Flink集群搭建
Flink 可以选择的部署方式有:
Local、Standalone(资源利用率低)、Yarn、Mesos、Docker、Kubernetes、AWS。
我们主要对 Standalone 模式和 Yarn 模式下的 Flink 集群部署进行分析。
我们对standalone模式的Flink集群进行安装,准备三台虚拟机,其中一台作为JobManager(hadoop1),另外两台作为 TaskManager(hadoop2、hadoop3)。
3.1 Standalone 模式安装
1、下载安装包(进入官网下载 flink.apache.org -- downloads)
https://archive.apache.org/dist/flink/flink-1.7.2/
flink-1.7.2-bin-scala_2.11.tgz
2、解压安装包flink-1.7.2-bin-scala_2.11.tgz
tar -zxvf flink-1.7.2-bin-scala_2.11.tgz
3、开始配置文件(flink-conf.yaml)
cd /home/bigdata/flink-1.7.2/conf
vim flink-conf.yaml
# 主节点地址
33行:jobmanager.rpc.address: hadoop1
# job远程连接端口号
37行:jobmanager.rpc.port: 6123
# jobManager的内存大小
42行:jobmanager.heap.size: 1024m
# taskmanager的内存大小
47行:taskmanager.heap.size: 1024m
# slot的个数
52行:taskmanager.numberOfTaskSlots: 2
# 并行度
56行:parallelism.default: 4
4、配置slaves节点(同步到其他节点,hadoop2/hadoop3)
cd /home/bigdata
scp /etc/profile hadoop2:/etc/
scp -r ./flink-1.7.2 hadoop3`pwd`
5、启动flink(在master中启动)
/home/bigdata/flink-1.7.2/bin/start-cluster.sh
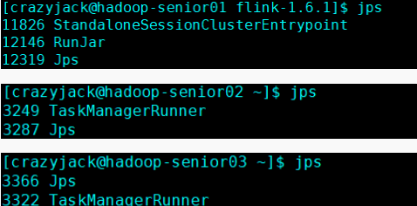
6、通过jsp查看进程信息
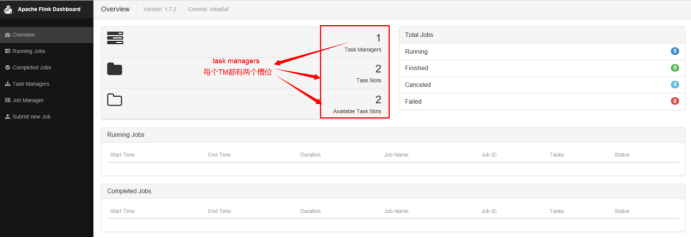
7、查看网页UI
192.168.11.11:8081
3.2 Yarn 模式安装
1、下载安装包(进入官网下载 flink.apache.org -- downloads)
https://archive.apache.org/dist/flink/flink-1.7.2/
flink-1.7.2-bin-scala_2.11.tgz
2、解压安装包flink-1.7.2-bin-scala_2.11.tgz
tar -zxvf flink-1.7.2-bin-scala_2.11.tgz
3、开始配置文件(flink-conf.yaml)
cd /home/bigdata/flink-1.7.2/conf
vim flink-conf.yaml
# 主节点地址
33行:jobmanager.rpc.address: hadoop1
# job远程连接端口号
37行:jobmanager.rpc.port: 6123
# jobManager的内存大小
42行:jobmanager.heap.size: 1024m
# taskmanager的内存大小
47行:taskmanager.heap.size: 1024m
# slot的个数
52行:taskmanager.numberOfTaskSlots: 2
# 并行度
56行:parallelism.default: 4
4、配置slaves节点(同步到其他节点,hadoop2/hadoop3)
hadoop2
hadoop3
cd /home/bigdata
scp /etc/profile hadoop2:/etc/
scp -r ./flink-1.7.2 hadoop3`pwd`
5、启动 Hadoop 集群(HDFS 和 Yarn)
start-all.sh
6、在hadoop1节点提交Yarn-Session(使用安装目录下bin 目录中的)
yarn-session.sh 脚本进行提交:
/opt/modules/flink-1.6.1/bin/yarn-session.sh -n 2 -s 6 -jm 1024 -tm 1024 -nm test -d
参数释义:
-n(--container):TaskManager 的数量。
-s(--slots): 每个 TaskManager 的 slot 数量,默认一个 slot 一个 core,默认每个
taskmanager 的 slot 的个数为 1。
-jm:JobManager 的内存(单位 MB)。
-tm:每个 taskmanager 的内存(单位 MB)。
-nm:yarn 的 appName(现在 yarn 的 ui 上的名字)。
-d:后台执行。
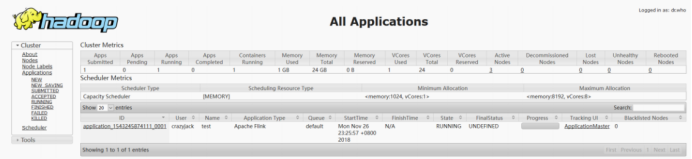
7、启动后查看 Yarn 的 Web 页面,可以看到刚才提交的会话
192.168.11.11:8088
8、在提交Session的节点查看进程

9、提交Jar到集群运行
/home/bigdata/flink-1.6.1/bin/flink run -m yarn-cluster examples/batch/WordCount.jar
10、提交后在 Yarn 的 Web 页面查看任务运行情况
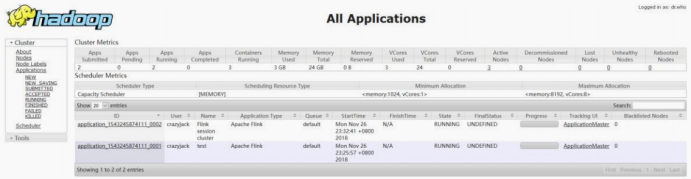
11、任务运行结束后在控制台打印如下输出