python用selenium爬取b站评论并制作词云图
前言
b站视频下的评论是下拉加载的。要想爬取所有评论,要么找到加载评论的链接寻找其规律,要么下拉到低等待页面评论全部加载。我小白一个,找不出规律,用下拉这种笨办法。
要是评论太多,下拉要好久,于是上网发现有selenium可以模拟浏览器的各种行为。这个不仅要导入模块,还要下载浏览器驱动,要配置好一会儿。
制作词云图还要停用词,网上可以下载,但还是要根据需求自己加些词。
提示:以下是本篇文章正文内容,下面案例可供参考
一、爬取b站评论
1.selenium配置
附上参考链接。如何配置selenium
2.代码
附上参考链接。用selenium爬取b站评论
上面的代码下拉只有一两次,拉不到低。我改进了一下,可以自己定下拉几次。
代码如下:
from selenium import webdriver
from time import sleep
import sys
l1=[]
av=input("请输入av号:")
from selenium.common.exceptions import NoSuchElementException #防止错误
def pa(): #定义函数,进行爬取
list = driver.find_elements_by_css_selector(
'#comment > div > div.comment > div.bb-comment > div.comment-list > div > div.con > p')
for i in list:
l1.append(i.text)
def la(a):#定义下拉函数
for i in range (a):
driver.execute_script('window.scrollBy(0,1000)')
sleep(0.25)
return
url = 'https://www.bilibili.com/video/'+av
edge_path = "D:\Edge驱动\msedgedriver.exe" #驱动的路径
driver = webdriver.Edge(executable_path=edge_path)
driver.get(url)
sleep(7)
driver.execute_script('window.scrollBy(0,document.body.scrollHeight)')
sleep(1.5)#页面滚动到底部
driver.execute_script('window.scrollBy(0,1000)')
sleep(1.5)
#等待网络
la(300)#下拉的次数,定太少爬不全,定太多爬太久,自己多试几次
sleep(7)
pa()
while (1):
try:
c =driver.find_element_by_css_selector("#comment > div > div.comment > div.bb-comment > div.bottom-page.paging-box-big > a.next")
#print(c)
c.click()#模拟点击下一页,当没有下一页的时候就会进行下面一个操作
sleep(5)
pa()
sleep(0.5)
except NoSuchElementException as e:
print("没")
break
for i in l1:
print(i)
f=open('神兵小将.txt','w',encoding='utf-8')#创建文本文件
f.writelines(l1)#保存到文本文件中这个只能爬取视频下的评论,不能爬取评论的评论。
二、制作词云图
1.下载停用词
我下载了一个停用词,又根据制作词云图的结果进行了一些添加。提取码是ybdw
2.代码
from wordcloud import WordCloud#导入词云模块
import PIL .Image as image#导入图片模块
import numpy as np#导入矩阵计算模块
import jieba#导入分词模块
import re#导入正则表达模块
def trans_CN(text):#定义分词函数,将连续的文本分为词组
word_list = jieba.cut(text)#将文本切开
#print(word_list)
result = " ".join(word_list)#词组间插入空格
result = result.replace("小破 站","小破站")#将划错的词连回去
result = result.replace("憨 憨","憨憨")#将划错的词连回去
result = result.replace("b 站","b站")#将划错的词连回去
result = result.replace("爷 青回","爷青回")#将划错的词连回去
result = result.replace("虎父无犬 子","虎父无犬子")#将划错的词连回去
#print(result)
single = re.compile(r'( . )',re.S)#定义正则表达式,将单个字挑出
Single = re.findall(single,result)#将单个字挑出,放入Single列表
for item in Single:#遍历单个字列表
result = result.replace(str(item)," ")#把每个字替换为空格
pass
return result#将结果作为函数返回值
with open("C:\\Users\\Ophiuchus\\source\\repos\\Python爬虫学习项目\\PythonApplication2\\神兵小将评论.txt",encoding='utf-8') as fp:#根据文件路径打开源数据
text = fp.read()#读取文本内容到text
text = trans_CN(text)#执行分词函数,并将返回值赋予text
mask = np.array(image.open("C:\\Users\\Ophiuchus\\Pictures\\Saved Pictures\\神兵小将.png"))#打开词云图的形状图片,并定义为掩膜
wordcloud = WordCloud(
max_words=400,#定义词云图显示的最大词量,默认为200
mask=mask,#确定掩膜
min_font_size=1,#确定最小词大小
max_font_size=50,#确定最大词大小
scale=5, #确定清晰度,按比列放大,数值越大,词云越清晰
#background_color='white',设定背景颜色
background_color=None, mode="RGBA",#将背景颜色设定为透明
stopwords = [line.strip() for line in open('C:\\Users\\Ophiuchus\\Desktop\\stopword.txt', 'r', encoding="gb18030").readlines()],#导入停用词
font_path = "C:\\Windows\\Fonts\\msyh.ttc"#确定字体
).generate(text)#词云图的各项设置
image_produce = wordcloud.to_image()#制作词云图
image_produce.save("filename.png")#保存名称与路径
image_produce.show()#展示词云图3.注意事项
- jieba划词并不准确,比如会把“小破站”划成“小破”和“站”两个词,因此需要把这些词接回去。
- 尽管有停用词屏蔽了很多无效词,但还是有许多单个字的词在词云图,意义并不明确。因此进行了对单个字挑出剔除的工作。
- 为了让词云图显得更紧密,可以把最大词的大小与最小词的大小差值设大些。字太小了会模糊,可以通过scale调整清晰度。
- 记得背景颜色设置成透明,这样更方便后期使用。也可以改成白色。
三、制作成品
1.初期成品
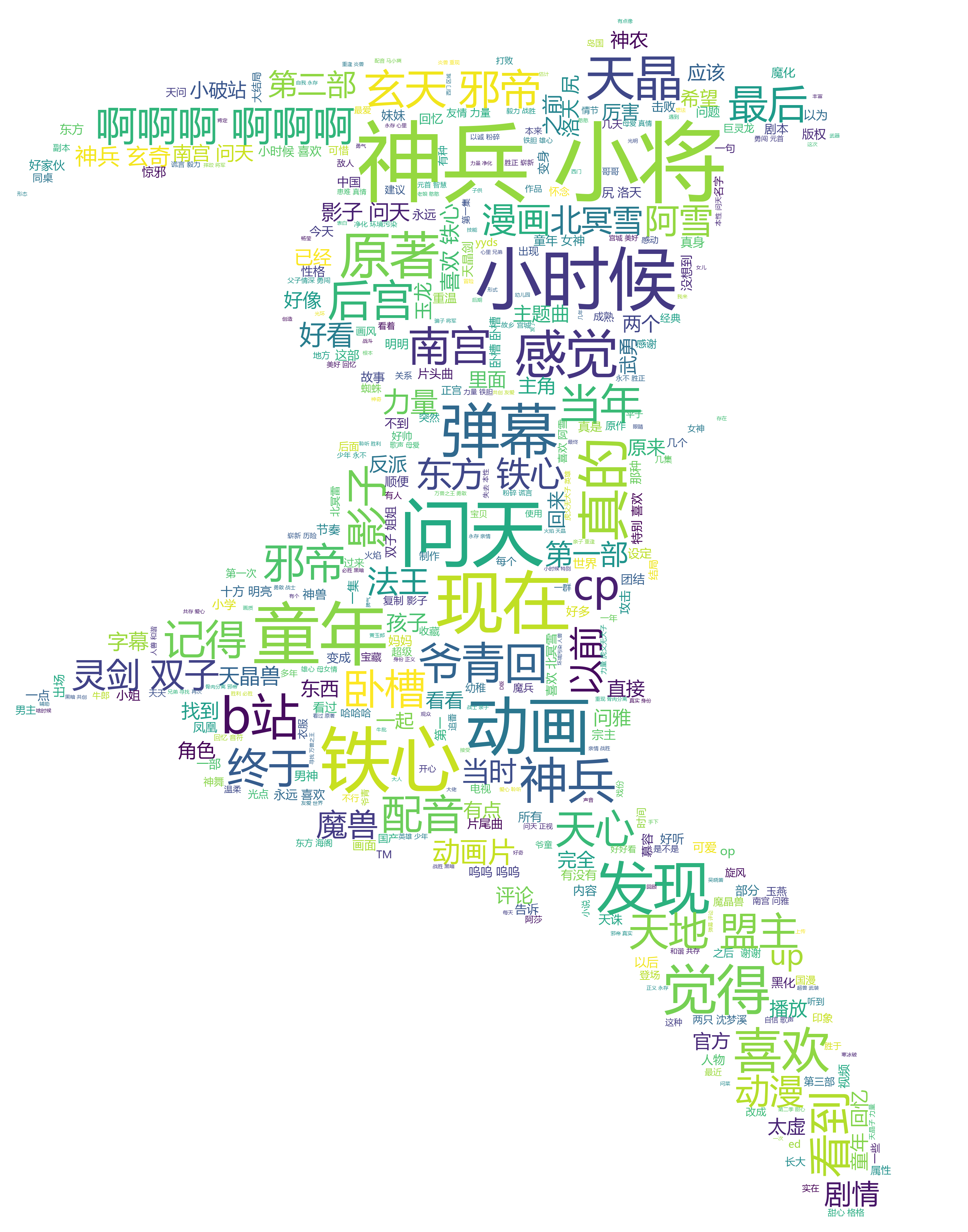
这个看不太清词云图形状,可以在底下垫一层原图,通过ppt在中间加一层半透明的白色蒙版。透明度10%到20%就行了,太透明了影响看词的效果。
2.成品

哇咔咔咔,开心。