基于Pyg实现GCN对Cora数据集的分类任务
1、Pyg的基本使用方法(参考官网)
1.1、图的表示方法
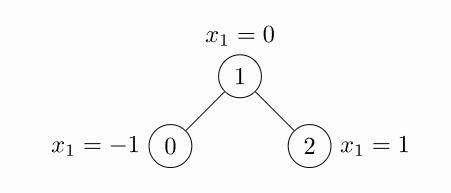
data.x: 节点的特征的shape[num_nodes, num_node_features]
data.edge_index:代表图的连接性,形状是[2, num_edges]
data.edge_attr: 边的特征的shape [num_edges, num_edge_features]
data.y: 对应的标签,可以是图级别的[1, *],也可以是节点类别的[num_nodes, *]
data.pos: 带形状的节点位置矩阵[num_nodes,num_dimensions] [num_nodes,num_dimensions]
对应下面的代码为如下
import torch
from torch_geometric.data import Data
#边的表示方式,0和1之间有节点,上面是0,下面是1,因为是无向图,所以有两个边
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
#x的特征值
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
#生成图
data = Data(x=x, edge_index=edge_index)
print(data)
结果为:Data(x=[3, 1], edge_index=[2, 4])
除此之外,还有一种生成图的方法,仍然以上图为基础
import torch
from torch_geometric.data import Data
edge_index = torch.tensor([[0, 1],
[1, 0],
[1, 2],
[2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index.t().contiguous())
结果为:Data(x=[3, 1], edge_index=[2, 4])
1.2、关于图的其他操作
常用的就是下面的,其他的可以参考官网
print(data.keys)
print(data['x'])
for key, item in data:
print(f'{key} found in data')
'edge_attr' in data
data.num_nodes 节点的个数
data.num_edges 边的数目
data.num_node_features 节点的特征
data.has_isolated_nodes() 是否有无边连接的点
data.has_self_loops() 是否有自环
data.is_directed() 是否是有向图
2、Cora数据集的介绍
Cora 数据集由机器学习论文组成,是近年来图深度学习很喜欢使用的数据集。在数据集中,论文被分为以下七类之一:
- 基于案例
- 遗传算法
- 神经网络
- 概率方法
- 强化学习
- 规则学习
- 理论
论文的选择方式是,在最终语料库中,每篇论文至少引用一篇论文或被至少一篇论文引用(即至少有一条出边或至少有一条入边,也就是样本点之间存在联系,没有任何一个样本点与其他样本点完全没联系。如果将样本点看做图中的点,则这是一个连通的图,不存在孤立点)。整个语料库中有2708篇论文。在词干堵塞和去除词尾后,且文档频率小于10的所有单词都被删除后,只剩下1433个独特的单词。
我们使用的是Planetoid,是已经处理好的数据,下面代码将详细介绍数据集中的数据类型和含义
from torch_geometric.datasets import Planetoid
dataset=Planetoid(root=r'./tmp/cora',name="Cora")
print(dataset[0])
#输出为Data(x=[2708, 1433], edge_index=[2, 10556], y=[2708], train_mask=[2708], val_mask=[2708], test_mask=[2708])
#图一共有2708个节点,每个节点的特征有1433的维度,edge_index代表一共有10556条边,y代表目标的值,也就是上面对应的7类的分类,train_mask,如果节点是训练集,是Ture,否则为false,上述val_mask和test_mask一样都是表示的这个意思,分别是验证集和测试集
print("网络数据包含的类的数量",dataset.num_classes)
print("网络的数据的边的特征的数量",dataset.num_edge_features)
print("网络数据边的数量:",dataset.data.edge_index.shape[1]/2)
print("网络数据节点的特征数量:",dataset.num_node_features)
print("网络数据节点的数量:",dataset.data.x.shape[0])
#输出为
# 网络数据包含的类的数量 7
# 网络的数据的边的特征的数量 0
# 网络数据边的数量: 5278.0
# 网络数据节点的特征数量: 1433
# 网络数据节点的数量: 2708
定义网络模型
参考官网文档的两层GCN模型
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1=GCNConv(dataset.num_node_features,16)
self.conv2=GCNConv(16,dataset.num_classes)
def forward(self,data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
开始训练
from torch.nn import functional as F
import torch_geometric
from torch_geometric.nn import GCNConv
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GCN().to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
model.eval()
pred = model(data).argmax(dim=1)
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {acc:.4f}')
训练的结果为:
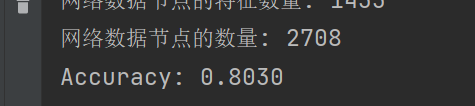
= int(correct) / int(data.test_mask.sum())
print(f’Accuracy: {acc:.4f}')
训练的结果为:
[外链图片转存中...(img-3IcxF9u5-1684847664665)]