C++20形式的utf-8字符串转宽字符串,不依赖编译器编码形式
默认的char[]编码都是要看编译器编译选项的,你选了ANSI那它就是ANSI,你选了UTF8那它就是UTF8.
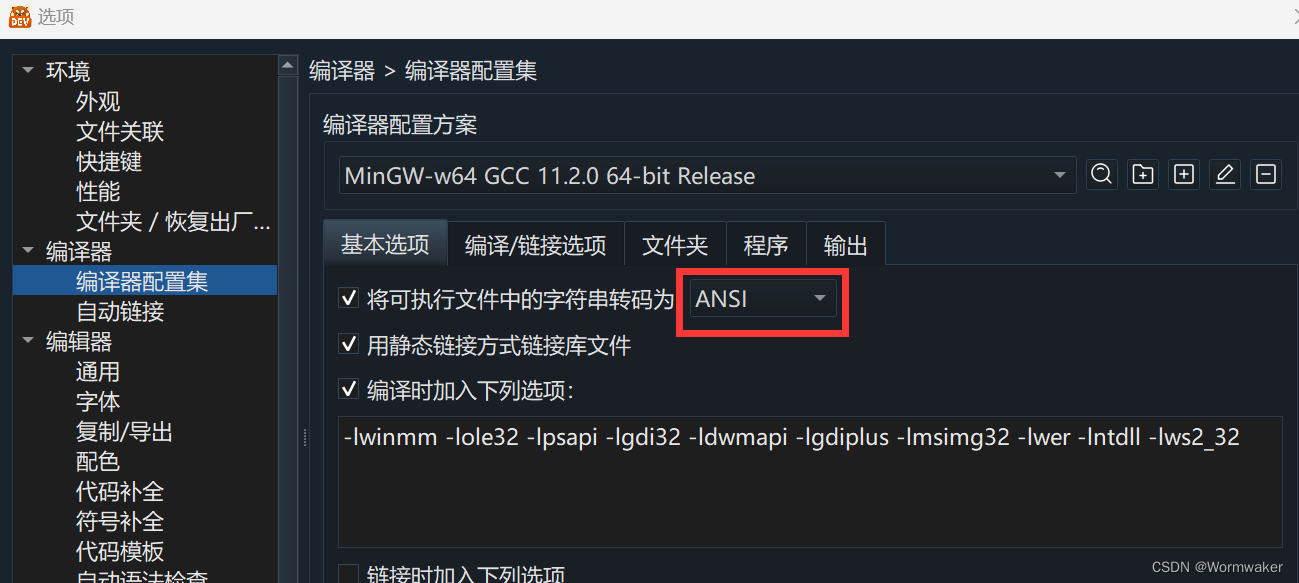
【注意:经典DevC++只支持ANSI编码(痛苦);上图是小熊猫DevC++,则有这个选项】
这一点对我的代码造成了麻烦。我就是要用utf8字符串,无视编译器编码选项,并输出,怎么搞?
先看什么是麻烦的代码:
#include <windows.h>
#include <stdio.h>
// 将UTF-8字符串转换为宽字符串(不一定是UTF-16)
wchar_t* utf8_to_wstr(const char* utf8_string)
{
// 获取UTF-8字符串的长度
int len = strlen(utf8_string);
// 计算所需缓冲区大小
int w_size = MultiByteToWideChar(CP_UTF8, 0, utf8_string, len, NULL, 0);
// 分配宽字符串缓冲区
wchar_t* w_string = (wchar_t*)malloc((w_size + 1) * sizeof(wchar_t));
// 将UTF-8多字节转换为宽字符串
MultiByteToWideChar(CP_UTF8, 0, utf8_string, len, w_string, w_size);
w_string[w_size] = L'\0'; // 添加NULL终止字符
return w_string;
}
int main() {
const char* utf8_string = "Wormwaker创作";
// 转换为wchar_t*
wchar_t* w_string = utf8_to_wstr(utf8_string);
// 使用MessageBoxW显示UTF-16字符串
MessageBoxW(NULL, w_string, L"MessageBoxW", MB_OK);
// 释放内存
free(w_string);
return 0;
}
上述代码字符以char类型存储,编码依赖编译器选项。如果为ANSI,则结果为:

如果为UTF-8,才是正确的结果:
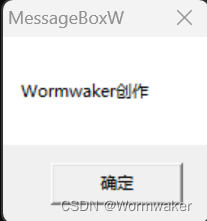
· 试想,把含类似于这样一段代码的项目(例如一个软件或是一个游戏)代码发给你一个朋友,他一看运行出来是乱码,他第一反应就是你写的有问题,是你的问题。他基本不会考虑自己的编码选项有问题。你可能还要教他怎么调,这将消耗你宝贵的时间。于是,这段代码可能需要变得兼容一点。
随着时代的进步,C++针对utf编码的字符出现了更新:
C++11
1.添加新字符类型 char16_t 和 char32_t,分别对应utf-16和utf-32编码。同时也添加了相应的std::basic_string,也就是 std::u16string 和 std::u32string.
2.添加三种字符串字面量前缀:u, U, 以及 u8,分别对应utf-16, utf-32, utf-8编码。
注意:此时还没有 char8_t !
这时候就可以写这样的代码了:
char16_t utf16c = u'好';
char32_t utf32c = U'好';
char utf8[] = u8"你好世界";
char16_t utf16[] = u"你好世界";
char32_t utf32[] = U"你好世界";
注意!因为没有 char8_t[],所以u8字符串被存在了char[]里。
而且:
C++ 17
到了C++17才添加了对u8前缀的utf-8字符的支持!也就是说,下面这么写必须 有 是C++17标准:
char utf8c = u8'a'; // C++17标准
//char utf8c = u8'好';
到这里已经可以实现我们想要的兼容性了,不过到最后再一起说
C++ 20
C++20终于把 char8_t 加入到了基本类型中。现如今所有u8的字符和字符串都必须用char8_t系列存储了,不允许使用char了。 也就是说,应该改成这样:
char8_t uft8c = u8'a'; //C++20
const char8_t* pstrUtf8 = u8"Hello World";
std::u8string sutf8 {u8"Hello Universe"};
当然有char8_t那就肯定也一起出了std::u8string.

最后就是兼容可靠的代码的书写了:
针对C++17标准:
#include <windows.h>
#include <stdio.h>
// 将UTF-8字符串转换为宽字符串(不一定是UTF-16)
wchar_t* utf8_to_wstr(const char* utf8_string)
{
// 获取UTF-8字符串的长度
int len = strlen(utf8_string);
// 计算所需缓冲区大小
int w_size = MultiByteToWideChar(CP_UTF8, 0, utf8_string, len, NULL, 0);
// 分配宽字符串缓冲区
wchar_t* w_string = (wchar_t*)malloc((w_size + 1) * sizeof(wchar_t));
// 将UTF-8多字节转换为宽字符串
MultiByteToWideChar(CP_UTF8, 0, utf8_string, len, w_string, w_size);
w_string[w_size] = L'\0'; // 添加NULL终止字符
return w_string;
}
int main() {
const char* utf8_string = u8"Wormwaker创作";
// 转换为wchar_t*
wchar_t* w_string = utf8_to_wstr(utf8_string);
// 使用MessageBoxW显示UTF-16字符串
MessageBoxW(NULL, w_string, L"MessageBoxW", MB_OK);
// 释放内存
free(w_string);
return 0;
}
就看这么一句就行了:
const char* utf8_string = u8"Wormwaker创作";
这样即使编译器默认以ANSI编码EXE,也会单独把这个字符串以UTF-8编码的,达到了想要的效果。
针对≥C++20标准:
#include <windows.h>
#include <stdio.h>
// 将UTF-8字符串转换为宽字符串(不一定是UTF-16)
wchar_t* utf8_to_wstr(const char8_t* utf8_string)
{
// 获取UTF-8字符串的长度
int len = strlen((const char*)utf8_string);
// 计算所需缓冲区大小
int w_size = MultiByteToWideChar(CP_UTF8, 0, (const char*)utf8_string, len, NULL, 0);
// 分配宽字符串缓冲区
wchar_t* w_string = (wchar_t*)malloc((w_size + 1) * sizeof(wchar_t));
// 将UTF-8多字节转换为宽字符串
MultiByteToWideChar(CP_UTF8, 0, (const char*)utf8_string, len, w_string, w_size);
w_string[w_size] = L'\0'; // 添加NULL终止字符
return w_string;
}
int main() {
const char8_t* utf8_string = u8"Wormwaker创作";
// 转换为wchar_t*
wchar_t* w_string = utf8_to_wstr(utf8_string);
// 使用MessageBoxW显示UTF-16字符串
MessageBoxW(NULL, w_string, L"MessageBoxW", MB_OK);
// 释放内存
free(w_string);
return 0;
}
要注意的是
1.
const char8_t* utf8_string = u8"Wormwaker创作";
2.在所有const char* (或LPCSTR)的参数处都要把const char8_t* 强转成const char*.
如果你的编译器支持C++20标准,建议就用这第二种。毕竟在未来的标准下都得这么写。
完美解决!