flink动态表中的窗口
flink动态表中的窗口
| Flink Window | 作用 |
|---|---|
| GroupWindow | 对window中的数据按照字段进行分组 |
| OverWindow | 在整个Window窗口的条件下,对数据进行统计操作等 |
Table API和SQL需要引入的依赖有两个:planner和bridge。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.10.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.10.1</version>
</dependency>
滚动窗口
TableAPI方式
滚动窗口(Tumbling windows)要用Tumble类来定义,另外还有三个方法:
over:定义窗口长度
on:用来分组(按时间间隔)或者排序(按行数)的时间字段
as:别名,必须出现在后面的groupBy中
// Tumbling Event-time Window
.window(Tumble.over("10.minutes").on("rowtime").as("w"))
// Tumbling Processing-time Window
.window(Tumble.over("10.minutes").on("proctime").as("w"))
// Tumbling Row-count Window
.window(Tumble.over("10.rows").on("proctime").as("w"))
滑动窗口
TableAPI方式
滑动窗口(Sliding windows)要用Slide类来定义,另外还有四个方法:
over:定义窗口长度
every:定义滑动步长
on:用来分组(按时间间隔)或者排序(按行数)的时间字段
as:别名,必须出现在后面的groupBy中
// Sliding Event-time Window
.window(Slide.over("10.minutes").every("5.minutes").on("rowtime").as("w"))
// Sliding Processing-time window
.window(Slide.over("10.minutes").every("5.minutes").on("proctime").as("w"))
// Sliding Row-count window
.window(Slide.over("10.rows").every("5.rows").on("proctime").as("w"))
会话窗口
TableAPI方式
会话窗口(Session windows)要用Session类来定义,另外还有三个方法:
withGap:会话时间间隔
on:用来分组(按时间间隔)或者排序(按行数)的时间字段
as:别名,必须出现在后面的groupBy中
// Session Event-time Window
.window(Session.withGap.("10.minutes").on("rowtime").as("w"))
// Session Processing-time Window
.window(Session.withGap.("10.minutes").on("proctime").as("w"))
FlinkSQL方式
我们已经了解了在Table API里window的调用方式,同样,我们也可以在SQL中直接加入窗口的定义和使用。Group Windows在SQL查询的Group BY子句中定义。与使用常规GROUP BY子句的查询一样,使用GROUP BY子句的查询会计算每个组的单个结果行。
SQL支持以下Group窗口函数:
TUMBLE(time_attr, interval)
定义一个滚动窗口,第一个参数是时间字段,第二个参数是窗口长度。
HOP(time_attr, interval, interval)
定义一个滑动窗口,第一个参数是时间字段,第二个参数是窗口滑动步长,第三个是窗口长度。
SESSION(time_attr, interval)
定义一个会话窗口,第一个参数是时间字段,第二个参数是窗口间隔(Gap)。
另外还有一些辅助函数,可以用来选择Group Window的开始和结束时间戳,以及时间属性。
这里只写TUMBLE_*,滑动和会话窗口是类似的(HOP_*,SESSION_*)。
TUMBLE_START(time_attr, interval)
TUMBLE_END(time_attr, interval)
TUMBLE_ROWTIME(time_attr, interval)
TUMBLE_PROCTIME(time_attr, interval)
接下来就是具体的例子
Group Windows
(1)ProcessTime
1)TimeWindow
1>Tumble
package day07;
import bean.SensorReading;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQL09_ProcessTime_GroupWindow_Tumble {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//获取TableAPI执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.读取端口数据转换为JavaBean
SingleOutputStreamOperator<SensorReading> sensorDS = env.socketTextStream("hadoop102", 9999)
.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0],
Long.parseLong(fields[1]),
Double.parseDouble(fields[2]));
});
//----TableApi的形式 -----------------------------------------------------
//3.将流转换为表并指定处理时间字段
Table table = tableEnv.fromDataStream(sensorDS, "id,ts,temp,pt.proctime");
//4.基于时间的滚动窗口TableAPI
// over("10.seconds").on("pt").as("tw"),
// over("10.seconds"),表示的是窗口的大小为10s,注意是seconds
// on("pt")基于时间字段pt,
// as("tw"),是一个别名,tw。
Table tableResult = table.window(Tumble.over("10.seconds").on("pt").as("tw"))
//根据处理时间和id进行分组
.groupBy("tw,id")
.select("id,id.count,tw.start"); //可以拿到当前事件的开始时间tw.start,。
//----sql的形式---------------------------------------------------------
//5.基于时间的滚动窗口SQL API
tableEnv.createTemporaryView("sensor", table); //这里只能从table中读取数据建表,因为table中有pt这个字段。
//这里是second,不是复数。可以获取窗口的开始时间或者是结束时间--tumble_end()、tumble_start()
//也就是窗口信息也是可以拿到的。
Table sqlResult = tableEnv.sqlQuery("select id,count(id),tumble_end(pt,interval '10' second) " +
"from sensor " +
"group by id,tumble(pt,interval '10' second)");
//6.转换为流进行输出
tableEnv.toAppendStream(tableResult, Row.class).print("Table");
tableEnv.toAppendStream(sqlResult, Row.class).print("SQL");
//7.执行任务
env.execute();
}
}
2>Slide
package day07;
import bean.SensorReading;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Slide;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQL10_ProcessTime_GroupWindow_Slide {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//获取TableAPI执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.读取端口数据转换为JavaBean
SingleOutputStreamOperator<SensorReading> sensorDS = env.socketTextStream("hadoop102", 9999)
.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0],
Long.parseLong(fields[1]),
Double.parseDouble(fields[2]));
});
//3.将流转换为表并指定处理时间字段
Table table = tableEnv.fromDataStream(sensorDS, "id,ts,temp,pt.proctime");
//4.基于时间的滚动窗口TableAPI
// over("10.seconds").every("5.seconds")
// over("10.seconds"),表示窗口的大小为10s。
//every("5.seconds"),表示滑动的步长为5s。
//滑动窗口不能在select后获取窗口的信息
Table tableResult = table.window(Slide.over("10.seconds").every("5.seconds").on("pt").as("sw"))
.groupBy("sw,id")
.select("id,id.count");
//5.基于时间的滚动窗口SQL API
//hop(pt,interval '5' second,interval '10' second),用hop来表示滑动窗口的有关信息
//注意第一个是滑动步长,第二个参数是窗口的大小。
//滑动窗口不能在select后获取窗口的信息
tableEnv.createTemporaryView("sensor", table);
Table sqlResult = tableEnv.sqlQuery("select id,count(id) " +
"from sensor " +
"group by id,hop(pt,interval '5' second,interval '10' second)");
//6.转换为流进行输出
tableEnv.toAppendStream(tableResult, Row.class).print("Table");
tableEnv.toAppendStream(sqlResult, Row.class).print("SQL");
//7.执行任务
env.execute();
}
}
3>Session
package day07;
import bean.SensorReading;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Session;
import org.apache.flink.table.api.Slide;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQL11_ProcessTime_GroupWindow_Session {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//获取TableAPI执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.读取端口数据转换为JavaBean
SingleOutputStreamOperator<SensorReading> sensorDS = env.socketTextStream("hadoop102", 9999)
.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0],
Long.parseLong(fields[1]),
Double.parseDouble(fields[2]));
});
//3.将流转换为表并指定处理时间字段
Table table = tableEnv.fromDataStream(sensorDS, "id,ts,temp,pt.proctime");
//4.基于时间的滚动窗口TableAPI
//select后面不能得到会话信息
//以5s作为一个会话窗口,按照处理时间和id进行分组。所以就是一个id一个窗口,一直输入的话看不见结果的,停止输入,等5s,可以看见结果。
Table tableResult = table.window(Session.withGap("5.seconds").on("pt").as("sw"))
.groupBy("sw,id")
.select("id,id.count");
//5.基于时间的滚动窗口SQL API
//select后面不能得到会话信息
tableEnv.createTemporaryView("sensor", table);
Table sqlResult = tableEnv.sqlQuery("select id,count(id) " +
"from sensor " +
"group by id,session(pt,interval '5' second)");
//6.转换为流进行输出
tableEnv.toAppendStream(tableResult, Row.class).print("Table");
tableEnv.toAppendStream(sqlResult, Row.class).print("SQL");
//7.执行任务
env.execute();
//以5s作为一个会话窗口,按照处理时间和id进行分组。所以就是一个id一个窗口,一直输入的话看不见结果的,停止输入,等5s,可以看见结果。
}
}
2) CountWindow(计数窗口没有sql写法)
1>Tumble_Count
package day07;
import bean.SensorReading;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQL12_ProcessTime_GroupWindow_Tumble_Count {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//获取TableAPI执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.读取端口数据转换为JavaBean
SingleOutputStreamOperator<SensorReading> sensorDS = env.socketTextStream("hadoop102", 9999)
.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0],
Long.parseLong(fields[1]),
Double.parseDouble(fields[2]));
});
//3.将流转换为表并指定处理时间字段
Table table = tableEnv.fromDataStream(sensorDS, "id,ts,temp,pt.proctime");
//4.基于时间的滚动窗口TableAPI
//窗口的大小为5行。
Table tableResult = table.window(Tumble.over("5.rows").on("pt").as("tw"))
.groupBy("tw,id")
.select("id,id.count");
//5.转换为流进行输出
tableEnv.toAppendStream(tableResult, Row.class).print("Table");
//6.执行任务
env.execute();
}
}
2>Slide_Count
package day07;
import bean.SensorReading;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Slide;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQL13_ProcessTime_GroupWindow_Slide_Count {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//获取TableAPI执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.读取端口数据转换为JavaBean
SingleOutputStreamOperator<SensorReading> sensorDS = env.socketTextStream("hadoop102", 9999)
.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0],
Long.parseLong(fields[1]),
Double.parseDouble(fields[2]));
});
//3.将流转换为表并指定处理时间字段
Table table = tableEnv.fromDataStream(sensorDS, "id,ts,temp,pt.proctime");
//4.基于时间的滚动窗口TableAPI
//.over("5.rows").every("2.rows").on("pt").as("sw")
//over("5.rows"),5行数据作为一个窗口。
//滑动步长为2行。
Table tableResult = table.window(Slide.over("5.rows").every("2.rows").on("pt").as("sw"))
.groupBy("sw,id")
.select("id,id.count");
//5.转换为流进行输出
tableEnv.toAppendStream(tableResult, Row.class).print("Table");
//7.执行任务
env.execute();
}
}
(2)EventTime
1)TimeWindow
1>Tumble
package day07;
import bean.SensorReading;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQL14_EventTime_GroupWindow_Tumble {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//获取TableAPI执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.读取端口数据转换为JavaBean
SingleOutputStreamOperator<SensorReading> sensorDS = env.socketTextStream("hadoop102", 9999)
.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0],
Long.parseLong(fields[1]),
Double.parseDouble(fields[2]));
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<SensorReading>(Time.seconds(2)) {
@Override
public long extractTimestamp(SensorReading element) {
return element.getTs() * 1000L;
}
});
//3.将流转换为表并指定处理时间字段
Table table = tableEnv.fromDataStream(sensorDS, "id,ts,temp,rt.rowtime");
//4.TableAPI
// Table tableResult = table.window(Tumble.over("10.seconds").on("rt").as("tw"))
// .groupBy("tw,id")
// .select("id,id.count");
Table tableResult = table.window(Tumble.over("10.seconds").on("rt").as("tw"))
.groupBy("tw,id")
.select("id,id.count");
//5.SQL
tableEnv.createTemporaryView("sensor", table); //如果没有时间字段的话,可以用sensorDS创建临时表,但是流中没有时间字段,所以从table表中获取数据,来创建临时表。
Table sqlResult = tableEnv.sqlQuery("select id,count(id) " +
"from sensor " +
"group by id,tumble(rt,interval '10' second)");
//6.转换为流进行打印输出
tableEnv.toAppendStream(tableResult, Row.class).print("Table");
tableEnv.toAppendStream(sqlResult, Row.class).print("SQL");
//7.执行
env.execute();
//------视频15
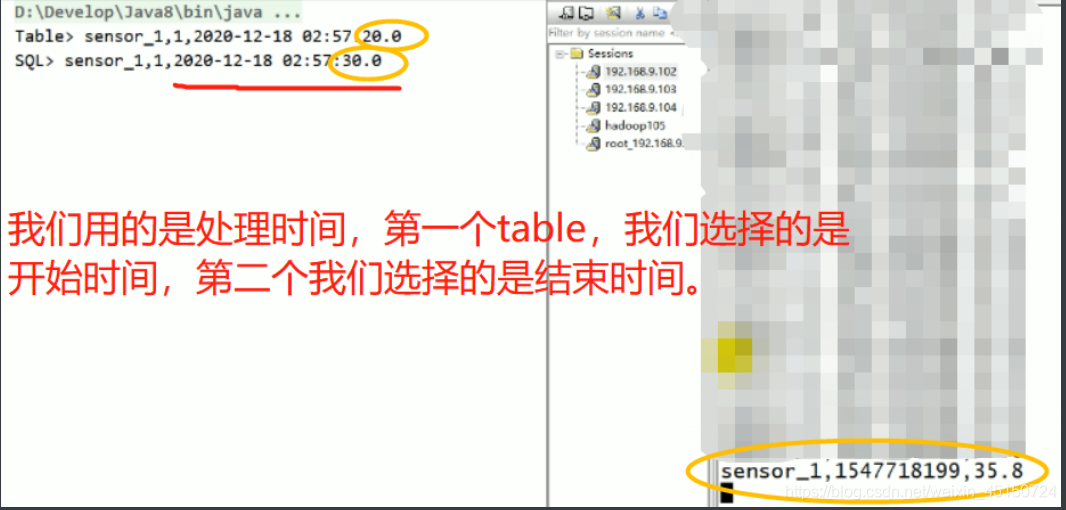
//窗口是10s,延迟2s.
//199,202有结果
//seneor_1,11111199,35.8
//seneor_6,11111202,35.8
//为什么用sensor_6,事件时间为202的时候,也能输出 seneor_1,1 呢?
//watermark会往下游传。watermark到了200,窗口就得关。和key没有关系,只有会话窗口会看key.
//和watermark传递有关系,向下广播。
//和并行度有点关系。
}
}
2>Slide
package day07;
import bean.SensorReading;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.table.api.Slide;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQL15_EventTime_GroupWindow_Slide {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//获取TableAPI执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.读取端口数据转换为JavaBean
SingleOutputStreamOperator<SensorReading> sensorDS = env.socketTextStream("hadoop102", 9999)
.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0],
Long.parseLong(fields[1]),
Double.parseDouble(fields[2]));
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<SensorReading>(Time.seconds(2)) {
@Override
public long extractTimestamp(SensorReading element) {
return element.getTs() * 1000L;
}
});
//3.将流转换为表并指定处理时间字段
Table table = tableEnv.fromDataStream(sensorDS, "id,ts,temp,rt.rowtime");
//4.TableAPI
Table tableResult = table.window(Slide.over("10.seconds").every("2.seconds").on("rt").as("sw"))
.groupBy("sw,id")
.select("id,id.count");
//5.SQL
tableEnv.createTemporaryView("sensor", table);
Table sqlResult = tableEnv.sqlQuery("select id,count(id) " +
"from sensor " +
"group by id,hop(rt,interval '2' second,interval '10' second)");
//6.转换为流进行打印输出
tableEnv.toAppendStream(tableResult, Row.class).print("Table");
tableEnv.toAppendStream(sqlResult, Row.class).print("SQL");
//7.执行
env.execute();
//10,2。每个时间处于5个窗口
//只要是事件时间,统一都看watermark。
// sensor_1,1547777199,35.8
// sensor_6,1547777202,45
//因为并行度是1,所以会输出 sensor_1,1
}
}
3>Session
package day07;
import bean.SensorReading;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.table.api.Session;
import org.apache.flink.table.api.Slide;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQL16_EventTime_GroupWindow_Session {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//获取TableAPI执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.读取端口数据转换为JavaBean
SingleOutputStreamOperator<SensorReading> sensorDS = env.socketTextStream("hadoop102", 9999)
.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0],
Long.parseLong(fields[1]),
Double.parseDouble(fields[2]));
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<SensorReading>(Time.seconds(2)) {
@Override
public long extractTimestamp(SensorReading element) {
return element.getTs() * 1000L;
}
});
//3.将流转换为表并指定处理时间字段
Table table = tableEnv.fromDataStream(sensorDS, "id,ts,temp,rt.rowtime");
//4.TableAPI
Table tableResult = table.window(Session.withGap("5.seconds").on("rt").as("sw"))
.groupBy("sw,id")
.select("id,id.count");
//5.SQL
tableEnv.createTemporaryView("sensor", table);
Table sqlResult = tableEnv.sqlQuery("select id,count(id) " +
"from sensor " +
"group by id,session(rt,interval '5' second)");
//6.转换为流进行打印输出
tableEnv.toAppendStream(tableResult, Row.class).print("Table");
tableEnv.toAppendStream(sqlResult, Row.class).print("SQL");
//7.执行
env.execute();
//5s的窗口,2s的延迟。
//基于事件时间
// sensor_1,1547777199,35.8
// sensor_6,1547777206,45
//因为并行度是1,所以会输出 sensor_1,1
//只要是事件时间,统一都看watermark。
}
}
2)CountWindow
EventTime目前没有计数窗口
overwindow(没有滚动、滑动那一套)
package bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class SensorReading {
private String id;
private Long ts;
private Double temp;
}
(1)ProcessTime
package day07;
import bean.SensorReading;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Over;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQL17_ProcessTime_OverWindow {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//获取TableAPI执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.读取端口数据转换为JavaBean
SingleOutputStreamOperator<SensorReading> sensorDS = env.socketTextStream("hadoop102", 9999)
.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0],
Long.parseLong(fields[1]),
Double.parseDouble(fields[2]));
});
//3.将流转换为表并指定处理时间字段
Table table = tableEnv.fromDataStream(sensorDS, "id,ts,temp,pt.proctime");
//4.基于时间的滚动窗口TableAPI
//---orderBy是必须选项。
//Over.partitionBy("id").orderBy("pt").as("ow"),这个是开窗,下面的select中的字段可以用 over 别名的方式,对字段进行开窗。
//例如:id.count over ow,这个就是id在开窗之后,进行计数,什么样的开窗,就是ow的那种方式。
Table tableResult = table.window(Over.partitionBy("id").orderBy("pt").as("ow"))
.select("id,id.count over ow,temp.max over ow");
//5.基于时间的滚动窗口SQL API
//over中没有倒序这一说,数据还没有来,谁是第一条呢?
tableEnv.createTemporaryView("sensor", table);
Table sqlResult = tableEnv.sqlQuery("select id,count(id) over(partition by id order by pt) ct " +
"from sensor");
//6.转换为流进行输出
//给每一个数据都开了一个独立的窗口。使用append流即可,因为不可能撤回数据。
tableEnv.toRetractStream(tableResult, Row.class).print("Table");
tableEnv.toRetractStream(sqlResult, Row.class).print("SQL");
//7.执行任务
env.execute();
}
}
(2)EventTime
package day07_exercise;
import bean.SensorReading;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.table.api.Over;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.java.StreamTableEnvironment;
import org.apache.flink.types.Row;
public class FlinkSQL18_EventTime_OverWindow {
public static void main(String[] args) throws Exception {
//1.获取执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
//获取TableAPI执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//2.读取端口数据转换为JavaBean
SingleOutputStreamOperator<SensorReading> sensorDS = env.socketTextStream("hadoop102", 9999)
.map(line -> {
String[] fields = line.split(",");
return new SensorReading(fields[0],
Long.parseLong(fields[1]),
Double.parseDouble(fields[2]));
})
//这里watermark,我们使用自动增加的类型。
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<SensorReading>() {
@Override
public long extractAscendingTimestamp(SensorReading element) {
return element.getTs();
}
});
//3.将流转换为表并指定处理时间字段
Table table = tableEnv.fromDataStream(sensorDS, "id,ts,temp,rt.rowtime");
//4.TableAPI
Table tableResult = table.window(Over.partitionBy("id").orderBy("rt").as("ow"))
.select("id,id.count over ow");
//5.SQL
tableEnv.createTemporaryView("sensor", table); //常规注意,这里的数据来源只能是上面的table,因为上面的流中没有rt那个字段。
Table sqlResult = tableEnv.sqlQuery("select id,count(id) over(partition by id order by rt) ct " +
"from sensor");
//6.转换为流进行打印输出
tableEnv.toAppendStream(tableResult, Row.class).print("Table");
tableEnv.toAppendStream(sqlResult, Row.class).print("SQL");
//7.执行
env.execute();
}
}
需要注意的是:
我们用的是自增的watermark,源码里面是给事件事件减去了1ms,用来防止相同的数据过来的时候,第一相同数据就把窗口关闭了,以后的相同的数据无法进行计算。
相同的时间戳的数据放在一个窗口里面。
比如说数据是1、2、2、3、4,这些数据过来的时候。


EventTime类型,只看watermark,不看key。watermark推动事件的进展