深度学习AI编译器-LLVM简介
1、什么是LLVM
LLVM的命名最早来源于底层语言虚拟机(Low Level Virtual Machine)的缩写。它是一个用于建立编译器的基础框架,以C++编写。创建此工程的目的是对于任意的编程语言,利用该基础框架,构建一个包括编译时、链接时、执行时等的语言执行器。目前官方的LLVM只支持处理C/C++,Objective-C三种语言,当然也有一些非官方的扩展,使其支持ActionScript、Ada、D语言、Fortran、GLSL、Haskell、Java bytecode、Objective-C、Python、Ruby、Rust、Scala以及C#。
LLVM是一个编译器框架。LLVM作为编译器框架,是需要各种功能模块支撑起来的,你可以将clang和lld都看做是LLVM的组成部分,框架的意思是,你可以基于LLVM提供的功能开发自己的模块,并集成在LLVM系统上,增加它的功能,或者就单纯自己开发软件工具,而利用LLVM来支撑底层实现。LLVM由一些库和工具组成,正因为它的这种设计思想,使它可以很容易和IDE集成(因为IDE软件可以直接调用库来实现一些如静态检查这些功能),也很容易构建生成各种功能的工具(因为新的工具只需要调用需要的库就行)。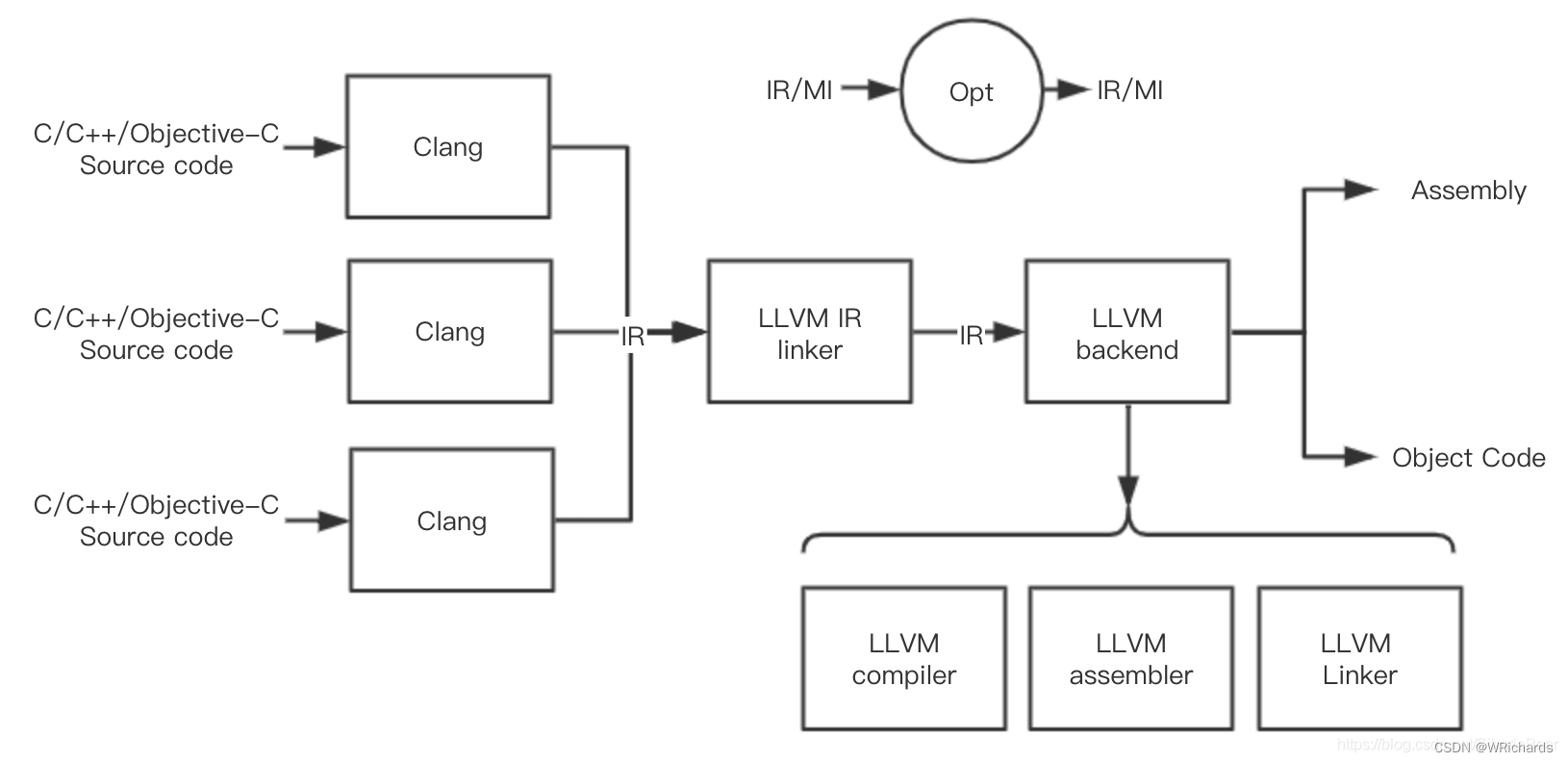
常见的结构如下图

主要由三个部分组成。
前端:将高级语言例如C或者其他语言转换成LLVM定义的中间表达方式 LLVM IR。例如非常有名的clang, 就是一个转换C/C++的前端。
中端:中端主要是对LLVM IR本身进行一下优化,输入是LLVM, 输出还是LLVM, 主要是消除无用代码等工作,一般来讲这个部分是不需要动的,可以不管他。
后端:后端输入是LLVM IR, 输出是我们的机器码。我们通常说的编译器应该主要是指这个部分。大部分优化都从这个地方实现。
至此,LLVM架构的模块化应该说的比较清楚了。很大的一个特点是隔离了前后端。
如果你想支持一个新语言,就重新实现一个前端,例如华为“仓颉”就有自己的前端来替换clang。
如果你想支持一个新硬件,那你就重行实现一个后端,让它可以正确的把LLVM IR映射到自己的芯片。
前端

经过词法分析、语法分析、语义分析、LLVM IR生产,最终将C++转化成后端认可的LLVM IR。
词法分析:将编程语言取出一个个词,遇到不认识的字符就报错。例如将a=b+c 拆成a,= ,b ,+, c
语法分析:将语法提取出来,例如你写了个a+b=c, 明显不符合语法,直接报错
语义分析:分析一下你写的代码实际含义是不是对,例如a=b+c, a,b,c有没有定义,类型是不是对的
LLVM IR生产:经过上述三步,将你写的代码转化成树状描述(抽象语法树),然后再转化成IR定义的IR即可。
举个直观的栗子,你写的C++
// add.cpp
int add(int a, int b) {
return a + b;
}
生产的LLVM IR
(这个地方你不需要看懂每个细节,知道大概想类汇编的语言就行了, 专业的形式叫SSA, Static Single Assignment (SSA)
; ModuleID = 'add.cpp'
source_filename = "add.cpp"
target datalayout = "e-m:o-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-apple-macosx10.15.0"
; Function Attrs: noinline nounwind optnone ssp uwtable
define i32 @_Z3addii(i32, i32) #0 {
%3 = alloca i32, align 4
%4 = alloca i32, align 4
store i32 %0, i32* %3, align 4
store i32 %1, i32* %4, align 4
%5 = load i32, i32* %3, align 4
%6 = load i32, i32* %4, align 4
%7 = add nsw i32 %5, %6
ret i32 %7
}
后端
后端把你的LLVM转换成真正的汇编(或者机器码)。主要的流程如下。这个我们要重点讲讲,因为后续我们就是要实现一个这个东西支持一个新的芯片。
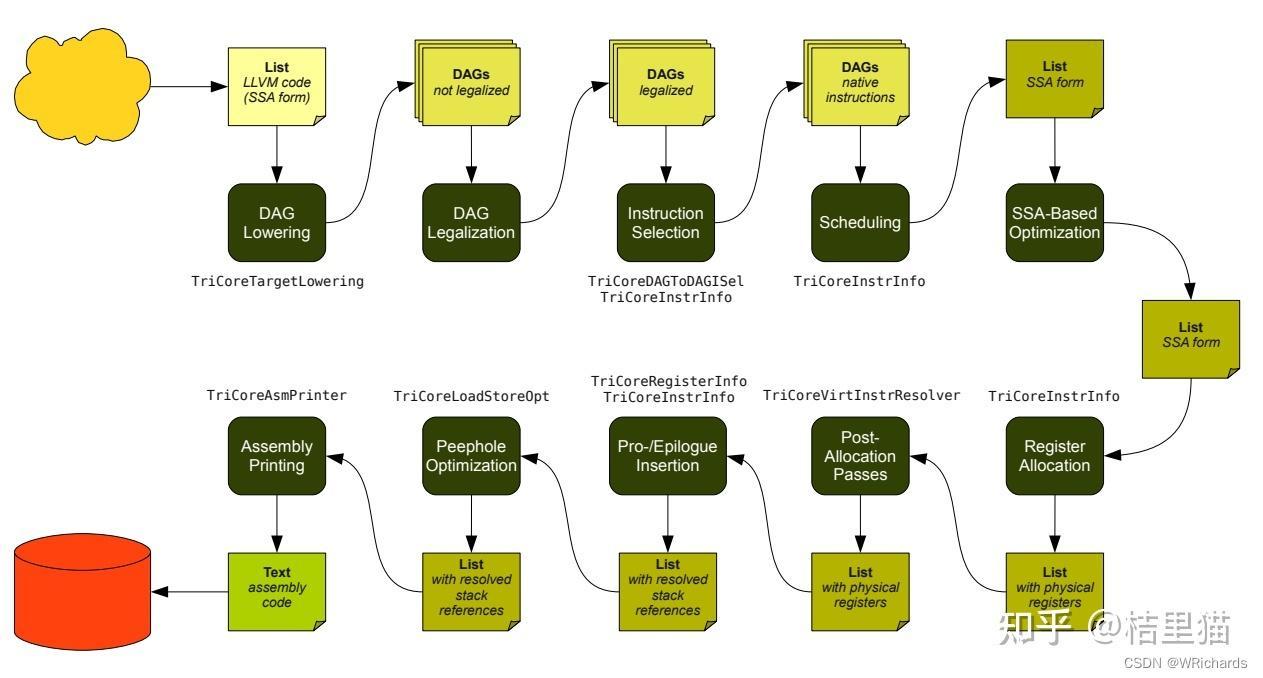
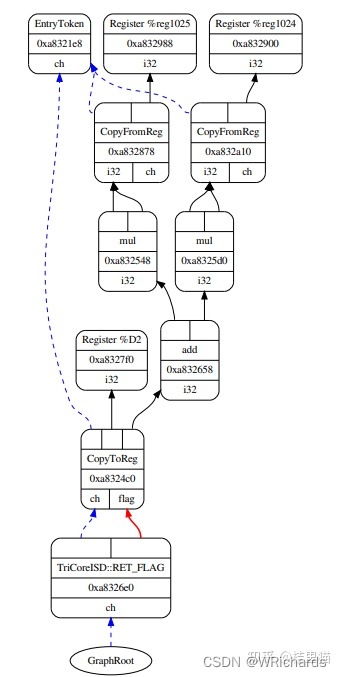
DAG Lowering
这个主要负责将你的LLVM IR转换为有向无环图,便于后续利用图算法优化。
例如将下面的LLVM IR 转换成图,每个节点是一个指令。

DAG Legalization
DAG图合法化,3.1中的DAG图都是LLVM IR指令,但实际上LLVM IR指令不可能被芯片全部支持,这个步骤就是替换这些不合法的指令。
Instruction Selection
这个步骤其实和3.2算是一起的功能,都是为了将LLVM IR转换成机器支持的Machine DAG.

如上图,将store换成机器仍可的st, 将16位的寄存器转向32位。一切向机器指令靠拢。
Scheduling
这个步骤主要是调整指令顺序的,从有向无环图再展开成顺序的指令。
例如把下面的指令调成这样的。

把%C的store提前一些,因为下一条ld要用C啦。
SSA-based Machine Code Optimization
这一步骤主要是做一些公共表达式合并啊去除的操作。
Register Allocation
这一步就要分配寄存器了。在3.5之前我们认为寄存器其实是可以无限用的,但实际硬件的寄存器有限的。所以我们得考虑寄存器数量与寄存器值的生命周期,将虚拟的寄存器替换成实际的寄存器。这个一般会用到图着色等等算法,贼复杂,好在LLVM都实现好了,不用在重复造轮子。
例如一个芯片,有32个可用的寄存器,如果函数使用到了64个,多的就只能压如堆栈或者等着了。
具体怎么分配的,知乎有专家研究,见下面的文章。Frank Wang:LLVM寄存器分配(一)
Prologue/Epilogue Code Insertion
这个主要是加上函数调用前的指令和函数结束后的指令。主要是调用前把参数存下来,调用后把结果写到固定的寄存器里。
Peephole optimizations
这个步骤主要是对代码再最后抢救一番。比如把x*2换成x<1
再比如下面这样

将两个32bit的存储换成一个64bit的存储
Code Emission
最后一步显然,将上述优化好的中间格式转换成我们真正需要的汇编,由汇编器翻译成机器码,大功告成。