深度学习基础学习-深度可分离卷积
这里仅仅介绍自己关于这方面的了解,大佬绕道
1 普通卷积
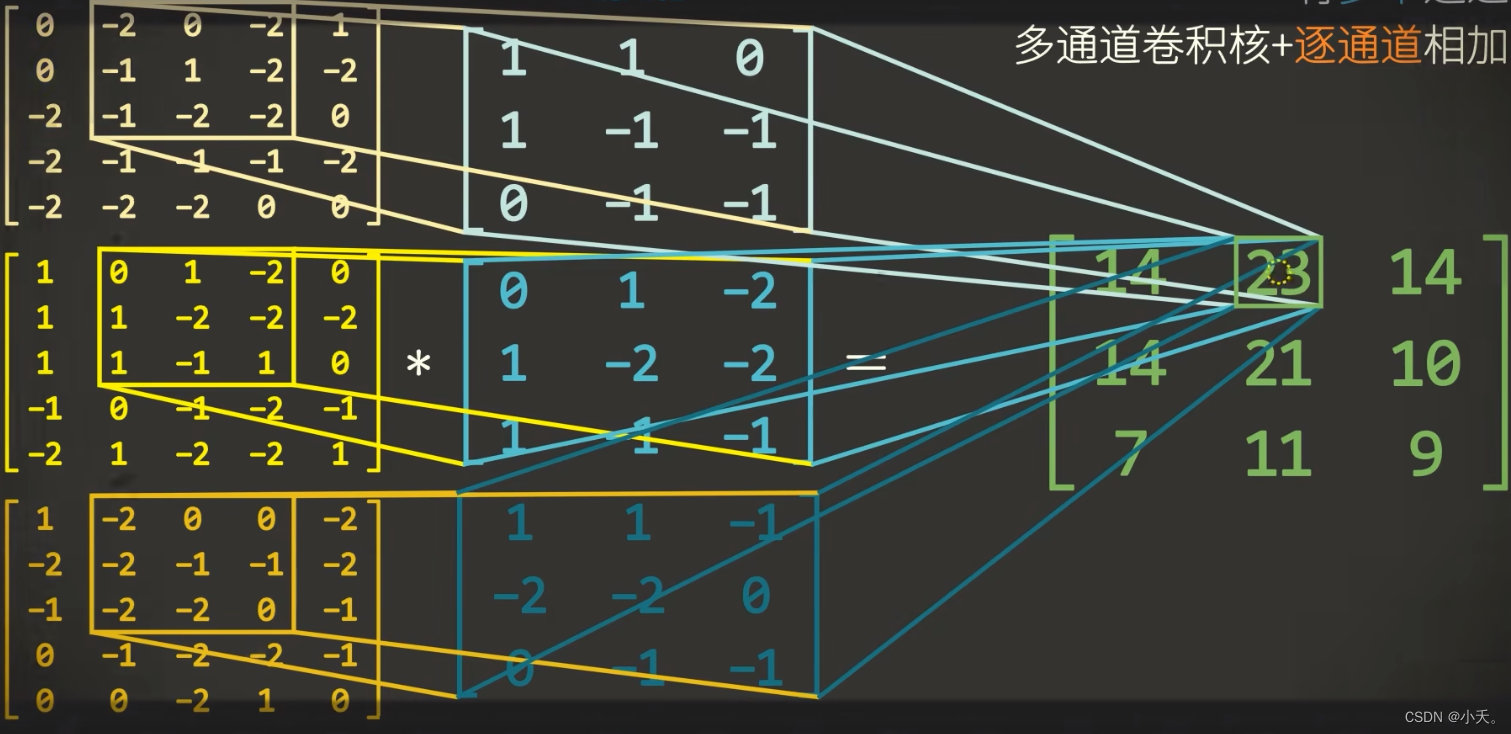
我们采取不同的卷积核对输入进行卷积,学习到了对于每个通道的输入特征,最后进行整合,得到了多通道的特征信息,也就是说融合了单通道卷积核的特征信息与多通道之间的联系,即空间与通道的融合。
这是一个最基础的卷积,将输入通过四个不同的滤波器,得到对应的输出,接下来我们对其进行扩展
(1)单纯增加输入通道数

单纯增加我们输入特征的通道数(比如隐藏层的输出很高如192层,作为下一层的输入,那么其通道数也会很大),对应滤波器的通道数也会增加
(2)增加滤波器个数

增加滤波器个数则会令输出特征的通道数增大,从而导致参数量的上升。
(3)参数量的计算

如果上述的两个维度分别都做了2倍的变换,那么最后总的参数量则是原来的四倍。
上述所说是最传统的卷积方式,随着深度学习的发展,我们意识到网络的加深有助于性能的提升,但与此同时带来的也是参数量的上涨,于是才有了以下的发展
2 逐深度卷积(depthwise conv)
重点:逐深度卷积是将通道进行分组
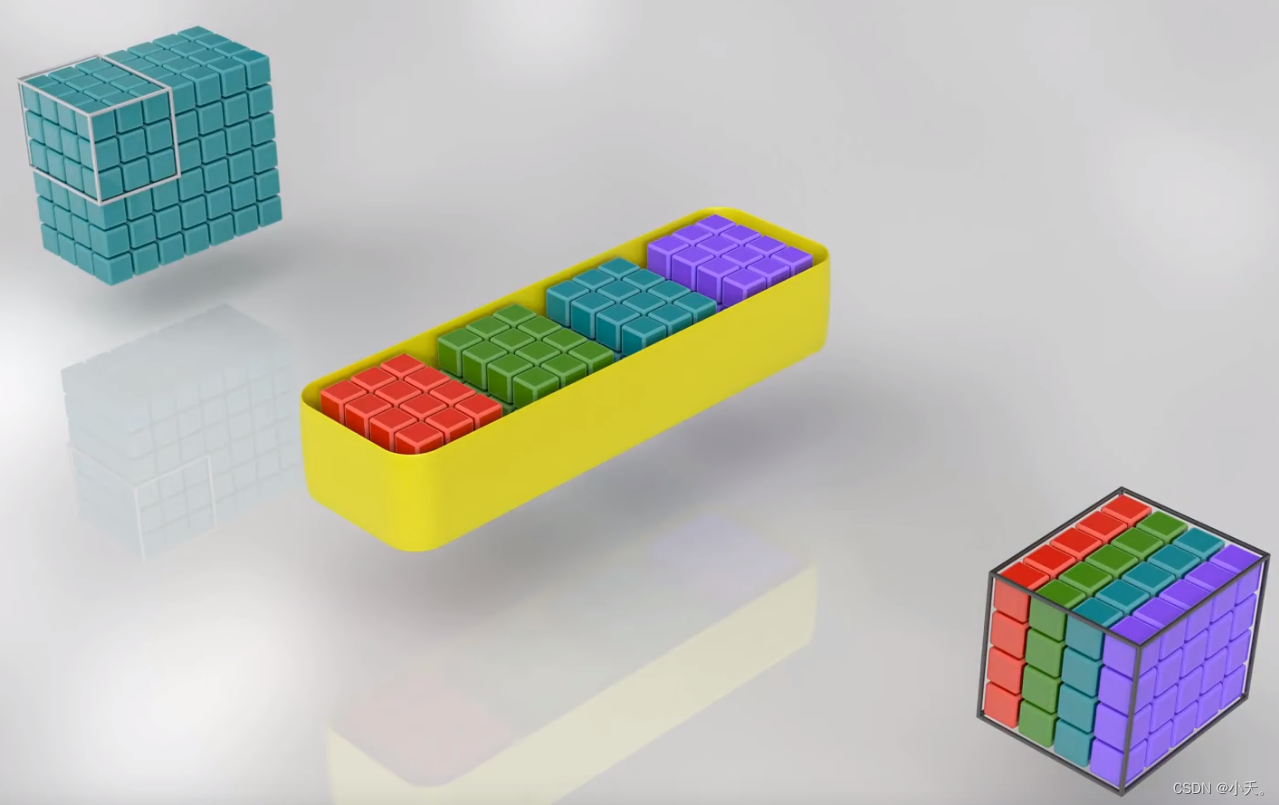
2.1 将输入通道分为两组
接着按照上面的例子,如果针对输入通道数过多的情况,我们先将输入通道单独的分为两组

那么这里的滤波器对应的通道数将是原来的一半(滤波器个数不变),输入通道进行分组后,这里的滤波器也分为了两组,第一组滤波器对应第一组的输入,第二组滤波器对应第二组的输入,最后将分组的两个通道整合在一起。
2.2 第一组分组进行卷积


这里可以明显看到,滤波器的深度只和当前组的深度相同,而不是整个输入的深度。滤波器个数仍然是对应最后的输出通道数,唯一不同的即第一个分组只收集了前四个滤波器的特征,而没有后面四个;第二组只收集了后四个滤波器的特征。
2.3 第二组分组进行卷积
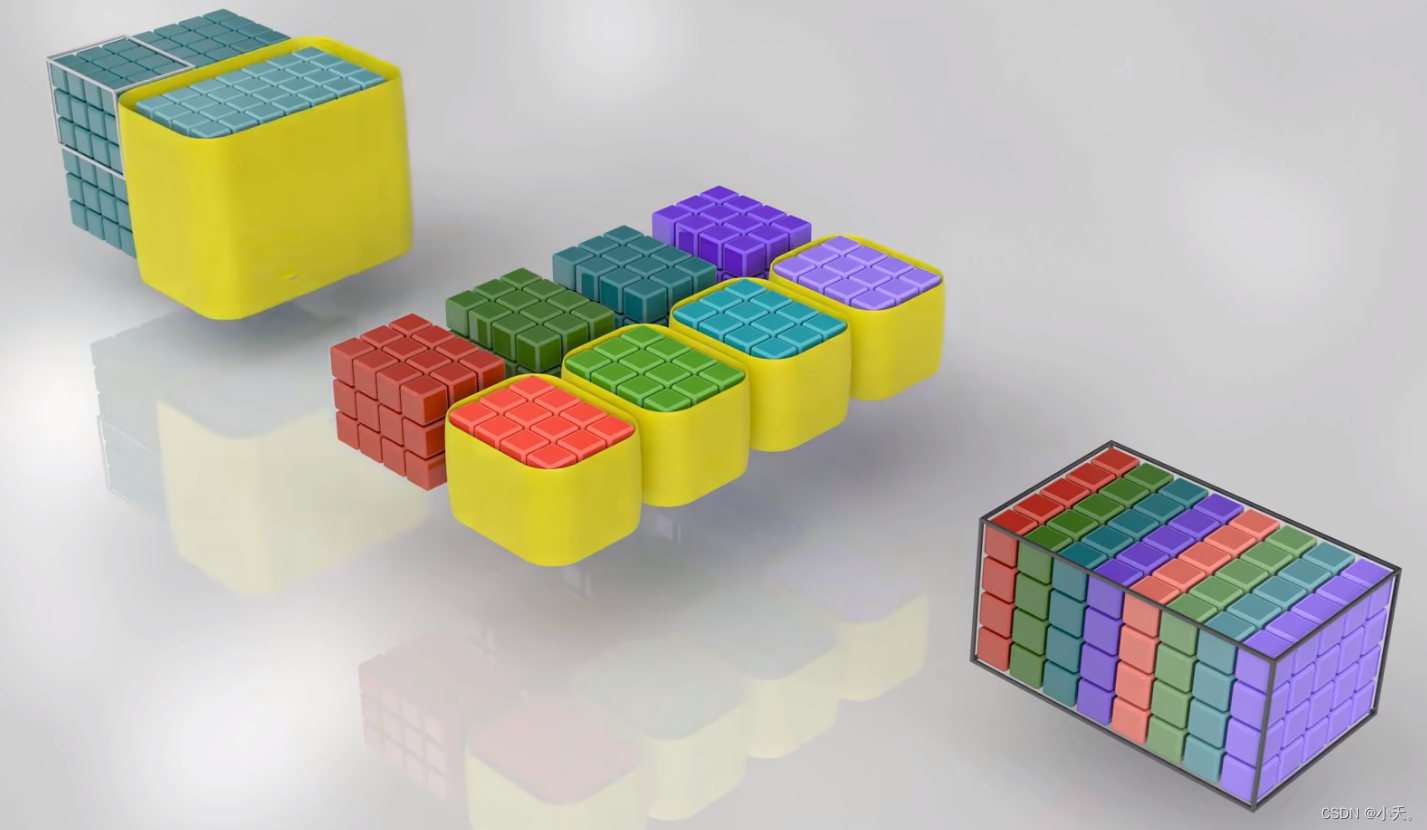

这样一来,我们分两组完成了整个卷积过程。
2.4 将所有通道单独分为一组

这就是对应的深度卷积,但是这样的深度卷积存在明显的问题。
2.5 深度卷积存在的问题
2.5.1 每一组分组只对应一个滤波器的特征
这个问题其实在前面两个分组的时候提到过,当我们将通道数分为两组的时候第一个分组只收集了前四个滤波器的特征,而没有后面四个;第二组只收集了后四个滤波器的特征。这个问题在二分组的时候可能不明显,但是对于每个通道都单独分组的情况下,这个缺陷尤为明显,我们的每个分组对应一个通道,一个通道只对应一个滤波器,也就是说,第一个输出特征只依赖于第一个输入特征,我们无法得到像没有分组情况下的能得到全部表达能力的情况。


分组卷积每个通道上可以获取不同的特征信息,但是缺点是只能获取对应单通道的信息。

这种情况下的分组卷积其实是丧失了一部分表达能力的,每一组通道只对应一个滤波器的特征信息,所以接下来引出了深度可分离卷积,其核心思想是加入了逐点卷积,也就是我们常说的1x1卷积,1x1卷积最重要的部分即可以不改变空间上的信息,但是却能获取所有通道上的信息,我们通过这个特殊的特征,可以做到通道上的信息融合,从而弥补分组卷积的缺陷。
3 逐点卷积(点对点卷积,pointwise conv)
重点:逐点卷积是通道上的信息融合,即它不改变空间上的任何信息,而能获取所有通道上的信息
逐点卷积按字面理解即1x1卷积,关于1x1卷积可以参考1x1卷积的作用
如下图所示
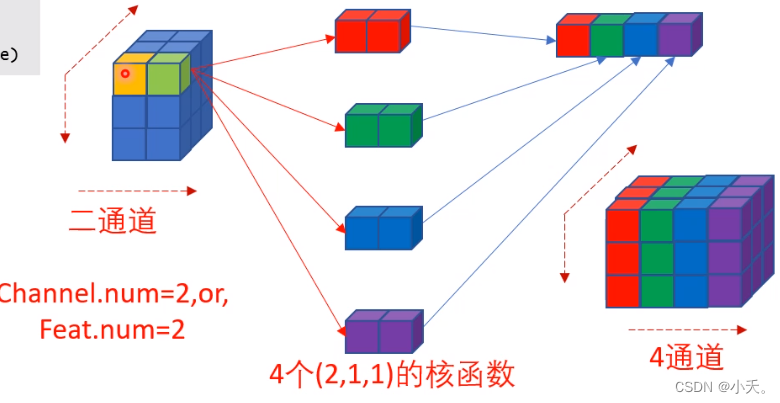
一个输入2通道的3x3特征,经过4个1x1卷积后,不改变其空间上的大小,在通道上将其扩展到了4通道。
那么此处逐点卷积做到的就是通道上的信息融合,但是不改变空间上信息。

如上图所示,点对点卷积的方式,不改变空间上的信息,但是却能获取所有通道的信息
4 逐深度可分离卷积
按照字面理解,深度可分离卷积即深度卷积+逐点卷积,同时做到空间与通道上的信息融合,同时大大的降低了参数量。
按前面所说,基于分组卷积的方式,丧失了部分表达能力,我们通过1x1卷积能进行通道融合的方式,将空间与通道结合,弥补了分组卷积信息缺失的特点。


对比上述两个图
- 第一个是分组卷积,可以获取空间上的信息(输入通过3x3卷积对应中间层的一个像素点,正好可以对应后文的1x1卷积),但是缺无法获取通道融合的信息
- 第二个是深度卷积,对于空间上的信息只能获取一个像素点的信息,但是却能融合所有通道的信息
将上述两个部分进行融合,即可得到我们的深度可分离卷积
5 深度可分离卷积参数量计算
5.1 普通卷积
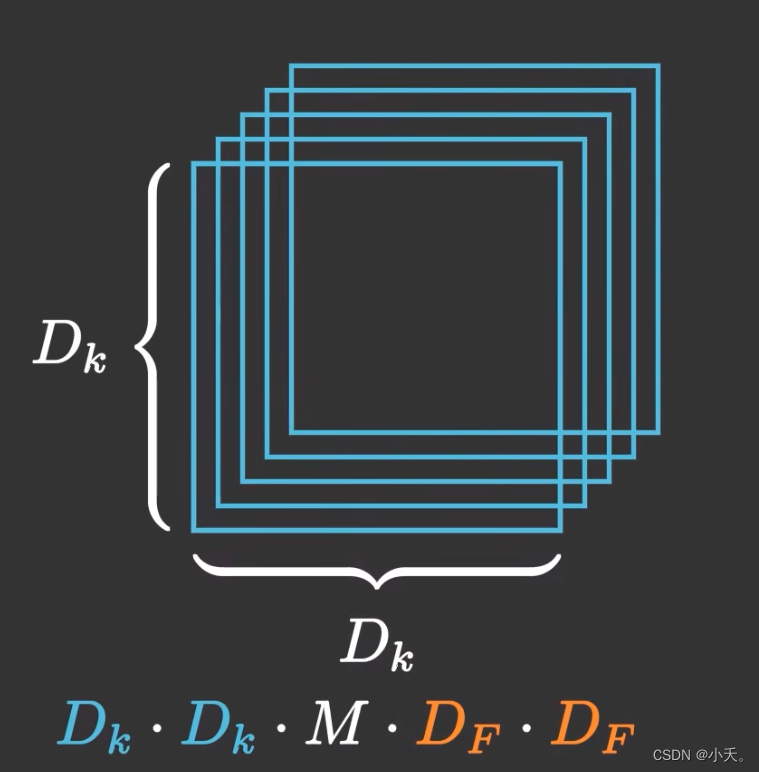
5.2 深度可分离卷积
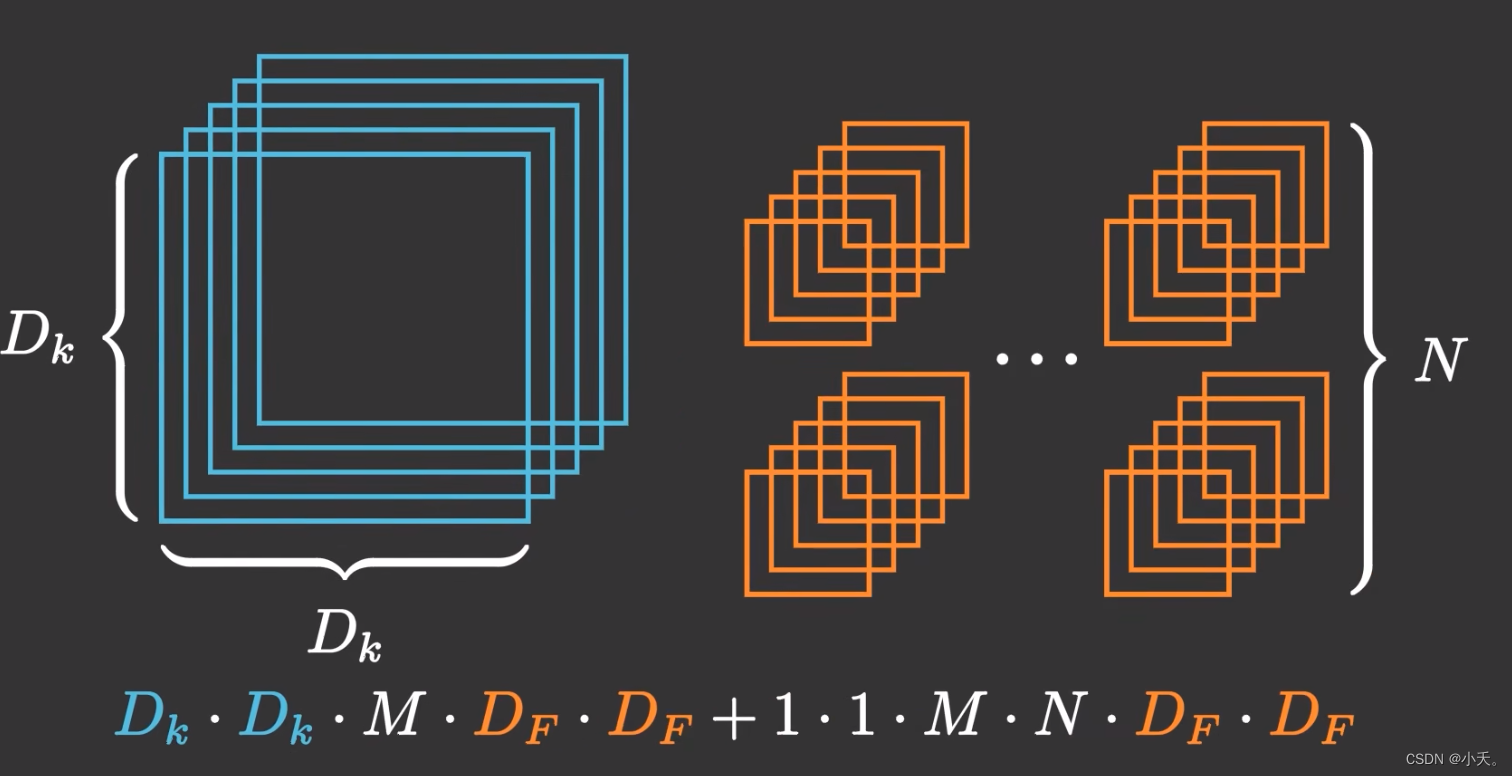
其中第一个式子没有了N通道数,而转为了1x1卷积获取通道信息
5.3 参数量比较
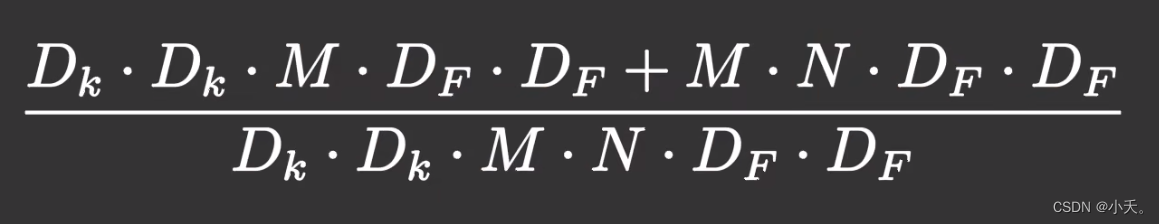
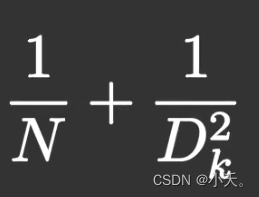
假设输出通道数为256,卷积核大小是3x3,那么采用深度可分离卷积的参数量将是原来的0.12
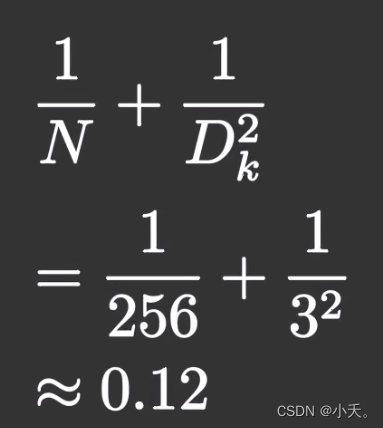
6 深度可分离卷积的实验结果
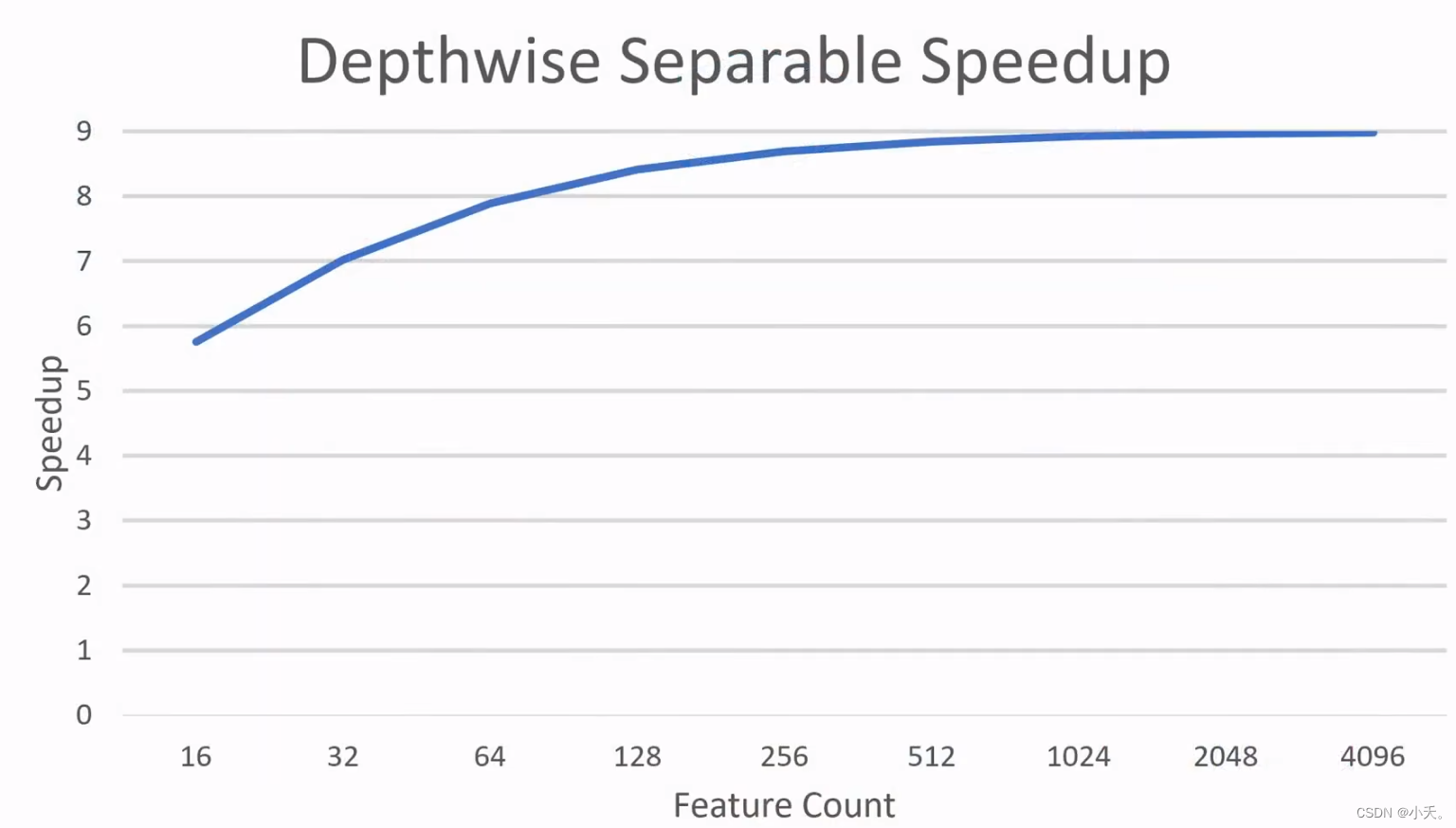
针对这个结果,表明对应特征通道数越多的情况下,我们的加速速度更加快,也就是参数量减少的更多