yolov5 安全帽检测 全流程 全资源 技术交流(相互学习)!!!
yolov5 做安全帽检测示例 (全流程、全资源)

文章目录
前言
在业余时间看了很多关于手把手教你搭建yolov5目标识别框架的博主文章,大多涉及的细节不够多,很多内容一笔带过,不够开源。写这篇技术总结性质的文章,主要是1、尽可能详尽,指导闭坑,完全开源。2、技术交流,取长补短,相互学习。
**项目背景:**用yolov5框架来实时检测安全帽佩戴状态。
数据集的获取及标定:1,直接可以在百度飞浆网站上获取相应的数据集(数据集只有两个标签分类:person和hat(带安全帽的),已经标定好,大约7500张,标定的数据集是json格式的,需要进行转化------txt格式。网上很多数据集只有json格式和图片,有这两个就够了,不要想要什么自行车,本文附带了json格式转化成txt格式的代码。欢迎品尝!!!)
硬件:不建议使用cpu来训练大量数据集,太慢了,想出验证结果或者优化参数,CPU不适合做!!!CPU不适合做!!!CPU不适合做!!!别问为什么,因为我已经试过了。可以在百度飞浆上用免费算力进行训练。但百度飞浆的维护又不太好,兼容性太差。感兴趣可以试试。有条件的,最好自己搭建硬件平台。
一、追根溯源:目标检测框架 yolov5
链接: 这是一位博主写的目标检测算法演变及比较,很不错!!!
二、言归正传:软硬件环境搭建
我的硬件:
处理器 12th Gen Intel® Core™ i9-12900K 3.20 GHz
机带 RAM 32.0 GB (31.8 GB 可用)
设备 ID BEE4439A-3A46-43A3-8657-B9F8873A1A5D
产品 ID 00331-10000-00001-AA112
系统类型 64 位操作系统, 基于 x64 的处理器
显卡:英伟达3060
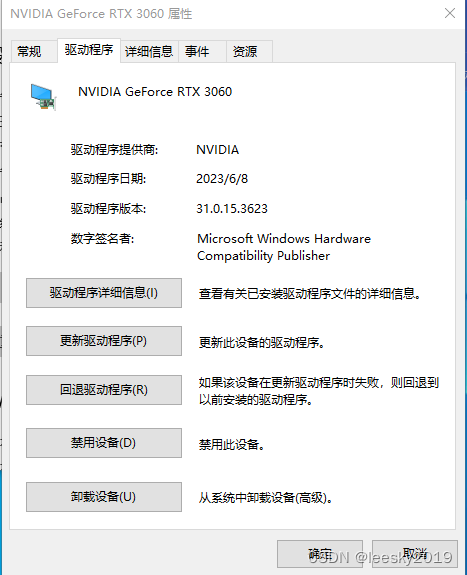
注意程序的版本号!我们使用GPU进行数据集的训练!
软件环境
链接: 软件主要是cuda—cudnn—anaconda—pycharm环境及版本的相互匹配!!!
链接: 快速下载cuda—注意和你的驱动版本匹配
这个链接可以指导你完成cuda—cudnn 的安装。我在这里不详细讲了,很多博主都写了相关文章,很不错。但是!!!!!
他们没有将如何闭坑,示例:
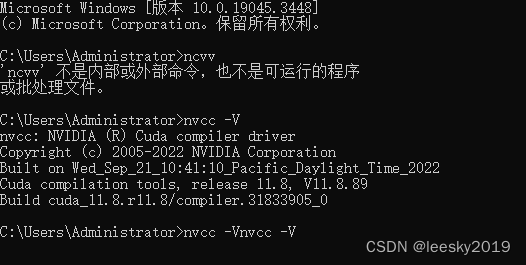
这是cuda的安装好的运行结果。
配置完成后,我们可以验证是否配置成功,主要使用CUDA内置的deviceQuery.exe 和 bandwidthTest.exe:
首先win+R启动cmd,cd到安装目录下的 …\extras\demo_suite,然后分别执行bandwidthTest.exe和deviceQuery.exe(进到目录后需要直接输“bandwidthTest.exe”和“deviceQuery.exe”),得到下图:
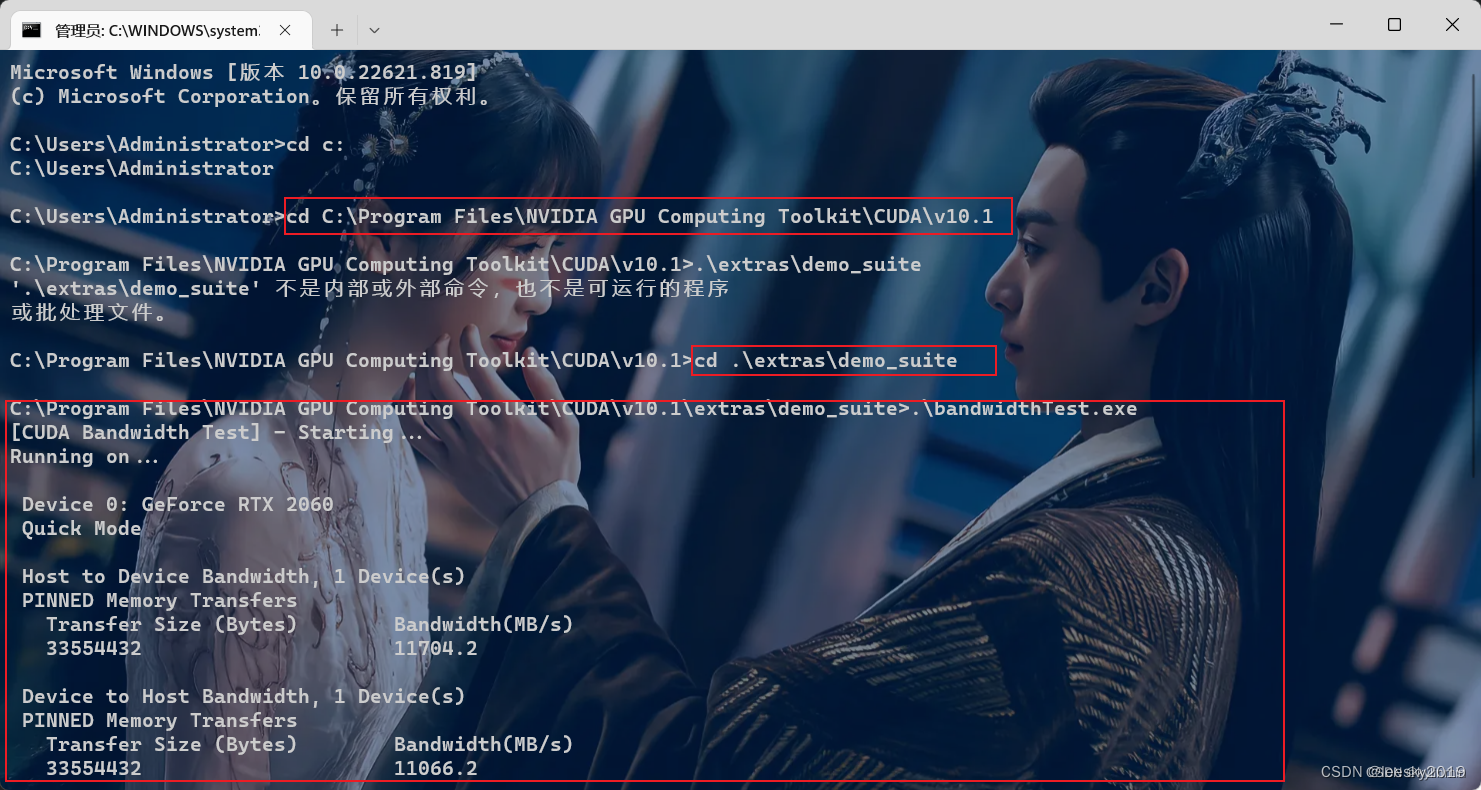 截止到这里,软件环境搭建好了一半,然后安装软件配套环境anaconda和pycharm,他们二者也得搭配起来使用,不然后面涉及到YOLOV5相关环境,很是麻烦,容易出现版本调整,频繁报错的情况。
截止到这里,软件环境搭建好了一半,然后安装软件配套环境anaconda和pycharm,他们二者也得搭配起来使用,不然后面涉及到YOLOV5相关环境,很是麻烦,容易出现版本调整,频繁报错的情况。
我这里的anaconda版本是:
Anaconda3-2023.03-0-Windows-x86_64
pycharm版本是:PyCharm 2021.1.3 x64
**PyCharm 2021.1.3 x64破解方法:安装一个30天无限激活的插件就可以。这个方法很多网站有,不再赘述。**链接: 激活方法
三、闪转腾挪:闭坑关键点
经过上述安装—卸载—安装的过程,基本上都好了,再通过各种渠道下载好yolov5的源码及权重文件,终于可以开始测试代码了。但是,但是,但是!又出现问题了:
https://blog.csdn.net/charlie_C9299/article/details/126092797
**我也出现了类似的情况:原因是在运行yolov5代码时候,它会自动检测系统环境版本是否满足:
YOLOv5 requirements.txt中的环境要求,不满足的话,它会自动下载更新,这个环节就容易反复导致运行时提示你没有GPU设备,或者是提示你插在不到GPU,即使你前面环境搭建过程中没有任何错误。
Usage: pip install -r requirements.txt
torch>=1.7.0
torchvision>=0.8.1
Logging -------------------------------------
tensorboard>=2.4.1
出现这样的情况,多数都是因为torchvision和tensorboard版本更新时候,anaconda中自动把相关的cuda和pytorch版本进行了更新,所以这块我们最好是自己在英伟达官网下载和你自己版本匹配的torchvision和tensorboard,
链接: 可以看看这个文章!

在anaconda的命令行中用pip安装。
其中CU118是你的cuda版本号 注意:torch版本和torchvision都是CU118,三者版本必须一致才可以。保险起见,可以将YOLOv5 requirements.txt中torchvision和tensorboard前面加上#(表示跳过版本检测,不更新下载)。这样的话,基本就避免了AssertionError: Invalid CUDA ‘–device 0,1,2’ requested, use ‘–device cpu’ or pass valid CUDA device(s)错误的发生。
关于其他问题的报错,基本上通过度娘可以快速解决。
示例:AttributeError: module ‘numpy‘ has no attribute ‘int‘. https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/131430993
四、摩拳擦掌:开始训练—验证—检测
数据集的使用
labelme软件使用,这里不做介绍了,自己做数据集很慢,但是专业检测领域的话,必须自己做数据集并进行标注。现在有个职业就是数据标注员,拉框框就可以赚钱那种。
使用现成的数据集,主要得看懂数据集分类情况和标注格式,一般是json格式,你可以打开相应的图片和json,可以发现分类标签名称和个数,------这里只要用于修改.yaml训练参数文件。特别提示:
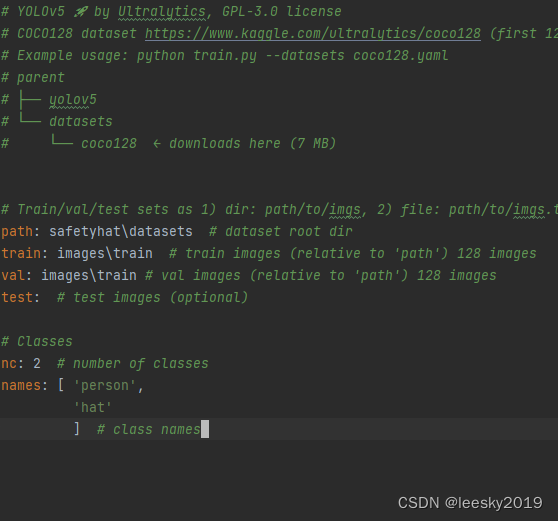
name中person和hat 位置是不能颠倒的,因为:
import os
import xml.etree.ElementTree as ET
# VOC 标签和对应的类别名称
VOC_LABELS = {
'person': 0,
'hat': 1
#可以根据自己的分类增加字典内容,但是需要和yaml文件中name列表一一对应。
}
# VOC 数据集路径
VOC_PATH = 'E:\pythonProject\yolov5_wzry\yolov5\safetyhat\datasets\VOC2028\Annotations'
# YOLO 格式标注文件保存路径
YOLO_PATH = 'E:\pythonProject\yolov5_wzry\yolov5\safetyhat\datasets\VOC2028\Label'
def convert_voc_to_yolo(xml_file):
# 解析 XML 文件
tree = ET.parse(xml_file)
root = tree.getroot()
# 获取图像的宽度和高度
size = root.find('size')
width = int(size.find('width').text)
height = int(size.find('height').text)
# 遍历每一个物体
for obj in root.findall('object'):
# 获取物体的类别和位置信息
label = obj.find('name').text
xmin = int(obj.find('bndbox/xmin').text)
ymin = int(obj.find('bndbox/ymin').text)
xmax = int(obj.find('bndbox/xmax').text)
ymax = int(obj.find('bndbox/ymax').text)
# 将坐标信息转换为 YOLO 格式
x_center = float(xmin + xmax) / 2 / width
y_center = float(ymin + ymax) / 2 / height
w = float(xmax - xmin) / width
h = float(ymax - ymin) / height
# 获取类别的 ID
label_id = VOC_LABELS[label]
# 将标注信息保存到 YOLO 格式的文件中
yolo_file.write(f'{label_id} {x_center} {y_center} {w} {h}\n')
# 遍历 VOC 数据集中的所有 XML 文件
for root, dirs, files in os.walk(VOC_PATH):
for file in files:
if file.endswith('.xml'):
# 打开 YOLO 格式的文件
yolo_filename = os.path.splitext(file)[0] + '.txt'
yolo_file = open(os.path.join(YOLO_PATH, yolo_filename), 'w')
# 转换 XML 文件为 YOLO 格式
xml_file = os.path.join(root, file)
convert_voc_to_yolo(xml_file)
# 关闭 YOLO 格式的文件
yolo_file.close()
# 上述代码中,我们将 VOC_LABELS 字典中的键值对修改为 person: 0 和 bat: 1,然后在 #convert_voc_to_yolo 函数中根据标签名称获取类别 ID。需要注意的是,如果你的数据集中存在其他标签
# 或类别,也需要根据实际情况进行修改。
在上述代码(json转化为txt文件,标签定义的顺是固定的,txt文件中的0代表person,1代表hat。与它对应的name【0,1,2,…】)如果不一一对应就容易出现 张冠李戴的检测结果。训练半天,小细节翻车。
train.py
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5x', help='initial weights path') # 修改处 初始权重
parser.add_argument('--cfg', type=str, default=ROOT /'safetyhat/safetyhat_model.yaml', help='model.yaml path') # 修改处 训练模型文件
parser.add_argument('--data', type=str, default=ROOT /'safetyhat/safetyhat.yaml', help='dataset.yaml path') # 修改处 数据集参数文件
parser.add_argument('--hyp', type=str, default=ROOT / 'data/hyps/hyp.scratch-low.yaml', help='hyperparameters path') # 超参数设置
parser.add_argument('--epochs', type=int, default=100) # 修改处 训练轮数
parser.add_argument('--batch-size', type=int, default=10, help='total batch size for all GPUs, -1 for autobatch') # 修改处 batch size
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=384, help='train, val image size (pixels)')# 修改处 图片大小
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--noval', action='store_true', help='only validate final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable AutoAnchor')
parser.add_argument('--noplots', action='store_true', help='save no plot files')
parser.add_argument('--evolve', type=int, nargs='?', const=300, help='evolve hyperparameters for x generations')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')#修改处,选择
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--optimizer', type=str, choices=['SGD', 'Adam', 'AdamW'], default='SGD', help='optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=10, help='max dataloader workers (per RANK in DDP mode)')#修改处
parser.add_argument('--project', default=ROOT / 'runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--cos-lr', action='store_true', help='cosine LR scheduler')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--patience', type=int, default=100, help='EarlyStopping patience (epochs without improvement)')
parser.add_argument('--freeze', nargs='+', type=int, default=[0], help='Freeze layers: backbone=10, first3=0 1 2')
parser.add_argument('--save-period', type=int, default=-1, help='Save checkpoint every x epochs (disabled if < 1)')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
这里是调整参数的重点:
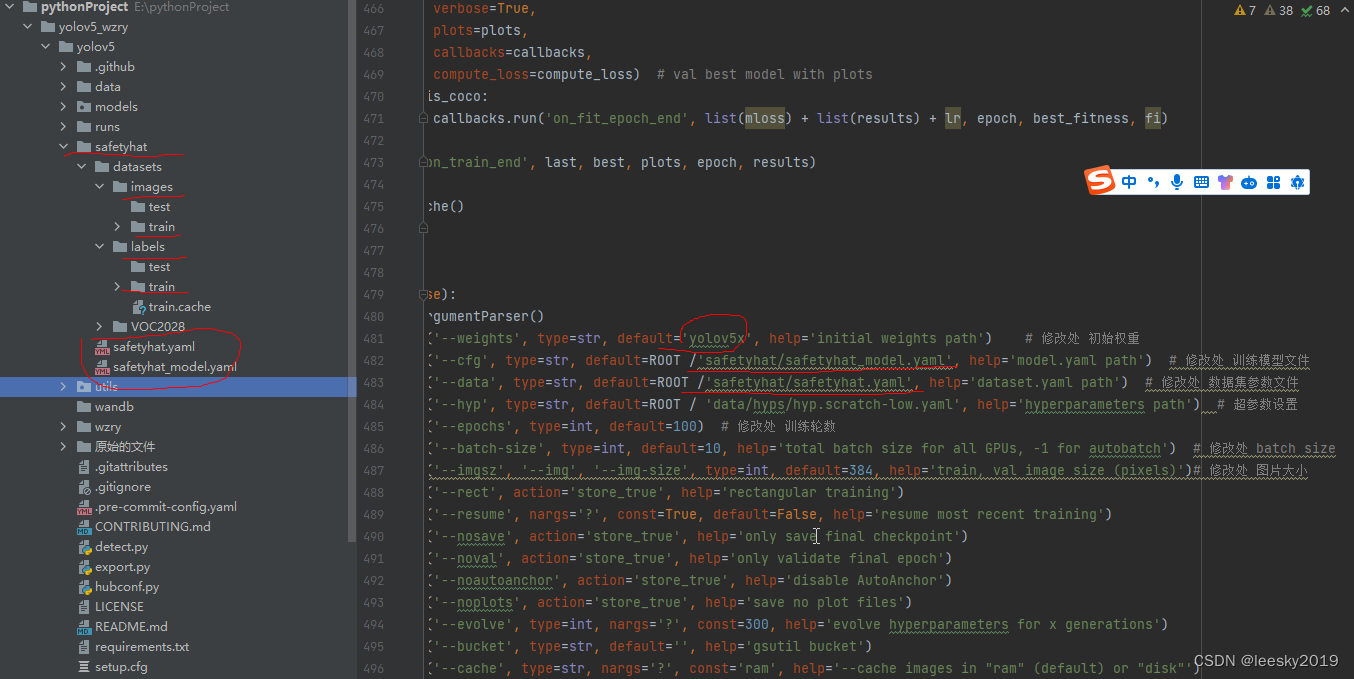
可以看出来一一对应的参数设置—很简单。注意地址的对应关系就行。
这里要搞懂yolov5的文件组织框架
链接: yolov5 这个可以作为参考
yaml相关参数设置
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: python train.py --datasets coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here (7 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: safetyhat\datasets # dataset root dir
train: images\train # train images (relative to 'path') 128 images
val: images\train # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
nc: 2 # number of classes
names: [ 'person',
'hat'
] # class names
上面是训练参数设置,主要设置了训练图片的地址和训练图片标注好的数据集地址(txt文件地址),设置了分类数量nc 以及标签名称name
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 2 # number of classes
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
这里主要设置了训练网络结构参数,# Parameters
nc: 2 # number of classes
depth_multiple: 1.33 # model depth multiple
width_multiple: 1.25 # layer channel multiple
这些都是今后调参的重点内容。可以根据训练及验证情况进行调整。




这就是训练后的结果,识别效果很不错。
在detect中,我们选择GPU 视频实时检测:
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default=ROOT /'runs/train/exp18/weights/last.pt', help='model path(s)') # 修改处 权重文件
# parser.add_argument('--source', type=str, default=ROOT /'wzry/datasets/images/test/SVID_20210726_111258_1.mp4', help='file/dir/URL/glob, 0 for webcam')# 修改处 图像、视频或摄像头
parser.add_argument('--source', type=str, default='0', help='file/dir/URL/glob, 0 for webcam')# 修改处 图像、视频或摄像头
parser.add_argument('--data', type=str, default=ROOT / 'safetyhat/safetyhat.yaml', help='(optional) dataset.yaml path') # 修改处 参数文件
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w') # 修改处 高 宽
parser.add_argument('--conf-thres', type=float, default=0.85, help='confidence threshold') # 置信度
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')# 非极大抑制
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='0', help='cuda device, i.e. 0 or 0,1,2,3 or cpu') # 修改处
实际效果
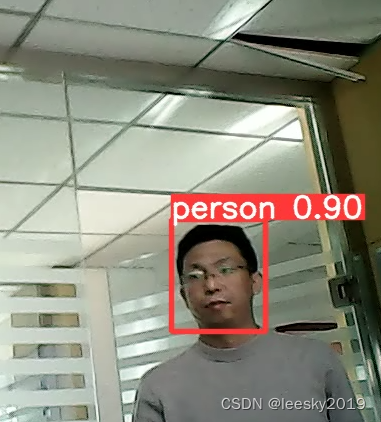
写在最后:
经过一段时间折腾,完成了软硬件环境搭建和代码调试,出现过很多反复和错误,多尝试,一旦实现效果,收获满满。对yolov5运行机制和训练模式有更深的理解,理解之后,通过一次次成功的试验,向实际应用靠拢。接下来要做的内容是:掌握调参,加速、移植,甚至是改写c。上面的所有内容及代码我将开源,不设任何限制获取。链接:https://pan.baidu.com/s/1_1fd5dqzwZI6DEptmMbkUQ
提取码:r85g