python基础阶段(五)—— 函数
-
概念(作用):写了一段代码实现了某个小功能; 然后把这些代码集中到一块, 起一个名字; 下一次就可以根据这个名字再次使用这个代码块, 这就是函数,它可以使代码模块化,更加方便
1. 定义函数
1.1 简单定义
- def 函数名称(参数1,参数2,... ):
- 函数体
在我们调用函数时,直接用 函数名称(参数)即可,多参时,形参和实参需要一一对应
注意:python中的函数是引用传递(即:是指传递过来的, 是一个变量的地址,通过地址, 可以操作同一份原件),不是值传递(即:是指传递过来的, 是一个数据的副本,修改副本, 对原件没有任何影响)
1.2 函数参数
- 形参和实参
在函数的定义中,所用的参数是形参——它是函数完成工作所需的一项信息,而在我们调用函数过程中,输入的参数是实参——它是调用时传递给函数的信息
def greet(name):
print("Hello," + name.title() + "!")
greet("russell")
#在该例中,name是形参,“russell”是实参
- 不定长参数:
有些时候,在函数体中我们需要处理的数据不确定长度,因此我们无法确定参数具体的个数,此时可以:
(1)在形参前面加一个星号(*),使函数接收一个元组(元组比列表的好处:不可变)
(2)在形参前面加两个星号(*),使函数接收一个字典(调用:函数名(参数1 = x ,...) )
- 参数的装包和拆包(针对于上述两种函数)
装包:把传递的参数, 包装成一个集合(元组 列表) 其实上面两种函数就是进行了装包操作
拆包:把集合参数, 再次分解成单独的个体 (只需要在参数使用时前面再加上*或**)
def test(*aaa): #装包操作
print(aaa) #未拆包
print(*aaa) #拆包
test(1,"a",3)
#结果为:(1, 'a', 3)
# 1 a 3- 缺省参数(默认值)
有时使用函数时,某个参数一般为一个固定值,这种参数可输入也可不输入,如果不输入,则可以使用默认值,这种参数就是缺省参数
定义方式:def 函数名(变量名 = 默认值):
1.3 返回值
当我们通过某个函数, 处理好数据之后, 想要拿到处理的结果,然后对这个结果进行进一步的操作
- 语法:def 函数 ():
函数体
return 数据 - 注意:(1)return语句下面的代码,不会再执行
(2)return只可以返回一次,如果想返回多个数据,可以包装成列表、元组等返回
def caculate(a,b):
he = a + b
cha = a - b
return (he,cha)
print(caculate(1,2))- return 和 print 的区别,以及return函数的必要性
(1)定义一个函数,最后不写return,调用函数是没有输出的
(2)定义一个函数,最后用return,调用时相当于函数告诉计算机结果,计算机再打印出来
(3)定义一个函数,最后用print,调用时相当于在运行过程中,就直接打印出来了
1.4 函数的使用注释
- 定义格式:
def 函数 () :
''' 这里写帮助信息 ''' (这个三引号可以跨行写)
函数体
- 使用help(函数)可以查看函数使用说明
2. 函数的几种高级使用
2.1 偏函数
- 场景:
当我们编了一个参数较多的函数时,我们发现某些参数在大多场景下都是固定的值,重新编写可能麻烦,为了简化,就可以新创建一个偏函数
- 语法: import functools(模块)
newFunc = functools.partial(旧函数, 特定参数 = 默认值)
2.2 高阶函数及返回函数
- 当一个函数A的参数, 接收的又是另一个函数时, 则把这个函数A成为是"高阶函数"
- "返回函数"是指一个函数内部, 它返回的数据是另外一个函数
# 返回函数案例
def func(flag):
def sum(a,b,c):
return a+b+c
def sub(a,b,c):
return a-b-c
#根据不同的flag值调取不同的参数
if flag == "+":
return sum
elif flag == "-":
return sub
result = func("+")
print(result(1,3,5))2.3 匿名函数
- 匿名函数也成为lambda函数,顾名思义,即没有名字的函数
- 语法:lambda 参数1, 参数2.. : 表达式
- lambda函数适用于一些简单的场景,可以省去编写def函数公式,操作更方便
# key参数讲解
num = [("abc",12),("abd",10)]
# def getkey(x):
# return x[0] # 0:根据第一个元素排序 1:根据第二个元素排序
# print(sorted(num,key = getkey))
print(sorted(num,key = lambda x:x[0]))
# 利用被注释掉的函数比较复杂,此处就可以直接利用lambda函数2.4 闭包(closure)
在函数嵌套的前提下,内层函数引用了外层函数的变量(包括参数),外层函数又把内层函数
当做返回值进行返回(返回值是一个函数),则这个内层函数+所引用的外层变量, 称为 "闭包"。
闭包的作用是可以保存当前的运行环境
- 注意:
(1)闭包中,若要修改引用的外层变量,需要使用 nonlocal+变量名(使之成为局部变量)
(2)闭包中,若引用了一个后期会变化的变量,要注意函数在定义时不会识别这个变量所对应的值,只有在执行时才会识别
- 所以使用闭包时,返回函数尽量不要引用任何循环变量,或者后续会发生变化的变量。
- 如果一定要引用循环变量,方法是再创建一个函数,用该函数的参数绑定循环变量当前的值,无论该循环变量后续如何更改,已绑定到函数参数的值不变
# 根据配置信息, 生成不同的分割线函数
def line_a(content,length):
'''
内层函数line()引用了外层函数变量content以及length
外层函数把内层函数line()当作返回值返回
'''
def line():
print("-"*(length//2) + content + "-"*(length//2))
return line
line1 = line_a("xxx",40)
line2 = line_a("分割线",60) #不同的配置信息,生成的函数不同
line1()
line2()2.5 装饰器
python装饰器就是用于拓展原来函数功能的一种函数,这个函数的特殊之处在于它的返回值也是一个函数(闭包),它其实就是闭包的一种
作用:在函数名以及函数体不改变的前提下, 给一个函数附加一些额外代码
他在执行@zsq时,等同于执行 func()=zsq(func)
# 在不改变原结构和函数名的条件下,增加”登录验证“额外语句
def fss():
print("发说说")
# 修改如下:使用闭包(装饰器)
def check(func):
def inner():
print("登录操作验证......")
func() #关键,相当于fss函数会在这里嵌套
return inner
@check #在这里就执行,立即执行 相当于:fss() = check(fss),
def fss(): #即:要将inner返回给外界,用fss函数来接收
print("发说说")
fss() # 调用fss就相当于调用上面的inner函数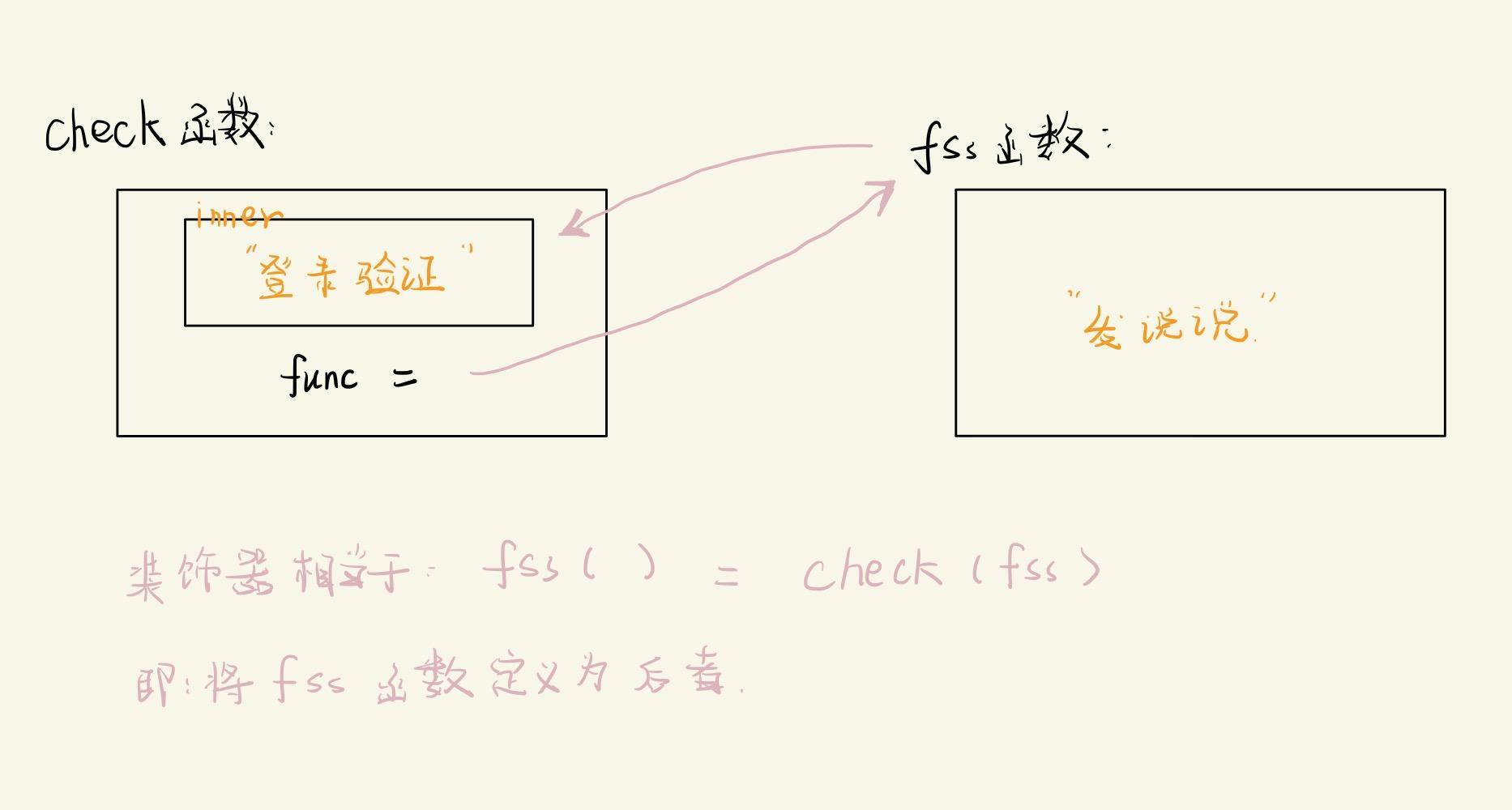
- 注意:
(1)装饰器可以叠加,由下到上装饰,从上到下执行,即谁在最外层/上面,先执行谁
(2)对于有参数的函数,也要在inner函数中添加对应个数的参数(名称也要一致)
为了通用于多个函数,也可以用不定长参数代替,结合装包拆包的操作运用
(3)对于有返回值的函数,也要在inner函数中加入return语句(保持两者格式一致)
这是因为在return语句中,返回值仅仅返回给了函数的调用,并未返回给inner
#装饰有参数和返回值的函数 案例
def zsq(func):
def inner(*arg,**kwargs): # 使用不定长参数处理多个函数参数数量不一致的情况
print("-" * 30)
res = func(*arg,**kwargs) # 函数的返回值返回给res,并未返回给inner函数
return res
return inner
@zsq
def num(n1,n2,n3):
return n1 + n2 + n3
@zsq
def num2(n):
return n
print(num(1,2,3))
print(num2(8))(4)对于有参数的装饰器(我们希望根据不同的参数得到不同的装饰器),
我们不能在装饰器中增加额外的参数
原因如下:
我们可能会认为增加了参数之后@zsq(char = “ - ”),执行时代码会变成
func()= zsq(func,char = “ - ”) ,但python解释器并非如此设计,
它对加上了参数的装饰器多做了一层封装,执行func时相当于执行了这段代码:
func1 = zsq(char)
func2 = func1(func1)
正因为额外多封装了一层,所以函数和装饰器参数传入装饰器的顺序是不一样的
因此,我们只需要在装饰器当中多封装一层就可以了,用来输入不同的参数而获取不同的装饰器,并返回这个装饰器
# 带有参数的装饰器 案例
def getzsq(char): #这个函数专门用来获取装饰器
def zsq(func):
def inner():
print(char * 30)
func()
return inner
return zsq
@getzsq("x") # 先执行这一行,再执行下一行
@getzsq("*")
def num():
print("陌生老朋友")
num()2.6 生成器
生成器是一个特殊的迭代器,他比迭代器更“优雅”,任何实现了 next方法的对象都可称为迭代器。
- 迭代器:
顾名思义,迭代器就是用于迭代操作(for 循环)的对象,它像列表一样可以迭代获取其中的每一个元素,但他的优点是不像列表把所有元素一次性加载到内存,而是采用惰性计算的方法,等到调用 next 方法时候才返回该元素,节省了大量内存
- 生成器:
普通函数用 return 返回一个值,而在 Python 中还有一种函数,用关键字 yield 来返回值,这种函数叫生成器函数,函数被调用时会返回一个生成器对象,生成器本质上还是一个迭代器,但更加简洁
- 生成器的创建及访问
# 创建方式1:将列表的[]改为() l = (i * 2 for i in range(1,1000) if i % 2 ==0 ) print(l) # 输出结果为:<generator object <genexpr> at 0x000001AB69EF9510> print(next(l)) # 访问生成器 # 创建方式2:生成器函数:用yeild代替return返回 # yield,可以阻断当前函数执行,然后使用next函数会让函数继续执行, # 当执行到下一个yield函数,又会暂停 def func(n): yield n*2 print(next(func(5))) # 访问方式1:next函数 for i in func(5): # 访问方式2:for x in xxx print(i) func(5).close() # 关闭生成器
2.7 递归函数
在函数A的内部,继续调用函数A
- 两个重点:传递 & 回归(有传递,一定要有回归,否则会成为无限循环)
# 案例:求n的阶乘
# n! = n * (n-1)! = n * n-1 * (n-2)! = ......
def jiecheng(n):
if n == 1:
return 1
return n * jiecheng(n-1) #再次调用函数
print(jiecheng(5))3.函数的作用域
Python是静态作用域,在Python中,变量的作用域源于它在代码中的位置;
在不同的位置, 可能有不同的命名空间
3.1 命名空间的类别
LEGB规则:按照L -> E -> G -> B 的顺序进行查找,从内到外访问,就近原则
| LEGB(由小到大) | 命名空间 | 作用范围 |
|---|---|---|
| L | 函数内的命名空间 | 当前整个函数体范围 |
| E | 外部嵌套函数的命名空间 | 闭包函数 |
| G | 全局命名空间 | 当前模块(文件) |
| B | 内建模块命名空间 | 所有模块(文件) |
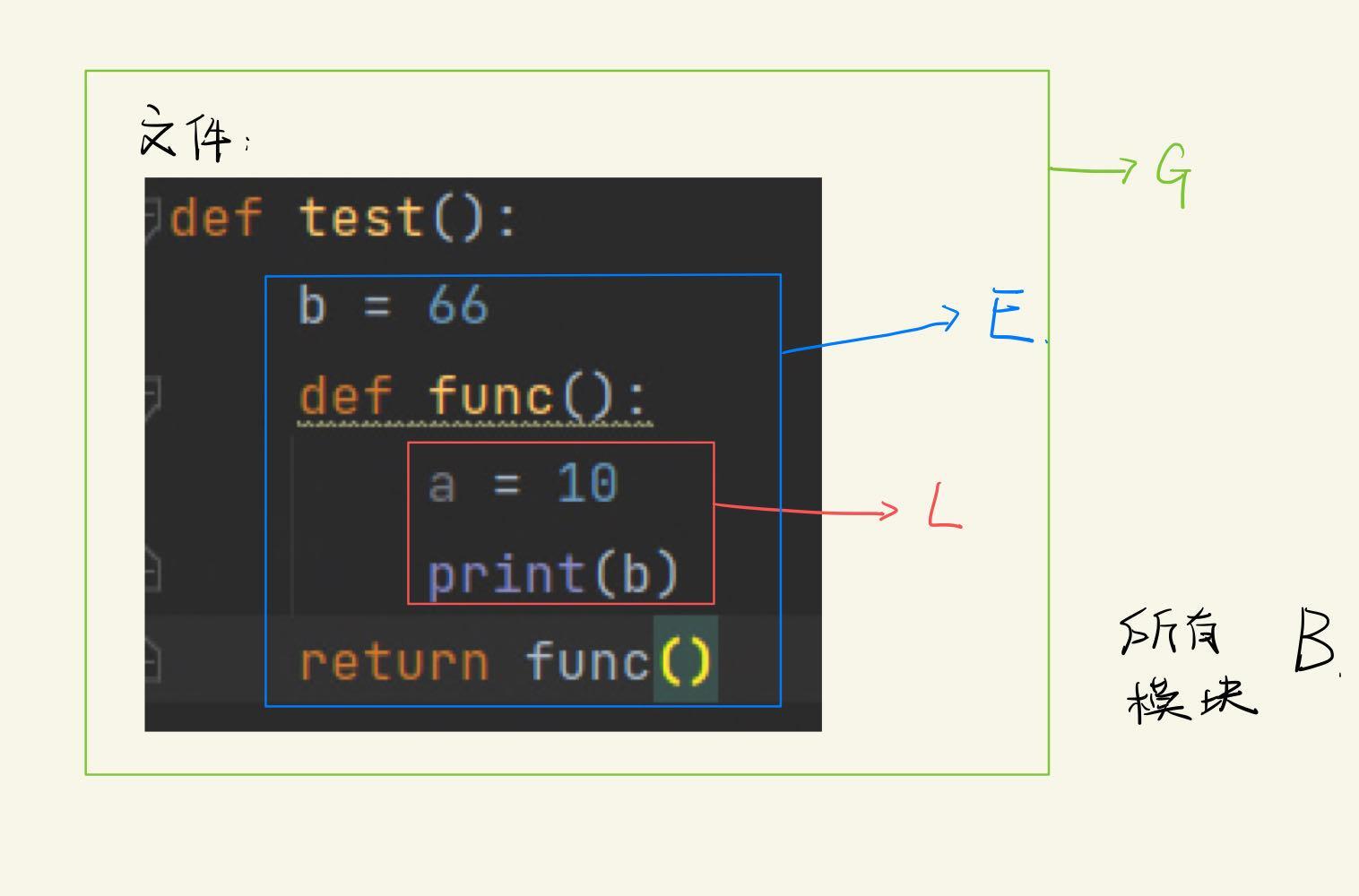
- 注意:Python中没有块级作用域:比如 if while for 后的代码块,这些代码块都不是作用域
3.2 基于命名空间的常见变量类型
| 变量类型 | 定义 | 作用域 | 查看方式 |
|---|---|---|---|
| 局部变量 | 在一个函数内部定义的变量 | 函数内部 | locals() |
| 全局变量 | 在函数外部, 文件最外层定义的变量 | 整个文件内部 | globals() |
- 若全局变量和局部变量重名,访问时采用就近原则
- 若要在函数内的命名空间中修改全局变量:使用global + 变量名
- 若要在函数内的命名空间中修改外层函数中的变量:使用 nonlocal + 变量名
a = 10 # 全局变量
def test():
b = 66
global a #在函数空间修改全局变量a
a = 20
def func():
nonlocal b#在函数空间修改外层函数变量b
b = 55
print(a)
print(b)
return func()
print(a) #结果为10
test() #结果为 a = 20,b = 55