【arxiv】论文找 idea : 关于 OVD 的论文扫读(四)
文章目录
- 一、DetCLIPv2: Scalable Open-Vocabulary Object Detection Pre-training via Word-Region Alignment
- 二、Prompt-Guided Transformers for End-to-End Open-Vocabulary Object Detection
- 三、Bridging the Gap between Object and Image-level Representations for Open-Vocabulary Detection
- 四、P3OVD: Fine-grained Visual-Text Prompt-Driven Self-Training for Open-Vocabulary Object Detectio
- 五、Open Vocabulary Object Detection with Proposal Mining and Prediction Equalization
- 六、Open Vocabulary Object Detection with Pseudo Bounding-Box Labels
一、DetCLIPv2: Scalable Open-Vocabulary Object Detection Pre-training via Word-Region Alignment
论文地址:
https://arxiv.org/pdf/2304.04514.pdf

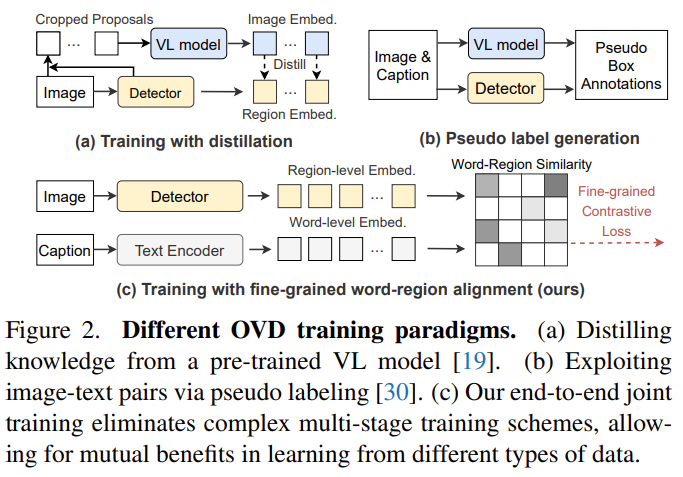
本文介绍了DetCLIPv2,这是一个高效且可扩展的训练框架,结合大规模的图像-文本对来实现开放词汇的目标检测(OVD)。
与先前通常依赖于预训练的视觉-语言模型(例如CLIP)或通过伪标签过程利用图像-文本对的OVD框架不同,DetCLIPv2以端到端的方式直接学习来自大规模图像-文本对的细粒度词-区域对齐。
为了实现这一目标,我们采用区域建议和文本词之间的最大词-区域相似度来引导对比目标。为了在学习广泛概念的同时使模型具备定位能力,DetCLIPv2使用检测、定位和图像-文本对数据的混合监督,在统一的数据形式下进行训练。通过联合训练和采用低分辨率输入的图像-文本对,DetCLIPv2能够高效有效地利用图像-文本对数据:与DetCLIP相比,DetCLIPv2利用了13倍的图像-文本对,但训练时间相似,并且改善了性能。在预训练过程中使用了1300万个图像-文本对,DetCLIPv2展示了卓越的开放词汇检测性能,例如,DetCLIPv2在LVIS基准测试中使用Swin-T骨干网络实现了40.4%的零样本平均精度(AP),超过了之前的工作GLIP/GLIPv2/DetCLIP分别达到的14.4/11.4/4.5% AP,甚至大幅度超过了其全监督对应物。
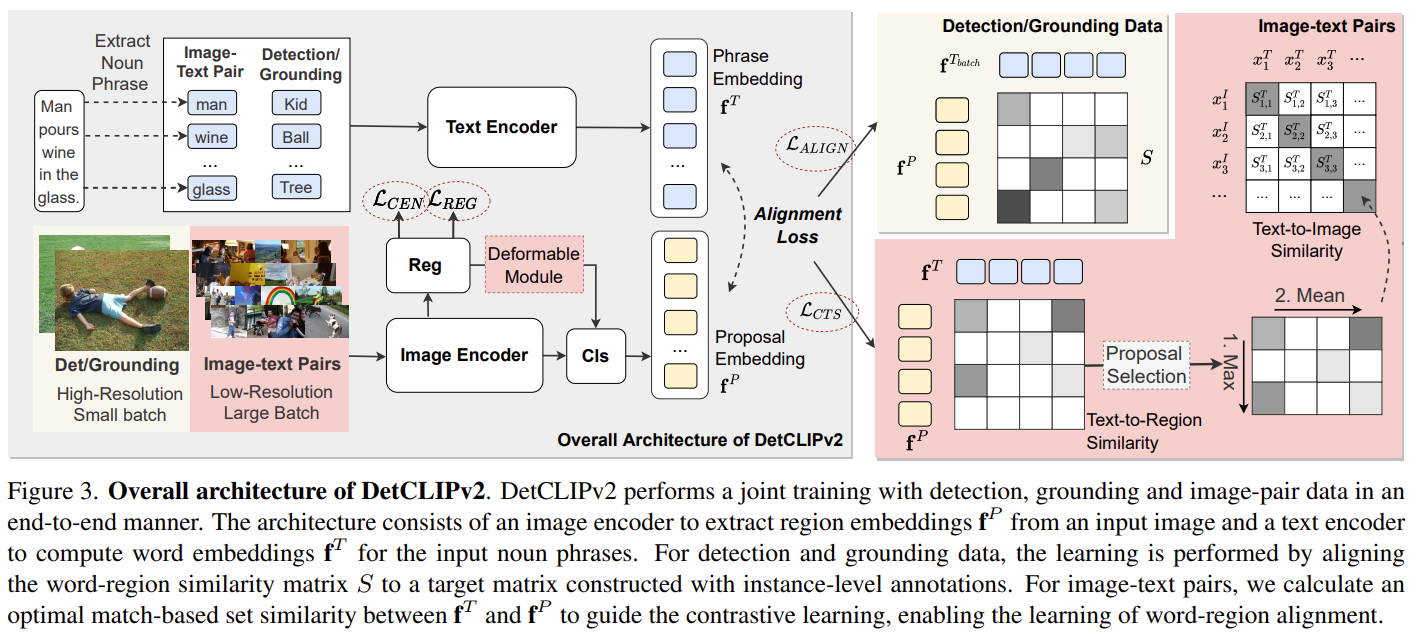
我们在训练中使用了来自不同来源的多个数据集(表1)。具体而言,对于检测数据,我们使用了来自Objects365v2 数据集的一个采样子集(表示为O365),其中包含了66万张图像;对于grounding数据,我们使用了GoldG 数据集,其中移除了COCO 图像,这样可以在LVIS 上进行更公平的零样本评估。对于图像-文本配对数据,我们使用了两个版本的Conceptual Captions (CC)数据集,即CC3M 和CC12M(合称为CC15M)。
二、Prompt-Guided Transformers for End-to-End Open-Vocabulary Object Detection
论文地址:
https://arxiv.org/pdf/2303.14386.pdf

Prompt-OVD是一种高效且有效的开放词汇目标检测框架,它利用了来自CLIP的类别嵌入作为提示,引导Transformer解码器在基本类别和新颖类别中进行目标检测。此外,我们提出了新颖的基于RoI的掩蔽注意力和RoI剪枝技术,帮助充分利用基于Vision Transformer的CLIP的零样本分类能力,从而在最小的计算成本下提高检测性能。我们在OV-COCO和OV-LVIS数据集上的实验证明,Prompt-OVD的推理速度比第一个端到端的开放词汇检测方法(OV-DETR)快了21.2倍,同时在类似推理时间范围内的四个基于两阶段的方法中,也获得了更高的平均精度(AP)。代码将很快发布。
三、Bridging the Gap between Object and Image-level Representations for Open-Vocabulary Detection
论文地址:
https://arxiv.org/pdf/2207.03482.pdf

现有的开放词汇目标检测器通常通过利用不同形式的弱监督来扩大其词汇大小,以帮助推广到推理阶段的新颖对象。在开放词汇检测(OVD)中使用的两种流行的弱监督形式包括预训练的CLIP模型和图像级别监督。我们注意到,这两种监督模式在目标检测任务中并没有得到最优对齐:CLIP是通过图像-文本对进行训练,缺乏对象的精确定位,而图像级别监督是使用启发式方法进行的,不能准确地指定局部对象区域。在这项工作中,我们提出通过执行基于对象的语言嵌入的对齐来解决这个问题。此外,我们使用伪标记过程仅使用图像级别监督进行视觉对齐,该过程提供高质量的对象候选提案,并帮助在训练过程中扩展词汇。我们通过一种新颖的权重传递函数将上述两种对象对齐策略建立起联系,以聚合它们的互补优势。本质上,所提出的模型旨在在OVD环境中减小对象和以图像为中心的表示之间的差距。在COCO基准测试中,我们提出的方法在新颖类别上达到了36.6 AP50,绝对优于之前最佳性能的8.2。对于LVIS,我们在罕见类别的遮罩AP上超过了最先进的ViLD模型5.0,整体上超过了3.4。
这项工作的主要贡献包括:
- 提出了基于区域的知识蒸馏方法,用于调整面向图像的CLIP嵌入,以适应局部区域,从而改善区域与语言嵌入之间的对齐。研究表明,通过获得良好对齐的表示,有助于改善文本驱动的OVD(对象-视觉描述)流程的整体性能。
- 为弱图像标签提供视觉基础:该方法利用预训练的多模态视觉转换器(ViTs)生成高质量的目标提案,以视觉方式对弱图像标签进行基础。该方法通过使用伪标签,即根据模型的预测为无标签数据分配标签,扩大了类别词汇表,并因此在新的目标类别上具有更好的泛化能力。
- 集成面向对象的对齐:尽管上述贡献主要集中在视觉领域,但作者提出了一种新的权重传递函数,通过在区域级别的视觉-语言映射上显式条件化(伪标记的)图像级别VL(视觉-语言)映射。这种集成方式使得该方法是首个在单一架构中同时整合对象中心的视觉和语言对齐的方法,用于OVD。
- 性能改进:研究人员进行了大量实验证明了所提方法的改进。在COCO和LVIS基准测试上,该方法相对于当前最先进的方法,在新颖类和罕见类上的平均精度(AP)分别提升了8.2和5.0个百分点。此外,对COCO、OpenImages和Objects365进行的跨数据集评估也表明,与现有方法相比,该方法具有一致的改进效果,展示了其泛化能力。
总结起来,这项工作的主要贡献包括基于区域的知识蒸馏、对弱图像标签的伪标记、对象中心对齐的集成以及在各种基准测试中相较于现有方法取得的OVD能力的改进。
四、P3OVD: Fine-grained Visual-Text Prompt-Driven Self-Training for Open-Vocabulary Object Detectio
论文地址:
https://arxiv.org/pdf/2211.00849.pdf

近期的一些研究工作受到视觉-语言方法(VLMs)在零样本分类中的成功启发,尝试将这一方法延伸到目标检测领域,利用预训练的VLMs的定位能力,在自我训练的方式下为未知类别生成伪标签。
然而,由于当前的VLMs通常是通过将句子嵌入与全局图像嵌入进行对齐的方式进行预训练的,它们的直接使用缺乏对目标实例的细粒度对齐,而这是目标检测的核心。
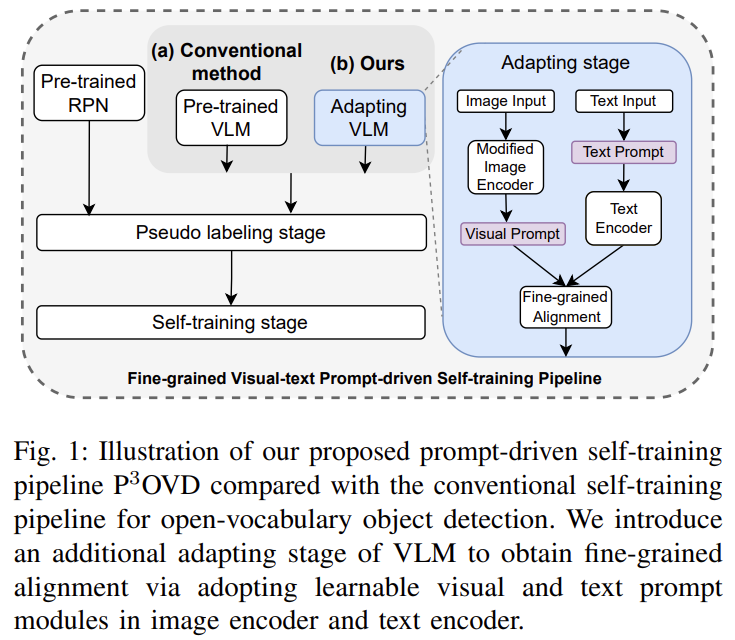
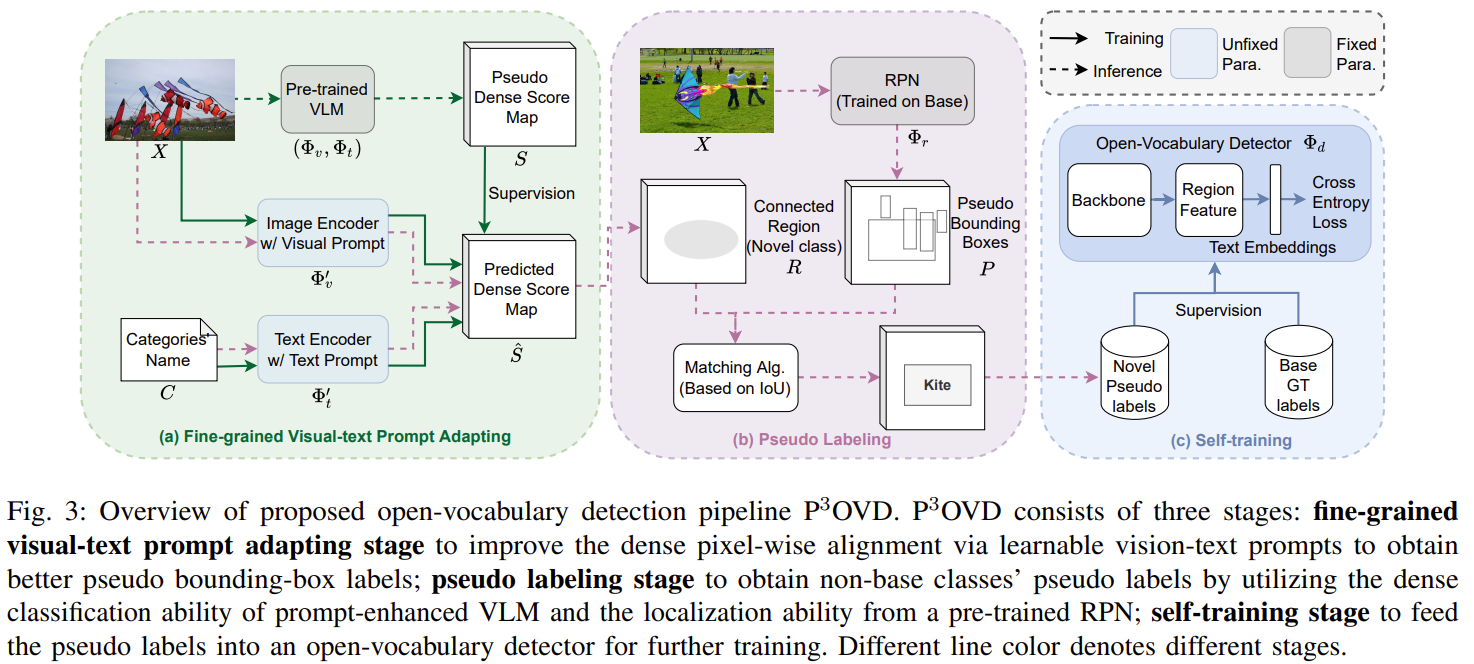
在本文中,我们提出了一种简单而有效的针对开放词汇检测(Open-Vocabulary Detection)的预训练-自适应伪标签范式(Pretrain-adaPt-Pseudo labeling paradigm,简称P3OVD),通过引入一个细粒度的视觉-文本提示自适应阶段,增强了当前自我训练范式的能力,实现了更强大的细粒度对齐。在自适应阶段中,我们通过使用可学习的文本提示解决一个辅助的密集像素级预测任务,使VLM能够获得细粒度的对齐。
此外,我们还提出了一个视觉提示模块,为视觉分支提供任务信息(即需要预测的类别),以更好地使预训练的VLM适应下游任务。实验证明,我们的方法在开放词汇目标检测方面实现了最先进的性能,例如在COCO数据集上未见类别上达到31.5%的mAP(平均精度均值)。
五、Open Vocabulary Object Detection with Proposal Mining and Prediction Equalization
论文地址:
https://arxiv.org/pdf/2206.11134.pdf

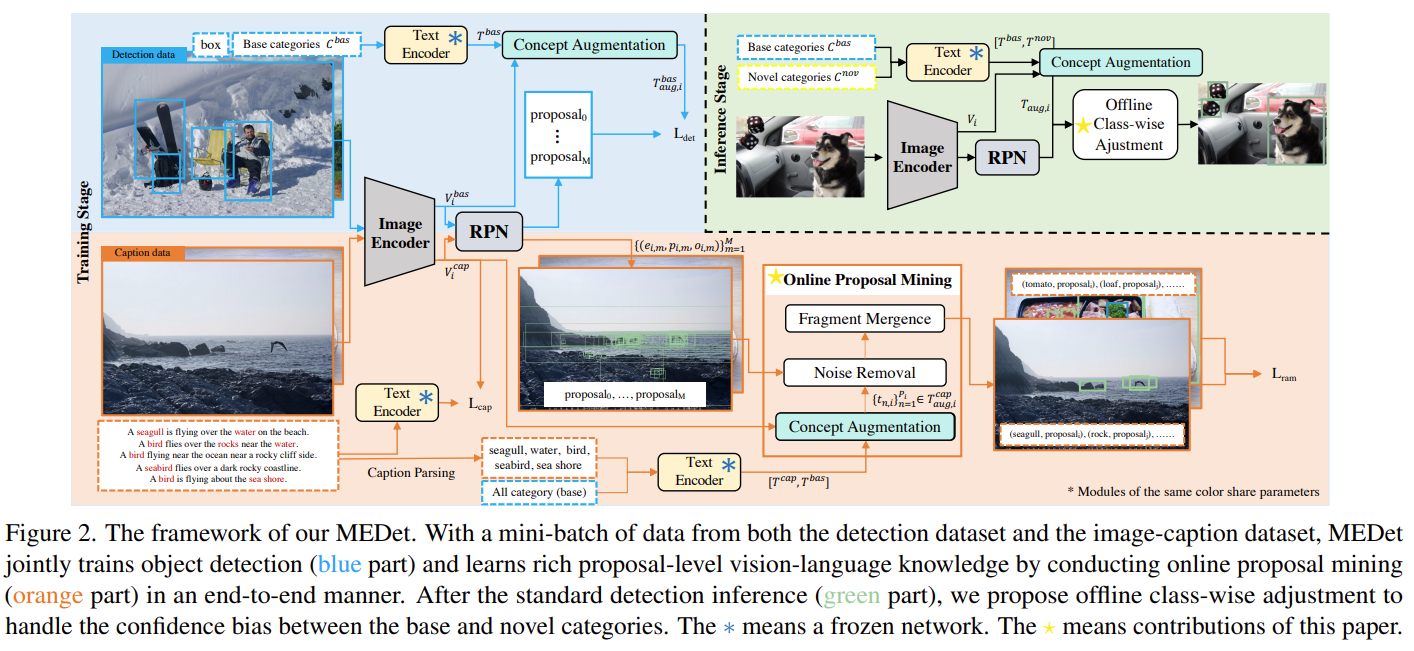
尽管从预训练的视觉-语言模型中学习对于开放词汇目标检测(OVD)来说是有效的,可以识别训练词汇之外的物体,但仍存在两个问题,即提案级别的视觉-语言对齐和基础-新颖类别预测平衡。在本文中,我们引入了一种新颖的开放词汇目标检测(MEDet)框架,以解决这些问题。具体而言,我们通过以粗到细和在线方式对继承的视觉-语义知识进行提案挖掘,从而实现了面向检测的提案级别特征对齐。同时,我们通过对离线类别进行调整,强化新颖类别预测的置信度,从而提高整体OVD性能。广泛的实验证明了MEDet方法相对于最先进方法的优越性。特别是,我们将MS COCO数据集上新颖类别的mAP从29.1%提升到32.6%,在LVIS数据集上获得了22.4%的掩膜AP,提高了1.4%。为了可复现性,我们匿名发布了代码。
六、Open Vocabulary Object Detection with Pseudo Bounding-Box Labels
论文地址:
https://arxiv.org/pdf/2111.09452.pdf

尽管目标检测取得了巨大的进展,但大多数现有方法仅适用于有限的目标类别集,这是因为在训练数据中需要进行边界框标注的人力工作量巨大。为了缓解这个问题,最近的开放词汇和零样本检测方法尝试在训练期间检测超出已见目标类别的新颖目标类别。它们通过在预定义的基础类别上进行训练来实现这一目标,以引导对新颖对象的泛化能力。然而,它们的潜力仍然受到可用于训练的基础类别集的限制。为了扩大基础类别集,我们提出了一种方法,可以从大规模图像-标题对中自动生成各种对象的伪边界框标注。我们的方法利用预训练的视觉-语言模型的定位能力生成伪边界框标签,然后直接将其用于训练目标检测器。实验证明,我们的方法在COCO新颖类别上的AP值比最先进的开放词汇检测器提高了8%,在PASCAL VOC上提高了6.3%,在Objects365上提高了2.3%,在LVIS上提高了2.8%。