yes or no?基于词典的情感分析法
自更博以来第一次断更,现在先把文本分析的坑补上,这篇文章着重介绍情感分析的两种基本方法之一:基于词典的情感分析(下篇讲基于监督的情感分析),建模环境为R。
目录
1 背景与目的
1.1 情感分析的应用场景
顾客的评价最能反映其对商品的使用感受,对此类信息进行加工,提炼产品痛点和亮点,实现针对性改进和营销,是一个很有意义的方向。
研究这些文本内容的情感倾向(比如正、负or中),就是咱们情感分析要解决的问题。
1.2 情感分析的痛点
1)研究对象难,情感分析的研究对象是长文本,相比其它传统数据类型,难度更大,加上话语表达博大精深拐弯抹角阴阳怪气,连人都分不清的话中话,就别指望模型了;
2)建模过程难,这也是文本类分析的通病,有大量分词操作和超级稀疏矩阵,吃内存;
3)前期工作要求高,有些数据和模型几乎啥都不要可以直接上手,但情感分析不行,基于词典的情感分析需要精确度较高囊括范围较广的词典,基于监督的情感分析则需要预置情感类型准确性较高的文本进行训练,这些数据都是需要人工标注的。
情感分析前期准备工作量大,中间建模过程难,最后结果也未必如人意,但还是要做,因为大型语料以人力实现难、枯燥且不具有连续型,而一个不断训练提升的模型最后不管是从成本从效率还是准确性来说相比起来并不差。另外,以工具解放工具人,让人去干人该干的事,也是建模的初衷之一。
2 方法与实现
2.1 什么是基于词典的情感分析
简单来说就是以包含的褒义词和贬义词的数量投票。
先分词,然后对比分词结果与已总结好的褒义词和贬义词词典,统计两类词汇的数量,哪边多情感偏向哪边。词典的准确性直接影响该方法的分类效果,常规情感词典参考:
2.2 怎么做词典式情感分析
2.2.1 数据介绍
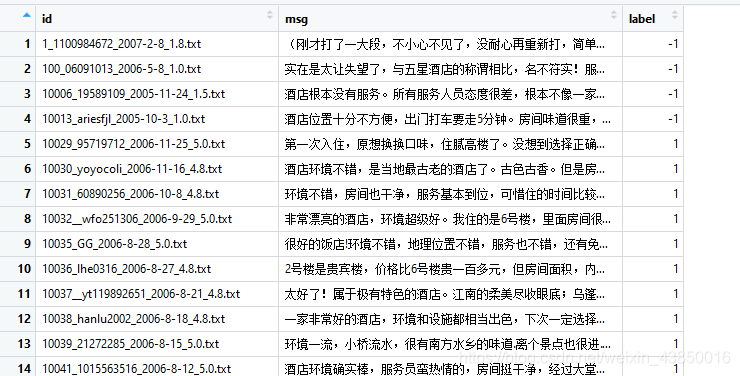
1)语料
酒店评论文本:训练集23967条,测试集4000条(清华李军标注整理)
2)词典
正向词汇21563个,负向词汇24575个(上面方法介绍中提到的参考词典的分类汇总)

2.2.2 训练集分词
#文本清洗
sentence <- as.vector(test$msg)
sentence <- gsub("[[:digit:]]*", "", sentence) #清除数字[a-zA-Z]
sentence <- gsub("[a-zA-Z]", "", sentence)
sentence <- gsub("\\.", "", sentence)
test <- test[!is.na(sentence), ]
sentence <- sentence[!is.na(sentence)]
test <- test[!nchar(sentence) < 2, ]
sentence <- sentence[!nchar(sentence) < 2]
#将情感词典加入分词器 pos+neg 权重 去重
weight <- rep(1,nrow(pos))
pos <- cbind(pos, weight)
weight <- rep(-1,nrow(neg))
neg <- cbind(neg, weight)
posneg <- rbind(pos, neg)
names(posneg) <- c("term", "weight")
posneg <- posneg[!duplicated(posneg$term), ]
library(Rwordseg)
insertWords(posneg$term)
#分词,向量化
x <- segmentCN(strwords = sentence)
temp <- lapply(x, length);temp <- unlist(temp)
id <- rep(test$id, temp)
label <- rep(test$label, temp)
term <- unlist(x)
testterm <- as.data.frame(cbind(id, term, label), stringsAsFactors = F)
#去停用词
stopword <- read.csv("dict/stopword.csv", header = T, sep = ",", stringsAsFactors = F)
stopword <- stopword[!stopword$term %in% posneg$term,]
testterm <- testterm[!testterm$term%in% stopword,]
2.2.3 情感分析(统计两性词汇数量并比较)
#情感得分
library(plyr)
testterm1 <- join(testterm, posneg) #分词情感词典匹配
testterm1 <- testterm1[!is.na(testterm1$weight), ]
dictresult <- aggregate(weight ~ id, data = testterm1, sum)
dictresult$newlable<-ifelse(dictresult$weight>0,1,-1)
2.2.4 测试集验证、结果评价与调优
#结果校验
temp <- unique(testterm[, c("id", "label")])
dictresult <- join(dictresult, temp)
evalue <- table(dictresult$newlable, dictresult$label)
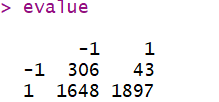
很明显,效果并不好,仅55%,考虑从3个角度优化:
改进方向1:调整临界值
改进方向2:优化分词结果(去除高频词、重复词)
改进方向3:优化词典(校正词汇与情感)
以容易实现的法1为例,当阈值调整为1时,正确率可提升至58.9%
ss<-seq(-1,1,0.1)
pp<-c()
for (i in 1:length(ss)) {
newlable<-ifelse(dictresult$weight>ss[i],1,-1)
kk<-data.frame(dictresult$label,newlable)
pp[i]<-sum(kk[,1]==kk[,2])/nrow(kk)
}
ss[which.max(pp)]