NCBI数据下载的几种方法
这一篇记录一下NCBI/Genbank数据库中批量下载数据的几种方法:
1、迅雷
将所有序列的下载链接整理在一起后在迅雷中创建下载,可以批量进行序列下载
注:不知道是电脑还是网络问题,有时候下载的超慢甚至连接不上
2、TBtools
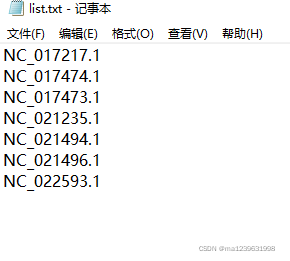
首先准备好需要下载的序列号,将其放入一个text文件中
打开TBtools软件,点击Sequence Toolkit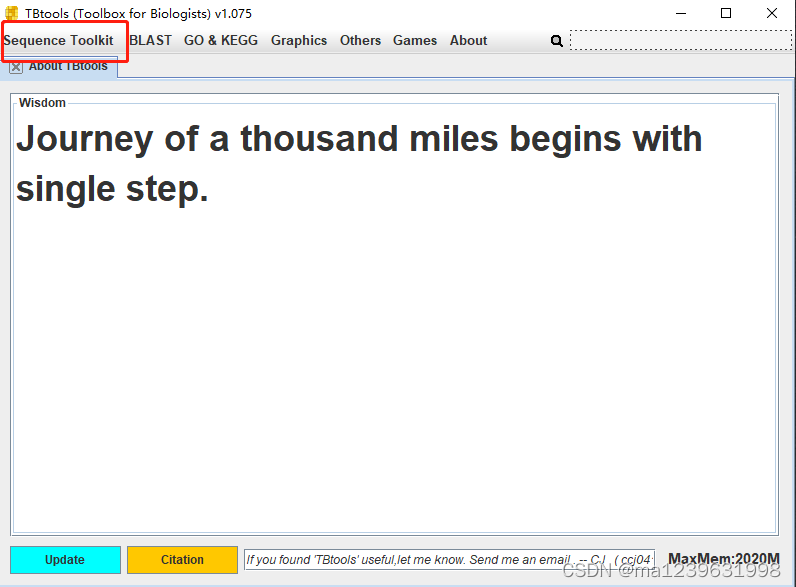
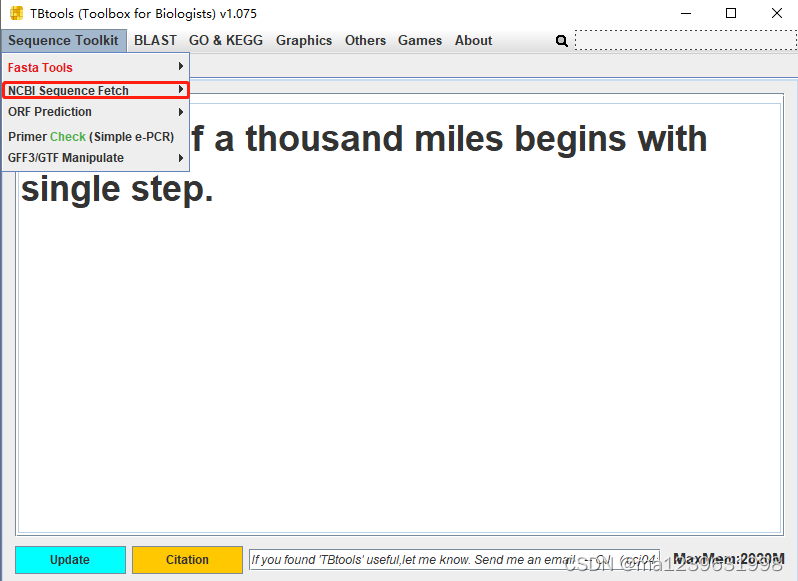
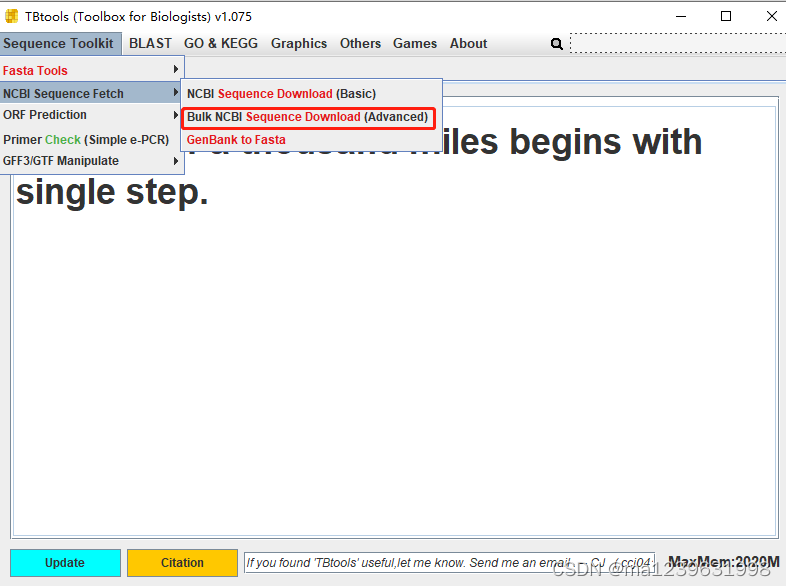
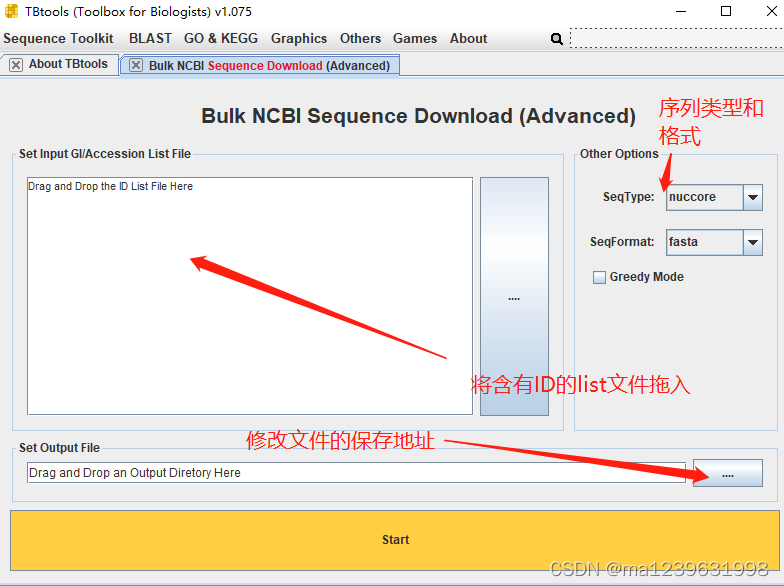
点击Start,等待下载即可
3、利用Biopython下载
##一条一条地下载基因序列 from Bio import Entrez,SeqIO Entrez.email = "用户邮箱" ids='序列的ID号' hd_efetch_fa = Entrez.efetch(db='nucleotide', id=ids, rettype="fasta") read_efetch_fa = hd_efetch_fa.read() with open('保存数据的文件',"w") as file: file.write(read_efetch_fa) print(' finished!')
##批量下载序列,序列号存放在download.txt文件中,下载下来的序列分别写入以1为起始名的fasta文件中 from Bio import Entrez,SeqIO file_in_name="download.txt" Entrez.email = '你的邮箱' input_file=open(file_in_name,"r") i=0 for record_id in input_file:##一行一行读取序列的ID号 hd_efetch_fa = Entrez.efetch(db='nucleotide', id=record_id, rettype="fasta") read_efetch_fa = hd_efetch_fa.read() i=i+1 with open(str(i)+'.fasta'', "w") as file:##将下载的序列顺序存放在以i=1为起始名的文件中 file.write(read_efetch_fa) print('finished!')##每当一个序列下载完成就打印一次finished!
ok,静待后续继续补充