【深度学习】YOLO V5 超参数优化
超参数优化方法
https://en.wikipedia.org/wiki/Hyperparameter_optimization
深度学习模型超参数优化是指通过调整模型的超参数(即不由模型自身学习的参数)来改善模型的性能和泛化能力。超参数包括学习率、批次大小、层的数量和大小、正则化参数等。
超参数优化可以被视为在超参数空间中搜索最优解的过程。超参数空间由各种超参数的取值范围组成,搜索的目标是找到最佳的超参数组合,使得模型在给定任务和数据集上达到最佳性能。
此外超参数优化是一个迭代的过程,目标是找到一组最佳的超参数配置,以最大程度地提高模型的性能。以下是一些常见的超参数优化方法:
网格搜索(Grid Search):遍历预定义的超参数组合,通过交叉验证或验证集上的性能评估来确定最佳组合。这种方法适用于超参数空间较小的情况,但当超参数数量增加时,计算成本会急剧增加。随机搜索(Random Search):随机选择一组超参数组合,并通过性能评估来选择最佳组合。相对于网格搜索,随机搜索可以更好地处理超参数空间较大的情况,并且通常具有更高的效率。贝叶斯优化(Bayesian Optimization):使用贝叶斯方法建立超参数与模型性能之间的函数关系,通过不断选择具有最大期望改进的超参数进行迭代优化。贝叶斯优化通常能够在相对较少的迭代次数内找到更好的超参数组合。梯度优化(Gradient-based Optimization):将超参数优化问题转化为梯度优化问题,通过计算超参数对模型性能的梯度来更新超参数。这种方法需要模型性能关于超参数的梯度信息,通常需要更复杂的推导和计算。自动机器学习(AutoML):使用自动化工具和算法搜索超参数空间,以找到最佳的超参数组合。AutoML方法结合了以上的方法,并引入了自动化的流程来加速超参数搜索和模型选择过程。遗传算法(Evolutionary optimization):将超参数组合看作是个体,并通过遗传算法的操作(如选择、交叉和变异)来模拟进化过程。初始时,随机生成一组超参数组合作为种群,并通过交叉和变异等操作生成新的个体。早停法(Early stopping-based):根据验证集上的性能指标(如验证误差或准确率)来监控模型的训练过程。训练过程中,如果验证集上的性能指标在一定轮次内不再改善或开始出现下降趋势,就可以停止训练,避免过拟合。
YOLO V5 超参数
https://raw.githubusercontent.com/ultralytics/yolov5/master/train.py
weights:初始权重路径,指定用于模型初始化的权重文件的路径。cfg:模型配置文件的路径,指定用于定义模型结构的配置文件。data:数据集配置文件的路径,指定用于加载训练和验证数据的配置文件。hyp:超参数文件的路径,指定包含训练过程中的超参数设置的文件。epochs:总的训练轮数,指定要执行的训练迭代次数。batch-size:每个批次的图像数量,指定每个训练批次中要使用的图像数目。imgsz:训练和验证图像的尺寸(像素),指定用于训练和验证的图像的大小。rect:是否进行矩形训练,如果启用,则在训练过程中将图像调整为固定的矩形尺寸。resume:是否恢复最近的训练,如果设置为True,则会自动加载最近的训练检查点并继续训练。nosave:是否只保存最终的检查点,如果启用,则只保存最后一个训练轮次的模型检查点。noval:是否只验证最终的训练轮次,如果启用,则只在最后一个训练轮次进行验证。noautoanchor:是否禁用自动锚框的计算。noplots:是否保存不生成任何图表文件。evolve:进化超参数的代数数目,指定要对超参数进行进化优化的代数数目。bucket:gsutil存储桶的名称,指定要将训练结果上传到的存储桶。cache:图像缓存方式,指定训练过程中使用的图像缓存方式(ram或disk)。image-weights:是否在训练中使用加权图像选择。device:设备选择,指定要在哪个设备上进行训练(cuda设备或CPU)。multi-scale:是否在训练过程中使用多尺度数据增强。single-cls:是否将多类别数据训练为单类别。optimizer:优化器选择,指定要使用的优化器(SGD、Adam或AdamW)。sync-bn:是否使用同步批归一化,在DDP模式下可用。workers:最大数据加载器工作线程数目(DDP模式下每个RANK的最大工作线程数)。project:保存路径的项目名称,指定保存训练结果的项目名称。name:保存路径的实验名称,指定保存训练结果的实验名称。exist-ok:是否允许使用已存在的项目和实验名称,如果启用,则不会增加新的编号。quad:是否使用四通道数据加载器。cos-lr:是否使用余弦学习率调度程序。label-smoothing:标签平滑的ε值,指定用于标签平滑的ε值。patience:EarlyStopping的等待次数(未改进的训练轮次数)。freeze:冻结层的索引列表,指定要冻结的网络层。save-period:每隔多少轮保存一次检查点(如果小于1,则禁用保存)。seed:全局训练种子,指定用于训练的随机种子。local_rank:自动DDP多GPU参数,不要修改。
YOLO V5 训练建议
https://docs.ultralytics.com/yolov5/tutorials/tips_for_best_training_results/
如果数据集足够大且标注良好,那么在不改变模型或训练设置的情况下,通常可以获得良好的结果。如果一开始没有获得良好的结果,则可以采取一些措施来改善,但始终建议用户首先使用默认YOLO V5设置进行训练,然后再考虑是否进行任何更改。这有助于建立性能基线并找出改进的方向。
如果对训练结果有疑问,建议从结果图表(训练损失、验证损失、P、R、mAP)、PR曲线、混淆矩阵、训练集合成图像、测试结果以及数据集统计图像中寻找答案。
数据集
每类图像:推荐每类至少1500张图像。
每类实例:推荐每类至少10000个实例(有标签的对象)。
图像的多样性:对于真实世界的使用情况,建议使用不同时间、不同季节、不同天气、不同光照、不同角度、不同来源(在线获取、本地采集、不同相机)的图像等。
标签一致性:所有图像中所有类别的实例必须都有标签。部分标注将无法工作。
标签准确性:标签必须紧密包围每个对象。对象与其边界框之间不应有空白。没有对象应该缺少标签。
标签验证:在训练开始时查看train_batch*.jpg以验证标签是否正确,即查看示例的合成图像。
背景图像:背景图像是没有对象的图像,将其添加到数据集中以减少误报(FP)。
模型结构
较大的模型(如YOLOv5x和YOLOv5x6)在几乎所有情况下都能产生更好的结果,但是参数更多,训练时需要更多的CUDA内存,并且运行速度较慢。对于移动部署,推荐使用YOLOv5s/m,对于云端部署,推荐使用YOLOv5l/x。
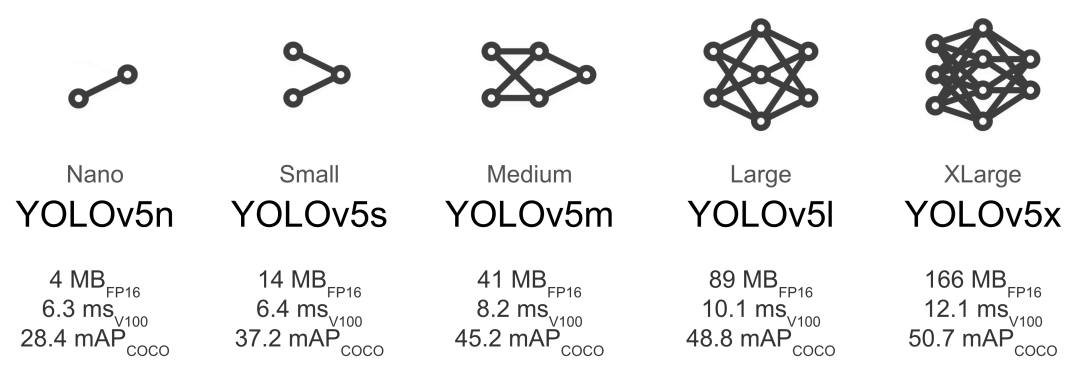
在小到中等规模的数据集上训练,建议直接使用训练模型参数。
python train.py --data custom.yaml --weights yolov5s.pt
yolov5m.pt
yolov5l.pt
yolov5x.pt
custom_pretrained.pt在大型数据集(如COCO、Objects365、OIv6)上训练,建议可以考虑指定网络结构从头训练。
调参方法
在修改任何设置之前,首先使用默认设置进行训练,以建立性能基准。
训练轮数:从300轮开始。如果早期出现过拟合,可以减少轮数。如果在300轮之后没有出现过拟合,可以继续训练更多轮次,例如600、1200等。图像大小:COCO数据集以640的本机分辨率进行训练,但由于数据集中有大量小物体,因此可以尝试更高分辨率的训练,例如1280。如果数据集中有许多小物体,自定义数据集将受益于以本机分辨率或更高分辨率进行训练。最佳的推理结果可以在与训练时相同的。Batch size:使用硬件允许的最大的batch size。太小的batch size会导致不良的批归一化统计结果,超参数:默认的超参数在hyp.scratch-low.yaml文件中。我们建议在考虑修改任何超参数之前先使用默认超参数进行训练。通常情况下,增加数据增强的超参数可以减少和延迟过拟合,从而实现更长的训练和更高的最终mAP。
YOLO V5 遗传优化
https://docs.ultralytics.com/yolov5/tutorials/hyperparameter_evolution/
YOLO自带了使用遗传算法(GA)进行优化的超参数优化的教程,也是推荐大家来进行使用。
默认超参数
YOLOv5使用大约30个超参数来进行各种训练设置。这些超参数在/data/hyps目录下的*.yaml文件中进行定义。更好的初始猜测将产生更好的最终结果,但在进行进化之前正确初始化这些值非常重要。
定义适应度
适应度是我们希望最大化的值。在YOLOv5中,我们定义了一个默认的适应度函数,它是一组指标的加权组合:mAP@0.5贡献10%的权重,mAP@0.5:0.95贡献剩余的90%,其中精确率P和召回率R没有被考虑进来。您可以根据需要调整这些权重。
def fitness(x):
# 将模型的适应度定义为指标的加权组合
w = [0.0, 0.0, 0.1, 0.9] # [P, R, mAP@0.5, mAP@0.5:0.95] 的权重
return (x[:, :4] * w).sum(1)演化搜索
通过添加 --evolve 参数,可以启动超参数的进化过程,使用遗传算法来搜索更优的超参数配置。
python train.py --epochs 10 --data coco128.yaml --weights yolov5s.pt --cache --evolve默认的进化设置将运行基础场景300次,即进行300代的进化。您可以通过 --evolve 参数来修改代数,例如 python train.py --evolve 1000。
主要的遗传操作包括交叉和突变。在这个工作中,使用突变操作,以前几代中最好的父代为基础,以80%的概率和0.04的变异率生成新的后代。结果将记录在 runs/evolve/exp/evolve.csv 中。
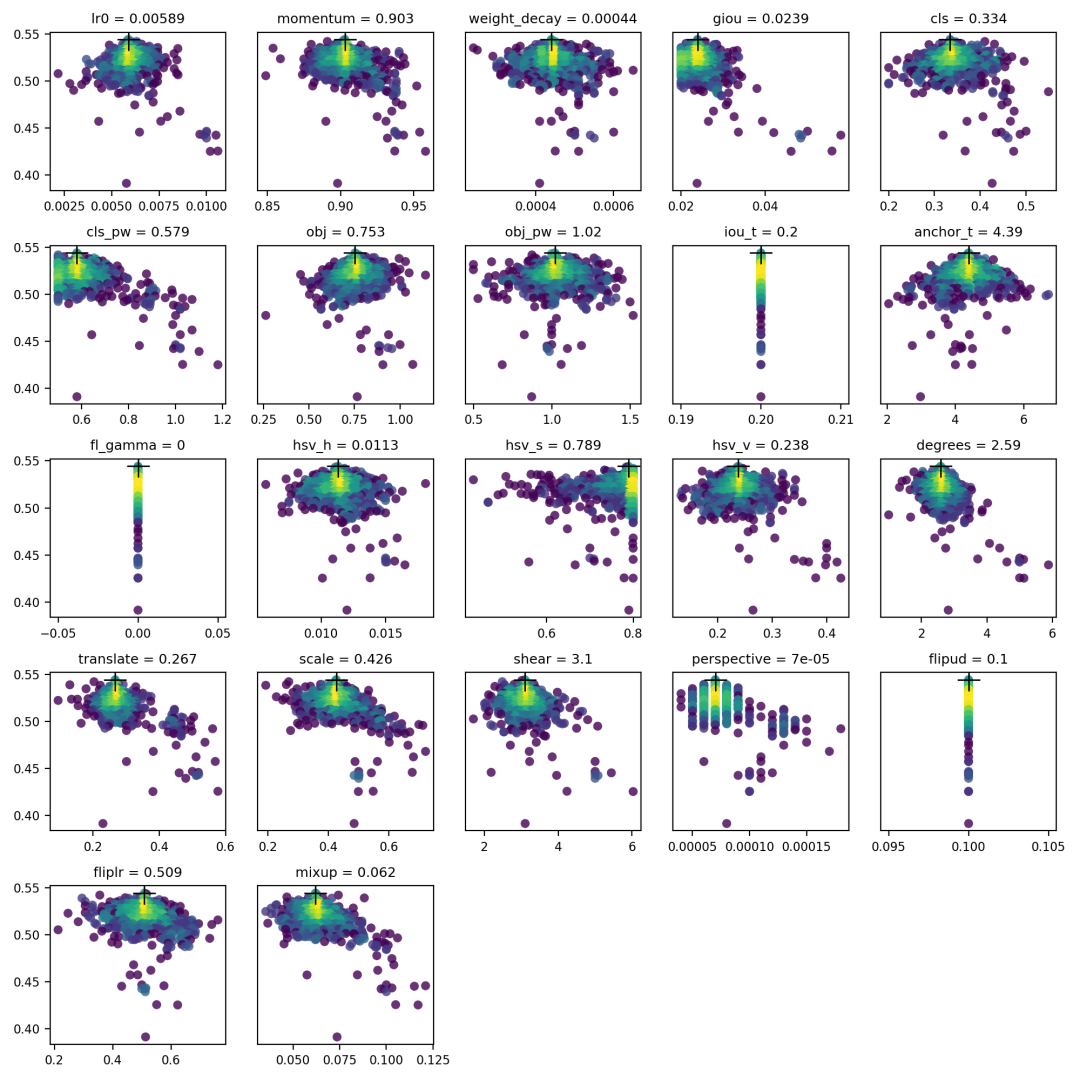
YOLO V5默认超参数
无数据增强版本
https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.no-augmentation.yaml
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
# Hyperparameters when using Albumentations frameworks
# python train.py --hyp hyp.no-augmentation.yaml
# See https://github.com/ultralytics/yolov5/pull/3882 for YOLOv5 + Albumentations Usage examples
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.3 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 0.7 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
# this parameters are all zero since we want to use albumentation framework
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0 # image HSV-Hue augmentation (fraction)
hsv_s: 0 # image HSV-Saturation augmentation (fraction)
hsv_v: 0 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0 # image translation (+/- fraction)
scale: 0 # image scale (+/- gain)
shear: 0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.0 # image flip left-right (probability)
mosaic: 0.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)轻度数据增强版本
https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-low.yaml
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.5 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 1.0 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)中度数据增强版本
https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-med.yaml
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.3 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 0.7 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.9 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.1 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)重度数据增强版本
https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-high.yaml
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 0.05 # box loss gain
cls: 0.3 # cls loss gain
cls_pw: 1.0 # cls BCELoss positive_weight
obj: 0.7 # obj loss gain (scale with pixels)
obj_pw: 1.0 # obj BCELoss positive_weight
iou_t: 0.20 # IoU training threshold
anchor_t: 4.0 # anchor-multiple threshold
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.9 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.1 # image mixup (probability)
copy_paste: 0.1 # segment copy-paste (probability)
往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习微信群请扫码