新一代爬取JavaScript渲染页面的利器-playwright(二)
接上文:新一代爬取JavaScript渲染页面的利器-playwright(一)
上文我们主要讲了Playwright的特点、安装、基本使用、代码生成的使用以及模拟移动端浏览,这篇我们主要讲下Playwright的选择器以及常见的操作方法。
6.选择器
我们可以把传入的字符串称为Element Selector,除了它已经支持的CSS选择器、XPath,Playwright还为它拓展了一些方便好用的规则,例如直接根据文本内容筛选,根据节点的层级结构筛选等。
- 文本选择
文本选择支持text=这样的语句进行筛选,例如:
page.click(“text=Log in”)
该句代表点击文本内容是Log in的节点
- CSS选择器
例如根据id/class筛选:
page.click(“button”)
page.click(“nav-bar .contact-us-item”)
根据特定的节点属性进行筛选:
page.click(“[data-test-login-button]”)
page.click(“[aria-label=‘Sign in’]”)
- CSS选择器+文本值
常用的方法是has-text和text,前者代表节点中包含指定的字符串,后者代表节点中的文本值和指定的字符串完全匹配,示例如下:
page.click(“article:has-text(‘playwright’)”)
page.click(“#nav-bar :text(‘Contact us’)”)
- CSS选择器+节点关系
CSS选择器还可以结合文本关系来筛选节点,例如指定另一个选择器,示例如下:
page.click(“.item-description:has(.item-promo-banner)”)
这里选择的就是class为item-description的节点,且该节点还要包含class为item-promo-banner的子节点。
另外还可以结合一些相对位置关系,例如使用right-of指定位于某个节点右侧的节点。
page.click(“input:right-of(:text(‘Username’))”)
这里选择的就是一个input节点,并且该节点要位于Username的节点的右侧。
- XPath
XPath也是支持的,不过是xpath关键字需要我们自己来指定,示例如下:
page.click(“xpath=//button”)
7.常用操作方法
下面介绍些一些常用的操作方法。例如click(点击),fill(输入)等等,这些方法都属于page对象,所有方法都可以从page对象的API文档查找。
下面介绍几个常见的操作方法的用法。
- 事件监听
page对象提供一个on方法,用来监听页面中发生的各个事件,例如close,console,load,request,response等。
这里我们监听response事件,在每次页面请求得到相应的时候会触发这个事件,我们可以设置回调方法来获取响应中的全部信息,示例如下:
from playwright.sync_api import sync_playwright
def on_response(response):
print(f'State{response.status}:{response.url}')
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response',on_response)
page.goto('https://spa6.scrape.center')
page.wait_for_load_state('networkidle')
browser.close()
可以看到输出结果如下;
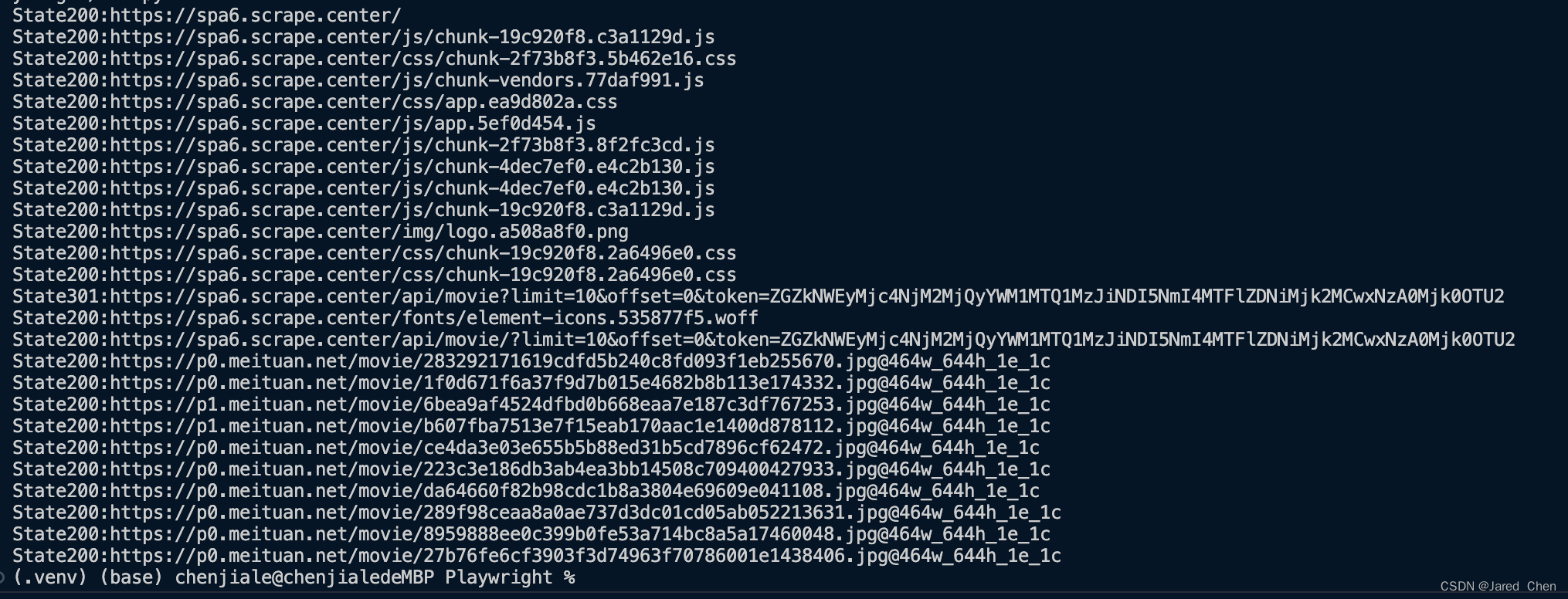
我们在创建page对象后,就开始监听response事件,同时将回调方法设置为on_response,其接收一个参数,然后输出响应中的状态码和链接。
如果观察网页请求包内容可以发现,这个输出结果正好对应浏览器network中所有的请求和响应。
这个网站的真实的数据都是Ajax加载的,同时Ajax请求中还带有加密参数,不容易轻易获取。但是有了on_response方法,如果我们想截取Ajax请求,是非常容易的。
from playwright.sync_api import sync_playwright
def on_response(response):
if '/api/movie' in response.url and response.status == 200:
print(response.json)
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.on('response',on_response)
page.goto('https://spa6.scrape.center')
page.wait_for_load_state('networkidle')
browser.close()
可以看到我们通过on_response方法拦截了Ajax请求,直接拿到了响应结果,即使这个Ajax请求中有加密参数也不用担心,因为这里截获的是最后的请求结果。
- 获取页面源代码
调用page对象的content方法可以获取网页源码。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center')
page.wait_for_load_state('networkidle')
html = page.content()
print(html)
browser.close()
运行结果就是页面源代码,然后可以再利用一些解析工具就可以提取到想要的信息了。
- 页面点击
实现页面点击的方法就是click方法,click方法的API定义如下:
page.click(selector,**kwargs)
其中,必须传入的数据是selector,其他参数都是可选的。selector代表选择器,用来匹配想要点击的节点,如果有多个节点都匹配,只使用第一个。
其他比较重要的参数如下:
-
click_count:点击次数,默认为1.
-
timeout:等待找到要点击节点的超时的时间,默认为30秒。
-
position:需要传入如一个字典,要带有x和y属性,代表点击位置相对节点左上角的偏移量。
-
force:即使按钮设置了不可点击,也要强制点击,默认是False。
-
文本输入
文本输入对应的方法是fill,其API定义如下:
page.fill(selector,value,**kwargs)
第一个selector代表选择器,value代表输入的内容,还可以通过timeout参数查找对应节点的最长等待时间。
- 获取节点属性
除了操作节点本身,我们也可以获得节点的属性,方法是get_attribute。
page.get_attribute(selector,name,**kwargs)
这个有两个必传参数,selector和name,name代表要获取属性的名称。示例如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center')
page.wait_for_load_state('networkidle')
href = page.get_attribute('a.name','href')
print(href)
browser.close()
这里调用了get_attribute方法,传入的selector参数值是a.name,代表查找class为name的a的节点,name的参数传入了href,输出结果如下。
/detail/ZWYzNCN0ZXVxMGJ0dWEjKC01N3cxcTVvNS0takA5OHh5Z2ltbHlmeHMqLSFpLTAtbWIx
这里看到对应节点的href属性只输出了一条,因为如果匹配了多个节点,就只返回第一个。
- 获取多个节点
对于获取所有节点,我们可以使用query_selector_all方法来获取。它会返回节点列表,通过遍历得到单个节点后,可以调用上面介绍的针对单个节点的方法完成一些操作和获取属性。示例如下:
# 获取多个节点
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center')
page.wait_for_load_state('networkidle')
elements = page.query_selector_all('a.name')
for element in elements:
print(element.get_attribute('href'))
print(element.text_content())
browser.close()
这里通过query_selector_all方法获取了所有可以匹配得到的节点,每个节点对应一个ElementHandle对象,然后通过该对象的get_attribute和text_content得到节点的属性和文本。运行结果如下:
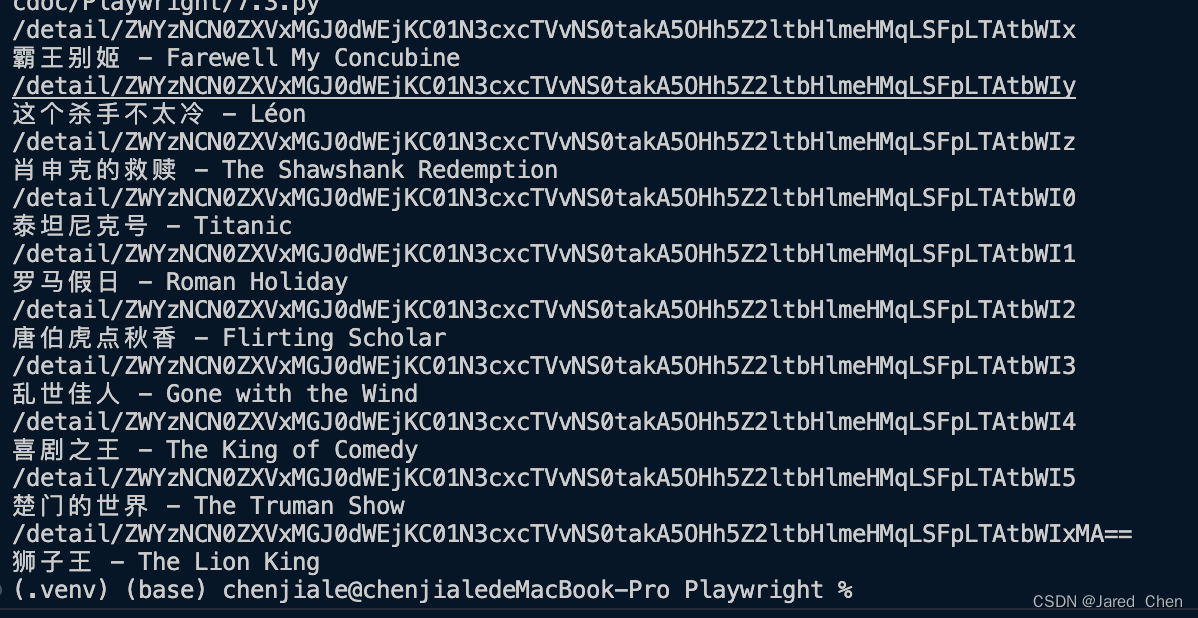
- 获取单个节点
多个节点用query_selector_all,那么单个节点自然就是query_selector,如果匹配到多个节点,那么就只返回第一个。
示例如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto('https://spa6.scrape.center')
page.wait_for_load_state('networkidle')
element = page.query_selector('a.name')
print(element.get_attribute('href'))
print(element.text_content())
browser.close()
运行后可以看到只返回了第一个节点的信息。
- 网络劫持
利用route方法可以实现网络劫持和修改操作,例如修改request的属性,修改响应结果等。
from playwright.sync_api import sync_playwright
import re
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
def cancel_request(route,request):
route.abort()
page.route(re.compile(r"(\.png)|(\.jpg)"),cancel_request)
page.goto('https://spa6.scrape.center')
page.wait_for_load_state('networkidle')
page.screenshot(path='no_picture.png')
browser.close()
这里调用了route方法,第一个参数通过正则表达式传入了URL路径,cancel_request 方法接收两个参数,一个是route,代表CallableRoute对象,另一个是request代表Request对象,这里我们直接调用CallableRoute对象的abort方法,取消了这次请求,导致最终的结果是取消全部图片的加载。结果截图如下图所示:
我们在爬取的过程中只关心的是图片的url,图片是否加载出来并不重要,这样可以提高整个页面的加载速度,提高爬取效率。
另外还可以利用这个功能对一些响应内容进行修改,例如我们可以将相应的结果直接修改为我们自定义的文本内容。
我们先定义一个文本文件,命名demo.html,内容如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Hack Response</title>
</head>
<body>
<h1>Hack Response</h1>
</body>
</html>
代码编写如下:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
def modify_response(route,request):
print(f"Modifying response for {request.url}")
route.fulfill(path = "./demo.html")
page.route('**/*', modify_response)
page.goto('https://spa6.scrape.center')
page.wait_for_load_state('networkidle')
browser.close()
这里我们使用callableRoute对象的fulfill方法指定了一个本地文件。

这时可以看到响应结果已经被修改了,但是URL没有变,我们可以利用route方法,灵活的控制请求和响应的内容,从而在某些场景下达到某些目的。