yolov5训练加速--一个可能忽视的细节(mmdetection也一样),为什么显卡使用率老是为0?(续)
之前写过一篇训练加速的文章:
https://blog.csdn.net/ogebgvictor/article/details/129784503
但是有些细节需要更正或者补充,故再写一篇。
目录
一。是用缩放到640的jpg训练,还是用缩放到640的npy文件训练?
一。是用缩放到640的jpg训练,还是用缩放到640的npy文件训练?
如果训练分辨率用640,那么在训练的过程中,yolov5会先把图片resize成640,然后再进行后续的处理(数据增强、前向推理),所以你把图片事先resize成640,似乎是一样的。但是如果你把它保存为jpg,然后在训练的时候用这个640的jpg,其实与原图resize到640是不一样的!
因为jpg是有损编码,会有一定的损失。而原图resize到640,比如采用双线性插值,它其实是具有超像素的信息的,但是保存为640的jpg,就又会损失掉一部分信息。所以最好在resize成640后,直接用numpy把它保存为npy文件,这是完全无损的。(题外话:比如用1080p的显示器,去播放2K甚至4K的视频,可能就是觉得比播放1080p的视频更清晰,可能就是因为有超像素的信息~~)
你可能会问:损失的那一点点信息有关系吗?下面实验一下。我用的数据集是cityscape数据集,从中选了10个分类:'person', 'rider', 'car', 'truck', 'bus', 'train', 'motorcycle', 'bicycle'。这个数据集的图片分辨率都是2048乘1024的,所以缩放到640的话,缩放比例为3.2,这个比例还是蛮大的。原图上面有大小不一的物体,有的小物体在缩放后就会很小了。并且此数据集中重叠的物体很多。所以用640分辨率来训练,其实并不是很合适,但是这正好用来验证一下640jpg导致的损失信息对训练效果的影响。
1.先改一下代码
用yolov5-7.0的代码来实验,但是他的代码在把图片保存为npy的时候(即训练参数--cache disk),并没有先缩放到640再保存,而是直接按原图尺寸保存。
对应函数为utils/dataloaders.py中的LoadImagesAndLabels.cache_images_to_disk(),所以我把它修改了一下,如下cache_images_to_disk是我修改后的,cache_images_to_disk_old是修改前的。
def cache_images_to_disk(self, i):
# Saves an image as an *.npy file for faster loading
f = self.npy_files[i]
if not f.exists():
im = cv2.imread(self.im_files[i]) # BGR
assert im is not None, f'Image Not Found {f}'
h0, w0 = im.shape[:2] # orig hw
r = self.img_size / max(h0, w0) # ratio
if r != 1: # if sizes are not equal
interp = cv2.INTER_LINEAR if (self.augment or r > 1) else cv2.INTER_AREA
im = cv2.resize(im, (int(w0 * r), int(h0 * r)), interpolation=interp)
np.save(f.as_posix(), im)
def cache_images_to_disk_old(self, i):
# Saves an image as an *.npy file for faster loading
f = self.npy_files[i]
if not f.exists():
np.save(f.as_posix(), cv2.imread(self.im_files[i]))修改的逻辑其实就是参照load_image函数,如果是把图片缓存到内存中(即训练参数--cache的默认值ram),则会调此函数获取resize后的图片,然后赋值给self.ims。
接下来对比一下缓存到内存中与修改后的缓存640npy的训练结果是否一样。
2.实验
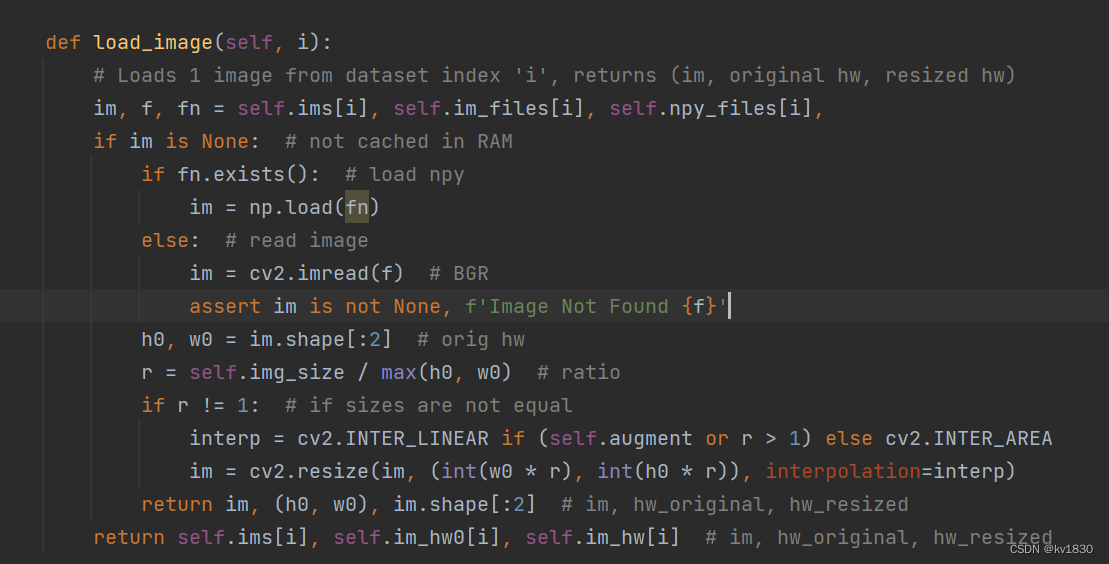
a)缓存到内存中
python train.py --data data/cityscape.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 32 --epochs 100 --hyp data/hyps/hyp.scratch-low.yaml --name cityscape_ram_test --cache --worker 4
起初是因为省时间,只训练了100轮,不过后来我发现想训练300轮的话,在90轮左右就过拟合了,也说明了640分辨率可能并不太适合用在cityscape数据集上。
另外说明一下为啥要指定worker4呢,一个是缓存到内存中后,解码完全不用时间,读取npy也是相当快的,但其实最主要的问题是:内存不够。。。,在windows上训练,worker进程与主进程基本上不共享内存(因为多进程用的是spawn模式),所以主进程加载到内存中的npy,worker进程都会复制一遍,那就是几倍的关系。
map50-95为27.6%,map50为47.4%
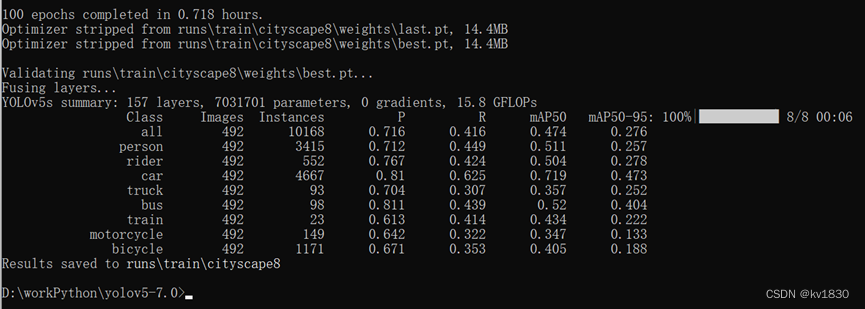
b)缓存640npy
python train.py --data data/cityscape.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 32 --epochs 100 --hyp data/hyps/hyp.scratch-low.yaml --name cityscape_cache_disk_100 --cache disk --worker 8
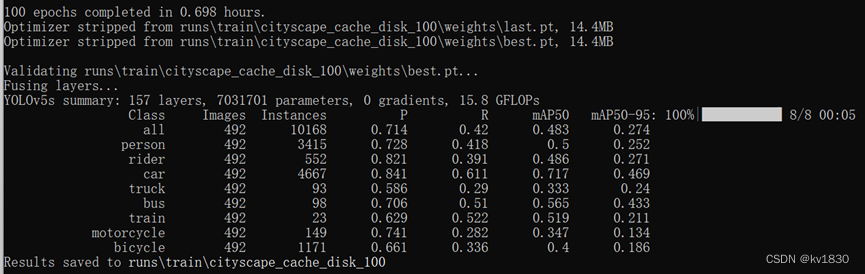
map50-95为27.4%,map50为48.3%。
两者差不多吧,map50高了0.9%,这个可能是有点随机性的差异。虽然yolov5是设置了固定随机种子,但有的时候相同条件下训练结果一样,有的时候又不完全一样。
c)接下来用缩放到640的jpg来训练
python train.py --data data/cityscape_640.yaml --cfg models/yolov5s.yaml --weights weights/yolov5s.pt --batch-size 32 --epochs 100 --hyp data/hyps/hyp.scratch-low.yaml --name cityscape_640_nocache --worker 8
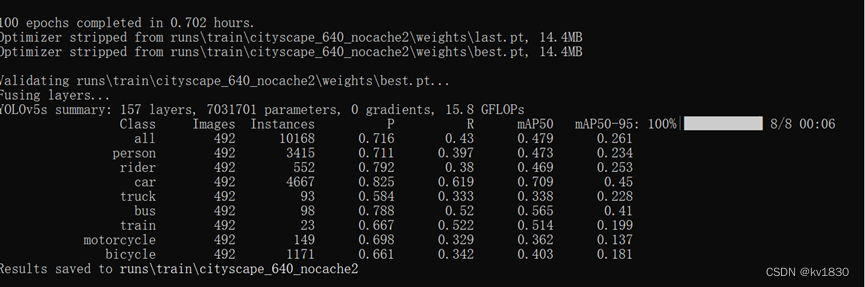
map50-95为26.1%,map50为47.9%
可以看到map50-95与640npy相比,下降了1.3%。
d)640npy与640jpg交叉验证
接下来我们用它训练的模型在原图上验证一下(其实就是原图resize到640了)
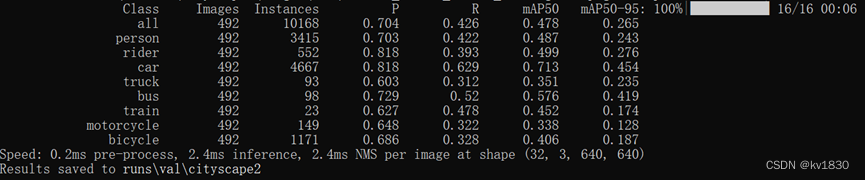
神奇地发现,map50-95居然还提升了0.4%
接着我们再用640npy训练的模型在640jpg上验证一下
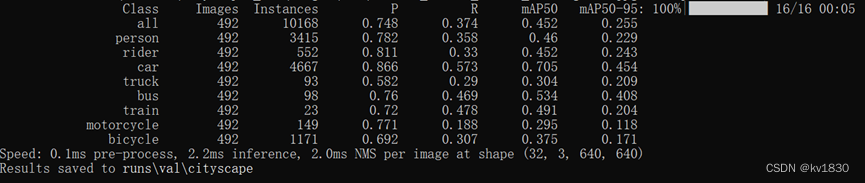
更神奇地发现,这下降的真是有点多,640npy在原图上的验证结果相比,map50-95下降1.9%,map50下降3.1%
e)数据有点多,为方便对比,放个表上来
| P | R | mAP50 | mAP50-95 | |
| 缓存到内存中 | 0.716 | 0.416 | 0.474 | 0.276 |
| 缓存640npy | 0.714 | 0.42 | 0.483 | 0.274 |
| 640npy在640jpg上验证 | 0.748 | 0.374 | 0.452 | 0.255 |
| 640jpg | 0.716 | 0.43 | 0.479 | 0.261 |
| 640jpg在原图上验证 | 0.704 | 0.426 | 0.478 | 0.265 |
对比上表,有几点发现
1)用640jpg来训练,mAP50-95略有下降,但是如果用它的模型在原图上验证,效果又会回升一点
注:这里的原图指的是原图resize到640哦
2)用640npy训练的模型,在640jpg上验证,性能下降地更明显
3)所以说首先可肯定的是,640jpg的训练与原图训练绝对是不一样的,具体选择哪种方案来训练,就看你最终会在什么样的场景下去使用你的模型,如果你推理的时候都是用大图推理(即大图resize到640直接推理,而不是拿个640的jpg来推理),那就用640npy的方案就行了。
4)至于为什么640npy训练的结果在640jpg上是最差的,可能的原因是640npy里的超像素信息比较多,训练的时候模型比较依赖这些超像素的信息,而你现在验证的时候没有这些信息了(或者说损失掉了较多的信息),那自然是会导致性能下降的
3.但是如果我就是有可能要用640jpg呢
如题,如果我就是有可能在推理的时候,就是有可能会遇到小图的jpg(当然,大图的也有),那其实也很简单啊,就是让你的模型看到更多的情况就行了。但是如果训练集中只有大图,手动制作一批640jpg的副本,似乎有点浪费空间。其实完全可以在训练的过程中动态实现。
在yolov5的数据集类的LoadImagesAndLabels.__getitem__()方法中(utils/dataloaders.py),会调一个数据增强的方法,注意上面的self.augment在训练集中默认是True
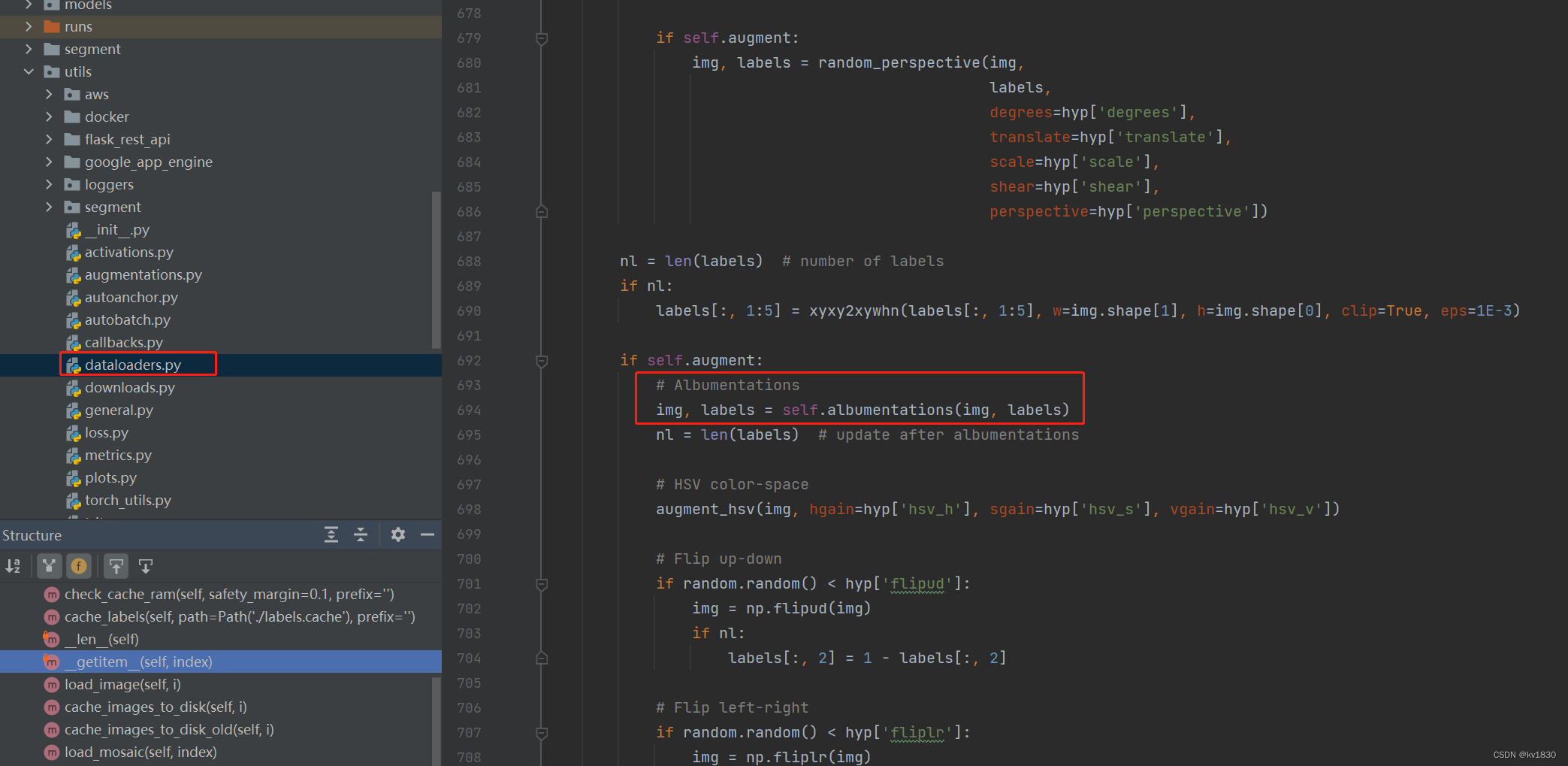
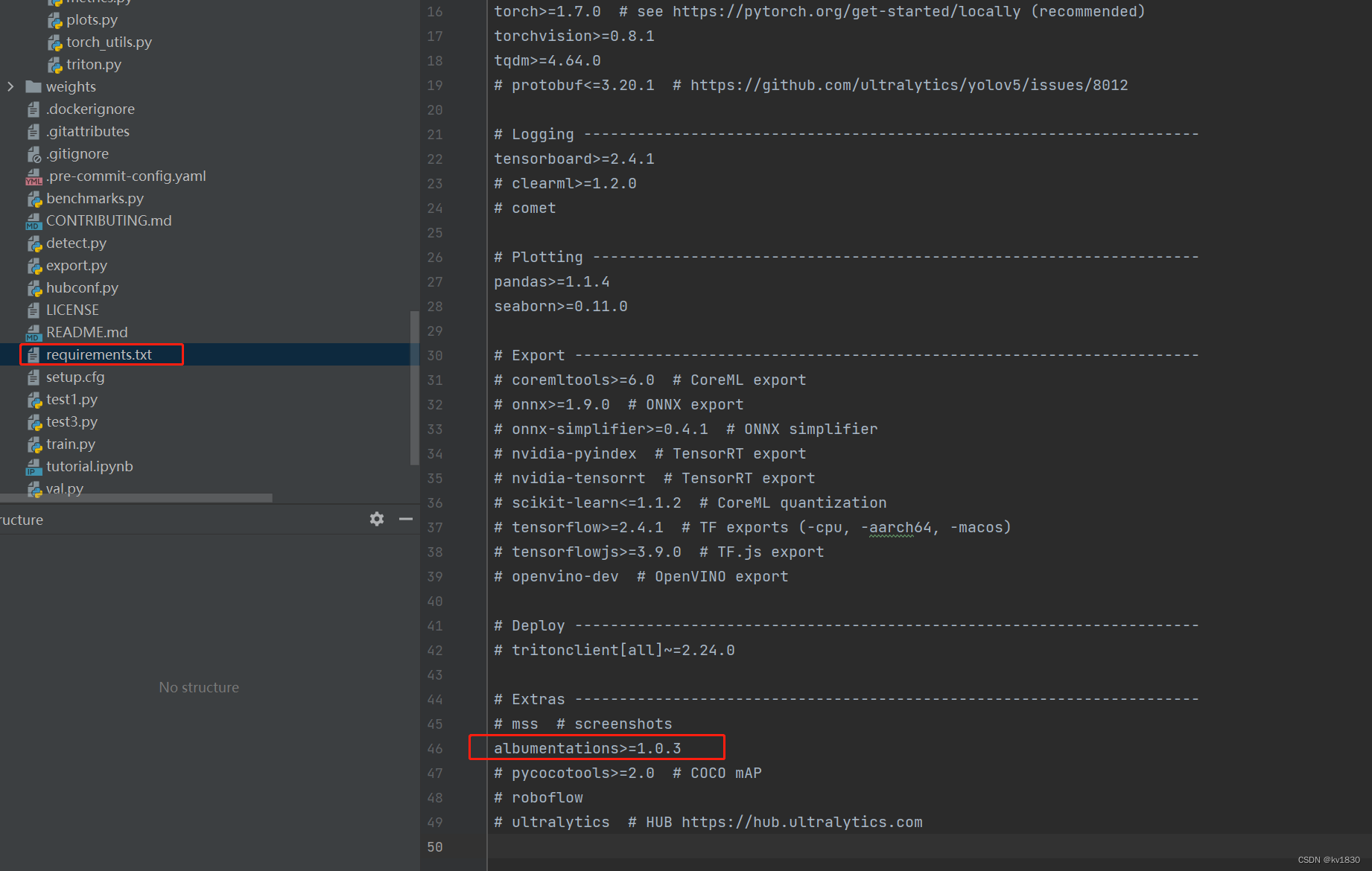
其对应代码在utils/augmentations.py中,红框中就是jpg压缩增强,这里的概率p原来写的是0.0,我改成0.1了,即让它在训练的时候,会有10%的概率动态地把图片做jpg压缩,压缩质量范围就是quality_lower(这里写的75)到quality_upperI(默认100)。另外上面还有模糊增强,只是使用的概率更小,只有1%,这些也可能会提升模型的鲁棒性。
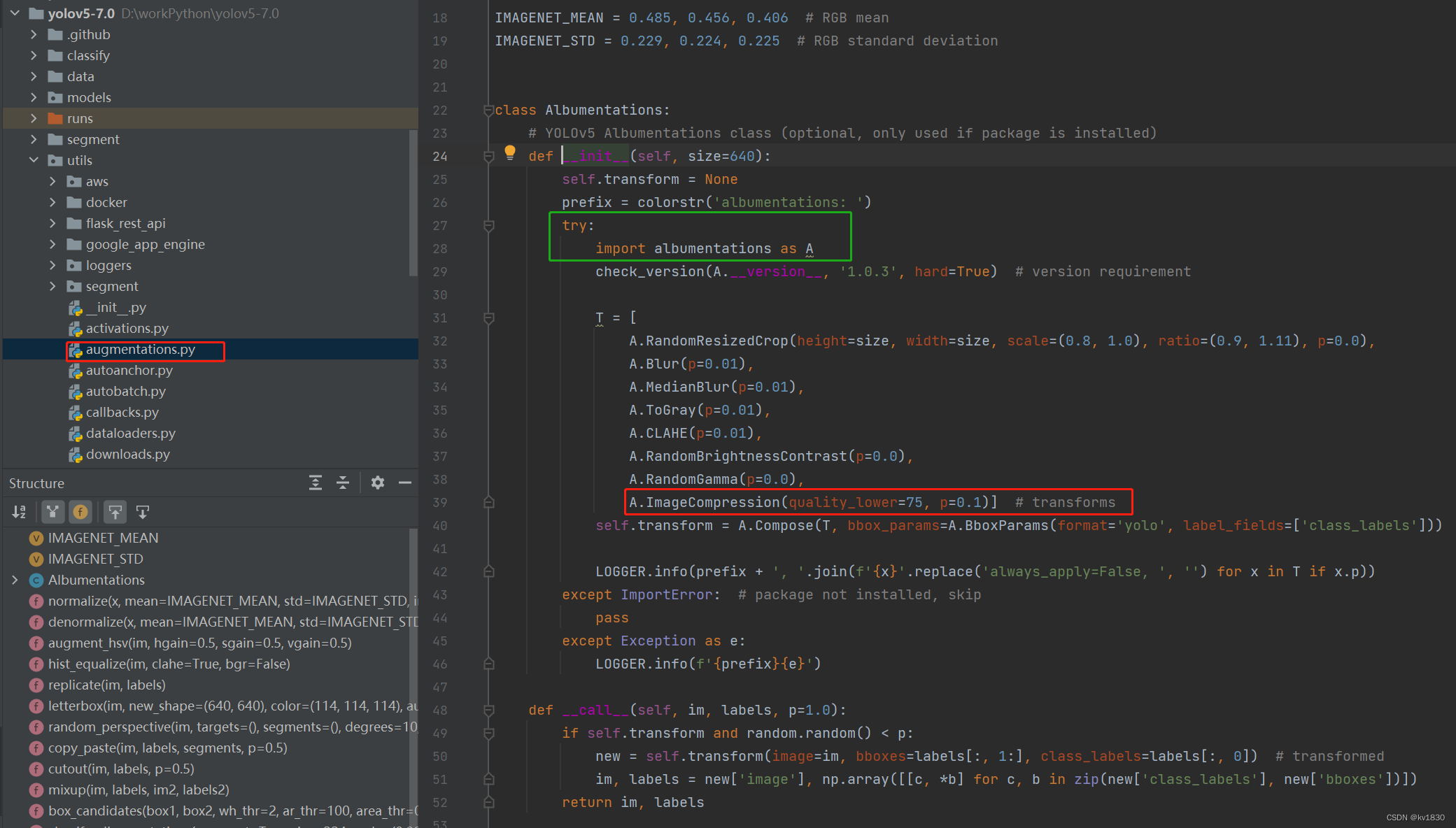
还有一点要注意,即上图中的绿框,它为啥要在try-catch里面来导入增强模块呢,因为yolov5的requirements.txt里面其实没让你装albumentations包,它是注释掉的!你得取消注释,装一下才行。下图我已经取消注释了。
接下来还是用640npy训练,但是这次是开启了10%概率的jpg压缩增强哦,省时间还是100轮~~
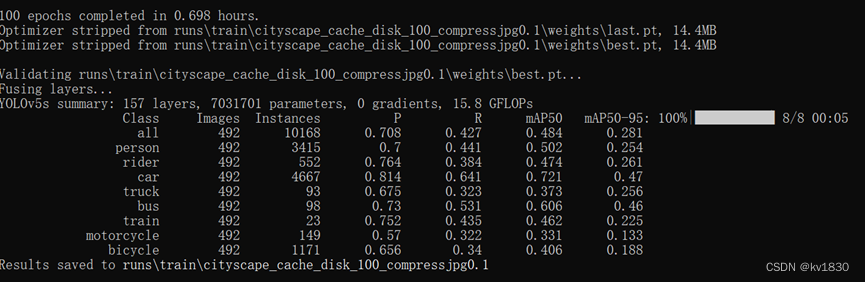
达到了最高的mAP!
然后在640jpg上再验证一下
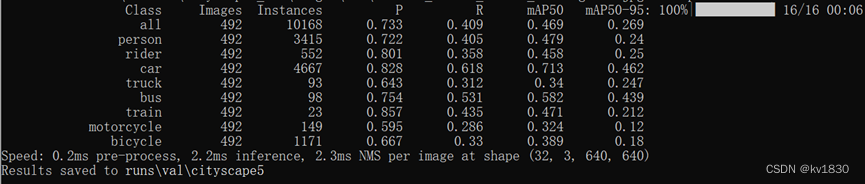
与原图的验证效果,还是有下降,但是下降地比之前小了一些。并且它的mAP50-95比直接用640jpg训练还要高。另外可能跟训练轮数也有关系,100轮,10%的概率jpg增强,触发增强的次数比较少,并且提高了增强强度后,可能更不容易过拟合了,300轮可能会达到更好的效果。
直接上汇总表对比
| P | R | mAP50 | mAP50-95 | |
| 缓存到内存中 | 0.716 | 0.416 | 0.474 | 0.276 |
| 缓存640npy | 0.714 | 0.42 | 0.483 | 0.274 |
| 640npy在640jpg上验证 | 0.748 | 0.374 | 0.452 | 0.255 |
| 640jpg | 0.716 | 0.43 | 0.479 | 0.261 |
| 640jpg在原图上验证 | 0.704 | 0.426 | 0.478 | 0.265 |
| 缓存640npy(开启jpg增强,0.1概率) | 0.708 | 0.427 | 0.484 | 0.281 |
| 缓存640npy(开启jpg增强) 在640jpg上验证 | 0.733 | 0.409 | 0.469 | 0.269 |
二。更多细节
1.坐标超像素
大图resize到小图,可以具有超像素信息。对应的物体边框其实也是可以有超像素信息的。如果你在缩放图片后,使用的是缩放后的舍去小数位的坐标,有可能会导致模型训练效果下降哦。
由于yolov5所使用的标注文件中是以小数形式的相对坐标宽高来保存边框,所以你不需要过多地去关注它(只要你小数点后保留精度不要太低就行,保留6位基本就够啦)。
但如果你用的不是yolov5,并且你需要提前缩放图片来加速训练,那你就需要仔细关注一下边框坐标的问题了。比如你用的算法可能需要用coco数据集、voc数据集,它们用的都是绝对坐标。你如果要提前制作一份缩放后的数据集,那你应该用带小数位的坐标,并且你还要关注一下你所用的算法是怎么去使用这些坐标的,如果解析的时候仍然是当作整数来用(有可能报错,也有可能舍小数位),那你得把它们改改,最终保证整个流程一直走到损失计算的时候,都不会丢失小数位才行。
2.对齐精度
由于你额外处理了数据集,可能会担心影响模型性能,尤其是如果在处理过程有严重错误地话,那可能就不是影响性能这么简单了。所以你需要先验证一下你改的对不对,最起码保证同一个模型,在你缩放后的数据集上的验证结果,与在原图上的验证结果是一样的。
那你就要注意一些细微的细节
a)图片缩放方法是否一致
比如yolov5缩放图片的时候,长边缩放到640,缩放比例为r,短边用r缩放后如果结果不为整数,那就舍掉小数位(所以实际上长短边的缩放比例可能不一样哦),那么你想对齐验证精度的话,你最好是保证跟它完全一致。否则可能验证结果就是有那么一点点差别,然后你又不知道这是为什么,就挺难受(可能也有点担心,我是不是哪错了~~)。
并且不是什么算法都是这么缩放的,比如mmdetection,它就不是直接舍掉那个小数位,而是用4舍5入的方式。所以你需要仔细去看一下你所用的算法代码。
尤其是如果你用的是绝对坐标,并且需要自己去缩放坐标的时候,这就更重要了,因为上面只是涉及到让模型看到的图片可能会有一点点差别,而你缩放坐标如果没有正确处理长短边的缩放比例,你这就不是差别,而是差错了。你本意是让模型能用到超像素的边框坐标,而你实际上可能让它用了错误的边框坐标,虽然只有那一点点错,但可能反而让你达不到超像素的效果。
b)算法代码会不会有坑?
还真可能有,如果原来的算法代码在缩放的时候,就有那么一点点差错,那你自然就对齐不了了,所以在你确认自己没错的时候,就仔细看看算法代码是不是他自己就错了~~
三。batch-size8和16、32,为啥没区别?
如果没做读图加速,并且使用的就是s级别的小模型,有可能会发现,用batch-size8训练一轮,与用batch-size32训练一轮,居然没有明显区别。比如我在公司的V100环境,用的是mmdetection,yolox-s级别的模型,就观察到这种情况。就算图片加载慢,但batch8完全不可能充分利用到显卡算力,我batch32总能在GPU计算这一块节省不少时间吧?
其实加载数据与GPU计算(前向推理、反向传播)这两者不是串行的,而是并行的,当然前提是dataloader的worker不是0,所以它们其实是木桶效应。
在你开启迭代dataloader之后,worker们就开始加载图片啦,比如你要batch8,它们并不是搞到8个处理后的图片给你后就休息了,它们会事先多加载一点,然后给你,你去GPU计算的时候,它们又会去继续加载,当然不是无限加载啊,具体的调度算法我没有去看。但是在它们加载图片比较快的时候(即存在空闲期的情况下),它们绝对不会出现较大的延时,就是说你每次要图的时候都能立马给你,让你的GPU尽量不等待。
但是如果加载图片慢,那就真没办法了,不是worker们偷闲,人家全速运转都满足不了你的需求。此时你把batch8提升成batch32,那肯定是一点用都没有,因为此时的总体运行时间就是图片加载时间,你把batch8提升成batch32,只会让GPU的闲时占比更高,不会有其它变化。
所以如果情况反过来,你要训练yolov5l,yolov5x级别的模型,很可能此时木桶的短板变成了显卡,而不是加载图片,那你就完全不用管加载图片的事情了。但是如果你想省电、或者延长CPU使用寿命、或者降低CPU温度的话,你还是可以去优化一下的~~
你可能会说,上面的木桶短板说法是不是你猜测的?我们跑一个具体的例子来验证一下。
1.取数据比GPU计算快
from torch.utils.data import Dataset, DataLoader
import torch
from datetime import datetime
import time
def colorstr(*input):
# Colors a string https://en.wikipedia.org/wiki/ANSI_escape_code, i.e. colorstr('blue', 'hello world')
*args, string = input if len(input) > 1 else ('blue', 'bold', input[0]) # color arguments, string
colors = {
'black': '\033[30m', # basic colors
'red': '\033[31m',
'green': '\033[32m',
'yellow': '\033[33m',
'blue': '\033[34m',
'magenta': '\033[35m',
'cyan': '\033[36m',
'white': '\033[37m',
'bright_black': '\033[90m', # bright colors
'bright_red': '\033[91m',
'bright_green': '\033[92m',
'bright_yellow': '\033[93m',
'bright_blue': '\033[94m',
'bright_magenta': '\033[95m',
'bright_cyan': '\033[96m',
'bright_white': '\033[97m',
'end': '\033[0m', # misc
'bold': '\033[1m',
'underline': '\033[4m'}
return ''.join(colors[x] for x in args) + f'{string}' + colors['end']
def get_time_str():
return datetime.now().strftime('%Y/%m/%d %H:%M:%S.%f')[:-3]
class MyDataSet(Dataset):
def __init__(self):
self.data = list(range(20))
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
print(f'{get_time_str()}:{torch.utils.data.get_worker_info().id}:reading...')
time.sleep(0.3)
result = self.data[idx]
print(f'{get_time_str()}:{torch.utils.data.get_worker_info().id}:return {self.data[idx]}')
return result
if __name__ == '__main__':
train_data = MyDataSet()
train_loader = DataLoader(train_data, batch_size=4,
shuffle=True,
num_workers=2)
start_time = time.time()
for i, item in enumerate(train_loader):
print(colorstr('red', 'bold', f'{get_time_str()}:main:predict {item}'))
time.sleep(0.7)
print(colorstr('red', 'bold', f'{get_time_str()}:main:predict end'))
print(f'耗时{(time.time() - start_time)}秒')代码很简单,数据集里面有20个数字,数据集每取一项都耗时0.3秒(用sleep模拟),dataloader的batch设为4,因为有两个worker并行,所以取一次数据的总时间就是0.3秒。而取到数据后进行GPU计算需要0.7秒(还是用sleep模拟),所以说每推理一次的耗时大于取数据的时间。并且在取数据的开始结束,推理的开始结束都打了日志,那我们看看主进程到底会不会存在等待取数据而导致GPU闲置的情况。
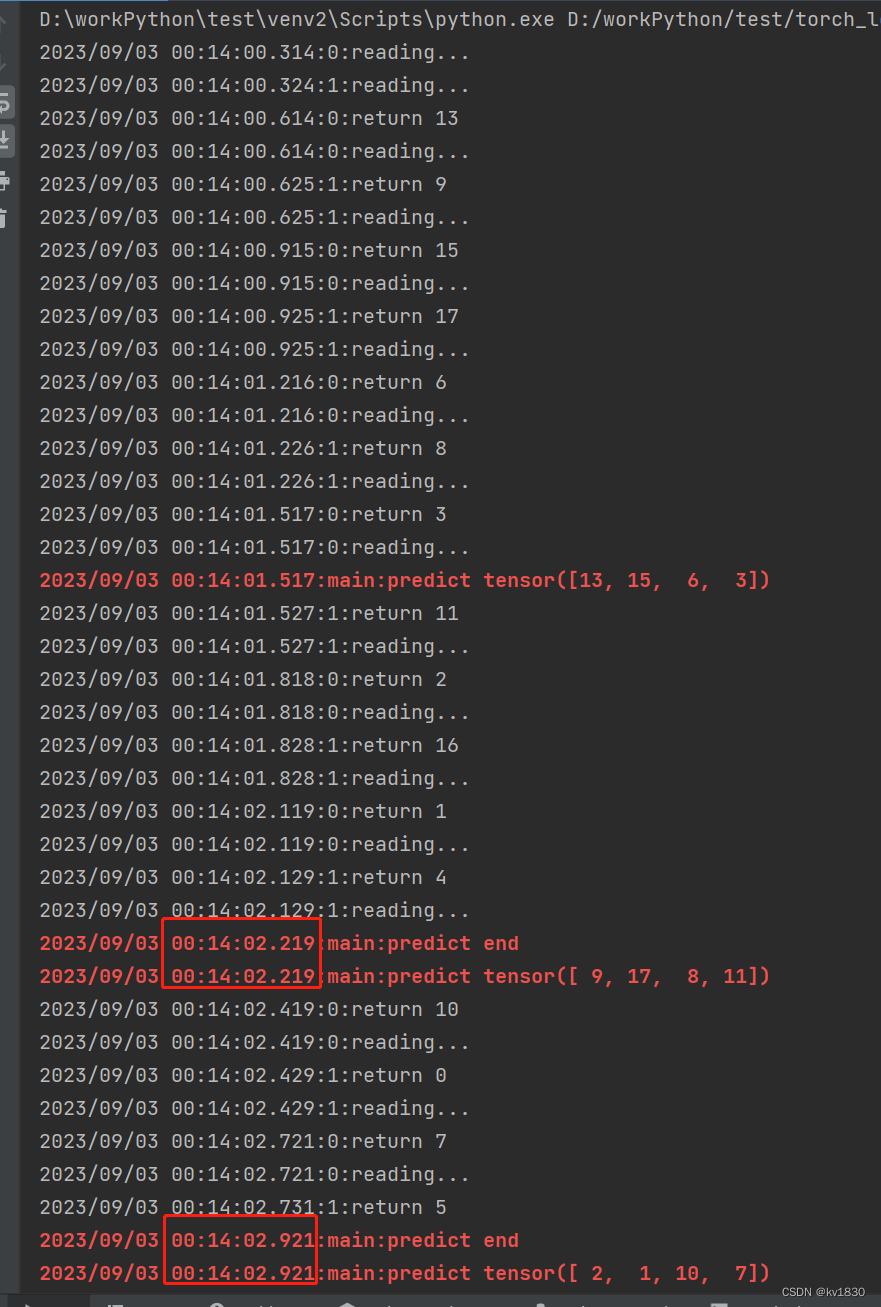
可以看到,在毫秒级是没有等待的哦(这里为了方便观察,借用了yolov5里面的colorstr函数,可以在控制台打印带颜色的字符)。并且会发现,第一次迭代dataload的时候,它会先多取一些数据,然后再返回给主进程,这样做的好处就是,如果取数据和GPU计算的时间差不多,接下来大家就可以不间断地并行执行了。
2.取数据比GPU计算慢
不重复贴代码了,就是修改一下两处sleep的时间就行了,改为每取一次数据0.7秒,每计算一轮0.3秒。
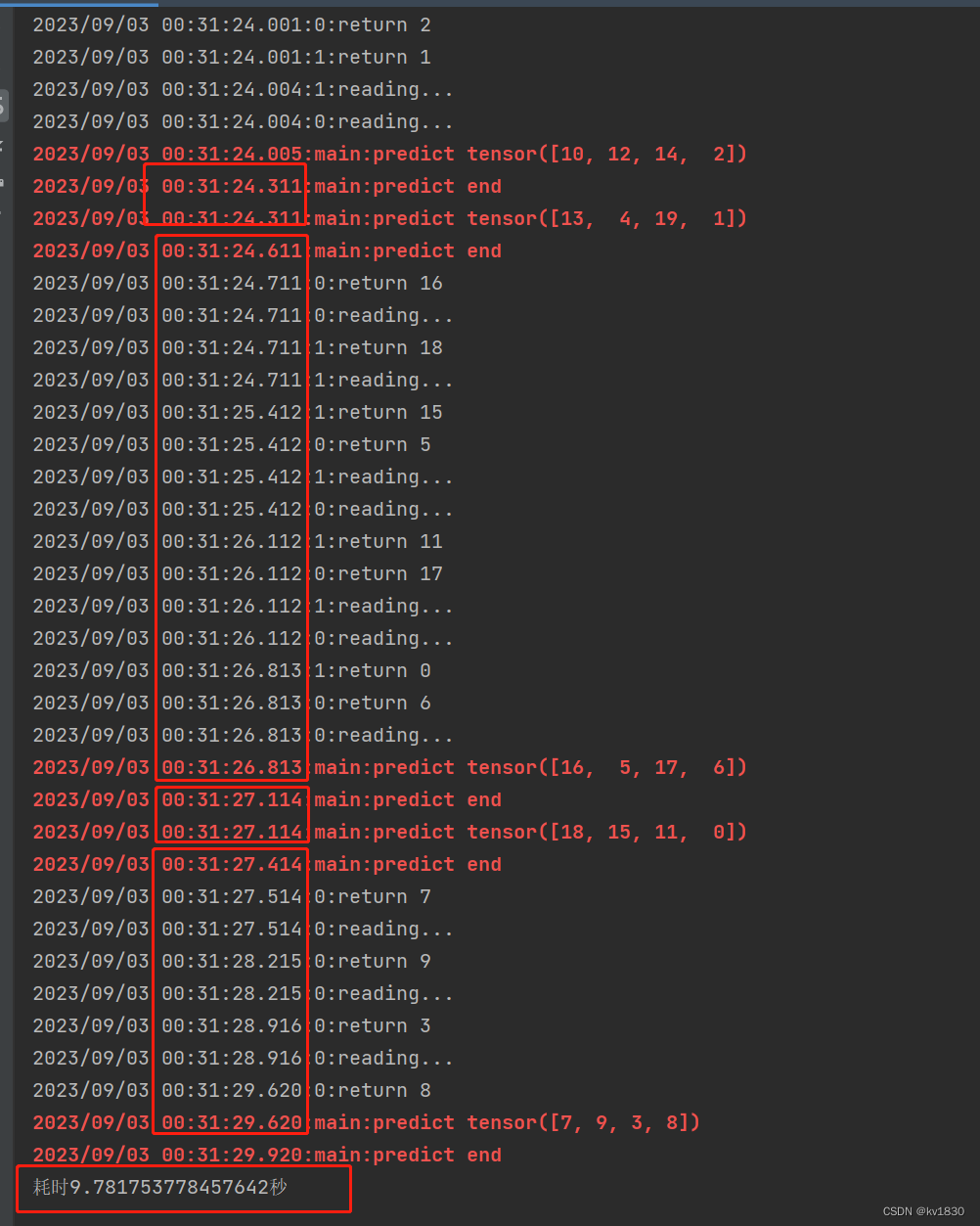
耗时9.78秒,可以看到主进程有两轮没等,有两轮等了。那两轮没等是因为dataloader攒齐了两轮的数据一次性给主进程了,但是这样也改变不了终将要等的局面。
3.取数据比GPU慢,并且提升batch-size
直接把batch-size调为8,并且模拟GPU计算的一轮时间仍然是0.3秒,因为我们模拟的场景是,batch-size为4的时候,不能充分利用GPU,而8仍然没有发挥GPU的全部性能。所以计算一次的时间自然就不变啦。但是这样能不能缩短整体的运行时间呢?
还是直接贴一下改动的地方
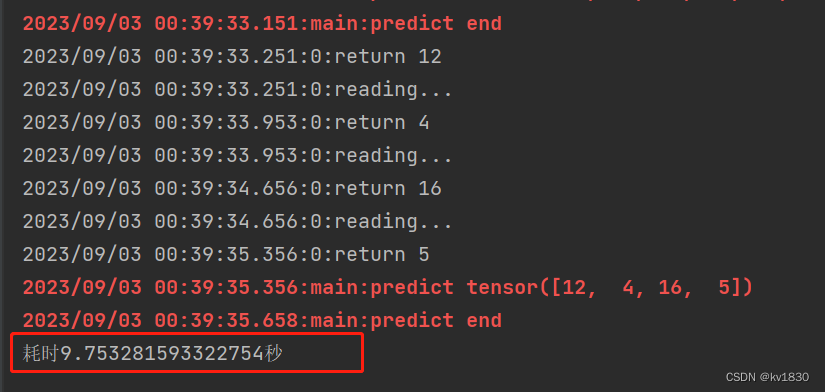
耗时9.75秒,每次运行时间不完全一样,几乎没有节省什么时间。
注:如果你提升num_workers,那肯定是会缩短总体运行时间的(因为我们是用sleep来模拟CPU计算时间的,它实际上完全不占CPU),但是我们设定的场景是2个worker已经让cpu满负荷了,所以不能作弊!
4.取数据比GPU慢,并且继续提升batch-size
之前已经说了不会缩短时间,但这里想说的是,这还甚至有可能会延长时间哦,现在把batch设为16,每一次计算时间仍然不变,仍然是0.3秒
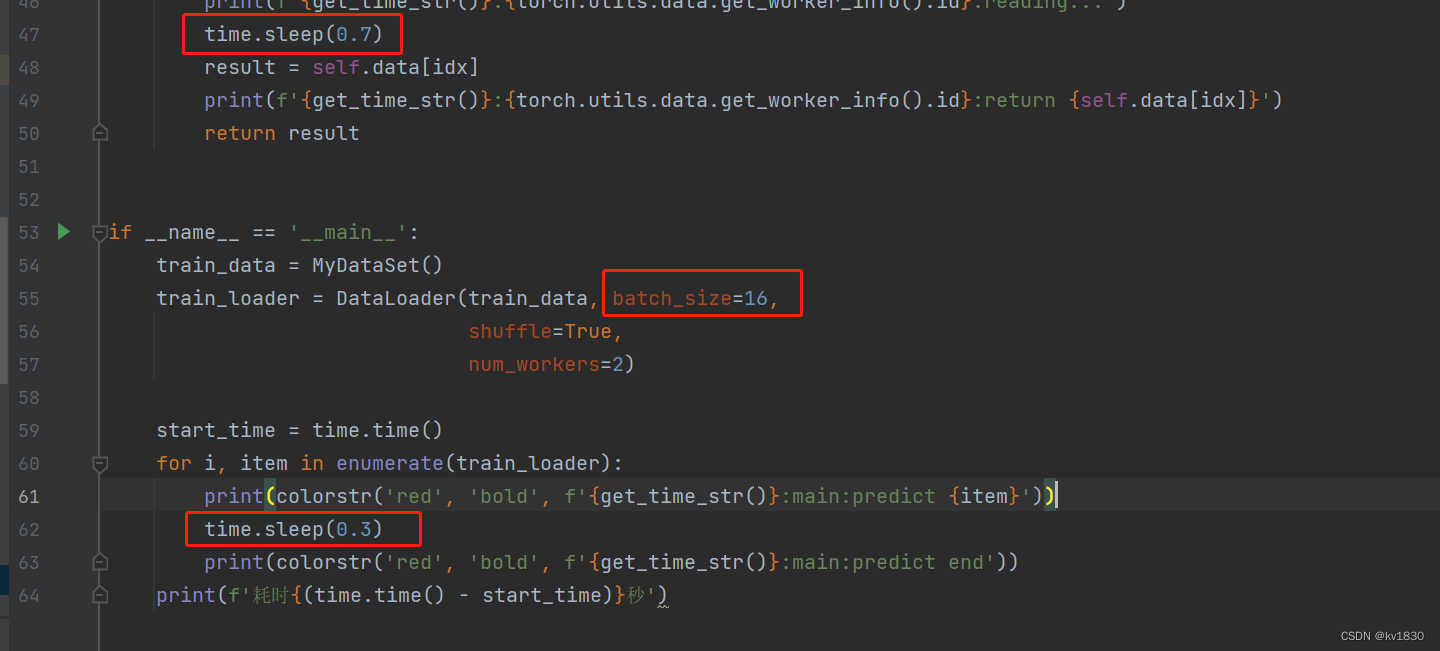
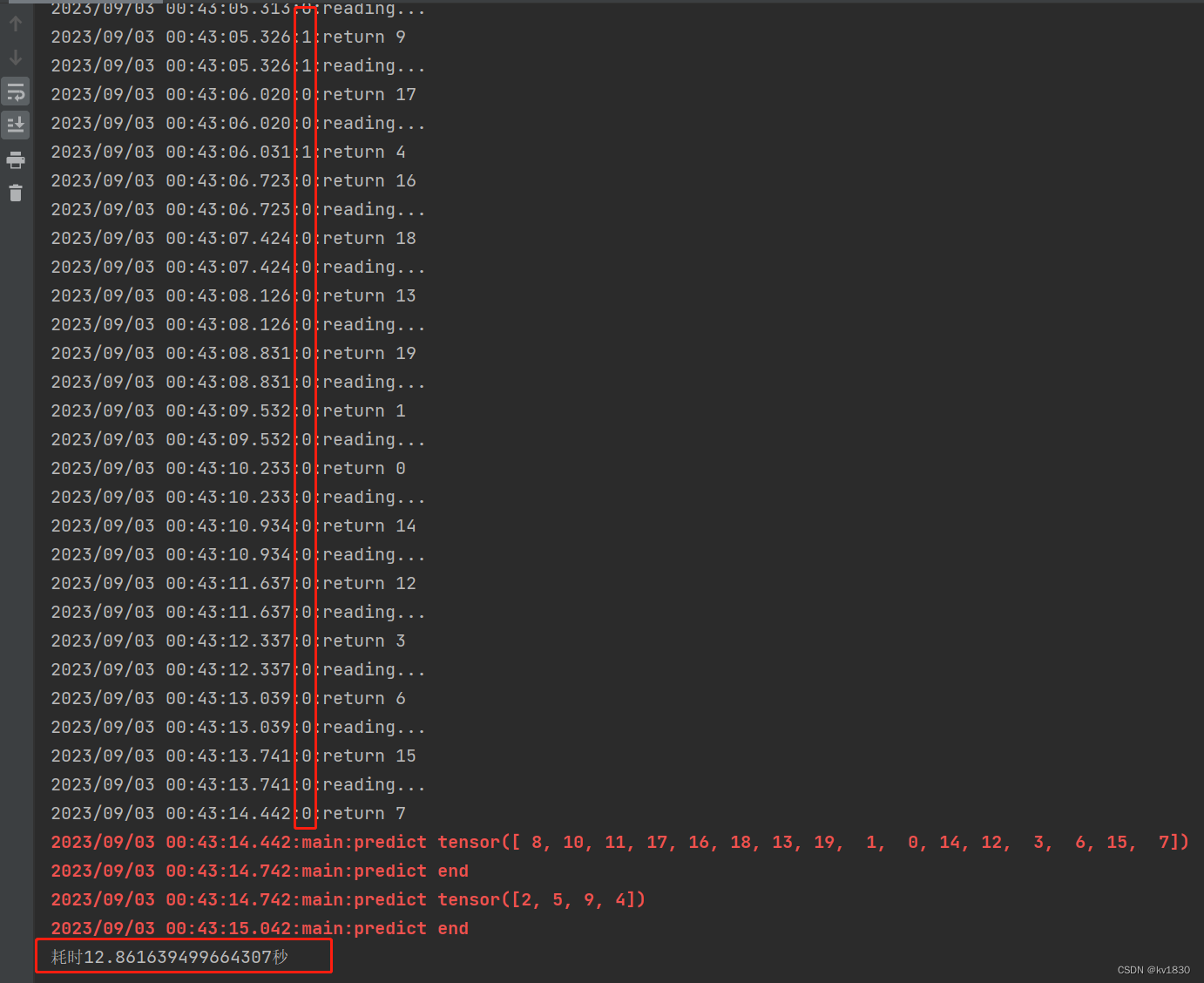
见证奇迹的时间到了,耗时12.86秒,一开始取数据,两个worker是并行取的,但到了后面,全是worker0在取,worker1到一旁休息去了!这就非常有意思了,有时间要研究研究dataload的源码看看。
另外,如果你把batch设为20的话,你可能会发现,全程都只有worker0在工作,worker1压根就没来!