【服务器部署】作为首选,这些操作你不会,说不过去了吧
目录
引言
早期的业务都是基于单体节点部署,由于前期访问流量不大,因此单体结构也可满足需求,但随着业务增长,流量也越来越大,那么最终单台服务器受到的访问压力也会逐步增高。时间一长,单台服务器性能无法跟上业务增长,就会造成线上频繁宕机的现象发生,最终导致系统瘫痪无法继续处理用户的请求。
“
从上面的描述中,主要存在两个问题:①单体结构的部署方式无法承载日益增长的业务流量。②当后端节点宕机后,整个系统会陷入瘫痪,导致整个项目不可用。
因此在这种背景下,引入负载均衡技术可带来的收益:
- 「系统的高可用:」 当某个节点宕机后可以迅速将流量转移至其他节点。
- 「系统的高性能:」 多台服务器共同对外提供服务,为整个系统提供了更高规模的吞吐。
- 「系统的拓展性:」 当业务再次出现增长或萎靡时,可再加入/减少节点,灵活伸缩。
OK~,既然引入负载均衡技术可给我们带来如此巨大的好处,那么又有那些方案可供选择呢?主要有两种负载方案,「「硬件层面与软件层面」」 ,比较常用的硬件负载器有A10、F5等,但这些机器动辄大几万乃至几十万的成本,因此一般大型企业会采用该方案,如银行、国企、央企等。而成本有限,但依旧想做负载均衡的项目,那么可在软件层面实现,如典型的Nginx等,软件层的负载也是本文的重点,毕竟Boss们的准则之一就是:「「能靠技术实现的就尽量不花钱。」」
“
当然,如果你认为本文对你而言有帮助,记得点赞、收藏、关注三连噢!
一、性能天花板-Nginx概念深入浅出
Nginx是目前负载均衡技术中的主流方案,几乎绝大部分项目都会使用它,Nginx是一个轻量级的高性能HTTP反向代理服务器,同时它也是一个通用类型的代理服务器,支持绝大部分协议,如TCP、UDP、SMTP、HTTPS等。

Nginx与Redis相同,都是基于多路复用模型构建出的产物,因此它与Redis同样具备 「「资源占用少、并发支持高」」 的特点,在理论上单节点的Nginx同时支持5W并发连接,而实际生产环境中,硬件基础到位再结合简单调优后确实能达到该数值。
先来看看Nginx引入前后,客户端请求处理流程的对比:
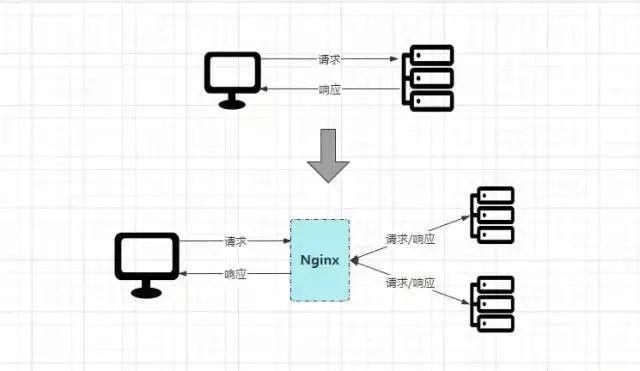
原本客户端是直接请求目标服务器,由目标服务器直接完成请求处理工作,但加入Nginx后,所有的请求会先经过Nginx,再由其进行分发到具体的服务器处理,处理完成后再返回Nginx,最后由Nginx将最终的响应结果返回给客户端。
了解了Nginx的基本概念后,再来快速搭建一下环境,以及了解一些Nginx的高级特性,如动静分离、资源压缩、缓存配置、IP黑名单、高可用保障等。
二、Nginx环境搭建
❶首先创建Nginx的目录并进入:
[root@localhost]# mkdir /soft && mkdir /soft/nginx/
[root@localhost]# cd /soft/nginx/
❷下载Nginx的安装包,可以通过FTP工具上传离线环境包,也可通过wget命令在线获取安装包:
[root@localhost]# wget https://nginx.org/download/nginx-1.21.6.tar.gz
没有wget命令的可通过yum命令安装:
[root@localhost]# yum -y install wget
❸解压Nginx的压缩包:
[root@localhost]# tar -xvzf nginx-1.21.6.tar.gz
❹下载并安装Nginx所需的依赖库和包:
[root@localhost]# yum install --downloadonly --downloaddir=/soft/nginx/ gcc-c++
[root@localhost]# yum install --downloadonly --downloaddir=/soft/nginx/ pcre pcre-devel4
[root@localhost]# yum install --downloadonly --downloaddir=/soft/nginx/ zlib zlib-devel
[root@localhost]# yum install --downloadonly --downloaddir=/soft/nginx/ openssl openssl-devel
也可以通过yum命令一键下载(推荐上面哪种方式):
[root@localhost]# yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel
执行完成后,然后ls查看目录文件,会看一大堆依赖:
紧接着通过rpm命令依次将依赖包一个个构建,或者通过如下指令一键安装所有依赖包:
[root@localhost]# rpm -ivh --nodeps *.rpm
❺进入解压后的nginx目录,然后执行Nginx的配置脚本,为后续的安装提前配置好环境,默认位于/usr/local/nginx/目录下(可自定义目录):
[root@localhost]# cd nginx-1.21.6
[root@localhost]# ./configure --prefix=/soft/nginx/
❻编译并安装Nginx:
[root@localhost]# make && make install
❼最后回到前面的/soft/nginx/目录,输入ls即可看见安装nginx完成后生成的文件。
❽修改安装后生成的conf目录下的nginx.conf配置文件:
[root@localhost]# vi conf/nginx.conf
修改端口号:listen 80;
修改IP地址:server_name 你当前机器的本地IP(线上配置域名);
❾制定配置文件并启动Nginx:
[root@localhost]# sbin/nginx -c conf/nginx.conf
[root@localhost]# ps aux | grep nginx
Nginx其他操作命令:
sbin/nginx -t -c conf/nginx.conf # 检测配置文件是否正常
sbin/nginx -s reload -c conf/nginx.conf # 修改配置后平滑重启
sbin/nginx -s quit # 优雅关闭Nginx,会在执行完当前的任务后再退出
sbin/nginx -s stop # 强制终止Nginx,不管当前是否有任务在执行
❿开放80端口,并更新防火墙:
[root@localhost]# firewall-cmd --zone=public --add-port=80/tcp --permanent
[root@localhost]# firewall-cmd --reload
[root@localhost]# firewall-cmd --zone=public --list-ports
⓫在Windows/Mac的浏览器中,直接输入刚刚配置的IP地址访问Nginx:
最终看到如上的Nginx欢迎界面,代表Nginx安装完成。
三、Nginx反向代理-负载均衡
首先通过SpringBoot+Freemarker快速搭建一个WEB项目:springboot-web-nginx,然后在该项目中,创建一个IndexNginxController.java文件,逻辑如下:
@Controller
public class IndexNginxController {
@Value("${server.port}")
private String port;
@RequestMapping("/")
public ModelAndView index(){
ModelAndView model = new ModelAndView();
model.addObject("port", port);
model.setViewName("index");
return model;
}
}
在该Controller类中,存在一个成员变量:port,它的值即是从application.properties配置文件中获取server.port值。当出现访问/资源的请求时,跳转前端index页面,并将该值携带返回。
前端的index.ftl文件代码如下:
<html>
<head>
<title>Nginx演示页面</title>
<link href="nginx_style.css" rel="stylesheet" type="text/css"/>
</head>
<body>
<div style="border: 2px solid red;margin: auto;width: 800px;text-align: center">
<div id="nginx_title">
<h1>欢迎来到熊猫高级会所,我是竹子${port}号!</h1>
</div>
</div>
</body>
</html>
从上可以看出其逻辑并不复杂,仅是从响应中获取了port输出。
OK~,前提工作准备就绪后,再简单修改一下nginx.conf的配置即可:
upstream nginx_boot{
# 30s内检查心跳发送两次包,未回复就代表该机器宕机,请求分发权重比为1:2
server 192.168.0.000:8080 weight=100 max_fails=2 fail_timeout=30s;
server 192.168.0.000:8090 weight=200 max_fails=2 fail_timeout=30s;
# 这里的IP请配置成你WEB服务所在的机器IP
}
server {
location / {
root html;
# 配置一下index的地址,最后加上index.ftl。
index index.html index.htm index.jsp index.ftl;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
# 请求交给名为nginx_boot的upstream上
proxy_pass http://nginx_boot;
}
}
“
至此,所有的前提工作准备就绪,紧接着再启动
Nginx,然后再启动两个web服务,第一个WEB服务启动时,在application.properties配置文件中,将端口号改为8080,第二个WEB服务启动时,将其端口号改为8090。
最终效果就是
因为配置了请求分发的权重,8080、8090的权重比为2:1,因此请求会根据权重比均摊到每台机器,也就是8080一次、8090两次、8080一次…
Nginx请求分发原理
客户端发出的请求192.168.12.129最终会转变为:http://192.168.12.129:80/,然后再向目标IP发起请求,流程如下:
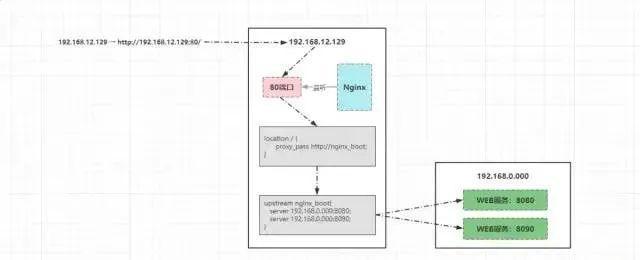
- 由于
Nginx监听了192.168.12.129的80端口,所以最终该请求会找到Nginx进程; Nginx首先会根据配置的location规则进行匹配,根据客户端的请求路径/,会定位到location /{}规则;- 然后根据该
location中配置的proxy_pass会再找到名为nginx_boot的upstream; - 最后根据
upstream中的配置信息,将请求转发到运行WEB服务的机器处理,由于配置了多个WEB服务,且配置了权重值,因此Nginx会依次根据权重比分发请求。
四、Nginx动静分离
动静分离应该是听的次数较多的性能优化方案,那先思考一个问题:「「为什么需要做动静分离呢?它带来的好处是什么?」」 其实这个问题也并不难回答,当你搞懂了网站的本质后,自然就理解了动静分离的重要性。先来以淘宝为例分析看看:
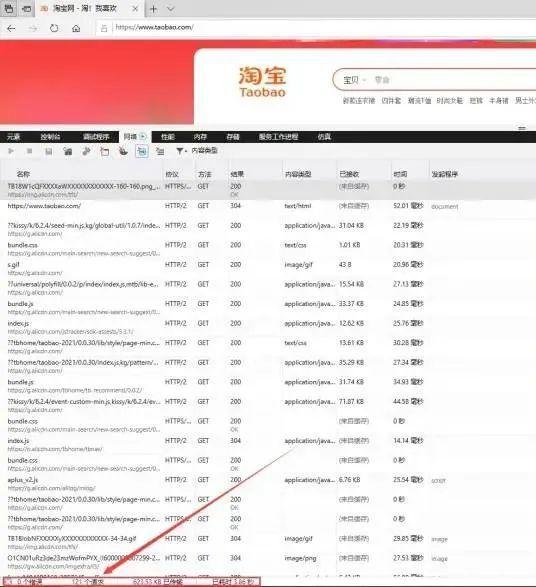
当浏览器输入www.taobao.com访问淘宝首页时,打开开发者调试工具可以很明显的看到,首页加载会出现100+的请求数,而正常项目开发时,静态资源一般会放入到resources/static/目录下:
在项目上线部署时,这些静态资源会一起打成包,那此时思考一个问题:「「假设淘宝也是这样干的,那么首页加载时的请求最终会去到哪儿被处理?」」 答案毋庸置疑,首页100+的所有请求都会来到部署WEB服务的机器处理,那则代表着一个客户端请求淘宝首页,就会对后端服务器造成100+的并发请求。毫无疑问,这对于后端服务器的压力是尤为巨大的。
“但此时不妨分析看看,首页
100+的请求中,是不是至少有60+是属于*.js、*.css、*.html、*.jpg.....这类静态资源的请求呢?答案是Yes。
既然有这么多请求属于静态的,这些资源大概率情况下,长时间也不会出现变动,那为何还要让这些请求到后端再处理呢?能不能在此之前就提前处理掉?当然OK,因此经过分析之后能够明确一点:「「做了动静分离之后,至少能够让后端服务减少一半以上的并发量。」」 到此时大家应该明白了动静分离能够带来的性能收益究竟有多大。
OK~,搞清楚动静分离的必要性之后,如何实现动静分离呢?其实非常简单,实战看看。
①先在部署Nginx的机器,Nginx目录下创建一个目录static_resources:
mkdir static_resources
②将项目中所有的静态资源全部拷贝到该目录下,而后将项目中的静态资源移除重新打包。
③稍微修改一下nginx.conf的配置,增加一条location匹配规则:
location ~ .*\.(html|htm|gif|jpg|jpeg|bmp|png|ico|txt|js|css){
root /soft/nginx/static_resources;
expires 7d;
}
然后照常启动nginx和移除了静态资源的WEB服务,你会发现原本的样式、js效果、图片等依旧有效,如下:
其中static目录下的nginx_style.css文件已被移除,但效果依旧存在。
最后解读一下那条location规则:
location ~ .*\.(html|htm|gif|jpg|jpeg|bmp|png|ico|txt|js|css)
~代表匹配时区分大小写.*代表任意字符都可以出现零次或多次,即资源名不限制\.代表匹配后缀分隔符.(html|...|css)代表匹配括号里所有静态资源类型
综上所述,简单一句话概述:该配置表示匹配以.html~.css为后缀的所有资源请求。
「最后提一嘴,也可以将静态资源上传到文件服务器中,然后location中配置一个新的upstream指向。」
五、Nginx资源压缩
建立在动静分离的基础之上,如果一个静态资源的Size越小,那么自然传输速度会更快,同时也会更节省带宽,因此我们在部署项目时,也可以通过Nginx对于静态资源实现压缩传输,一方面可以节省带宽资源,第二方面也可以加快响应速度并提升系统整体吞吐。
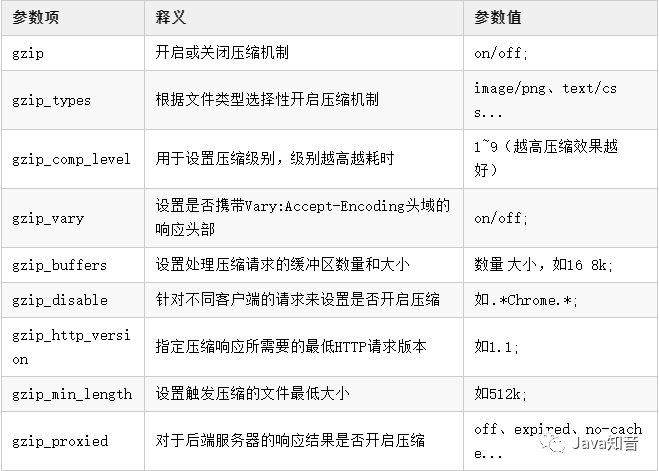
在Nginx也提供了三个支持资源压缩的模块ngx_http_gzip_module、ngx_http_gzip_static_module、ngx_http_gunzip_module,其中ngx_http_gzip_module属于内置模块,代表着可以直接使用该模块下的一些压缩指令,后续的资源压缩操作都基于该模块,先来看看压缩配置的一些参数/指令:
了解了Nginx中的基本压缩配置后,接下来可以在Nginx中简单配置一下:
http{
# 开启压缩机制
gzip on;
# 指定会被压缩的文件类型(也可自己配置其他类型)
gzip_types text/plain application/javascript text/css application/xml text/javascript image/jpeg image/gif image/png;
# 设置压缩级别,越高资源消耗越大,但压缩效果越好
gzip_comp_level 5;
# 在头部中添加Vary: Accept-Encoding(建议开启)
gzip_vary on;
# 处理压缩请求的缓冲区数量和大小
gzip_buffers 16 8k;
# 对于不支持压缩功能的客户端请求不开启压缩机制
gzip_disable "MSIE [1-6]\."; # 低版本的IE浏览器不支持压缩
# 设置压缩响应所支持的HTTP最低版本
gzip_http_version 1.1;
# 设置触发压缩的最小阈值
gzip_min_length 2k;
# 关闭对后端服务器的响应结果进行压缩
gzip_proxied off;
}
在上述的压缩配置中,最后一个gzip_proxied选项,可以根据系统的实际情况决定,总共存在多种选项:
off:关闭Nginx对后台服务器的响应结果进行压缩。expired:如果响应头中包含Expires信息,则开启压缩。no-cache:如果响应头中包含Cache-Control:no-cache信息,则开启压缩。no-store:如果响应头中包含Cache-Control:no-store信息,则开启压缩。private:如果响应头中包含Cache-Control:private信息,则开启压缩。no_last_modified:如果响应头中不包含Last-Modified信息,则开启压缩。no_etag:如果响应头中不包含ETag信息,则开启压缩。auth:如果响应头中包含Authorization信息,则开启压缩。any:无条件对后端的响应结果开启压缩机制。
OK~,简单修改好了Nginx的压缩配置后,可以在原本的index页面中引入一个jquery-3.6.0.js文件:
<script type="text/javascript" src="jquery-3.6.0.js"></script>
分别来对比下压缩前后的区别:
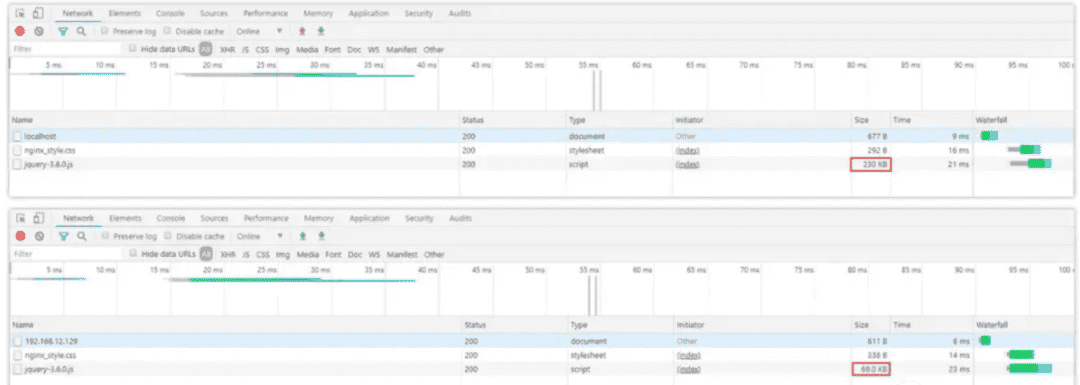
从图中可以很明显看出,未开启压缩机制前访问时,js文件的原始大小为230K,当配置好压缩后再重启Nginx,会发现文件大小从230KB→69KB,效果立竿见影!
“
注意点:①对于图片、视频类型的数据,会默认开启压缩机制,因此一般无需再次开启压缩。②对于
.js文件而言,需要指定压缩类型为application/javascript,而并非text/javascript、application/x-javascript。
六、Nginx缓冲区
先来思考一个问题,接入Nginx的项目一般请求流程为:“客户端→Nginx→服务端”,在这个过程中存在两个连接:“客户端→Nginx、Nginx→服务端”,那么两个不同的连接速度不一致,就会影响用户的体验(比如浏览器的加载速度跟不上服务端的响应速度)。
其实也就类似电脑的内存跟不上CPU速度,所以对于用户造成的体验感极差,因此在CPU设计时都会加入三级高速缓冲区,用于缓解CPU和内存速率不一致的矛盾。在Nginx也同样存在缓冲区的机制,主要目的就在于:「「用来解决两个连接之间速度不匹配造成的问题」」 ,有了缓冲后,Nginx代理可暂存后端的响应,然后按需供给数据给客户端。先来看看一些关于缓冲区的配置项:
-
proxy_buffering:是否启用缓冲机制,默认为on关闭状态。 -
client_body_buffer_size:设置缓冲客户端请求数据的内存大小。 -
proxy_buffers:为每个请求/连接设置缓冲区的数量和大小,默认4 4k/8k。 -
proxy_buffer_size:设置用于存储响应头的缓冲区大小。 -
proxy_busy_buffers_size:在后端数据没有完全接收完成时,Nginx可以将busy状态的缓冲返回给客户端,该参数用来设置busy状态的buffer具体有多大,默认为proxy_buffer_size*2。 -
proxy_temp_path:当内存缓冲区存满时,可以将数据临时存放到磁盘,该参数是设置存储缓冲数据的目录。 -
path是临时目录的路径。 -
- 语法:
proxy_temp_path path;path是临时目录的路径
- 语法:
-
proxy_temp_file_write_size:设置每次写数据到临时文件的大小限制。 -
proxy_max_temp_file_size:设置临时的缓冲目录中允许存储的最大容量。 -
非缓冲参数项:
-
proxy_connect_timeout:设置与后端服务器建立连接时的超时时间。proxy_read_timeout:设置从后端服务器读取响应数据的超时时间。proxy_send_timeout:设置向后端服务器传输请求数据的超时时间。
具体的nginx.conf配置如下:
http{
proxy_connect_timeout 10;
proxy_read_timeout 120;
proxy_send_timeout 10;
proxy_buffering on;
client_body_buffer_size 512k;
proxy_buffers 4 64k;
proxy_buffer_size 16k;
proxy_busy_buffers_size 128k;
proxy_temp_file_write_size 128k;
proxy_temp_path /soft/nginx/temp_buffer;
}
上述的缓冲区参数,是基于每个请求分配的空间,而并不是所有请求的共享空间。当然,具体的参数值还需要根据业务去决定,要综合考虑机器的内存以及每个请求的平均数据大小。
“
最后提一嘴:使用缓冲也可以减少即时传输带来的带宽消耗。
七、Nginx缓存机制
对于性能优化而言,缓存是一种能够大幅度提升性能的方案,因此几乎可以在各处都能看见缓存,如客户端缓存、代理缓存、服务器缓存等等,Nginx的缓存则属于代理缓存的一种。对于整个系统而言,加入缓存带来的优势额外明显:
- 减少了再次向后端或文件服务器请求资源的带宽消耗。
- 降低了下游服务器的访问压力,提升系统整体吞吐。
- 缩短了响应时间,提升了加载速度,打开页面的速度更快。
那么在Nginx中,又该如何配置代理缓存呢?先来看看缓存相关的配置项:
「proxy_cache_path」:代理缓存的路径。
语法:
proxy_cache_path path [levels=levels] [use_temp_path=on|off] keys_zone=name:size [inactive=time] [max_size=size] [manager_files=number] [manager_sleep=time] [manager_threshold=time] [loader_files=number] [loader_sleep=time] [loader_threshold=time] [purger=on|off] [purger_files=number] [purger_sleep=time] [purger_threshold=time];
是的,你没有看错,就是这么长…,解释一下每个参数项的含义:
path:缓存的路径地址。levels:缓存存储的层次结构,最多允许三层目录。use_temp_path:是否使用临时目录。keys_zone:指定一个共享内存空间来存储热点Key(1M可存储8000个Key)。inactive:设置缓存多长时间未被访问后删除(默认是十分钟)。max_size:允许缓存的最大存储空间,超出后会基于LRU算法移除缓存,Nginx会创建一个Cache manager的进程移除数据,也可以通过purge方式。manager_files:manager进程每次移除缓存文件数量的上限。manager_sleep:manager进程每次移除缓存文件的时间上限。manager_threshold:manager进程每次移除缓存后的间隔时间。loader_files:重启Nginx载入缓存时,每次加载的个数,默认100。loader_sleep:每次载入时,允许的最大时间上限,默认200ms。loader_threshold:一次载入后,停顿的时间间隔,默认50ms。purger:是否开启purge方式移除数据。purger_files:每次移除缓存文件时的数量。purger_sleep:每次移除时,允许消耗的最大时间。purger_threshold:每次移除完成后,停顿的间隔时间。
「proxy_cache」:开启或关闭代理缓存,开启时需要指定一个共享内存区域。
语法:
proxy_cache zone | off;
zone为内存区域的名称,即上面中keys_zone设置的名称。
「proxy_cache_key」:定义如何生成缓存的键。
语法:
proxy_cache_key string;
string为生成Key的规则,如$scheme$proxy_host$request_uri。
「proxy_cache_valid」:缓存生效的状态码与过期时间。
语法:
proxy_cache_valid [code ...] time;
code为状态码,time为有效时间,可以根据状态码设置不同的缓存时间。
例如:proxy_cache_valid 200 302 30m;
「proxy_cache_min_uses」:设置资源被请求多少次后被缓存。
语法:
proxy_cache_min_uses number;
number为次数,默认为1。
「proxy_cache_use_stale」:当后端出现异常时,是否允许Nginx返回缓存作为响应。
语法:
proxy_cache_use_stale error;
error为错误类型,可配置timeout|invalid_header|updating|http_500...。
「proxy_cache_lock」:对于相同的请求,是否开启锁机制,只允许一个请求发往后端。
语法:
proxy_cache_lock on | off;
「proxy_cache_lock_timeout」:配置锁超时机制,超出规定时间后会释放请求。
proxy_cache_lock_timeout time;
「proxy_cache_methods」:设置对于那些HTTP方法开启缓存。
语法:
proxy_cache_methods method;
method为请求方法类型,如GET、HEAD等。
「proxy_no_cache」:定义不存储缓存的条件,符合时不会保存。
语法:
proxy_no_cache string...;
string为条件,例如$cookie_nocache $arg_nocache $arg_comment;
「proxy_cache_bypass」:定义不读取缓存的条件,符合时不会从缓存中读取。
语法:
proxy_cache_bypass string...;
和上面proxy_no_cache的配置方法类似。
「add_header」:往响应头中添加字段信息。
语法:
add_header fieldName fieldValue;
「$upstream_cache_status」:记录了缓存是否命中的信息,存在多种情况:
MISS:请求未命中缓存。HIT:请求命中缓存。EXPIRED:请求命中缓存但缓存已过期。STALE:请求命中了陈旧缓存。REVALIDDATED:Nginx验证陈旧缓存依然有效。UPDATING:命中的缓存内容陈旧,但正在更新缓存。BYPASS:响应结果是从原始服务器获取的。
“
PS:这个和之前的不同,之前的都是参数项,这个是一个Nginx内置变量。
OK~,对于Nginx中的缓存配置项大概了解后,接着来配置一下Nginx代理缓存:
http{
# 设置缓存的目录,并且内存中缓存区名为hot_cache,大小为128m,
# 三天未被访问过的缓存自动清楚,磁盘中缓存的最大容量为2GB。
proxy_cache_path /soft/nginx/cache levels=1:2 keys_zone=hot_cache:128m inactive=3d max_size=2g;
server{
location / {
# 使用名为nginx_cache的缓存空间
proxy_cache hot_cache;
# 对于200、206、304、301、302状态码的数据缓存1天
proxy_cache_valid 200 206 304 301 302 1d;
# 对于其他状态的数据缓存30分钟
proxy_cache_valid any 30m;
# 定义生成缓存键的规则(请求的url+参数作为key)
proxy_cache_key $host$uri$is_args$args;
# 资源至少被重复访问三次后再加入缓存
proxy_cache_min_uses 3;
# 出现重复请求时,只让一个去后端读数据,其他的从缓存中读取
proxy_cache_lock on;
# 上面的锁超时时间为3s,超过3s未获取数据,其他请求直接去后端
proxy_cache_lock_timeout 3s;
# 对于请求参数或cookie中声明了不缓存的数据,不再加入缓存
proxy_no_cache $cookie_nocache $arg_nocache $arg_comment;
# 在响应头中添加一个缓存是否命中的状态(便于调试)
add_header Cache-status $upstream_cache_status;
}
}
}
接着来看一下效果,如下:
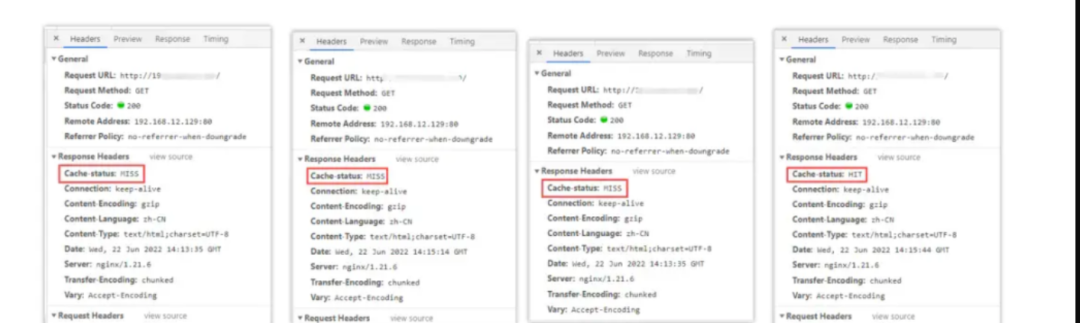
第一次访问时,因为还没有请求过资源,所以缓存中没有数据,因此没有命中缓存。第二、三次,依旧没有命中缓存,直至第四次时才显示命中,这是为什么呢?因为在前面的缓存配置中,我们配置了加入缓存的最低条件为:「「资源至少要被请求三次以上才会加入缓存。」」 这样可以避免很多无效缓存占用空间。
缓存清理
当缓存过多时,如果不及时清理会导致磁盘空间被“吃光”,因此我们需要一套完善的缓存清理机制去删除缓存,在之前的proxy_cache_path参数中有purger相关的选项,开启后可以帮我们自动清理缓存,但遗憾的是:purger系列参数只有商业版的NginxPlus才能使用,因此需要付费才可使用。
不过天无绝人之路,我们可以通过强大的第三方模块ngx_cache_purge来替代,先来安装一下该插件:①首先去到Nginx的安装目录下,创建一个cache_purge目录:
[root@localhost]# mkdir cache_purge && cd cache_purge
②通过wget指令从github上拉取安装包的压缩文件并解压:
[root@localhost]# wget https://github.com/FRiCKLE/ngx_cache_purge/archive/2.3.tar.gz
[root@localhost]# tar -xvzf 2.3.tar.gz
③再次去到之前Nginx的解压目录下:
[root@localhost]# cd /soft/nginx/nginx1.21.6
④重新构建一次Nginx,通过--add-module的指令添加刚刚的第三方模块:
[root@localhost]# ./configure --prefix=/soft/nginx/ --add-module=/soft/nginx/cache_purge/ngx_cache_purge-2.3/
⑤重新根据刚刚构建的Nginx,再次编译一下,「但切记不要make install」 :
[root@localhost]# make
⑥删除之前Nginx的启动文件,不放心的也可以移动到其他位置:
[root@localhost]# rm -rf /soft/nginx/sbin/nginx
⑦从生成的objs目录中,重新复制一个Nginx的启动文件到原来的位置:
[root@localhost]# cp objs/nginx /soft/nginx/sbin/nginx
至此,第三方缓存清除模块ngx_cache_purge就安装完成了,接下来稍微修改一下nginx.conf配置,再添加一条location规则:
location ~ /purge(/.*) {
# 配置可以执行清除操作的IP(线上可以配置成内网机器)
# allow 127.0.0.1; # 代表本机
allow all; # 代表允许任意IP清除缓存
proxy_cache_purge $host$1$is_args$args;
}
然后再重启Nginx,接下来即可通过http://xxx/purge/xx的方式清除缓存。
八、Nginx实现IP黑白名单
有时候往往有些需求,可能某些接口只能开放给对应的合作商,或者购买/接入API的合作伙伴,那么此时就需要实现类似于IP白名单的功能。而有时候有些恶意攻击者或爬虫程序,被识别后需要禁止其再次访问网站,因此也需要实现IP黑名单。那么这些功能无需交由后端实现,可直接在Nginx中处理。
Nginx做黑白名单机制,主要是通过allow、deny配置项来实现:
allow xxx.xxx.xxx.xxx; # 允许指定的IP访问,可以用于实现白名单。
deny xxx.xxx.xxx.xxx; # 禁止指定的IP访问,可以用于实现黑名单。
要同时屏蔽/开放多个IP访问时,如果所有IP全部写在nginx.conf文件中定然是不显示的,这种方式比较冗余,那么可以新建两个文件BlocksIP.conf、WhiteIP.conf:
# --------黑名单:BlocksIP.conf---------
deny 192.177.12.222; # 屏蔽192.177.12.222访问
deny 192.177.44.201; # 屏蔽192.177.44.201访问
deny 127.0.0.0/8; # 屏蔽127.0.0.1到127.255.255.254网段中的所有IP访问
# --------白名单:WhiteIP.conf---------
allow 192.177.12.222; # 允许192.177.12.222访问
allow 192.177.44.201; # 允许192.177.44.201访问
allow 127.45.0.0/16; # 允许127.45.0.1到127.45.255.254网段中的所有IP访问
deny all; # 除开上述IP外,其他IP全部禁止访问
分别将要禁止/开放的IP添加到对应的文件后,可以再将这两个文件在nginx.conf中导入:
http{
# 屏蔽该文件中的所有IP
include /soft/nginx/IP/BlocksIP.conf;
server{
location xxx {
# 某一系列接口只开放给白名单中的IP
include /soft/nginx/IP/blockip.conf;
}
}
}
对于文件具体在哪儿导入,这个也并非随意的,如果要整站屏蔽/开放就在http中导入,如果只需要一个域名下屏蔽/开放就在sever中导入,如果只需要针对于某一系列接口屏蔽/开放IP,那么就在location中导入。
“
当然,上述只是最简单的
IP黑/白名单实现方式,同时也可以通过ngx_http_geo_module、ngx_http_geo_module第三方库去实现(这种方式可以按地区、国家进行屏蔽,并且提供了IP库)。
九、Nginx跨域配置
跨域问题在之前的单体架构开发中,其实是比较少见的问题,除非是需要接入第三方SDK时,才需要处理此问题。但随着现在前后端分离、分布式架构的流行,跨域问题也成为了每个Java开发必须要懂得解决的一个问题。
跨域问题产生的原因
产生跨域问题的主要原因就在于 「同源策略」 ,为了保证用户信息安全,防止恶意网站窃取数据,同源策略是必须的,否则cookie可以共享。由于http无状态协议通常会借助cookie来实现有状态的信息记录,例如用户的身份/密码等,因此一旦cookie被共享,那么会导致用户的身份信息被盗取。
同源策略主要是指三点相同,「「协议+域名+端口」」 相同的两个请求,则可以被看做是同源的,但如果其中任意一点存在不同,则代表是两个不同源的请求,同源策略会限制了不同源之间的资源交互。
Nginx解决跨域问题
弄明白了跨域问题的产生原因,接下来看看Nginx中又该如何解决跨域呢?其实比较简单,在nginx.conf中稍微添加一点配置即可:
location / {
# 允许跨域的请求,可以自定义变量$http_origin,*表示所有
add_header 'Access-Control-Allow-Origin' *;
# 允许携带cookie请求
add_header 'Access-Control-Allow-Credentials' 'true';
# 允许跨域请求的方法:GET,POST,OPTIONS,PUT
add_header 'Access-Control-Allow-Methods' 'GET,POST,OPTIONS,PUT';
# 允许请求时携带的头部信息,*表示所有
add_header 'Access-Control-Allow-Headers' *;
# 允许发送按段获取资源的请求
add_header 'Access-Control-Expose-Headers' 'Content-Length,Content-Range';
# 一定要有!!!否则Post请求无法进行跨域!
# 在发送Post跨域请求前,会以Options方式发送预检请求,服务器接受时才会正式请求
if ($request_method = 'OPTIONS') {
add_header 'Access-Control-Max-Age' 1728000;
add_header 'Content-Type' 'text/plain; charset=utf-8';
add_header 'Content-Length' 0;
# 对于Options方式的请求返回204,表示接受跨域请求
return 204;
}
}
在nginx.conf文件加上如上配置后,跨域请求即可生效了。
“
但如果后端是采用分布式架构开发的,有时候RPC调用也需要解决跨域问题,不然也同样会出现无法跨域请求的异常,因此可以在你的后端项目中,通过继承
HandlerInterceptorAdapter类、实现WebMvcConfigurer接口、添加@CrossOrgin注解的方式实现接口之间的跨域配置。
十、Nginx防盗链设计
首先了解一下何谓盗链:「「盗链即是指外部网站引入当前网站的资源对外展示」」 ,来举个简单的例子理解:
“
好比壁纸网站
X站、Y站,X站是一点点去购买版权、签约作者的方式,从而积累了海量的壁纸素材,但Y站由于资金等各方面的原因,就直接通过<img src="X站/xxx.jpg" />这种方式照搬了X站的所有壁纸资源,继而提供给用户下载。
那么如果我们自己是这个X站的Boss,心中必然不爽,那么此时又该如何屏蔽这类问题呢?那么接下来要叙说的**「「防盗链」」** 登场了!
Nginx的防盗链机制实现,跟一个头部字段:Referer有关,该字段主要描述了当前请求是从哪儿发出的,那么在Nginx中就可获取该值,然后判断是否为本站的资源引用请求,如果不是则不允许访问。Nginx中存在一个配置项为valid_referers,正好可以满足前面的需求,语法如下:
valid_referers none | blocked | server_names | string ...;
none:表示接受没有Referer字段的HTTP请求访问。blocked:表示允许http://或https//以外的请求访问。server_names:资源的白名单,这里可以指定允许访问的域名。string:可自定义字符串,支配通配符、正则表达式写法。
简单了解语法后,接下来的实现如下:
# 在动静分离的location中开启防盗链机制
location ~ .*\.(html|htm|gif|jpg|jpeg|bmp|png|ico|txt|js|css){
# 最后面的值在上线前可配置为允许的域名地址
valid_referers blocked 192.168.12.129;
if ($invalid_referer) {
# 可以配置成返回一张禁止盗取的图片
# rewrite ^/ http://xx.xx.com/NO.jpg;
# 也可直接返回403
return 403;
}
root /soft/nginx/static_resources;
expires 7d;
}
根据上述中的内容配置后,就已经通过Nginx实现了最基本的防盗链机制,最后只需要额外重启一下就好啦!当然,对于防盗链机制实现这块,也有专门的第三方模块ngx_http_accesskey_module实现了更为完善的设计,感兴趣的小伙伴可以自行去看看。
“
PS:防盗链机制也无法解决爬虫伪造
referers信息的这种方式抓取数据。
十一、Nginx大文件传输配置
在某些业务场景中需要传输一些大文件,但大文件传输时往往都会会出现一些Bug,比如文件超出限制、文件传输过程中请求超时等,那么此时就可以在Nginx稍微做一些配置,先来了解一些关于大文件传输时可能会用的配置项:

在传输大文件时,client_max_body_size、client_header_timeout、proxy_read_timeout、proxy_send_timeout这四个参数值都可以根据自己项目的实际情况来配置。
“
上述配置仅是作为代理层需要配置的,因为最终客户端传输文件还是直接与后端进行交互,这里只是把作为网关层的
Nginx配置调高一点,调到能够“容纳大文件”传输的程度。当然,Nginx中也可以作为文件服务器使用,但需要用到一个专门的第三方模块nginx-upload-module,如果项目中文件上传的作用处不多,那么建议可以通过Nginx搭建,毕竟可以节省一台文件服务器资源。但如若文件上传/下载较为频繁,那么还是建议额外搭建文件服务器,并将上传/下载功能交由后端处理。
十二、Nginx配置SLL证书
随着越来越多的网站接入HTTPS,因此Nginx中仅配置HTTP还不够,往往还需要监听443端口的请求,HTTPS为了确保通信安全,所以服务端需配置对应的数字证书,当项目使用Nginx作为网关时,那么证书在Nginx中也需要配置,接下来简单聊一下关于SSL证书配置过程:
①先去CA机构或从云控制台中申请对应的SSL证书,审核通过后下载Nginx版本的证书。
②下载数字证书后,完整的文件总共有三个:.crt、.key、.pem:
.crt:数字证书文件,.crt是.pem的拓展文件,因此有些人下载后可能没有。.key:服务器的私钥文件,及非对称加密的私钥,用于解密公钥传输的数据。.pem:Base64-encoded编码格式的源证书文本文件,可自行根需求修改拓展名。
③在Nginx目录下新建certificate目录,并将下载好的证书/私钥等文件上传至该目录。
④最后修改一下nginx.conf文件即可,如下:
# ----------HTTPS配置-----------
server {
# 监听HTTPS默认的443端口
listen 443;
# 配置自己项目的域名
server_name www.xxx.com;
# 打开SSL加密传输
ssl on;
# 输入域名后,首页文件所在的目录
root html;
# 配置首页的文件名
index index.html index.htm index.jsp index.ftl;
# 配置自己下载的数字证书
ssl_certificate certificate/xxx.pem;
# 配置自己下载的服务器私钥
ssl_certificate_key certificate/xxx.key;
# 停止通信时,加密会话的有效期,在该时间段内不需要重新交换密钥
ssl_session_timeout 5m;
# TLS握手时,服务器采用的密码套件
ssl_ciphers ECDHE-RSA-AES128-GCM-SHA256:ECDHE:ECDH:AES:HIGH:!NULL:!aNULL:!MD5:!ADH:!RC4;
# 服务器支持的TLS版本
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
# 开启由服务器决定采用的密码套件
ssl_prefer_server_ciphers on;
location / {
....
}
}
# ---------HTTP请求转HTTPS-------------
server {
# 监听HTTP默认的80端口
listen 80;
# 如果80端口出现访问该域名的请求
server_name www.xxx.com;
# 将请求改写为HTTPS(这里写你配置了HTTPS的域名)
rewrite ^(.*)$ https://www.xxx.com;
}
OK~,根据如上配置了Nginx后,你的网站即可通过https://的方式访问,并且当客户端使用http://的方式访问时,会自动将其改写为HTTPS请求。
十三、Nginx的高可用
线上如果采用单个节点的方式部署Nginx,难免会出现天灾人祸,比如系统异常、程序宕机、服务器断电、机房爆炸、地球毁灭…哈哈哈,夸张了。但实际生产环境中确实存在隐患问题,由于Nginx作为整个系统的网关层接入外部流量,所以一旦Nginx宕机,最终就会导致整个系统不可用,这无疑对于用户的体验感是极差的,因此也得保障Nginx高可用的特性。
“
接下来则会通过
keepalived的VIP机制,实现Nginx的高可用。VIP并不是只会员的意思,而是指Virtual IP,即虚拟IP。
keepalived在之前单体架构开发时,是一个用的较为频繁的高可用技术,比如MySQL、Redis、MQ、Proxy、Tomcat等各处都会通过keepalived提供的VIP机制,实现单节点应用的高可用。
Keepalived+重启脚本+双机热备搭建
①首先创建一个对应的目录并下载keepalived到Linux中并解压:
[root@localhost]# mkdir /soft/keepalived && cd /soft/keepalived
[root@localhost]# wget https://www.keepalived.org/software/keepalived-2.2.4.tar.gz
[root@localhost]# tar -zxvf keepalived-2.2.4.tar.gz
②进入解压后的keepalived目录并构建安装环境,然后编译并安装:
[root@localhost]# cd keepalived-2.2.4
[root@localhost]# ./configure --prefix=/soft/keepalived/
[root@localhost]# make && make install
③进入安装目录的/soft/keepalived/etc/keepalived/并编辑配置文件:
[root@localhost]# cd /soft/keepalived/etc/keepalived/
[root@localhost]# vi keepalived.conf
④编辑主机的keepalived.conf核心配置文件,如下:
global_defs {
# 自带的邮件提醒服务,建议用独立的监控或第三方SMTP,也可选择配置邮件发送。
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server localhost
smtp_connect_timeout 30
# 高可用集群主机身份标识(集群中主机身份标识名称不能重复,建议配置成本机IP)
router_id 192.168.12.129
}
# 定时运行的脚本文件配置
vrrp_script check_nginx_pid_restart {
# 之前编写的nginx重启脚本的所在位置
script "/soft/scripts/keepalived/check_nginx_pid_restart.sh"
# 每间隔3秒执行一次
interval 3
# 如果脚本中的条件成立,重启一次则权重-20
weight -20
}
# 定义虚拟路由,VI_1为虚拟路由的标示符(可自定义名称)
vrrp_instance VI_1 {
# 当前节点的身份标识:用来决定主从(MASTER为主机,BACKUP为从机)
state MASTER
# 绑定虚拟IP的网络接口,根据自己的机器的网卡配置
interface ens33
# 虚拟路由的ID号,主从两个节点设置必须一样
virtual_router_id 121
# 填写本机IP
mcast_src_ip 192.168.12.129
# 节点权重优先级,主节点要比从节点优先级高
priority 100
# 优先级高的设置nopreempt,解决异常恢复后再次抢占造成的脑裂问题
nopreempt
# 组播信息发送间隔,两个节点设置必须一样,默认1s(类似于心跳检测)
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
# 将track_script块加入instance配置块
track_script {
# 执行Nginx监控的脚本
check_nginx_pid_restart
}
virtual_ipaddress {
# 虚拟IP(VIP),也可扩展,可配置多个。
192.168.12.111
}
}
⑤克隆一台之前的虚拟机作为从(备)机,编辑从机的keepalived.conf文件,如下:
global_defs {
# 自带的邮件提醒服务,建议用独立的监控或第三方SMTP,也可选择配置邮件发送。
notification_email {
root@localhost
}
notification_email_from root@localhost
smtp_server localhost
smtp_connect_timeout 30
# 高可用集群主机身份标识(集群中主机身份标识名称不能重复,建议配置成本机IP)
router_id 192.168.12.130
}
# 定时运行的脚本文件配置
vrrp_script check_nginx_pid_restart {
# 之前编写的nginx重启脚本的所在位置
script "/soft/scripts/keepalived/check_nginx_pid_restart.sh"
# 每间隔3秒执行一次
interval 3
# 如果脚本中的条件成立,重启一次则权重-20
weight -20
}
# 定义虚拟路由,VI_1为虚拟路由的标示符(可自定义名称)
vrrp_instance VI_1 {
# 当前节点的身份标识:用来决定主从(MASTER为主机,BACKUP为从机)
state BACKUP
# 绑定虚拟IP的网络接口,根据自己的机器的网卡配置
interface ens33
# 虚拟路由的ID号,主从两个节点设置必须一样
virtual_router_id 121
# 填写本机IP
mcast_src_ip 192.168.12.130
# 节点权重优先级,主节点要比从节点优先级高
priority 90
# 优先级高的设置nopreempt,解决异常恢复后再次抢占造成的脑裂问题
nopreempt
# 组播信息发送间隔,两个节点设置必须一样,默认1s(类似于心跳检测)
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
# 将track_script块加入instance配置块
track_script {
# 执行Nginx监控的脚本
check_nginx_pid_restart
}
virtual_ipaddress {
# 虚拟IP(VIP),也可扩展,可配置多个。
192.168.12.111
}
}
⑥新建scripts目录并编写Nginx的重启脚本,check_nginx_pid_restart.sh:
[root@localhost]# mkdir /soft/scripts /soft/scripts/keepalived
[root@localhost]# touch /soft/scripts/keepalived/check_nginx_pid_restart.sh
[root@localhost]# vi /soft/scripts/keepalived/check_nginx_pid_restart.sh
#!/bin/sh
# 通过ps指令查询后台的nginx进程数,并将其保存在变量nginx_number中
nginx_number=`ps -C nginx --no-header | wc -l`
# 判断后台是否还有Nginx进程在运行
if [ $nginx_number -eq 0 ];then
# 如果后台查询不到`Nginx`进程存在,则执行重启指令
/soft/nginx/sbin/nginx -c /soft/nginx/conf/nginx.conf
# 重启后等待1s后,再次查询后台进程数
sleep 1
# 如果重启后依旧无法查询到nginx进程
if [ `ps -C nginx --no-header | wc -l` -eq 0 ];then
# 将keepalived主机下线,将虚拟IP漂移给从机,从机上线接管Nginx服务
systemctl stop keepalived.service
fi
fi
⑦编写的脚本文件需要更改编码格式,并赋予执行权限,否则可能执行失败:
[root@localhost]# vi /soft/scripts/keepalived/check_nginx_pid_restart.sh
:set fileformat=unix # 在vi命令里面执行,修改编码格式
:set ff # 查看修改后的编码格式
[root@localhost]# chmod +x /soft/scripts/keepalived/check_nginx_pid_restart.sh
⑧由于安装keepalived时,是自定义的安装位置,因此需要拷贝一些文件到系统目录中:
[root@localhost]# mkdir /etc/keepalived/
[root@localhost]# cp /soft/keepalived/etc/keepalived/keepalived.conf /etc/keepalived/
[root@localhost]# cp /soft/keepalived/keepalived-2.2.4/keepalived/etc/init.d/keepalived /etc/init.d/
[root@localhost]# cp /soft/keepalived/etc/sysconfig/keepalived /etc/sysconfig/
⑨将keepalived加入系统服务并设置开启自启动,然后测试启动是否正常:
[root@localhost]# chkconfig keepalived on
[root@localhost]# systemctl daemon-reload
[root@localhost]# systemctl enable keepalived.service
[root@localhost]# systemctl start keepalived.service
其他命令:
systemctl disable keepalived.service # 禁止开机自动启动
systemctl restart keepalived.service # 重启keepalived
systemctl stop keepalived.service # 停止keepalived
tail -f /var/log/messages # 查看keepalived运行时日志
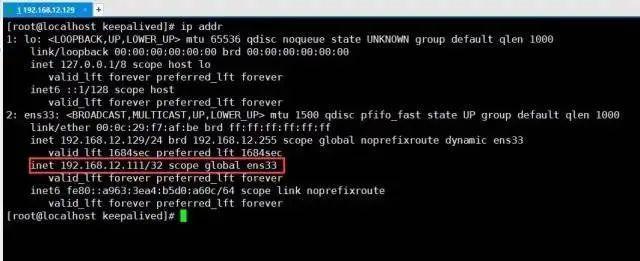
⑩最后测试一下VIP是否生效,通过查看本机是否成功挂载虚拟IP:
[root@localhost]# ip addr
“
从上图中可以明显看见虚拟
IP已经成功挂载,但另外一台机器192.168.12.130并不会挂载这个虚拟IP,只有当主机下线后,作为从机的192.168.12.130才会上线,接替VIP。最后测试一下外网是否可以正常与VIP通信,即在Windows中直接ping VIP:
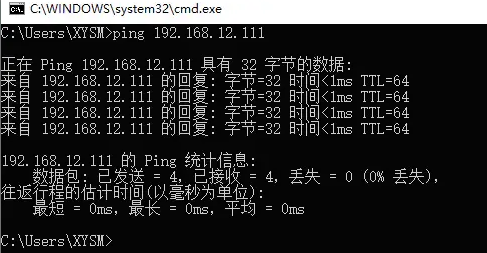
外部通过VIP通信时,也可以正常Ping通,代表虚拟IP配置成功。
Nginx高可用性测试
经过上述步骤后,keepalived的VIP机制已经搭建成功,在上个阶段中主要做了几件事:
- 一、为部署
Nginx的机器挂载了VIP。 - 二、通过
keepalived搭建了主从双机热备。 - 三、通过
keepalived实现了Nginx宕机重启。
由于前面没有域名的原因,因此最初server_name配置的是当前机器的IP,所以需稍微更改一下nginx.conf的配置:
sever{
listen 80;
# 这里从机器的本地IP改为虚拟IP
server_name 192.168.12.111;
# 如果这里配置的是域名,那么则将域名的映射配置改为虚拟IP
}
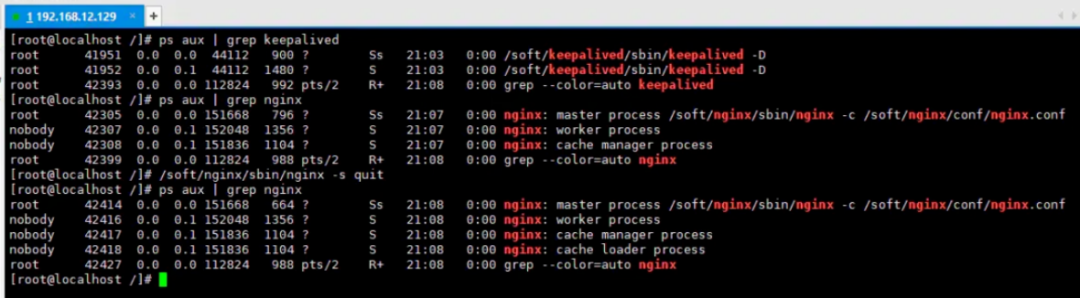
最后来实验一下效果:
“
在上述过程中,首先分别启动了
keepalived、nginx服务,然后通过手动停止nginx的方式模拟了Nginx宕机情况,过了片刻后再次查询后台进程,我们会发现nginx依旧存活。
从这个过程中不难发现,keepalived已经为我们实现了Nginx宕机后自动重启的功能,那么接着再模拟一下服务器出现故障时的情况:
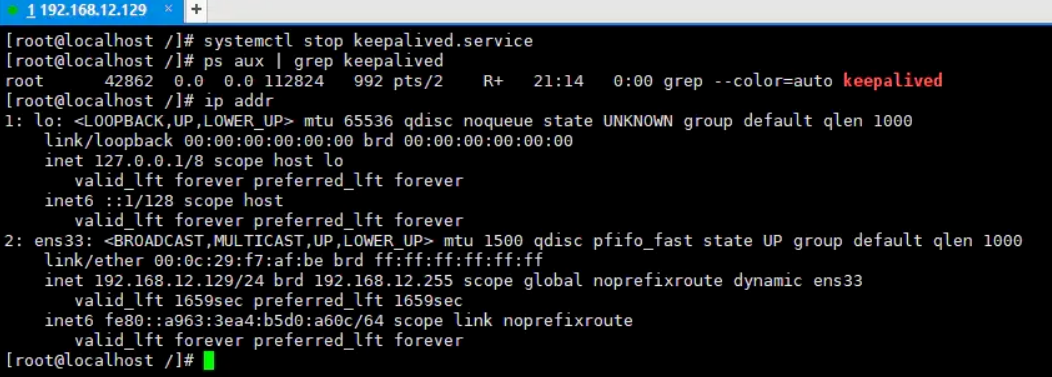
“
在上述过程中,我们通过手动关闭
keepalived服务模拟了机器断电、硬件损坏等情况(因为机器断电等情况=主机中的keepalived进程消失),然后再次查询了一下本机的IP信息,很明显会看到VIP消失了!
现在再切换到另外一台机器:192.168.12.130来看看情况:
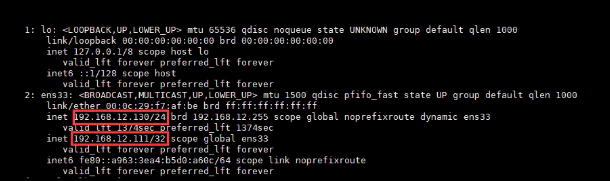
“
此刻我们会发现,在主机
192.168.12.129宕机后,VIP自动从主机飘移到了从机192.168.12.130上,而此时客户端的请求就最终会来到130这台机器的Nginx上。
「「最终,利用Keepalived对Nginx做了主从热备之后,无论是遇到线上宕机还是机房断电等各类故障时,都能够确保应用系统能够为用户提供7x24小时服务。」」
十四、Nginx性能优化
到这里文章的篇幅较长了,最后再来聊一下关于Nginx的性能优化,主要就简单说说收益最高的几个优化项,在这块就不再展开叙述了,毕竟影响性能都有多方面原因导致的,比如网络、服务器硬件、操作系统、后端服务、程序自身、数据库服务等。
优化一:打开长连接配置
通常Nginx作为代理服务,负责分发客户端的请求,那么建议开启HTTP长连接,用户减少握手的次数,降低服务器损耗,具体如下:
upstream xxx {
# 长连接数
keepalive 32;
# 每个长连接提供的最大请求数
keepalived_requests 100;
# 每个长连接没有新的请求时,保持的最长时间
keepalive_timeout 60s;
}
优化二、开启零拷贝技术
零拷贝这个概念,在大多数性能较为不错的中间件中都有出现,例如Kafka、Netty等,而Nginx中也可以配置数据零拷贝技术,如下:
sendfile on; # 开启零拷贝机制
零拷贝读取机制与传统资源读取机制的区别:
- 「传统方式:」 硬件–>内核–>用户空间–>程序空间–>程序内核空间–>网络套接字
- 「零拷贝方式:」 硬件–>内核–>程序内核空间–>网络套接字
从上述这个过程对比,很轻易就能看出两者之间的性能区别。
优化三、开启无延迟或多包共发机制
在Nginx中有两个较为关键的性能参数,即tcp_nodelay、tcp_nopush,开启方式如下:
tcp_nodelay on;
tcp_nopush on;
TCP/IP协议中默认是采用了Nagle算法的,即在网络数据传输过程中,每个数据报文并不会立马发送出去,而是会等待一段时间,将后面的几个数据包一起组合成一个数据报文发送,但这个算法虽然提高了网络吞吐量,但是实时性却降低了。
“
因此你的项目属于交互性很强的应用,那么可以手动开启
tcp_nodelay配置,让应用程序向内核递交的每个数据包都会立即发送出去。但这样会产生大量的TCP报文头,增加很大的网络开销。
相反,有些项目的业务对数据的实时性要求并不高,追求的则是更高的吞吐,那么则可以开启tcp_nopush配置项,这个配置就类似于“塞子”的意思,首先将连接塞住,使得数据先不发出去,等到拔去塞子后再发出去。设置该选项后,内核会尽量把小数据包拼接成一个大的数据包(一个MTU)再发送出去.
“
当然若一定时间后(一般为
200ms),内核仍然没有积累到一个MTU的量时,也必须发送现有的数据,否则会一直阻塞。
tcp_nodelay、tcp_nopush两个参数是“互斥”的,如果追求响应速度的应用推荐开启tcp_nodelay参数,如IM、金融等类型的项目。如果追求吞吐量的应用则建议开启tcp_nopush参数,如调度系统、报表系统等。
“
注意:①
tcp_nodelay一般要建立在开启了长连接模式的情况下使用。②tcp_nopush参数是必须要开启sendfile参数才可使用的。
优化四、调整Worker工作进程
Nginx启动后默认只会开启一个Worker工作进程处理客户端请求,而我们可以根据机器的CPU核数开启对应数量的工作进程,以此来提升整体的并发量支持,如下:
# 自动根据CPU核心数调整Worker进程数量
worker_processes auto;
“
工作进程的数量最高开到
8个就OK了,8个之后就不会有再大的性能提升。
同时也可以稍微调整一下每个工作进程能够打开的文件句柄数:
# 每个Worker能打开的文件描述符,最少调整至1W以上,负荷较高建议2-3W
worker_rlimit_nofile 20000;
“
操作系统内核(
kernel)都是利用文件描述符来访问文件,无论是打开、新建、读取、写入文件时,都需要使用文件描述符来指定待操作的文件,因此该值越大,代表一个进程能够操作的文件越多(但不能超出内核限制,最多建议3.8W左右为上限)。
优化五、开启CPU亲和机制
对于并发编程较为熟悉的伙伴都知道,因为进程/线程数往往都会远超出系统CPU的核心数,因为操作系统执行的原理本质上是采用时间片切换机制,也就是一个CPU核心会在多个进程之间不断频繁切换,造成很大的性能损耗。
而CPU亲和机制则是指将每个Nginx的工作进程,绑定在固定的CPU核心上,从而减小CPU切换带来的时间开销和资源损耗,开启方式如下:
worker_cpu_affinity auto;
优化六、开启epoll模型及调整并发连接数
在最开始就提到过:Nginx、Redis都是基于多路复用模型去实现的程序,但最初版的多路复用模型select/poll最大只能监听1024个连接,而epoll则属于select/poll接口的增强版,因此采用该模型能够大程度上提升单个Worker的性能,如下:
events {
# 使用epoll网络模型
use epoll;
# 调整每个Worker能够处理的连接数上限
worker_connections 10240;
}
这里对于
select/poll/epoll模型就不展开细说了,后面的IO模型文章中会详细剖析。
总结
nginx 在服务的大部分作用,实操,文章内都做描述,就说不熟到服务器上还有什么不能搞的,小伙伴们,一起学起来呦