扩散模型 DDPM 核心代码梳理
参考内容:
大白话AI | 图像生成模型DDPM | 扩散模型 | 生成模型 | 概率扩散去噪生成模型
AIGC 基础,从VAE到DDPM 原理、代码详解
全网最简单的扩散模型DDPM教程
The Annotated Diffusion Model
How does Stable Diffusion work?
LaTeX公式编辑器
pytorch-beginner
强烈推荐:
- 大白话AI | 图像生成模型DDPM | 扩散模型 | 生成模型 | 概率扩散去噪生成模型,特别透彻的讲清楚了前向扩散和反向去噪的公式推导
- pytorch-beginner代码仓库,里面包含了AE、VAE的pytorch代码实现
- AIGC 基础,从VAE到DDPM 原理、代码详解知乎文章,其中包含了详细完整的公式推导,并且用tensorflow框架实现了AE、VAE、Conditional VAE、DDPM、Conditional DDPM的简化版代码实现
备注: 具体公式的推导请查看参考链接,本文只记录核心步骤的几个核心公式。
什么是扩散模型?
与Normalizing Flows、GAN或VAEs等生成模型一样,它们都将噪声从一些简单分布转换为数据样本。这也是使用神经网络学习从纯噪声开始逐渐去噪进行内容生成的过程。扩散模型主要包括以下两个过程:
- 前向加噪: 前向加噪过程是一个固定的、预定义的过程,通过逐步的往一张真实图像上添加高斯噪声,最终得到一个完全的高斯噪声图像
- 反向去噪: 反向去噪过程通过训练学习一个神经网络模型,模型的输入是一张带有噪声的图像,模型的输出是预测得到的噪声,逐步减去预测的噪声,最终得到一张真实的图像
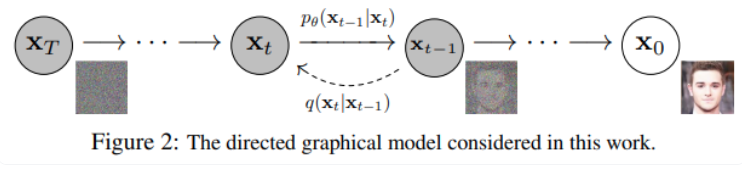
加噪、去噪、训练、推理阶段相关的数学公式
- 前向加噪
在前向加噪过程中,逐步的往真实图片上添加高斯噪声,每一步添加高斯噪声的公式表示如下:
x
t
=
1
−
β
t
x
t
−
1
+
β
t
ϵ
t
\begin{equation}x_{t} = \sqrt{1-\beta_{t}}x_{t-1} + \sqrt{\beta_{t}}\epsilon_{t}\end{equation}
xt=1−βtxt−1+βtϵt
其中,
0
<
β
1
<
β
2
<
⋯
<
β
T
<
1
0 < \beta_{1} < \beta_{2} < \dots < \beta_{T} < 1
0<β1<β2<⋯<βT<1,
ϵ
∼
N
(
0
,
1
)
\epsilon \sim N(0,1)
ϵ∼N(0,1),
β
t
\beta_{t}
βt的取值可以想神经网络的学习率衰减那样,使用线性的、余弦变化的。由于正态分布的均值和方差具有可加性,从[1, T]时刻逐步添加噪声的过程可以通过一步得到:
x
t
=
α
t
ˉ
x
0
+
1
−
α
t
ˉ
ϵ
\begin{equation}x_{t} = \sqrt{\bar{\alpha_{t}}}x_{0} + \sqrt{1 - \bar{\alpha_{t}}}\epsilon\end{equation}
xt=αtˉx0+1−αtˉϵ
其中,
α
t
=
1
−
β
t
\alpha_{t} = 1 - \beta_{t}
αt=1−βt,
α
t
ˉ
=
α
t
α
t
−
1
…
α
1
\bar{\alpha_{t}} = \alpha_{t}\alpha_{t-1}\dots\alpha_{1}
αtˉ=αtαt−1…α1。
- 模型训练
在模型训练阶段,对于一个真实的图像数据,随机生成[1, T]之前的整数,表示往真实图片数据中添加噪声的次数,然后将添加噪声后的图片输入到神经网络模型中,预测添加的噪声,基于神经网络预测的噪声和真实添加的噪声,计算损失:
L
o
s
s
=
∣
∣
ϵ
−
ϵ
θ
(
α
t
ˉ
x
0
+
1
−
α
t
ˉ
∗
ϵ
,
t
)
∣
∣
2
\begin{equation}Loss = ||\epsilon -\epsilon_{\theta}(\sqrt{\bar{\alpha_{t}}}x_{0} + \sqrt{1 - \bar{\alpha_{t}}}*\epsilon, t)||^{2}\end{equation}
Loss=∣∣ϵ−ϵθ(αtˉx0+1−αtˉ∗ϵ,t)∣∣2
其中,
ϵ
\epsilon
ϵ表示在前向加噪过程中,使用公式(2)往真实图片中添加的随机噪声,
ϵ
θ
\epsilon_{\theta}
ϵθ表示一个神经网络模型,输入一个带有噪声的图像,以及对应添加噪声的时间步数,输出预测的噪声,
x
0
x_{0}
x0表示原始的真实图像,
t
t
t表示时间步数。

- 反向去噪
在反向去噪过程中,使用神经网络预测输出一个和输入图像一样大小的噪声数据,从输入图像中减去噪声数据,实现去噪。
x
t
−
1
=
1
α
t
(
x
t
−
β
t
β
t
ˉ
∗
ϵ
θ
(
x
t
,
t
)
)
+
δ
t
∗
z
\begin{equation}x_{t-1} = \frac{1}{\sqrt{\alpha_{t}}}(x_{t} - \frac{\beta_{t}}{\sqrt{\bar{\beta_{t}}}}*\epsilon _{\theta }(x_{t},t)) + \delta_{t}*z\end{equation}
xt−1=αt1(xt−βtˉβt∗ϵθ(xt,t))+δt∗z
其中,
ϵ
θ
\epsilon _{\theta}
ϵθ是一个神经网络模型,
ϵ
θ
(
x
t
,
t
)
\epsilon _{\theta }(x_{t},t)
ϵθ(xt,t)是神经网络模型预测输出的噪声,
β
t
ˉ
=
1
−
α
t
ˉ
\bar{\beta_{t}} = 1 - \bar{\alpha_{t}}
βtˉ=1−αtˉ。
- 模型推理
在模型推理阶段,也就是模型训练完之后进行图像的生成阶段,设置好迭代生成的时间步数
t
t
t,通过一个随机噪声
x
t
x_{t}
xt,不断执行下面的步骤,直到公式(5)中的
t
=
1
t = 1
t=1,实现图像的生成:
x
t
−
1
=
1
α
t
(
x
t
−
β
t
β
t
ˉ
∗
ϵ
θ
(
x
t
,
t
)
)
+
δ
t
∗
z
\begin{equation}x_{t-1} = \frac{1}{\sqrt{\alpha_{t}}}(x_{t} - \frac{\beta_{t}}{\sqrt{\bar{\beta_{t}}}}*\epsilon _{\theta }(x_{t},t)) + \delta_{t}*z\end{equation}
xt−1=αt1(xt−βtˉβt∗ϵθ(xt,t))+δt∗z
x
t
=
x
t
−
1
\begin{equation}x_{t} = x_{t-1}\end{equation}
xt=xt−1
t
=
t
−
1
\begin{equation}t = t-1\end{equation}
t=t−1
当公式(5)中的
t
=
1
t = 1
t=1时,也就是最后一轮去噪,不加
δ
t
∗
z
\delta_{t}*z
δt∗z,最后得到的
x
0
x_{0}
x0就是生成的图像内容。

UNet网络结构
UNet神经网络在特定的时间步
t
t
t 接收噪声图像并返回预测的噪声。预测的噪声是一个与输入图像具有相同的大小/分辨率的张量。从技术上讲,网络输入和输出相同形状的张量。在DDPM中采用UNet架构的神经网络,UNet网络中主要包括以下部分:
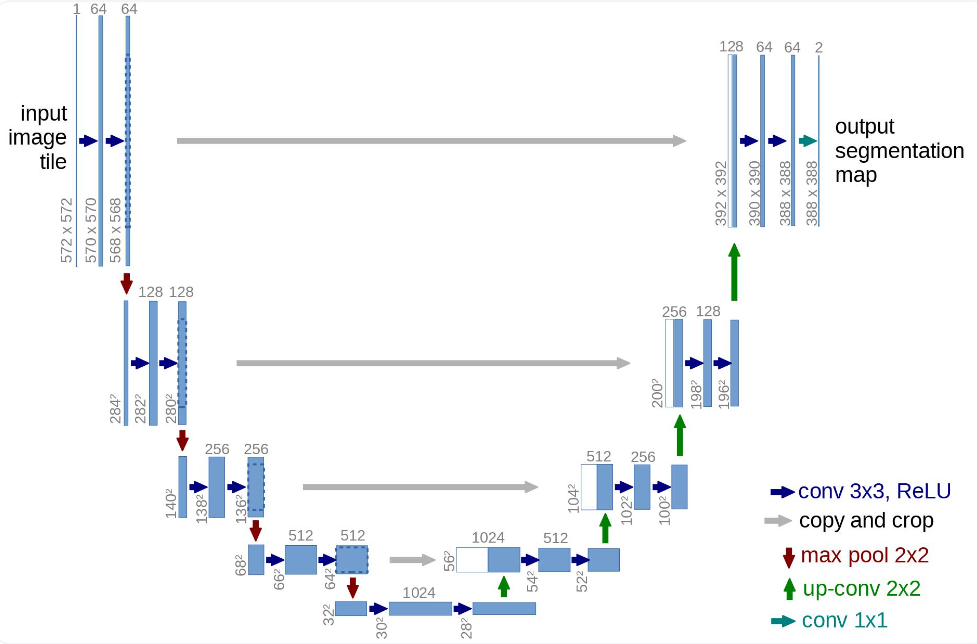
- 下采样:使用卷积 + 池化的方式实现图像分辨率的下采样
- 上采样:使用转置卷积或者线性插值的方式,提升特征图的分辨率
- Short-cut连接:将下采样和上采样得到的分辨率相同额特征图在通道维度上进行融合,有利于捕捉细粒度的图像特征
- 注意力机制:使用注意力机制计算特征图上每个位置之间的注意力关系
- time-embedding:由于DDPM是逐步生成图像的,所以需要一个特征能够标记当前执行到哪个时间步了
DDPM核心代码解释
- 基础代码:构造 α , β , α ˉ , β ˉ \alpha,\beta,\bar{\alpha},\bar{\beta} α,β,αˉ,βˉ等参数
- 使用不同的策略构建 β \beta β 序列
def linear_beta_schedule(timesteps):
"""
在0.0001到0.02之间,均匀采样timesteps个数值,构造成beta序列
"""
beta_start = 0.0001
beta_end = 0.02
return torch.linspace(beta_start, beta_end, timesteps)
def cosine_beta_schedule(timesteps, s=0.008):
"""
cosine schedule as proposed in https://arxiv.org/abs/2102.09672
"""
steps = timesteps + 1
x = torch.linspace(0, timesteps, steps)
alphas_cumprod = torch.cos(((x / timesteps) + s) / (1 + s) * torch.pi * 0.5) ** 2
alphas_cumprod = alphas_cumprod / alphas_cumprod[0]
betas = 1 - (alphas_cumprod[1:] / alphas_cumprod[:-1])
return torch.clip(betas, 0.0001, 0.9999)
def quadratic_beta_schedule(timesteps):
beta_start = 0.0001
beta_end = 0.02
return torch.linspace(beta_start**0.5, beta_end**0.5, timesteps) ** 2
def sigmoid_beta_schedule(timesteps):
beta_start = 0.0001
beta_end = 0.02
betas = torch.linspace(-6, 6, timesteps)
return torch.sigmoid(betas) * (beta_end - beta_start) + beta_start
- 根据生成的 β \beta β 序列,生成 α , α ˉ , β ˉ \alpha,\bar{\alpha},\bar{\beta} α,αˉ,βˉ等, α , β , α ˉ , β ˉ \alpha,\beta,\bar{\alpha},\bar{\beta} α,β,αˉ,βˉ等参数的序列长度对于最大的迭代步长timesteps
timesteps = 300
# define beta schedule
betas = linear_beta_schedule(timesteps=timesteps)
# define alphas
alphas = 1. - betas
alphas_cumprod = torch.cumprod(alphas, axis=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
sqrt_recip_alphas = torch.sqrt(1.0 / alphas)
# calculations for diffusion q(x_t | x_{t-1}) and others
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - alphas_cumprod)
# calculations for posterior q(x_{t-1} | x_t, x_0)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)
- 备注:
- betas对应 β \beta β
- alphas对应 α = 1 − β \alpha = 1 - \beta α=1−β
- alphas_cumprod对应 α ˉ \bar{\alpha} αˉ
- sqrt_recip_alphas对应 1 α \frac{1}{\sqrt{\alpha}} α1
- sqrt_alphas_cumprod对应 1 α ˉ \frac{1}{\sqrt{\bar{\alpha}}} αˉ1
- sqrt_one_minus_alphas_cumprod对应 1 − α ˉ \sqrt{1 - \bar{\alpha}} 1−αˉ
- 在训练阶段对于batch中的每个样本,加噪的迭代次数是从[0, T]中进行随机采样的,所以训练阶段每个样本的加噪次数 t ∈ [ 0 , T ] t \in [0, T] t∈[0,T] 是不同的,使用gather函数获取到每个样本的t对应的 α , β , α ˉ , β ˉ \alpha,\beta,\bar{\alpha},\bar{\beta} α,β,αˉ,βˉ等参数,对应的代码如下:
def extract(a, t, x_shape):
batch_size = t.shape[0]
out = a.gather(-1, t.cpu())
return out.reshape(batch_size, *((1,) * (len(x_shape) - 1))).to(t.device)
- 前向加噪:根据上一步计算得到的 α , β , α ˉ , β ˉ \alpha,\beta,\bar{\alpha},\bar{\beta} α,β,αˉ,βˉ等参数,将一张真实图像 x 0 x_{0} x0 使用公式(2)进行多次加噪,得到加噪后的图像,对应代码如下:
def q_sample(x_start, t, noise=None):
if noise is None:
noise = torch.randn_like(x_start)
# x_start就是前面讲的最原始图像 x_0,根据 t 获取到对应的alpha,beta等参数
sqrt_alphas_cumprod_t = extract(sqrt_alphas_cumprod, t, x_start.shape)
sqrt_one_minus_alphas_cumprod_t = extract(
sqrt_one_minus_alphas_cumprod, t, x_start.shape
)
# 使用公式(2)对图像进行前向加噪
return sqrt_alphas_cumprod_t * x_start + sqrt_one_minus_alphas_cumprod_t * noise
- UNet模型:将加噪后的样本以及每个样本对应的加噪次数 t 输入到UNet网络模型中,UNet模型预测输出加入的噪声,将UNet的输出结果与加入到图像中的噪声使用公式(3)计算损失,训练UNet网络模型。
def p_losses(denoise_model, x_start, t, noise=None, loss_type="l1"):
if noise is None:
noise = torch.randn_like(x_start)
# x_start就是前面讲的最原始图像 x_0,这一步就是往 x_0 中加入t次的噪声
x_noisy = q_sample(x_start=x_start, t=t, noise=noise)
# 将加入噪声的图像以及对应的时间步数 t 输入到UNet模型
predicted_noise = denoise_model(x_noisy, t)
# 将UNet预测的结果与加入的噪声计算损失
if loss_type == 'l1':
loss = F.l1_loss(noise, predicted_noise)
elif loss_type == 'l2':
loss = F.mse_loss(noise, predicted_noise)
elif loss_type == "huber":
loss = F.smooth_l1_loss(noise, predicted_noise)
else:
raise NotImplementedError()
return loss
- 模型推理:当训练完UNet之后,在模型推理也就是图像生成阶段执行反向去噪过程。首先生成一张纯噪声的图像,初始时间步设置为timesteps,将噪声图像和时间步数值 t 输入到UNet模型中,预测得到输出结果,然后使用公式(4)计算得到经过去噪之后 t-1时间步的输出,如此迭代,直到 t=0为止。
def p_sample(model, x, t, t_index):
betas_t = extract(betas, t, x.shape)
sqrt_one_minus_alphas_cumprod_t = extract(
sqrt_one_minus_alphas_cumprod, t, x.shape
)
sqrt_recip_alphas_t = extract(sqrt_recip_alphas, t, x.shape)
# Equation 11 in the paper
# Use our model (noise predictor) to predict the mean
model_mean = sqrt_recip_alphas_t * (
x - betas_t * model(x, t) / sqrt_one_minus_alphas_cumprod_t
)
if t_index == 0:
return model_mean
else:
posterior_variance_t = extract(posterior_variance, t, x.shape)
noise = torch.randn_like(x)
# Algorithm 2 line 4:
return model_mean + torch.sqrt(posterior_variance_t) * noise
# Algorithm 2 (including returning all images)
def p_sample_loop(model, shape):
device = next(model.parameters()).device
b = shape[0]
# start from pure noise (for each example in the batch)
img = torch.randn(shape, device=device)
imgs = []
for i in tqdm(reversed(range(0, timesteps)), desc='sampling loop time step', total=timesteps):
img = p_sample(model, img, torch.full((b,), i, device=device, dtype=torch.long), i)
imgs.append(img.cpu().numpy())
return imgs
def sample(model, image_size, batch_size=16, channels=3):
return p_sample_loop(model, shape=(batch_size, channels, image_size, image_size))
注意事项:
- torch.randn生成符合标准正态分布的数据,torch.rand生成符合0-1之间均匀分布的数据
- UNet有利于细粒度的图像生成
- DDPM简化版完整代码
下面的代码主要来自于AIGC 基础,从VAE到DDPM 原理、代码详解中的第五节,在原文中作者详细推理了DDPM的各个公式,并用tensorflow实现了简化版的DDPM代码,基于此版本的代码使用pytorch框架进行了重写:
import torch
from torch import nn
from torch.nn import functional as F
# import tensorflow as tf
import numpy as np
from einops import reduce
from torchvision.io import read_image
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torch import optim
import os
from torchvision.utils import save_image
from torch.nn import DataParallel
from einops import rearrange
from transformers import get_cosine_schedule_with_warmup
from functools import partial
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
class ConvResidualLayer(nn.Module):
"""
UNet网络中的残差模块
"""
def __init__(self, filter_num, is_encoder=False, is_decoder=False, is_shortcut=False):
super(ConvResidualLayer, self).__init__()
in_channels = filter_num
out_channels = filter_num
# UNet的Encoder下采样阶段
if is_encoder:
if filter_num == 128:
self.conv1 = nn.Conv2d(filter_num, filter_num, kernel_size=1)
self.gn1 = nn.GroupNorm(num_groups=8, num_channels=filter_num)
in_channels = filter_num
out_channels = filter_num
else:
self.conv1 = nn.Conv2d(filter_num // 2, filter_num, kernel_size=1)
self.gn1 = nn.GroupNorm(num_groups=8, num_channels=filter_num)
in_channels = filter_num
out_channels = filter_num
# UNet的Decoder的上采样阶段
if is_decoder:
if filter_num == 128:
self.conv1 = nn.Conv2d(filter_num * 2, filter_num, kernel_size=1)
self.gn1 = nn.GroupNorm(num_groups=8, num_channels=filter_num)
in_channels = filter_num
out_channels = filter_num
else:
self.conv1 = nn.Conv2d(filter_num * 2, filter_num // 2, kernel_size=1)
self.gn1 = nn.GroupNorm(num_groups=8, num_channels=filter_num // 2)
in_channels = filter_num // 2
out_channels = filter_num // 2
if is_shortcut:
self.conv1 = nn.Conv2d(filter_num, filter_num, kernel_size=1)
self.gn1 = nn.GroupNorm(num_groups=8, num_channels=filter_num)
in_channels = filter_num
out_channels = filter_num
self.act1 = nn.SiLU()
self.conv2 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.gn2 = nn.GroupNorm(num_groups=8, num_channels=out_channels)
self.act2 = nn.SiLU()
def forward(self, inputs):
residual = self.conv1(inputs)
x = self.gn1(residual)
x = self.act1(x)
x = self.conv2(x)
x = self.gn2(x)
x = self.act2(x)
# print("x.shape: {}, residual.shape: {}".format(x.shape, residual.shape))
out = x + residual
return out / 1.44
class SimpleDDPMModel(nn.Module):
def __init__(self, max_time_step=100, device=None):
super(SimpleDDPMModel, self).__init__()
self.max_time_step = max_time_step
self.device = device
betas = np.linspace(1e-4, 0.02, self.max_time_step, dtype=np.float64)
alphas = 1.0 - betas
alphas_bar = np.cumprod(alphas, axis=0)
betas_bar = 1.0 - alphas_bar
alphas_bar_prev = F.pad(torch.from_numpy(alphas_bar[:-1]), (1, 0), value=1.0).detach().cpu().numpy()
self.betas, self.alphas, self.alphas_bar, self.betas_bar, self.alphas_bar_prev = tuple(
map(
lambda x: torch.tensor(x, dtype=torch.float32, device=self.device, requires_grad=False),
[betas, alphas, alphas_bar, betas_bar, alphas_bar_prev]
)
)
# filter_nums = [64, 128, 256]
filter_nums = [128, 256, 512]
self.encoders = [
nn.Sequential(
ConvResidualLayer(filter_num, is_encoder=True),
nn.MaxPool2d(2)
).to(self.device)
for filter_num in filter_nums]
self.mid_conv = ConvResidualLayer(filter_nums[-1], is_shortcut=True).to(self.device)
self.decoders = [
nn.Sequential(
nn.Upsample(scale_factor=2),
ConvResidualLayer(filter_num, is_decoder=True),
# ConvResidualLayer(filter_num)
).to(self.device)
for filter_num in reversed(filter_nums)]
self.first_conv = nn.Conv2d(1, filter_nums[0], kernel_size=3, padding=1).to(self.device)
self.final_conv = nn.Sequential(
ConvResidualLayer(filter_nums[0] * 2, is_shortcut=True),
nn.Conv2d(filter_nums[0] * 2, 1, kernel_size=3, padding=1),
).to(self.device)
self.img_size = 32
self.time_embeddings = [nn.Embedding(self.max_time_step, max(filter_nums[0], filter_num // 2)).to(self.device) for filter_num in filter_nums]
def q_noisy_sample(self, x_0, t, noisy):
"""
图像加噪
:param x_0:
:param t:
:param noisy:
:return:
"""
alpha_bar, beta_bar = self.extract([self.alphas_bar, self.betas_bar], t)
sqrt_alpha_bar, sqrt_beta_bar = torch.sqrt(alpha_bar), torch.sqrt(beta_bar)
return sqrt_alpha_bar * x_0 + sqrt_beta_bar * noisy
def extract(self, sources, t):
"""
提取不同时间步对应的alpha、beta等参数
:param sources:
:param t:
:return:
"""
bs = t.shape[0]
targets = [torch.gather(source, index=t[:, 0], dim=0) for i, source in enumerate(sources)]
return tuple(map(lambda x: torch.reshape(x, [bs, 1, 1, 1]), targets))
def p_real_sample(self, x_t, t, pred_noisy):
"""
从x_t经过一步去噪得到x_t-1
:param x_t:
:param t:
:param pred_noisy:
:return:
"""
alpha, beta, alpha_bar, beta_bar, alpha_bar_prev = self.extract([
self.alphas, self.betas, self.alphas_bar, self.betas_bar, self.alphas_bar_prev], t)
noisy = torch.randn_like(x_t)
# noisy_weight = torch.sqrt(beta)
noisy_weight = beta * (1. - alpha_bar_prev) / (1. - alpha_bar)
bs = x_t.shape[0]
noisy_mask = torch.reshape(
1 - (t == 0).float(), [bs, 1, 1, 1]
)
noisy_weight *= noisy_mask
x_t_1 = (x_t - beta * pred_noisy / torch.sqrt(beta_bar)) / torch.sqrt(alpha) + noisy * noisy_weight
return x_t_1
def encoder(self, noisy_img, t, labels=None, training=False, mask_ratio=1.0):
"""
UNet的Encoder下采样
:param noisy_img:
:param t:
:param labels:
:param training:
:param mask_ratio:
:return:
"""
xs = []
for idx, conv in enumerate(self.encoders):
# print(conv)
time_embedding = self.time_embeddings[idx](t)
# print("idx: {}, time_emd.shape: {}, t: {}".format(idx, time_embedding.shape, t))
time_embedding = torch.reshape(time_embedding, [-1, time_embedding.shape[-1], 1, 1])
# print("idx: {}, noisy.shape: {}, time_emd.shape: {}".format(idx, noisy_img.shape, time_embedding.shape))
noisy_img += time_embedding
noisy_img = conv(noisy_img)
xs.append(noisy_img)
return xs
def decoder(self, noisy_img, xs, t):
"""
UNet的Decoder上采样
:param noisy_img:
:param xs:
:param t:
:return:
"""
xs.reverse()
for idx, conv in enumerate(self.decoders):
# print("xs: {}, noisy: {}".format(xs[idx].shape, noisy_img.shape))
# 上采样的过程中包含UNet之前的横向连接
noisy_img = conv(torch.concat([xs[idx], noisy_img], dim=1))
time_embedding = self.time_embeddings[len(self.decoders) - idx - 1](t)
time_embedding = torch.reshape(time_embedding, [-1, time_embedding.shape[-1], 1, 1])
noisy_img += time_embedding
return noisy_img
def pred_noisy(self, data, training=False, labels=None, mask_ratio=1.0):
"""
预测噪声
:param data:
:param training:
:param labels:
:param mask_ratio:
:return:
"""
img = data["img_data"]
bs = img.shape[0]
noisy = torch.randn_like(img, device=self.device)
t = data.get("t", None)
if t is None:
t = torch.randint(0, self.max_time_step, (bs, 1), device=self.device).long()
noisy_img = self.q_noisy_sample(img, t, noisy)
else:
noisy_img = img
noisy_img = self.first_conv(noisy_img)
r = noisy_img.clone()
xs = self.encoder(noisy_img, t.to(self.device), labels=labels, training=training, mask_ratio=mask_ratio)
# print("xs length: {}, xs.shape: {}".format(len(xs), xs[-1].shape))
x = self.mid_conv(xs[-1])
x = self.decoder(x, xs, t.to(self.device))
x = torch.concat([x, r], dim=1)
pred_noisy = self.final_conv(x)
return noisy, pred_noisy
def forward(self, data):
noisy, pred_noisy = self.pred_noisy(data, training=True, labels=data["labels"], mask_ratio=0.15)
return noisy, pred_noisy
def generate(self, bs=128, labels=None):
"""
从随机噪声经过逐步去噪生成图像
:param bs:
:param labels:
:return:
"""
img_list = []
x_t = torch.randn([bs, 1, self.img_size, self.img_size], device=self.device)
for i in reversed(range(0, self.max_time_step)):
t = torch.reshape(torch.tensor(i, device=self.device).repeat(bs), [bs, 1])
# print("t shape: {}".format(t.shape))
_, pred_noisy = self.pred_noisy({"img_data": x_t, "t": t}, labels=labels, training=False)
x_t = self.p_real_sample(x_t, t, pred_noisy)
img_list.append(x_t)
return x_t, img_list
def to_img(x):
x = x.clamp(0, 255)
x = x.view(x.size(0), 1, 32, 32)
# print(x.shape, x.dtype)
return x
if __name__ == '__main__':
device = torch.device("cuda:0")
model = SimpleDDPMModel(device=device, max_time_step=300)
model.to(device)
num_epochs = 100
batch_size = 256
learning_rate = 1e-3
image_size = 32
img_transform = transforms.Compose([
transforms.Resize(image_size), # [0, 255]
transforms.ToTensor(), # [0, 1]
transforms.Lambda(lambda t: (t * 2) - 1) # [-1, 1]
])
reverse_transform = transforms.Compose([
# transforms.Lambda(lambda t: t.clamp(-1, 1)),
transforms.Lambda(lambda t: (t + 1) / 2),
transforms.Lambda(lambda t: t * 255),
])
dataset = MNIST('../../datasets', transform=img_transform, download=True)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# loss_function = nn.MSELoss(reduction="mean")
loss_function = nn.SmoothL1Loss(reduction="mean")
lr_scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=50,
num_training_steps=len(dataloader) * num_epochs)
for epoch in range(num_epochs):
model.train()
train_loss = 0
for batch_idx, data in enumerate(dataloader):
img, labels = data
if torch.cuda.is_available():
img = img.cuda()
labels = labels.cuda()
data = {"img_data": img, "labels": labels}
optimizer.zero_grad()
noisy, pred_noisy = model(data)
loss = loss_function(noisy, pred_noisy)
loss.backward()
train_loss += loss.item()
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}, LR: {}'.format(
epoch,
batch_idx * len(img),
len(dataloader.dataset), 100. * batch_idx / len(dataloader),
loss.item() / len(img), optimizer.param_groups[0]["lr"]))
lr_scheduler.step()
print('====> Epoch: {} Average loss: {:.4f}'.format(
epoch, train_loss / len(dataloader.dataset)))
if epoch % 1 == 0:
with torch.no_grad():
model.eval()
gen_img, denoise_img = model.generate(4)
denoise_img = torch.concat(denoise_img, dim=0)
gen_img = (gen_img + 1) * 0.5
denoise_img = (denoise_img + 1) * 0.5
denoise_img = rearrange(denoise_img, "(t b) c h w -> (b t) c h w", b=4)
save_image(gen_img, './ddpm_img/image_gen_{}.png'.format(epoch))
save_image(denoise_img, './ddpm_img/image_denoise_{}.png'.format(epoch), nrow=30)
torch.save(model.state_dict(), 'ddpm.pth')
上述简易代码在MNIST数据集上训练,生成的图像效果如下:

Conditional DDPM带有条件的图像生成
在DDPM的基础上,为了能够生成类别可控的图像,在训练阶段,在UNet的下采样和上采样过程中,添加能够表示当前样本所属类别的特征,使得模型能够学习到当输入对应的特征时就生成对应类别的图像。在上述DDPM代码的基础上主要添加了以下步骤:
- 像添加time_embedding一样,为每个类别生成一个可学习的embedding添加到网络模型中,因为UNet网络是层级结构的,每一层及的特征大小不一样,所以结合UNet的结构,分别在每一层级都添加可学习的表示每个类别的embedding。
self.conditional_embeddings = [nn.Embedding(10, max(filter_nums[0], filter_num // 2)).to(self.device) for filter_num in filter_nums]
- 在UNet的Encoder阶段的每个层级上,添加表示训练图像所属类别的特征。
def encoder(self, noisy_img, t, labels=None, training=False, mask=0.0):
xs = []
for idx, conv in enumerate(self.encoders):
# print(conv)
time_embedding = self.time_embeddings[idx](t)
# print("idx: {}, time_emd.shape: {}, t: {}".format(idx, time_embedding.shape, t))
time_embedding = torch.reshape(time_embedding, [-1, time_embedding.shape[-1], 1, 1])
# print("idx: {}, noisy.shape: {}, time_emd.shape: {}".format(idx, noisy_img.shape, time_embedding.shape))
noisy_img += time_embedding
conditional_embedding = self.conditional_embeddings[idx](labels)
conditional_embedding = torch.reshape(conditional_embedding, [-1, conditional_embedding.shape[-1], 1, 1])
if training:
# 参照BERT随机掩码的方式,这里选择随机添加类别特征
if mask < 0.15:
conditional_embedding = torch.zeros_like(conditional_embedding)
noisy_img += conditional_embedding
noisy_img = conv(noisy_img)
xs.append(noisy_img)
return xs
- 在UNet的Decoder阶段的每个层级上,添加表示训练图像所属类别的特征。
def decoder(self, noisy_img, xs, t, labels=None, training=False, mask=0.0):
xs.reverse()
for idx, conv in enumerate(self.decoders):
# print("xs: {}, noisy: {}".format(xs[idx].shape, noisy_img.shape))
noisy_img = conv(torch.concat([xs[idx], noisy_img], dim=1))
time_embedding = self.time_embeddings[len(self.decoders) - idx - 1](t)
time_embedding = torch.reshape(time_embedding, [-1, time_embedding.shape[-1], 1, 1])
noisy_img += time_embedding
conditional_embedding = self.conditional_embeddings[len(self.decoders) - idx - 1](labels)
conditional_embedding = torch.reshape(conditional_embedding, [-1, conditional_embedding.shape[-1], 1, 1])
if training:
if mask < 0.15:
conditional_embedding = torch.zeros_like(conditional_embedding)
noisy_img += conditional_embedding
return noisy_img
- 完整的Conditional DDPM的代码如下:
import torch
from torch import nn
from torch.nn import functional as F
import numpy as np
from einops import reduce
from torchvision.io import read_image
from torchvision import transforms
from torchvision.datasets import MNIST
from torch.utils.data import DataLoader
from torch import optim
import os
from torchvision.utils import save_image
from torch.nn import DataParallel
from einops import rearrange
from transformers import get_cosine_schedule_with_warmup
from functools import partial
os.environ["CUDA_VISIBLE_DEVICES"] = "3"
class ConvResidualLayer(nn.Module):
def __init__(self, filter_num, is_encoder=False, is_decoder=False, is_shortcut=False):
super(ConvResidualLayer, self).__init__()
in_channels = filter_num
out_channels = filter_num
if is_encoder:
if filter_num == 128:
self.conv1 = nn.Conv2d(filter_num, filter_num, kernel_size=1)
self.gn1 = nn.GroupNorm(num_groups=8, num_channels=filter_num)
in_channels = filter_num
out_channels = filter_num
else:
self.conv1 = nn.Conv2d(filter_num // 2, filter_num, kernel_size=1)
self.gn1 = nn.GroupNorm(num_groups=8, num_channels=filter_num)
in_channels = filter_num
out_channels = filter_num
if is_decoder:
if filter_num == 128:
self.conv1 = nn.Conv2d(filter_num * 2, filter_num, kernel_size=1)
self.gn1 = nn.GroupNorm(num_groups=8, num_channels=filter_num)
in_channels = filter_num
out_channels = filter_num
else:
self.conv1 = nn.Conv2d(filter_num * 2, filter_num // 2, kernel_size=1)
self.gn1 = nn.GroupNorm(num_groups=8, num_channels=filter_num // 2)
in_channels = filter_num // 2
out_channels = filter_num // 2
if is_shortcut:
self.conv1 = nn.Conv2d(filter_num, filter_num, kernel_size=1)
self.gn1 = nn.GroupNorm(num_groups=8, num_channels=filter_num)
in_channels = filter_num
out_channels = filter_num
self.act1 = nn.SiLU()
self.conv2 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1)
self.gn2 = nn.GroupNorm(num_groups=8, num_channels=out_channels)
self.act2 = nn.SiLU()
def forward(self, inputs):
residual = self.conv1(inputs)
x = self.gn1(residual)
x = self.act1(x)
x = self.conv2(x)
x = self.gn2(x)
x = self.act2(x)
# print("x.shape: {}, residual.shape: {}".format(x.shape, residual.shape))
out = x + residual
return out / 1.44
class SimpleDDPMModel(nn.Module):
def __init__(self, max_time_step=100, device=None):
super(SimpleDDPMModel, self).__init__()
self.max_time_step = max_time_step
self.device = device
betas = np.linspace(1e-4, 0.02, self.max_time_step, dtype=np.float64)
alphas = 1.0 - betas
alphas_bar = np.cumprod(alphas, axis=0)
betas_bar = 1.0 - alphas_bar
alphas_bar_prev = F.pad(torch.from_numpy(alphas_bar[:-1]), (1, 0), value=1.0).detach().cpu().numpy()
self.betas, self.alphas, self.alphas_bar, self.betas_bar, self.alphas_bar_prev = tuple(
map(
lambda x: torch.tensor(x, dtype=torch.float32, device=self.device, requires_grad=False),
[betas, alphas, alphas_bar, betas_bar, alphas_bar_prev]
)
)
# filter_nums = [64, 128, 256]
filter_nums = [128, 256, 512]
self.encoders = [
nn.Sequential(
ConvResidualLayer(filter_num, is_encoder=True),
nn.MaxPool2d(2)
).to(self.device)
for filter_num in filter_nums]
self.mid_conv = ConvResidualLayer(filter_nums[-1], is_shortcut=True).to(self.device)
self.decoders = [
nn.Sequential(
nn.Upsample(scale_factor=2),
ConvResidualLayer(filter_num, is_decoder=True),
).to(self.device)
for filter_num in reversed(filter_nums)]
self.first_conv = nn.Conv2d(1, filter_nums[0], kernel_size=3, padding=1).to(self.device)
self.final_conv = nn.Sequential(
ConvResidualLayer(filter_nums[0] * 2, is_shortcut=True),
nn.Conv2d(filter_nums[0] * 2, 1, kernel_size=3, padding=1),
).to(self.device)
self.img_size = 32
self.time_embeddings = [nn.Embedding(self.max_time_step, max(filter_nums[0], filter_num // 2)).to(self.device) for filter_num in filter_nums]
self.conditional_embeddings = [nn.Embedding(10, max(filter_nums[0], filter_num // 2)).to(self.device) for filter_num in filter_nums]
# 公式64,图像加噪声
def q_noisy_sample(self, x_0, t, noisy):
alpha_bar, beta_bar = self.extract([self.alphas_bar, self.betas_bar], t)
sqrt_alpha_bar, sqrt_beta_bar = torch.sqrt(alpha_bar), torch.sqrt(beta_bar)
return sqrt_alpha_bar * x_0 + sqrt_beta_bar * noisy
def extract(self, sources, t):
bs = t.shape[0]
targets = [torch.gather(source, index=t[:, 0], dim=0) for i, source in enumerate(sources)]
return tuple(map(lambda x: torch.reshape(x, [bs, 1, 1, 1]), targets))
# 公式131, 计算Loss
def p_real_sample(self, x_t, t, pred_noisy):
alpha, beta, alpha_bar, beta_bar, alpha_bar_prev = self.extract([
self.alphas, self.betas, self.alphas_bar, self.betas_bar, self.alphas_bar_prev], t)
noisy = torch.randn_like(x_t)
# noisy_weight = torch.sqrt(beta)
noisy_weight = beta * (1. - alpha_bar_prev) / (1. - alpha_bar)
bs = x_t.shape[0]
noisy_mask = torch.reshape(
1 - (t == 0).float(), [bs, 1, 1, 1]
)
noisy_weight *= noisy_mask
x_t_1 = (x_t - beta * pred_noisy / torch.sqrt(beta_bar)) / torch.sqrt(alpha) + noisy * noisy_weight
return x_t_1
# unet 下采样
def encoder(self, noisy_img, t, labels=None, training=False, mask=0.0):
xs = []
for idx, conv in enumerate(self.encoders):
# print(conv)
time_embedding = self.time_embeddings[idx](t)
# print("idx: {}, time_emd.shape: {}, t: {}".format(idx, time_embedding.shape, t))
time_embedding = torch.reshape(time_embedding, [-1, time_embedding.shape[-1], 1, 1])
# print("idx: {}, noisy.shape: {}, time_emd.shape: {}".format(idx, noisy_img.shape, time_embedding.shape))
noisy_img += time_embedding
conditional_embedding = self.conditional_embeddings[idx](labels)
conditional_embedding = torch.reshape(conditional_embedding, [-1, conditional_embedding.shape[-1], 1, 1])
if training:
if mask < 0.15:
conditional_embedding = torch.zeros_like(conditional_embedding)
noisy_img += conditional_embedding
noisy_img = conv(noisy_img)
xs.append(noisy_img)
return xs
# unet 上采样
def decoder(self, noisy_img, xs, t, labels=None, training=False, mask=0.0):
xs.reverse()
for idx, conv in enumerate(self.decoders):
# print("xs: {}, noisy: {}".format(xs[idx].shape, noisy_img.shape))
noisy_img = conv(torch.concat([xs[idx], noisy_img], dim=1))
time_embedding = self.time_embeddings[len(self.decoders) - idx - 1](t)
time_embedding = torch.reshape(time_embedding, [-1, time_embedding.shape[-1], 1, 1])
noisy_img += time_embedding
conditional_embedding = self.conditional_embeddings[len(self.decoders) - idx - 1](labels)
conditional_embedding = torch.reshape(conditional_embedding, [-1, conditional_embedding.shape[-1], 1, 1])
if training:
if mask < 0.15:
conditional_embedding = torch.zeros_like(conditional_embedding)
noisy_img += conditional_embedding
return noisy_img
# 预测噪声
def pred_noisy(self, data, training=False, labels=None):
img = data["img_data"]
bs = img.shape[0]
noisy = torch.randn_like(img, device=self.device)
t = data.get("t", None)
if t is None:
t = torch.randint(0, self.max_time_step, (bs, 1), device=self.device).long()
noisy_img = self.q_noisy_sample(img, t, noisy)
else:
noisy_img = img
noisy_img = self.first_conv(noisy_img)
r = noisy_img.clone()
mask = torch.rand((1,)).item()
xs = self.encoder(noisy_img, t.to(self.device), labels=labels, training=training, mask=mask)
# print("xs length: {}, xs.shape: {}".format(len(xs), xs[-1].shape))
x = self.mid_conv(xs[-1])
x = self.decoder(x, xs, t.to(self.device), labels=labels, training=training, mask=mask)
x = torch.concat([x, r], dim=1)
pred_noisy = self.final_conv(x)
return noisy, pred_noisy
def forward(self, data):
noisy, pred_noisy = self.pred_noisy(data, training=True, labels=data["labels"])
return noisy, pred_noisy
# 从随机噪声生成图像
def generate(self, bs=128, labels=None):
img_list = []
x_t = torch.randn([bs, 1, self.img_size, self.img_size], device=self.device)
for i in reversed(range(0, self.max_time_step)):
t = torch.reshape(torch.tensor(i, device=self.device).repeat(bs), [bs, 1])
# print("t shape: {}".format(t.shape))
_, pred_noisy = self.pred_noisy({"img_data": x_t, "t": t}, labels=labels, training=False)
x_t = self.p_real_sample(x_t, t, pred_noisy)
img_list.append(x_t)
return x_t, img_list
def to_img(x):
x = x.clamp(0, 255)
x = x.view(x.size(0), 1, 32, 32)
# print(x.shape, x.dtype)
return x
if __name__ == '__main__':
from matplotlib import pyplot as plt
device = torch.device("cuda:0")
model = SimpleDDPMModel(device=device, max_time_step=300)
model.to(device)
num_epochs = 100
batch_size = 256
learning_rate = 1e-3
image_size = 32
img_transform = transforms.Compose([
transforms.Resize(image_size), # [0, 255]
transforms.ToTensor(), # [0, 1]
transforms.Lambda(lambda t: (t * 2) - 1) # [-1, 1]
])
reverse_transform = transforms.Compose([
# transforms.Lambda(lambda t: t.clamp(-1, 1)),
transforms.Lambda(lambda t: (t + 1) / 2),
transforms.Lambda(lambda t: t * 255),
])
dataset = MNIST('../../datasets', transform=img_transform, download=True)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# loss_function = nn.MSELoss(reduction="mean")
loss_function = nn.SmoothL1Loss(reduction="mean")
lr_scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=50,
num_training_steps=len(dataloader) * num_epochs)
for epoch in range(num_epochs):
model.train()
train_loss = 0
for batch_idx, data in enumerate(dataloader):
img, labels = data
if torch.cuda.is_available():
img = img.cuda()
labels = labels.cuda()
data = {"img_data": img, "labels": labels}
optimizer.zero_grad()
noisy, pred_noisy = model(data)
loss = loss_function(noisy, pred_noisy)
loss.backward()
train_loss += loss.item()
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}, LR: {}'.format(
epoch,
batch_idx * len(img),
len(dataloader.dataset), 100. * batch_idx / len(dataloader),
loss.item() / len(img), optimizer.param_groups[0]["lr"]))
lr_scheduler.step()
print('====> Epoch: {} Average loss: {:.4f}'.format(
epoch, train_loss / len(dataloader.dataset)))
if epoch % 1 == 0:
with torch.no_grad():
labels = []
for i in range(10):
labels.append(i)
labels = torch.tensor(labels, device=device)
model.eval()
gen_img, denoise_img = model.generate(bs=10, labels=labels)
denoise_img = torch.concat(denoise_img, dim=0)
gen_img = (gen_img + 1) * 0.5
denoise_img = (denoise_img + 1) * 0.5
denoise_img = rearrange(denoise_img, "(t b) c h w -> (b t) c h w", b=10)
save_image(gen_img, './conditional_ddpm_img/image_gen_{}.png'.format(epoch))
save_image(denoise_img[::5, ...], './conditional_ddpm_img/image_denoise_{}.png'.format(epoch), nrow=30)
torch.save(model.state_dict(), 'conditional_ddpm.pth')
上述简易代码在MNIST数据集上训练,分别生成从0到9的的图像,效果如下:
