SQL学习
【参考文献】
本·福达:《SQL必知必会》,第5版,刘晓霞、 钟鸣译,北京:人民邮电出版社,2020年
基本概念
DBMS:database management system(数据库管理系统)
提取信息
SELECT
SQL应用案例:提取北宋政区
在CHGIS的数据中,需要提取北宋(960-1127)时期的政区。画分析草图,可以知道,如果按照Begin Year 和 End Year ( 用a b c d e f表示)作为筛选标准,一共有6种可能的情况,其中4种情况的年代符合北宋的时间区间。
b1<960 and 960 <b2 < 1127
c1<960 and 1127<c2
960<d1<1127 and 960<d2<1127
960<e1<1127 and 1127<e2
不符合的是:
a1<a2<960 (北宋前的政区)
1127<f1<f2 (北宋后的政区)
根据以上的分析,写如下SQL语句。
SELECT * FROM v6_time_pref_utf_wgs84 WHERE:
("BEG_YR" <=960) AND (960 <= "END_YR" <=1127)但是,该句语法错误。原因在于,(960 <= "END_YR" <=1127) 这个得分开写,用AND连接,否则机器识别不了。更正后如下:
("BEG_YR" <=960) AND (960 <= "END_YR" AND "END_YR" <=1127);
("BEG_YR" <=960) AND (1127 <= "END_YR" );
(960 <= "BEG_YR" AND "BEG_YR" <=1127) AND (960 <= "END_YR" AND "END_YR" <=1127 );
(960 <= "BEG_YR" AND "BEG_YR" <=1127) AND ( "END_YR" >= 1127 );
于是,运行这个语句。
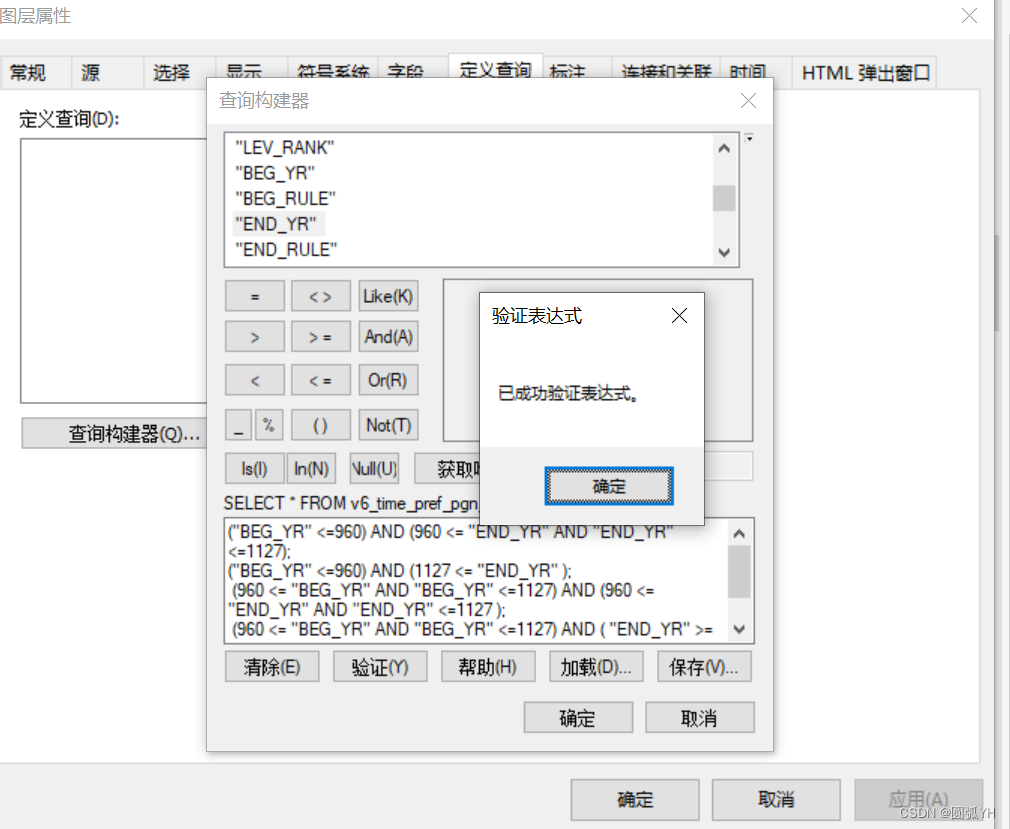
在Arcgis图层的查询构建器中运行,成功验证了表达式。运行后效果如下:
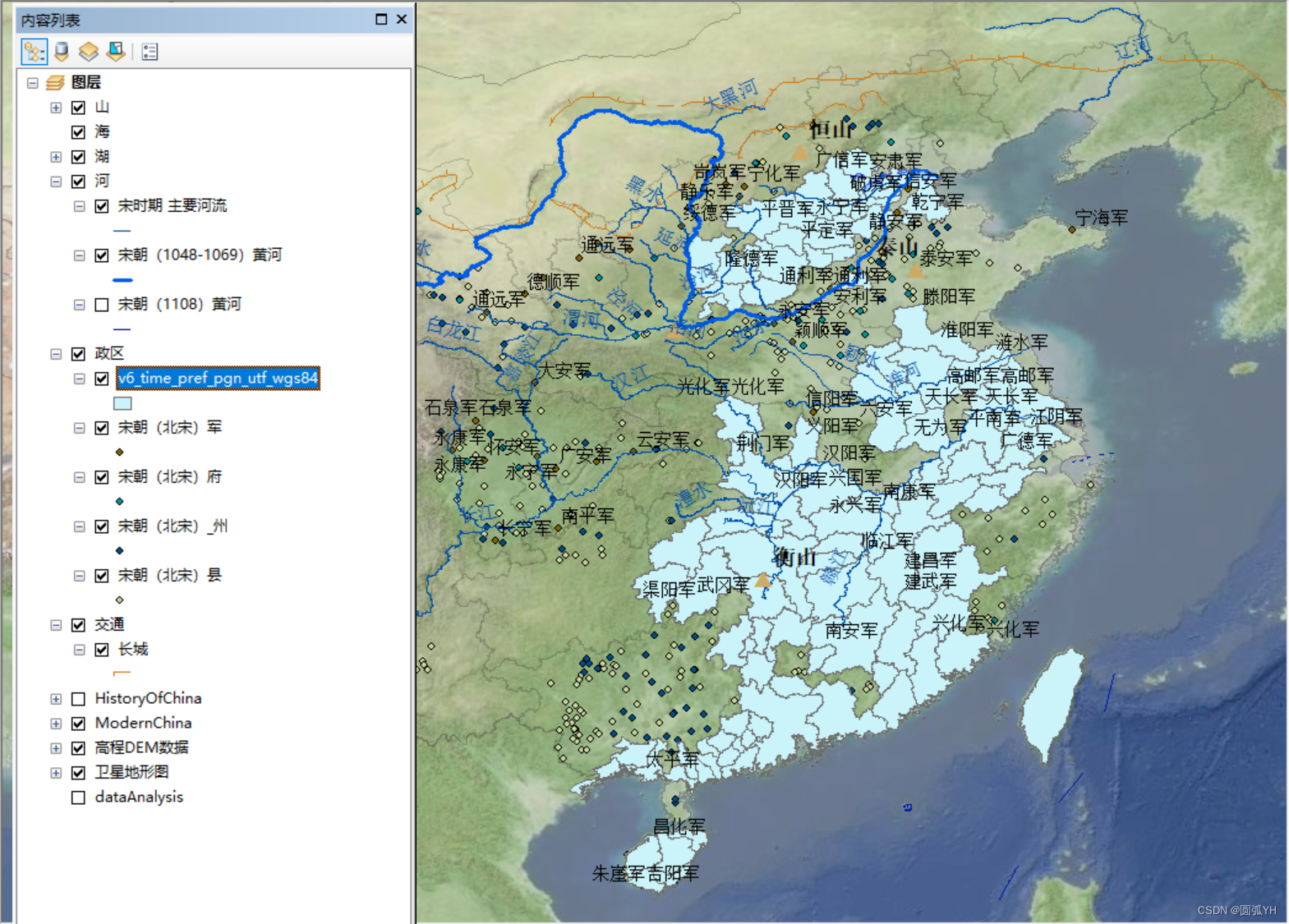
不过,这个政区显然不全。所以,需要回顾,考虑一下问题出在哪里。
可能的原因是CHGIS的数据本来就不全,有遗漏。
逻辑结构
AND 和OR
如下代码所示:
((("BEG_YR" <=960) AND (960 <= "END_YR" AND "END_YR" <=1127)) OR (("BEG_YR" <=960) AND (1127 <= "END_YR" )) OR
( (960 <= "BEG_YR" AND "BEG_YR" <=1127) AND (960 <= "END_YR" AND "END_YR" <=1127 )) OR
( (960 <= "BEG_YR" AND "BEG_YR" <=1127) AND ( "END_YR" >= 1127 ))) AND "NAME_CH" LIKE '%军'
用多重括号,将筛选条件并列在一起。
然后,可以加上AND语句,构建新的筛选条件。
如图所示,这是带以“军”为名称的宋代行政区。
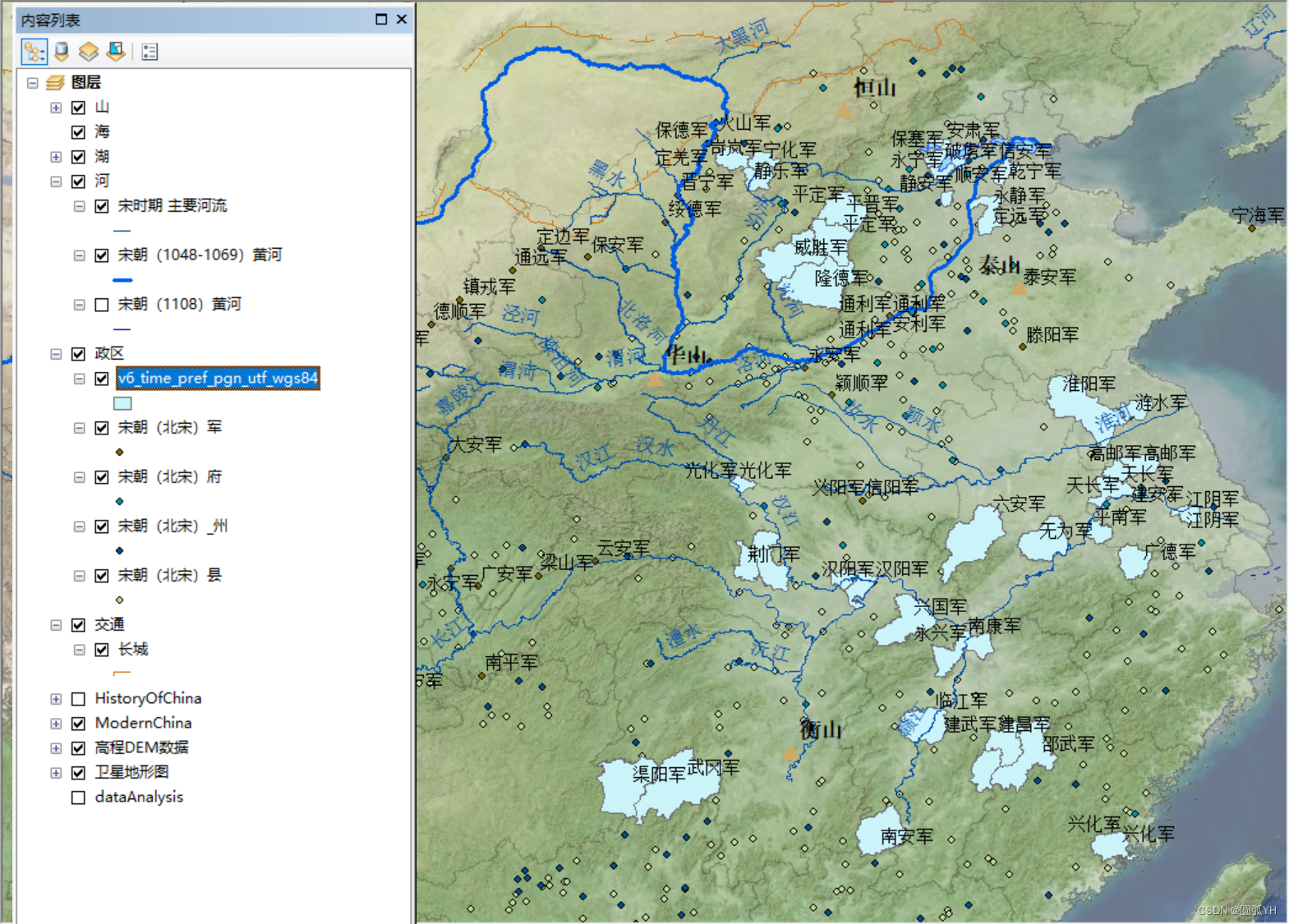
用同样的这段代码,获得所有的宋代“军”级行政位置点。
((("BEG_YR" <=960) AND (960 <= "END_YR" AND "END_YR" <=1127)) OR (("BEG_YR" <=960) AND (1127 <= "END_YR" )) OR
( (960 <= "BEG_YR" AND "BEG_YR" <=1127) AND (960 <= "END_YR" AND "END_YR" <=1127 )) OR
( (960 <= "BEG_YR" AND "BEG_YR" <=1127) AND ( "END_YR" >= 1127 ))) AND "NAME_CH" LIKE '%军'
效果如下图所示
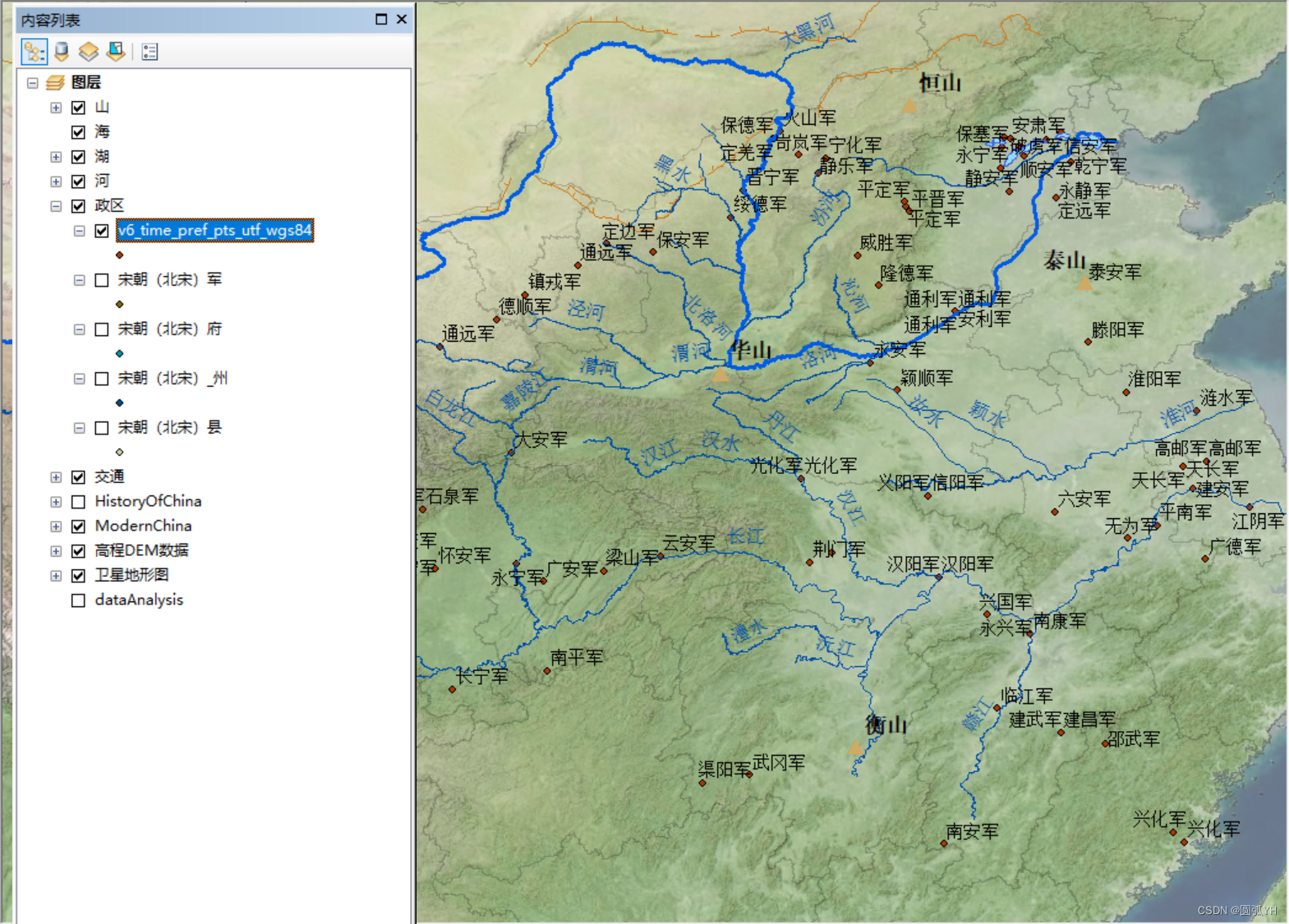
但是,下面遇到的问题是,存在同名现象,或者某些字条信息,虽然时间不同,但是名字相同。需要将同名的只保留一个。如何操作?
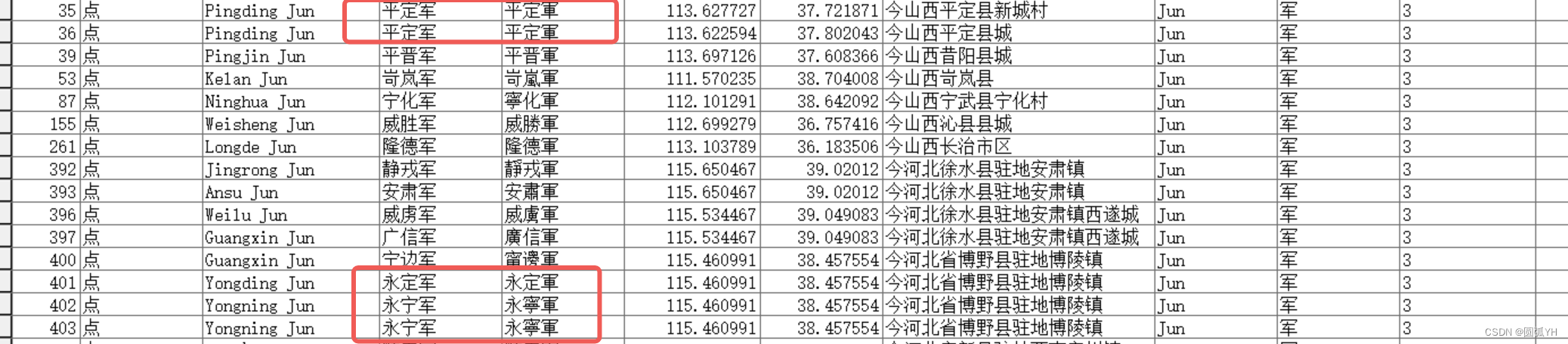
SQL应用:提取唐代政区
如下代码:
((("BEG_YR" <=618) AND (960 <= "END_YR" AND "END_YR" <=907)) OR (("BEG_YR" <=618) AND (907 <= "END_YR" )) OR
( (618 <= "BEG_YR" AND "BEG_YR" <=907) AND (618 <= "END_YR" AND "END_YR" <=907 )) OR
( (618 <= "BEG_YR" AND "BEG_YR" <=907) AND ( "END_YR" >= 907 ))) AND "NAME_CH" LIKE '%州'SQL应用:提取西汉政区
((("BEG_YR" <=-202) AND (-202 <= "END_YR" AND "END_YR" <=8)) OR (("BEG_YR" <=-202) AND (8 <= "END_YR" )) OR
( (-202 <= "BEG_YR" AND "BEG_YR" <=8) AND (-202 <= "END_YR" AND "END_YR" <=8 )) OR
( (-202 <= "BEG_YR" AND "BEG_YR" <=8) AND ( "END_YR" >= 8 ))) AND "NAME_CH" LIKE '%县'属性表去重
问题:
Arcgis软件的一个屬性表名称为“唐朝县”,属性表中有多个字段,其中一个字段为"NAME_CH",该字段下面有一些同名的数据,这些同名的数据,只需要保留一个,请问如何操作?如何写SQL语言?
DISTINCT
下面想将SQL语句进一步优化:
SELECT DISTINCT "NAME_CH" FROM v6_time_pref_utf_wgs84 WHERE:
("BEG_YR" <=960) AND (960 <= "END_YR" AND "END_YR" <=1127);
("BEG_YR" <=960) AND (1127 <= "END_YR" );
(960 <= "BEG_YR" AND "BEG_YR" <=1127) AND (960 <= "END_YR" AND "END_YR" <=1127 );
(960 <= "BEG_YR" AND "BEG_YR" <=1127) AND ( "END_YR" >= 1127 );但是,遗憾的是该表达式是有错误的。
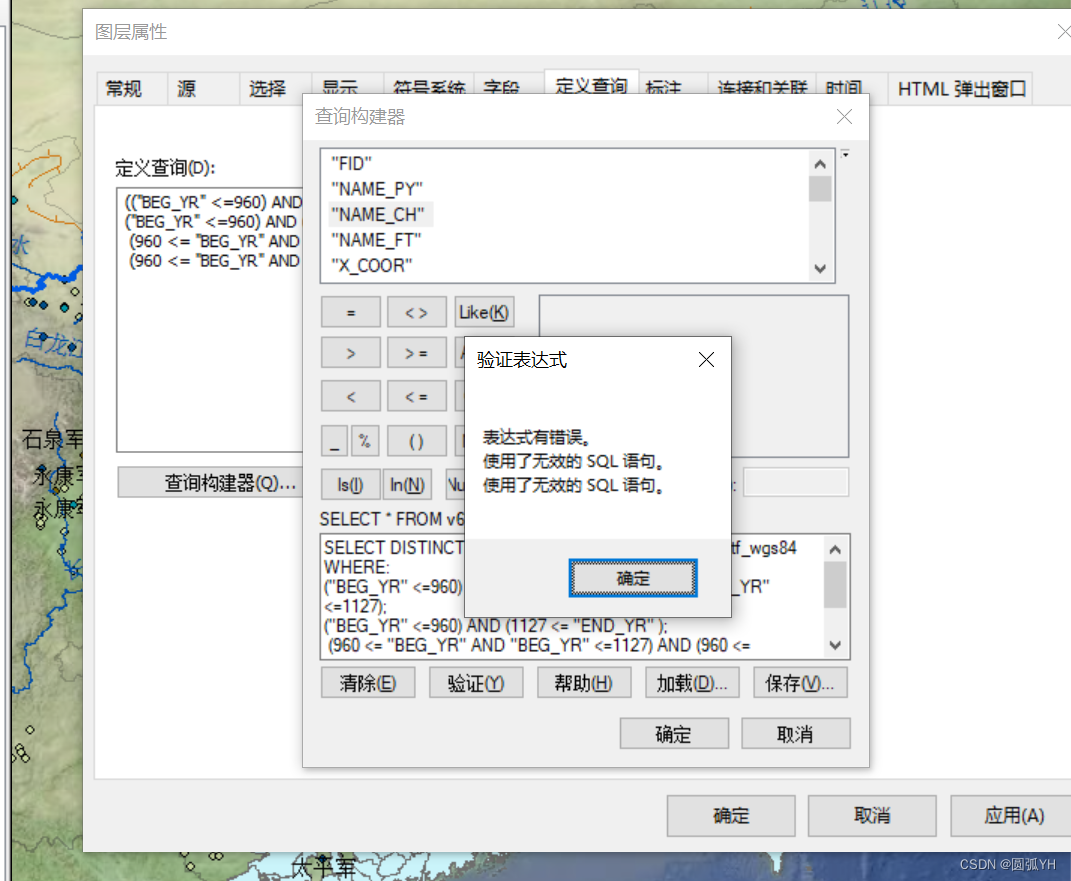
错误的原因,可能是Arcgis查询构建器的界面中,已经有了该语句:
SELECT * FROM v6_time_pref_utf_wgs84 WHERE:所以,就不能再使用另外的SELECT语句。
SELECT DISTINCT "NAME_CH" FROM v6_time_pref_utf_wgs84 WHERE:查询构建器
针对这个情况,只需要在“图层属性”界面中,输入SQL语言,点击“确定”后,出现“查询构建器”,这个时候,SQL第一句就变为输入的句子了。
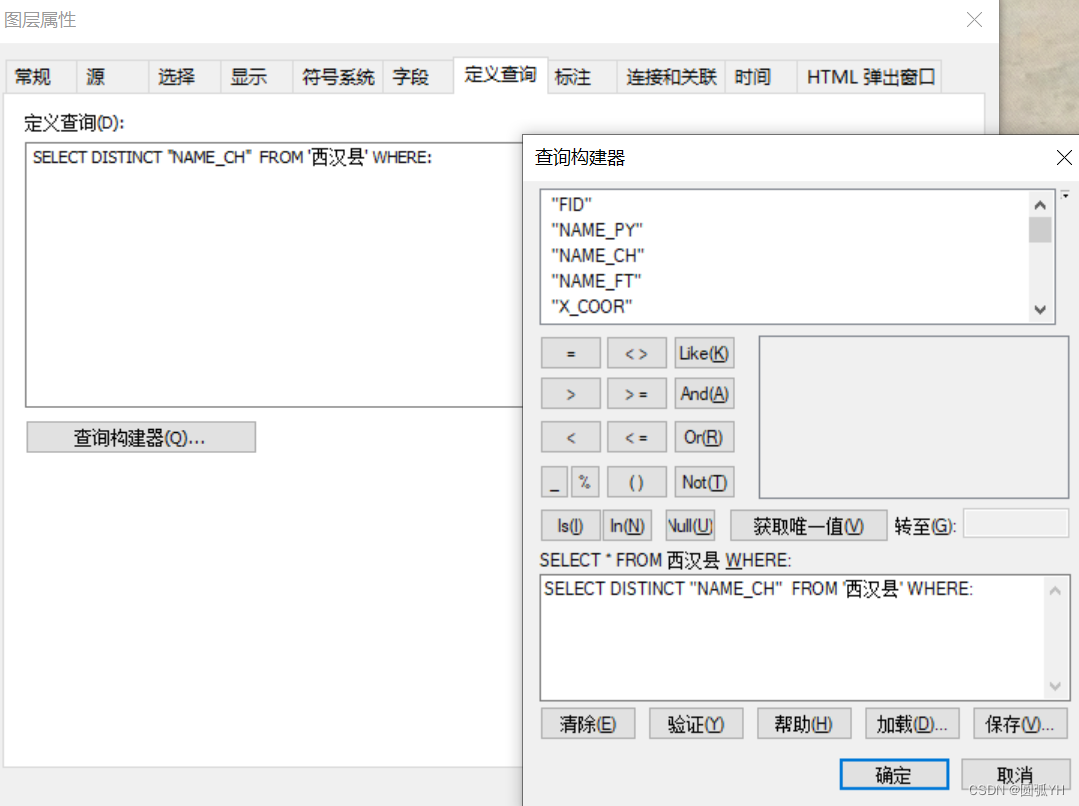
但是,在操作的时候,发现语句是有问题的,无法执行。
现在,将问题明确一下:
Arcgis屬性表中,有多个字段,其中一个字段为"NAME_CH",该字段下面有一些同名的数据,这些同名的数据,只需要保留一个,请问如何操作?如何写SQL语言?
实际上,最简单的是这样子的:
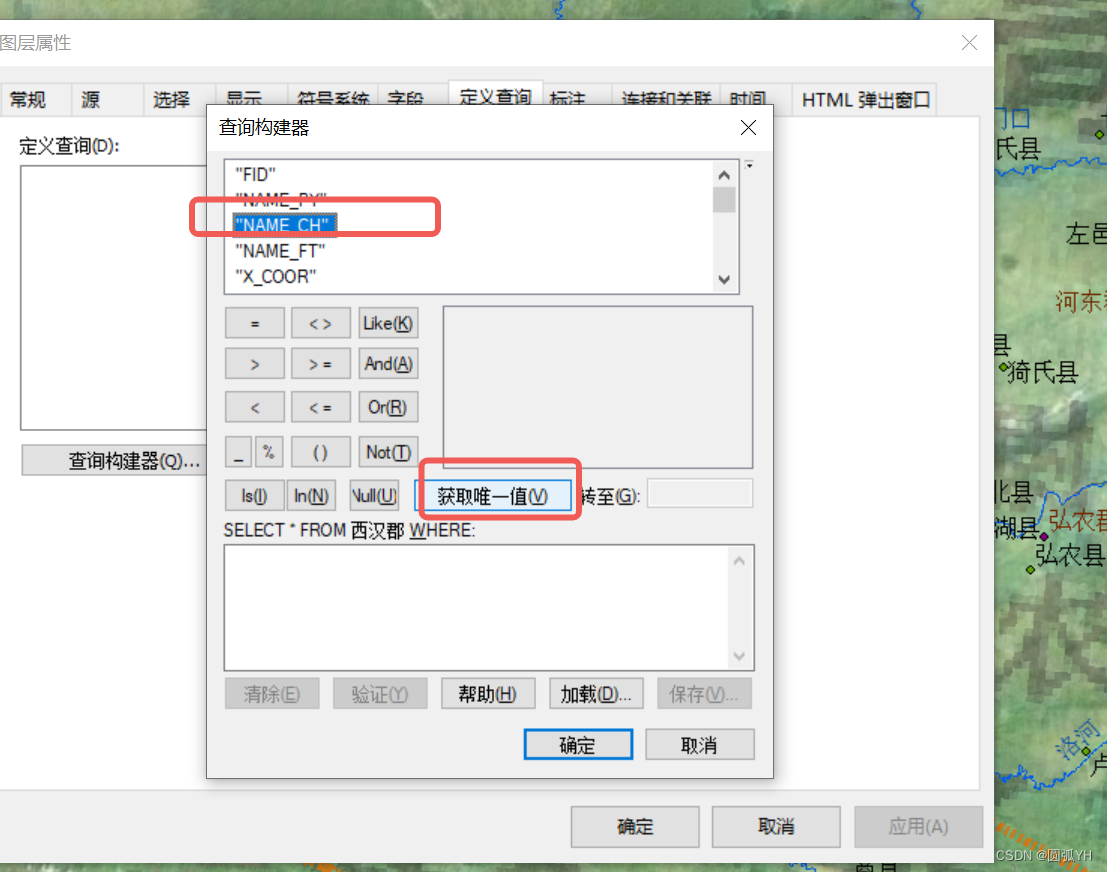
选中该字段,然后点击“获取唯一值”。
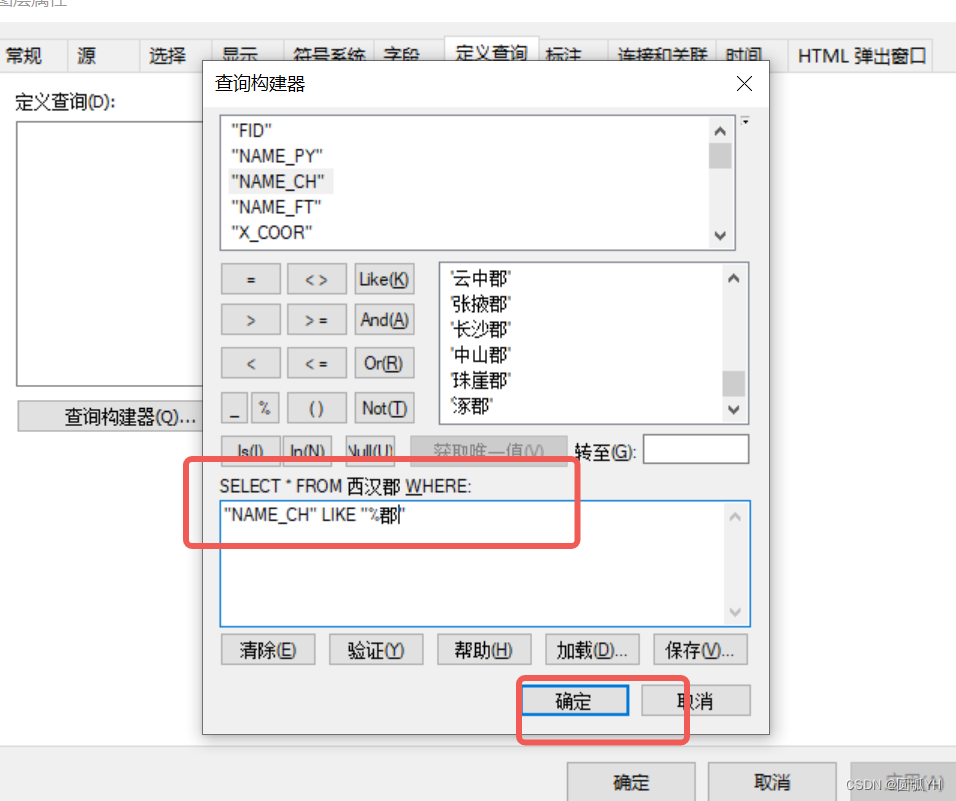
然后输入常规的SQL语言,这个时候再点击“确定”,这个时候,就能把众多在“NAME_CH”字段同名数据,只保留一个。
但是这个又失败了。
SELECT DISTINCT 'NAME_CH' FROM 唐朝县 WHERE:
"NAME_CH" LIKE '县'Python安装包 arcpy
Arcgis软件的一个屬性表名称为“唐朝县”,属性表中有多个字段,其中一个字段为"NAME_CH",该字段下面有一些同名的数据,这些同名的数据,只需要保留一个,请问如何操作?如何在Arcgis中写python语言?
于是,可以尝试用Python的办法。
import arcpy
# 设置你的工作空间(即,你的数据所在的位置)
arcpy.env.workspace = "E:\DH\Map\【历史】政区\唐朝时期 政区\唐朝县.shp"
# 输入和输出表
input_table = "E:\DH\Map\【历史】政区\唐朝时期 政区\唐朝县.shp"
output_table = "唐朝县_cleaned.shp"
# 定义一个函数来检查重复的行并删除
def remove_duplicates(input_table, output_table):
# 创建一个查询,选择NAME_CH字段的所有唯一值
query = "NAME_CH IN (SELECT DISTINCT NAME_CH FROM 唐朝县)"
# 使用查询创建新的输出表
arcpy.CopyRows_management(input_table, output_table, where_clause=query)
# 调用函数进行清理
remove_duplicates(input_table, output_table)
以上是人工智能生成的代码。
精简后如下:
import arcpy
arcpy.env.workspace = "E:\DH\Map\【历史】政区\唐朝时期 政区\唐朝县.shp"
input_table = "E:\DH\Map\【历史】政区\唐朝时期 政区\唐朝县.shp"
output_table = "唐朝县_cleaned.shp"
def remove_duplicates(input_table, output_table):
query = "NAME_CH IN (SELECT DISTINCT NAME_CH FROM 唐朝县)"
arcpy.CopyRows_management(input_table, output_table, where_clause=query)
remove_duplicates(input_table, output_table)
但是,运行后,并没有成功。
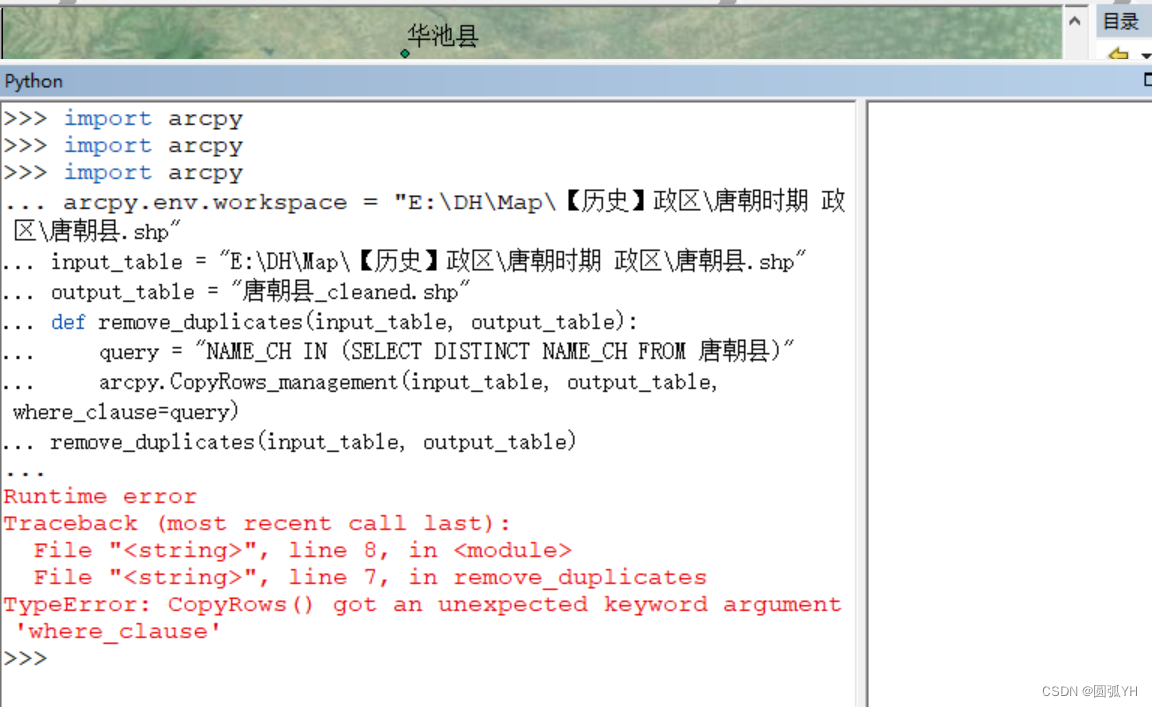
运行之后,出现效果如上。于是又询问文心一言,修正后的代码如下:
import arcpy
arcpy.env.workspace = "E:\DH\Map\【历史】政区\唐朝时期 政区\唐朝县.shp"
input_table = "E:\DH\Map\【历史】政区\唐朝时期 政区\唐朝县.shp"
output_table = "唐朝县_cleaned.shp"
def remove_duplicates(input_table, output_table):
query = "NAME_CH IN (SELECT DISTINCT NAME_CH FROM 唐朝县)"
arcpy.CopyRows_management(input_table, output_table,query)
remove_duplicates(input_table, output_table)
然后,得到了新的表格。但是,里面的数据并没有变化。

那么如何进一步优化呢?显然,需要想一些更好的方法。
【心得】