关于guacamole项目中的一点感悟与理解
关于guacamole项目中的一点想法
前言
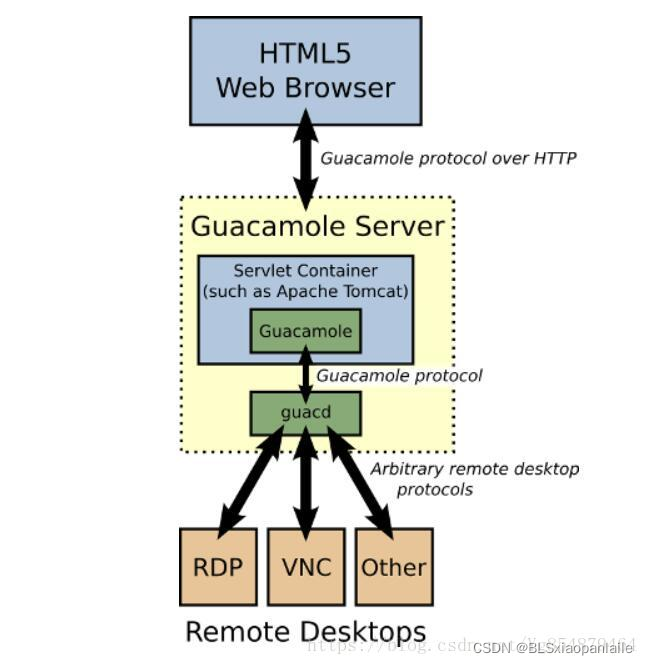
Guacamole 是基于 Web 的 VNC 客户端,使用它可以通过web浏览器访问远程服务器终端并进行操作。它的基本架构如下图所示。
巧合之下,前段时间了解了项目中guacd模块有关的一些内容,重点关注的是这个模块启动过程中涉及网络IO、线程、进程的建立(网络并发模型)等,学习记录在此,希望可以便人便己。
一、guacd模块启动相关
整个guacd模块的启动比较复杂,下面画了一个简要的代码流程图(流程图中主要关注的是网络IO、进程、线程的建立),如下所示。
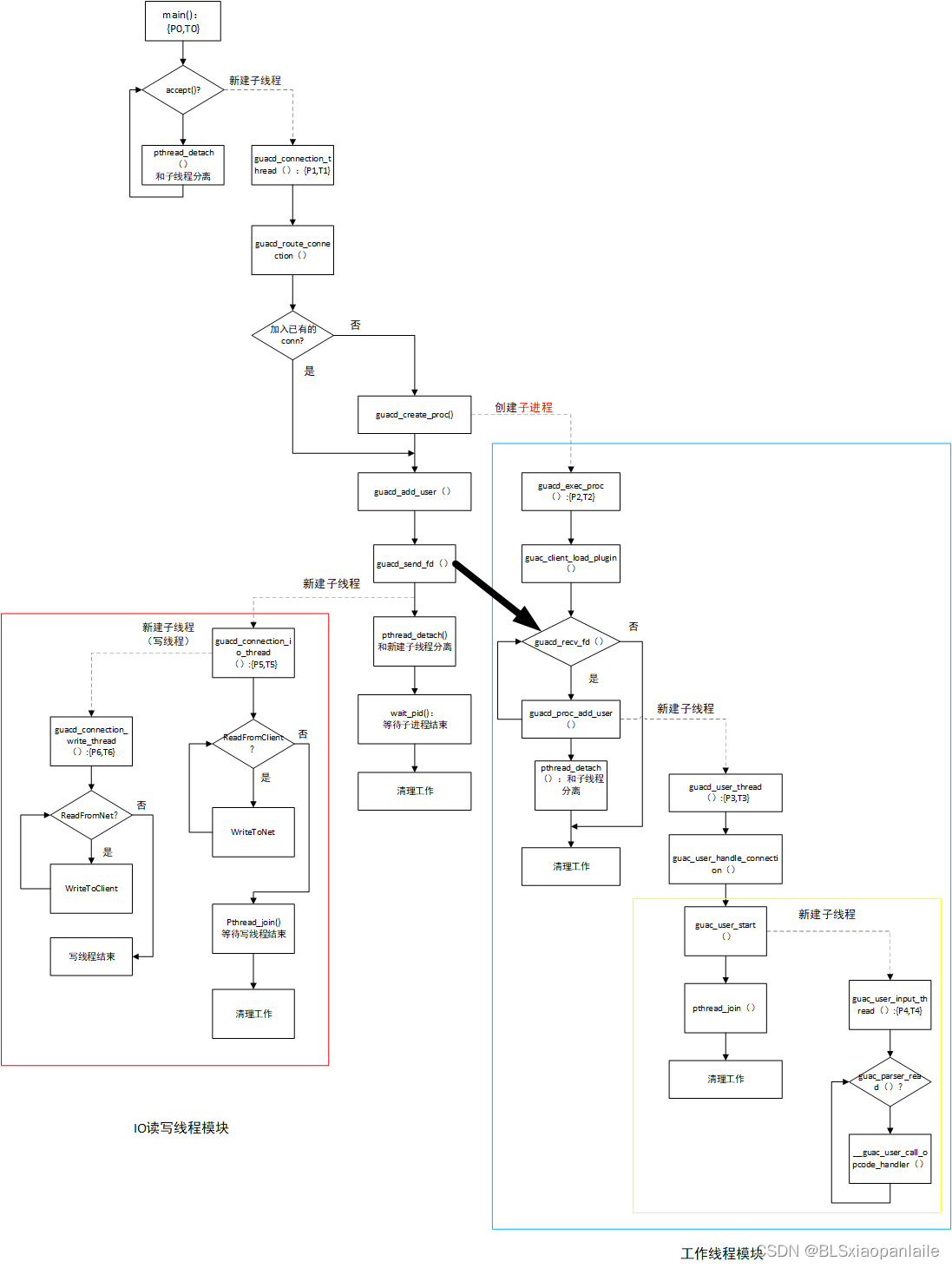
流程比较复杂,下面根据上图简要介绍下:
-
guacd所在的main(假设所在进程为P0,线程也是T0)运行之后,会在打开一个监听端口,等待accep()连接到来;
-
当有连接到来之时,新建一个线程T1(对应的进程是P1)处理请求;然后T0接着accept;
-
T1执行guacd_connection_thread(),在这个函数中判断连接请求是不是想加入原有的连接,还是建立新的连接。
//蓝色右边部分:作为第一个进程,加载插件,然后建立工作进程
-
如果是新建连接,则会新建一个子进程P2;在P2中先通过动态链接的方式加载协议,之后阻塞在guacd_recv_fd()上,等待父进程P1(建立子进程后父进程P1返回继续执行原来的任务,执行guac_add_user())发送父子间通信的套接字端口proc_fd (这个proc_fd是用于IO线程和工作线程之间沟通用的);
-
若P2接收到了发送的P1proc_fd,会新建一个线程T3;在T3中执行guacd_user_thread. 在guacd_user_thread中是主要建立连接关系的一些操作,然后执行 guac_user_handle_connection()
-
在guac_user_handle_connection()中又新建了一个子线程T4(这算是工作线程);在T4中正式通过proc_fd和IO线程联系,循环处理客户端的请求。
//红色左边部分:用于为每个请求建立IO线程(一个读线程、一个写线程)
-
在上述步骤3中,若请求是想加入一个已有的连接,则会跳过建立新进程的步骤;直接执行guacd_add_user();
-
在guacd_add_user()中会建立一个unix套接字用于父子进程通信,通过guacd_send_fd()发送给子进程(步骤3中的)
-
之后会新建io子线程T5,在io子线程中执行guacd_connection_io_thread();在guacd_connection_io_thread()中又会新建一个写线程T6, 用来从网络中读,然后写到客户端(即工作线程);T5线程当做读线程,从客户端(即工作线程)读数据,写入到网络中。
其基本的逻辑有两点需要说明:
1、一个连接可以被多个用户共享(类似于分享屏幕),第一个建立这个连接的用户叫做这个连接的owner,逻辑会走一遍右边建立新进程的过程(需要加载动态库插件)。 后续想加入同一个连接的用户则不需要建立新的进程,只需要由owner所对应的进程建立工作线程即可。
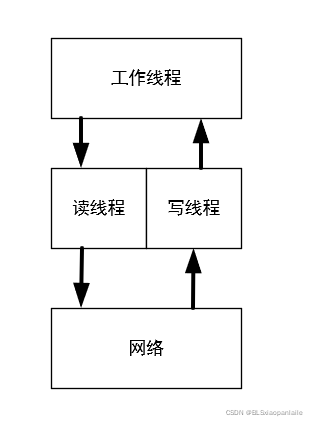
2、每个用户都会为其建立一组IO线程(读线程和写线程)和工作线程。其中前者主要是当做工作线程和网络之间的通信中介,其目的大概是提高整体的IO效率;后者的工作则主要是进行实际的业务处理。其基本关系如下图所示。
二、一些感悟与理解
-
关于IO线程和工作线程

在guacamole中会为每个用户建立一组IO线程和工作线程。按照我目前所了解的,很多项目,尤其是涉及到网络IO的项目,其IO并发模型中大都会把用户的整个逻辑拆分为IO和实际的业务处理,对应由不同的线程进行处理。有必要吗?大部分情况下还是有必要的,尤其是对于并发量较大的web业务来说。按照我的理解分离IO线程和业务处理线程好处以下几点:
(1)、一是可以在某种程度情况下,IO线程和业务线程并发处理(甚至可以利用多核的优点达到并行),使得业务线程在处理业务之时不影响IO(客户端的请求和回复),当然这也只是在一定程度上的,如果业务线程一直跟不上,IO线程再快,整体的服务质量也会下降。
(2)、可以使用IO复用的机制,让IO线程同时处理多个连接的IO,或者使用以IO复用为基础的Reactor模式,大大提高系统的并发量。
(3)、IO线程和业务线程解耦,在某些情况下可以方便的进行勘误或者性能调优,这一点我目前还没遇到过。当然把IO线程和业务线程分离也有一点不好的地方,由于把整个的业务逻辑(IO+具体对数据的处理)进行了拆分,因此在数据传递时会出现线程切换,造成一些性能损耗;在guacd中IO线程和工作线程分属于两个进程,切换的损耗还要更大些。
-
关于IO复用
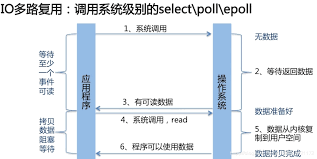
在很多现在的项目中都使用了IO复用的机制(epoll、select等),由多个连接共享一个IO线程。但是guacd这里用的就不是IO复用;它是给每个用户建立连接对应的一个IO读写线程和一个工作线程(应该是一个?),这种方式的话并发量可能不是很高,guacd为什么要这么设计呢?我想了想,大概是由于guacamole面向的大都是视频传输,传输的数据量都比较大,如果使用同一个线程来进行IO,会造成IO线程忙不过来的状况,倒不如使用每个连接一组IO线程的情形。这样说的话,选择什么样的IO并发模型也不是定数,还要根据具体的业务要求来进行判断。
-
关于建立线程还是建立进程
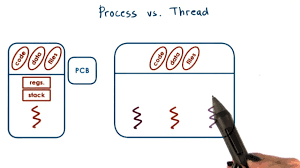
线程和进程最主要的区别在我来看有两点,这两点分别是二者的优缺点:进程独立而切换慢,线程共享而切换快。在guacd中大部分逻辑都是建立的线程,但是在第一个owner建立连接的时候创建的是进程。按照我的理解是因为每个owner主管的连接所对应协议不尽相同,所需要加载的插件也不同,如果都是用线程的话,那么只能把所有用到的插件都加载到同一份进程空间中,大家一起共享了。虽然这么说理论说好像也可以,但这样的话占用的进程空间可能也比较了。 同时,所有的线程都放在一个进程中,逻辑上也有点混乱。
-
关于同步
我们以前学操作系统的时候知道线程、进程同步的一些机制,比如说条件变量、信号量等等。其实从某种程度上来说,使用IO的阻塞操作也可以达到同样的效果,如上图中的owner所在进程在等着父进程发送fd,也算是一种同步操作;再比如说,pthread_join,wait_pid这些等待子线程、子进程退出的操作,也能算作是一种同步手段。
我的理解是,从本质上来说,这些手段底层都需要有共享的一个“东西”( 可以是阻塞中的fd,可以是信号量中的信号,也可以是条件变量中的变量等等),用来起到一个通知的作用。 -
关于进程和线程
什么是进程,什么是线程?在linux上线程也是一种进程。那么它们的本质是什么?是一种执行流。 新建了一个进程或者线程,就相当于开辟了一个新的执行流,让其他的执行流因为暂时阻塞的缘故,cpu可以选择另一个执行流,以此来增加cpu的利用率和系统整体的吞吐量。
-
一点的不理解

最后,在来谈点不理解的内容吧。
一般来说,根据运行时间长短,线程或者进程可分为两种,一种是长期任务,一种是短期任务;长期任务的生命周期一般由用户的进入与退出(连接的建立与断开、或者整个程序的开始与结束)来决定,一般主逻辑里都会有一个while{} 循环(如上图中的IO线程和工作线程);而短期的任务一般是临时的任务,执行完就结束了,一般不会有一直运行的循环操作(如上述guacd中的accpet之后建立的T1);我不懂的是,为什么在上述流程图中的owner所在进程主管的部分(右半黄色部分),在有用户想要加入已有的连接之后,需要创建两个线程T3、T4;代码中T3新建了T4之后,就一直在那join了(阻塞住了),反正也没用,为什么不直接用T3来当做工作线程处理整个逻辑呢?目前还不是很懂,有了解的小伙伴,可以教教我。
参考
【1】guacamole项目地址
【2】《真象还原》
【3】为什么建议 Netty 的 I/O 线程与业务线程分离
【4】框架篇:见识一下linux高性能网络IO+Reactor模型