操作系统4:进程通信类型和通信实现方式
目录
(3)消息传递系统(Message passing system)
(4)客户机-服务器系统(Client-Server system)
进程通信是指进程之间的信息交换。由于进程的互斥与同步,需要在进程间交换一定的信息,所以它们也是一种进程通信,但只是一种低级的进程通信。比如信号量机制,该机制通信低级的原因在于:
- 效率低:生产者每次只能向缓冲池投放一个产品(消息),消费者每次只能从缓冲区中取得一个消息。//数据量少
- 通信对用户不透明:OS 只为进程之间的通信提供了共享存储器。而关于进程之间通信所需之共享数据结构的设置、数据的传送、进程的互斥与同步,都必须由程序员去实现,显然,对于用户而言,这是非常不方便的。//过程繁琐
在进程之间要传送大量数据时,应当利用 OS 提供的高级通信工具,该工具最主要的特点是:
- 高效地传送大量数据。用户可直接利用高级通信命令(原语)高效地传送大量的数据。//数据量大
- 使用方便。OS 隐藏了实现进程通信的具体细节,向用户提供了一组用于实现高级通信的命令(原语),用户可方便地直接利用它实现进程之间的通信。或者说,通信过程对用户是透明的。这样就大大减少了通信程序编制上的复杂性。//使用简单
1、进程通信的类型
随着 OS 的发展,用于进程之间实现通信的机制也在发展,并已由早期的低级进程通信机制发展为能传送大量数据的高级通信工具机制。目前,高级通信机制可归结为四大类:共享存储器系统、管道通信系统、消息传递系统以及客户机-服务器系统。
(1)共享存储器系统(Shared-Memory System)
在共享存储器系统中,相互通信的进程共享某些数据结构或共享存储区,进程之间能够通过这些空间进行通信。据此,又可把它们分成以下两种类型://共享存储
- 基于共享数据结构的通信方式。在这种通信方式中,要求诸进程共用某些数据结构,借以实现诸进程间的信息交换,如在生产者-消费者问题中的有界缓冲区。操作系统仅提供共享存储器,由程序员负责对公用数据结构的设置及对进程间同步的处理。这种通信方式仅适于传递相对少量的数据,通信效率低下,属于低级通信。//数据量少->使用共享存储器
- 基于共享存储区的通信方式。为了传输大量数据,在内存中划出了一块共享存储区域,诸进程可通过对该共享区的读或写交换信息,实现通信,数据的形式和位置甚至访问控制都是由进程负责,而不是 OS。这种通信方式属于高级通信。需要通信的进程在通信前,先向系统申请获得共享存储区中的一个分区,并将其附加到自己的地址空间中,便可对其中的数据进行正常读、写,读写完成或不再需要时,将其归还给共享存储区。//数据量大->使用内存
(2)管道(pipe)通信系统
所谓“管道”,是指用于连接一个读进程和一个写进程以实现它们之间通信的一个共享文件,又名 pipe 文件。
向管道(共享文件)提供输入的发送进程(即写进程)以字符流形式将大量的数据送入管道;而接受管道输出的接收进程(即读进程)则从管道中接收(读)数据。由于发送进程和接收进程是利用管道进行通信的,故又称为管道通信。//管道通信原理
这种方式首创于 UNIX 系统,由于它能有效地传送大量数据,因而又被引入到许多其它操作系统中。为了协调双方的通信,管道机制必须提供以下三方面的协调能力:
- 互斥:即当一个进程正在对 pipe 执行读/写操作时,其它(另一)进程必须等待。
- 同步:指当写(输入)进程把一定数量(如4KB)的数据写入 pipe,便去睡眠等待,直到读(输出)进程取走数据后再把它唤醒。当读进程读到空的 pipe 时,也应睡眠等待,直至写进程将数据写入管道后才将之唤醒。
- 确定对方是否存在:只有确定了对方已存在时才能进行通信。
(3)消息传递系统(Message passing system)
在该机制中,进程不必借助任何共享存储区或数据结构,而是以格式化的消息(message)为单位,将通信的数据封装在消息中,并利用操作系统提供的一组通信命令(原语),在进程间进行消息传递,完成进程间的数据交换。// 使用通信原语
该方式隐藏了通信实现细节,使通信过程对用户透明化,降低了通信程序设计的复杂性和错误率,成为当前应用最为广泛的一类进程间通信的机制。例如:在计算机网络中,消息(message)又称为报文;在微内核操作系统中,微内核与服务器之间的通信无一例外都是采用了消息传递机制;由于该机制能很好地支持多处理机系统、分布式系统和计算机网络,因此也成为这些领域最主要的通信工具。
基于消息传递系统的通信方式属于高级通信方式,因其实现方式的不同,可进一步分成两类:
- 直接通信方式:是指发送进程利用 OS 所提供的发送原语,直接把消息发送给目标进程。
- 间接通信方式:是指发送和接收进程,都通过共享中间实体(称为邮箱)的方式进行消息的发送和接收,完成进程间的通信。
(4)客户机-服务器系统(Client-Server system)
前面所述的共享内存、消息传递等技术,虽然也可以用于实现不同计算机间进程的双向通信,但客户机-服务器系统的通信机制,在网络环境的各种应用领域已成为当前主流的通信实现机制,其主要的实现方法分为三类:套接字、远程过程调用和远程方法调用。//主流通信机制
4.1 - 套接字(Socket)
套接字起源于 20 世纪 70 年代加州大学克利分校版本的 UNIX,是 UNIX 操作系统下的网络通信接口。一开始,套接字被设计用在同一台主机上多个应用程序之间的通信(即进程间的通信),主要是为了解决多对进程同时通信时端口和物理线路的多路复用问题。//区分端口,多路复用
一个套接字就是一个通信标识类型的数据结构,包含了通信目的的地址、通信使用的端口号、通信网络的传输层协议、进程所在的网络地址,以及针对客户或服务器程序提供的不同系统调用(或 API 函数)等,是进程通信和网络通信的基本构件。//地址+端口+协议
套接字是为客户/服务器模型而设计的,通常,套接字包括两类:
基于文件型:通信进程都运行在同一台机器的环境中,套接字是基于本地文件系统支持的,一个套接字关联到一个特殊的文件,通信双方通过对这个特殊文件的读写实现通信,其原理类似于前面所讲的管道。// 管道
基于网络型:该类型通常采用的是非对称方式通信,即发送者需要提供接收者命名。通信双方的进程运行在不同主机的网络环境下,被分配了一对套接字,一个属于接收进程(或服务器端),一个属于发送进程(或客户端)。
一般地,发送进程发出连接请求时,随机申请一个套接字,主机为之分配一个端口,与该套接字绑定,不再分配给其它进程。接收进程拥有全局公认的套接字和指定的端口(如 FTP 服务器监听的端口为 21,Web 服务器监听端口为 80),并通过监听端口等待客户请求。因此,任何进程都可以向它发出连接请求和信息请求,以方便进程之间通信连接的建立。接收进程一旦收到请求,就接受来自发送进程的连接,完成连接,即在主机间传输的数据可以准确地发送到通信进程,实现进程间的通信;当通信结束时,系统通过关闭接收进程的套接字撤销连接。//套接字工作原理
套接字的优势在于,它不仅适用于同一台计算机内部的进程通信,也适用于网络环境中不同计算机间的进程通信。由于每个套接字拥有唯一的套接字号(也称套接字标识符),这样系统中所有的连接都持有唯一的一对套接字及端口连接,对于来自不同应用程序进程或网络连接的通信,能够方便地加以区分,确保了通信双方之间逻辑链路的唯一性,便于实现数据传输的并发服务,而且隐藏了通信设施及实现细节,采用统一的接口进行处理。//使用套接字的优点
4.2 - 远程过程调用和远程方法调用
远程过程调用 RPC(Remote Procedure Call),是一个通信协议,用于通过网络连接的系统。该协议允许运行于一台主机(本地)系统上的进程调用另一台主机(远程)系统上的进程,而对程序员表现为常规的过程调用,无需额外地为此编程。如果涉及的软件采用面向对象编程,那么远程过程调用亦可称做远程方法调用。//远程过程和远程方法调用是一回事
负责处理远程过程调用的进程有两个,一个是本地客户进程,另一个是远程服务器进程,这两个进程通常也被称为网络守护进程,主要负责在网络间的消息传递,一般情况下.这两个进程都是处于阻塞状态,等待消息。
为了使远程过程调用看上去与本地过程调用一样,即希望实现 RPC 的透明性,使得调用者感觉不到此次调用的过程是在其他主机上执行的,RPC 引入一个存根(stub)的概念:在本地客户端每个能够独立运行的远程过程都拥有一个客户存根(client stubborn),本地进程调用远程过程实际是调用该过程关联的存根;与此类似,在每个远程进程所在的服务器端,其所对应的实际可执行进程也存在一个服务器存根(stub)与其关联。本地客户存根与对应的远程服务器存根一般也是处于阻塞状态,等待消息。//远程过程调用原理
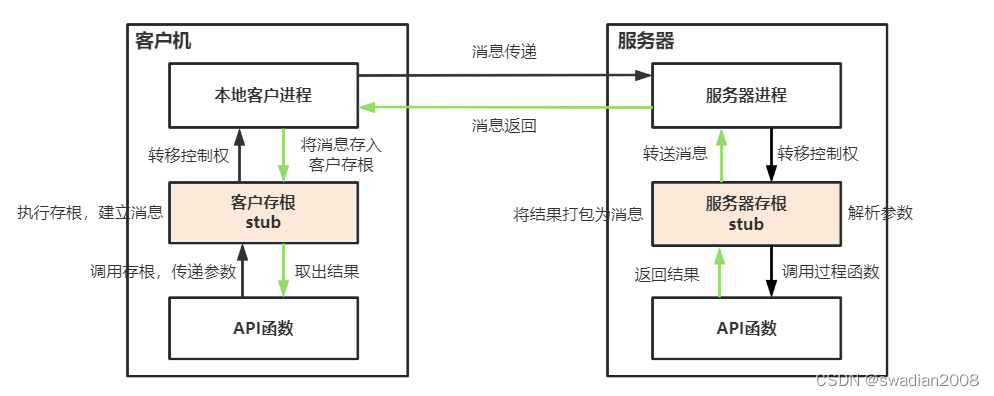
如上图所示,远程过程调用的主要步骤是://目前微服务的通信基础
- 本地过程调用者以一般方式调用远程过程在本地关联的客户存根,传递相应的参数,然后将控制权转移给客户存根。
- 客户存根执行,完成包括过程名和调用参数等信息的消息建立,将控制权转移给本地客户进程。
- 本地客户进程完成与服务器的消息传递,将消息发送到远程服务器进程。
- 远程服务器进程接收消息后转入执行,并根据其中的远程过程名找到对应的服务器存根,将消息转给该存根。
- 该服务器存根接到消息后,由阻塞状态转入执行状态,拆开消息从中取出过程调用的参数,然后以一般方式调用服务器上关联的过程
- 在服务器端的远程过程运行完毕后,将结果返回给与之关联的服务器存根
- 该服务器存根获得控制权运行,将结果打包为消息,并将控制权转移给远程服务器进程
- 远程服务器进程将消息发送回客户端
- 本地客户进程接收到消息后,根据其中的过程名将消息存入关联的客户存根,再将控制权转移给客户存根
- 客户存根从消息中取出结果,返回给本地调用者进程,并完成控制权的转移
这样,本地调用者再次获得控制权,并且得到了所需的数据,得以继续运行。显然,上述步骤的主要作用在于:将客户过程的本地调用转化为客户存根,再转化为服务器过程的本地调用,对客户与服务器来说,它们的中间步骤是不可见的,因此,调用者在整个过程中并不知道该过程的执行是在远程,而不是在本地。
2、消息传递通信的实现方式
在进程之间通信时,源进程可以直接或间接地将消息传送给目标进程,因此可将进程通信分为直接和间接两种通信方式。常见的直接消息传递系统和信箱通信就是分别采用这两种通信方式。
(1)直接消息传递系统
在直接消息传递系统中采用直接通信方式,即发送进程利用 OS 所提供的发送命(原语),直接把消息发送给目标进程。
1.1 - 直接通信原语
对称寻址方式:该方式要求发送进程和接收进程都必须以显式方式提供对方的标识符。通常,系统提供下述两条通信命令(原语):
send(receiver,message); 发送一个消息给接收进程
receive(sender,message); 接收Sender发来的消息例如,原语 Send(P2,m1) 表示将消息 m1 发送给接收进程 P2;而原语 Receive(P1,m1) 则表示接收由 P1 发来的消息 m1。
对称寻址方式的不足在于,一旦改变进程的名称,则可能需要检查所有其它进程的定义,有关对该进程旧名称的所有引用都必须查找到,以便将其修改为新名称,显然,这样的方式不利于实现进程定义的模块化。//进程变更比较麻烦
非对称寻址方式:在某些情况下,接收进程可能需要与多个发送进程通信,无法事先指定发送进程。例如,用于提供打印服务的进程,它可以接收来自任何一个进程的 “打印请求” 消息。对于这样的应用,在接收进程的原语中,不再需要命名发送进程,只需填写表示源进程的参数,即完成通信后的返回值,而发送进程仍需要命名接收进程。
该方式的发送和接收原语可表示为://接收不再需要预先知道发送方的进程名
send(P,message); 发送一个消息给进程 P
receive(id,message); 接收来自任何进程的消息,id变量可设置为进行通信的发送方进程id或名字。1.2 - 消息的格式
在消息传递系统中所传递的消息,必须具有一定的消息格式。
在单机系统环境中,由于发送进程和接收进程处于同一台机器中,有着相同的环境,所以消息的格式比较简单,可采用比较短的定长消息格式,以减少对消息的处理和存储开销。该方式可用于办公自动化系统中,为用户提供快速的便笺式通信。
但定长消息方式对于需要发送较长消息的用户是不方便的。为此,可采用变长的消息格式,即进程所发送消息的长度是可变的。对于变长消息,系统无论在处理方面还是存储方面,都可能会付出更多的开销,但其优点在于方便了用户的使用。
1.3 - 进程的同步方式
在进程之间进行通信时,同样需要有进程同步机制,以使诸进程间能协调通信。不论是发送进程还是接收进程,在完成消息的发送或接收后,都存在两种可能性,即进程或者继续发送(或接收)或者阻塞。//执行或阻塞
由此,我们可得到三种情况:
- 发送进程阻塞,接收进程阻塞。这种情况主要用于进程之间紧密同步,发送进程和接收进程之间无缓冲时。
- 发送进程不阻塞、接收进程阻塞。这是一种应用最广的进程同步方式。平时,发送进程不阻塞,因而它可以尽快地把一个或多个消息发送给多个目标;而接收进程平时则处于阻塞状态,直到发送进程发来消息时才被唤醒。
- 发送进程和接收进程均不阻塞。这也是一种较常见的进程同步形式。平时,发送进程和接收进程都在忙于自己的事情,仅当发生某事件使它无法继续运行时,才把自己阻塞起来等待。
1.4 - 通信链路
为使在发送进程和接收进程之间能进行通信,必须在两者之间建立一条通信链路。有两种方式建立通信链路。
- 第一种方式是:由发送进程在通信之前用显式的 “建立连接” 命令(原语)请求系统为之建立一条通信链路,在链路使用完后拆除链路。这种方式主要用于计算机网络中。//网络
- 第二种方式是:发送进程无须明确提出建立链路的请求,只须利用系统提供的发送命令(原语),系统会自动地为之建立一条链路。这种方式主要用于单机系统中。//单机
而根据通信方式的不同,则又可把链路分成两种:
- 单向通信链路,只允许发送进程向接收进程发送消息,或者相反
- 双向通信链路,既允许由进程 A 向进程 B 发送消息,也允许进程 B 同时向进程 A 发送消息。
(2)信箱通信
信箱通信属于间接通信方式,即进程之间的通信,需要通过某种中间实体(如共享数据结构等)来完成。该实体建立在随机存储器的公用缓冲区上,用来暂存发送进程发送给目标进程的消息;接收进程可以从该实体中取出发送进程发送给自己的消息,通常把这种中间实体称为邮箱(或信箱),每个邮箱都有一个唯一的标识符。消息在邮箱中可以安全地保存,只允许核准的目标用户随时读取。因此,利用邮箱通信方式既可实现实时通信,又可实现非实时通信。// 消息队列
2.1 - 信箱的结构
信箱定义为一种数据结构。在逻辑上,可以将其分为两个部分:
- 信箱头:用以存放有关信箱的描述信息,如信箱标识符、信箱的拥有者、信箱口令、信箱的空格数等。
- 信箱体:由若干个可以存放消息(或消息头)的信箱格组成,信箱格的数目以及每格的大小是在创建信箱时确定的。
在消息传递方式上,最简单的情况是单向传递。消息的传递也可以是双向的。下图给出了双向通信链路的通信方式。
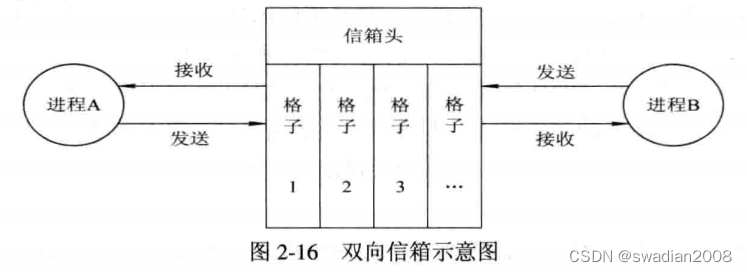
2.2 - 信箱通信原语
系统为邮箱通信提供了若干条原语,分别用于:
- 邮箱的创建和撤消。进程可利用邮箱创建原语来建立一个新邮箱,创建者进程应给出邮箱名字、邮箱属性(公用、私用或共享);对于共享邮箱,还应给出共享者的名字。当进程不再需要读邮箱时,可用邮箱撤消原语将之撤消。
- 消息的发送和接收。当进程之间要利用邮箱进行通信时,必须使用共享邮箱,并利用系统提供的下述通信原语进行通信。
Send(mailbox,message);将一个消息发送到指定邮箱
Receive(mailbox,message);从指定邮箱中接收一个消息3.3 - 信箱的类型
邮箱可由操作系统创建,也可由用户进程创建,创建者是邮箱的拥有者。据此,可把邮箱分为以下三类:
- 私用邮箱。用户进程可为自己建立一个新邮箱,并作为该进程的一部分。邮箱的拥有者有权从邮箱中读取消息,其他用户则只能将自己构成的消息发送到该邮箱中。这种私用邮箱可采用单向通信链路的邮箱来实现。当拥有该邮箱的进程结束时,邮箱也随之消失。//用户创建
- 公用邮箱。由操作系统创建,并提供给系统中的所有核准进程使用。核准进程既可把消息发送到该邮箱中,也可从邮箱中读取发送给自己的消息。显然,公用邮箱应采用双向通信链路的邮箱来实现。通常,公用邮箱在系统运行期间始终存在。//操作系统创建
- 共享邮箱。由某进程创建,在创建时或创建后指明它是可共享的,同时须指出共享进程的名字。邮箱的拥有者和共享者都有权从邮箱中取走发送给自己的消息。//用户创建
在利用邮箱通信时,在发送进程和接收进程之间,存在以下四种关系:
- 一对一关系。发送进程和接收进程可以建立一条两者专用的通信链路,使两者之间的交互不受其他进程的干扰。
- 多对一关系。允许提供服务的进程与多个用户进程之间进行交互,也称为客户/服务器交互(client/server interaction)。
- 一对多关系。允许一个发送进程与多个接收进程进行交互,使发送进程可用广播方式向接收者(多个)发送消息。
- 多对多关系。允许建立一个公用邮箱,让多个进程都能向邮箱中投递消息;也可从邮箱中取走属于自己的消息。
3、直接消息传递系统实例
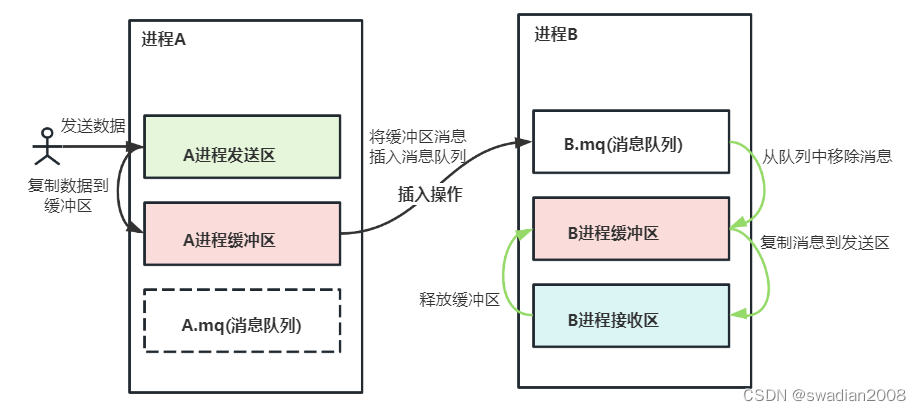
消息缓冲队列通信机制首先由美国的 Hansan 提出,并在 RC 4000 系统上实现,后来被广泛应用于本地进程之间的通信中。在这种通信机制中,发送进程利用 Send 原语将消息直接发送给接收进程;接收进程则利用 Receive 原语接收消息。消息缓冲队列图示:
(1)消息缓冲队列通信机制中的数据结构
消息缓冲区。在消息缓冲队列通信方式中,主要利用的数据结构是消息缓冲区。它可描述如下:
type struct message_buffer {
int sender; //发送者进程标识符
int size; //消息长度
char text; //消息正文
struct message buffer next; //指向下一个消息缓冲区的指针
}PCB 中有关通信的数据项。在操作系统中采用了消息缓冲队列通信机制时,除了需要为进程设置消息缓冲队列外,还应在进程的 PCB 中增加消息队的列队首指针,用于对消息队列进行操作,以及用于实现同步的互斥信号量 mutex 和资源信号量 sm。
在 PCB 中应增加的数据项可描述如下:
type struct processcontrol_block {
...
struct message_buffer mq; //消息队列队首指针
semaphore mutex; //消息队列互斥信号量
semaphore sm; //消息队列资源信号量
...
} PCB;(2)发送原语
发送进程在利用发送原语发送消息之前,应先在自己的内存空间中设置一个发送区 a,如下图 所示,把待发送的消息正文、发送进程标识符、消息长度等信息填入其中,然后调用发送原语,把消息发送给目标进程。// 设置发送区
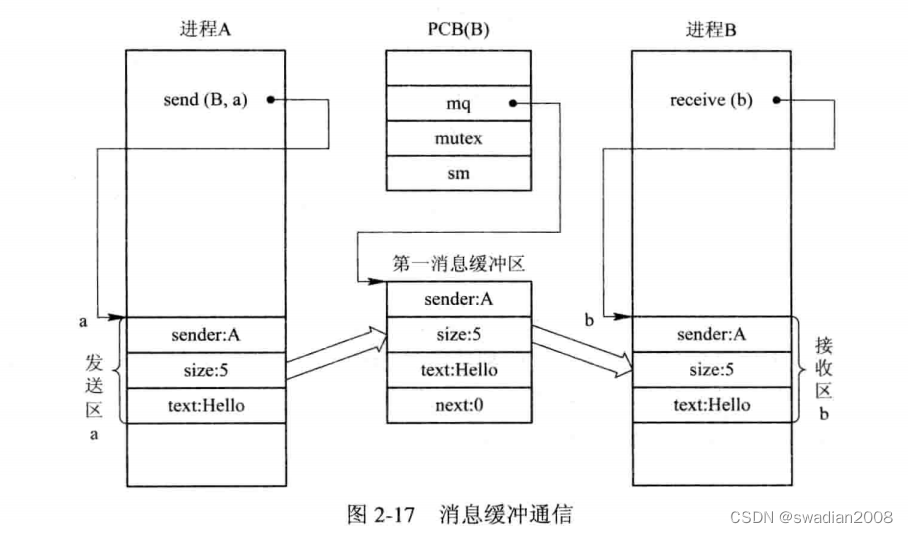
发送原语首先根据发送区 a 中所设置的消息长度 a.size 来申请一缓冲区 i,接着,把发送区 a 中的信息复制到缓冲区 i 中。为了能将 i 挂在接收进程的消息队列 mq 上,应先获得接收进程的内部标识符 j,然后将 i 挂在 j.mq 上,由于该队列属于临界资源,故在执行 insert 操作的前后都要执行 wait 和 signal 操作。// 申请缓冲区,然后还需要获取接收进程的标识符
发送原语可描述如下:
void send(receiver,a) { //1-发送区:receiver为接收进程标识符,a为发送区首址;
getbuf(a.size,i); //2-缓冲区:根据a.size申请缓冲区;
copy(i.sender,a.sender); //3-缓冲区复制操作:将发送区a中的信息复制到消息缓冲区i中;
i.size=a.size;
copy(i.text,a.text);
i.next=0;
getid(PCBset,receiver.j); //4-获取接收者标识:获得接收进程内部的标识符;
wait(j.mutex);
insert(&j.mq,i); //5-消息插入:将消息缓冲区插入接受进程的消息队列;
signal(j.mutex);
signal(j.sm); //6-唤醒数据消费:资源信号量+1
}(3)接收原语
接收进程调用接收原语 receive(b),从自己的消息缓冲队列 mq 中摘下第一个消息缓冲区 i,并将其中的数据复制到以 b 为首址的指定消息接收区内。接收原语描述如下:
void receive(b) {
j = internal name; //j为接收进程内部的标识符;
wait(j.sm); //如果资源为空,此时将阻塞
wait(j.mutex); //使用同步原语操作j.mq
remove(j.mq, i); //将消息队列中第一个消息移出;
signal(j.mutex);
copy(b.sender, i.sender); //缓冲区->接收区,将消息缓冲区i中的信息复制到接收区b:
b.size =i.size;
copy(b.text, i.text);
releasebuf(i); //释放消息缓冲区;
}
至此,全文结束。因为热爱,请把技术进行到底。