数据结构——栈和队列
前言
栈和队列是两种不同的线性数据结构。这两种数据结构相比之前的基础数据结构顺序表和链表来说,特点更加突出,实用性也更强。而这两种数据结构的实现也建立在顺序表和链表的基础之上,建议先了解顺序表和链表的原理再学习栈和队列。
【顺序表解析】传送门:http://t.csdn.cn/TZ5mw。
【链表解析】传送门:http://t.csdn.cn/CRTmg。
1 栈
1.1 区分栈与栈区
可能有些同学在学习内存的时候听说过内存中的栈区。栈区与本文中讨论的栈是有本质区别的。栈区是内存中的一块区域,而栈是一种数据结构。
1.2 思路引入
不知道大家有没有去过超市,由于网上购物的兴起,我已经很久没有去过线下的超市了。记得小时候去超市的时候,由于要买的东西比较多,通常会推上一个购物车,这样一来我可以把挑选好的商品放入购物车中,等到结账时再拿出来。
到结账时,要把商品一件一件的放到收银台上,在这个过程中我们可以发现,我们通常都是先拿位于上方的商品,再拿下方的。这是因为上方商品压住了下方商品,导致我们难以先拿下方商品。而这些商品的相对位置其实与我们将其放入购物车的时间有关,越早放入购物车,商品就越位于下方。因此,后进入购物车的商品,通常先离开购物车,这就是栈的特点。

1.3 基本思路
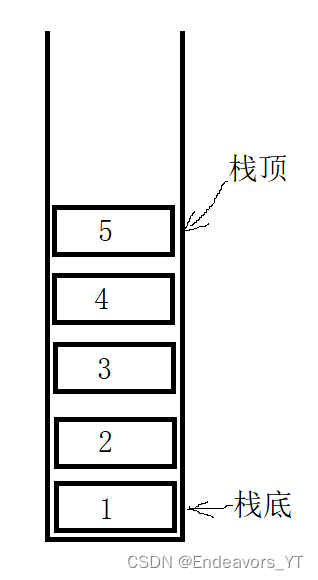
栈(Stack)是一种线性数据结构,可以想象一下把购物车压缩成线状(竖直放置),每个高度上只能放一件商品,如下图。
通常,我们将最后一个元素的位置称为栈顶,第一个元素的位置称为栈底。如此一来,插入和删除元素都只能在栈顶进行,我们通常把栈的插入称为入栈,删除称为出栈。
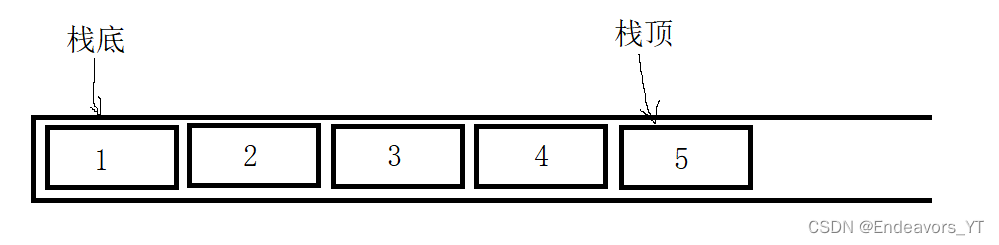
其实与上图类似的图形,在学习基础数据结构时我们就见到过。我们将上图顺时针旋转90度可以得到以下图形。
这样看是不是清楚多了,这其实就是一个顺序表,而所谓的入栈和出栈其实就是顺序表的尾插和尾删。
1.4 栈的实现
栈的实现可以使用顺序表,也可以使用链表。这里我选用顺序表进行模拟实现。
1.4.1 接口
既然是通过顺序表来实现栈,那么模拟的结构也与顺序表相似,区别在于栈有唯一的插入和删除方式,也就没有头插,尾插,随机插入这类说法了。
由于在栈里只能操作栈顶元素,因此这里多了一个获取栈顶元素的功能,用来访问栈内元素。另外,在使用栈的时候,有时会以栈是否为空作为判断条件,因此多出一个判空功能。学习过顺序表后,下面的实现看上去就非常简单了。
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
#define MAX 100 //最大容量
#define STACKADD 2 //扩容容量
typedef int SDateType;
typedef struct Stack
{
SDateType* data;
int top;
int capacity;
}Stack;
//初始化栈
void StackInit(Stack* ps);
//判空
bool StackEmpty(Stack* ps);
//入栈
void StackPush(Stack* ps, SDateType x);
//出栈
void StackPop(Stack* ps);
//获取栈顶元素
void StackGetTop(Stack* ps, SDateType* d);
//销毁栈
void StackDestroy(Stack* ps);1.4.2 初始化与判空
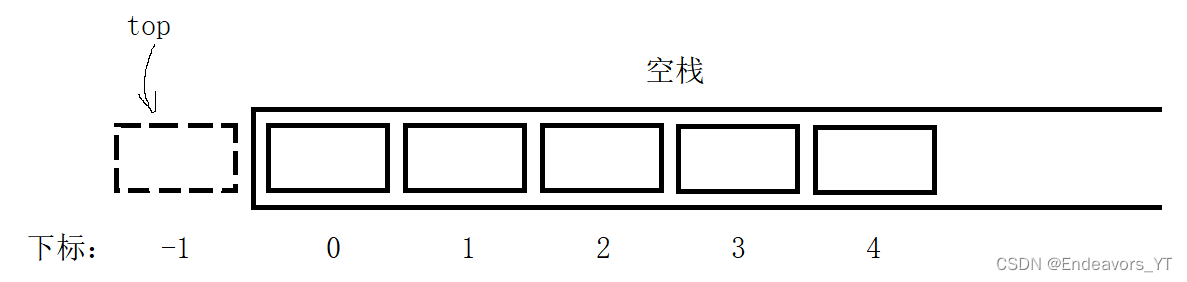
由于我们是用顺序表来实现栈,那么这里我们就可以参考顺序表的初始化。不同点在于,由于栈顶是栈最后一个元素所在的位置,因此在初始化时,由于栈为空,那么栈顶的位置显然不是0。在这里我们可以将top初始化为-1,那么当第一个元素入栈时,让top自增1,栈顶位置就变成了0,这样就解决了这一问题。
void StackInit(Stack* ps)
{
assert(ps);
ps->data = (SDateType*)malloc(STACKADD * sizeof(SDateType));
if (ps->data == NULL)
{
perror("Init malloc:");
return;
}
ps->top = -1;
ps->capacity = STACKADD;
}完成初始化后,再来看判空就非常简单了,因为初始化后的栈不就是一个空栈吗?那么判空的条件就是top等于-1。
bool StackEmpty(Stack* ps)
{
assert(ps);
if (ps->top != -1)
return false;
else
return true;
}1.4.3 入栈,出栈与获取栈顶元素
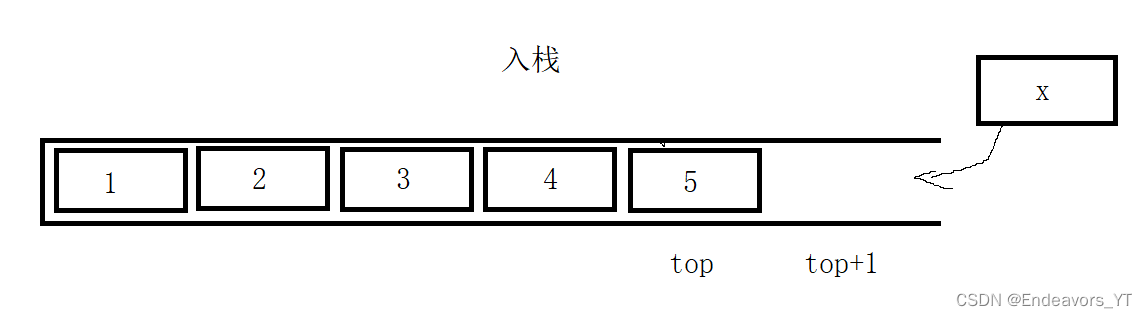
根据上面的分析,入栈和出栈的操作就是顺序表的尾插和尾删。需要注意点的是栈顶的位置并不是最后一个元素的下一个位置,因此需要在top+1位置插入。过程我就不过多介绍了,不理解的可以先学习顺序表。
void StackPush(Stack* ps, SDateType x)
{
assert(ps);
ps->top++;
if (ps->top == ps->capacity && ps->capacity != MAX)
{
ps->data = (SDateType*)realloc(ps->data, (ps->capacity + STACKADD) * sizeof(SDateType));
if(ps->data==NULL)
{
perror("Push realloc:");
return;
}
}
ps->data[ps->top] = x;
} 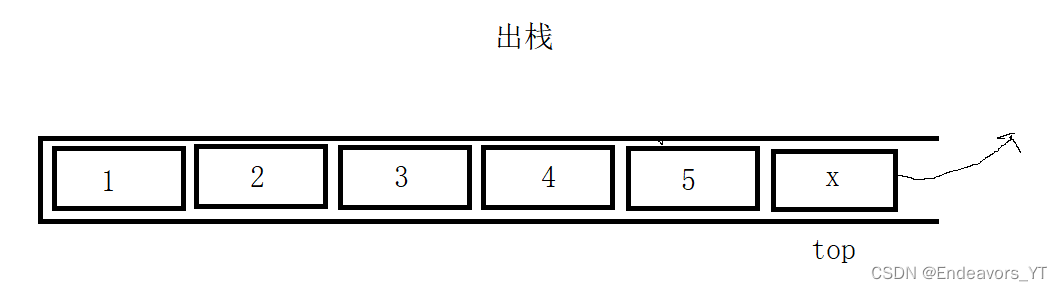
void StackPop(Stack* ps)
{
assert(ps);
assert(!StackEmpty(ps));
ps->top--;
}关于获取栈顶元素,这个操作比较简单,就是通过下标访问数组元素,将栈顶元素值赋给传入的指针变量所指向的变量。
void StackGetTop(Stack* ps, SDateType* d)
{
assert(ps);
assert(!StackEmpty(ps));
*d = ps->data[ps->top];
}1.4.4 栈的销毁
动态开辟的空间使用完毕后都要手动释放,而栈的销毁只要有首元素的地址(栈底地址)即可。
void StackDestroy(Stack* ps)
{
assert(ps);
free(ps->data);
ps->data = NULL;
}1.5 疑难杂症
1.5.1 为何不采用头插和头删
我在画图时将竖直的栈顺时针旋转90度形成了顺序表,那么可不可以逆时针旋转90度呢?这样一来,我们的入栈和出栈操作就变成了顺序表的头插和头删。而在顺序表中,尾插和尾删的时间复杂度均为O(1),而头插和头删的时间复杂度均为O(n)。这就是入栈和出栈采用尾插和尾删而不是头插和头删的原因。
1.5.2 为何不采用链表实现
与顺序表相比,链表的头插和头删的时间复杂度均为O(1),并且在其它方面链表的效率也不输顺序表。在栈的实现中,链表唯一一点不如顺序表的地方就在于销毁。链表的节点是散布内存各处的,销毁时需要通过遍历逐一释放节点,时间复杂度为O(n)。而顺序表的数据存储在一段连续的空间上,只需要空间的首地址即可一键释放,时间复杂度为O(1)。这就是文章采用顺序表实现栈的原因。
2 队列
2.1 思路引入
队列(Queue)在生活中其实非常常见,如在食堂排队打饭的队列、在超市收银台排队等待支付的队列,或是等待办理某项业务的队列。这些队列的出现通常是为了控制秩序,提高业务办理的效率。
数据结构中所说的队列与我们生活中的队列有一个共同点的特点。假设我们把排队的人看成一个一个的节点,排在最前面的人称为队头,最后的人称为队尾。由于排队是为了办理某项业务,那么当队头的人办理完业务之后就可以离开了,称为出队列,而如果有新需要办理该业务的人,则他应该排在队尾,称为入队列。

2.2 基本思路
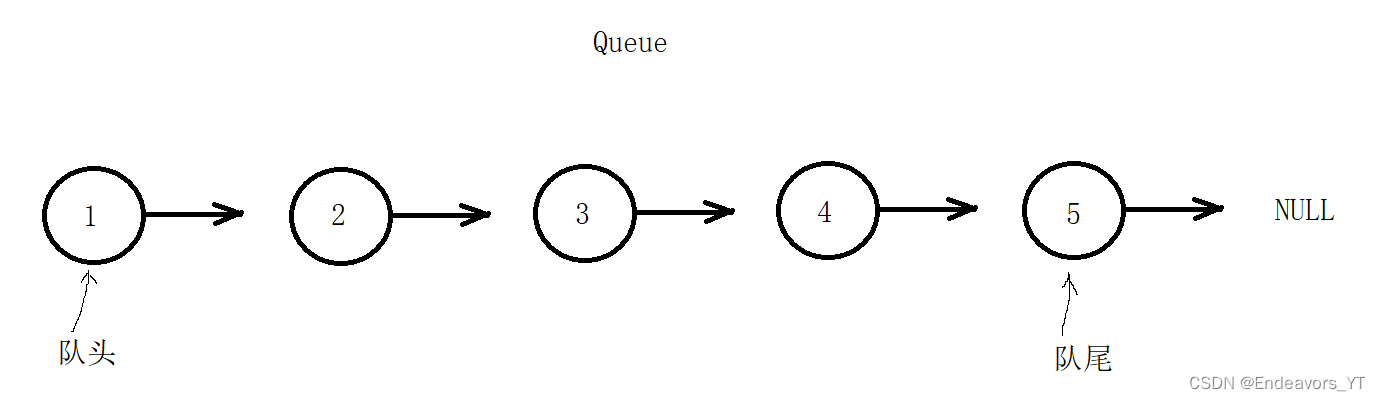
根据上面的分析,队列的数据插入和删除的特点为一侧插入,另一侧删除。也就是说,我们可以采用头插加尾删的组合,也可以采用头删加尾插的组合。
如下图(图中箭头方向为链表节点的指针方向,不是队列朝向)。
2.3 队列的实现
队列作为一种线性数据结构,我们同样可以用顺序表或者链表还原。我认为最好理解的实现方式就是采用头删加尾插的链表来实现队列。
2.3.1 接口
采用链表来实现,首先要做的就是声明所需的链表节点结构。而对于队列,这里我选择再声明一个Queue结构,可以保存队列的队头节点和队尾节点的地址,这样一来就能通过地址更快速地找到队尾节点而不是遍历链表。
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
typedef int QDataType;
typedef struct QueueNode
{
QDataType data;
struct QueueNode* next;
}QueueNode;
typedef struct Queue
{
QueueNode* front;
QueueNode* rear;
}Queue;
//初始化队列
void QueueInit(Queue* pq);
//判空
bool QueueEmpty(Queue* pq);
//入队
void QueuePush(Queue* pq, QDataType x);
//出队
void QueuePop(Queue* pq);
//取队头元素
void QueueGetFront(Queue* pq, QDataType* d);
//销毁队列
void QueueDestroy(Queue* pq);2.3.2 初始化与判空
我们期望的初始化结果应该是一个空队列,也就是一个没有任何节点的队列,那么我们的初始化就并不需要创建节点,只需要将队列的front指针和rear指针置空即可。
那么队列的判空条件也就显而易见了,当front指针为空时,该队列即为空队列。代码如下。
void QueueInit(Queue* pq)
{
assert(pq);
pq->front = pq->rear = NULL;
}bool QueueEmpty(Queue* pq)
{
assert(pq);
if (pq->front == NULL)
return true;
else
return false;
}2.3.3 入队列、出队列与获取队头元素
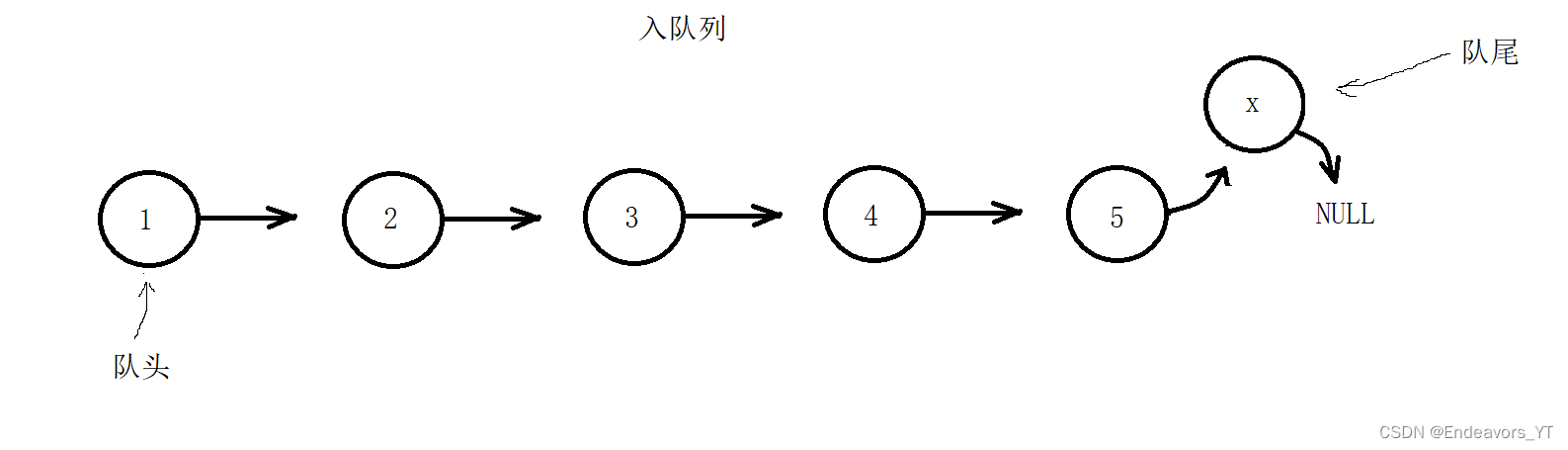
前面也提到过,我们这里的入队列采用尾插,出队列采用头删,这样的方式与生活最接近,更好理解。
在入队列时,我们可以通过队尾指针直接访问队尾节点,大大提高了尾插效率,其它与链表的尾插无太大区别,同样需要注意处理链表为空的特殊情况。出队列则与链表头删无区别。这样一来,入队列和出队列的时间复杂度均为O(1)。
如果采用顺序表来实现队列,将无可避免使用顺序表的头插或者头删,而其时间复杂度将达到O(n)。
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
if (pq->front == NULL)
{
pq->front = pq->rear = (QueueNode*)malloc(sizeof(QueueNode));
if (pq->front == NULL)
{
perror("Push malloc:");
return;
}
pq->rear->data = x;
pq->rear->next = NULL;
}
else
{
QueueNode* newnode = (QueueNode*)malloc(sizeof(QueueNode));
if (newnode == NULL)
{
perror("Push malloc:");
return;
}
pq->rear->next = newnode;
pq->rear = pq->rear->next;
pq->rear->data = x;
pq->rear->next = NULL;
}
}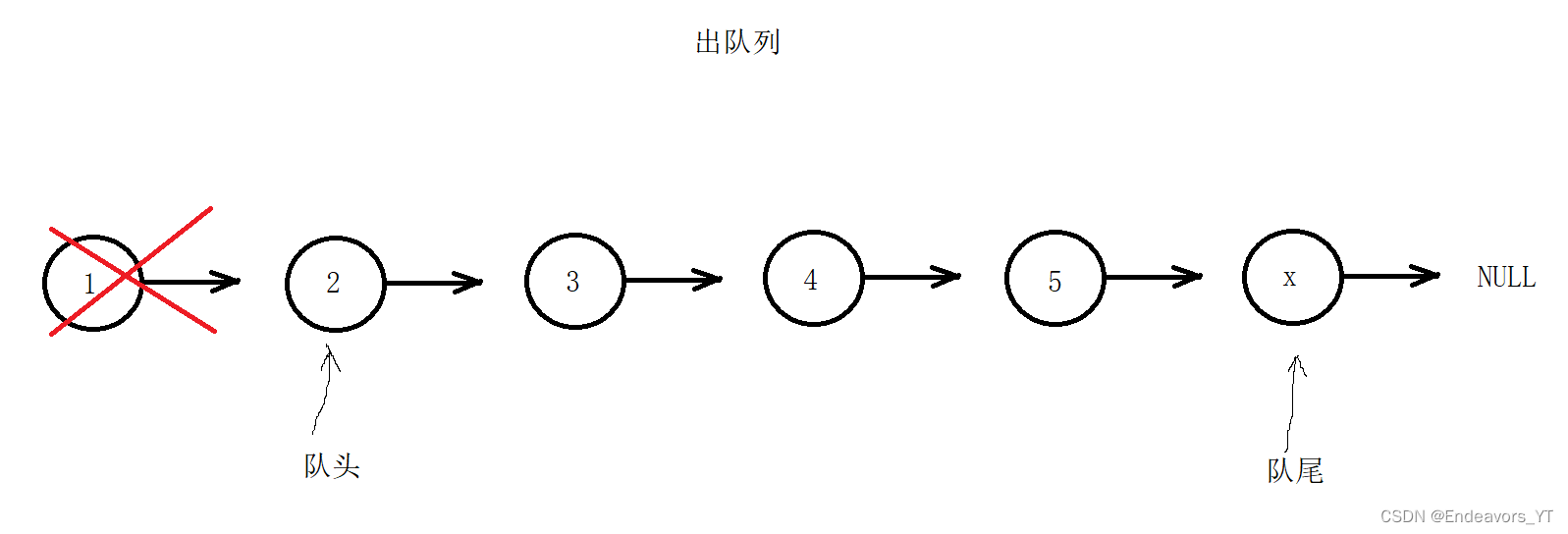
void QueuePop(Queue* pq)
{
assert(pq);
assert(!QueueEmpty(pq));
QueueNode* prev = pq->front;
if (pq->front == pq->rear)
pq->rear = NULL;
pq->front = pq->front->next;
prev->next = NULL;
free(prev);
}获取队头元素较简单,这里直接看代码。
void QueueGetFront(Queue* pq, QDataType* d)
{
assert(pq);
assert(!QueueEmpty(pq));
*d = pq->front->data;
}2.3.4 队列的销毁
由于本文使用链表实现队列,故销毁队列与销毁链表的方式一样,通过循环遍历来销毁。
void QueueDestroy(Queue* pq)
{
assert(pq);
QueueNode* cur = pq->front;
while (cur)
{
cur = cur->next;
pq->front->next = NULL;
free(pq->front);
pq->front = cur;
}
pq->rear = NULL;
}结束语
本篇主要介绍了栈和队列两种数据结构的实现思路,并用顺序表和链表分别模拟实现。栈和队列在部分算法中应用较多,非常有必要学习。如果文章内容有误,欢迎各位大佬指正。