YOLOv5S网络框架设计-CSC&C3&SPPF模块
总体框架:
在6.0版本的框架中,Neck和Head是一个整体统称为Head
Yolov5s由Backbone(网络主干)和Head(头部)组成
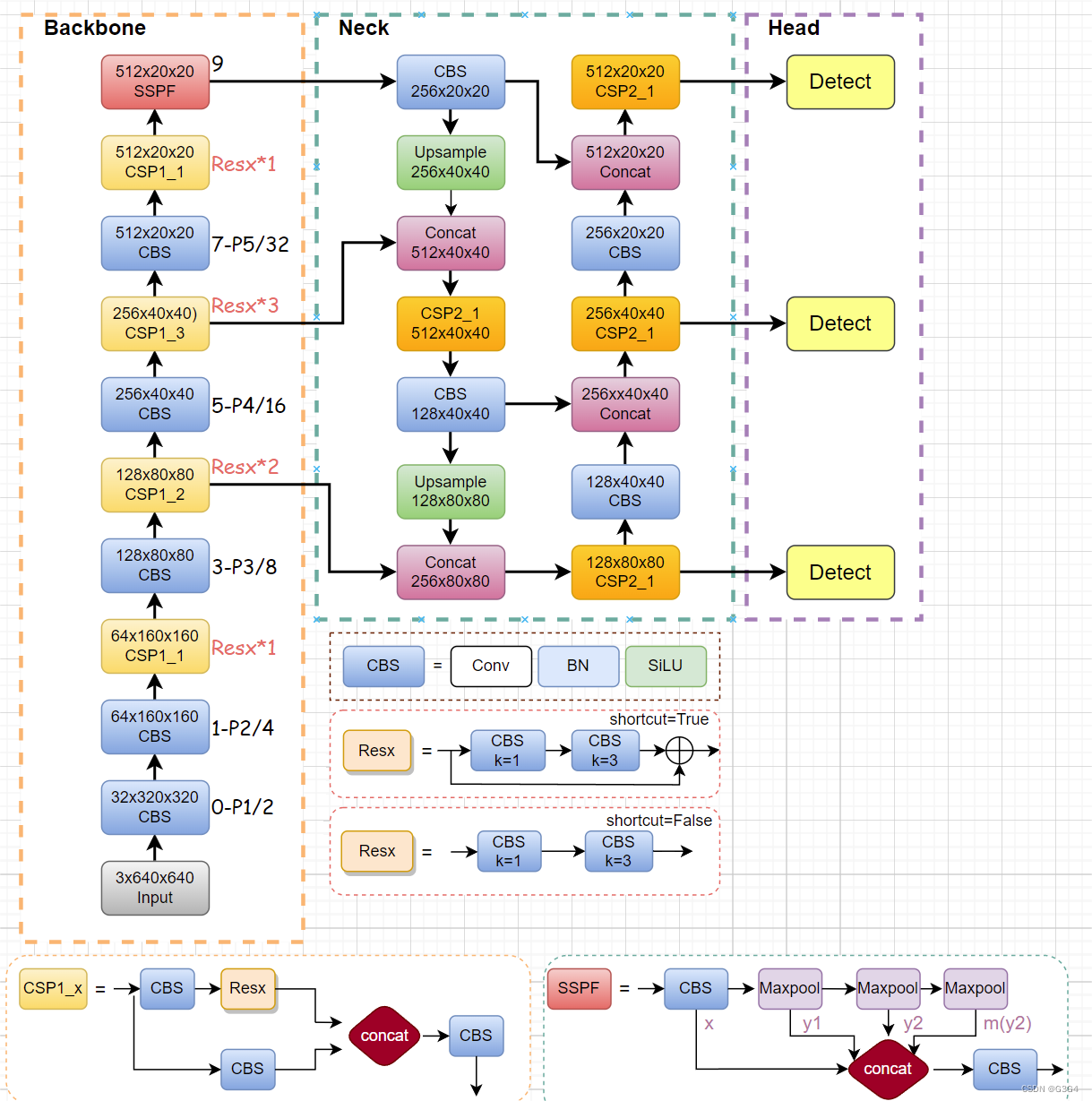
各个小模块
CBS模块

CBS模块在common.py中定义为Class Conv:
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
return self.act(self.conv(x))
CBS: C代表Conv,B代表BatchNorm2d,S代表SiLu激活函数
CBS模块封装了卷积、批归一化和激活函数的组合操作
self.conv : 用nn.Conv2d 创建了一个二维卷积层
self.bn:使用 nn.BatchNorm2d 创建了一个二维批归一化层
self.act:根据 act 参数确定是否应用激活函数,默认为 nn.SiLU(),如果 act 既不是 True 也不是 nn.Module 类型,则应用恒等函数 nn.Identity()。
运算顺序由前向传播方法def forward 中,先对输入 x 进行卷积操作,然后应用批归一化和激活函数,并返回结果。
在融合正向传播方法 forward_fuse 中,与正向传播方法类似,但没有应用批归一化层,仅对卷积结果应用激活函数,并返回结果。
nn.Conv2d 对由多个输入平面组成的输入信号进行二维卷积
二维卷积的定义:一维卷积卷积核只能在长度方向上进行滑窗操作,二维卷积可以在长和宽方向上进行滑窗操作,三维卷积可以在长、宽以及channel方向上进行滑窗操作。一个卷积核运算一次得到一个值,output channel取决于卷积核的个数。
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
c1:输入通道数c2:输出通道数k:卷积核大小,默认为1s:步长,默认为1autopad(k, p)是一个辅助函数,用于自动计算卷积操作中的填充大小,k:卷积核的大小,p:期望的输出特征图的大小,填充大小groups:分组数,默认为1,表示不使用分组卷积,大于1则使用分组卷积;bias:是否使用偏置项,默认为False,表示不使用偏置项
另:Conv2d中还有一个重要的参数就是空洞卷积dilation,通俗解释就是控制kernel点(卷积核点)间距的参数,通过改变卷积核间距实现特征图及特征信息的保留,在语义分割任务中空洞卷积比较有效。
nn.BatchNorm2d数据归一化处理
在卷积神经网络的卷积层后一般会添加BatchNorm2d进行数据归一化处理,使数据在进行激活函数非线性处理单元之前不会因为数据过大而导致网络性能不稳定。
目的:使特征图满足均值为0,方差为1的分布规律。对输入batch的每一个特征通道进行Normalize。
nn.SiLU激活函数
激活函数定义:在多层神经网络中,上层节点的输出和下层节点的输入之间具有一个函数关系,这个函数称为激活函数。
激活函数使神经网络具有非线性,决定感知机是否激发。这种非线性赋予了深度网络学习复杂函数的能力。如果不使用激活函数,则相当于f(x)=x,这也就是最原始的感知机,即每一层节点的输入都是上层输出的线性函数,使得网络的逼近能力有限。
YOLOv5中激活函数实现的相关代码在utils/activations.py中
C3模块
C3模块在common.py中定义为Class C3:
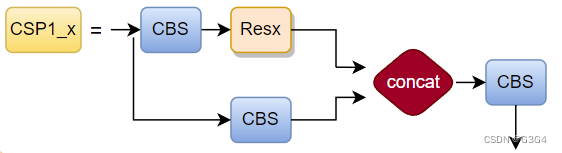
CSP即backbone中的C3,因为在backbone中C3存在shortcut,而在neck中C3不使用shortcut,所以backbone中的C3层使用CSP1_x表示,neck中的C3使用CSP2_x表示。
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels 隐藏通道数
self.cv1 = Conv(c1, c_, 1, 1)#输入通道数,输出通道数,卷积核大小,步长
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # 输入通道数,输出通道数,卷积核大小,act=FReLU(c2)
self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
参数说明:
c_:隐藏通道数c1:输入通道数c2:输出通道数n:CSP Bottleneck 的重复次数,默认为1shortcut:是否使用残差连接(shortcut connection),默认为Trueg:组卷积(group convolution)的分组数,默认为1e:通道扩展率(channel expansion rate),默认为0.5
self.cv1:调用了自定义的 Conv 模块来进行1*1卷积操作,输入通道数c1,输出通道数是隐藏通道数c_
self.cv2:与self.cv1相同
self.cv3:将两个特征图压缩为输出通道数,输入通道数是隐藏通道数的二倍,输出通道数c2
self.m:self.m操作使用nn.Sequential将n个Bottleneck块串接到网络中(具体几个要结合配置文件里的参数计算!即number×depth_multiple个),每个Bottleneck块具有输入和输出通道数都为 c_
forward(self, x):前向传播方法,定义了模块的数据流。输入特征图有两个分支,一条分支通过第一个卷积层 self.cv1,再经过self.m进行 CSP Bottleneck 处理,得到子特征图1;另一分支通过第二个卷积层 self.cv2后得到子特征图2。最后将子特征图1和子特征图2按通道拼接(torch.cat)并通过第三个卷积层 self.cv3 得到最终输出。
Bottleneck:瓶颈层
要想了解Bottleneck,还要从Resnet说起。在Resnet出现之前,人们的普遍为网络越深获取信息也越多,模型泛化效果越好。然而随后大量的研究表明,网络深度到达一定的程度后,模型的准确率反而大大降低。这并不是过拟合造成的,而是由于反向传播过程中的梯度爆炸和梯度消失。也就是说,网络越深,模型越难优化,而不是学习不到更多的特征。
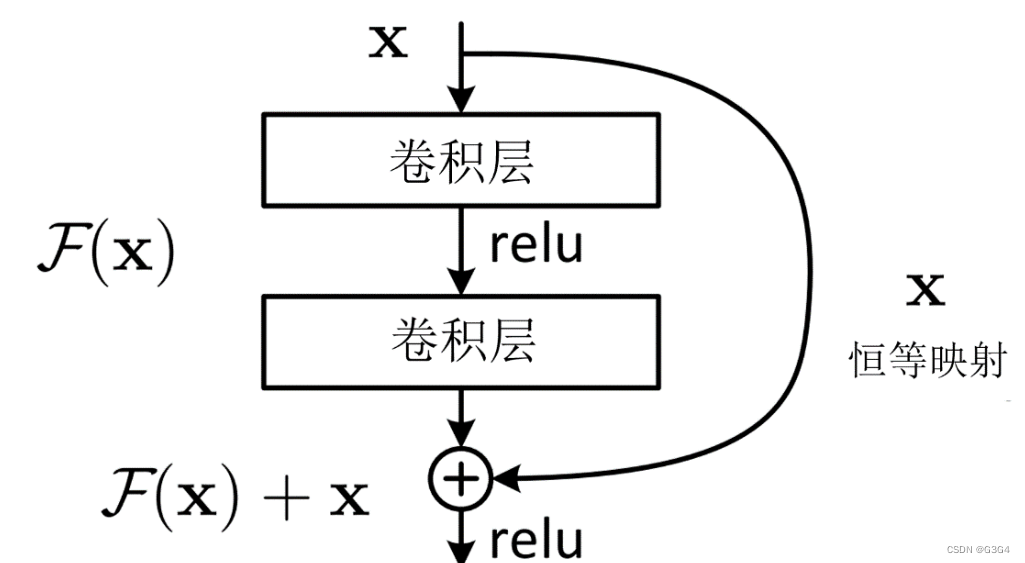
为了能让深层次的网络模型达到更好的训练效果,残差网络中提出的残差映射替换了以往的基础映射。对于输入x,期望输出H(x),网络利用恒等映射将x作为初始结果,将原来的映射关系变成F(x)+x。与其让多层卷积去近似估计H(x) ,不如近似估计H(x)-x,即近似估计残差F(x)。因此,ResNet相当于将学习目标改变为目标值H(x)和x的差值,后面的训练目标就是要将残差结果逼近于0
残差模块的优点:
1.梯度弥散方面。加入ResNet中的shortcut结构之后,在反传时,每两个block之间不仅传递了梯度,还加上了求导之前的梯度,这相当于把每一个block中向前传递的梯度人为加大了,也就会减小梯度弥散的可能性。
2.特征冗余方面。正向卷积时,对每一层做卷积其实只提取了图像的一部分信息,这样一来,越到深层,原始图像信息的丢失越严重,而仅仅是对原始图像中的一小部分特征做提取。这显然会发生类似欠拟合的现象。加入shortcut结构,相当于在每个block中又加入了上一层图像的全部信息,一定程度上保留了更多的原始信息。
在resnet中,人们可以使用带有shortcut的残差模块搭建几百层甚至上千层的网络,而浅层的残差模块被命名为Basicblock(18、34),深层网络所使用的的残差模块,就被命名为了Bottleneck(50+)
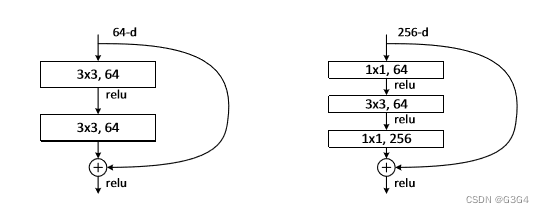
Bottleneck与Basicblock最大的区别是卷积核的组成。 Basicblock由两个3x3的卷积层组成,Bottleneck由两个1x1卷积层夹一个3x3卷积层组成:其中1x1卷积层降维后再恢复维数,让3x3卷积在计算过程中的参数量更少、速度更快。Bottleneck减少了参数量,优化了计算,保持了原有的精度。
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
可以看到,CSP中的Bottleneck同resnet模块中的类似,先是1x1的卷积层(CBS),然后再是3x3的卷积层,最后通过shortcut与初始输入相加。但是这里与resnet的不同点在于:CSP将输入维度减半运算后并未再使用1x1卷积核进行升维,而是将原始输入x也降了维,采取concat的方法进行张量的拼接,得到与原始输入相同维度的输出。其实这里能区分一点就够了:resnet中的shortcut通过add实现,是特征图对应位置相加而通道数不变;而CSP中的shortcut通过concat实现,是通道数的增加。二者虽然都是信息融合的主要方式,但是对张量的具体操作又不相同.
其次,对于shortcut是可根据任务要求设置的,比如在backbone中shortcut=True,neck中shortcut=False。


SPPF模块
SPPF模块在common.py中定义为Class SPPF:
class SPPF(nn.Module):
# Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher
def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13))
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1 = self.m(x)
y2 = self.m(y1)
return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1))
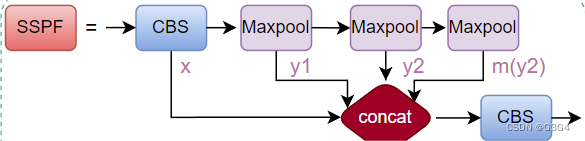
SSPF模块将经过CBS的x、一次池化后的y1、两次池化后的y2和3次池化后的self.m(y2)先进行拼接,然后再CBS提取特征
SPPF 层通过使用不同大小的池化核来捕捉输入图像的多尺度信息,并且减少通道数。这有助于提高模型的感受野和特征表达能力。
nn.MaxPool2d:最大池化操作
卷积操作中池化层提取重要信息的操作,可以去掉不重要的信息,减少计算开销。最大池化操作相当于核在图像上移动的时候,筛选出被核覆盖区域的最大值。目的就是为了保留输入的特征,但是同时把数据量减少,对于整个网路来说,进行计算的参数就变少了,就会训练的更快。