中文NER方法总结
中文NER方法总结
中文命名实体识别主要有四大主流算法,序列标注,指针网络,多头标注,片段排列。
1. 四大抽取算法
1.1 序列标注
最简单的softmax+CE的方法,是一种token级别的分类任务。这种方法最简单,但没有考虑到标签之间的关系。仅仅在特征提取时,上后文是有联系的,每个时刻分类时,互不相关,这样就会出现很不合理的预测,如BB等。
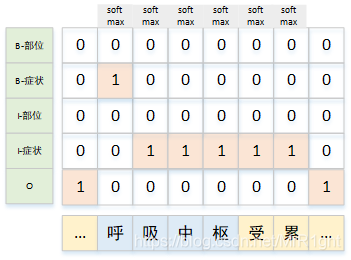
在每一个位置使用softmax进行 2 C + 1 2C+1 2C+1分类(如果使用BIO标注格式的话,C为类别总数)。
基于CRF的模型在softmax+CE上做改进,预测时会考虑标签之间的联系。CRF也存在局限性,序列标注表示为线性链的条件随机场。仅仅假设相邻的两个节点存在联系,不相邻节点时条件无关的(也就是马尔科夫随机场定义中的局部/全局的马尔科夫性)。在前端网络考虑各时刻token的关联性,在crf考虑标签的关联性,两部分分开。
1.2 指针网络
对每个span的start和end进行标记,如果是多片段抽取就转化成L个2分类(L为序列长度)。如果涉及多标签可以转化成层叠式指针网络(C个指针网络,C为类别总数)。
单片段抽取
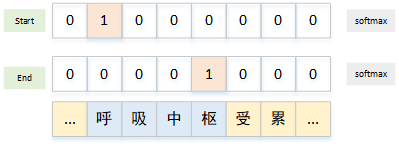
如果每个输入只有一个片段需要抽取,只需要设计两个L分类的输出分别预测start_ids和end_ids。将每个位置看做一个类别。使用softmax 搭建两个L分类。
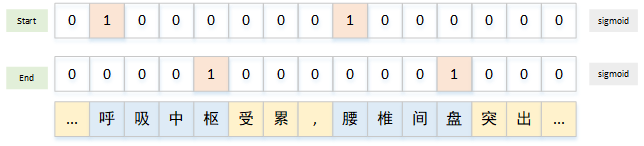
多片段抽取-sigmoid
如果一句话有多个片段需要抽取(同样的每个位置看做是一个类别),那么start和end都要分得多个标签上,也就是多任务分类。将softmax改为sigmoid即可。序列的每个位置都做0-1二分类。
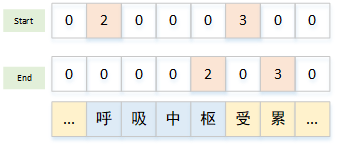
多标签抽取
上面的情形都是只有一种标签需要抽取,如上面的部位,如果同时需要抽取多个标签,则需要在序列每个token位置做
C
+
1
C+1
C+1分类(C表示总类别数)。
1.3 多头标注
多头标注(multi-head)构建一个 L × L × ( C + 1 ) L\times L\times (C+1) L×L×(C+1)的span矩阵(C类外加None)。如下图, s p a n { 呼 } { 枢 } = 1 span\{呼\}\{枢\}=1 span{呼}{枢}=1表示[呼吸中枢]是一个部位实体。 s p a n { 呼 } { 累 } = 2 span\{呼\}\{累\}=2 span{呼}{累}=2表示[呼吸中枢受累]是一个症状实体。多头标注的重点在于如何构造span矩阵,如何解决0-1标签稀疏问题。
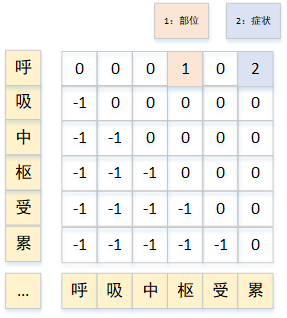
ACL2020的《Named Entity Recognition as Dependency Parsing》采取Biaffine机制构造Span矩阵;
1.4 片段排列
简单粗暴的枚举法,枚举所有可能,并对每种可能进行分类。对有长度为L的序列。共有 L ( L + 1 ) / 2 L(L+1)/2 L(L+1)/2种片段排列。分别对每一个片段进行分类。

2. Nested NER
实体嵌套是NER要解决的一大难题。多头标注和片段排列的方法天然的就支持嵌套实体的抽取,序列标注和span的方法做微小调整后也可以实现嵌套实体抽取。
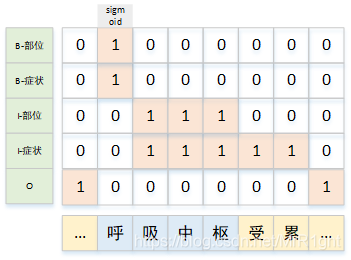
2.1 序列标注-多标签分类
序列标注是对序列每个token位置进行多分类预测。只需要将多分类改为多标签分类即可。
2.2 指针网络
层叠式指针网络
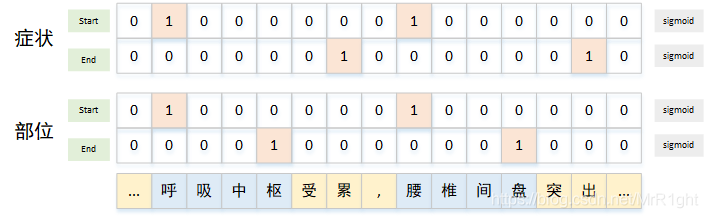
层叠式指针网络即C个针织网络。每个预测一个类别。
MRC-QA+指针标注
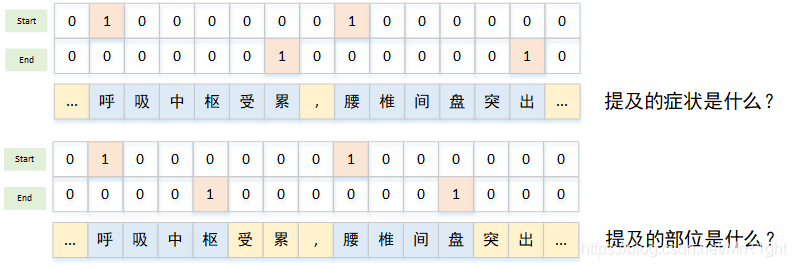
使用MRC阅读理解的方式进行抽取,构造每个实体的解释作为该类实体的query,需要抽取的原始文本作为passage上下文。预测该实体在passage中的位置。
"ORG":"找出公司,商业机构,社会组织等组织机构",
"LOC":"找出国家,城市,山川等抽象或具体的地点",
"PER":"找出真实和虚构的人名"
1、相较于序列标注的方法,MRC的好处在于引入了query这个先验知识。比如对于LOC类别,我们构造这样的query:找出国家,城市,山川等抽象或具体的地点。模型通过attention机制,对于query中的国家,城市,山川词汇学习到了地点的关注信息,加入到passage中的实体信息捕捉中。
2、很好的解决了实体嵌套问题,同时论文还提出了loss:span_loss(据测试效果不好)。