OFD开发系列(三)-文本提取
来源:OFD开发系列(三)-文本提取_ofdrw-CSDN博客
一、提取场景
和之前文章类似,我们首先明确文本提取的场景。文本提取是指提取OFD正文的文本数据,然后将文本存储到搜索引擎以对OFD文档进行更好的归档、检索等;文本也可以提取摘要数据方便预览信息;文本还可以分词、分类等,对文档进行智能化分类。这些用法,大大的提高了文档检索效率。注意,ofdrw的文本提取不包含模板页,只提取正文页。
二、准备工作
同样的,我们首先引入ofdrw的依赖包,如下所示:
<!--junit-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
<scope>provided</scope>
</dependency>
<!-- ofdrw -->
<dependency>
<groupId>org.ofdrw</groupId>
<artifactId>ofdrw-full</artifactId>
<version>1.6.10</version>
</dependency>其次,我们准备一个待提取文本的文档,此处我们对一个电子发票进行提取(文档为测试所用,侵权联系删除),如下所示:
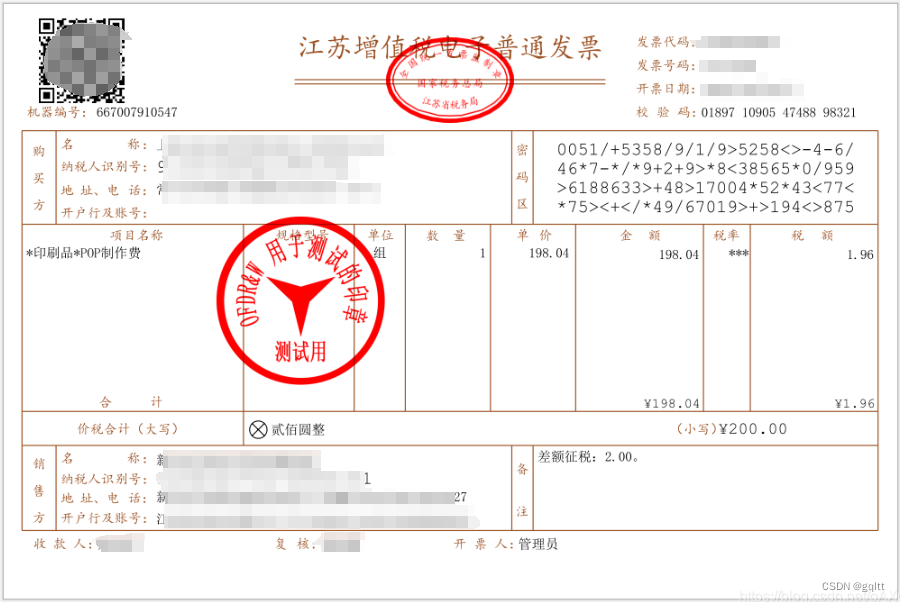
三、调用API
3.1、提取全部
示例代码如下:
@Test
public void testContentExtractor() {
try (OFDReader reader = new OFDReader(Paths.get("src/test/resources/b.ofd"))) {
ContentExtractor extractor = new ContentExtractor(reader);
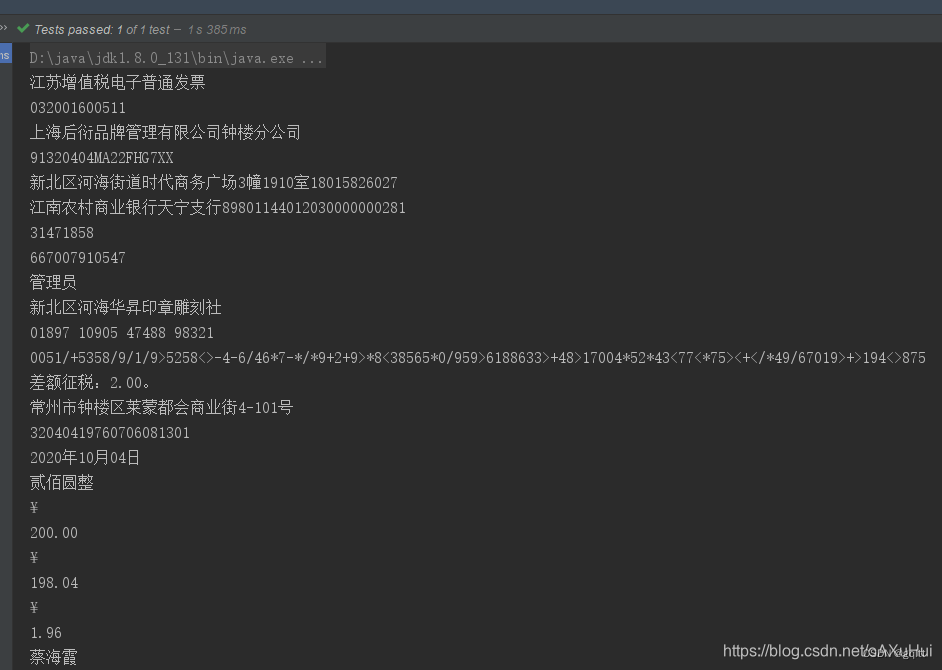
for (String content : extractor.extractAll()) {
System.out.println(content);
}
} catch (IOException e) {
e.printStackTrace();
}
}提取结果如下:
3.2、指定页提取
@Test
public void testContentExtractor() {
try (OFDReader reader = new OFDReader(Paths.get("src/test/resources/c.ofd"))) {
ContentExtractor extractor = new ContentExtractor(reader);
//指定页提取
List<String> pageContent = extractor.getPageContent(1);
for (String content : pageContent) {
System.out.println(content);
}
} catch (IOException e) {
e.printStackTrace();
}
}3.3、指定接收器
此处接收器回调函数会返回页码和对应页码提取出来的文本,如下:
@Test
public void testContentExtractor() {
try (OFDReader reader = new OFDReader(Paths.get("src/test/resources/c.ofd"))) {
ContentExtractor extractor = new ContentExtractor(reader);
//指定页提取
extractor.traverse((page, content) -> System.out.println(page + "," + content));
} catch (IOException e) {
e.printStackTrace();
}
}四、写在最后
下一篇我们将对关键字提取做简单介绍,关键字提取和文本提取不同,关键字提取会返回关键字对应的坐标页码,以方便我们对合同内容进行定位,签章等