接口自动化测试-Requests模块实战详解,一篇打通...
目录:导读
前言
什么是requests?
requests是一个很实用的Python HTTP客户端库,编写爬虫和测试服务器响应数据时经常会用到, Requests是Python语言的第三方的库,专门用于发送HTTP请求
下载
pip install requests
请求方式
1、get请求
# GET无参请求
r = requests.get('http://www.baidu.com')
# GET有参请求
# 方法一
canshu = {"consName": "水瓶座","key":26183f3f48d787b5541aa3d0e767b359}
r = requests.get("http://web.juhe.cn:8080/constellation/getAll", params=canshu)
print(r)
# 方法二
r = requests.get("http://web.juhe.cn:8080/constellation/getAll?consName=水瓶座&key=26183f3f48d787b5541aa3d0e767b359")
print(r.text)
2、post请求
canshu = {"consName": "水瓶座", "key": "26183f3f48d787b5541aa3d0e767b359"}
r = requests.post("http://web.juhe.cn:8080/constellation/getAll", data=canshu)
print(r.text)
3、响应的内容
r.encoding # 获取当前的编码
r.encoding = 'utf-8' # 设置编码
r.text # 以encoding解析返回内容。字符串方式的响应体,会自动根据响应头部的字符编码进行解码。
r.content # 以字节形式(二进制)返回。字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩。
r.headers # 以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None
r.status_code # 响应状态码
r.raw # 返回原始响应体,也就是 urllib 的 response 对象,使用 r.raw.read()
r.ok # 查看r.ok的布尔值便可以知道是否登陆成功
#*特殊方法*#
r.json() # Requests中内置的JSON解码器,以json形式返回,前提返回的内容确保是json格式的,不然解析出错会抛异常
r.raise_for_status() # 失败请求(非200响应)抛出异常
4、超时设置
requests.get(url,timeout=1) # 超过等待时间则报错
5、添加请求头信息
requests.get(url,headers=headers) # 设置请求头
6、添加文件
requests.post(url, files=files) # 添加文件
7、文件传输
url = 'http://httpbin.org/post'
files = {'file': open('report.xls', 'rb')}
r = requests.post(url, files=files)
requests+pytest+allure框架
1、读取csv文件
"""存储csv数据"""
url,params,method
http://web.juhe.cn:8080/constellation/getAll,{"consName":"水瓶座","key":26183f3f48d787b5541aa3d0e767b359},get
http://japi.juhe.cn/qqevaluate123/qq,{"qq":1640484095,"key":1e5a939231f3a1bf225050d7fe92f569},post
"""读取数据"""
import csv
class ReadCsvClass():
def readCsv(self):
li = []
csv_open = csv.reader(open("../dataDemo/saveCSV.csv", "r", encoding="utf-8"))
for i in csv_open:
li.append(i)
li = li[1:]
return li
r = ReadCsvClass()
print(r.readCsv())
"""request请求接口返回状态码"""
import requests
from readDemo.readCsv import ReadCsvClass
r = ReadCsvClass()
cm = r.readCsv()
class CsvRequestsClass():
def csvRequests(self):
item = []
for i in cm:
if i[-1] == "get":
res = requests.get(url=i[0], params=i[1])
item.append(res.status_code)
else:
res = requests.post(url=i[0], data=i[1])
print(res.url)
item.append(res.status_code)
return item
c = CsvRequestsClass()
cc = c.csvRequests()
print(cc)
"""pytest断言设置并结合allure生成测试报告"""
import pytest
import os
from useRequests.csvrequests import CsvRequestsClass
c = CsvRequestsClass()
cc = c.csvRequests()
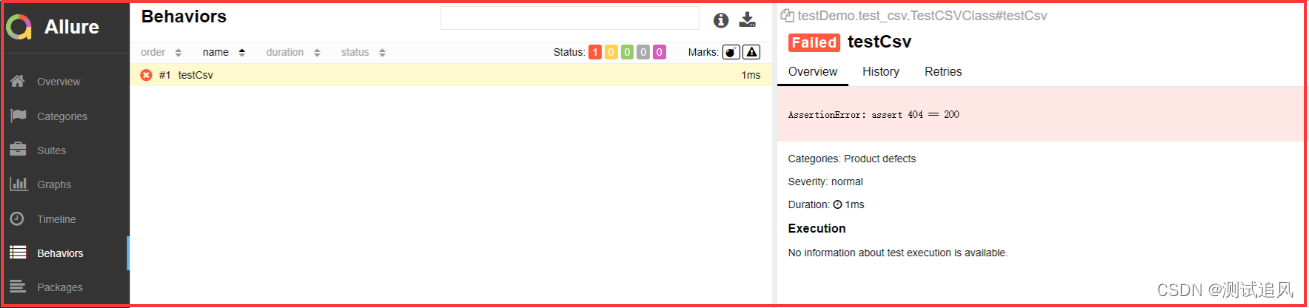
class TestCSVClass():
def testCsv(self):
for i in cc:
assert i == 200
if __name__ == '__main__':
pytest.main(['--alluredir', '../reportCsv/result', 'test_csv.py'])
split = 'allure ' + 'generate ' + '../reportCsv/result ' + '-o ' + '../reportCsv/html ' + '--clean'
os.system(split)
2、读取Excel文件
存储Excel数据
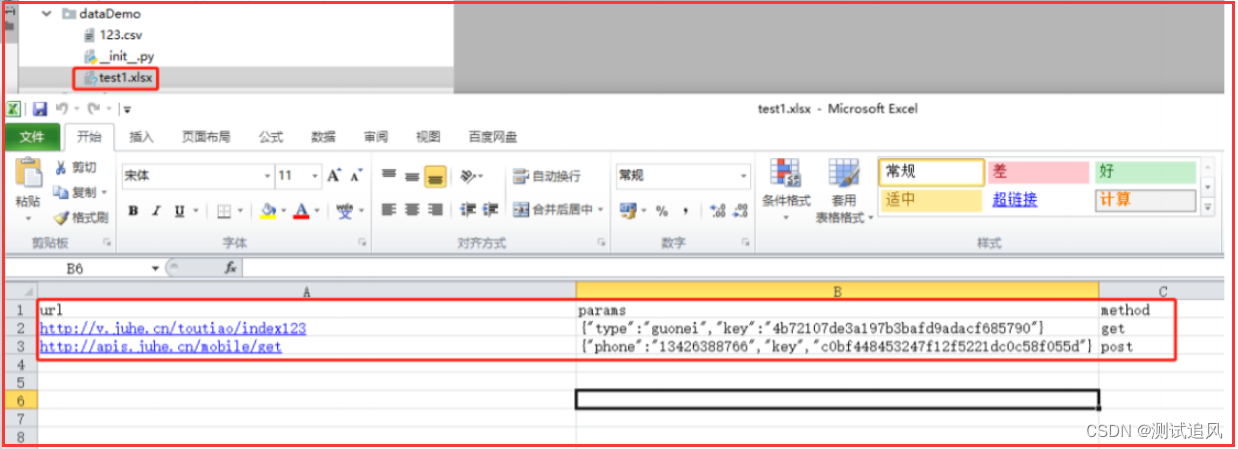
"""读取Excel数据"""
from openpyxl import load_workbook
class ReadExcelClass():
def readExcel(self):
# 打开表
workbook = load_workbook(r'F:\day--26\requests_test\dataDemo\saveExcel.xlsx')
# 定位表单
sheet = workbook['Sheet1']
print(sheet.max_row) # 3行
print(sheet.max_column) # 3列
item = [] # 把所有行的数据放到列表中
for i in range(2, sheet.max_row + 1):
adict = {} # 把每行的数据放到字典中
for j in range(1, sheet.max_column + 1):
adict[sheet.cell(1, j).value] = sheet.cell(i, j).value
item.append(adict)
return item
r = ReadExcelClass()
rr = r.readExcel()
print(rr)
"""request请求接口返回状态码"""
import requests
from readDemo.readExcel import ReadExcelClass
r = ReadExcelClass()
rr = r.readExcel()
class ExcelRequestsClass():
def excelRequest(self):
item = []
for i in rr:
if i["method"] == "get":
res = requests.get(url=i["url"], params=i["params"])
item.append(res.status_code)
else:
res = requests.post(url=i["url"], data=i["params"])
item.append(res.status_code)
return item
if __name__ == '__main__':
e = ExcelRequestsClass()
ee = e.excelRequest()
print(ee)
"""pytest断言设置并结合allure生成测试报告"""
import os
import pytest
from useRequests.excelrequests import ExcelRequestsClass
e = ExcelRequestsClass()
ee = e.excelRequest()
for i in ee:
print(i)
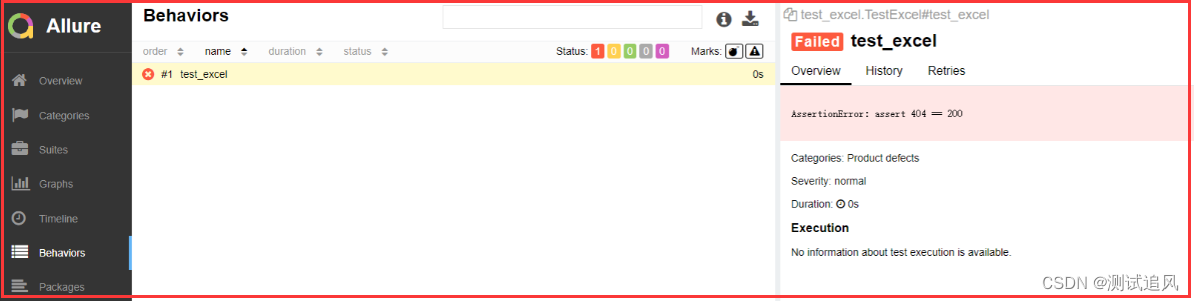
class TestExcel():
def test_excel(self):
for a in ee:
assert a == 200
if __name__ == '__main__':
pytest.main(['--alluredir', '../reportExcel/result', 'test_excel.py'])
split = 'allure ' + 'generate ' + '../reportExcel/result ' + '-o ' + '../reportExcel/html ' + '--clean'
os.system(split)
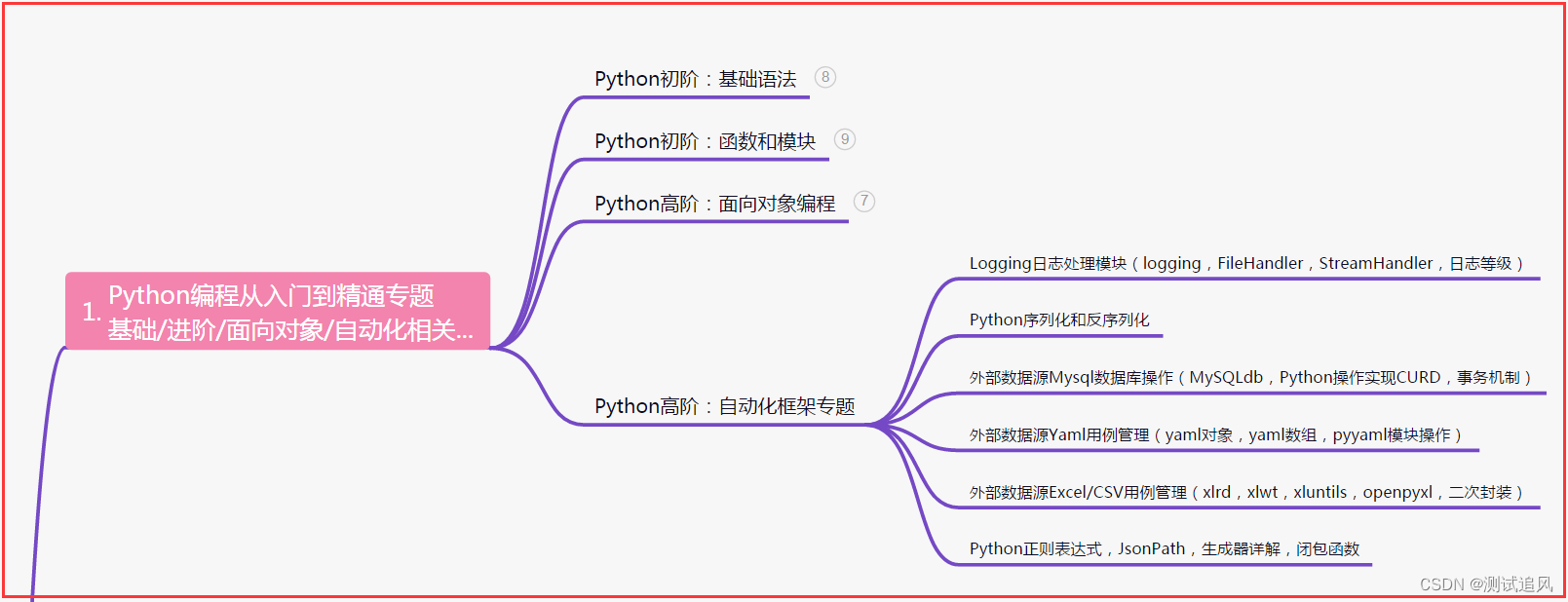
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通
二、接口自动化项目实战
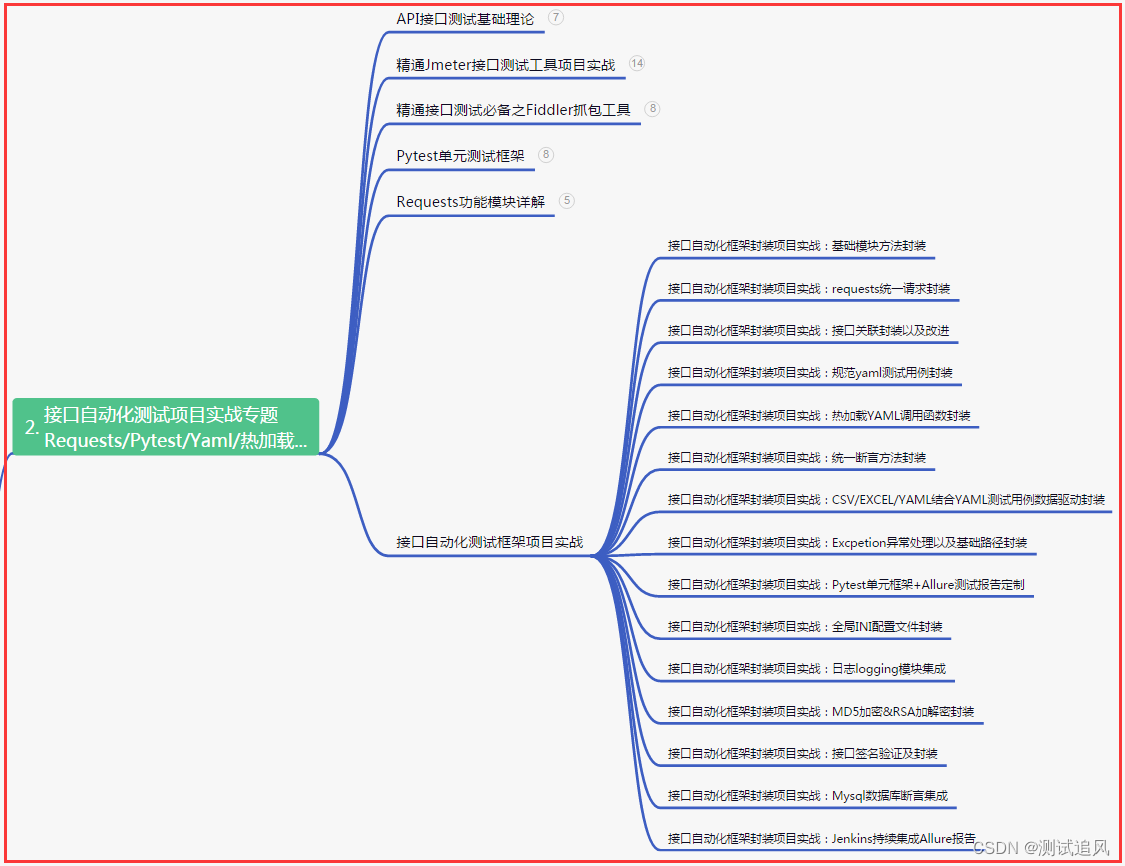
三、Web自动化项目实战
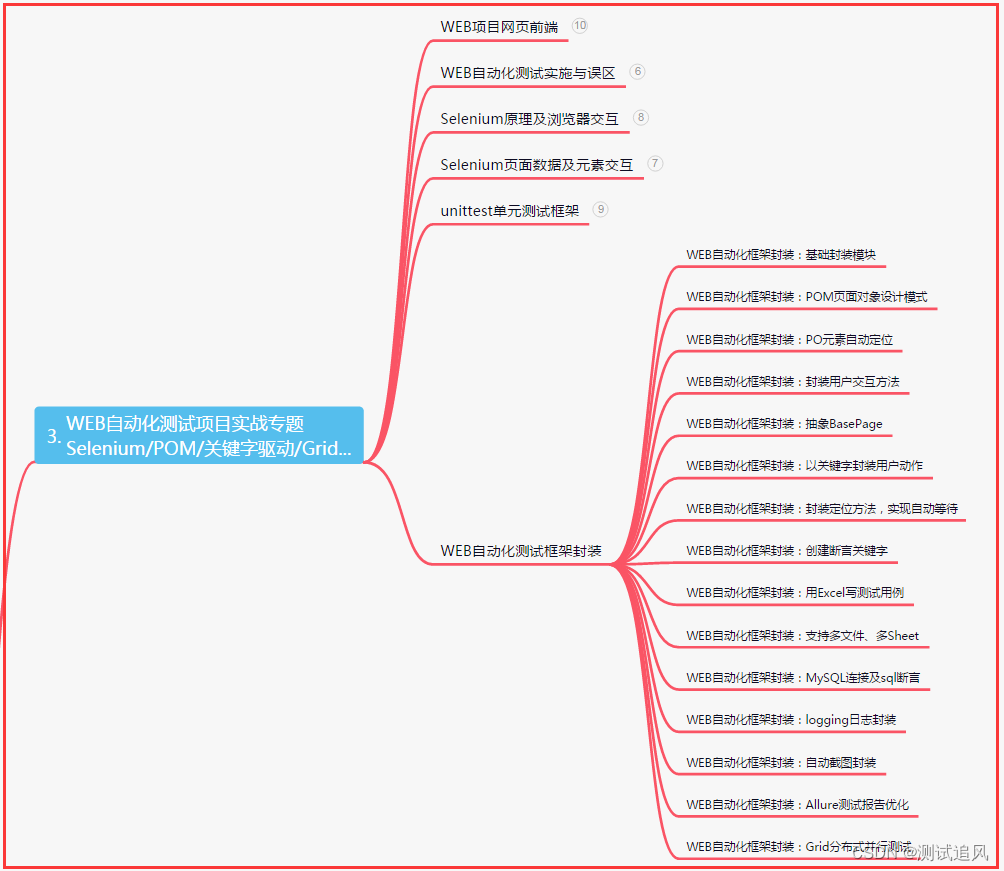
四、App自动化项目实战
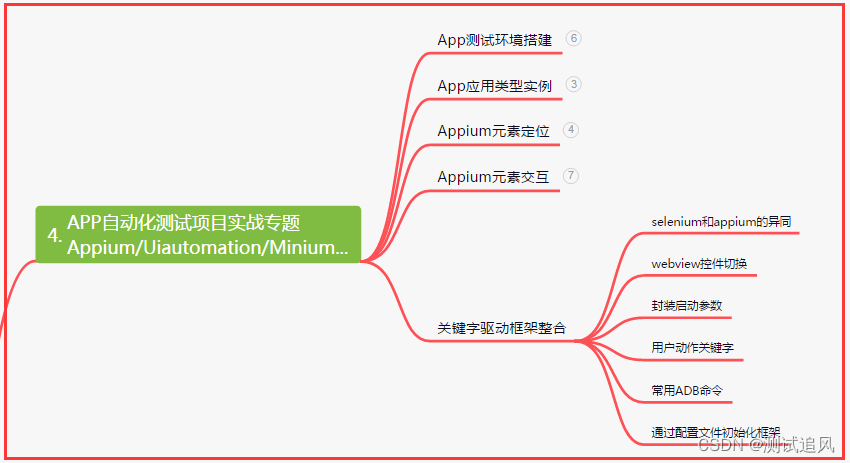
五、一线大厂简历
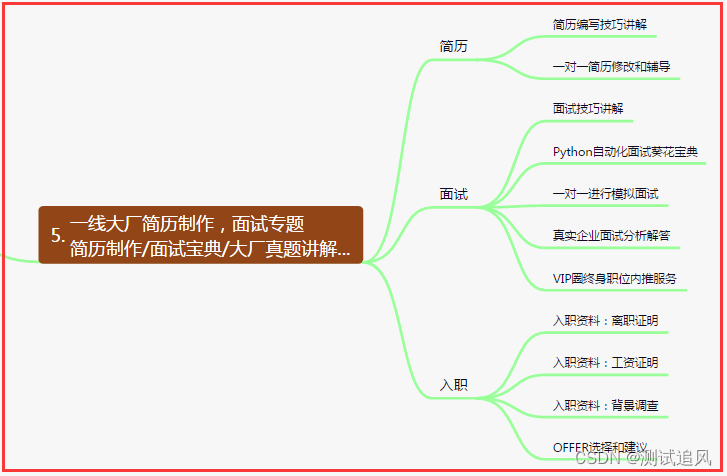
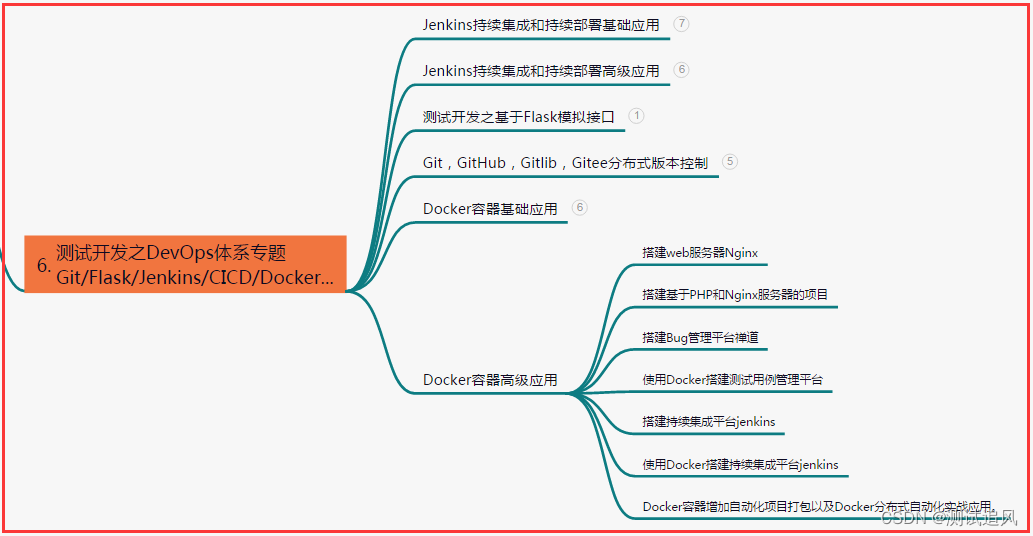
六、测试开发DevOps体系
七、常用自动化测试工具

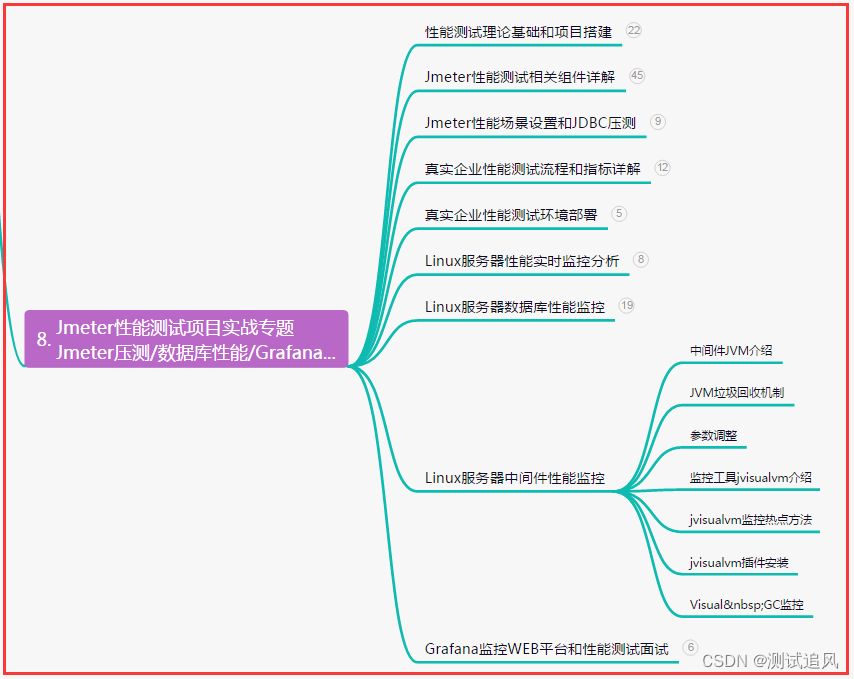
八、JMeter性能测试
九、总结(尾部小惊喜)
奋斗是燃起内心的火焰,不论困境多么险峻,只要保持信念,砥砺前行,你将释放出无尽的潜能,开创出属于自己的辉煌。勇敢地去追逐梦想,坚持不懈,那些努力必将转化为无坚不摧的力量。
奋斗是自我超越的征程,踏遍山河,磨平岁月。不论环境如何,心怀使命,百折不挠地追求梦想。激发内心的力量,释放出无限的能量。
人生如逆水行舟,不进则退。坚持奋斗,拥抱挑战,才能超越平凡,谱写出属于自己的辉煌篇章。不论前路多崎岖,保持信念和勇气,努力奋斗,必将驶向成功的彼岸。