【论文阅读】Swin-transformer网络结构详解
引言
之前的Transformer主要应用在NLP领域,从ViT开始在应用在视觉领域后,也逐渐出现更多Transformer在视觉领域的研究工作,今天介绍的Swin-transformer可以作为计算机视觉上的一种通用backbone。
优点
-
提出了一种层级式网络结构,解决视觉图像的多尺度问题。
-
提出了Shifted Windows,极大降低了transformer的计算复杂度。
-
可以广泛应用到所有计算机视觉领域(包括分类任务、分割任务、目标检测任务等)
解决的问题
-
和NLP领域不同,视觉领域同类的物体,在不同图像上/同意图像上的尺度会相差很大。
-
相较于文本,图像的尺寸过大,计算复杂度更高。
创新处
-
使用任意尺度的输入,计算复杂度和图像大小是线性关系而非平方级增长。
-
在小窗口内计算自注意力,特征图大小递减。好处是当窗口大小固定时,自注意力的复杂度就固定,复杂度和尺度呈线性关系,利用了图像的局部性的先验知识。
-
局部性指的是同一个物体不同部位或者语义相近的不同物体,大概率会出现在相邻的地方,所以对视觉任务来说,在小窗口内计算自注意力是合理的,在全局计算会造成计算的浪费。
和ViT区别

整体架构
网络架构
下图是Swin-transformer的网络架构:
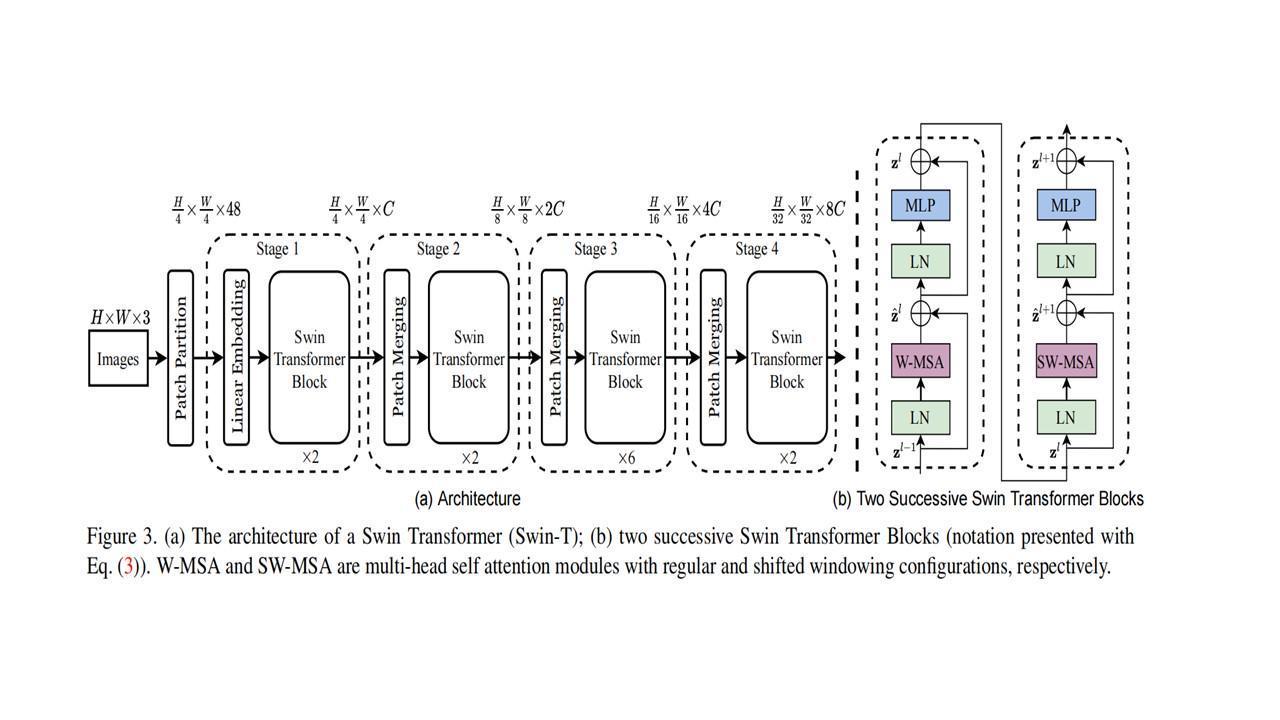
整体架构分为多个stage,输入图片大小为H*W*3;(默认为224*224*3)
-
经过patch partition操作将输入图片打成多个patch;patch size=4*4,则操作后得到的图片大小为56*56*48;
-
stage1:包括一个Linear Embedding操作和2个swi-transformer block,C代表一个超参数,即Transformer可以接受的值,对于Swin-Tiny 网络来说,C默认为96,此时维度变成56*56*96;(transformer block块不改变图片大小)
这里的patch partition操作和Linear Embedding操作相当于ViT的Linear Projection操作,而在代码中,利用一次卷积操作即可完成。
-
stage2:包括Patch Merging和2个block,Patch Merging相当于pixel shuffle的逆操作;具体如下图所示,此时维度为28*28*192;对于Patch Merging操作整体来说,空间维度减半,通道数量×2,这样和卷积神经网络完全对等;
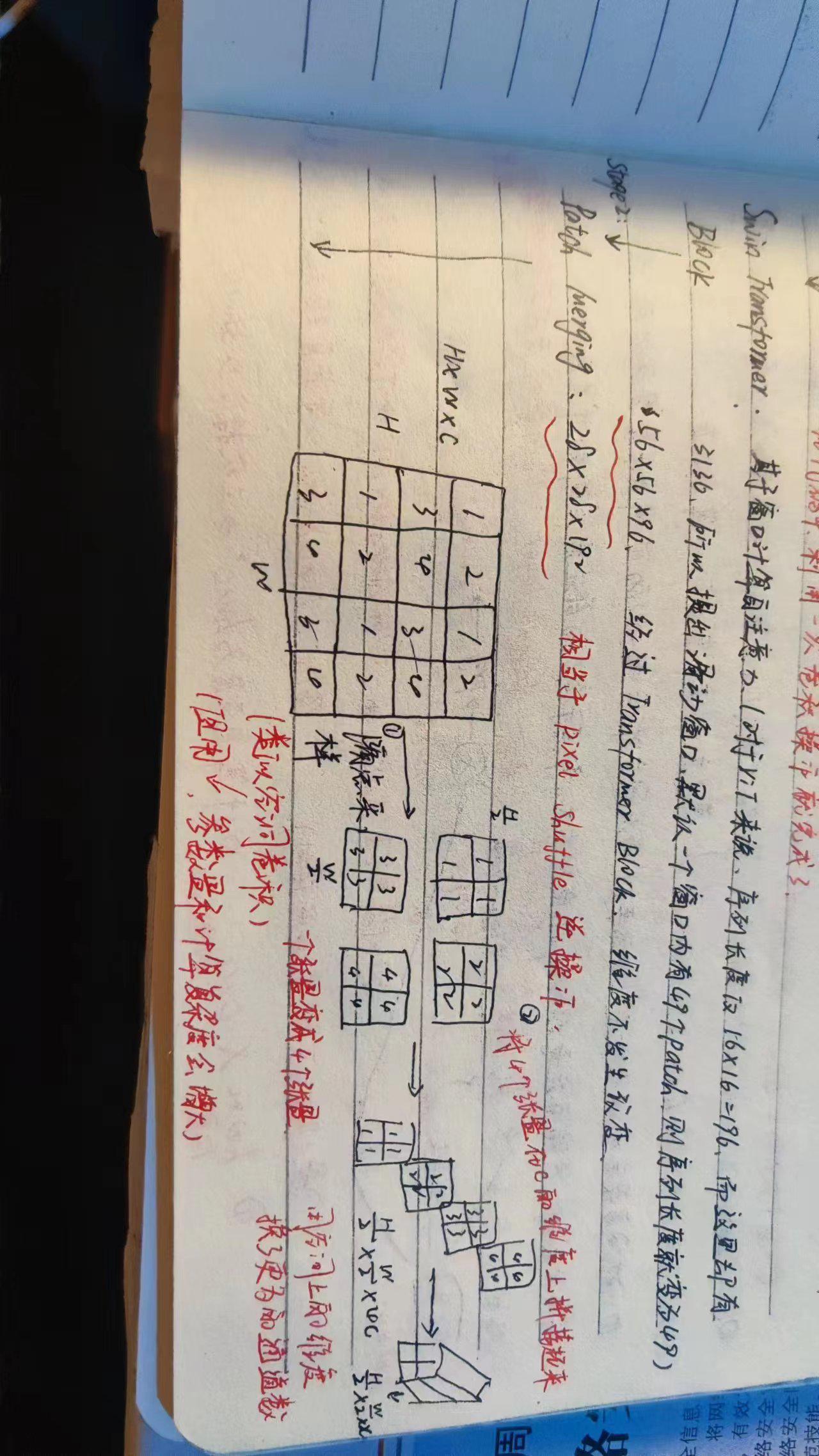
-
stage3:重复stage2,维度为14*14*384;
-
stage4:重复stage2,维度为7*7*768.
上述架构图中b图是两个连续的Swin Transformer Block。一个Swin Transformer Block由一个带两层MLP的shifted window based MSA组成。在每个MSA模块和每个MLP之前使用LayerNorm(LN)层,并在每个MSA和MLP之后使用残差连接。两层属于一个组合使用,所以stage中的block块是双数。
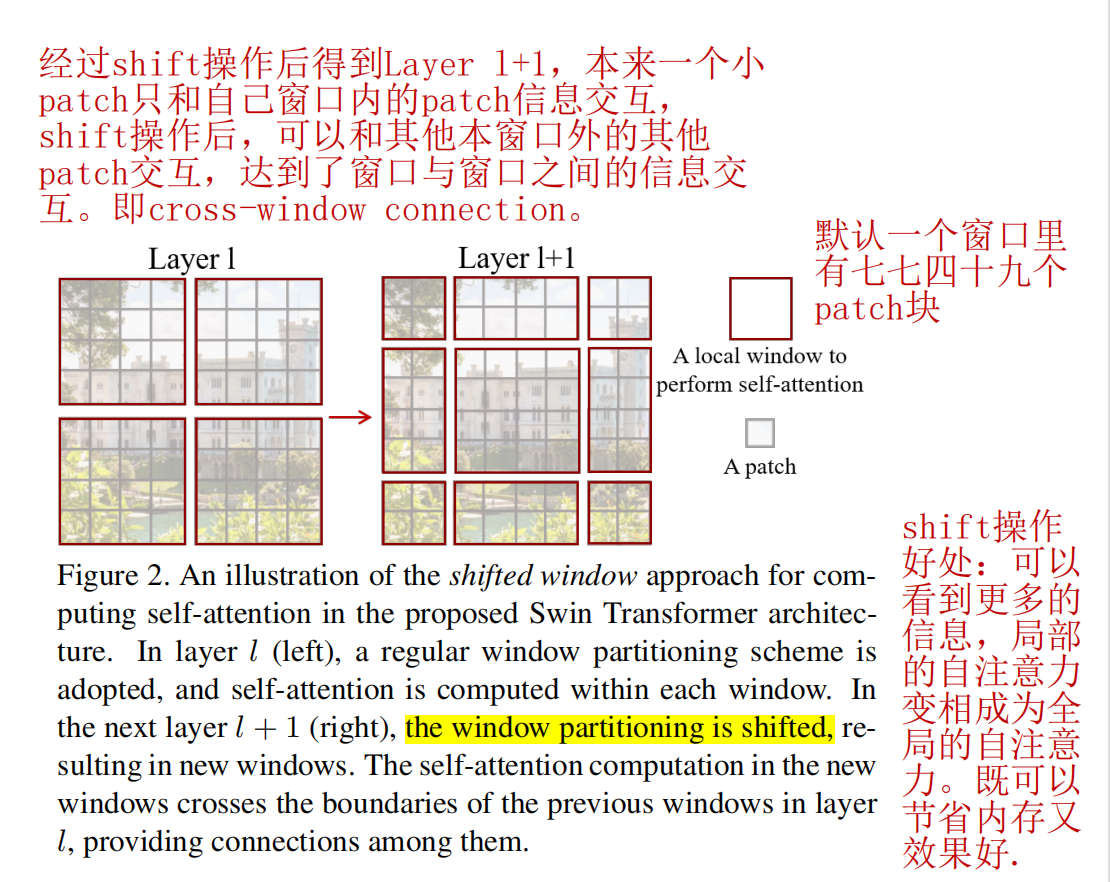
滑动窗口(shifted Windows)
论文中一个主要亮点是提出了滑动窗口的概念。
同时给出普通MSA和基于窗口的W-MSA(计算复杂度)的比较:
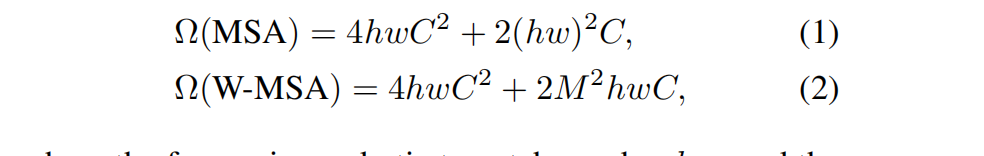
W-MSA虽然降低了计算复杂度,但是不重合的window之间缺乏信息交流,于是进一步引入shifted window partition:一种基于掩码的方式来解决不同window的信息交流问题,该方法在连续的Swin Transformer块中的两个Swin Transformer Block之间交替进行。
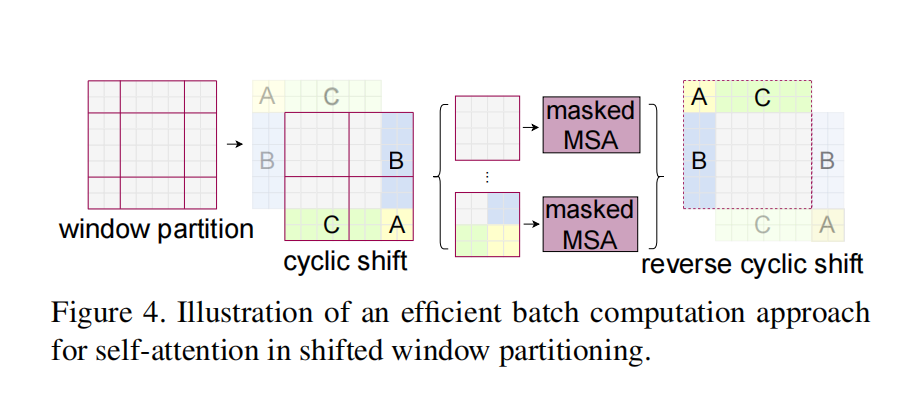
移动窗口达到了窗口与窗口之间的通信,但窗口数量增多(从原来的4个到之后的9个)且增多后各个窗口元素大小不同,而基于掩码的方式可以很好的解决这一问题。经过循环移位后在切分四宫格,则得到的还是4个窗口,再各个窗口做基于掩码的Mutil-Self Attention,最后操作是还原循环移位。
关于掩码的操作:
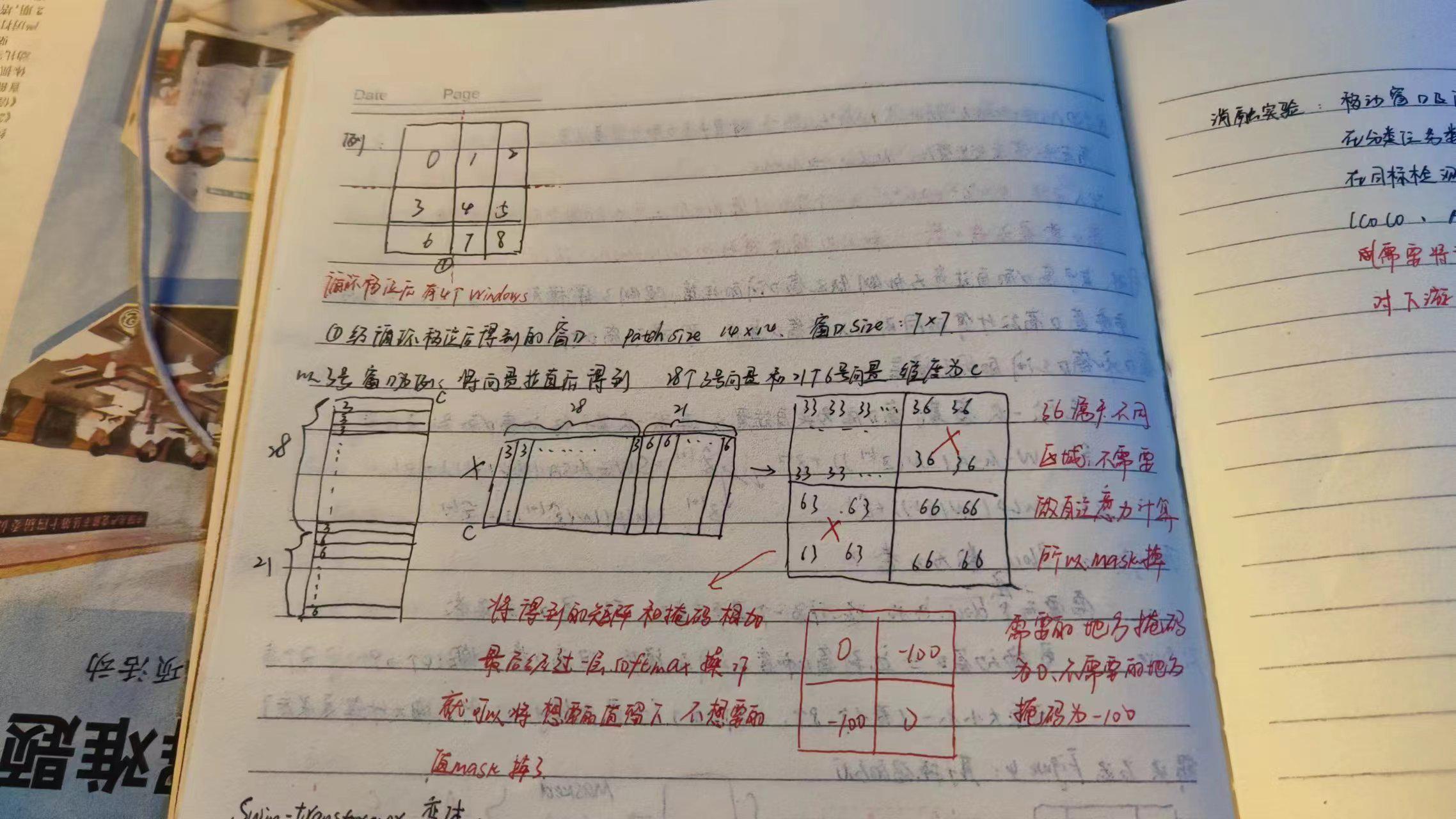
实验结果
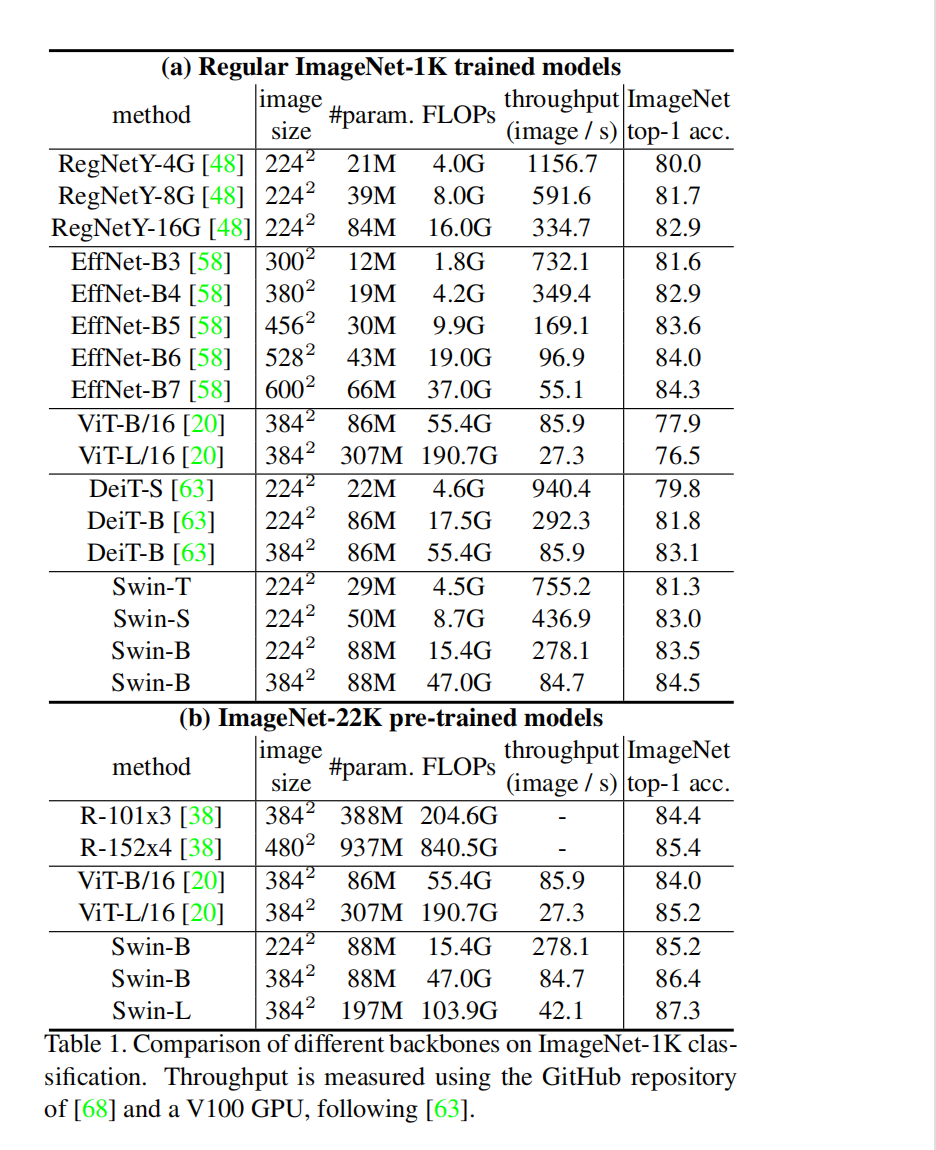
分类实验
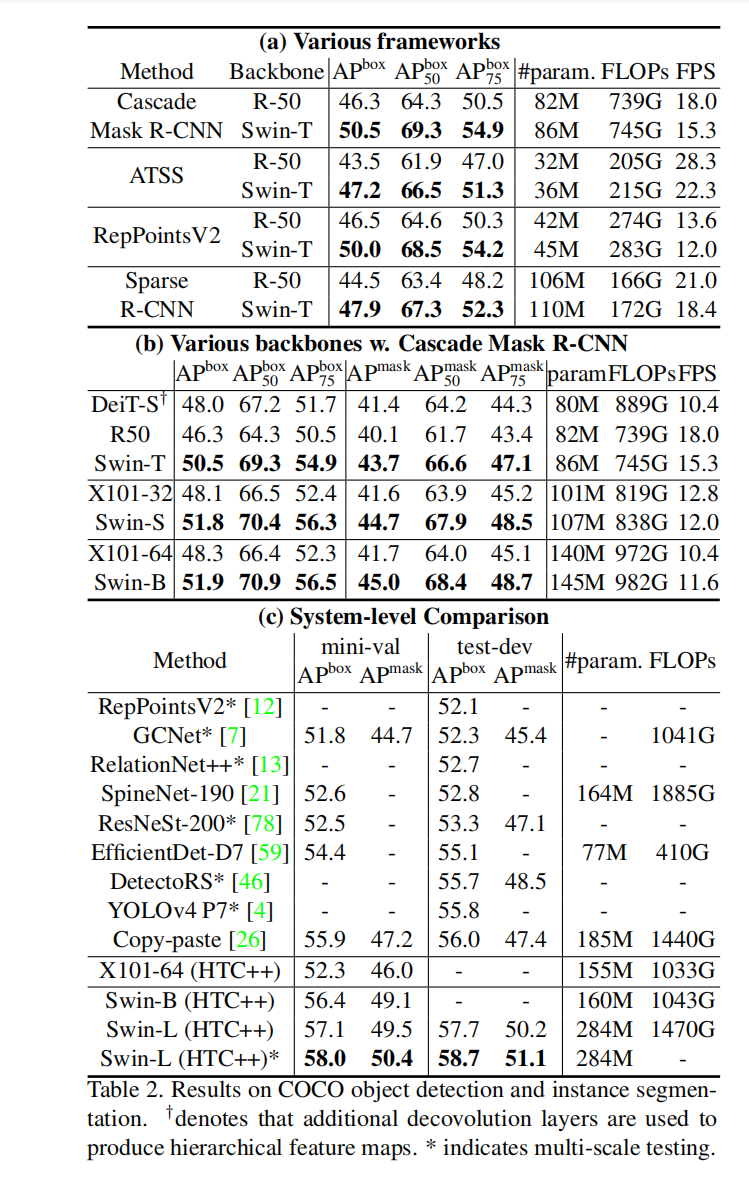
目标检测实验
语义分割实验
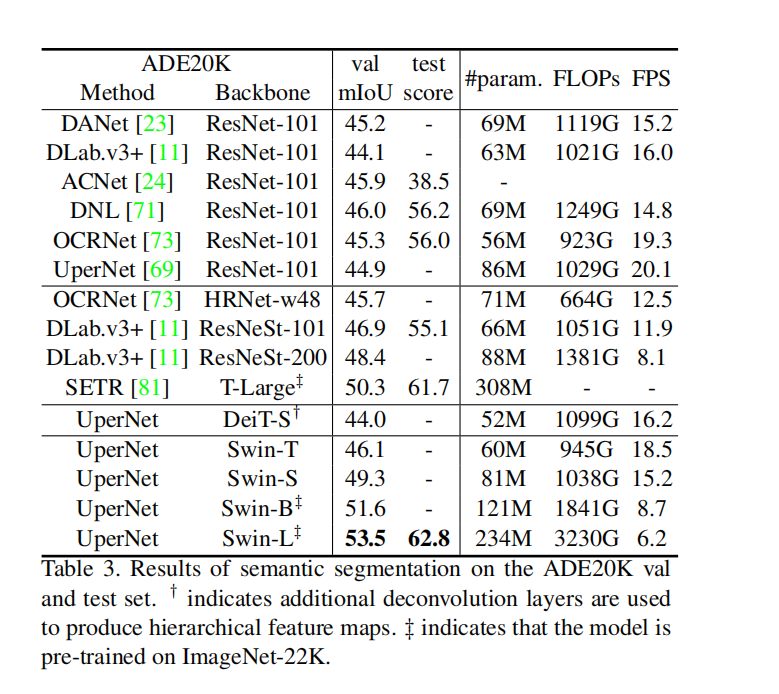
在多个任务中均可以达到很好的效果,也证明了Transformer完全可以在多个领域取代CNN。
论文地址及代码
论文:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows