大数据-预计算类引擎
预计算这种特殊的计算方法也属于在线计算的一种特例。预计算来源于数据仓库建设中的多维分析理论。如数据仓库建设所述,在 ROLAP 类型的数据仓库中,数据以行列表的形式来表示星形模型,计算属于现场计算。而 MOLAP 类型的数据仓库则以 Cube 立方体的形式存储数据,计算就属于预计算+现场计算了。
在生产实践上,如果 ClickHouse、Impala 属于 ROLAP 类型的计算引擎,Kylin 就属于 HOLAP (MOLAP+ROLAP)类型,即原始数据存储在 ROLAP 中(例如 Hive),Cube 数据单独计算存储在HBase 中。其在生成 Cube 立方体时不是现场计算的,属于预计算部分。面对终端查询时,利用 Cube 已经存在的“全量、多维”结果可以提供在线秒出终端所需结果的能力。
常见的多维分析有以下操作方式。
1)上卷:维度上的聚合或者直接消除维度,例如剔除时间维度的分析。
2)下钻:维度上的粒度更细划分,例如在时间维度上进一步划分年、月、日维度。类似的还有上钻,即同一维度上的细粒度聚合成粗粒度,例如将日、月聚合成年。
3)切片:固定一个维度的选取,例如只选取时间维度分析。
4)切块:固定多个维度的选取,但只取某个维度或者某些维度的区间上的直,例如时间维度上只选取一年范围内的数据。
5)旋转:维度转换,把分布在列上的数据直接按行显示,例如不同的年分列展示不同的销售总额,转换后直接在多行显示不同的年份及销售总额信息。
如果多维分析模型中,对 Cube 的生成不加以优化,上述的所有操作都会在 Cube 的结果当中,这样造成 Cube “爆炸”,浪费大量空间。
下面具体介绍Kylin。Kylin 是HOLAP 预计算的代表产品,也是国内在业界较出名的产品之一。
其具有以下特性。
1)提供基于 Hadoop 数据集的标准 SQL 查询能力。
2)提供增量构建 Cube 的能力,在秒级延迟下进行实时数据的多维分析。
3)提供 JDBC、ODBC、BI 工具的无缝接入能力。
Kylin 架构图如图7-18所示,按角色解析如下。
(1)数据源
1)支持 Hive 作为数据源,保留schema 元数据信息。
2)支持Kafka 作为流式数据源,保持增量构建 Cube 的能力。
3)支持 JDBC、Sqoop 作为关系型数据库源的导入工具,从而接入 RDBMS数据源的能力。
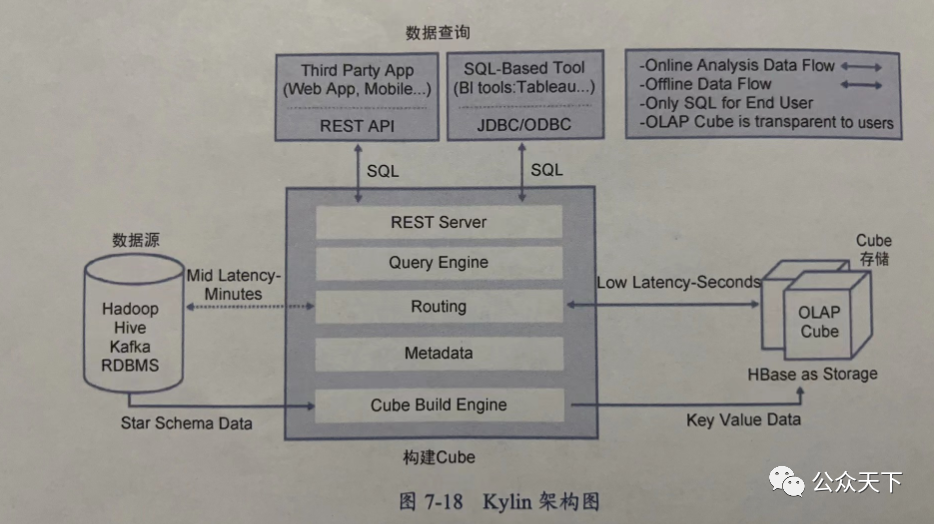
(2)构建 Cube
构建 Cube 的过程,就是计算各维度下度量值的过程,也就是完成 SQL 计算的过程。这个过程可以由 MapReduce 构建,也可以由Spark 构建,在其 3.1版本之后还可以使用 Flink 构建。
(3) Cube 存储
Cube 构建完毕之后,需要存储Cube 信息,包括 Cube 标识符、Cube 的结果(度量值),目前的版本支持 HBase 存储,Kylin 数据在 HBase 中的存储结构示例如图7-19所示。
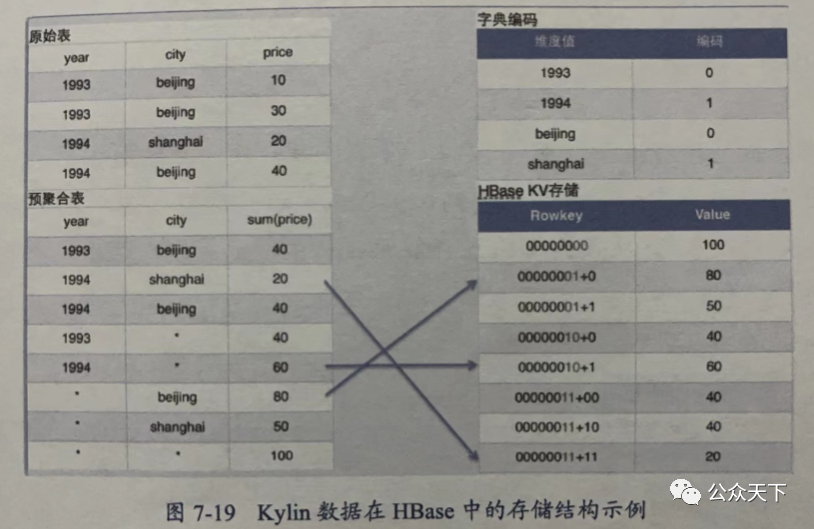
1)Cubeid +维度编码组成 HBase 的 Rowkey。
2)指标映射为 HBase 的列族。
3)度量值则是具体的字段值。
(4)数据查询
Kylin 提供基于 REST 的API 查询,也提供基于 JDBC 和ODBC 的查询,查询也是基于数据源库表的schema 信息,使用非常方便。
(5)Kylin 适用场景
Kylin 预计算方法比较好理解,在固定维度的场景下,提前 Cube 计算后针对 Cube 的查询将非常快,因此 Kylin 对于稳定的维度分析场景最为合适。同时,Kylin 查询的是度量值,并不是原始数据的值,因此适合对某个度量值进行聚合计算,而不是点查原始单条记录。
由于 Cube 是对所有维度都进行预计算,一般情况下要求对 Cube 中涉及的维度进行优化,否则容易造成 Cube 存储空间大大增加。有以下几个优化方法。
1)必要维度:一些必须存在的维度,例如时间维度。
2)层级维度:一些存在固定顺序的维度,例如省-市-区维度。
3)映射维度:有些维度之间有固定的映射关系,例如用户住址和街道,要求同时出现。
以上就是预计算引擎,接下来是用代码付诸实际行动的时候,希望对想了解大数据技术的你有帮助。