数据分析基础项目一、餐厅订单数据分析
——————————————学习资料和数据来源于B站-Python-学习库——————————
一、初识数据需求
1.拿到数据,加载数据,初步认识数据并确定数据待清洗方向(空值列、重复值、格式不符等)
#明确文件类型,加载数据,看数据信息
#数据类型:xlsx
data1= pd.read_excel("meal_order_detail.xlsx",sheet_name='meal_order_detail1')
data2= pd.read_excel("meal_order_detail.xlsx",sheet_name='meal_order_detail2')
data3= pd.read_excel("meal_order_detail.xlsx",sheet_name='meal_order_detail3')
data=pd.concat([data1,data2,data3],axis=0) #将每行数据合并
print(data.info())#读取数据信息,判断数据预处理方向(删除空值、重复值、修改数据格式)
print(data.describe())#看数据整体分布情况,包括中位数,平均值之类
使用info初识数据信息,包括数据行列数、占内存大小、有无NA列等
运行结果表明数据存在空值列,需要删除空值列
二、数据清理
#删除空值列
data=data.dropna(axis=1)三、数据分析及可视化
基于需求分析数据
- 2016整个8月所卖菜品的平均价格
- 2016整个8月最受欢迎的菜(点的频率最高)
- 点菜种类数较多的订单ID和该ID所点种类数
- 总消费排名前十的订单ID
- 平均消费排名前十的订单ID
- 订餐数量与时间的关系(以hour计,以day计,以星期计)
- 从消费情况看,判断大部分食客是偏向于聚餐高消费还是低消费
#1-8月份所有销售菜品的平均值,结果保留三位小数 avg_pandas = round(data['amounts'].mean(),3)#pandas自带的mean()函数 avg_numpy = round(np.mean(data['amounts']),3)#numpy自带的mean()函数,数据量大时建议使用,因为numpy底层由C++编写,运行效率高
#2-最受欢迎的菜品 dishes_f=data['dishes_name'].value_counts()[:10]#统计dishes_name列下不同菜品的个数,默认结果降序排列,切片取前十名 #可视化-绘制柱状图堆加折线图 dishes_f.plot(kind='bar',fontsize=8,color=['r','g','b'])#plt的plot函数绘图 dishes_f.plot(kind='line',color='r') for x,y in enumerate(dishes_f):#给图添加参数 plt.text(x,y+2,y,ha='center',fontsize=4)#设置数据标签 plt.show()#图展示出来
#3-点菜种类数较多的订单ID和该ID所点种类数
以订单ID分组,然后取出counts列,进行sum求和,求完排序,取前十
data_count=data.groupby(by='order_id')['counts'].sum().sort_values(ascending=False)
data_count[:10].plot(kind='bar',fontsize=8,color=['r','m','b','y','g'])
#4-总消费排名前十的订单ID
先计算每道菜的价格,放在total_amounts列
类似3-将counts改成total_total_amounts
data['total_amounts']=data['counts']*data['amounts'] data_total_amounts=data.groupby(by='order_id')['total_amounts'].sum().sort_values(ascending=False) data_total_amounts[:10].plot(kind='bar',fontsize=8,color=['r','m','b','y','g'])
#5-平均消费排名前十的订单ID
提取total_amounts列,counts列,并按order_id分组,分组后对每列求和
计算平均消费,放入avg_amounts列,排序,取前十
data['total_amounts']=data['counts']*data['amounts'] data_total_amounts=data[['order_id','total_amounts','counts']].groupby(by='order_id').sum()#分组取列时分组标准列要一起取出 data_total_amounts['avg_amounts']=data_total_amounts['total_amounts']/data_total_amounts['counts'] data_total_amounts['avg_amounts'].sort_values(ascending=False)[:10].plot(kind='bar',fontsize=8,color=['r','m','b','y','g'])
#6-order_id个数与时间关系(时间维度)
提取hour,day,week(对日期做映射,提取其中的hour(用于datetime64格式))
data['hour']=data['place_order_time'].map(lambda x:x.hour) data['day']=data['place_order_time'].map(lambda x:x.day) data['week']=data['place_order_time'].map(lambda x:x.weekday()) data['status']=1#订单状态,用于计算订单数量分组计算订单数量
data_hour=data.groupby(by='hour').count() data_day=data.groupby(by='day').count() data_week=data.groupby(by='week').count()作图
data_hour['status'].plot(kind='bar',fontsize=10) data_day['status'].plot(kind='bar',fontsize=10) data_week['status'].plot(kind='bar',fontsize=10)
四、数据分析报告
数据源为2016年某餐厅8月份订餐情况,通过该月的订单销售情况,明确餐厅内较受欢迎菜品以及餐厅较佳营业时间
分析结果:
从订单维度看:本月平均菜品的销售单价为44.821,其中最收欢迎的前十个菜如下图左上角1,可加大宣传力度和备菜量;前十个订单点菜种类在28种左右波动,点菜数量前十的订单,其点菜数量也在28左右,前十名订单的消费总额均在1100以上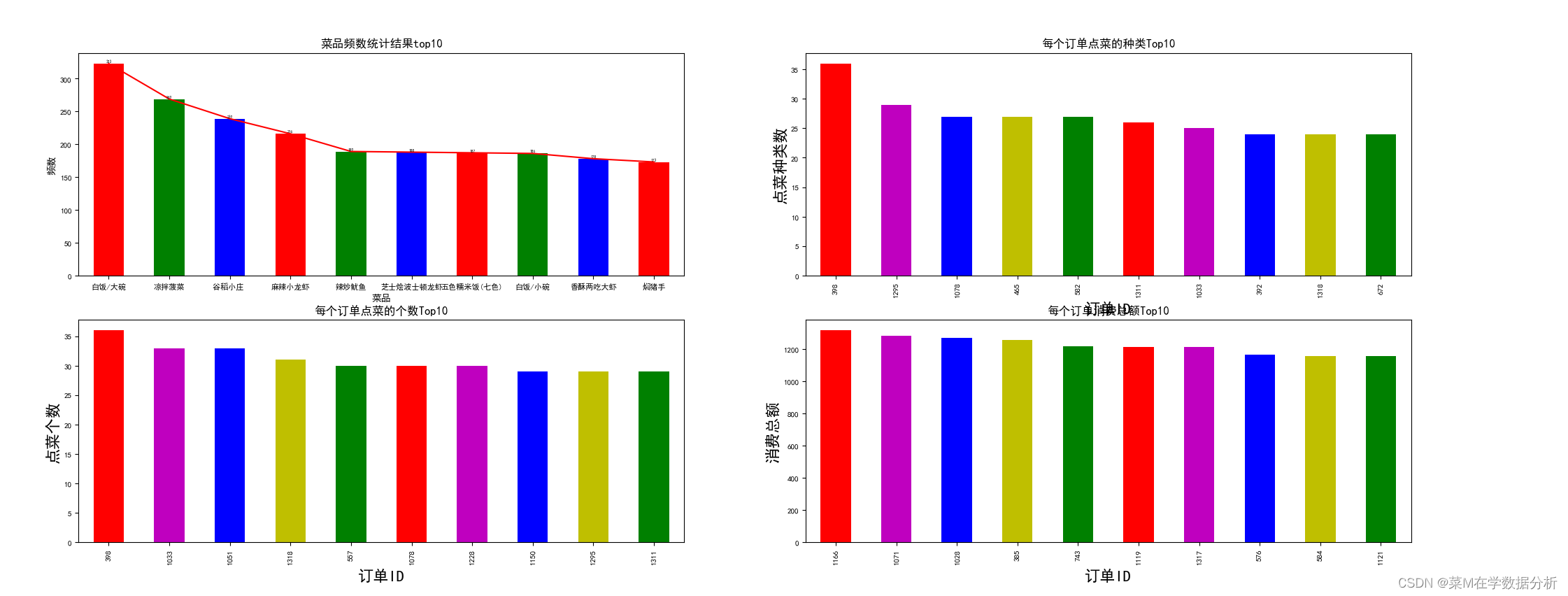
从时间维度可以得到的信息是,饭店可能在11点开始营业,因为订单是从11点开始增加,下午17点-21点生医较好,在该时间段可能忙不过来需要招聘临时工;从日期上来看,具有一定的规律,即五天迎来一次订单高峰,与一周中工作日和双休日规律类似,可能是周末迎来就餐高峰,后续在星期维度的分析确定了该部分猜测,即周末属于就餐高峰期,结合一天中17-21高峰更甚,可以建议招聘临时小时工,用于周六周日高峰忍受不足时应急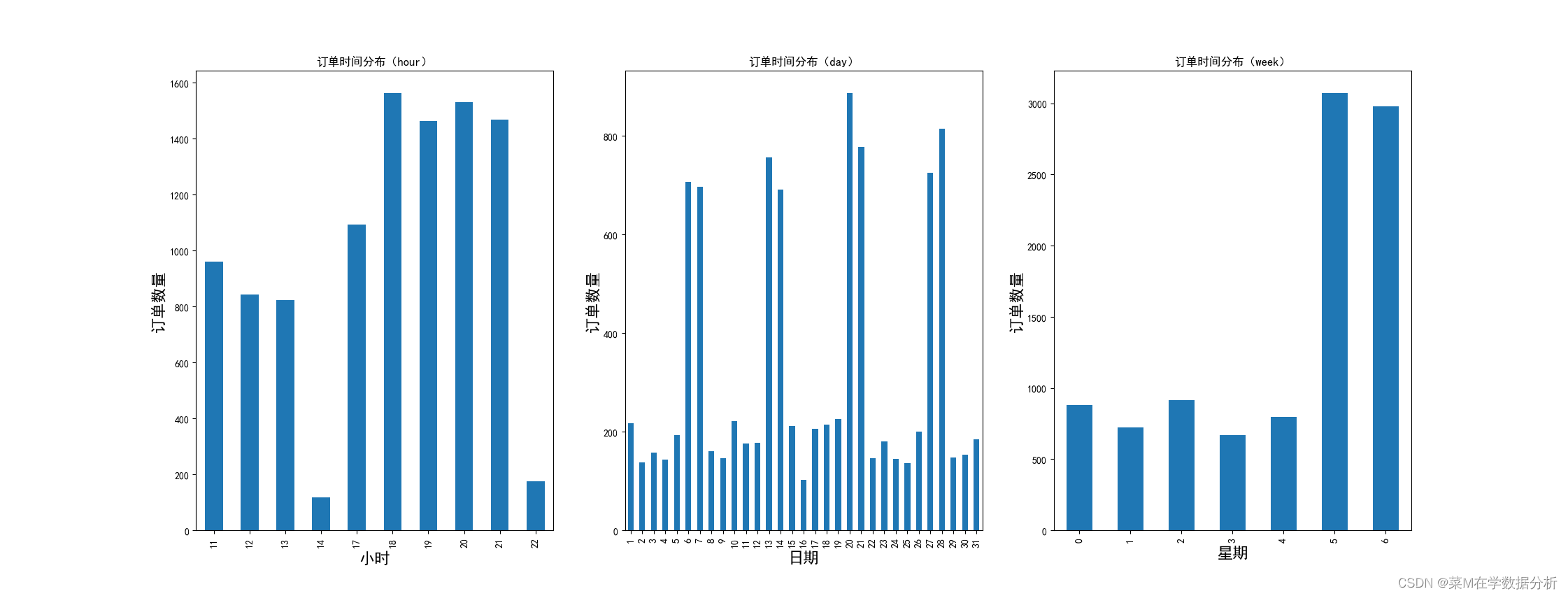
总结与思考:
从订单维度,可以得到订单下点菜个数和种类等情况,但由于没有明确的订单客户信息和该订单对应食客数,难以通过数据支持该餐厅的消费模式是在少人就餐还是多人聚餐上贡献较多,是青年还是学生(不同人员可能具有不同的消费力)
建议在搜集数据时,补充更详细的信息,例如性别、就餐人数、就餐人员层次等
知识点积累
1. 求均值,结果保留n位小数:round(data['列名].mean(),n)#pandas
round(np.mean(data['amounts']))#numpy
2. 合并数据:pd.concat([data1,data2,data3],axis=0)#0-新数据按行合并;1-新数据按列合并
3. map(function,iterable):根据给定的函数function,对指定序列iterable做映射
data.map(function):根据function,对data做映射
4.一张画布上绘制多个图-subplot方法(还有一个subplots方法以后补充):
plt.figure(figsize=(50,50))#画布尺寸
plt.subplot(221)2×2个图,第一个位置
#绘图代码#
plt.subplot(222)2×2个图,第二个位置
#绘图代码#
plt.subplot(223)2×2个图,第三个位置
#绘图代码#
plt.subplot(224)2×2个图,第四个位置
#绘图代码#
plt.show()#展示图
5. 在柱状图上添加折线