深度学习系列10:人脸识别概述
本文参考https://zhuanlan.zhihu.com/p/76513217
1. 基础
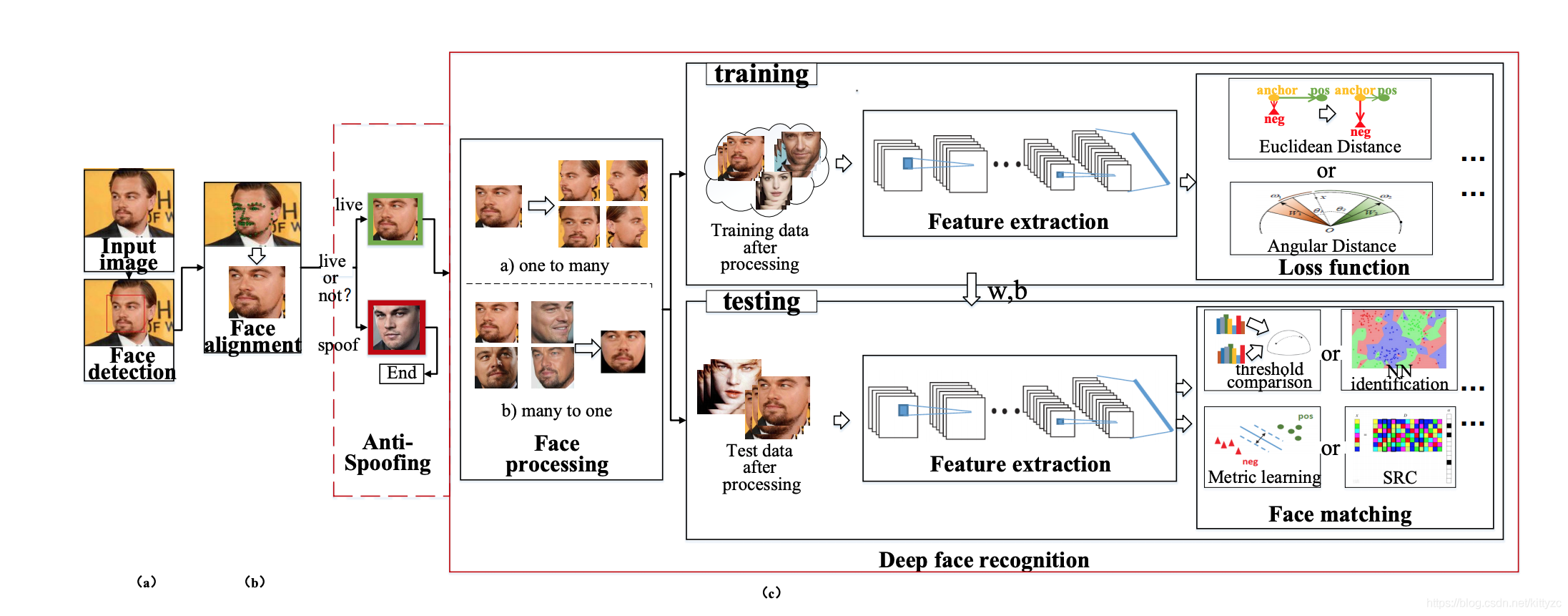
这是一篇review的文章。下图是基本流程:
1.1 数据集
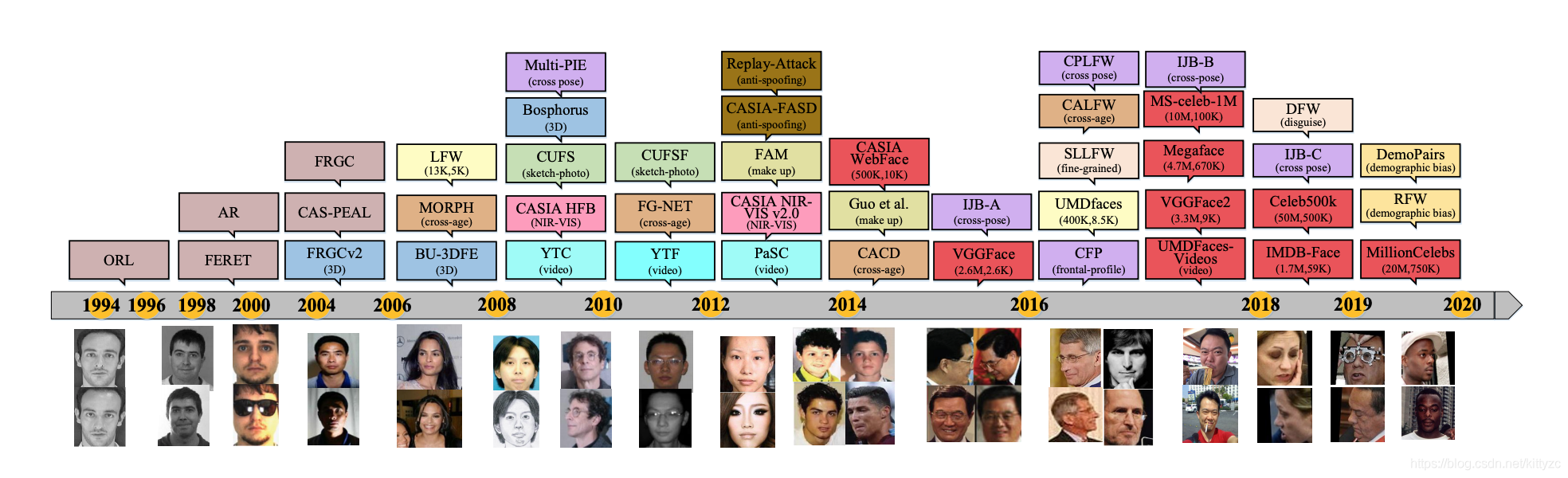
公开数据集的变迁如下:
1.2 前处理
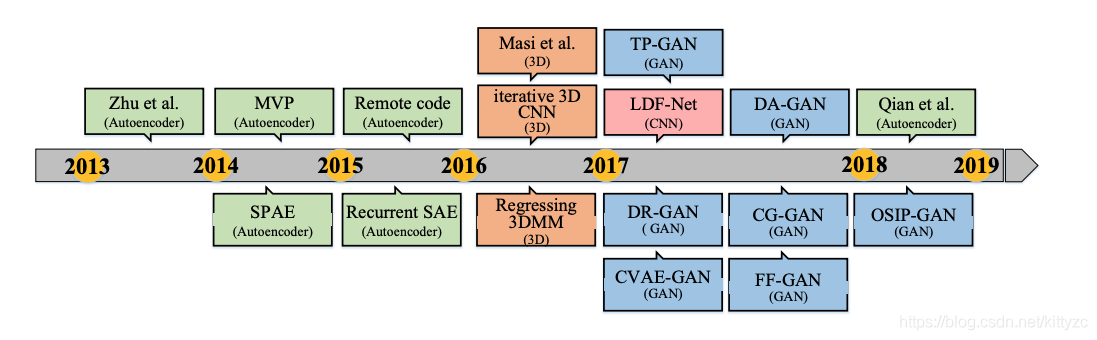
人脸处理的变迁如下:
1.3 网络架构
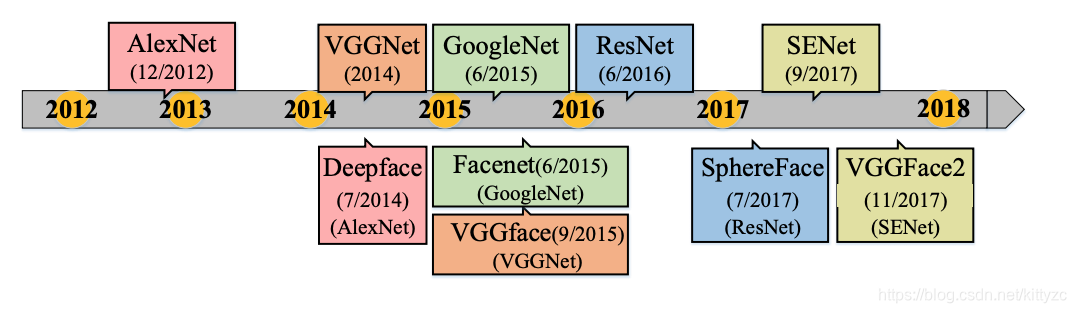
主架构的变迁如下图:
1.4 目标函数
通常,人脸识别可分为人脸识别和人脸验证。前者将一个人脸分类为一个特定的标识(identification),而后者确定一对图片是否属于同一人(Verification)。
闭集(open-set)是测试图像在训练集中可能出现过;开集(close-set)是测试图像没有在训练集中出现过。开集人脸识别比闭集人脸识别需要更强的泛化能力。过拟合会降低性能。Open-set FR对特征要求的准则:在特定的度量空间内, 需要类内的最大距离小于类间的最小距离。
标签预测(最后一个全连接的层)就像一个线性分类器,深度学习的特征需要容易分离(separable) 。此时softmax损失能够直接解决分类问题。但对于人脸验证任务,深度学习的特征不仅需要separable,还需要判别性(discriminative) 。 可以泛化从而识别没有标签预测的未见类别。
下面两图分别从不同的角度对问题进行分类:
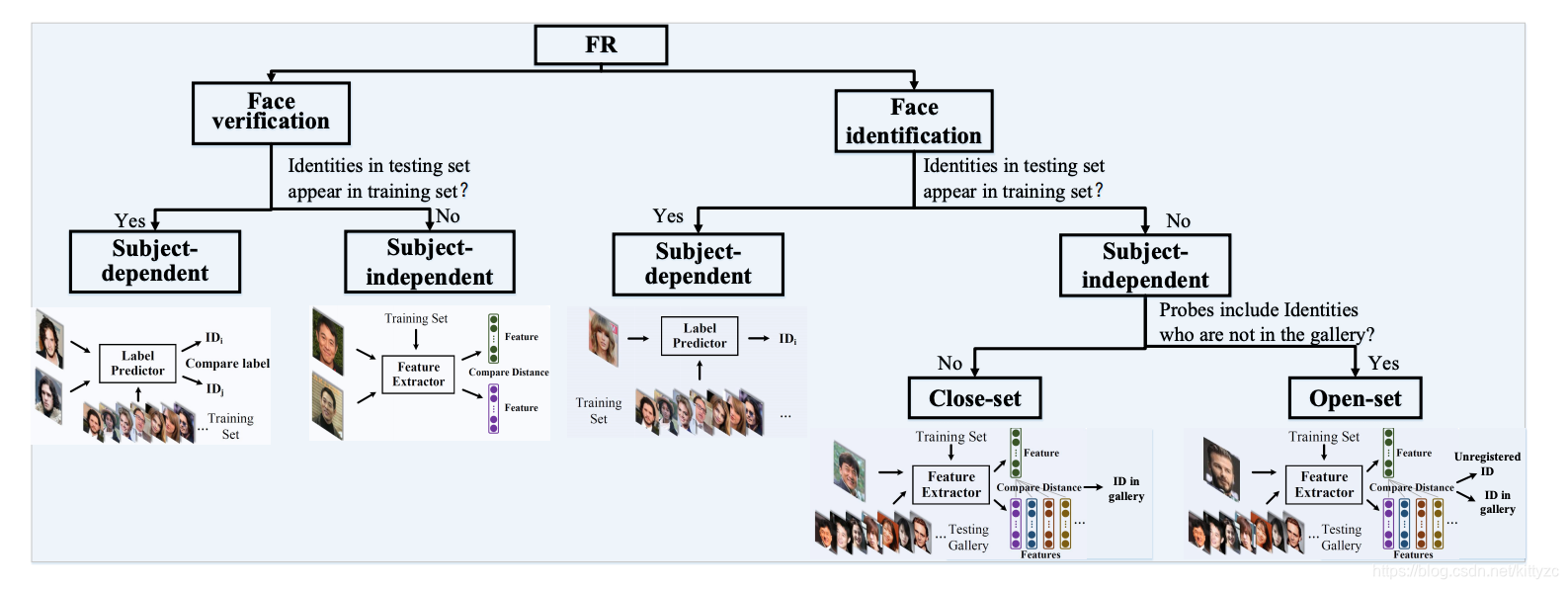
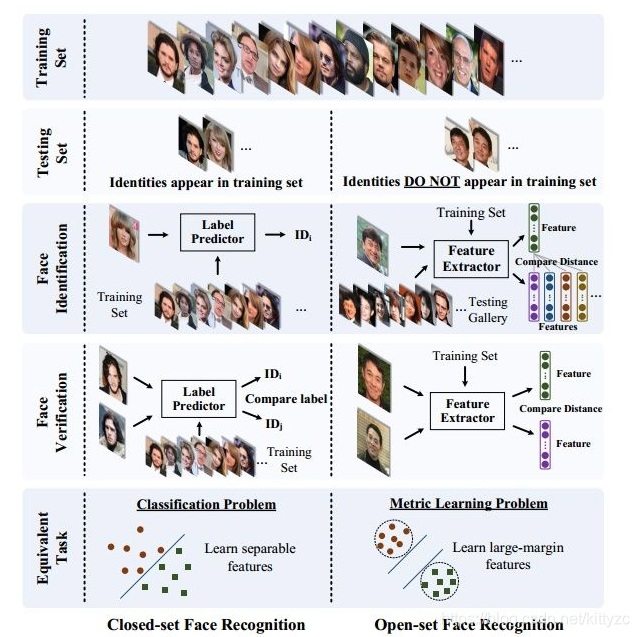
1.5 Metric
人脸识别的DCNNs有两个主要的研究方向:分类学习(softmax loss)、度量学习(triplet loss等)。
2014年的Deepface和DeepID标志着基于深度学习的FR诞生,用的是Softmax loss(多分类问题,交叉熵损失)。多分类问题只具有可分离性(separable),即将类间分离,而没有判别性(discriminative),即不能类内聚合。而人脸识别需要有可分离性+判别性,可以泛化到对未知人脸的同类与不同类的分类,所以有了后面的损失函数。
2015年之后,基于欧氏距离的损失在损失函数中一直扮演着重要的角色,如对比损失(Contrastive loss)、三元组损失(Triplet loss)、中心损失(Center loss)。
- Contrastive loss 最初源于Yann LeCun于2006年发表的 Dimensionality Reduction by Learning an Invariant Mapping,该损失函数原本主要是用于降维中,即本来相似的样本,在经过降维(特征提取)后,两个样本仍旧相似;而原本不相似的样本,在经过降维后,两个样本仍旧不相似。同样,该损失函数也可以很好的表达成对样本的匹配程度。对比损失,需要用成对样本X1和X2来训练,还需要标注Y标签是否相似。公式如下:
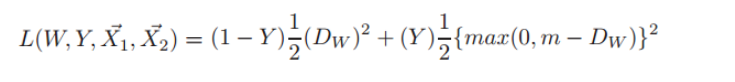
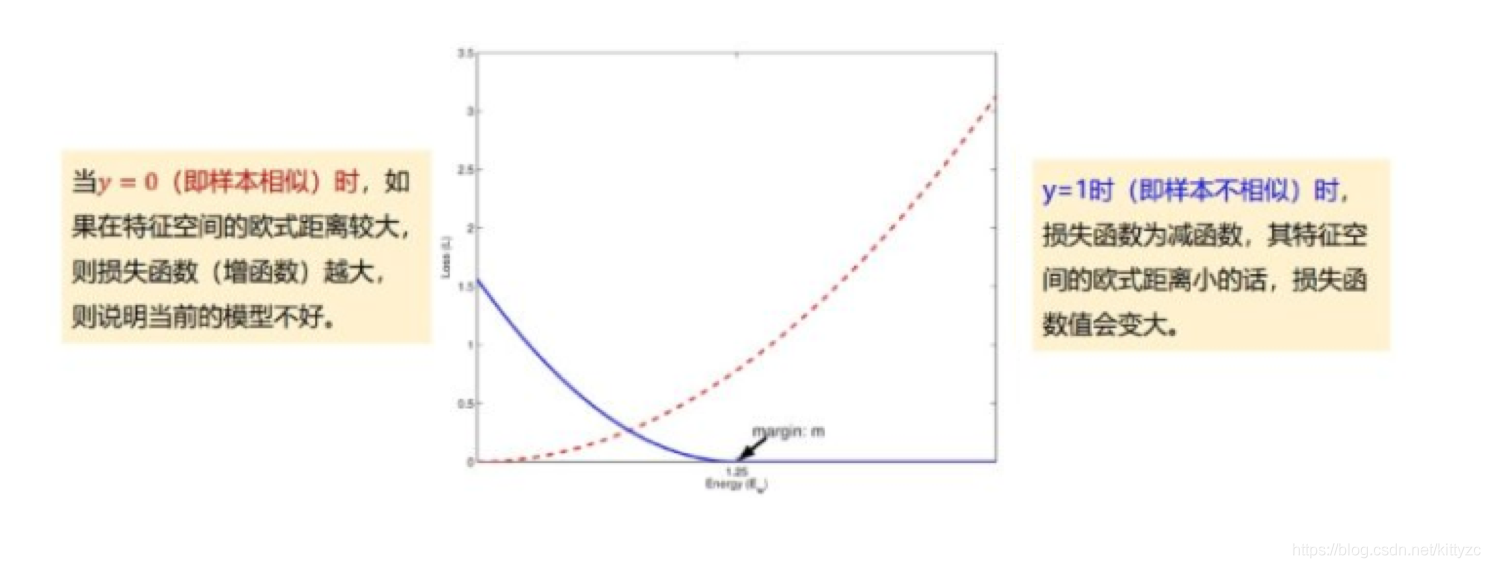
梯度计算公式如下,非常像受力模型,最后形成了在空间中的一种平衡状态。

- 三元组损失(Triplet Loss)源于google在2015发表的 FaceNet: A Unified Embedding for Face Recognition and Clustering,伴随FaceNet。三元组损失要求最小化锚点和具有相同的身份的正例之间的距离,并最大化锚点和不同身份的负例之间的距离。目标是让相同标签的两个示例使其嵌入在嵌入空间中靠近在一起,不同标签的两个示例的嵌入距离要很远,但不希望推动每个标签的训练嵌入到非常小的簇中。 唯一的要求是给出同一类的两个正例和一个负例,负例应该比正例的距离至少远margin。 这与SVM中使用的margin非常相似,这里希望每个类的簇由margin分隔。
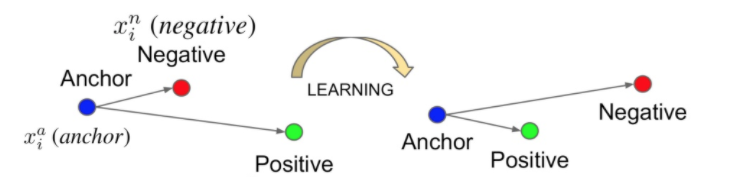
损失函数如下:
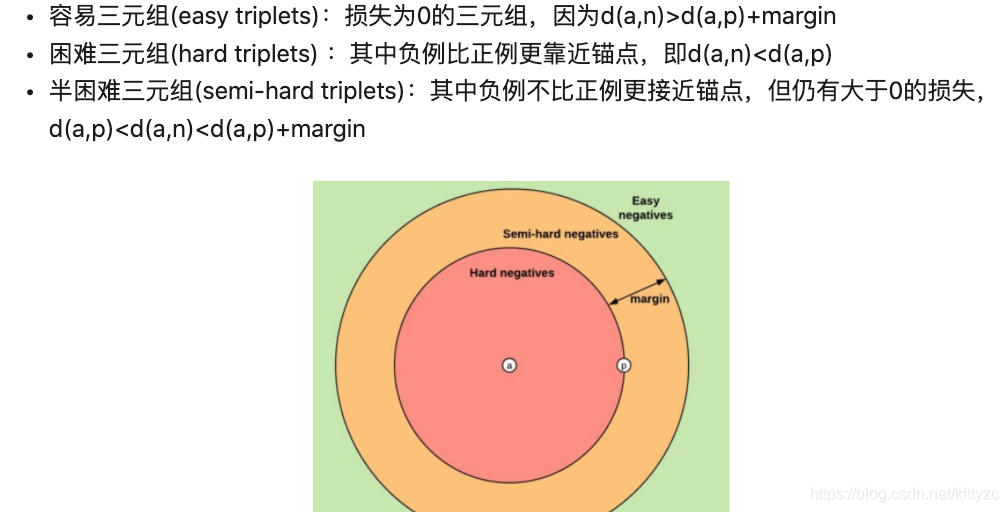
Facenet论文中采用了随机的semi-hard negative构建triplet进行训练。2017的《In Defense of the Triplet Loss for Person Re-Identification》提出batch hard的表现最好,即对于每一个anchor,选择hardest positive(距离anchor最远的positive example) 和 hardest negative(距离anchor最近的negative example)。假设一个batch的数据包含P*K张人脸,P个人,每人K张图片,则产生PK个triplet,这些triplet是最难分的
- Center Loss源于乔宇、Yandong Wen等在ECCV 2016上发表的 A Discriminative Feature Learning Approach for Deep Face Recognition。中心损失为每一个类别提供一个类别中心,最小化min-batch中每个样本与该类别中心的距离,即缩小类内距离。center可使用"xavier"进行初始化,然后在每个mini-batch迭代后在当前类别中更新一次。;每次迭代过程中,只对对应类别的特征取平均计算,相当于让cj是向x的平均移动。用softmax损失+中心损失的联合监督来训练CNN进行判别性特征学习,可以获得用于鲁棒的人脸识别的高判别性特征。标量λ用于平衡两个损失函数,则总的损失函数为:
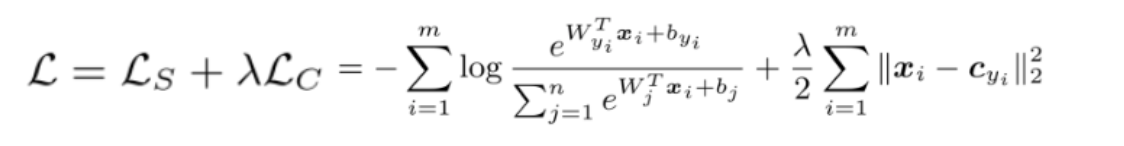
在联合监督下,DeepIDNet由0.7M人脸图像训练,在14小时内迭代28k收敛。但是从另一个角度上说,center loss采取的是在训练过程中用空间换取时间的策略
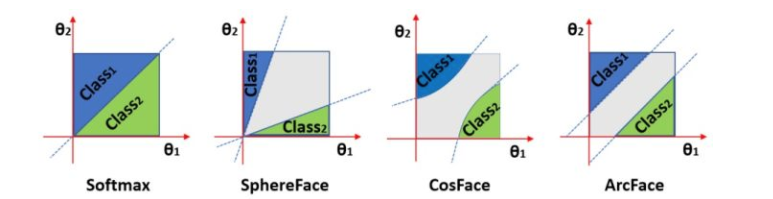
2017年,特征和权重归一化(Feature and weight normalization)也开始显示出优异的性能,这导致了softmax变种的研究,如L2 softmax。此外,在2016年和2017年,Large margin loss进一步推动了大间隔特征学习的发展,如L-softmax、A-softmax、Cosface、Arcface。原始Softmax loss获得的特征具有固有的角分布,将角度间隔与Softmax loss结合起来实际上是更自然的选择。
简单地通过角度分类,两类别是可以分离开的,但Softmax只学习到了可分离的特征,但内聚性不好,判别性不够。如下图的a和b。
Modified softmax loss能够直接优化角度,使CNN能够学习角度分布特征。为了实现角度决策边界,最终FC层的权重实际上是无用的。因此,首先对权重进行归一化并将偏置项归零
(
∣
∣
W
i
∣
∣
=
1
,
b
i
=
0
)
(||W_i||=1,b_i=0)
(∣∣Wi∣∣=1,bi=0),后验概率为
p
1
=
∣
∣
x
∣
∣
c
o
s
(
θ
1
)
,
p
2
=
∣
∣
x
∣
∣
c
o
s
(
θ
2
)
p_1=||x||cos(θ_1),p_2=||x||cos(θ_2)
p1=∣∣x∣∣cos(θ1),p2=∣∣x∣∣cos(θ2)虽然我们可以用这个改进的softmax loss来学习带有角边界的特征,加强了角度可分性,但是这些特征还是没有判别性(discriminative)。如图c和d
A-Softmax Loss进一步引入角度间隔(angular margin),让分类更加困难从而学习判别性。角度间隔更加大了,但分布的弧长变短了。如e f。A-Softmax loss(Angular Softmax loss)针对不同的类别采用不同的决策边界(每个边界都比原边界更严格),从而产生角间隔。引入一个整数m来定量控制决策边界,从类别1正确分类,需要cos(mθ_1)>cos(θ_2),决策边界就是cos(mθ_1)=cos(θ_2)。从类别2的则相反。从角度的观点来考虑,从标识1正确分类x需要mθ_1<θ_2,而从标识2正确分类x需要mθ_2<θ_1。
因为m是正整数,cos函数在0到π范围又是单调递减的,所以mθ_1要小于θ_2,m值越大,θ_1应越聚合,则学习的难度也越大,因此通过这种方式定义损失会逼得模型学到类间距离更大的,类内距离更小的特征。
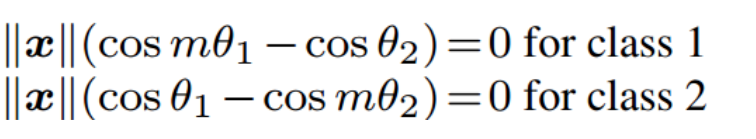

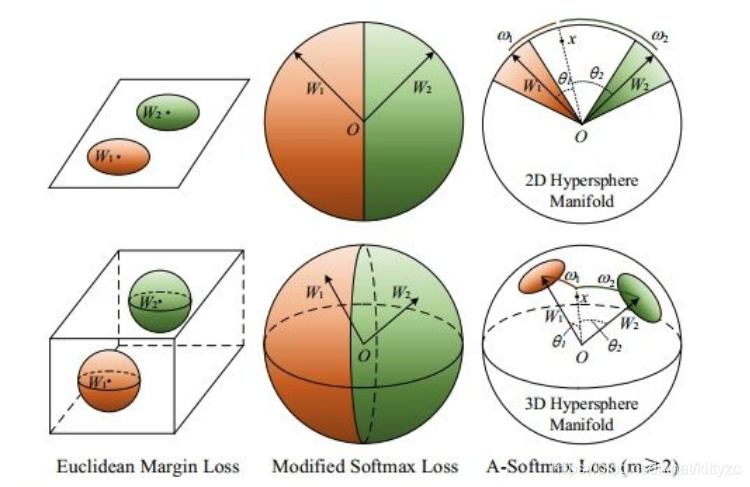
下面是不同的m的直观效果:
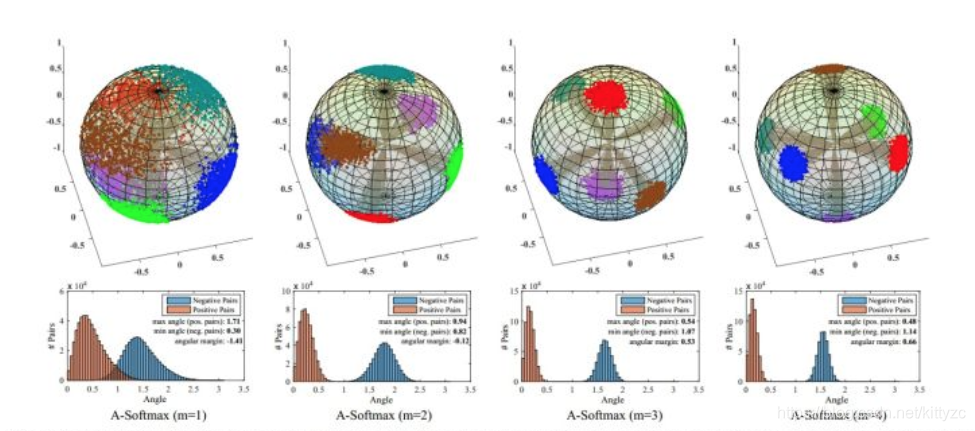
A-Softmax与L-Softmax的最大区别在于A-Softmax的权重归一化了。A-Softmax权重的归一化导致特征上的点映射到单位超球面上,而L-Softmax则不没有这个限制,这个特性使得两者在几何的解释上是不一样的。
如在训练时两个类别的特征输入在同一个区域时发生了区域的重叠,如图左边。A-Softmax只能从角度上分离这两个类别,也就是说它仅从方向上去分类,分类的结果如图中间;而L-Softmax不仅可以从角度上区别两个类,还能从权重的模(长度)上区别这两个类,结果如图右边。在数据集合大小固定的条件下,L-Softmax能有两个方法分类,训练可能没有使得它在角度与长度方向都分离,导致它的精确可能不如A-Softmax。
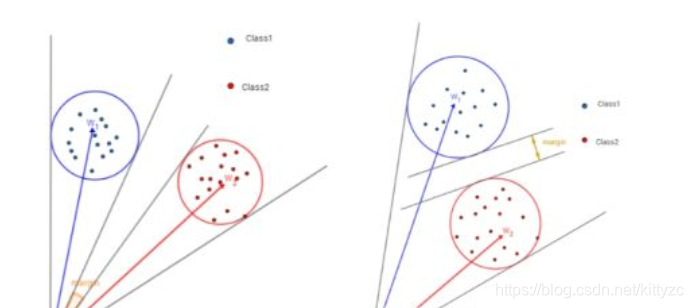
总结如下:
- DeepFace、DeepID:通过SoftMax Loss学习面部特征,但只具有可分离性而不具有明显的可判别性。
- DeepID2:结合了softmax loss和contrastive loss以增强特征的判别能力。但它们产生不同的特征分布,softmax损失会产生一个角度的特征分布,对比损失是在欧几里得空间学习到的特征分布,所以特征结合时可能不是一个自然的选择。
- FaceNet:使用Triplet loss来监督嵌入学习。但它需要非常大量数据(2亿张人脸图像),计算成本很高。对比损失和三元组损失都不能限制在单个样本上,因此需要精心设计的双/三重挖掘过程,这既耗时又对性能敏感。
- VGGFace:先训练CNN+Softmax loss,再用Triplet loss度量学习。
- A discriminative feature learning approach for deep face recognition. In ECCV2016:将Softmax loss与Center loss结合以增强特征的判别能力,但中心损失只起到缩小类间距离的作用,不具有增大类间距离的效果。
- L-Softmax loss(作者和A-softmax loss是同一批人)也隐含了角度的概念。利用改进的softmax loss进行具有角度距离的度量学习。作为一种正则化方法,它在闭集分类问题上显示了很大的进步。A-softmax loss简单讲就是在Large-Margin Softmax Loss的基础上添加了两个限制条件||W||=1归一化和b=0,使得预测仅取决于W和x之间的角度。
1.6 孪生网络
Contrastive loss训练过程中需要使用孪生网络架构。孪生神经网络的用途是衡量两个输入的相似程度。将两个输入feed进入左右两个神经网络,这两个神经网络分别将输入映射到新的空间中的向量,在新的空间中判断Cosine距离、exp function、欧式距离等就能得到两个输入的相似度了。通过Loss的训练来使相似图像的相似度D变小,不相似的图像相似度D变大。
孪生架构(Siamese Architecture)是一种框架,神经网络的“连体”是通过共享权值来实现的。如果左右两边不共享权值,而是两个不同的神经网络,就是伪孪生网络,适用于处理两个输入"有一定差别"的情况。
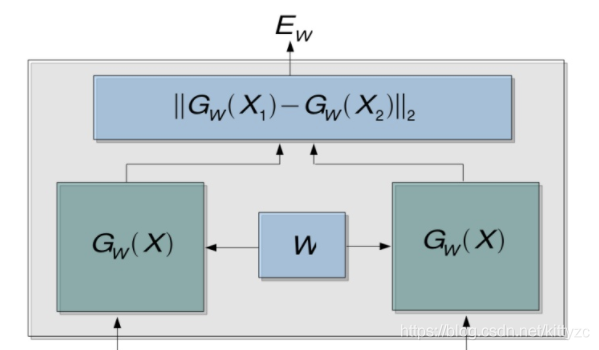
Triplet network是三胞胎连体,,输入是三个,一个负例+两个正例:
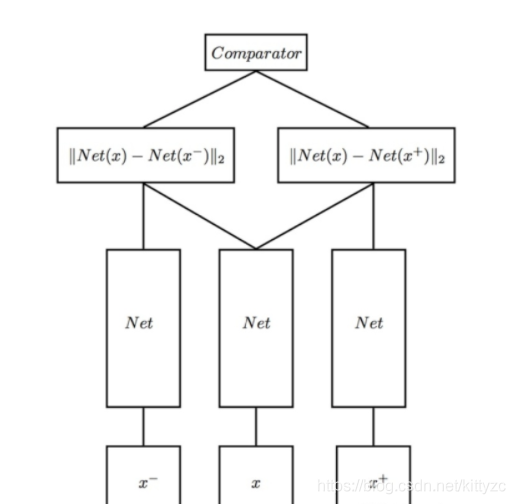
1.7 其他
应用到生产场景还有如下挑战:
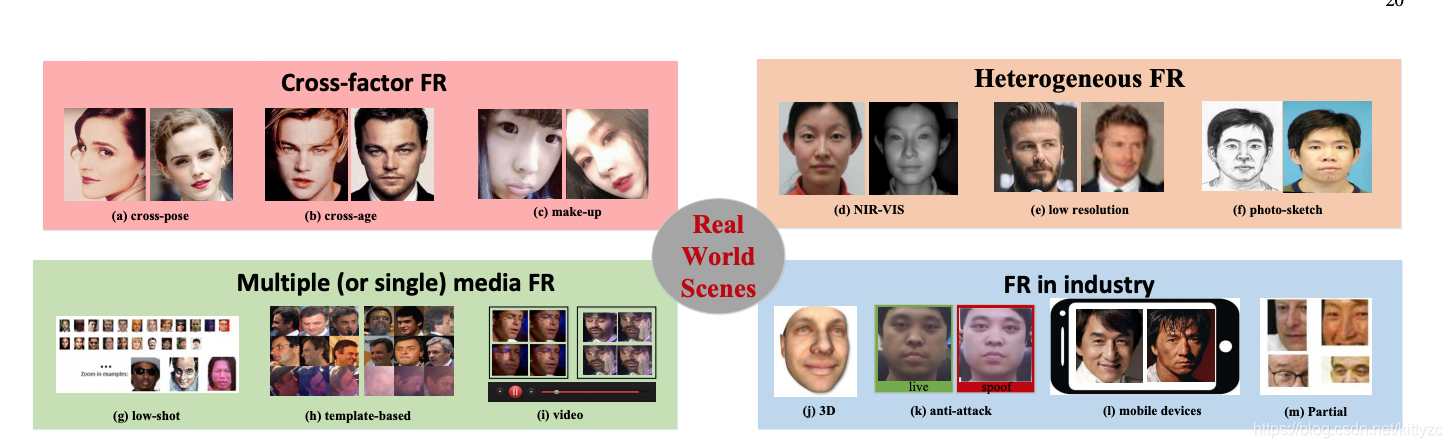
2. 网络架构
2.1 facebook deepface
这里是论文地址。使用英特尔2.2GHz的单核心CPU,从原始输入像素中提取特征0.18秒,对齐要0.05秒。总的来说,DeepFace是每幅图像0.33秒,含图像解码、人脸检测与比对、前馈网络、最终分类输出。
DeepFace是作为一个分类模型来训练的。基本框架人脸识别的基本流程是:detect -> aligh -> represent -> classify,在实现时需要使用3D对齐技术,然后将对齐的结果送入一个9层网络进行处理。DeepFace与之后的方法的较大的不同点在于,DeepFace在训练神经网络前,使用了3D对齐方法。论文认为神经网络能够work的原因在于一旦人脸经过对齐后,人脸区域的特征就固定在某些像素上了,此时,可以用卷积神经网络来学习特征。
针对同样的问题,DeepID和FaceNet并没有对齐,DeepID的解决方案是将一个人脸切成很多部分,每个部分都训练一个模型,然后模型聚合。FaceNet则是没有考虑这一点,直接以数据量大和特殊的目标函数取胜。
整个训练过程前两个卷积层采用了共享卷积核,后三个卷积采用不共享卷积核,倒数第二层采用全连接层提取出对应的人脸特征。最后一层是一个softmax层分类。DeepFace在训练过程中采用的是一般的交叉熵损失函数,并且采用一般的softmax对训练的数据进行分类。
首先是对齐:
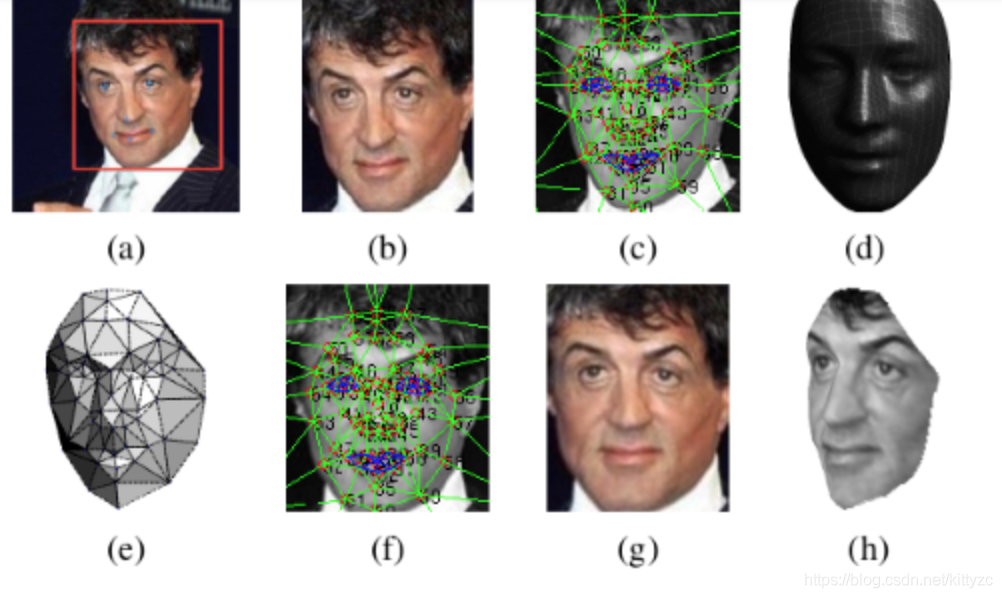
接下来是进入深度学习网络结构:

f7和f8是全连接层,这些层能够捕捉人脸图像中较远部分的特征之间的相关性,比如眼睛的形状与位置和嘴巴的形状与位置,f7层作为特征(4096D)。大约95%的参数来源于最后的全连接层。
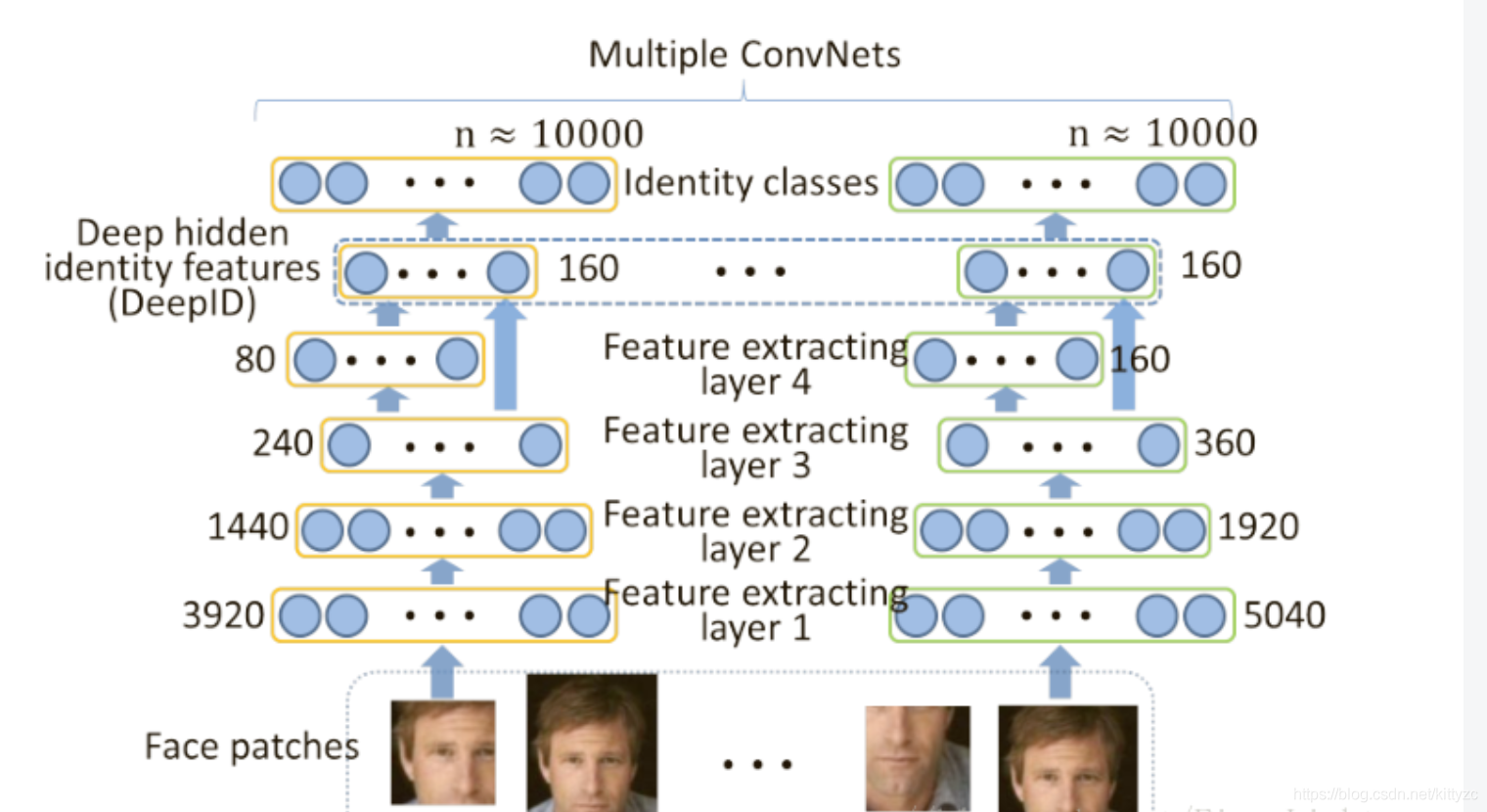
2.2 deepID1
DeepID1本质上还是一个分类问题。这里是论文链接。网络结构如下。注意DeepID的最后一个隐藏层全连接到第四个和第三个卷积层(在最大池化之后),使得它能观察到多尺度特征。第四个卷积层中的特征比第三个卷积层中的特征更全局,这对于特征学习至关重要,因为在沿着级联连续下采样之后,第四个卷积层包含太少的神经元并且成为信息传播的瓶颈。在第三卷积层(称为跳跃层)和最后隐藏层之间添加旁路连接减少了第四卷积层中可能的信息丢失。
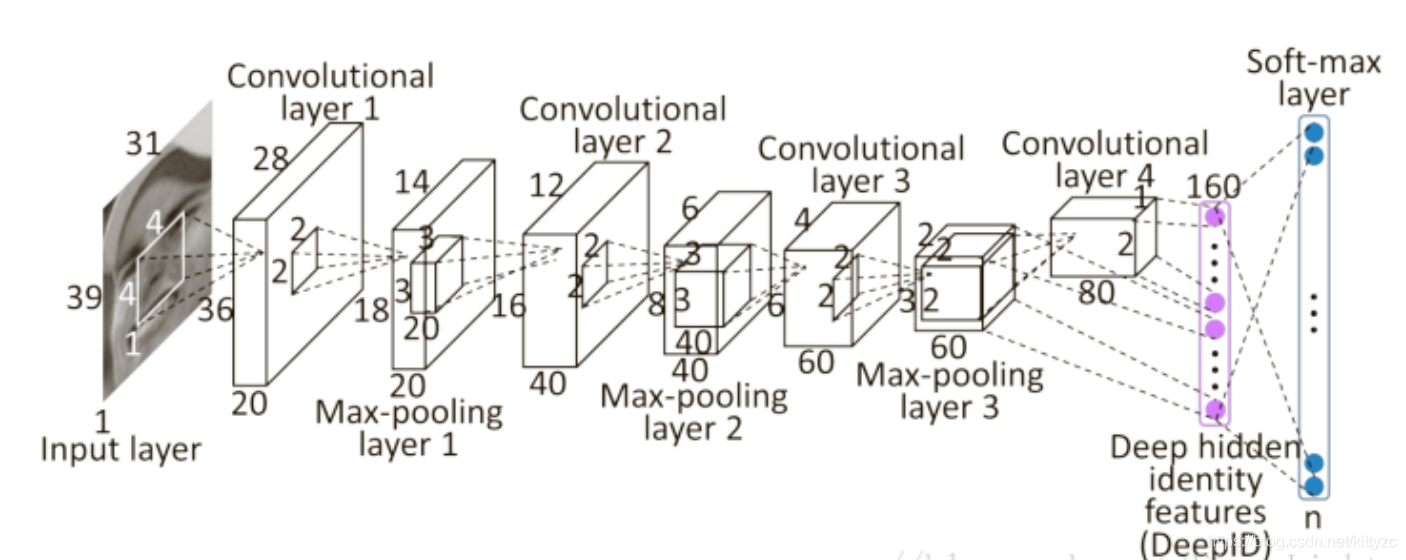
DeepID特征取自每个ConvNet的最后一个隐藏层,高度紧凑的160维DeepID包含丰富的身份信息,并且直接预测更大数量(如10000)的身份类别。DeepID维度远远低于预测的身份类别,这是学习高度紧凑和可辨识特征的关键。
基于弱对齐图像,通过5个landmarks将每张人脸划分成10regions,从10个区域、3种尺度、RGB和灰色2种通道方面截取出60个面部块,将从中提取特征。图中显示了10个面部区域和两个特定面部区域的3个尺度:(只用于人脸验证,训练DeepID时不用它)
然后每个patch都输入相同的网络,加上水平翻转后,提取出2*160=320维特征。60套patch并行计算,最终的特征向量长度为19200(160×2×60):
2.3 deepID2 & deepID2+
deepID2将问题改成了一个测度问题,也就是目标减少类内差距,增加类间差距。这也是现代reid算法的核心训练方法。测度问题的图示如下:
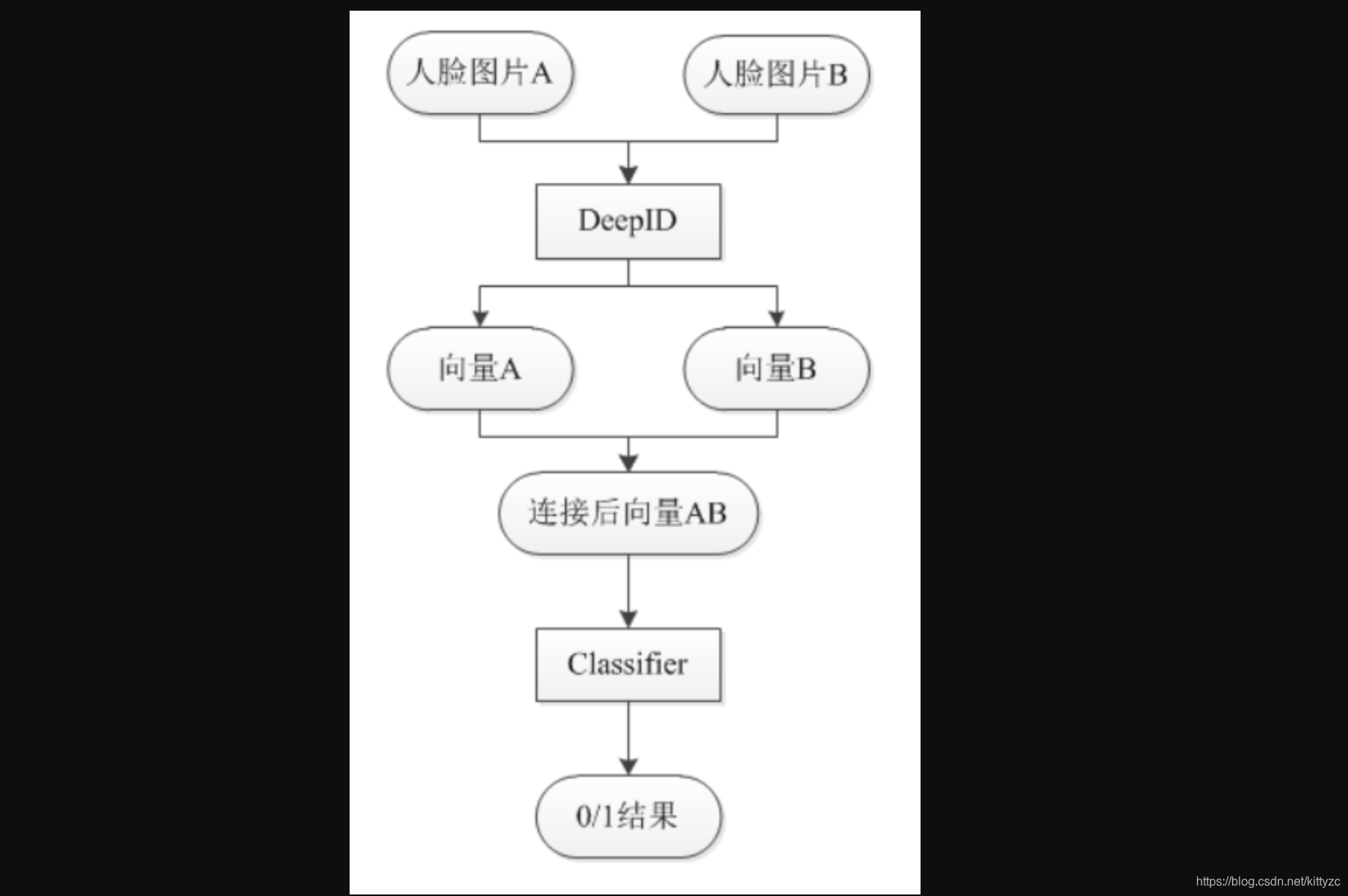
卷积层和deepID1是一样的,不同之处在于使用了两种不同的损失函数,一个是之前的identification损失,还有一个是contrastive损失,以一定的权重加起来。
基本流程还是一致的,先使用SDM算法检测出21个关键点,基于关键点对图片进行校正。然后将图片切分为400个patches,分到200个卷积网络里进行特征计算,每个patch生成2个160维的DeepID2特征。采用前向、后向贪心算法来选择最具代表性的特征,选取其中25个patches,总共25*160=4000维特征;这4000维特征使用PCA再次降维,最终产出180维特征。

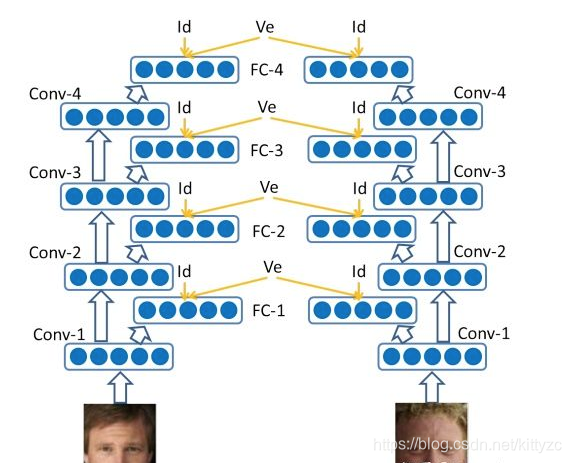
DeepID2+在DeepID2的基础上做了如下改动:
- DeepID层从160维提高到512维。
- 训练集将CelebFaces+和WDRef数据集进行了融合。共同拥有12000人,290000张图片。
- 将DeepID层不仅和第四层和第三层的max-pooling层连接,还连接了第一层和第二层的max-pooling层。
图中,ve表示监督信号(即验证信号和识别信号的加权和)。FC-n表示第几层的max-pooling。
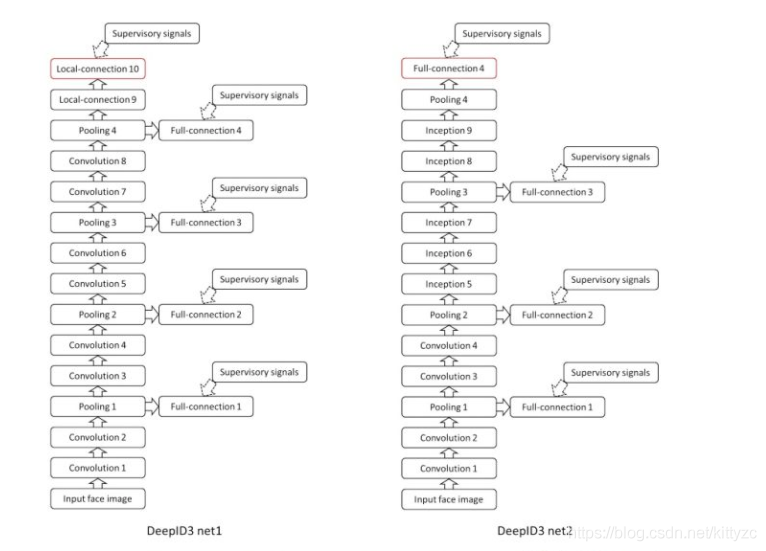
2.4 deepID3
eepID3是Yi Sun, Ding Liang, Xiaogang Wang, Xiaoou Tang在2015.02发表,提出基于VGGNet和GoogLeNet的人脸表示,DeepID3: Face Recognition with Very Deep Neural Networks。
主要修改点在于更深的网络层,还有连续两个conv layer的情况,有助于形成更大感受野和更复杂的非线性特征,同时使用了Inception后参数数量也有所降低。 监督信号作用在最后层和中间层。
到目前为止,在LFW上的准确率见下表:
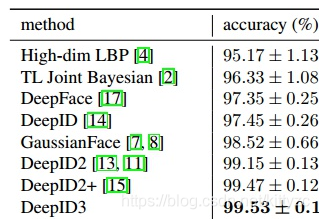
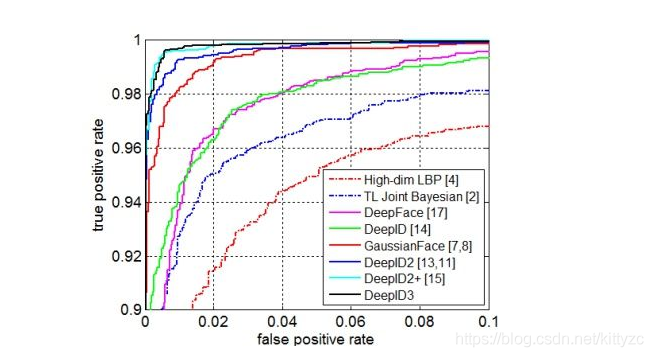
2.5 FaceNet
FaceNet是谷歌于CVPR2015.02发表,提出了一个对识别、验证、聚类等问题的统一解决框架,即它们都可以放到特征空间里做,需要专注解决的仅仅是如何将人脸更好的映射到特征空间,FaceNet: A Unified Embedding for Face Recognition and Clustering
FaceNet抛弃了DeepID2的Softmax分类层,再将 Contrastive Loss 改进为 Triplet Loss,以获得类内紧凑和类间差异。FaceNet提出了一个通用的人脸验证(这是同一个人吗)、人脸识别(这是谁)和人脸聚类(在这些面孔中找到同种人)系统,整个系统可以端到端学习。Triplet Loss直接反映了这些问题实现的目标,他们努力嵌入能够从图像x映射到特征空间R^d的f(x),以使两者的平方距离很大或很小。

使用Triplet Loss的主要缺点是,模型的拟合时间非常长,很少的数据就可以产生很多的三元组,样本数量是O(N3),当训练集很大时,基本不可能遍历到所有可能的样本(或能提供足够梯度额的样本)。模型好坏很依赖训练数据的 Sample 方式,理想的 Sample 方式不仅能提升算法最后的性能,更能略微加快训练速度。
用嵌入是因为两幅人脸图在高维空间的比较作用不大,而低维的嵌入空间的比较就能发挥作用。一旦产生了这种嵌入,则下述任务变得直截了当:
- 人脸验证仅涉及对两个嵌入之间的距离进行阈值处理;
- 人脸识别成为k-NN分类问题;
- 人脸聚类可以使用诸如k均值或agglomerative聚类的现成技术来实现。
LFW上98.87%。使用专用的人脸检测器,NN1实现了99.63%±0.09的分类准确度。Youtube Faces上,在每个视频中使用人脸检测器检测前100帧的所有对的平均相似度,分类准确度为95.12%±0.39。
2.6 vggFace
VGGFace是牛津大学视觉组于2015年发表,VGGNet也是他们提出的,基于VGGNet的人脸识别,Deep Face Recognition
backbone用的是vggnet中的D结构:
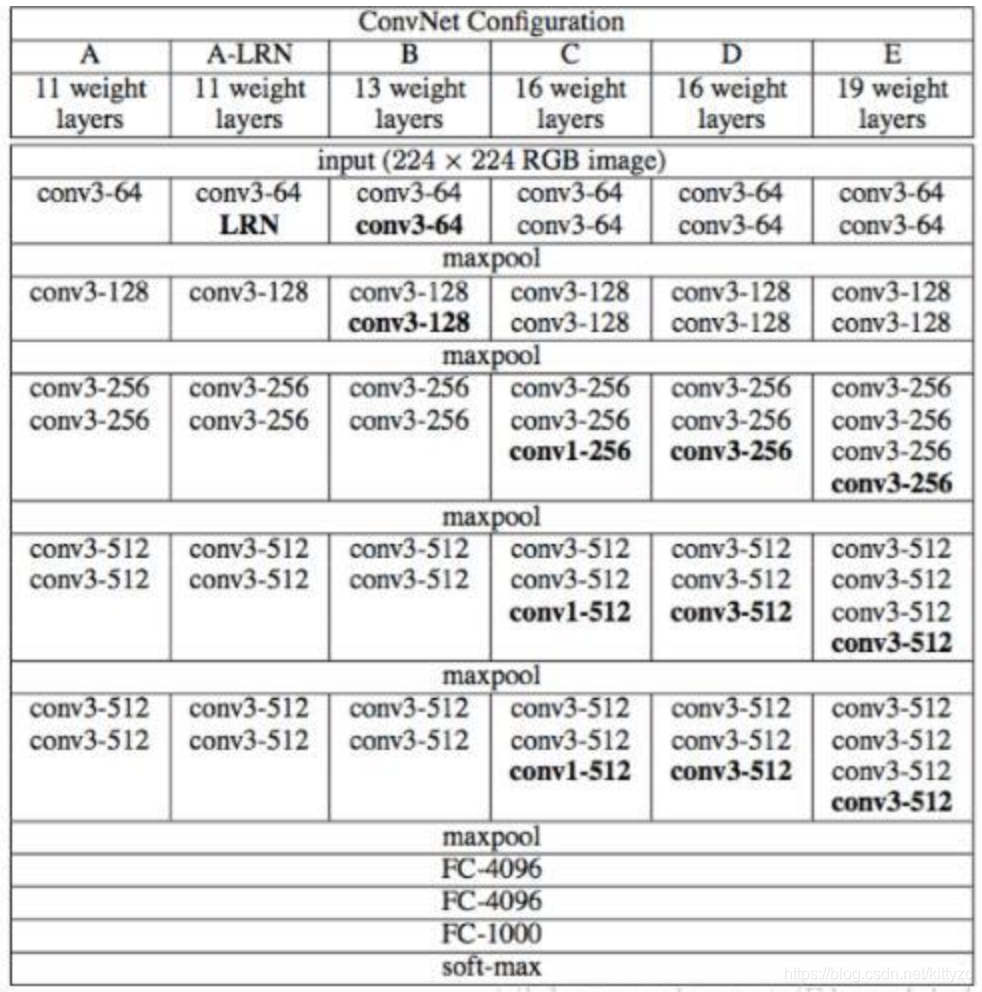
有3个全连接层,没有用local contrast normalization,使用Softmax在VggDataSet上预训练(分类问题),输出2622个类别概率。
人脸识别问题则是在人脸分类器基础上,用目标数据集fine-tuning映射层:VGGNet+Triplet loss,输出1024维的人脸表示,通过比较两个人脸嵌入的欧式距离来验证同个人。
度量学习是一个全连层,使用目标数据集(LFW)的训练集部分训练。通过训练好的度量学习层,获得人脸的1024维特征表达,然后直接以欧式距离来作为人脸是否为同一个脸的判定依据。
2.7 SphereFace
SphereFace(超球面)是佐治亚理工学院Weiyang Liu等在CVPR2017.04发表,提出了将Softmax loss从欧几里得距离转换到角度间隔,增加决策余量m,限制||W||=1和b=0,SphereFace: Deep Hypersphere Embedding for Face Recognition,github地址
这篇文章中提出了A-Softmax loss(Angular Softmax loss):使CNN能够学习角度识别特征,引人了角度间隔m,以使人脸特征的最大类内距离要小于最小类间距离,使学习的特征将更具有判别力。后面的L-Softmax loss、A-Softmax loss、CosFace、ArcFace、COCO loss、Angular Triplet Loss等都是angular margin learning系列。
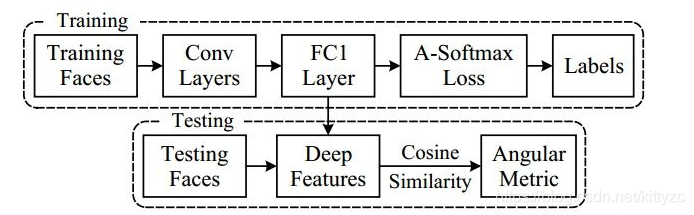
图像预处理部分,人脸关键点由MTCNN检测,再通过相似变换得到了被裁剪的对齐人脸。使用分类模型进行训练:CNN + A-Softmax Loss,CNN使用使用ResNet中的残差单元
测试阶段:从人脸分类器FC1层的输出中提取表示特征SphereFace,拼接了原始人脸特征和其水平翻转特征获得测试人脸的最终表示;对输入的两个特征计算余弦距离,得到角度度量。
人脸验证时,用阈值判断余弦距离。LFW上99.42%,YTF上95.0%,训练集使用CASIA-WebFace。2017年在MegaFace上识别率排名第一。
网络结构如下:
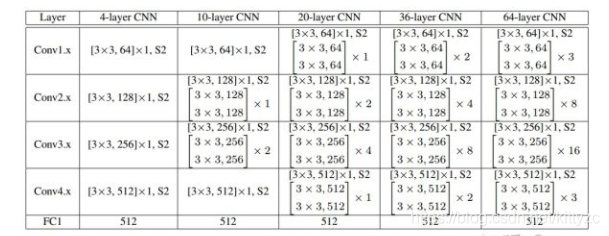
LFW上99.42%,YTF上95.0%。不如FaceNet,和DeepID2+、DeepID3相当,但它的训练集比FaceNet的小,CASIA-WebFace有49万张图片,1万个人。SphereFace仅使用公开可用的小规模数据集实现最先进的性能, 而其它商业算法使用私有和大规模数据集
2.8 CosFace
CosFace是腾讯AI Lab的Hao Wang等在CVPR2018.01发表,在SphereFace基础上改进了对特征向量归一化和additive cosine margin。由此,通过归一化和余弦决策边界的最大化,可实现类间差异的最大化和类内差异的最小化。CosFace: Large Margin Cosine Loss for Deep Face Recognition
损失函数使用了Large Margin Cosine Loss (LMCL):Cosine空间上的损失函数,将A-Softmax中的θ乘以m,改为了对cos(θ)减去余弦间隔m(additive cosine margin),还对特征向量和权重归一化。对LMCL来说,特征向量归一化到的固定值s需要足够大。
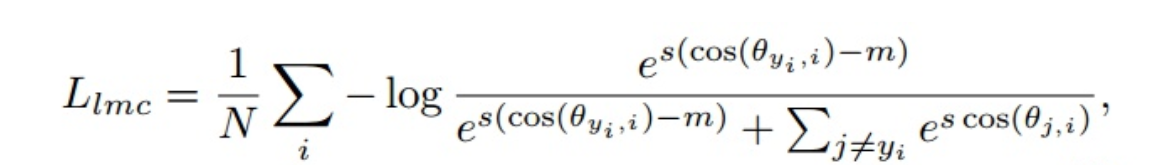
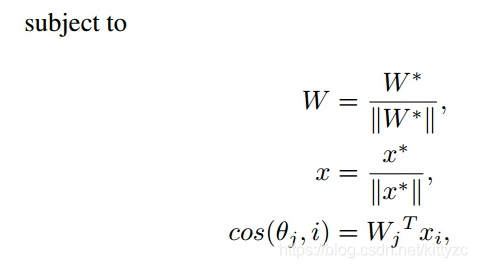
主要流程和SphereFace类似,用MTCNN对齐图片输入CNN进行训练,测试时也是经过此CNN来提取出特征,再做余弦相似度计算,来进行人脸验证和人脸识别。
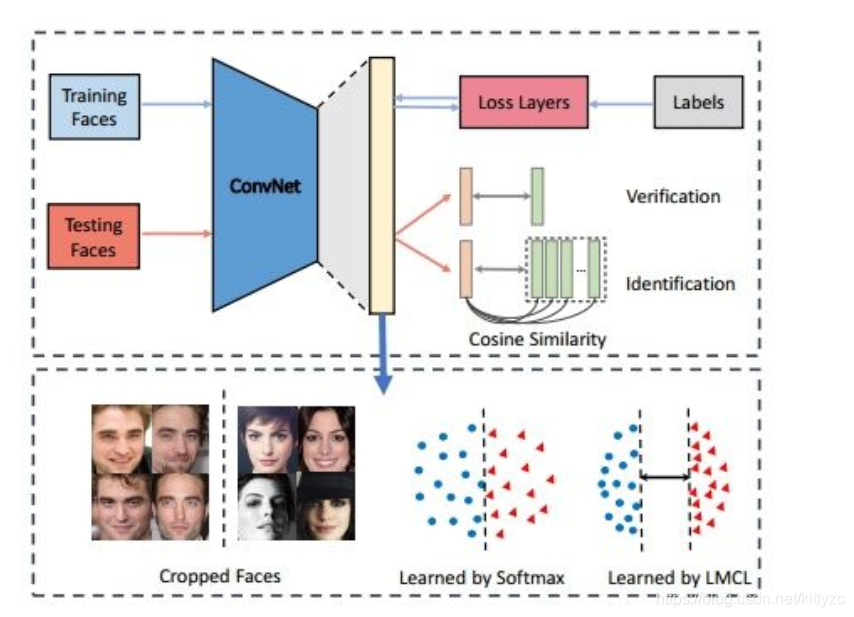
下图是不同损失函数示意:(NSL指的是Normalized Softmax Loss )
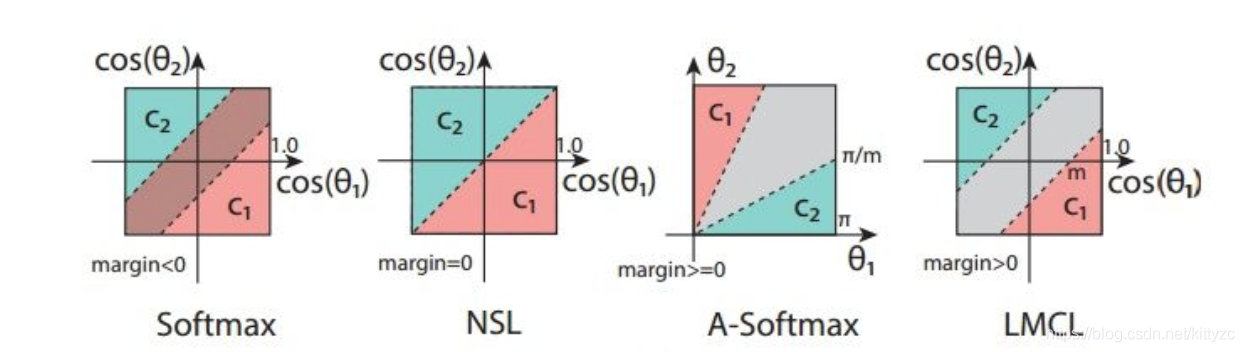
LFW上99.73%,YTF上97.6%,角度间隔损失系列首次超越FaceNet。数据集使用了多个公开数据集和一个私有数据集共500万张9万个人
2.9 ArcFace/InsightFace
ArcFace/InsightFace(弧度)是伦敦帝国理工学院邓建康等在2018.01发表,在SphereFace基础上改进了对特征向量归一化和加性角度间隔,提高了类间可分性同时加强类内紧度和类间差异,ArcFace: Additive Angular Margin Loss for Deep Face Recognition。这里是模型库。这里是github上的pytorch版本。
本文使用了ArcFace loss:Additive Angular Margin Loss(加性角度间隔损失函数),对特征向量和权重归一化,对θ加上角度间隔m,角度间隔比余弦间隔在对角度的影响更加直接。在xi和Wji之间的θ上加上角度间隔m(注意是加在了角θ上),以加法的方式惩罚深度特征与其相应权重之间的角度,从而同时增强了类内紧度和类间差异。
ArcFace中是直接在角度空间θ中最大化分类界限,而CosFace是在余弦空间cos(θ)中最大化分类界限。ArcFace直接优化geodesic distance margin(弧度),因为归一化超球体中的角和弧度的对应。为了性能的稳定,ArcFace不需要与其他loss函数实现联合监督,可以很容易地收敛于任何训练数据集。
预处理(人脸对齐)阶段,人脸关键点由MTCNN检测,再通过相似变换得到了被裁剪的对齐人脸。训练使用人脸分类器:ResNet50 + ArcFace loss
测试时,从人脸分类器FC1层的输出中提取512维的嵌入特征,对输入的两个特征计算余弦距离,再来进行人脸验证和人脸识别。
实际代码中训练时分为resnet model+arc head+softmax loss。resnet model输出特征;arc head将特征与权重间加上角度间隔后,再输出预测标签,求ACC是就用这个输出标签;softmax loss求预测标签和实际的误差。
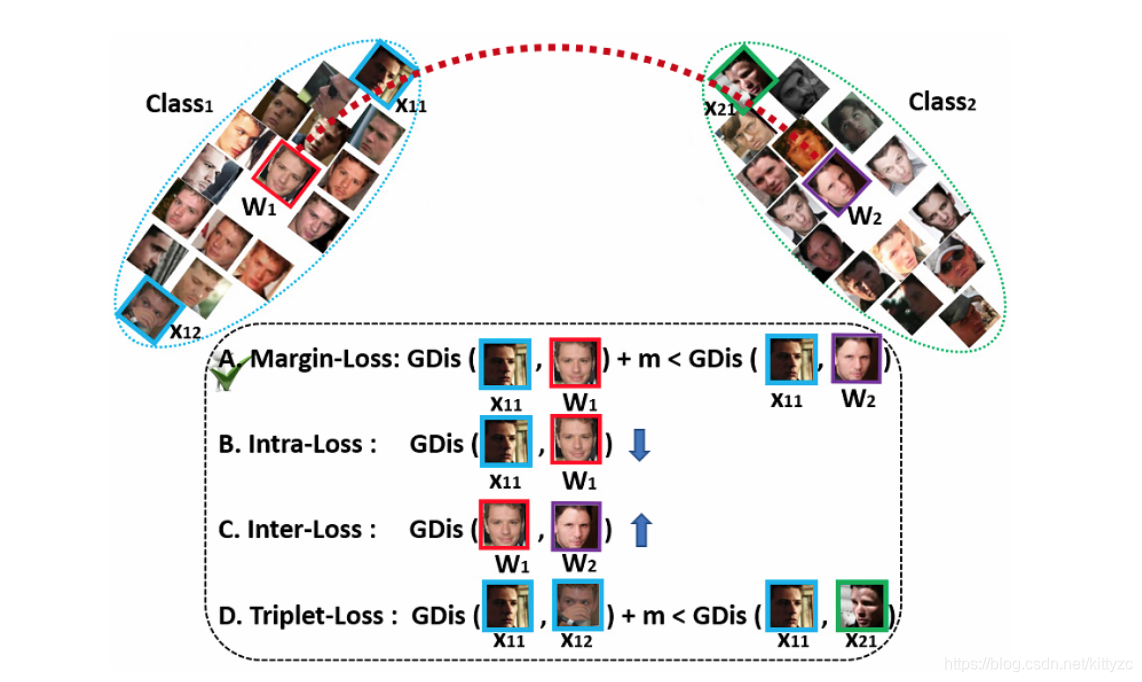
上图是论文中提出的几种不同的loss,最终选择了A。
LFW上99.83%,YTF上98.02%
2.10 VarGFaceNet
论文链接: VarGFaceNet: An Efficient Variable Group Convolution Neural Network for Lightweight Face Recognition
代码链接:GitHub/zma-c-137/VarGFaceNet
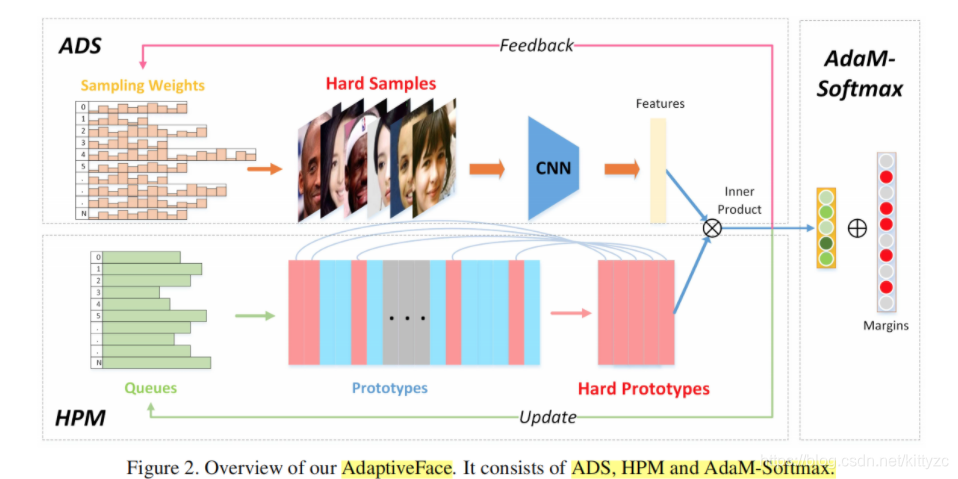
2.11 AdapticeFace
本文是对Margin based Softmax Loss的改进。主要针对人脸数据集类别不平衡的问题,以及难类别/难样本的挖掘,让训练过程变得高效。
2.12 RegularFace
论文主页。现有方法比如Center Loss, SphereFace, CosFace 和ArcFace都是集中于类内差异的压缩,在欧式空间(Center Loss)或者球面空间(SphereFace, CosFace 和ArcFace)上拉近特征到类中心的距离。
本文考虑的是判别性特征的另一个因素:类间相似。目的在于拉开不同类别间的距离,因此本文提出了一个正则化项 “Exclusve regularization”, 拉大不同类别的参数向量,生成具有“排斥性”的分类向量。
本文的创新点和优点有:
(1)用类别中心间的角度距离来评估类间分离性;
(2)提出了“Exclusive Regularization”来拉大不同类别间的角度距离;
(3)本文具有正交性,可以配合其他现有方法来进一步提高性能;
(4)在多个公开数据集上的性能有显著的提升
2.13 ShrinkTeaNet
提出了新的Teacher-Student Framework,即ShrinkTeaNet,以学习出轻量级、高精度、少参数的人脸识别网络
提出了Angular Dstillation Loss,以teacher net的特征方向以及样本分布为知识蒸馏到student中,使student更加灵活地提取特征,同时可以处理那些测试集中的未见类别,适用于开集任务
2.14 AirFace
论文链接
基于ArcFace loss提出了Air-Face loss
改进了MobileFace网络结构;
引入了注意力机制CBAM;
使用蒸馏技巧;
2.15 Efficient Polyface
3. 快速上手
3.1 DeepFace
deepface使用的算法包括:VGG-Face , Google FaceNet, OpenFace, Facebook DeepFace, DeepID and Dlib.
使用pip install deepface进行安装,然后直接使用:
demography = DeepFace.analyze(path + "yang1.jpeg", actions = ['age', 'gender', 'race', 'emotion'])
print("Age: ", demography["age"])
print("Gender: ", demography["gender"])
print("Emotion: ", demography["dominant_emotion"])
print("Race: ", demography["dominant_race"])
其他的例子参考github。