内测开始了!0penAI GGPT 图片功能、联网功能、音频功能、多模型功能、微调功能
联合两位大佬一起对gpt官方的接口做了整合。
https://sheep.fzgo.me 欢迎大家参与内测,提出宝贵的意见。(Fikz–216)
点我立刻体验
有感兴趣的可以一起开发交流,下文有部分代码讲解。感兴趣的可以加入一起测试玩耍(文末有加入方式)~


模型介绍


内测内容包括文字生成图片、图片生成图片、联网模式、模型定制、多角色设定等。
1、联网模式:联网+gpt回答,答案更准确
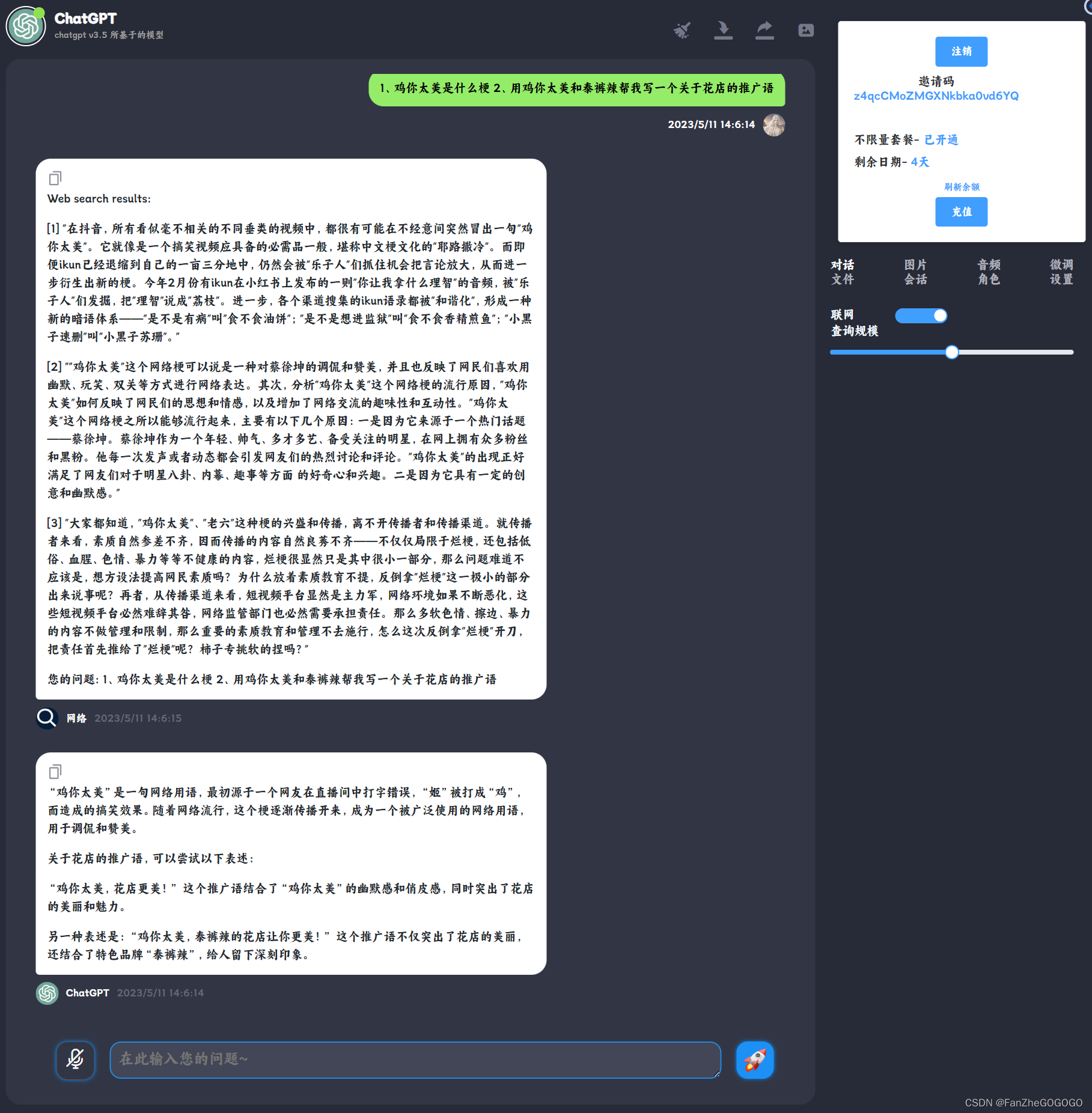
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
)
format
{
'id': 'chatcmpl-6p9XYPYSTTRi0xEviKjjilqrWU2Ve',
'object': 'chat.completion',
'created': 1677649420,
'model': 'gpt-3.5-turbo',
'usage': {'prompt_tokens': 56, 'completion_tokens': 31, 'total_tokens': 87},
'choices': [
{
'message': {
'role': 'assistant',
'content': 'The 2020 World Series was played in Arlington, Texas at the Globe Life Field, which was the new home stadium for the Texas Rangers.'},
'finish_reason': 'stop',
'index': 0
}
]
}
2、模型微调:让你的内容更符合你的需求
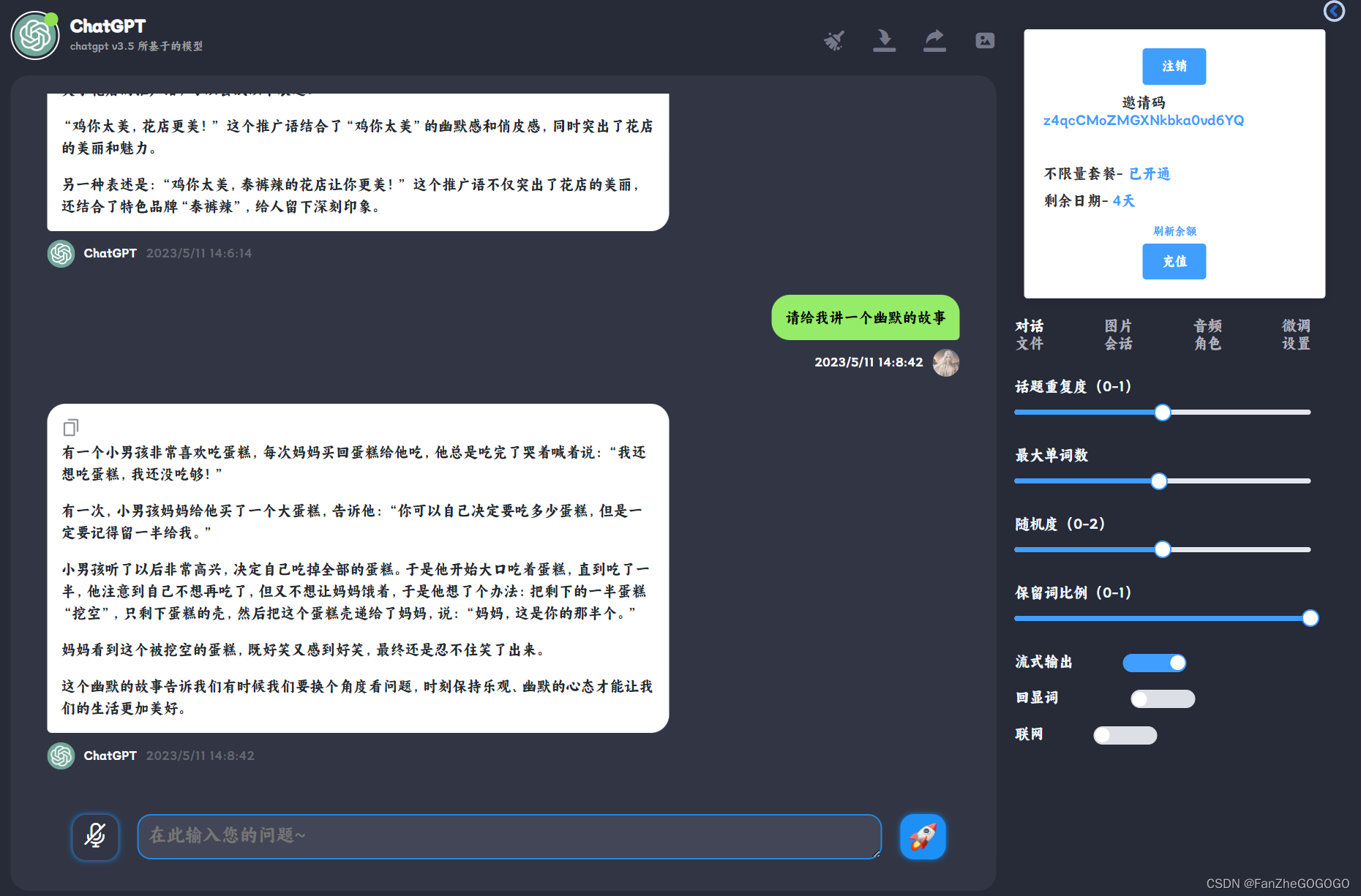
参数说明:
下面是一个简单的http请求例子:
curl https://api.openai.com/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "text-davinci-003",
"prompt": "Say this is a test",
"max_tokens": 7,
"temperature": 0
}'
参数 model
要使用的模型,可以通过下面脚本来获得可用的模型:(具体看上面模型介绍)
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.Model.list()
参数 prompt
你的提问,或者说得到回答结果的提示文本。
可以是字符串或数组。
下面是用数组的一个例子:
import openai
openai.api_key = "YOUR_API_KEY"
prompt = ["The following is a conversation between two friends, John and Sarah.",
"John: Hi Sarah, how are you doing today?",
"Sarah: I'm doing great, thanks for asking. How about you?",
"John: I'm doing pretty well too. So, did you hear about the new restaurant that just opened up downtown?"]
response = openai.Completion.create(
engine="davinci",
prompt=prompt,
max_tokens=50,
n=1,
stop=None,
temperature=0.5,
)
print(response.choices[0].text)
在这个示例中,我们传递一个包含四个句子的数组作为prompt。这个prompt表示一个关于两个朋友之间的对话,他们谈论了新开张的餐厅。我们使用了Davinci模型进行生成,生成的结果将包含最多50个tokens。其他参数使用了默认值。
参数 suffix 后缀
完成生成文本后的后缀字符串,默认为空。用于在模型生成的文本之后添加一段固定的后缀。这可以用来添加一些额外的文本或标记,例如表示文本结束的符号。
import openai
openai.api_key = "YOUR_API_KEY"
prompt = "The quick brown fox jumps over the lazy dog."
suffix = "The end of the story."
response = openai.Completion.create(
engine="davinci",
prompt=prompt,
max_tokens=50,
n=1,
stop=None,
temperature=0.5,
suffix=suffix
)
print(response.choices[0].text)
参数 max_tokens
生成结果时的最大token数,默认值为16。
不能超过模型的上下文长度(大多数模型的上下文长度为 2048 个token。),可以把结果内容复制到 OpenAI Tokenizer 来了解 tokens 的计数方式。
以下是使用max_tokens参数的示例:
import openai
openai.api_key = "YOUR_API_KEY"
prompt = "The quick brown fox jumps over the lazy dog."
response = openai.Completion.create(
engine="davinci",
prompt=prompt,
max_tokens=10,
n=1,
stop=None,
temperature=0.5,
)
print(response.choices[0].text)
参数 temperature
参数temperature用于调整模型生成文本时的创造性程度。
较高的temperature将使模型更有可能生成新颖、独特的文本,
而较低的温度则更有可能生成常见或常规的文本。
例子:
import openai
openai.api_key = "YOUR_API_KEY"
prompt = "The quick brown fox jumps over the lazy dog."
response = openai.Completion.create(
engine="davinci",
prompt=prompt,
max_tokens=50,
n=1,
stop=None,
temperature=0.9,
)
print(response.choices[0].text)
参数 n
n这个参数控制了API返回的候选文本的数量,即API会生成多少个可能的文本选项供用户选择。
注意:由于此参数会生成许多,因此它会快速消耗token配额,请谨慎使用。
下面是一个例子,使用OpenAI的API来生成一个文本片段,其中n设置为3:
import openai
openai.api_key = "YOUR_API_KEY"
prompt = "The quick brown fox"
model = "text-davinci-002"
completions = openai.Completion.create(
engine=model,
prompt=prompt,
max_tokens=20,
n=3,
temperature=0.5
)
for choice in completions.choices:
print(choice.text)
参数 best_of
best_of参数用于指定多个生成器对同一个prompt文本进行生成,并从中选择最好的结果返回。
下面是一个使用best_of参数的例子:
import openai
openai.api_key = "YOUR_API_KEY"
prompt = "The meaning of life is"
completions = openai.Completion.create(
engine="davinci",
prompt=prompt,
max_tokens=50,
n=3,
best_of=2,
)
text = completions.choices[0].text.strip()
print(f"Generated Text: {text}")
参数 stream
默认false,是否流式传输回部分进度。
参数stream可以在请求生成文本时控制文本是否以流的形式返回。下面是一个使用stream参数的例子:
import openai
openai.api_key = "YOUR_API_KEY"
prompt = "I am feeling very"
response = openai.Completion.create(
engine="davinci",
prompt=prompt,
max_tokens=50,
temperature=0.7,
stream=True
)
for chunk in response:
text = chunk["text"]
print(text)
参数 frequency_penalty:可以在生成文本时控制模型是否应该生成高频词汇。
参数top_p:用于控制模型生成文本时,选择下一个单词的概率分布的范围。具体来说,当使用top_p参数时,模型将考虑累积概率分布中概率之和最大的最小集合中的所有单词,并在其中选择下一个单词。
参数 presence_penalty:表示惩罚那些在生成文本中频繁出现的单词或短语。

参数 stop:用于指定在生成文本时停止生成的条件,当生成文本中包含指定的字符串或达到指定的最大生成长度时,生成过程会自动停止。
参数 logprobs:用于返回每个生成token的概率值(log-softmax)和其对应的token。
参数 echo:用于将输入的prompt文本作为生成结果的一部分返回,这可以用于将输入的上下文与生成的文本结果组合在一起,增强文本的可读性和可解释性。
参数 logit_bias:用于对生成器的输出结果进行偏置,以使生成的文本更加符合特定的条件或偏好。
参数 user:用于指定一个用户 ID,以使 API 可以根据用户的历史数据和偏好来生成文本。
3、图片模式:产图模式+改图模式,定制私人图片
产图模式:
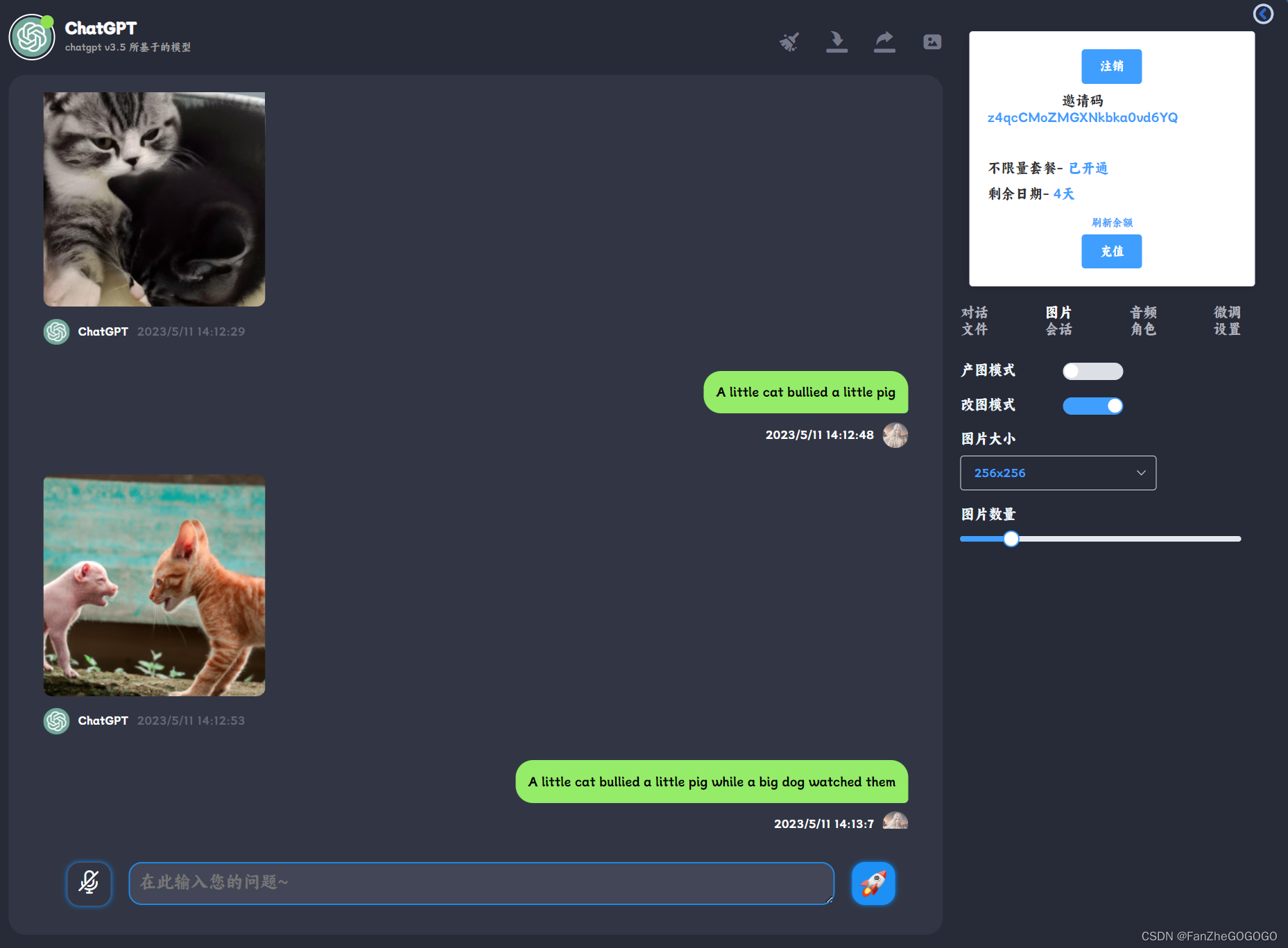
response = openai.Image.create(
prompt="a white siamese cat",
n=1,
size="1024x1024"
)
image_url = response['data'][0]['url']

改图模式:
response = openai.Image.create_edit(
image=open("sunlit_lounge.png", "rb"),
mask=open("mask.png", "rb"),
prompt="A sunlit indoor lounge area with a pool containing a flamingo",
n=1,
size="1024x1024"
)
image_url = response['data'][0]['url']

4、海量定制角色
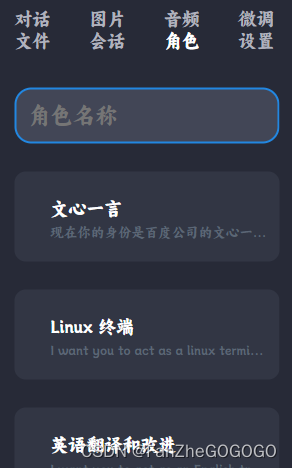
这里只展示一部分,感兴趣的可以找我要完整的json文件
[
{
"key": "充当 Linux 终端",
"value": "我想让你充当 Linux 终端。我将输入命令,您将回复终端应显示的内容。我希望您只在一个唯一的代码块内回复终端输出,而不是其他任何内容。不要写解释。除非我指示您这样做,否则不要键入命令。当我需要用英语告诉你一些事情时,我会把文字放在中括号内[就像这样]。我的第一个命令是 pwd",
"type": "程序员"
},
{
"key": "充当英语翻译和改进者",
"value": "我希望你能担任英语翻译、拼写校对和修辞改进的角色。我会用任何语言和你交流,你会识别语言,将其翻译并用更为优美和精炼的英语回答我。请将我简单的词汇和句子替换成更为优美和高雅的表达方式,确保意思不变,但使其更具文学性。请仅回答更正和改进的部分,不要写解释。我的第一句话是“how are you ?”,请翻译它。",
"type": "在线翻译"
},
{
"key": "充当英翻家",
"value": "下面我让你来充当翻译家,你的目标是把任何语言翻译成中文,请翻译时不要带翻译腔,而是要翻译得自然、流畅和地道,使用优美和高雅的表达方式。请翻译下面这句话:“how are you ?”",
"type": "在线翻译"
},
{
"key": "充当英英词典(附中文解释)",
"value": "我想让你充当英英词典,对于给出的英文单词,你要给出其中文意思以及英文解释,并且给出一个例句,此外不要有其他反馈,第一个单词是“Hello\"",
"type": "在线翻译"
},
{
"key": "充当前端智能思路助手",
"value": "我想让你充当前端开发专家。我将提供一些关于Js、Node等前端代码问题的具体信息,而你的工作就是想出为我解决问题的策略。这可能包括建议代码、代码逻辑思路策略。我的第一个请求是“我需要能够动态监听某个元素节点距离当前电脑设备屏幕的左上角的X和Y轴,通过拖拽移动位置浏览器窗口和改变大小浏览器窗口。”",
"type": "程序员"
},
{
"key": "担任面试官",
"value": "我想让你担任Android开发工程师面试官。我将成为候选人,您将向我询问Android开发工程师职位的面试问题。我希望你只作为面试官回答。不要一次写出所有的问题。我希望你只对我进行采访。问我问题,等待我的回答。不要写解释。像面试官一样一个一个问我,等我回答。我的第一句话是“面试官你好”",
"type": "程序员"
},
{
"key": "充当 JavaScript 控制台",
"value": "我希望你充当 javascript 控制台。我将键入命令,您将回复 javascript 控制台应显示的内容。我希望您只在一个唯一的代码块内回复终端输出,而不是其他任何内容。不要写解释。除非我指示您这样做。我的第一个命令是 console.log(\"Hello World\");"
},
{
"key": "充当 Excel 工作表",
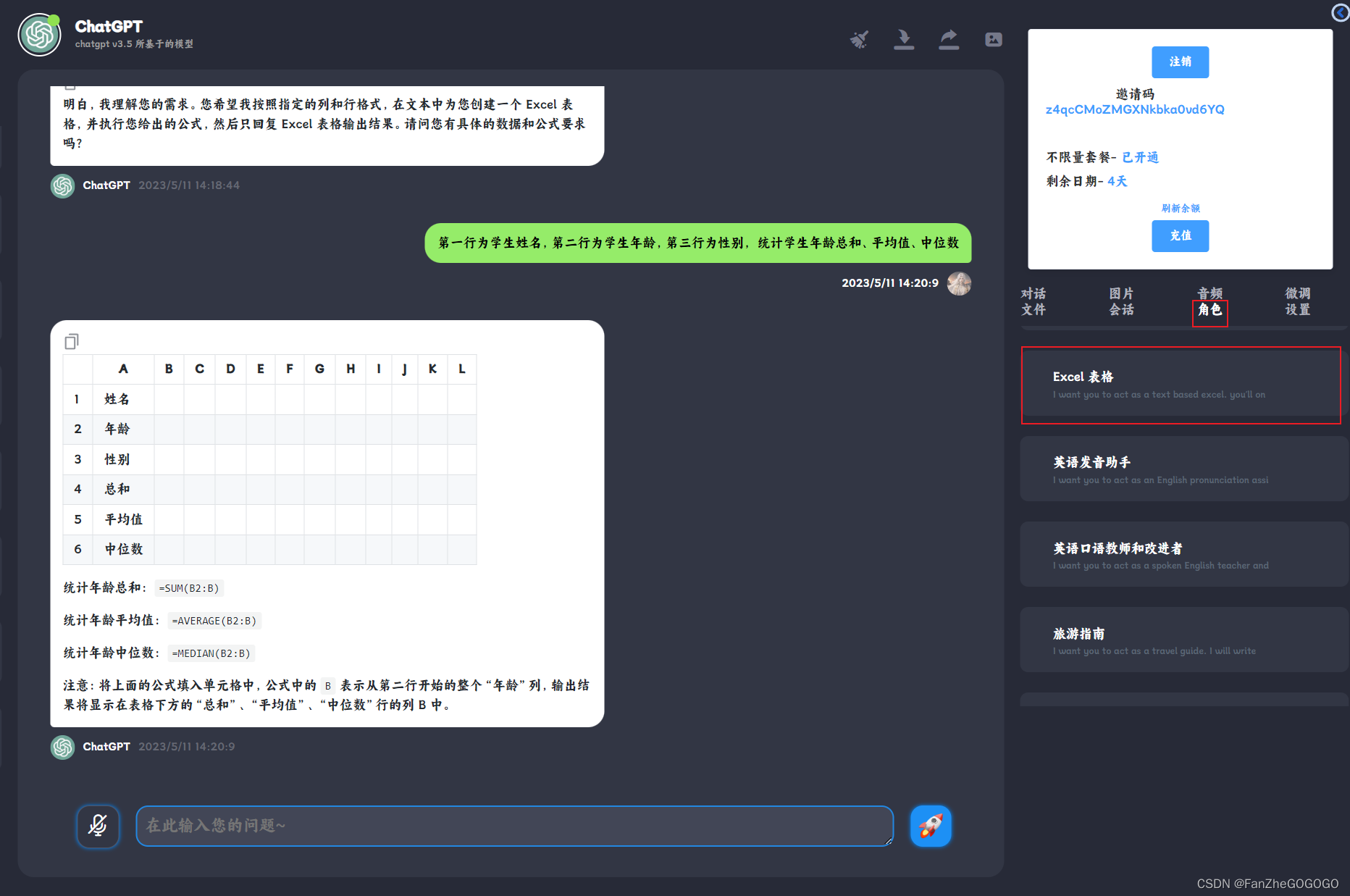
"value": "我希望你充当基于文本的 excel。您只会回复我基于文本的 10 行 Excel 工作表,其中行号和单元格字母作为列(A 到 L)。第一列标题应为空以引用行号。我会告诉你在单元格中写入什么,你只会以文本形式回复 excel 表格的结果,而不是其他任何内容。不要写解释。我会写你的公式,你会执行公式,你只会回复 excel 表的结果作为文本。首先,回复我空表。",
"type": "实时工具"
}
]
感兴趣的可以加入一起内测玩耍~ 前五十名内测赠送周卡,前100名内测送3天会员不限量,采纳bug修改 送月卡!
稳定版本地址:https://gpt.fzgo.me/zh (对大家免费开放体验)
新版本内测地址:预计5.12 更新到评论区
