【2023最新】Python 百度贴吧 爬取文本作者以及图片
前言
今天爬取百度贴吧
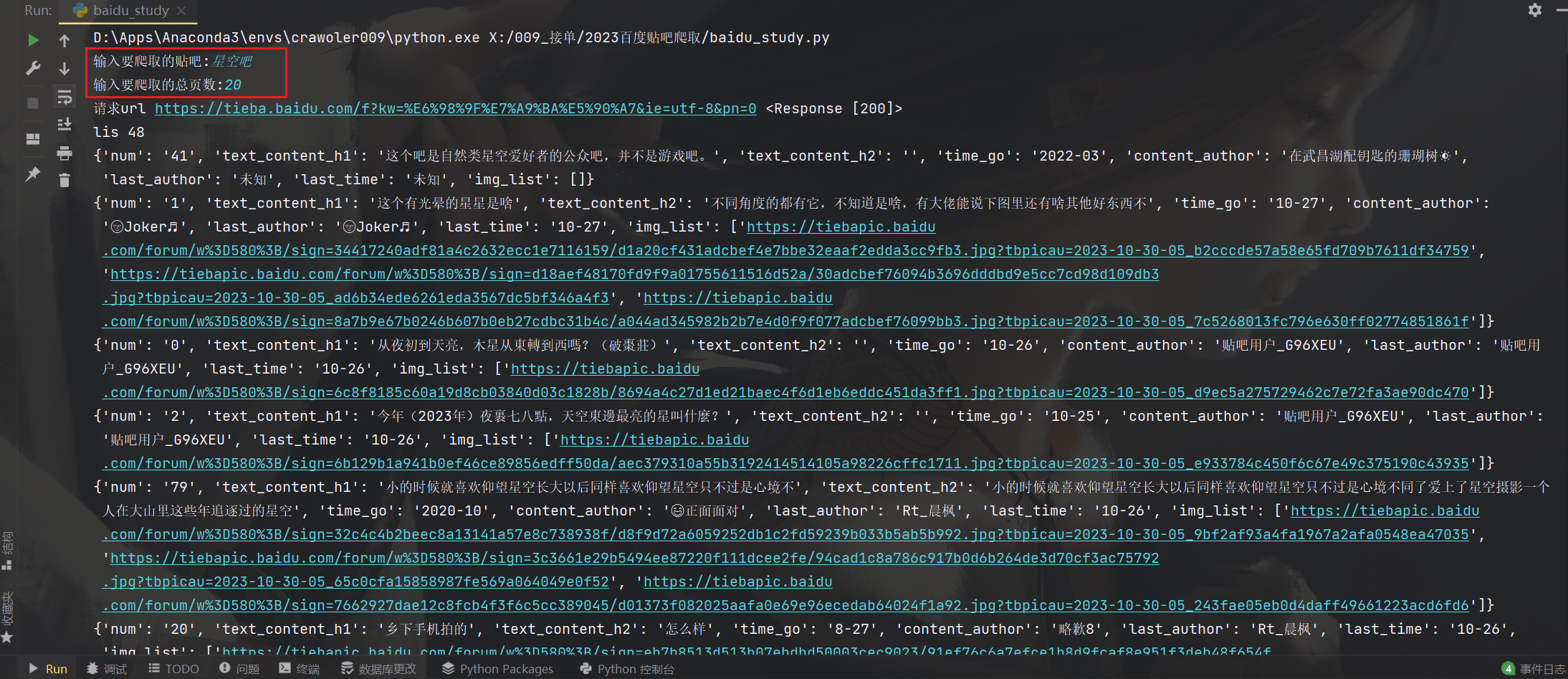
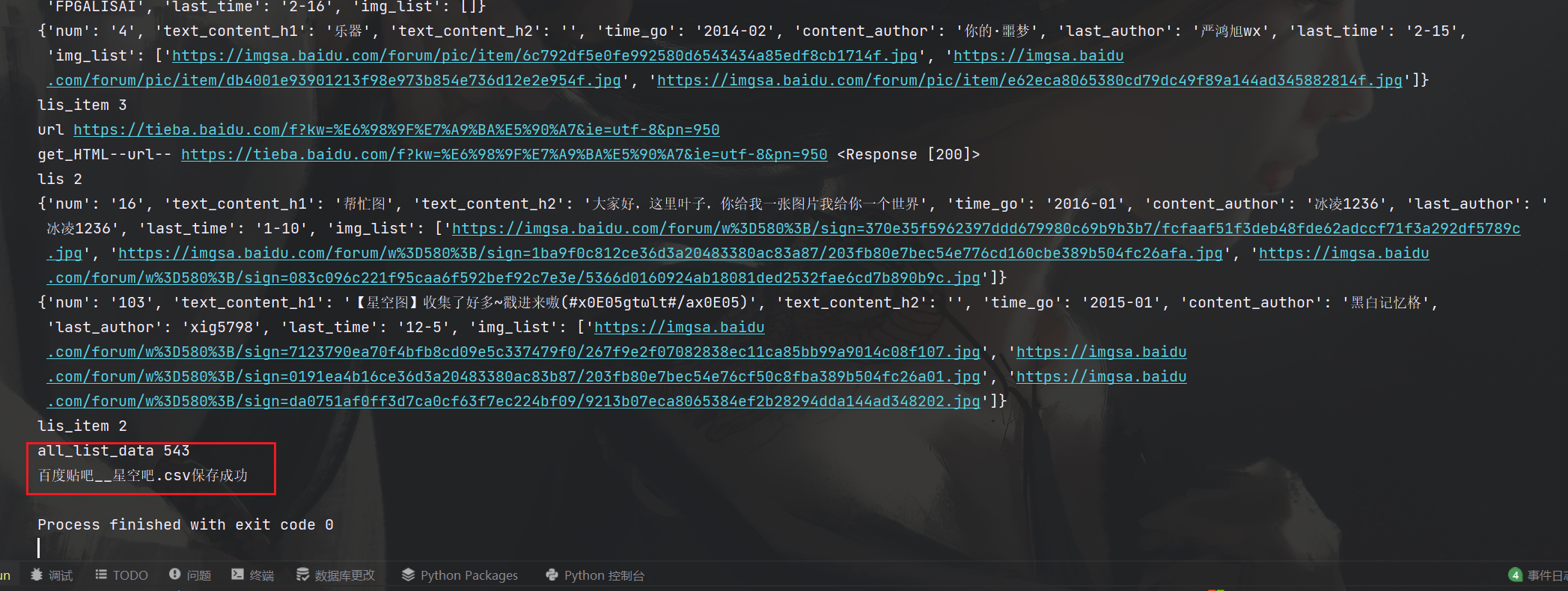
先看效果
可以输入爬取贴吧名,爬取的总页数,爬取的字段有帖子id,标题,内容,发表作者,发表时间,最后回帖人,最后回帖时间,图片
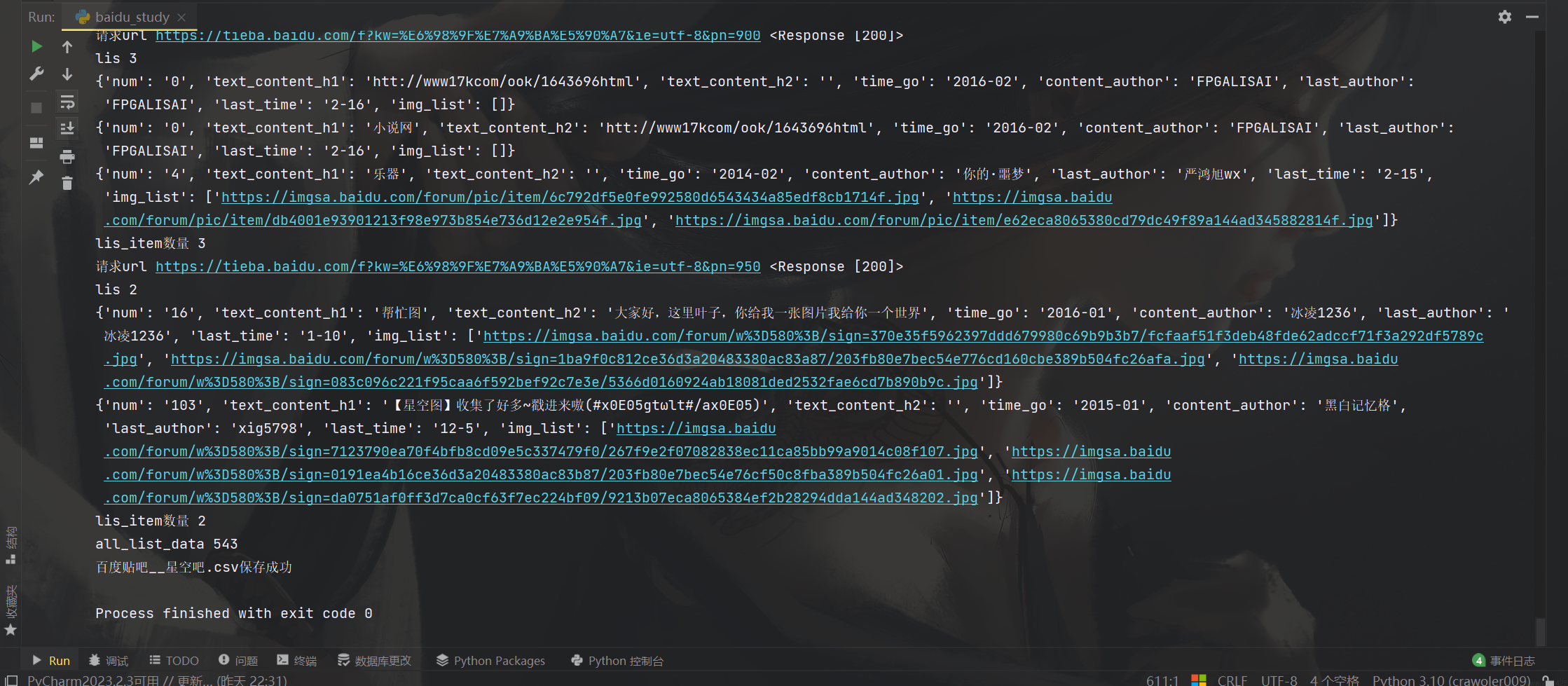
爬取的时候看到中间有几个url请求了0条评论,我们看下
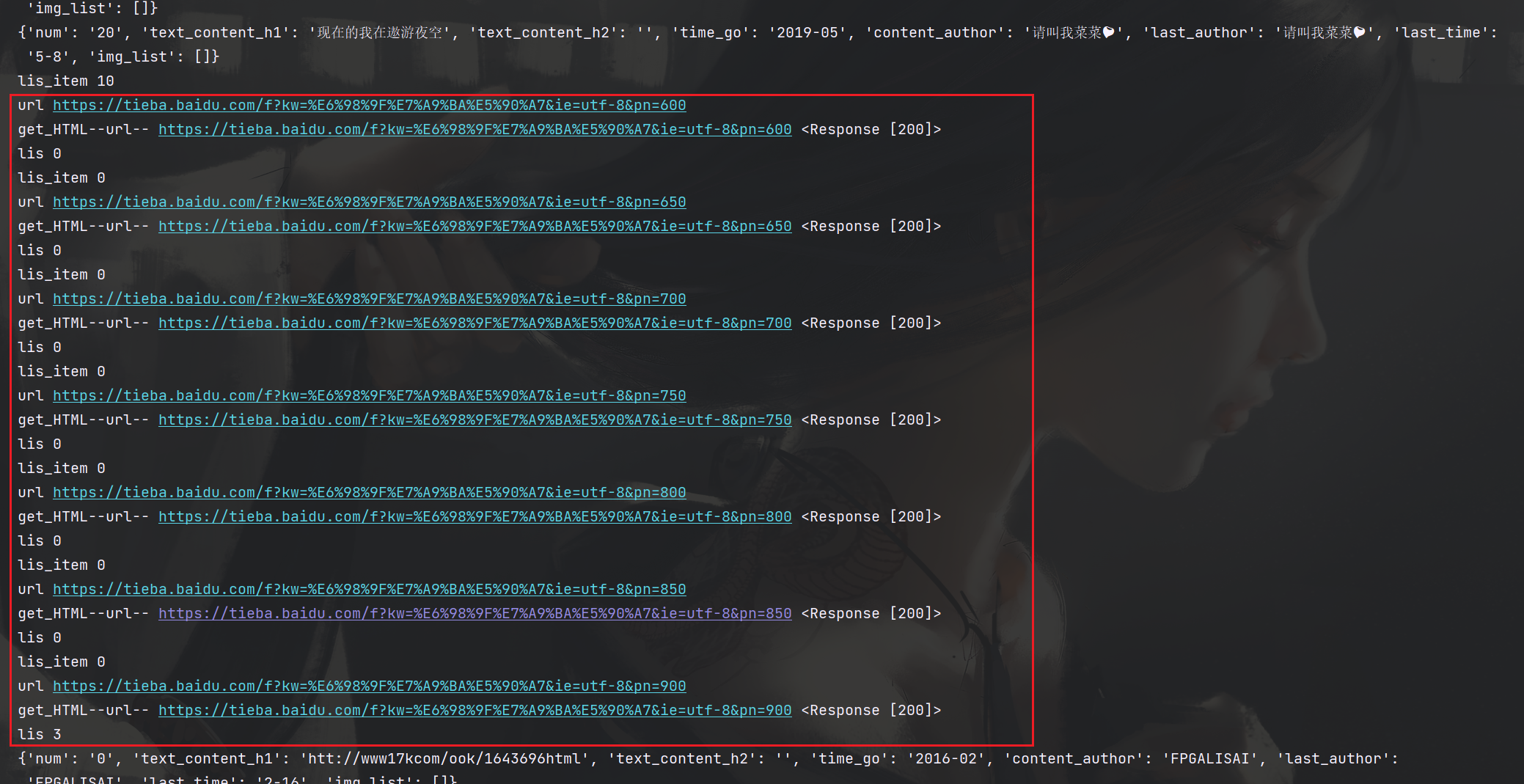

不是反爬的问题,是网站没有
我们再看看爬取的图片
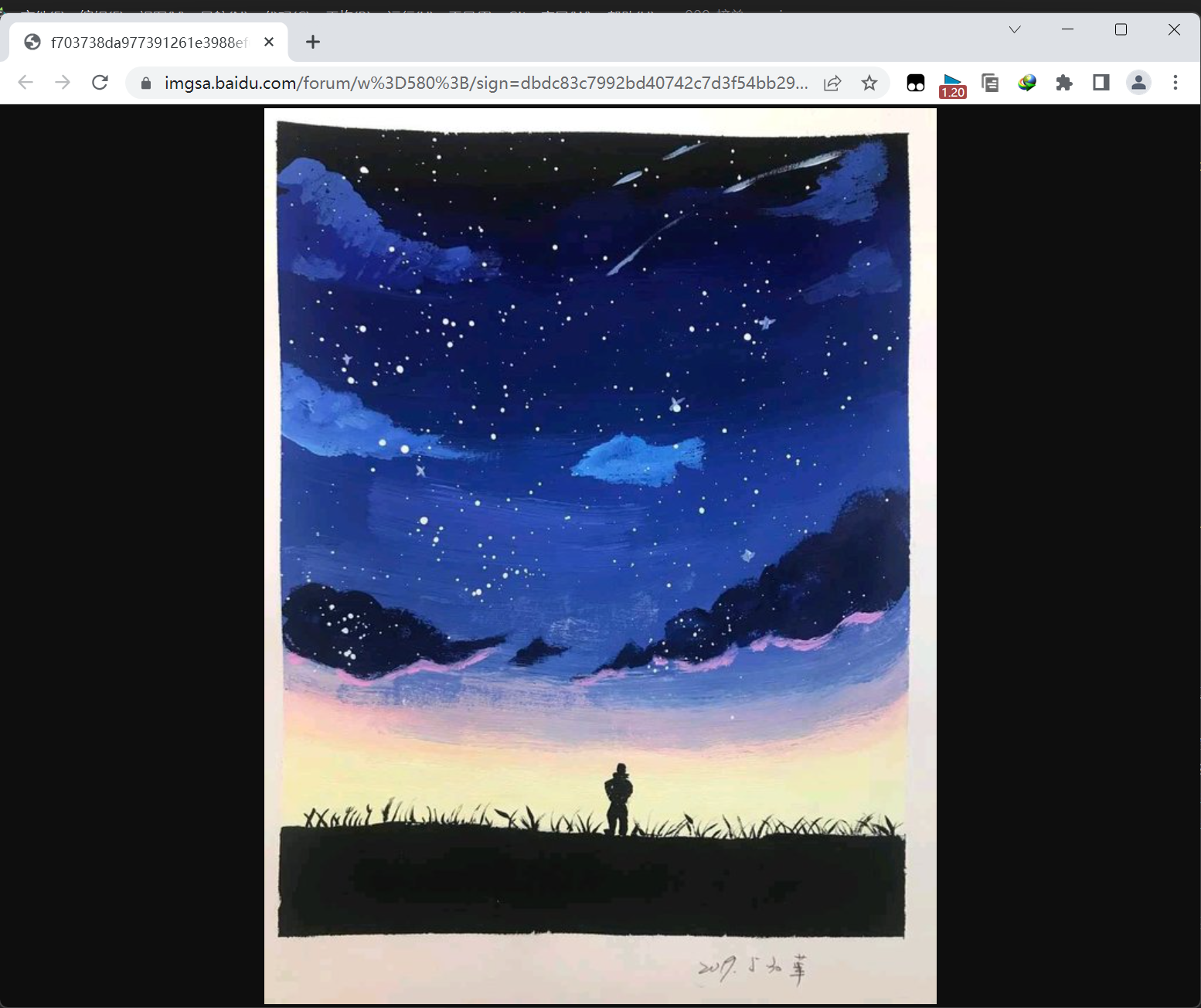
可以看到,图片也是大图没有问题
教程开始
1 分析百度贴吧
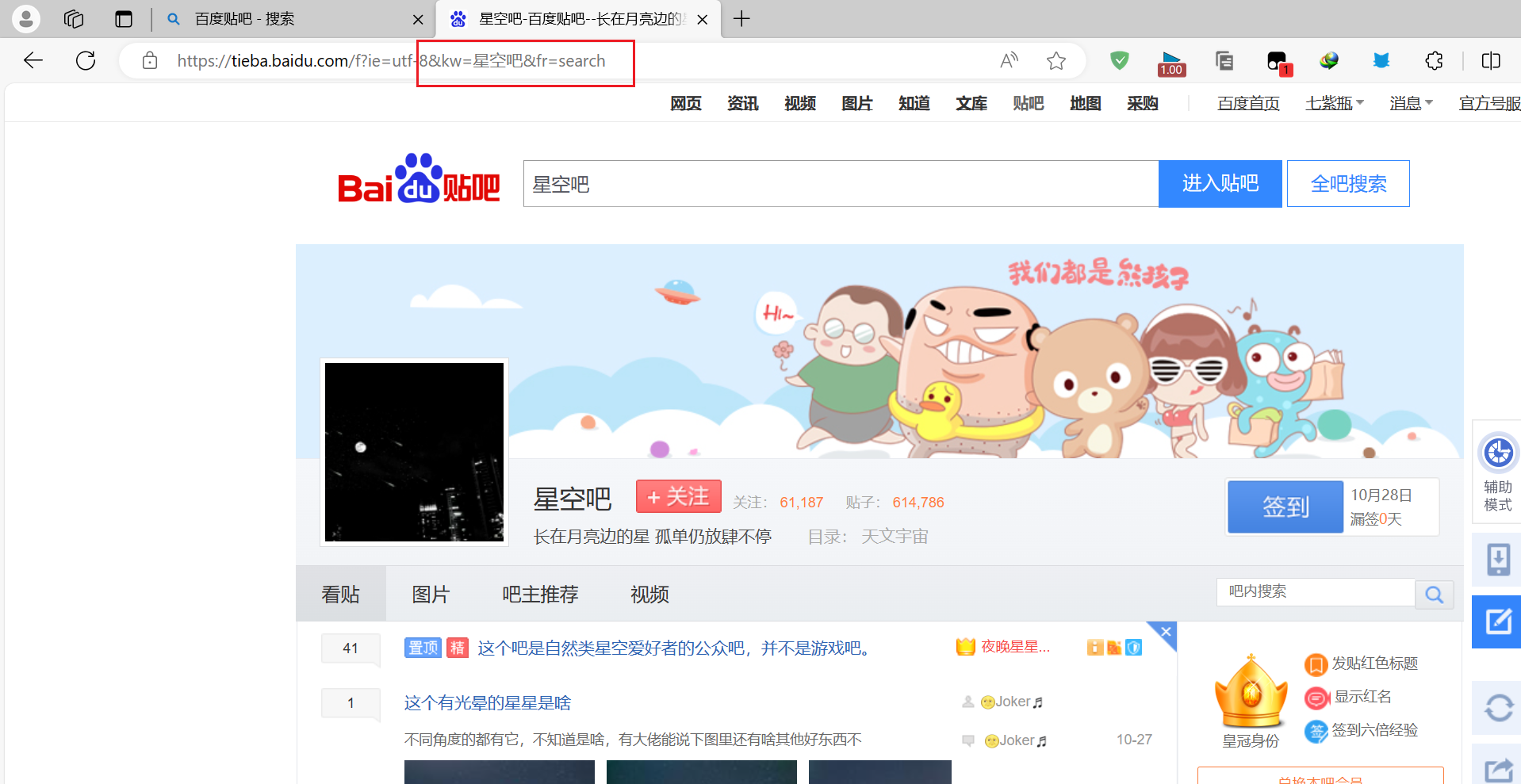
首先搜索贴吧
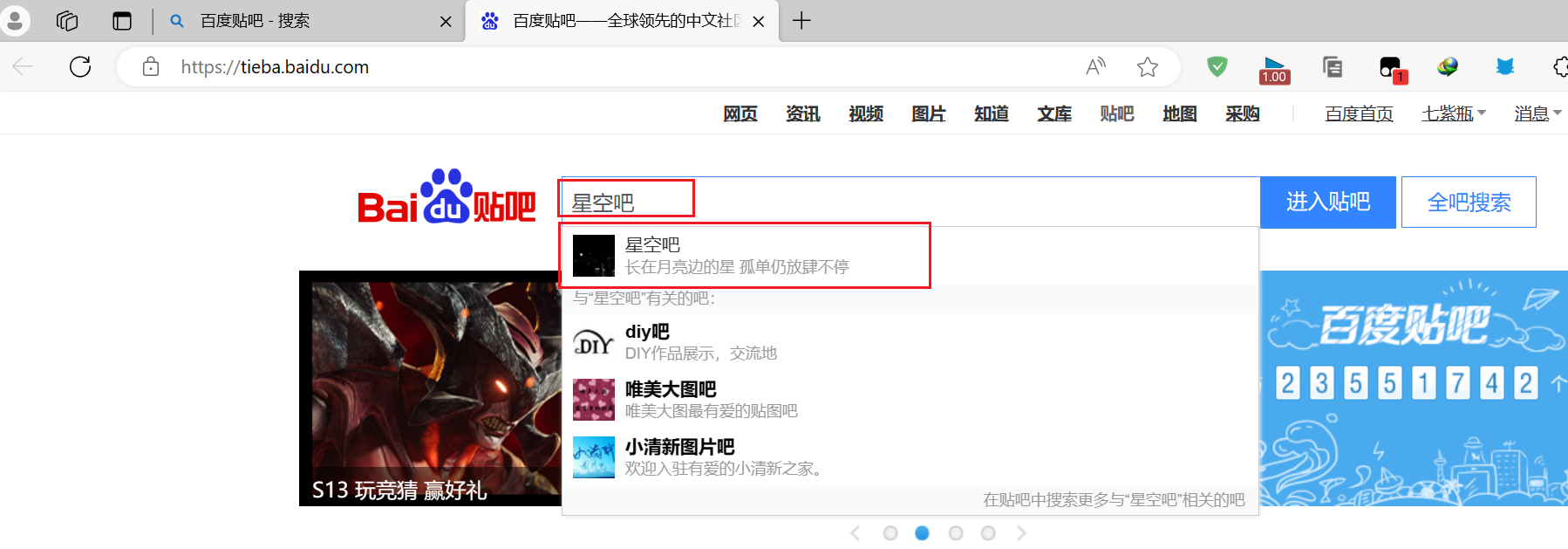
可以看到url后面多了几个参数,我们翻到第二页继续观察
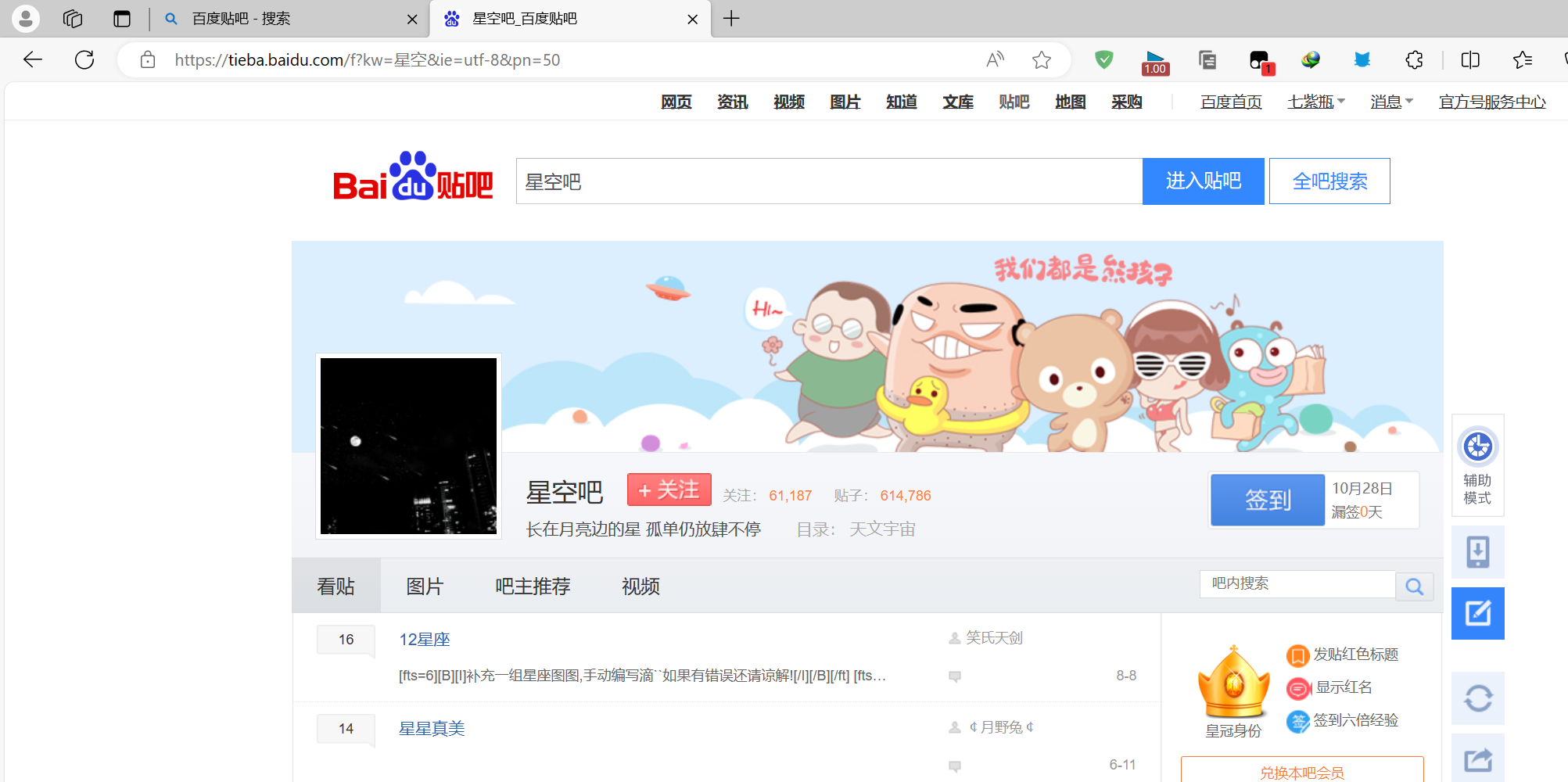
可以看到,百度贴吧的参数就是 kw 为搜索的关键词 ie为编码 pn为页码 一页为50
分析好url后我们就开始看他是静态资源还是动态资源
右键查看页面源代码
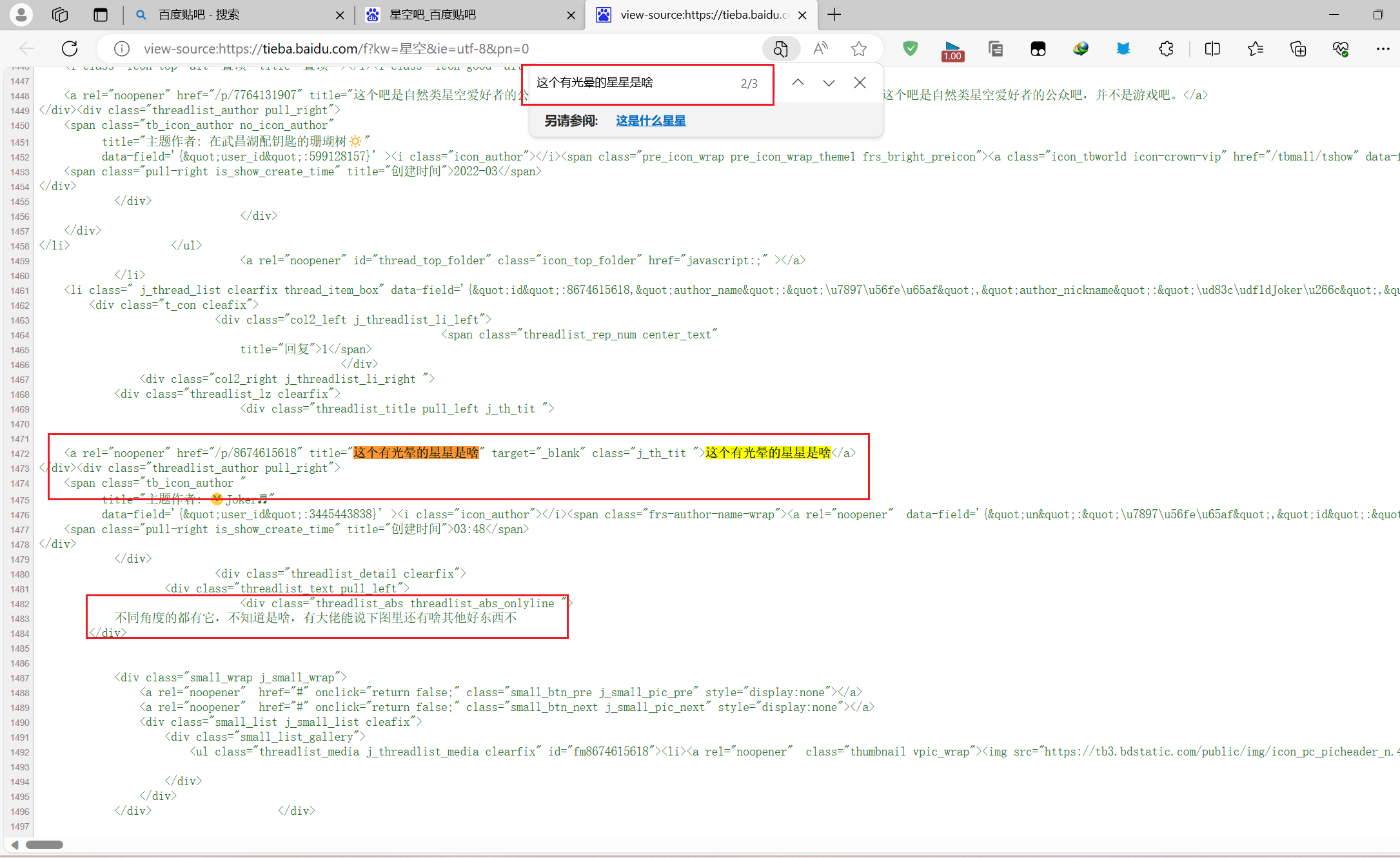
在源代码中搜索页面的内容,很明显,这个是静态资源
我们就不需要抓包了,只需要请求url就行
2 请求url获取源代码
右键检查,或者F12,打开开发者工具
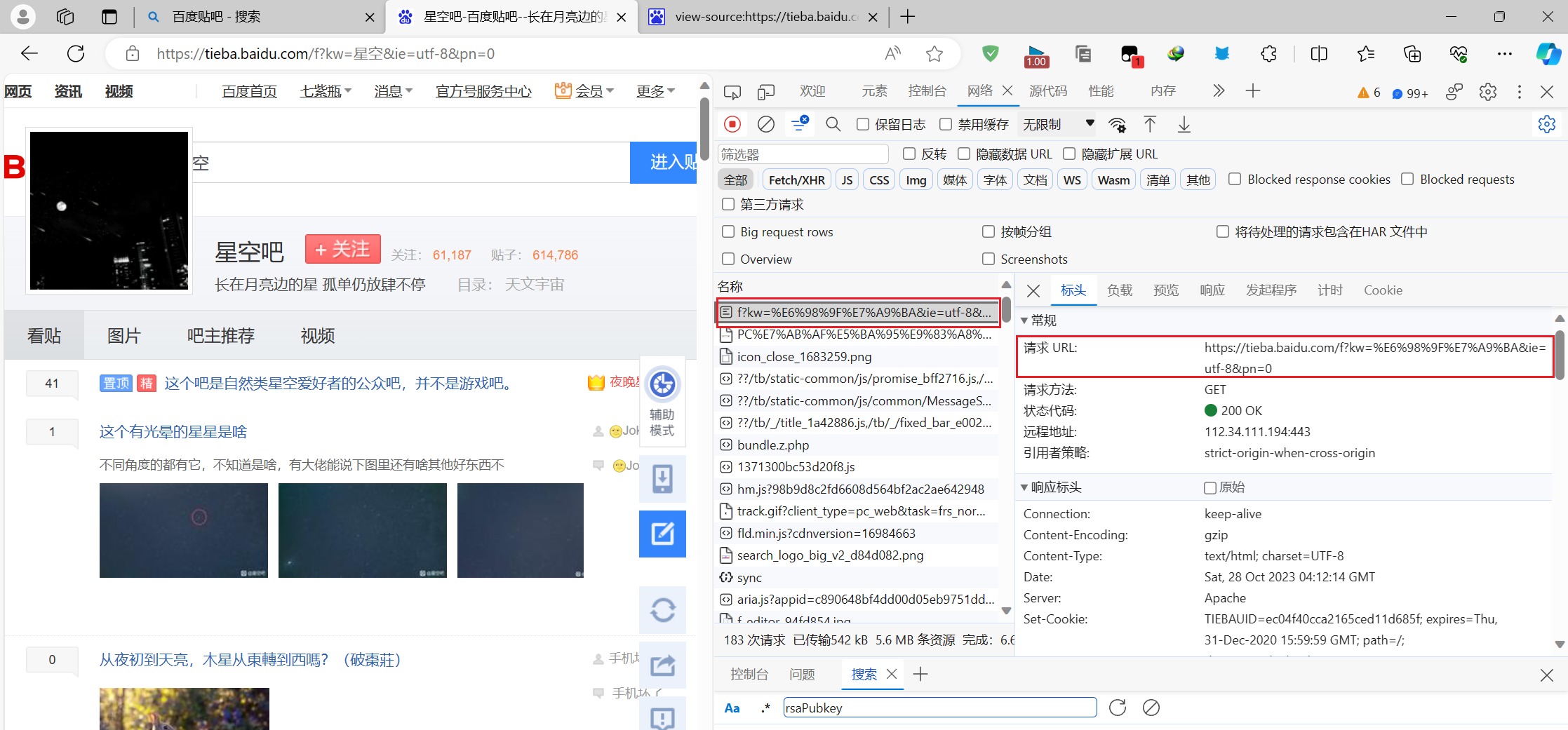
查看请求的url,可以看到星空那俩字被编码了,所以我们请求的时候也要编码
复制请求标头下的"User-Agent"
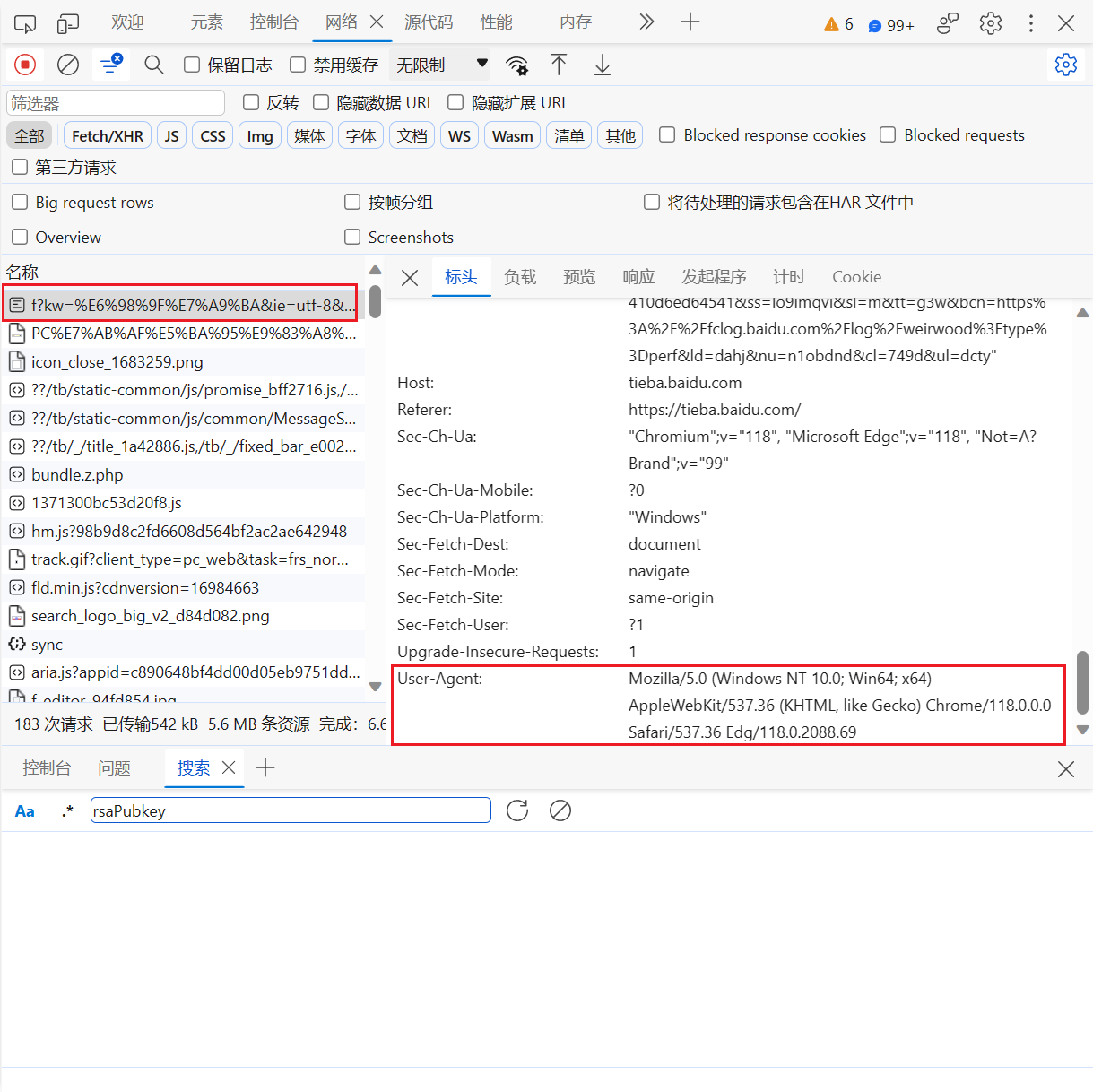
首先尝试请求头只有一个 “User-Agent” 能不能请求成功
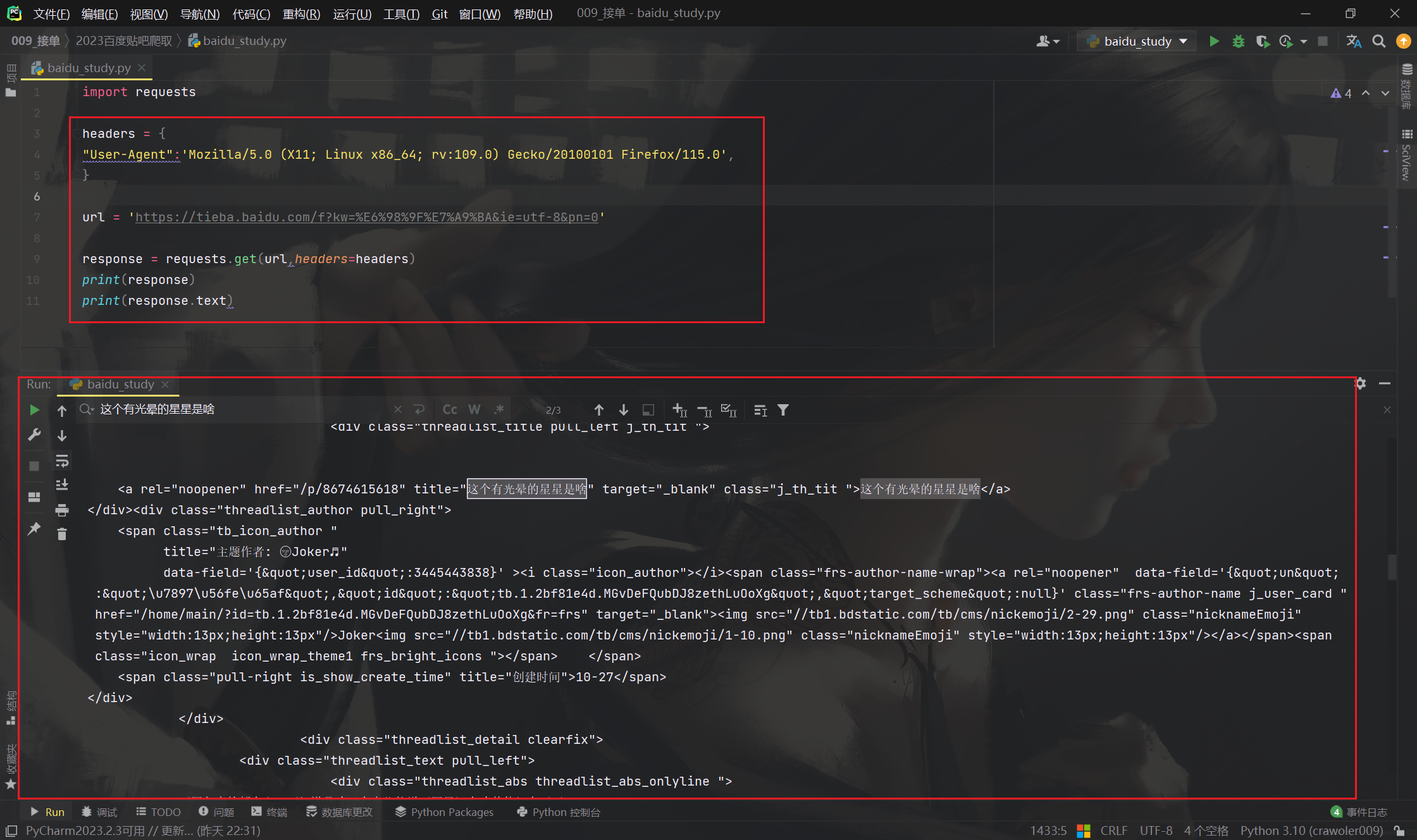
可以看到,请求头只放一个 UA也可以请求成功
所以我们使用UA库来防止被反爬
关于UA库点击查看 2023最新!!!Python爬虫获取 UA 工具 让你爬虫时如鱼得水的工具和模块
import random
import urllib.parse
import requests
from fake_useragent import UserAgent
# 获取网页源代码
def get_HTML(url):
headers = {
"User-Agent": random.choice(ua_list),
}
response = requests.get(url, headers=headers)
print('请求url', url, response)
return response.text
if __name__ == '__main__':
# 初始化 UA 库 防止反爬
ua = UserAgent()
ua_list = []
for i in range(20):
ua_list.append(ua.random)
kw = input('输入要爬取的贴吧:')
pn = int(input('输入要爬取的总页数:'))
for i in range(pn):
url = f'https://tieba.baidu.com/f?kw={urllib.parse.quote(kw)}&ie=utf-8&pn={i * 50}'
# 获取源代码
text = get_HTML(url)
print(text)
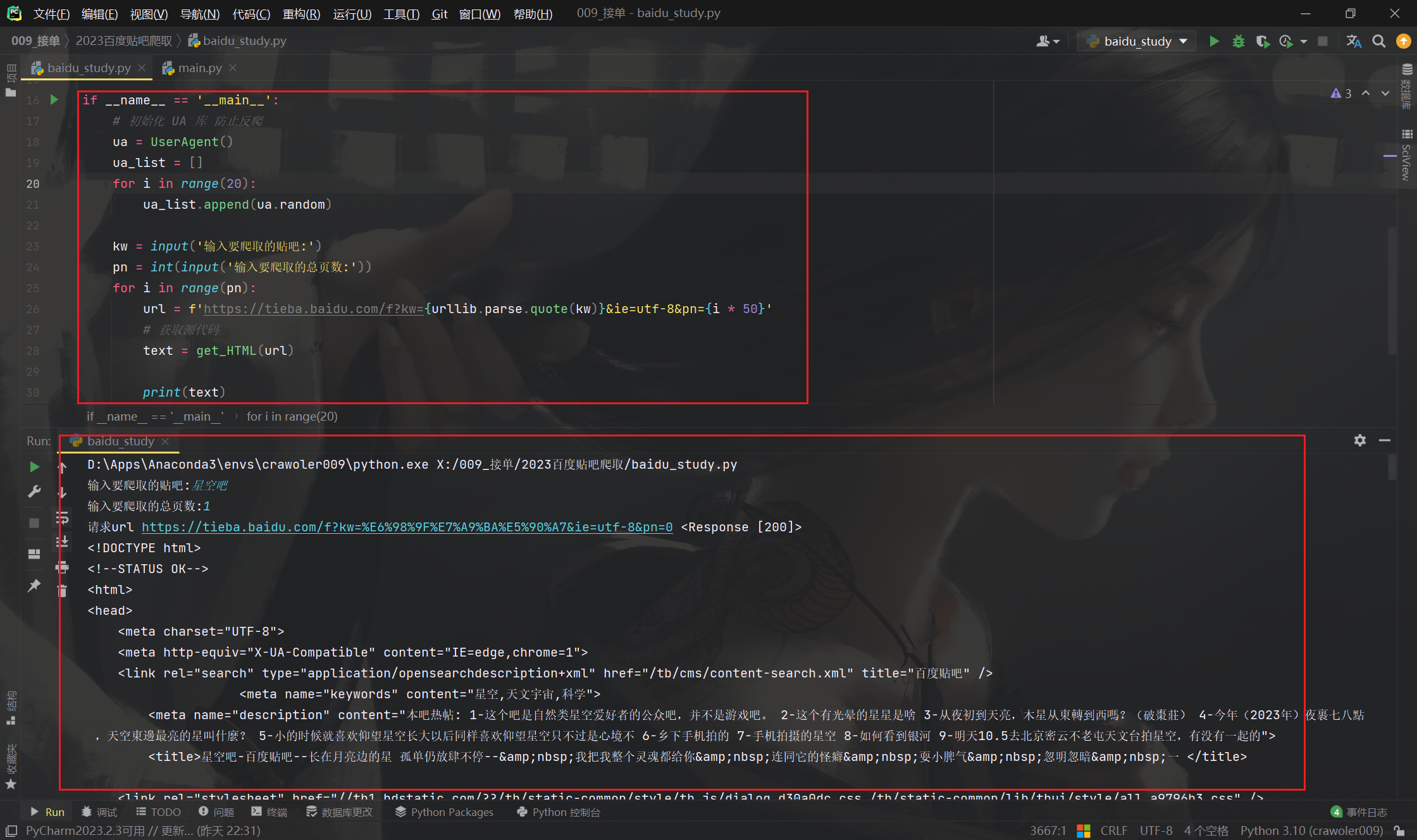
获取到源码后进行解析就行,我这里使用的是正则表达式
3 解析源代码 获取数据
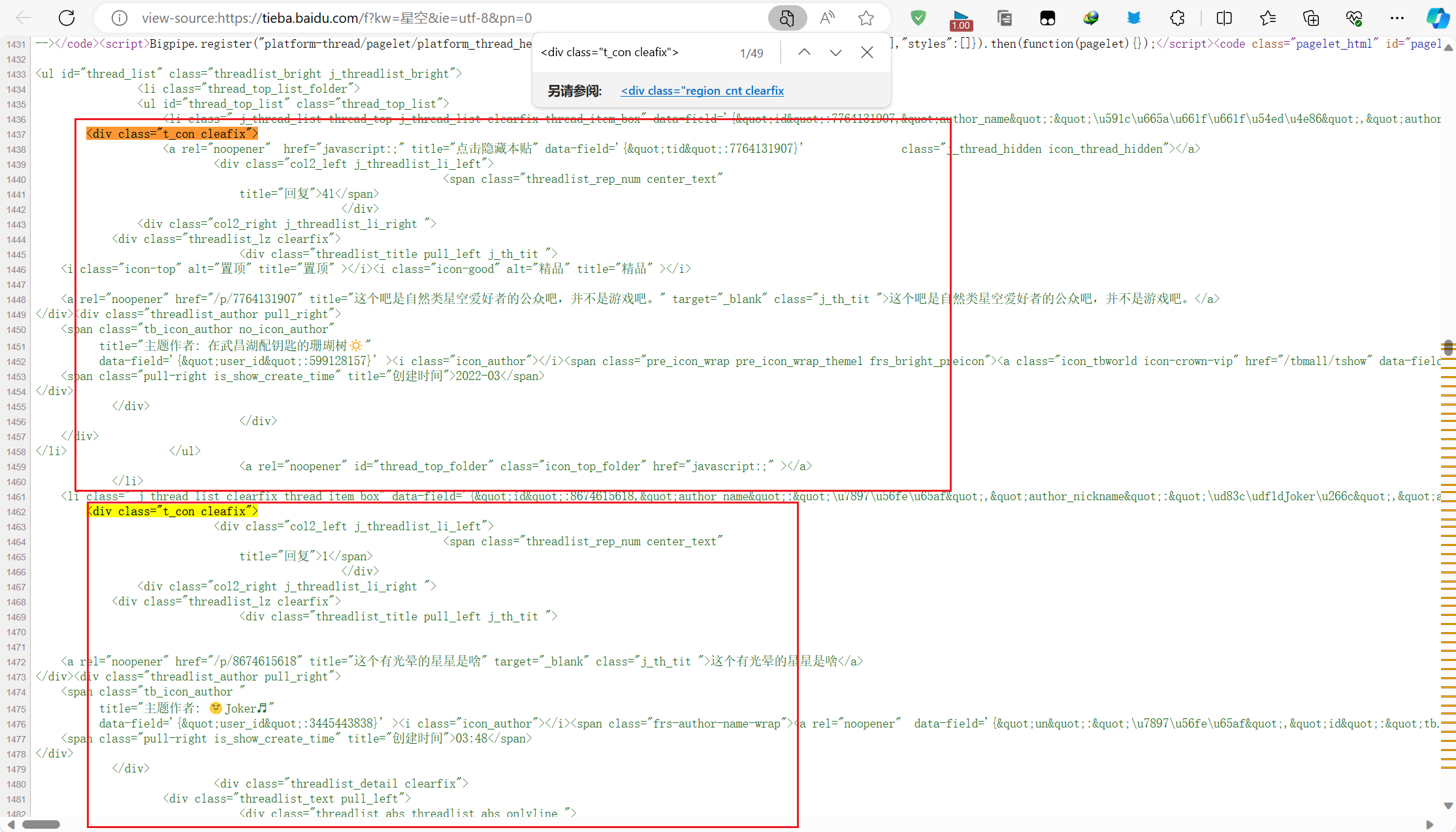
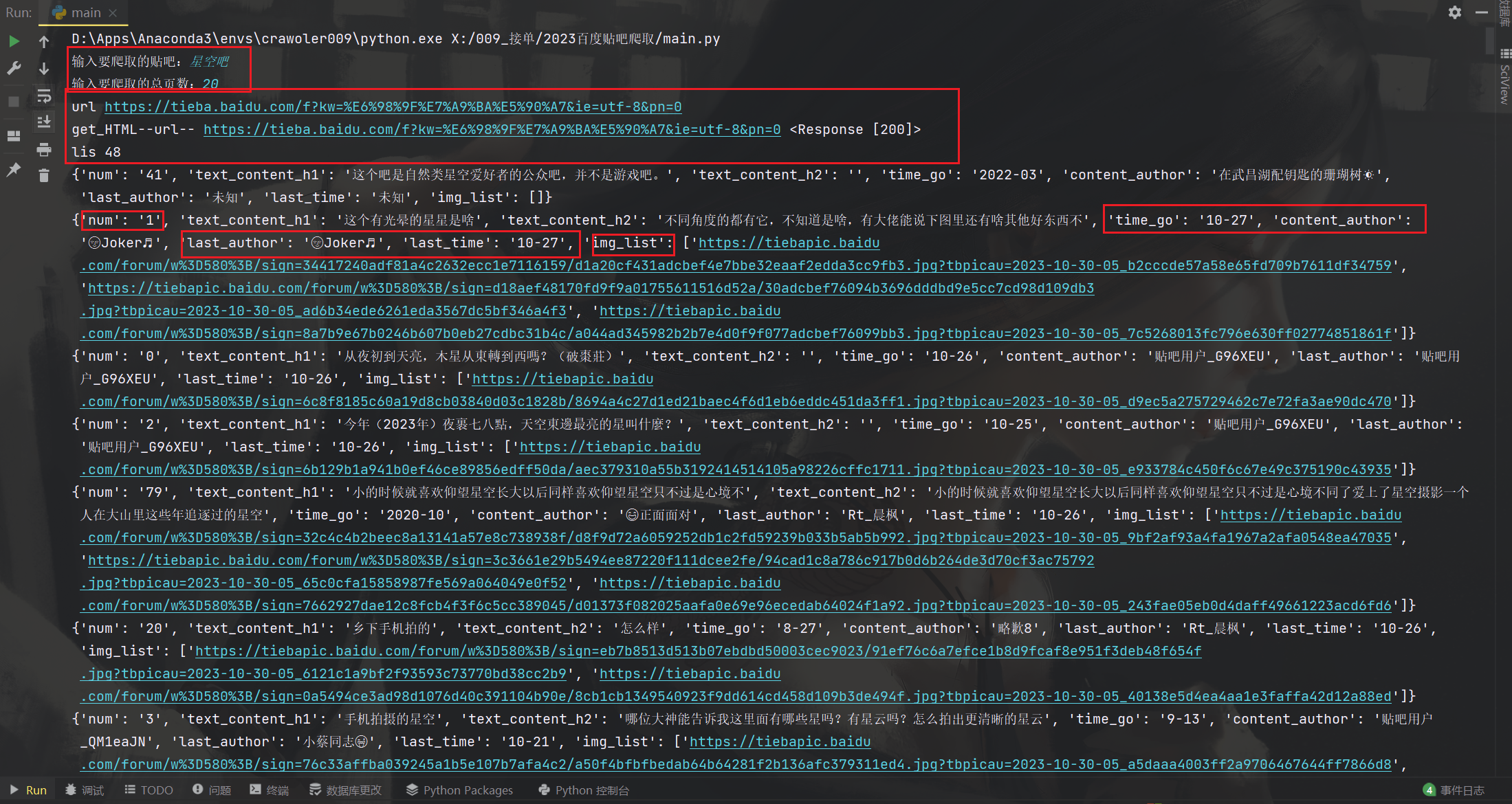
我们通过源代码可以看出,每一条数据,都在一个div里面
第一步,通过re获取全部的评论div
# 存放div
lis = re.findall('(<div class="t_con cleafix">.*?)<li class=', text, re.S)
print('lis', len(lis)) # lis 49
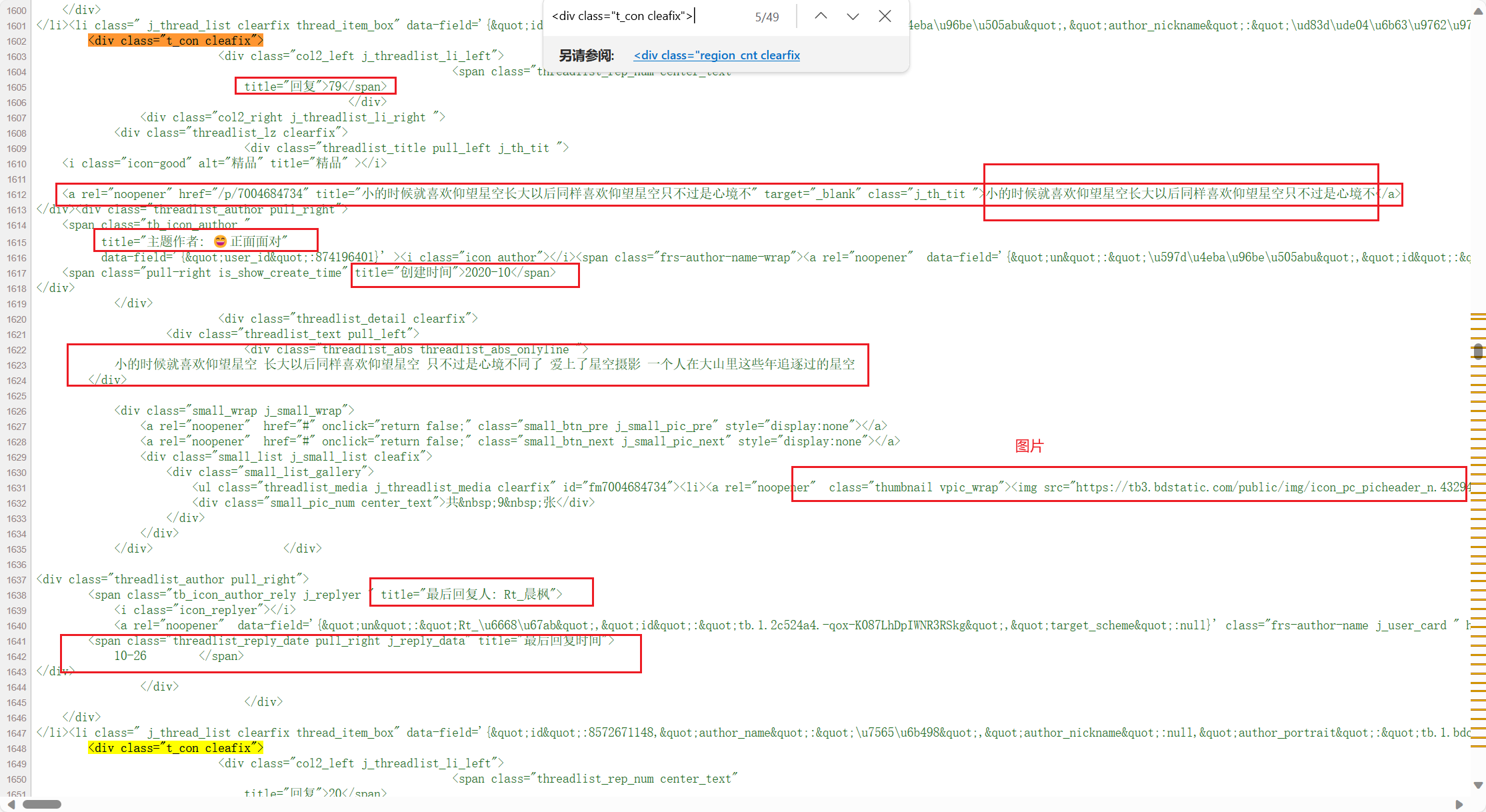
再仔细看源码,可以看到他们都是有规律的,直接使用正则获取
在我们爬取出来打印到控制台时,我们还可以看到,标题和正文,他们含有\n\r,其他字符和一些网页代码之类的
所以我们先写一个清洗内容的函数,把\n\r之类的全部删除
# 清洗数据,\n\r\t, 以及标签 去掉
def text_clean(content):
clean_new = re.sub('acla=".*?"data-flag=".*?"data-ame=".*?"', '', re.sub('[\s \<.*?\>]', '', str(content)))
return clean_new
接着在使用re正则表达式提取里面数据
# 存放字典的列表
lis_item = []
# 循环每一条评论
for item in lis:
# 创建字典
lis_dic = {}
# 获取贴纸id
num = re.findall('title="回复">(.*?)</span>', item)[0]
lis_dic['num'] = num # 放入字典
# 获取标题
text_content_h1 = re.findall('<a rel="noopener" href=".*?" title=".*?" target=".*?" class=".*?">(.*?)</a>',item)
# 判断标题是否存在
if len(text_content_h1) > 0:
# 存在的话放入字典并清洗内容
lis_dic['text_content_h1'] = text_clean(text_content_h1[0])
else:
# 不存在为空
lis_dic['text_content_h1'] = ''
# 获取正文文本
text_content_h2 = re.findall('<div class="threadlist_abs threadlist_abs_onlyline ">(.*?)</div>', item, re.S)
# 判断是否存在
if len(text_content_h2) > 0:
# 存在的话放入字典并清洗内容
lis_dic['text_content_h2'] = text_clean(text_content_h2[0])
else:
# 不存在为空
lis_dic['text_content_h2'] = ''
try:
# 获取创建时间
time_go = re.findall('<span class="pull-right is_show_create_time" title="创建时间">(.*?)</span>', item)[0]
except:
time_go = '未知'
lis_dic['time_go'] = time_go
# 获取主题作者
content_author = re.findall('title="主题作者:(.*?)"', item, re.S)
if len(content_author) > 0:
lis_dic['content_author'] = text_clean(content_author[0])
else:
lis_dic['content_author'] = '未知'
# 获取最后回复人
last_author = re.findall('title="最后回复人:(.*?)">', item, re.S)
if len(last_author) > 0:
lis_dic['last_author'] = text_clean(last_author[0])
else:
lis_dic['last_author'] = '未知'
# 获取最后回复时间
last_time = re.findall('title="最后回复时间">(.*?)</span>', item, re.S)
if len(last_time) > 0:
lis_dic['last_time'] = text_clean(last_time[0])
else:
lis_dic['last_time'] = '未知'
# 获取所有的img 注意,大图是bpic的地址
img_list = re.findall('<img src=".*?" attr=".*?" data-original=".*?" bpic="(.*?)" class=".*?" />', item, re.S)
lis_dic['img_list'] = img_list
# 打印字典
print(lis_dic)
# 添加到列表
lis_item.append(lis_dic)
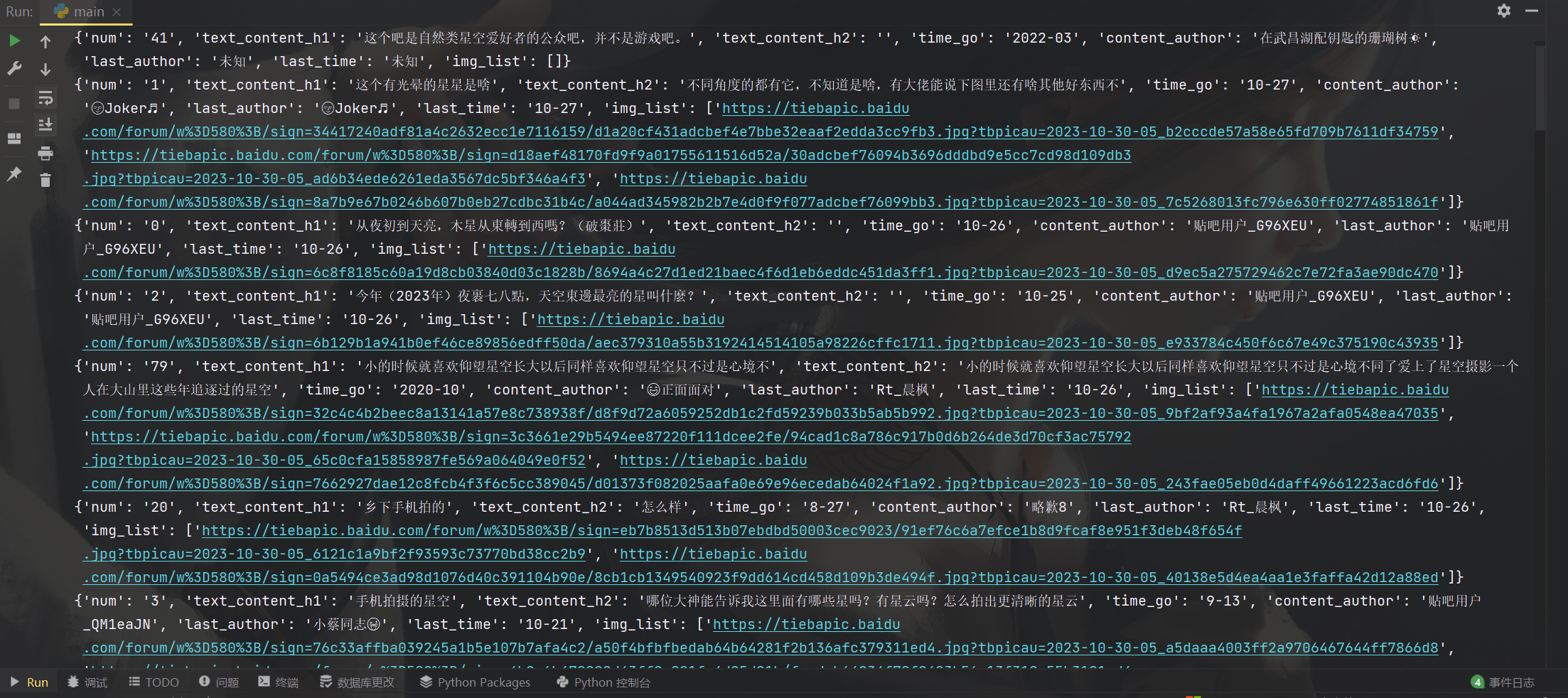
获取数据没有问题后,把他写成函数,传入参数为html源代码
# 获取html,解析数据
def get_data(text):
# 存放div
lis = re.findall('(<div class="t_con cleafix">.*?)<li class=', text, re.S)
print('lis', len(lis)) # lis 49
# 存放字典的列表
lis_item = []
# 循环每一条评论
for item in lis:
# 创建字典
lis_dic = {}
# 获取贴纸id
num = re.findall('title="回复">(.*?)</span>', item)[0]
lis_dic['num'] = num # 放入字典
# 获取标题
text_content_h1 = re.findall('<a rel="noopener" href=".*?" title=".*?" target=".*?" class=".*?">(.*?)</a>', item)
# 判断标题是否存在
if len(text_content_h1) > 0:
# 存在的话放入字典并清洗内容
lis_dic['text_content_h1'] = text_clean(text_content_h1[0])
else:
# 不存在为空
lis_dic['text_content_h1'] = ''
# 获取正文文本
text_content_h2 = re.findall('<div class="threadlist_abs threadlist_abs_onlyline ">(.*?)</div>', item, re.S)
# 判断是否存在
if len(text_content_h2) > 0:
# 存在的话放入字典并清洗内容
lis_dic['text_content_h2'] = text_clean(text_content_h2[0])
else:
# 不存在为空
lis_dic['text_content_h2'] = ''
try:
# 获取创建时间
time_go = re.findall('<span class="pull-right is_show_create_time" title="创建时间">(.*?)</span>', item)[0]
except:
time_go = '未知'
lis_dic['time_go'] = time_go
# 获取主题作者
content_author = re.findall('title="主题作者:(.*?)"', item, re.S)
if len(content_author) > 0:
lis_dic['content_author'] = text_clean(content_author[0])
else:
lis_dic['content_author'] = '未知'
# 获取最后回复人
last_author = re.findall('title="最后回复人:(.*?)">', item, re.S)
if len(last_author) > 0:
lis_dic['last_author'] = text_clean(last_author[0])
else:
lis_dic['last_author'] = '未知'
# 获取最后回复时间
last_time = re.findall('title="最后回复时间">(.*?)</span>', item, re.S)
if len(last_time) > 0:
lis_dic['last_time'] = text_clean(last_time[0])
else:
lis_dic['last_time'] = '未知'
# 获取所有的img 注意,大图是bpic的地址
img_list = re.findall('<img src=".*?" attr=".*?" data-original=".*?" bpic="(.*?)" class=".*?" />', item, re.S)
lis_dic['img_list'] = img_list
# 打印字典
print(lis_dic)
# 添加到列表
lis_item.append(lis_dic)
print('lis_item数量',len(lis_item))
return lis_item
4 保存到csv文件
# csv标头
headers = ('num', 'text_content_h1', 'text_content_h2', 'time_go', 'content_author', 'last_author', 'last_time','img_list')
with open(f'百度贴吧__{kw}.csv', mode='w+', encoding='utf-8', newline="")as f:
# 创建一个字典数据的写入对象
writer = csv.DictWriter(f, fieldnames=headers)
writer.writeheader() # 写入表头
# 写数据
writer.writerows(all_list_data) # all_list_data是列表,列表里面是字典,字典是每一条评论的内容
print(f'百度贴吧__{kw}.csv保存成功')
5 完整源代码
import csv
import random
import re
import urllib.parse
import requests
from fake_useragent import UserAgent
# 获取网页源代码
def get_HTML(url):
headers = {
"User-Agent": random.choice(ua_list),
}
response = requests.get(url, headers=headers)
print('请求url', url, response)
return response.text
# 清洗数据,\n\r\t, 以及标签 去掉
def text_clean(content):
clean_new = re.sub('acla=".*?"data-flag=".*?"data-ame=".*?"', '', re.sub('[\s \<.*?\>]', '', str(content)))
return clean_new
# 获取html,解析数据
def get_data(text):
# 存放div
lis = re.findall('(<div class="t_con cleafix">.*?)<li class=', text, re.S)
print('lis', len(lis)) # lis 49
# 存放字典的列表
lis_item = []
# 循环每一条评论
for item in lis:
# 创建字典
lis_dic = {}
# 获取贴纸id
num = re.findall('title="回复">(.*?)</span>', item)[0]
lis_dic['num'] = num # 放入字典
# 获取标题
text_content_h1 = re.findall('<a rel="noopener" href=".*?" title=".*?" target=".*?" class=".*?">(.*?)</a>', item)
# 判断标题是否存在
if len(text_content_h1) > 0:
# 存在的话放入字典并清洗内容
lis_dic['text_content_h1'] = text_clean(text_content_h1[0])
else:
# 不存在为空
lis_dic['text_content_h1'] = ''
# 获取正文文本
text_content_h2 = re.findall('<div class="threadlist_abs threadlist_abs_onlyline ">(.*?)</div>', item, re.S)
# 判断是否存在
if len(text_content_h2) > 0:
# 存在的话放入字典并清洗内容
lis_dic['text_content_h2'] = text_clean(text_content_h2[0])
else:
# 不存在为空
lis_dic['text_content_h2'] = ''
try:
# 获取创建时间
time_go = re.findall('<span class="pull-right is_show_create_time" title="创建时间">(.*?)</span>', item)[0]
except:
time_go = '未知'
lis_dic['time_go'] = time_go
# 获取主题作者
content_author = re.findall('title="主题作者:(.*?)"', item, re.S)
if len(content_author) > 0:
lis_dic['content_author'] = text_clean(content_author[0])
else:
lis_dic['content_author'] = '未知'
# 获取最后回复人
last_author = re.findall('title="最后回复人:(.*?)">', item, re.S)
if len(last_author) > 0:
lis_dic['last_author'] = text_clean(last_author[0])
else:
lis_dic['last_author'] = '未知'
# 获取最后回复时间
last_time = re.findall('title="最后回复时间">(.*?)</span>', item, re.S)
if len(last_time) > 0:
lis_dic['last_time'] = text_clean(last_time[0])
else:
lis_dic['last_time'] = '未知'
# 获取所有的img 注意,大图是bpic的地址
img_list = re.findall('<img src=".*?" attr=".*?" data-original=".*?" bpic="(.*?)" class=".*?" />', item, re.S)
lis_dic['img_list'] = img_list
# 打印字典
print(lis_dic)
# 添加到列表
lis_item.append(lis_dic)
print('lis_item数量',len(lis_item))
return lis_item
if __name__ == '__main__':
# 初始化 UA 库 防止反爬
ua = UserAgent()
ua_list = []
for i in range(20):
ua_list.append(ua.random)
kw = input('输入要爬取的贴吧:')
pn = int(input('输入要爬取的总页数:'))
all_list_data = []
for i in range(pn):
url = f'https://tieba.baidu.com/f?kw={urllib.parse.quote(kw)}&ie=utf-8&pn={i * 50}'
# 获取源代码
text = get_HTML(url)
it_list = get_data(text)
all_list_data += it_list
print('all_list_data', len(all_list_data))
# 写入csv
headers = ('num', 'text_content_h1', 'text_content_h2', 'time_go', 'content_author', 'last_author', 'last_time',
'img_list') # 元组 列表 集合
with open(f'百度贴吧__{kw}.csv', mode='w+', encoding='utf-8', newline="")as f:
# 创建一个字典数据的写入对象
writer = csv.DictWriter(f, fieldnames=headers)
writer.writeheader() # 写入表头
# 写数据
writer.writerows(all_list_data)
print(f'百度贴吧__{kw}.csv保存成功')
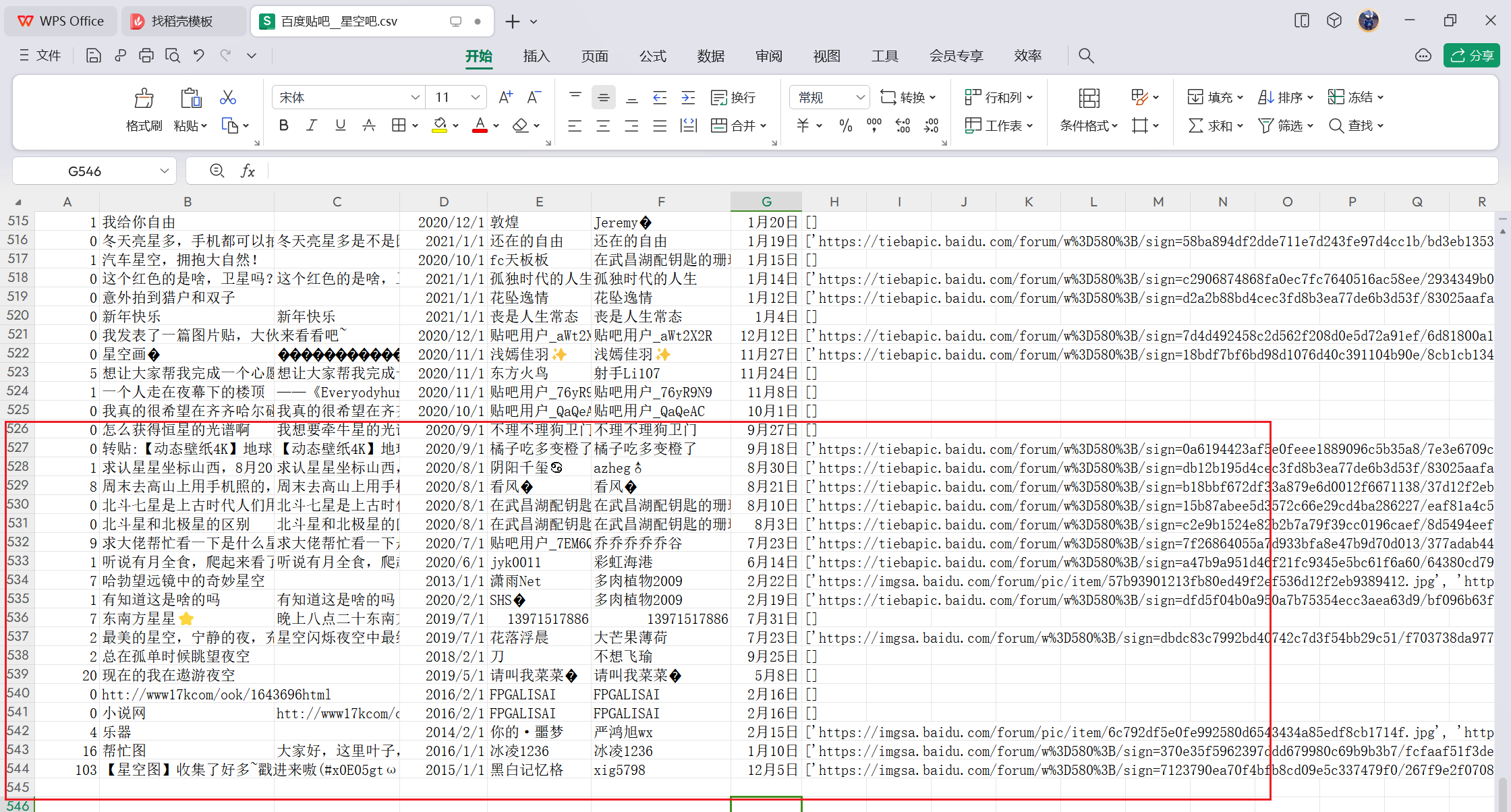
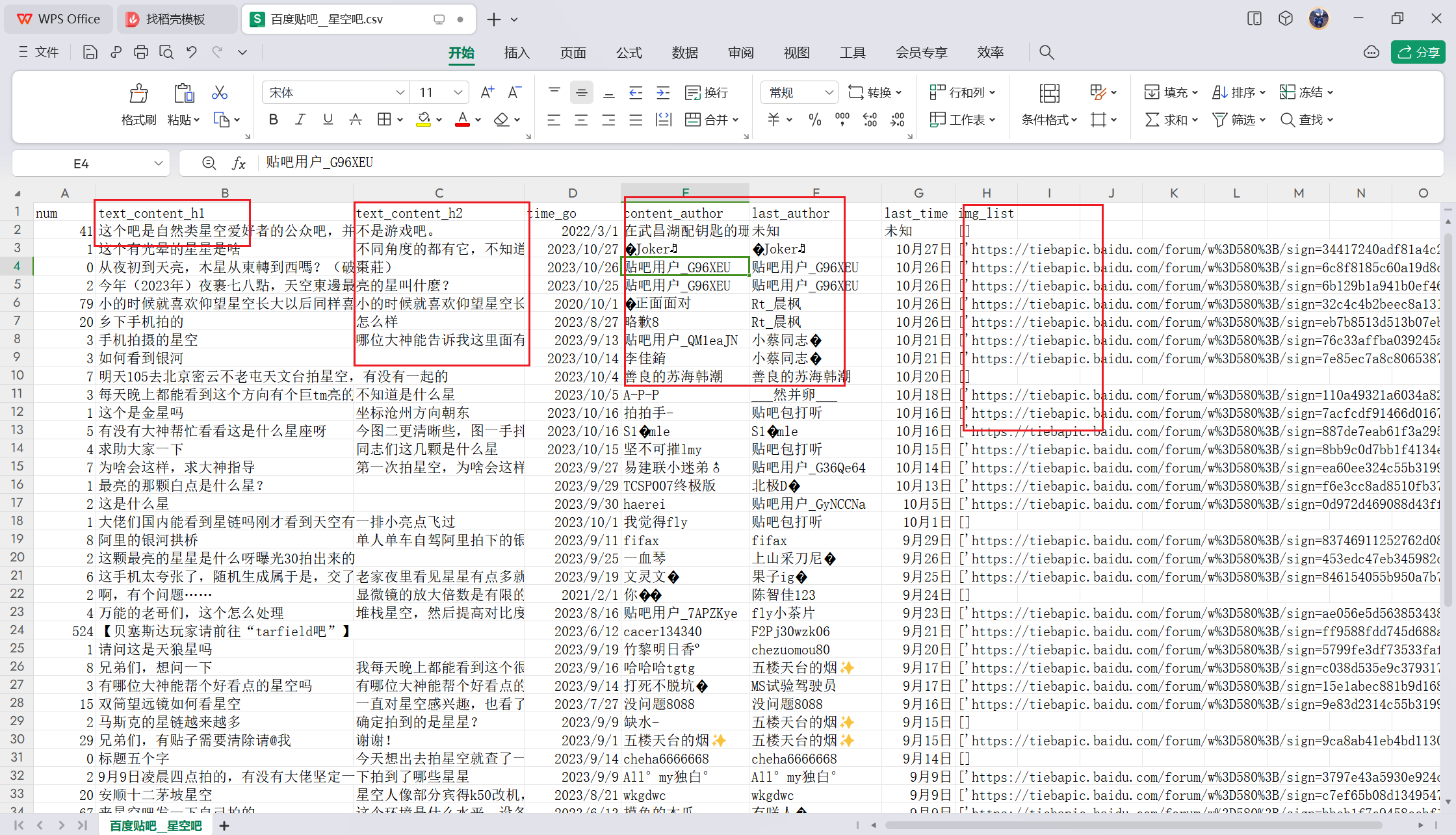
5 效果展示
爬取20页并保存到csv文件