy-MM-dd') )
from modeltest.order_info;
--同样效果
select
count(case when date >= to_date('2019-01-01','yyyy-MM-dd') and date < to_date('2020-01-01','yyyy-MM-dd') then 1 else null end)
,count(case when date >= to_date('2020-01-01','yyyy-MM-dd') and date < to_date('2021-01-01','yyyy-MM-dd') then 1 else null end)
,count(case when date >= to_date('2021-01-01','yyyy-MM-dd') then 1 else null end)
from modeltest.order_info;
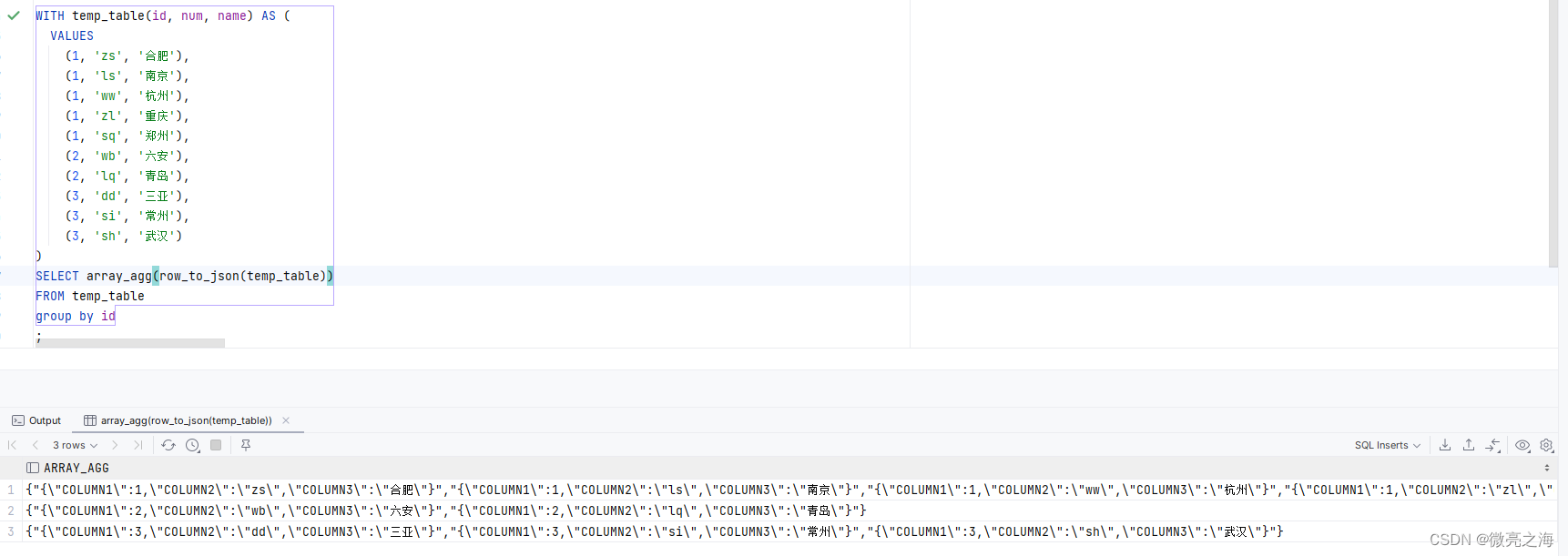
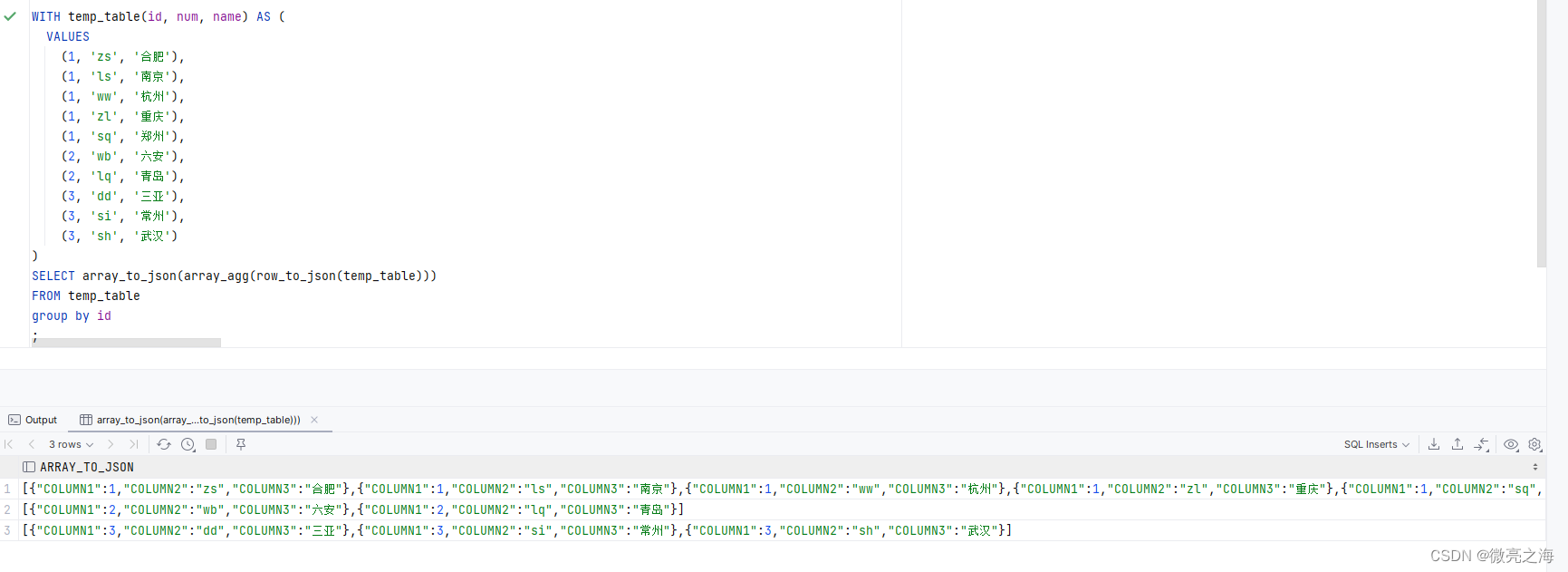
row_to_json
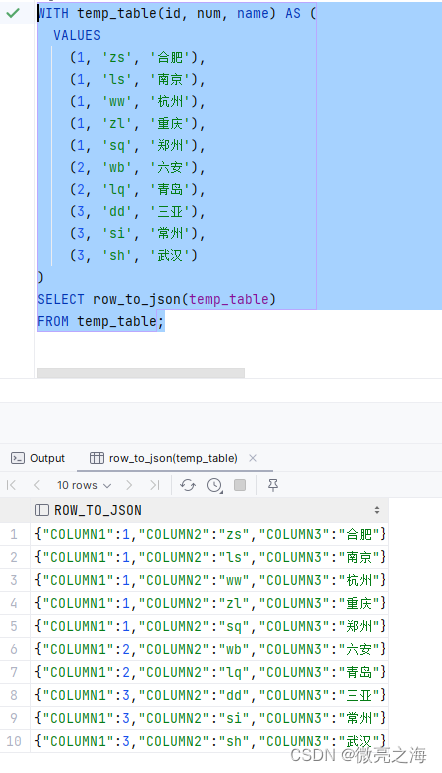
将查询结果 temp_table 使用 row_to_json 函数转换为 JSON 格式的行对象,然后使用 array_agg 函数将 同组(group by)内的所有行对象聚合为一个数组,最后使用 array_to_json 函数将数组转换为 JSON 格式的数据