python股票分析挖掘预测利器Numpy,Pandas,Matplotlib库经典练习题和项目代码(4)
本人股市多年的老韭菜了,各种股票分析书籍,技术指标书籍阅历无数,萌发想法,何不自己开发个股票预测分析软件,选择python因为够强大,它提供了很多高效便捷的数据分析工具包,
其中数据分析中常见的3大利器---Numpy,Pandas,Matplotlib库。
俗话说的好,工欲善其事,必先利其器,我们要做好项目,必先打好基础,那我们一起学习一下这三个数据分析库,我们前三章讲了Numpy库基础,Pandas库基础,Matplotlib库基础,
那我们这一章学习一下Numpy,Pandas,Matplotlib库在项目中的常见用法:
(1)Numpy知识代码
(1)常用科学计算函数代码:
import numpy as np
print(np.abs(-10)) # 求绝对值,该表达式返回10
print(np.around(1.2)) # 去掉小数位数,该表达式返回1
print(np.round_(1.7)) # 四舍五入,该表达式返回2
print(np.ceil(1.1)) # 求大于或等于该数的整数,该表达式返回2
print(np.floor(1.1)) # 求小于或等于该数的整数,该表达式返回1
print(np.sqrt(16)) # 求平方根值,该表达式返回4
print(np.square(6)) # 求平方,该表达式返回36
print(np.sign(6)) # 符号函数,如果大于0则返回1,该表达式返回1
print(np.sign(-6)) # 符号函数,如果小0则返回-1,该表达式返回-1
print(np.sign(0)) # 符号函数,如果等于0则返回0,该表达式返回0
print(np.log10(100)) # 求以10为底的对数,该表达式返回2
print(np.log2(4)) # 求以2为底的对数,该表达式返回2
print(np.exp(1)) # 求以e为底的幂次方,该表达式返回e
print(np.power(2,3)) # 求2的3次方,该表达式返回8(2)存储一维数组和多维数组对象:
import numpy as np
arr1 = np.arange(0,1,0.2)
# 输出[0. 0.2 0.4 0.6 0.8]
print(arr1)
# 输出<class 'numpy.ndarray'>
print(type(arr1))
print(arr1.ndim) # 返回arr1的维数,是1
# 输出[1 2 3 4]
print(np.array(range(1,5)))
arr2=np.array([[1,2,3],[4,5,6]]) # 二维数组
print(arr2.ndim) # 返回2
print(arr2.size) # 总长度,返回6
print(arr2.dtype) # 类型,返回int32
# 形状,返回(2, 3),表示二维数组,每个维度长度是3
print(arr2.shape)
arr3=np.array([1,3,5])
print(arr3.mean()) # 计算平均数,返回3
print(arr3.sum()) # 计算和,返回9
# 计算所有行的平均数,返回[2. 5.]
print(arr2.mean(axis=1))
# 计算所有列的平均数,返回[2.5 3.5 4.5]
print(arr2.mean(axis=0))(3)通过切片获取数组指定元素
创建数组后,可以通过切片方式获取指定范围的数据
import numpy as np
arr1 = np.arange(0,11,1)
# 输出[ 0 1 2 3 4 5 6 7 8 9 10]
print(arr1)
arrSplit1 = arr1[2:5]
# 输出[2 3 4]
print(arrSplit1)
# 输出[2 3 4 5 6 7 8 9],不包含10
print(arr1[2:-1]) # -1表示最右边的元素
# 输出[ 2 3 4 5 6 7 8 9 10]
print(arr1[2:]) # 表示从2号索引开始到最后,包含10
# 输出[0 1 2 3 4]
print(arr1[:5]) # 表示从0号索引开始到5号索引
# 输出[2 3 4 5 6 7 8]
print(arr1[2:-2]) # -2表示右边开始第2个元素
# 输出[0 1 2 3 4 5 6 7]
print(arr1[:-3]) # -3表示右边开始第3个元素
# 针对多维数组的切片
arr2 = np.array([[1, 2, 3],[4, 5, 6]])
# a输出[[2 3]
# [5 6]]
print(arr2[[0,1],1:])(2) Pandas知识代码
pandas库是基于Numpy库的一个开源python库,主要运用数据快速分析,清洗和准备等工作,某种程度来说可以把Pandas当成python版的Excel,与Numpy相比,Pandas库更擅长处理二维数组,Pandas库有处理一维数据结构的Series和二维数组的DataFrame.这是数据分析的重点,我们重点要学好 Pandas和Matplotlib的用法
(1)读取不同类型的文件数据
import pandas as pd
#解决数据输出时列名不对齐的问题
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
aa ='../data/TB2018.xlsx'
df = pd.DataFrame(pd.read_excel(aa))
df1= df[['买家会员名','买家实际支付金额']]
print(df1)
print('---------获取股票数据-----------')
bb ='../data/000001.csv'
df = pd.read_csv(bb,encoding = 'gbk')
df1= df[['date','open','high','close','low']]
df1.columns = ['日期','开盘价','最高价','闭市价','最低价']
print(df1)
print('---------获取文本数据-----------')
cc ='../data/fl4_name.txt'
df = pd.read_csv(cc,encoding='gbk')
print(df)注释:详细代码已经在python股票分析挖掘预测利器Numpy,Pandas,Matplotlib库学习中一些经典代码和练习
欢迎下载
(2)数据表拼接
假设创建了二个dataframe数据表,需要将他们合并
# **2.2.4 数据表拼接**
import pandas as pd
df1 = pd.DataFrame({'公司': ['万科', '阿里', '百度'], '分数': [90, 95, 85]})
df2 = pd.DataFrame({'公司': ['万科', '阿里', '京东'], '股价': [20, 180, 30]})
print(df1)
print(df2)
# (1) merge()函数
df3 = pd.merge(df1, df2)
print(df3)
df3 = pd.merge(df1, df2, how='outer')
print(df3)
df3 = pd.merge(df1, df2, how='left')
print(df3)
df3 = pd.merge(df1, df2, left_index=True, right_index=True)
print(df3)
# **补充知识点:根据行索引合并的join()函数**
df3 = df1.join(df2, lsuffix='_x', rsuffix='_y')
print(df3)
# (2) concat()函数
df3 = pd.concat([df1,df2], axis=0)
print(df3)
df3 = pd.concat([df1,df2],axis=1)
print(df3)
# (3) append()函数
df3 = df1.append(df2)
print(df3)
df3 = df1.append({'公司': '腾讯', '分数': '90'}, ignore_index=True)
print(df3)(3)Matplotlib知识代码
Matplotlib库是出色的数据可视化工具包,也是2D绘图库,比如我们股票的K线图以及折线图,饼状图等的,它提供了一整套的 API,可以生成出版质量级别的精美图形,Matplotlib 使绘图变得非常简单,在易用性和性能间取得了优异的平衡。使用 Matplotlib 绘制多曲线图。我们用几个简单的项目例子来学习一下
(1)雷达图
Matplotlib代码必须加上这二段,因为Matplotlib不支持中文显示 matplotlib.rcParams['font.family'] = 'Heiti TC'(mac操作系统需要加这句) matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'Heiti TC'
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
#matplotlib.rcParams[‘font.family’]为设置字体
radar_labels = np.array(['研究型(I)', '艺术型(A)', '社会型(S)', \
'企业型(E)', '常规型(C)', '现实型(R)'])
data = np.array([[0.40, 0.32, 0.35, 0.30, 0.30, 0.88],
[0.85, 0.35, 0.30, 0.40, 0.40, 0.30],
[0.43, 0.89, 0.30, 0.28, 0.22, 0.30],
[0.30, 0.25, 0.48, 0.85, 0.45, 0.40],
[0.20, 0.38, 0.87, 0.45, 0.32, 0.28],
[0.34, 0.31, 0.38, 0.40, 0.92, 0.28]]) # 数据值
#numpy.array([]),意为设置多维数组,python是有array功能的,但是仅仅可以定义一维数组,并不能定义多维数组,而numpy库提供了多维数组的定义。
data_labels = ('艺术家', '实验员', '工程师', '销售员', '社会工作者', '记事员')
angles = np.linspace(0, 2 * np.pi, 6, endpoint=False)
# angles=np.linspace表示要获得一组等差的数列,使用方法如下:numpy.linspace(start, stop, num=50, endpoint=True),
# 表示以start为起点,stop为结束点,中间一共取num个点,可以不填num,若不填,则默认为50,且num为非负的值。endpoint=True,
# 则取的点中包括结束点,endpoint=False,则取的点中不包括结束点
# numpy.pi为numpy库中的Π值,所以这里的angles=np.linspace(0,2*np.pi,6,endpoint=False)表示以0为起始点,2Π为结束点,不包含结束点一共取6个点。
data = np.concatenate((data, [data[0]]))
angles = np.concatenate((angles, [angles[0]]))
print(angles * 180 / np.pi)
radar_labels = np.concatenate((radar_labels, [radar_labels[0]]))
print(radar_labels)
fig = plt.figure(facecolor="white")#将图形的背景颜色设置为白色,如果不写,默认是rc
plt.subplot(111, polar=True)#绘制一个极坐标图
plt.plot(angles, data, 'o-', linewidth=1, alpha=0.2)
# plt.plot(angles,data,‘o-’,linewidth=1,alpha=0.2)表示以angles为横轴数据,data为纵轴数据,’-0’表示实线实心圈标记。
# alpha表示透明度(是浮点值),值从0-1不等,0为透明,1为不透明。linewidth表示线宽,为浮点值。
plt.fill(angles, data, alpha=0.25)
plt.thetagrids(angles * 180 / np.pi, radar_labels)
# plt.thetagrids方法用于设置极坐标角度网格线显示,参数为所要显示网格线的角度值列表,
# 且默认显示0°、45°、90°、135°、180°、225°、270°、315°的网格线。
# plt.thetagrids(angles180/np.pi,radar_labels)即为在angles180/Π的角度上,[ 0. 60. 120. 180. 240. 300. 0.]标上为radar_labels的标签。
plt.figtext(0.52, 0.95, '人格性格分析', ha='center', size=20)
# plt.figtext(x,y, txt, size=12) 在figure中的任意位置添加文本,前面两个参数是指定位置。
# plt.figtext(0.52,0.95,‘霍兰德人格分析’,ha=‘center’,size=20),意思为在0.52,0.95的位置处添加’霍兰德人格分析’的文本,字大小为20
legend = plt.legend(data_labels, loc=(0.94, 0.80), labelspacing=0.1)#这一行用来设置图例
# plt.legend(*args, **kwargs),为一般形式plt.legend(data_labels,loc=(0.94,0.80),labelspacing=0.1)
# 表示将数据data_labels添加至位置为(0.94,0.80),图例条目之间的垂直间距为0.1。
plt.savefig('holland_radar.jpg')
plt.show()
显示效果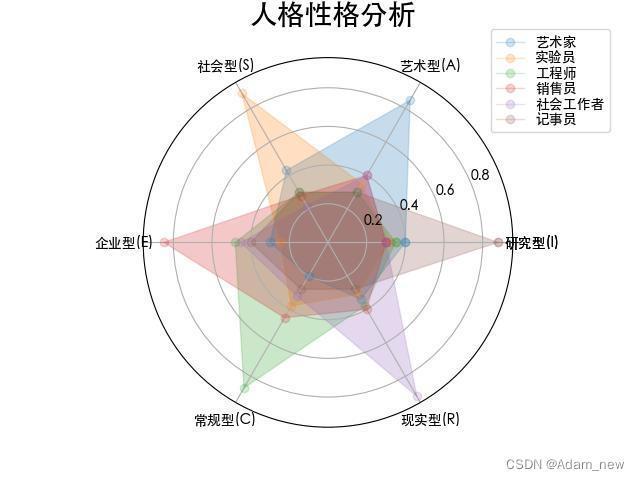
(2)简单k线图
这个案例介绍了从cvs表里读取股票数据,然后生成简单的k线图
import pandas as pd
import mplfinance as mpf
daily = pd.read_csv('002398.csv',index_col=0,parse_dates=True)
daily.index.name = 'Date'
daily.shape
daily.head(3)
daily.tail(3)
market_colors = mpf.make_marketcolors(up= 'green' , down= 'red' ,
edge= 'black' ,
wick={ 'up' : 'blue' , 'down' : 'orange' },
volume= 'purple' ,
ohlc= 'black' )
my_style = mpf.make_mpf_style(marketcolors=market_colors)
#mpf.plot(daily, type='candle')
mpf.plot(daily,type='candle',mav=(3,6,9),volume=True, style=my_style)
显示图片效果: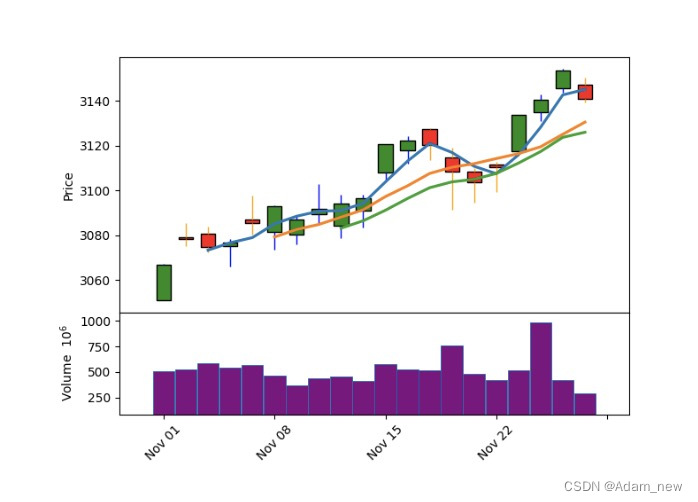
这这里只是简单的介绍了几个项目,更多的项目我已经打包整理到网上,欢迎下载
如果没看Numpy文章的,可以查看
python股票分析挖掘预测利器Numpy,Pandas,Matplotlib库知识点(1)
如果没看Pandas文章的,可以查看
python股票分析挖掘预测利器Numpy,Pandas,Matplotlib库知识点(2)
如果没看Matplotlib文章的,可以查看
python股票分析挖掘预测利器Numpy,Pandas,Matplotlib库知识点(3)
谢谢大家,欢迎学习交流!!!!