Fusion of multispectral data through illumination-aware deep neural networks for pedestrian det
近年来,多光谱行人检测作为一种有前景的解决方案受到了广泛的关注,可促进全天候应用(如安全监控和自动驾驶)的鲁棒人体目标检测。在本文中,我们证明了编码在多光谱图像中的光照信息可以显著提高行人检测的性能。提出了一种新的光照感知加权机制来准确描述场景的光照状况。将这些光照信息整合到双流深度卷积神经网络中,学习不同光照条件(白天和夜间)下的多光谱人类相关特征。此外,我们将光照信息与多光谱数据结合,生成更准确的语义分割,用于监督行人检测器的训练。将这些信息整合在一起,我们提出了一个基于光照感知行人检测和语义分割的多任务学习的有效的多光谱行人检测框架。我们提出的方法使用精心设计的多任务丢失函数进行端到端的训练,在KAIST多光谱行人数据集上优于最先进的方法。

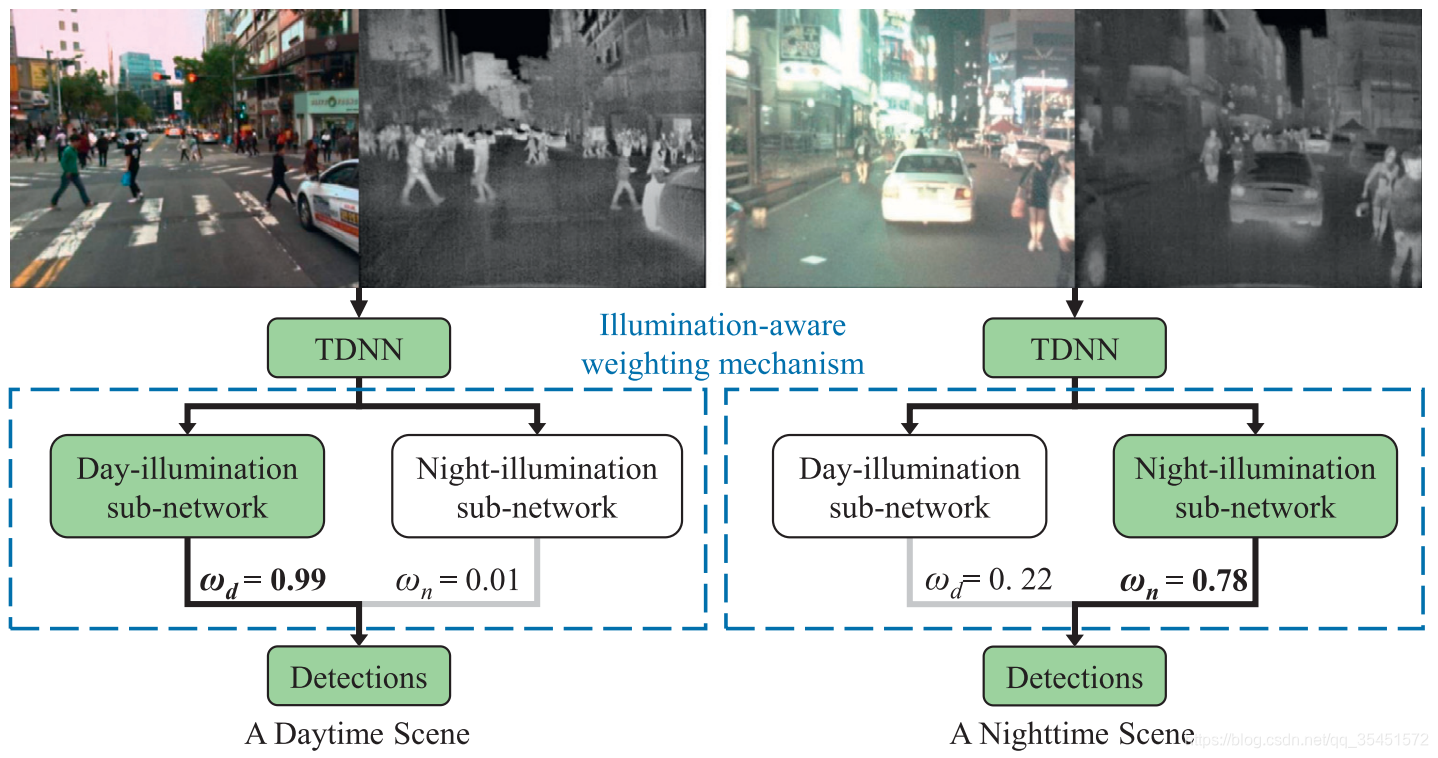
图1 (a)白天和(b)夜间场景中多光谱行人实例的特征。(a)和(b)中的第一行是行人实例的多光谱图像。(a)和(b)中的第二行显示了相应行人实例的特征映射可视化。使用深度神经区域建议网络(RPN)[41]生成可见光和热图像的特征图。在白天和夜间光照条件下,多光谱行人样本具有不同的特征。
在白天和夜间光照条件下,多光谱行人样本都表现出不同的特征,如图1所示。因此,使用多个内置子网(每个子网专门捕捉光照特定的视觉模式),为处理由光照变化引起的大量类内差异提供了一个有效的解决方案。根据多光谱数据对光照信息进行鲁棒估计,并将光照信息注入到多个光照感知子网络中,学习多光谱语义特征图,在不同光照条件下同时进行行人检测和语义分割。给出一对白天捕获的多光谱图像,我们提出的光照感知加权机制自适应地为白天-光照子网络(行人检测和语义分割)分配一个高权重,以学习白天的人类相关特征。相比之下,夜间场景的多光谱图像被用来训练夜间照明子网络。我们在图2中说明了这种光照感知加权机制是如何工作的。通过融合多个光照感知子网络的输出产生检测结果,并对较大的场景光照变化保持鲁棒性。
本文的主要贡献如下
- 证明了通过考虑多光谱语义特征的全连接神经网络体系结构可以稳健地确定场景的光照条件,估计的光照权重提供了有用的信息来提高行人检测的性能。
- 将光照感知机制整合到双流深度卷积神经网络中,以学习不同光照条件(白天和夜间)下的多光谱人类相关特征。第一个利用照明信息训练多光谱行人探测器。
- 提出一个完整的框架,用于多光谱行人检测基于联合学习illumination-aware行人检测和语义分割是训练有素的端到端使用一个精心设计的多任务损失,实现更高精度和更快的运行时相比,目前最先进的多光谱探测器。
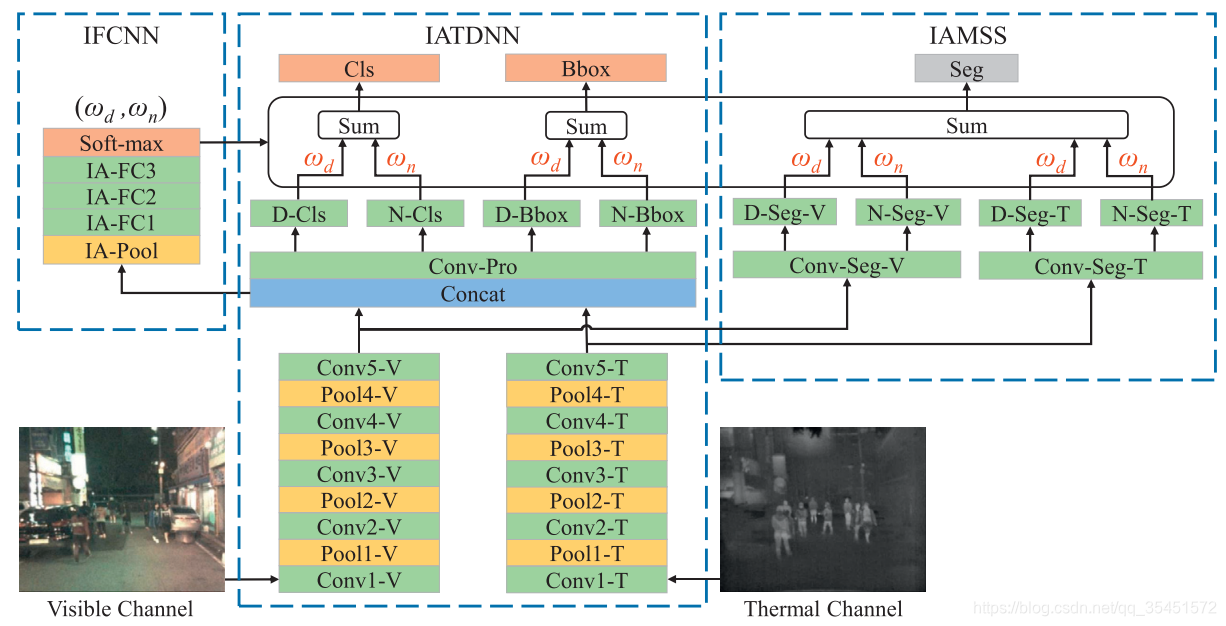
图3 提出的光照感知多光谱深度神经网络(IATDNN+IAMSS)的体系结构。注意,绿色方框表示卷积层和全连接层,黄色方框表示池化层,蓝色方框表示融合层,灰色方框表示分割层,橙色方框表示输出层。应该是彩色的。
如图3所示,光照感知多光谱深度神经网络的体系结构由光照全连接神经网络(IFCNN),光照感知双流深度卷积神经网络(IATDNN) 和 光照感知多光谱语义分割(IAMSS) 三个集成处理模块组成。
给定对齐的可见光和热图像,IFCNN计算光照感知权重,以确定它是白天的场景还是夜晚的场景。
通过提出的光照感知机制,IATDNN和IAMSS利用多个子网同时生成分类分数(Cls)、包围框(Bbox)和分割掩码(Seg)。例如,IATDNN使用两个独立的分类子网络(D-Cls和N-Cls)在昼夜照明下对人类进行分类。将各子网络的Cls、Bbox、Seg结果进行整合,通过根据场景光照条件定义的门函数得到最终输出。基于光照感知行人检测和语义分割的多任务学习,对该方法进行端到端的训练。
1.光照全连接神经网络(IFCNN)
如图3所示,将两幅可见光和红外图像送入前5个卷积层,并将两流深度卷积神经网络[20]的卷积层池化,提取每个流中的语义特征。TDNN的每个特征提取层流都以VGG-16[36]中的Conv1-5为骨干。然后融合两个通道的特征映射,通过连接层(Concat)生成双流特征映射(TSFM)。TSFM利用作为输入的IFCNN权重计算illumination-aware 的
ω
d
\omega_d
ωd 和
ω
n
=
(
1
−
ω
d
)
\omega_n =(1- \omega_d)
ωn=(1−ωd) 确定一个场景的照明条件。
IFCNN由一个池化层(IA-Pool)、三个全连接层(IA-FC1、IA-FC2、IA-FC3)和soft-max层(soft-max)组成。与空间金字塔池化层(SPP)一样,空间金字塔池化层消除了网络[16]的固定大小约束,IA-Pool使用双线性插值将TSFM的特征调整为固定长度的图形图(7 7),并为完全连接的层生成固定大小的输出。IA-FC1、IA-FC2、IA-FC3的信道数根据经验分别设置为512、64,2。Soft-max是IFCNN的最后一层。Softmax的输出是
ω
d
\omega_d
ωd 和
ω
n
\omega_n
ωn 。我们将照明误差术语li定义为:
L
I
=
−
ω
^
d
⋅
log
(
ω
d
)
−
ω
^
n
⋅
log
(
ω
n
)
L_{I}=-\hat{\omega}_{d} \cdot \log \left(\omega_{d}\right)-\hat{\omega}_{n} \cdot \log \left(\omega_{n}\right)
LI=−ω^d⋅log(ωd)−ω^n⋅log(ωn)
ω d \omega_d ωd 和 ω n = ( 1 − ω d ) \omega_n =(1- \omega_d) ωn=(1−ωd)是日夜的权重估计照明场景, ω d \omega_d ωd 和 ω n = ( 1 − ω d ) \omega_n =(1- \omega_d) ωn=(1−ωd)是照明的标签。如果训练图像捕获在日间照明条件下,我们设置 ω d = 1 \omega_d=1 ωd=1 否则 ω d = 0 \omega_d=0 ωd=0 。
2. 光照感知双流深度卷积神经网络(IATDNN)
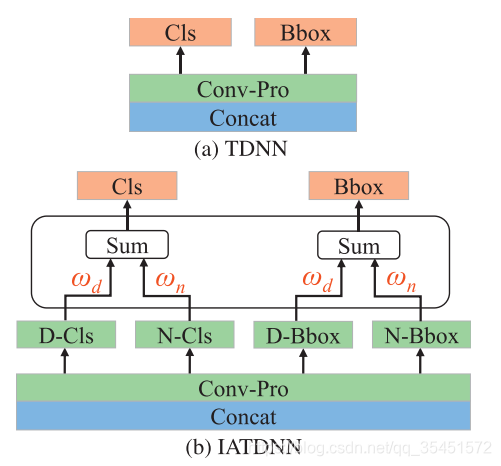
(a) TDNN和(b) IATDNN架构的比较。注意
ω
d
\omega_d
ωd 和
ω
n
\omega_n
ωn illumination-aware计算权重,绿框表示卷积层和全的黄色框表示池层,橙色蓝色框表示融合层,框表示输出层。应该是彩色的。(本图例中有关颜色的参考说明,读者可参考本文的网页版本。)
基于双流深度卷积神经网络[20]设计了IATDNN的体系结构。在IATDNN中采用RPN模型[41],因为它在行人检测方面有较好的性能。给定单个输入图像,RPN输出与自信分数相关联的多个边界框,通过分类和边界框回归生成行人建议。如图4 (a)所示,在Concat层之后附加一个3 3卷积层(con-pro),它有两个兄弟的11*1卷积层(Cls和Bbox),分别用于分类和边界盒回归。TDNN模型为利用TSFM进行鲁棒行人检测提供了一个有效的框架。我们进一步将照明信息整合到TDNN中,以生成不同照明条件下的分类和回归结果。其中,IATDNN包含4个子网络(D-Cls、N-Cls、D-Bbox、N-Bbox),产生如图4 (b)所示的光照感知检测结果。D-Cls和N-Cls分别计算白天和夜间光照条件下的分类得分,D-Bbox和N-Bbox分别生成白天和夜间场景的包围盒。这些子网络的输出使用IFCNN中计算的具有启发性的权值进行组合,从而产生最终的检测结果。检测损失项
L
D
E
L_{DE}
LDE定义为
L
D
=
∑
i
∈
S
L
c
l
s
(
c
i
f
,
c
^
i
)
+
λ
b
b
⋅
c
^
i
⋅
∑
i
∈
S
L
b
b
o
x
(
b
i
f
,
b
^
i
)
L_{D}=\sum_{i \in S} L_{c l s}\left(c_{i}^{f}, \hat{c}_{i}\right)+\lambda_{b b} \cdot \hat{c}_{i} \cdot \sum_{i \in S} L_{b b o x}\left(b_{i}^{f}, \hat{b}_{i}\right)
LD=∑i∈SLcls(cif,c^i)+λbb⋅c^i⋅∑i∈SLbbox(bif,b^i)
在
L
D
E
L_{DE}
LDE定义分类损失的总和
L
c
l
s
L_{cls}
Lcls和回归损失
L
b
b
o
x
L_{bbox}
Lbbox,
λ
b
b
\lambda_{b b}
λbb定义它们之间的正则化参数(我们组
λ
b
b
=
5
\lambda_{b b}= 5
λbb=5以前的工作[41])后,年代定义了mini-batch中的训练样本集。如果训练样本的一个地面真值包围框的相交过并(IoU)比率大于0.5,则认为该训练样本为正,否则为负。这里训练标签푐푖设置为1的正样本和0负的。对于每一个阳性样品,其边界框设置为푏푖计算边界框回归的损失。式(2)中,分类损失项L cls定义为
L
c
l
s
(
c
i
f
,
c
^
i
)
=
−
c
^
i
⋅
log
(
c
i
f
)
−
(
1
−
c
^
i
)
⋅
log
(
1
−
c
i
f
)
L_{c l s}\left(c_{i}^{f}, \hat{c}_{i}\right)=-\hat{c}_{i} \cdot \log \left(c_{i}^{f}\right)-\left(1-\hat{c}_{i}\right) \cdot \log \left(1-c_{i}^{f}\right)
Lcls(cif,c^i)=−c^i⋅log(cif)−(1−c^i)⋅log(1−cif)
回归损失项
L
b
b
o
x
L_{bbox}
Lbbox定义为
L
b
b
o
x
(
b
i
f
,
b
^
i
)
=
∑
smooth
L
1
(
b
i
j
f
,
b
^
i
j
)
L_{b b o x}\left(b_{i}^{f}, \hat{b}_{i}\right)=\sum \operatorname{smooth}_{L_{1}}\left(b_{i j}^{f}, \hat{b}_{i j}\right)
Lbbox(bif,b^i)=∑smoothL1(bijf,b^ij)
c
i
f
c_{i}^{f}
cif 与
b
i
f
b_{i}^{f}
bif 分别是预测分类的得分与回归的目标框。
s
m
o
o
t
h
L
1
{smooth}_{L_{1}}
smoothL1 是
L
1
L_1
L1正则损失,被用来学习
b
i
f
b_{i}^{f}
bif与
b
^
i
\hat{b}_{i}
b^i之间的映射关系。
在IATDNN中,
c
i
f
c_{i}^{f}
cif 是计算白天分类得分
c
i
d
c_{i}^{d}
cid与晚上分类得分
c
i
n
c_{i}^{n}
cin的总和。
c i f = ω d ⋅ c i d + ω n ⋅ c i n c_{i}^{f}=\omega_{d} \cdot c_{i}^{d}+\omega_{n} \cdot c_{i}^{n} cif=ωd⋅cid+ωn⋅cin
b
i
f
b_{i}^{f}
bif是两个边框的光照加权组合,是由D-Bbox子网和N-Bbox子网分别加权组成。
b
i
f
=
ω
d
⋅
b
i
d
+
ω
n
⋅
b
i
n
b_{i}^{f}=\omega_{d} \cdot b_{i}^{d}+\omega_{n} \cdot b_{i}^{n}
bif=ωd⋅bid+ωn⋅bin
通过上述光照加权机制,将给予dayillumination子网络(分类与回归)较高的优先级来学习白天场景中的人类相关特征。另一方面,利用夜间场景的多光谱特征图,在夜间照明条件下产生可靠的检测结果。
3. 光照感知的多光谱语义分割(IAMSS)
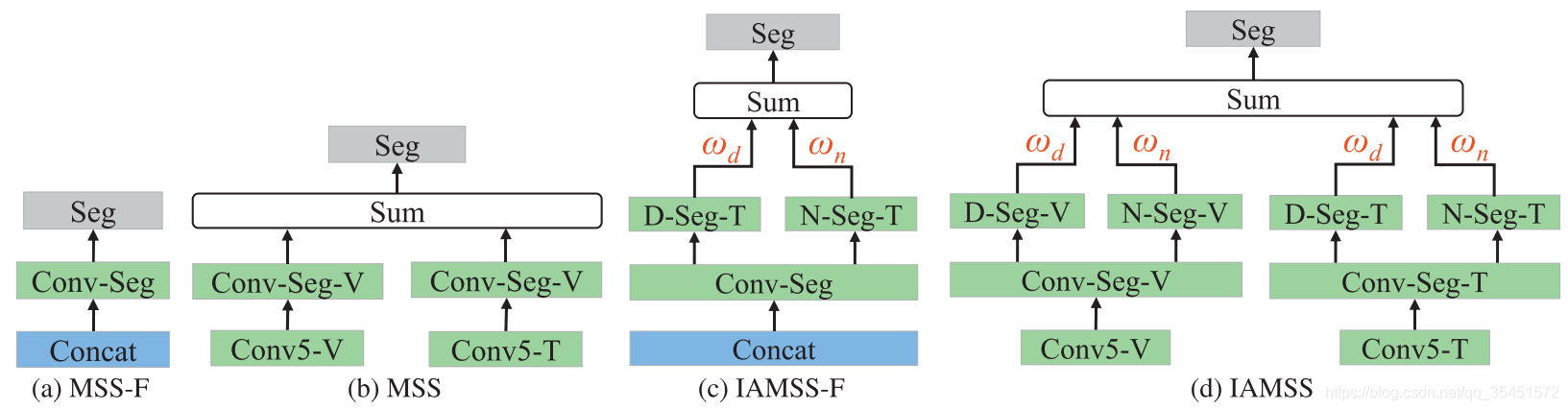
(a) MSS- f, (b) MSS, © IAMSS- f和(d) IAMSS体系的比较。注意,绿色方框表示卷积层,蓝色方框表示融合层,灰色方框表示分割层。应该是彩色的。
本文将语义分割方案与双流深度卷积神经网络相结合,以实现在多光谱图像上同时进行行人检测和分割。给定来自两个多光谱通道(可见光通道和热通道)的信息,在不同阶段(特征阶段与决策阶段)的融合会导致不同的分割结果。因此,我们希望研究一种适合多光谱分割任务的最佳融合体系结构。为此,我们设计了两种进行不同阶段融合的多光谱语义分割架构,分别为特征阶段多光谱语义分割(feature-stage multispectral semantic segmentation, MSS)和决策阶段多光谱语义分割(decision-stage multispectral semantic segmentation, MSS)。
如图5 (a)和(b)所示,MSS-F首先对Conv5-V和Conv5-T的特征图进行拼接,然后使用一个通用的Conv-Seg层来生成分割掩码。相比之下,MSS使用两个卷积层(convo - seg - v和convo - seg - t)为单个通道生成不同的分割图,然后结合两个流输出生成最终的分割掩码。此外,我们希望研究考虑场景的光照条件是否能提高语义分割的性能。
在MSS- f和MSS体系结构的基础上,我们设计了两种光照感知的多光谱语义分割网络(IAMSS- f和IAMSS)。使用两个分割子网络(d -seg和N-seg)生成光照感知语义分割结果,如图5 ©和(d)所示。需要注意的是,IAMSS- f包含两个子网络,IAMSS包含四个子网络。通过光照加权机制融合这些子网络的输出,利用IFCNN预测的光照权重生成多光谱语义分割。在第四节中,我们给出了这四种不同的多光谱分割体系结构的评价结果。
分割损失术语定义为:
L
S
=
∑
i
∈
C
∑
j
∈
S
[
−
s
^
j
⋅
log
(
s
i
j
f
)
−
(
1
−
s
^
j
)
⋅
log
(
1
−
s
i
j
f
)
]
L_{S}=\sum_{i \in C} \sum_{j \in S}\left[-\hat{s}_{j} \cdot \log \left(s_{i j}^{f}\right)-\left(1-\hat{s}_{j}\right) \cdot \log \left(1-s_{i j}^{f}\right)\right]
LS=∑i∈C∑j∈S[−s^j⋅log(sijf)−(1−s^j)⋅log(1−sijf)]
s i j f s_{i j}^{f} sijf定义为预测分割,C定义为分割流(MSS- f和IAMSS- f只包含一个分割流,MSS和IAMSS包含两个流),S定义为小批量的训练样本集。这里培训细分 c ^ i \hat{c}_{i} c^i设置为1的正样本和0负的。
D-Seg子网和N-Seg子网预测的两个分割掩码sd和s分别为
s
i
j
f
=
ω
d
⋅
s
i
j
d
+
ω
n
⋅
s
i
j
n
s_{i j}^{f}=\omega_{d} \cdot s_{i j}^{d}+\omega_{n} \cdot s_{i j}^{n}
sijf=ωd⋅sijd+ωn⋅sijn
我们对方程式中定义的损失项进行积分。(1),(2),(7)进行光照感知行人检测和分割的多任务学习。多任务丢失函数定义为
L
I
+
D
+
S
=
L
D
+
λ
i
a
⋅
L
I
+
λ
s
m
⋅
L
S
L_{I+D+S}=L_{D}+\lambda_{i a} \cdot L_{I}+\lambda_{s m} \cdot L_{S}
LI+D+S=LD+λia⋅LI+λsm⋅LS
式中, λ i a \lambda_{i a} λia和 λ s m \lambda_{sm} λsm分别为损失项 L I L_I LI和 L S L_S LS 的权衡系数。我们根据Brazil等人[3]提出的方法设置 λ i a = 1 \lambda_{i a}=1 λia=1, λ s m = 1 \lambda_{sm}=1 λsm=1。我们利用这个损失函数来联合训练光照感知的多光谱深度神经网络。
KAIST训练数据集由50172对对齐良好的多光谱图像组成,这些图像是在不同的光照条件下使用可见光和红外相机捕获的。在之前的工作[20]之后,每隔两帧对训练数据集进行图像采样,得到25086对训练图像。KAIST测试数据集由2252对多光谱图像组成,其中1455对是在白天捕获的。根据[17]中引入的合理设置,我们使用KAIST测试注释来评估检测性能。值得注意的是,CVC-14[14]是另一个包含可见热图像对的多光谱行人基准。然而,该多模态数据集是使用立体视觉系统获取的,可见图像和热图像没有正确对齐。此外,注解分别在热通道和可见通道中生成。一些行人注释仅在一个通道中生成,但在另一个通道中不可用。因此,本文仅使用KAIST数据集进行性能评价。
实现细节:我们使用以图像为中心的训练方案[41]训练所有的多光谱行人检测器。每个minibatch包含1张图片和120个锚点,随机抽取。如果锚与一个地真盒的IoU比率大于0.5,则认为锚为正,否则为负。利用在大型ImageNet数据集[35]上预训练的VGG-16[36]深度神经网络的前5个卷积层参数,对TDNN的每个流中的前5个卷积层进行初始化。全连通层和所有其他卷积层以零均值高斯分布的标准偏差进行初始化。各模块的详细配置见表1。我们提出的模型的源代码和检测结果将在未来向公众开放。在Caffe[18]框架下,采用随机梯度下降(SGD)[45]训练深度神经网络,其动量为0.9,权重衰减为0.0005[21]。为了避免因爆炸渐变[33]而导致的学习失败,我们使用了一个10的阈值来剪辑渐变。
评价指标:利用log-average miss rate (MR)[8]来评价各种多谱行人检测算法的性能。根据前面的工作[17],如果带有地面真值1的IoU超过50%,则检测到的包围框结果将被视为真阳性。未匹配的检测出的包围框为假阳性,未匹配的地真框为假阴性。根据Dollar等人[8]提出的方法,检测到的任何与忽略ground truth标签匹配的包围盒都不会被认为是真阳性,任何不匹配的忽略ground truth标签都不会被认为是假阴性。我们通过平均每幅图像9个假阳性(FPPI)值在对数空间中平均间隔10 2到10 0的缺失率来计算MR[17,19,20]。
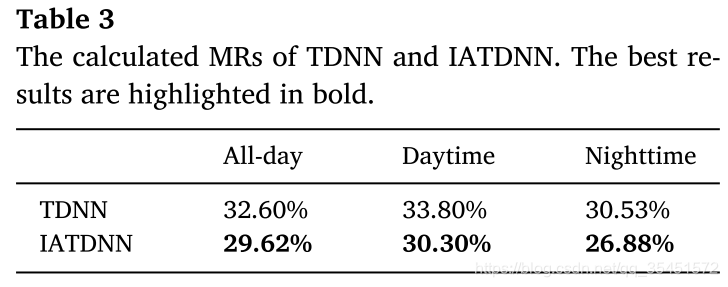
我们进一步评估是否可以利用照明信息来提高多光谱行人检测器的性能。具体来说,我们在不使用语义分割信息的情况下评估了TDNN和IATDNN的性能。将Eq.(1)中的光照损失项与Eq.(2)中的检测损失项相结合,共同训练IAFCNN和IATDNN,并使用检测损失项训练TDNN。TDNN模型为利用多光谱特征进行稳健的行人检测[20]提供了一种有效的框架。然而,它不区分在白天和夜间照明条件下的人类实例,并使用一个共同的Con-Prov层来生成检测结果。相比之下,IATDNN采用光照加权机制,自适应地组合多个光照感知子网(D-Cls、N-Cls、D-Reg、N-Reg)的输出,生成最终的检测结果。

光照加权机制在我们提出的光照感知深度神经网络中提供了一个重要的功能。我们首先评估IAFCNN能否准确计算出提供关键信息的光照权重,以平衡光照感知子网络的输出。我们利用KAIST测试数据集,其中包含白天(1455帧)和夜间(797帧)拍摄的多光谱图像,来评估IAFCNN的性能。一双很好地结合的多光谱图像,IAFCNN将输出day-illumination体重휔d。照明条件正确预测如果휔d比;0.5一个白天的场景或휔d & lt;夜间的0.5美元。此外,我们分别使用可见光图像(IFCNN-V)和热成像图像(IFCNN-T)提取的特征图来评估光照预测的性能,以研究哪个通道提供了最可靠的信息来确定场景的光照条件。IFCNN- v、IFCNN- t和IFCNN的架构如图6所示,表2比较了它们的预测精度。
结果表明,可见光通道的信息可用于昼景和夜景(昼景为97.94%,夜景为97.11%)的光照预测。这是一个合理的结果,因为人类可以很容易地根据视觉观察确定这是一个白天的场景或夜间的场景。虽然热通道不能单独用于光照预测,但它提供了对可见光通道的补充信息,提高了光照预测的性能。通过将可见光和热通道互补信息的融合,IFCNN计算出了比IFCNN- v(仅使用可见光图像)和IFCNN- t(仅使用热图像)更准确的光照权重。图7显示了一些IFCNN失败的情况。当白天光照条件不佳或夜间路灯照明良好时,IFCNN模型会产生错误的预测结果。总的来说,通过考虑多光谱语义特征,基于IFCNN可以鲁棒地确定场景的光照条件。