SPSS Modeler分析物流发货明细数据:K-MEANS(K均值)聚类和Apriori关联规则挖掘
全文链接:http://tecdat.cn/?p=32633
物流发货明细数据在现代物流业中扮演着至关重要的角色(点击文末“阅读原文”获取完整代码数据)。
通过对这些数据进行挖掘和分析,我们可以发现隐含在背后的供应链运营规律和商业模式,从而指导企业在物流策略、成本管理和客户服务等方面做出更加科学和有效的决策。
相关视频
SPSS Modeler是一款功能强大、界面友好的数据挖掘和分析工具,可以帮助企业对物流发货明细数据进行深入和准确的挖掘分析,提高数据价值和运营效率。
本文将以SPSS Modeler帮助客户分析物流发货明细数据,介绍如何使用SPSS Modeler对物流发货明细数据进行聚类分析和关联规则挖掘,并分析得出有益的结论和建议,为企业的物流运营和发展提供参考与支持。
数据的预处理
本研究的数据是一组关于物流的发货明细,数据包括以下字段:项目、指令日期、始发省、始发市、目的省、目的市、收货人单位、品名、数量、签收时间、签收数量、拒收数量和拒收原因。
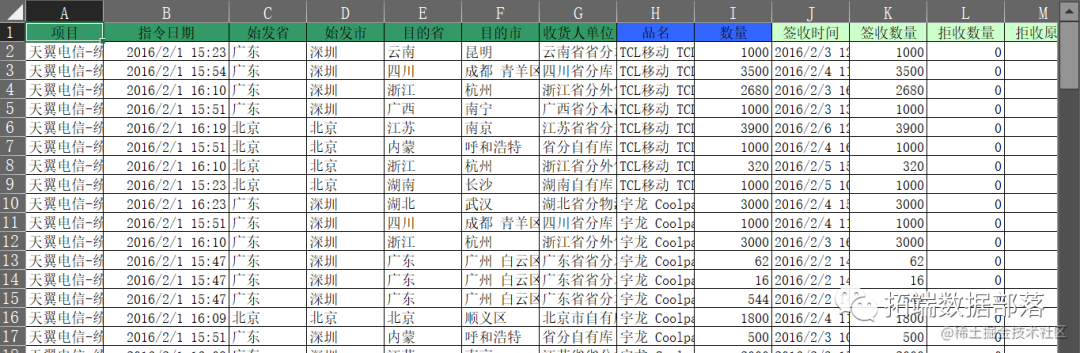
对数据进行预处理:
(1)补充缺失值。对没有记录的数据缺失采用平均值法,以该字段的平均分数填充。
(2)规范化数据。运用最小-最大规范化方法对数据进行规范化处理,将数据映射到[0,1]区间,计算公式如下。
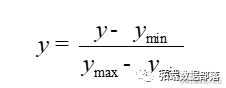
其中:ymax为该字段的最大值;
ymin为该字段的最小值。
过程及结果分析
(1)读取数据
选择SPSS Modeler的Source-Excel-Data,在Data选项页中通过Import Files输入框选定Excel格式的成绩表文件,并点击Read Values 按钮,将所有数据读入,如图所示。
(2)K-Means 模型设置
选择SPSS Modeler的Modeling-K-means,将K-Means模型节点添加进数据流来,双击K-Means图标,在弹出的对话框中选择Model选项页,选项页中的参数解释如下:
1)Numbers of cluster:制定生成的聚类数目,这里设置为3.
2)Use Partitioned Data:如果用户定义了分割数据集,选择训练数据集作为建模数据集,并利用测试数据集对模型进行评价。
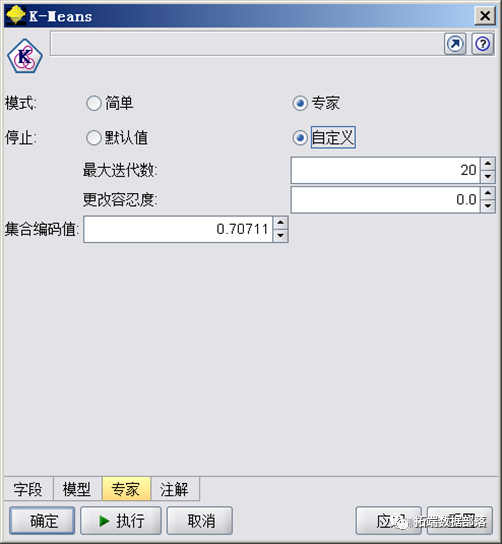
继续选择对话框中的Expert选项页,如图5所示,对该选项页中的参数做一下设置:
Model选项:选择Expert模式,表示将进行高级模式的选择。
Stop on选项:选择custom选项修改迭代终止的条件:
1)Maximum iterations(最大迭代数):该选项允许在迭代制定次数后终止训练,这里设置为20.
2)Change tolerance(差异容忍度):该选项允许在一次迭代中质心之间的最大差异小于制定水平时终止训练。
(3)执行和输出
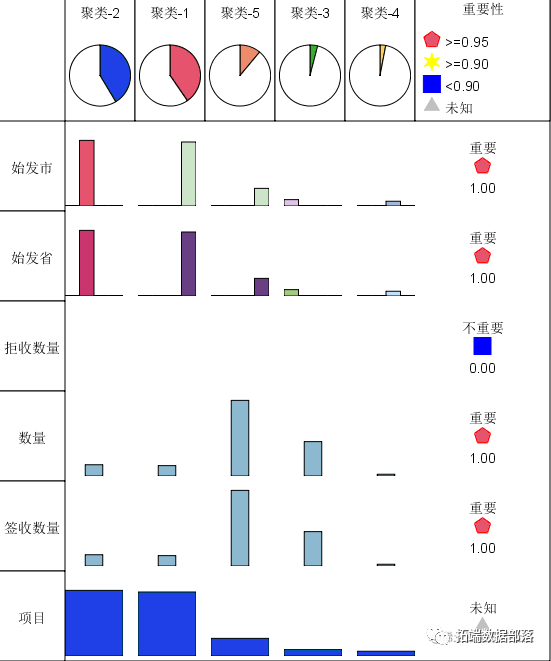
设置完成后,选中Execute 按钮,即可得到执行并观察到结果。点击VIEW选项卡,可以以图表的形式来显示模型的统计信息以及各个属性在各簇中的分布信息。
点击标题查阅往期内容

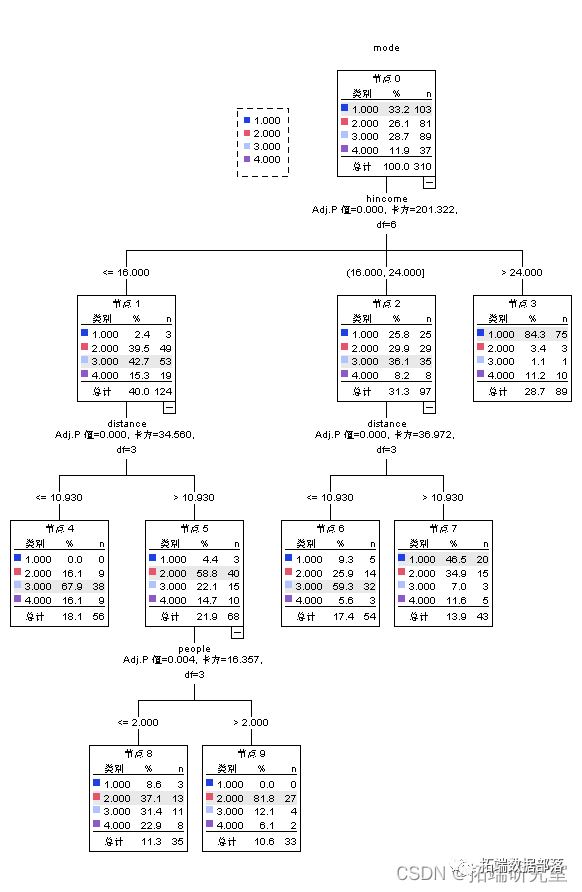
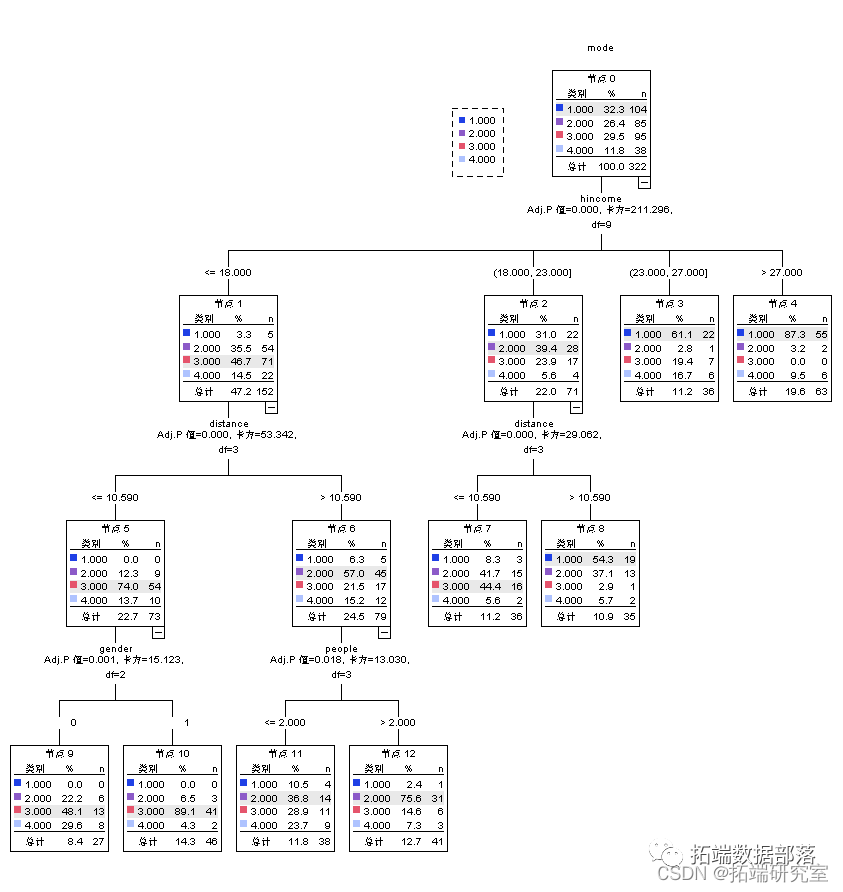
SPSS用K均值聚类KMEANS、决策树、逻辑回归和T检验研究通勤出行交通方式选择的影响因素调查数据分析

左右滑动查看更多

01
02
03
04
(4)聚类结果
结果表明:簇1和2中的签收数量较低,簇5中的签收数量一般,簇4中的签收数量最低,可见,大部分样本的签收数量处于中等水平;各变量在各簇中的显著程度均较大,表明不同聚类簇的签收数量的分化程度较高,差异显著。
簇1

簇2

簇3

簇4

簇5

从每个聚类簇的情况来看,签收数量最多的是第5个簇,该簇中的最多的始发地是广东深圳,签收数量达到了2833件,其次是上海,签收数量达到了1287。同时从结果可以看到四川成都的签收数量最低,说明物流的集中地集中在广东深圳上海等地。
关联规则挖掘
本文分别用Apriori算法对数据进行处理挖掘,具体结果如下所示。
(1)Apriori算法
虽然 Apriori 算法可以直接挖掘生成表中的交易数据集,但是为了关联挖掘其他算法的需要先把交易数据集转换成分析数据集,构建的数据流如图所示。
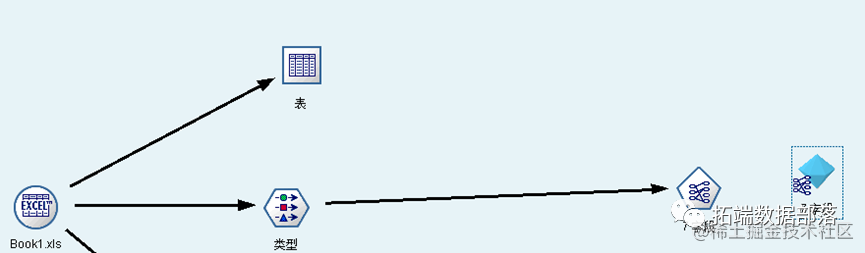
图 1 商品关联规则 Apriori 算法挖掘流图
通过格式转换,发现数据源中共有二十种商品,设最低条件支持度为15%,最小规则置信度为30%,最大前项数为5,选择专家模式,挖掘出大类商品的15条关联规则,如图所示。生成的38条规则如下所示:
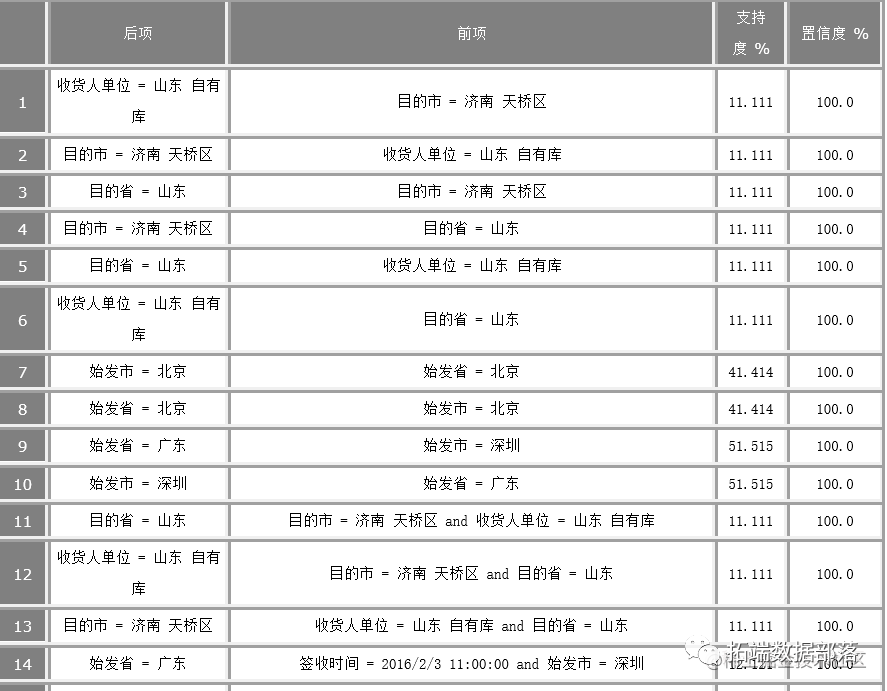
分析及建议: 通过图可以清晰的看到深圳、广东、北京的物流订单比较多,建议物流企业可以加大对这些地区的工作人员安排,由上述结果可知,发往北京和发往广东深圳的物流运单分别占总运单数的51.515%,41.414%,由此可见,北京 山东 深圳三个目的地的关联度较高,可以将这些地点的仓库摆放在一块,从而增加效率。同时可以看到 发往北京的物品中出现了较多的 三星 SM-W2016商品。因此,可以将这些商品交由专人来负责来提高效率。
最后我们得到了以下结果和文件:

本文中分析的数据分享到会员群,扫描下面二维码即可加群!


点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《SPSS Modeler分析物流发货明细数据:K-MEANS(K均值)聚类和Apriori关联规则挖掘》。
点击标题查阅往期内容
数据分享|R语言主成分PCA、因子分析、聚类对地区经济研究分析重庆市经济指标
数据分享|R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言逻辑回归logistic模型分析泰坦尼克titanic数据集预测生还情况
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言随机森林RandomForest、逻辑回归Logisitc预测心脏病数据和可视化分析
R语言基于Bagging分类的逻辑回归(Logistic Regression)、决策树、森林分析心脏病患者
R语言逻辑回归(Logistic回归)模型分类预测病人冠心病风险
R语言用局部加权回归(Lowess)对logistic逻辑回归诊断和残差分析
R语言用主成分PCA、 逻辑回归、决策树、随机森林分析心脏病数据并高维可视化
R语言用线性模型进行臭氧预测:加权泊松回归,普通最小二乘,加权负二项式模型,多重插补缺失值
R语言Bootstrap的岭回归和自适应LASSO回归可视化
R语言多元时间序列滚动预测:ARIMA、回归、ARIMAX模型分析
R语言用lme4多层次(混合效应)广义线性模型(GLM),逻辑回归分析教育留级调查数据
R语言混合效应逻辑回归(mixed effects logistic)模型分析肺癌数据
R语言建立和可视化混合效应模型mixed effect model
R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
R语言如何解决线性混合模型中畸形拟合(Singular fit)的问题
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
R语言用WinBUGS 软件对学术能力测验(SAT)建立分层模型
使用SAS,Stata,HLM,R,SPSS和Mplus的分层线性模型HLM
R语言用WinBUGS 软件对学术能力测验建立层次(分层)贝叶斯模型
SPSS中的多层(等级)线性模型Multilevel linear models研究整容手术数据
R语言高维数据的主成分pca、 t-SNE算法降维与可视化分析案例报告
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
R语言使用Metropolis- Hasting抽样算法进行逻辑回归
R语言自适应LASSO 多项式回归、二元逻辑回归和岭回归应用分析
R语言基于树的方法:决策树,随机森林,Bagging,增强树
python在Scikit-learn中用决策树和随机森林预测NBA获胜者
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
R语言用标准最小二乘OLS,广义相加模型GAM ,样条函数进行逻辑回归LOGISTIC分

![]()
