深度学习论文分享(九)Unifying Motion Deblurring and Frame Interpolation with Events
深度学习论文分享(九)Unifying Motion Deblurring and Frame Interpolation with Events
前言
论文原文:https://openaccess.thecvf.com/content/CVPR2022/papers/Zhang_Unifying_Motion_Deblurring_and_Frame_Interpolation_With_Events_CVPR_2022_paper.pdf
论文代码:https://github.com/XiangZ-0/EVDI
Title:Unifying Motion Deblurring and Frame Interpolation with Events
Authors:Xiang Zhang, Lei Y u†
Wuhan University, Wuhan, China.
在此仅做翻译
Abstract
基于帧的相机快门速度慢,曝光时间长,往往会造成视觉模糊和帧间信息丢失,从而降低拍摄视频的整体质量。为此,我们提出了一个基于事件的运动去模糊和帧插值的统一框架,用于模糊视频增强,其中利用极低的事件延迟来缓解运动模糊并促进中间帧预测。首先利用可学习的二重积分网络预测模糊帧与锐隐图像之间的映射关系,然后利用连续模糊输入和并发事件的信息,提出融合网络对粗糙结果进行细化。通过探索模糊帧、潜在图像和事件流之间的相互约束,我们进一步提出了一种自监督学习框架,使网络训练能够使用真实世界的模糊视频和事件。大量的实验表明,我们的方法优于最先进的方法,并在合成和现实世界的数据集上取得了显着的性能。代码可在https://github.com/XiangZ-0/EVDI上获得。
1. Introduction
高动态场景,如快速运动的目标或非线性运动,对高质量的视频生成提出了挑战,因为捕获的帧经常被模糊,目标信息在连续帧之间丢失[29]。现有的基于帧的方法试图通过发展运动去模糊[11]、帧插值[1]或模糊视频增强技术[10,25]来解决这些问题。然而,由于运动模糊性和强度纹理的擦除,基于帧的去模糊方法很难从严重模糊的视频中预测尖锐的潜在帧[11]。此外,目前基于帧的插值方法通常假设相邻帧之间的运动是线性的[1],这在现实场景中并不总是有效的,特别是在遇到非线性运动时,因此经常导致不正确的预测。
最近的研究揭示了事件相机[5]在运动去模糊和帧插值方面的优势。一方面,事件相机的输出固有地嵌入了精确的运动和锐利的边缘[2],因为它报告的异步事件数据具有极低的延迟(在µs量级)[5,13],这有效地缓解了运动模糊[14,21,22,31,34]。另一方面,事件相机可以记录几乎连续的亮度变化,以补偿连续帧之间缺失的信息,使得即使在非线性运动下也可以准确地恢复中间帧[14,30]。然而,现有的工作一般将运动去模糊和帧内插作为独立的任务,而运动模糊和帧间信息缺失问题在真实场景中具有很强的共现性,需要同时考虑。在实际场景中,上述方法面临以下两个主要挑战。
•独立任务的局限性:插值方法的性能[30]通常高度依赖于参考帧的质量,当参考帧被运动模糊降低时,很难插值出清晰的结果。对于去模糊任务,大多数方法[31,34]侧重于恢复模糊输入曝光时间内的清晰图像,而忽略了模糊帧之间的潜在图像(见图1)。
•数据不一致:大多数先前的工作使用标记良好的合成数据集进行监督学习[30,31]或半监督学习[34],这通常会导致真实场景中的性能下降,因为合成数据和真实世界数据之间的不一致[34]。
本文提出了一种统一的基于事件的视频去模糊和插值(EVDI)框架,用于模糊视频增强。该方法由两个主要模块组成:可学习的二重积分网络(LDI)和融合网络。LDI网络旨在从对应的事件中自动预测模糊帧与锐利潜像之间的映射关系,其中潜像的时间戳可以在模糊帧的曝光时间内(去模糊任务)或连续模糊帧之间(插值任务)任意选择。融合网络对潜在图像进行粗重建,并利用连续模糊帧和事件流的所有信息生成精细结果。在训练方面,我们利用模糊帧、锐隐图像和事件流之间的相互约束,提出了一个完全自监督的学习框架,帮助网络在不需要真实图像的情况下拟合真实世界数据的分布。
本文的主要贡献有三个方面:
•我们提出了一个基于事件的视频去模糊和插值的统一框架,该框架可以从模糊输入生成任意高帧率的清晰视频。
•我们提出了一个完全自监督的框架,使网络训练能够在没有任何标记数据的现实场景中进行。
•在合成和现实世界数据集上的实验表明,我们的方法在保持高效网络设计的同时实现了最先进的结果。
2. Related Work
2.1. Frame Interpolation
现有的基于帧的插值方法大致可以分为两类:基于翘曲(warping-based)的插值方法和基于核的插值方法。基于翘曲的方法[1,9,18,35]通常将光流[8,28]与图像翘曲相结合来预测中间帧,并且已经提出了几种技术来提高插值性能,例如前向翘曲[18],空间变压器网络[35]和深度信息[1]。然而,这些方法通常假设两个参考系之间的线性运动和亮度恒定,因此无法处理任意运动。基于核的方法[19,20]不是用光流扭曲参考帧,而是将帧插值建模为参考帧上的局部卷积,其中核直接从输入帧中估计。尽管基于核的方法对复杂的运动和亮度变化具有更强的鲁棒性,但其可扩展性往往受到卷积核大小的限制。
基于帧的插值的常见挑战是参考帧之间的信息缺失,这可以通过利用极低的事件延迟来缓解。最近的方法[30]利用了帧和事件的优点,即使在非线性运动下也能取得很好的插值效果,但其性能也与参考帧的质量密切相关,不能直接用于模糊视频增强。
2.2. Motion Deblurring
最流行的基于帧的去模糊方法之一是使用神经网络来学习模糊特征,并从模糊输入中预测清晰图像[7,11,17,37]。已经开发了几种技术来利用模糊帧内的时间信息,包括动态时间混合机制[7]、时空滤波器自适应网络[37]和帧内迭代[17]。最近的研究也揭示了动态事件去模糊化的潜力。事件流固有地嵌入运动信息和尖锐的边缘,这可以用来解决由运动模糊引起的时间模糊和纹理擦除。先锋的基于事件的方法根据物理事件生成模型将模糊帧、锐利潜像和相应的事件关联起来,实现运动去模糊[21,22],但由于物理电路的不完善,例如相机固有噪声,其性能往往会下降。为了缓解这一问题,已经提出了基于学习的方法[31,34]来拟合事件数据的分布,从而获得更好的去模糊性能。
然而,大多数去模糊方法只关注模糊帧曝光时间内的清晰潜像恢复,而模糊帧之间的信息在实际应用中也很重要,促使去模糊和插值相结合。
2.3. Joint Deblurring and Interpolation
以前基于帧的方法已经接近了联合去模糊和插值任务[10,25]。[10]的工作基于去模糊模块预处理的关键帧进行帧插值,[25]的工作将去模糊和插值作为一个统一的任务,实现了更好的增强性能。对于基于事件的方法,LEDVDI是最接近的相关工作[14],但LEDVDI被归类为级联方案,因为它在不同的阶段实现去模糊和插值。此外,上述所有方法都需要在合成数据集上进行监督训练,由于数据不一致,限制了它们在现实场景中的性能。
该方法利用帧和事件的信息,在不区分去模糊和插值任务的情况下实现了模糊视频增强。此外,提出了一种自监督学习框架,实现了真实事件和模糊视频的网络训练,保证了网络在真实场景下的性能。
3. Problem Statement
视频高动态场景经常会出现模糊伪影,模糊视频增强(BVE)对视觉感知起着重要作用。由于运动模糊和帧间信息的丢失,现有的基于帧的方法往往难以实现BVE,而借助事件可以有效地缓解这一问题。给定在曝光时间
T
i
,
T
i
+
1
\mathcal{T}_i, \mathcal{T}_{i+1}
Ti,Ti+1内捕获的两个连续模糊帧
B
i
,
B
i
+
1
B_i, B_{i+1}
Bi,Bi+1,以及在
T
i
+
1
i
\mathcal{T}^i_{i+1}
Ti+1i内触发的相应事件流
E
i
+
1
i
\mathcal{E}^i_{i +1}
Ei+1i,其中
T
i
+
1
i
≜
T
i
∪
T
i
→
i
+
1
∪
T
i
+
1
\mathcal{T}^i_{i+1} \triangleq T_i \cup T_{i \rightarrow i+1} \cup \mathcal{T}_{i+1}
Ti+1i≜Ti∪Ti→i+1∪Ti+1,其中
T
i
→
i
+
1
\mathcal{T}_{i→i+1}
Ti→i+1表示
B
i
B_i
Bi和
B
i
+
1
B_{i+1}
Bi+1之间的时间间隔,EVDI的任务是直接从模糊输入实现BVE,即
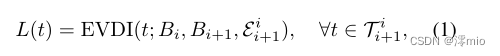
式中
L
(
t
)
L(t)
L(t)表示任意时间
t
∈
T
i
+
1
i
t∈\mathcal{T}^i_{i+1}
t∈Ti+1i的潜像。由式(1)可知,当
t
∈
T
i
t∈\mathcal{T}_i
t∈Ti或
T
i
+
1
\mathcal{T}_{i+1}
Ti+1时,EVDI退化为运动去模糊(Motion debluring, MD),当
t
∈
T
i
→
i
+
1
t∈\mathcal{T}_{i→i+1}
t∈Ti→i+1时,EVDI退化为帧插值(Frame Interpolation, FI)。因此,EVDI比MD和FI更具通用性,为BVE的任务提供了统一的表述。
EVDI vs. Frame Interpolation.
传统的FI任务旨在从尖锐参考帧
I
i
,
I
i
+
1
I_i, I_{i+1}
Ii,Ii+1中恢复中间潜图像{
L
(
t
)
L(t)
L(t)}
t
∈
T
i
→
i
+
1
_{t∈\mathcal{T}_{i→i+1}}
t∈Ti→i+1。提供在
T
i
→
i
+
1
\mathcal{T}_{i→i+1}
Ti→i+1中发出的并发事件流
E
i
→
i
+
1
\mathcal{E}_{i→i+1}
Ei→i+1,我们有
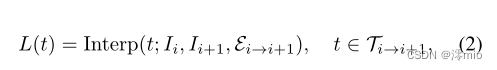
其中Interp(·)表示FI算子。大多数FI方法[1,9,30]旨在从高质量(清晰)参考帧
I
i
,
I
i
+
1
I_i, I_{i+1}
Ii,Ii+1中恢复帧间潜在图像,而EVDI直接接受模糊输入,这比传统FI更具挑战性。
EVDI vs. Motion Deblurring.
MD的目的是从对应的模糊帧
B
i
B_i
Bi中重构出清晰的潜在图像{
L
(
t
)
L(t)
L(t)}
t
∈
T
i
_{t∈T_i}
t∈Ti。提供
E
i
\mathcal{E}_i
Ei在
T
i
\mathcal{T}_i
Ti中触发的并发事件流,我们有
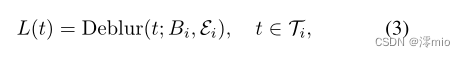
其中Deblur(·)表示MD操作符。现有的去模糊方法[4,27]主要集中在恢复曝光时间
T
i
\mathcal{T}_i
Ti内的潜帧,而EVDI既可以预测曝光时间
T
i
\mathcal{T}_i
Ti(或
T
i
+
1
\mathcal{T}_{i+1}
Ti+1)内的潜帧,也可以预测模糊帧
T
i
→
i
+
1
\mathcal{T}_{i→i+1}
Ti→i+1之间的潜帧,如图1所示。
理想情况下,EVDI可以通过统一公式(1)中的MD和FI来接近BVE任务。然而,要在现实场景中有效实现EVDI,仍然存在挑战。
•MD和FI应该在一个统一的框架内同时解决,以实现EVDI。先前对BVE的尝试[10,14]采用级联方案,在去模糊后执行帧插值,但这种方法经常将去模糊误差传播到插值阶段,导致次优结果。
•现有的相关方法一般是在监督学习框架内开发的[10,14,25],其中监督通常由合成的模糊图像和事件提供。因此,在真实场景中,由于合成数据和真实数据之间的不同分布,性能可能会下降。
4. Method
在这项工作中,我们提出用可训练的神经网络来近似最优EVDI模型,并利用模糊帧、锐隐帧和事件流之间的相互约束来开发一个自监督学习框架。
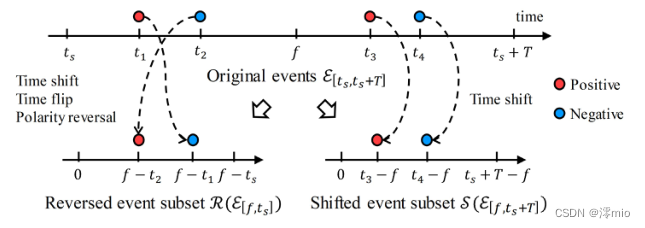
图2。预处理操作的示例。左侧事件子集经历时移、翻转和极性反转,即
R
(
⋅
)
R(·)
R(⋅),因为
t
s
−
f
<
0
t_s−f < 0
ts−f<0;右侧事件子集经过时移算子处理,即
S
(
⋅
)
S(·)
S(⋅),因为
t
s
+
T
−
f
≥
0
t_s + T− f ≥ 0
ts+T−f≥0
4.1. Unified Deblurring and Interpolation
我们首先回顾了事件的物理生成模型,当对数尺度亮度变化超过事件阈值
c
>
0
c > 0
c>0时触发事件,即:
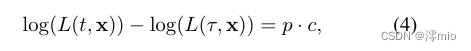
式中,
L
(
t
,
x
)
L(t, x)
L(t,x)和
L
(
τ
,
x
)
L(τ, x)
L(τ,x)分别表示时刻t和
τ
\tau
τ在像素位置x处的瞬时强度,极性
p
∈
p∈
p∈{+1,−1}表示亮度变化方向。借助事件,我们可以建立如下关系(为便于阅读,省略像素位置):
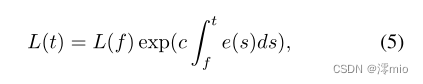
式中,
L
(
t
)
L(t)
L(t)和
L
(
f
)
L(f)
L(f)分别为瞬间
t
t
t和
f
f
f的隐像,
e
(
t
)
≜
p
⋅
δ
(
t
−
τ
)
e(t)\triangleq p·δ(t−τ)
e(t)≜p⋅δ(t−τ)为事件的连续表示,δ(·)为狄拉克函数。另一方面,模糊图像可表示为曝光时间内潜像的平均值[3],即:
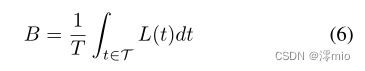
式中,
T
T
T表示曝光周期
T
\mathcal{T}
T的持续时间。结合式(5)和式(6),可以得到
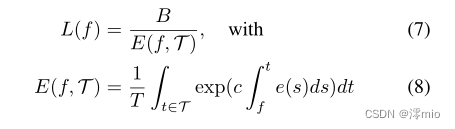
从事件角度表示模糊帧
B
B
B与潜像
L
(
f
)
L(f)
L(f)之间的关系,也称为基于事件的二重积分(event-based double integral, EDI)[22]。
4.1.1 Feasibility Analysis
先前[21,22]的工作重点是利用Eq.(7)还原曝光周期 T \mathcal{T} T内的锐隐图像,同时该公式也可以扩展到 T \mathcal{T} T外任意时间的隐帧恢复(请参见补充资料)。然而,直接应用Eq.(7)进行统一去模糊和插值往往会遇到以下障碍:首先, E ( f , T ) E(f, \mathcal{T}) E(f,T)的计算需要知道事件阈值 c c c,这对恢复性能至关重要[22],但由于其时间不稳定,难以准确估计。其次,由于物理传感器的非理想性[5],例如,有限的读出带宽,现实世界的事件是有噪声的,因此经常导致结果下降,特别是当遇到 E ( f , T ) E(f, \mathcal{T}) E(f,T)被噪声严重污染的事件的长期积分时。因此,我们建议采用基于学习的方法来拟合现实世界事件的统计数据。
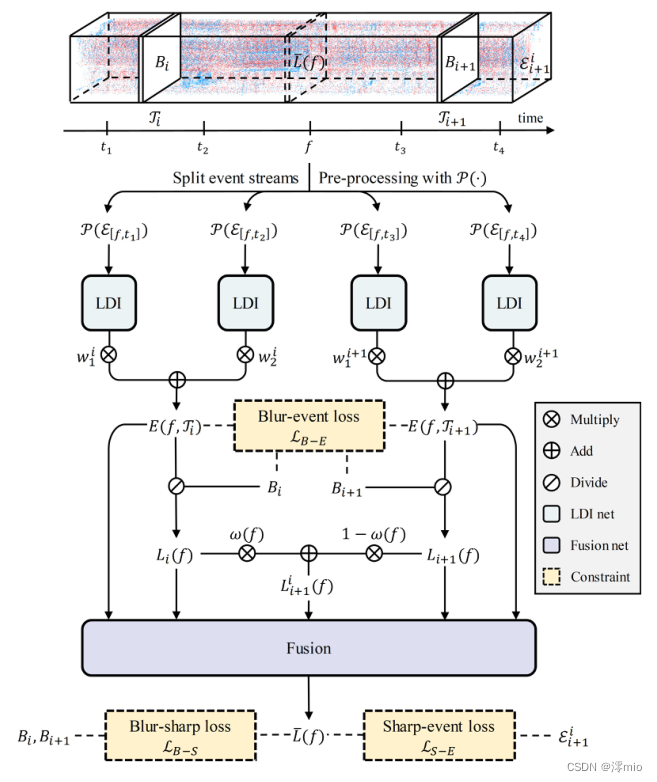
图3。所提出方法的数据流。我们利用两个连续的模糊帧Bi, Bi+1和并发事件E ii+1,首先根据目标时间戳f将事件分成4个子集,然后将经过P(·)预处理的事件馈送到4个权重共享LDI网络。然后,基于Bi、Bi+1及其对应的事件E(f, Ti)、E(f, Ti+1)的二重积分,生成Li(f)、Li+1(f)、Lii+1(f)三个粗结果,并通过融合网络对其进行细化,得到最终结果¯L(f)。
4.1.2 Network Architecture
我们的网络接收一个隐图像时间戳
f
∈
T
i
+
1
i
f∈\mathcal{T}^i_{i+1}
f∈Ti+1i,两个连续的模糊帧
B
i
,
B
i
+
1
B_i, B_{i+1}
Bi,Bi+1和对应的事件流
E
i
+
1
i
\mathcal{E}^i_{i+1}
Ei+1i作为输入,输出一个锐利的隐图像
L
(
f
)
L(f)
L(f)。我们的网络有两个主要模块:可学习的二重积分(LDI)网络和融合网络,其中LDI网络学习近似Eq.(8)的二重积分行为,融合网络用于细化模糊图像和LDI网络输出产生的结果,如图3所示。
LDI Network.
假设训练LDI网络近似于
E
(
0
,
T
[
0
,
T
]
)
≈
L
D
I
(
E
[
0
,
T
]
)
E(0, \mathcal{T}_{[0,T]})≈LDI(\mathcal{E}_{[0,T]})
E(0,T[0,T])≈LDI(E[0,T]),即
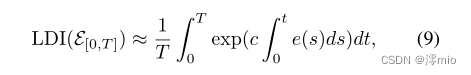
式中
T
[
0
,
T
]
\mathcal{T}_{[0,T]}
T[0,T]表示从
0
0
0到
T
>
0
T > 0
T>0的时间间隔,
E
[
0
,
T
]
\mathcal{E}_{[0,T]}
E[0,T]表示对应的事件流。现在我们考虑一个更一般的情况
E
(
f
,
T
)
E(f, \mathcal{T})
E(f,T)可以写成:
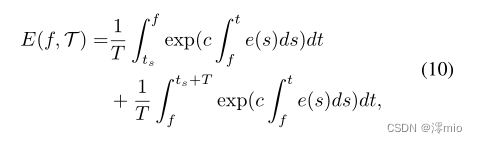
其中,
t
s
t_s
ts为
T
\mathcal{T}
T的起始时间。对式(10)应用
t
′
=
t
−
f
t' = t - f
t′=t−f和
s
′
=
s
−
f
s' = s - f
s′=s−f,我们得到
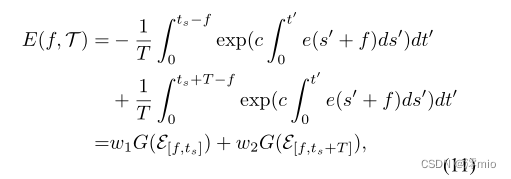
其中
ω
1
=
(
f
−
t
s
)
/
T
,
ω
2
=
(
t
s
+
T
−
f
)
/
T
\omega_1 = (f−t_s)/T, \omega_2 = (t_s + T−f)/T
ω1=(f−ts)/T,ω2=(ts+T−f)/T为权重,
G
(
⋅
)
G(·)
G(⋅)为一般公式,定义为
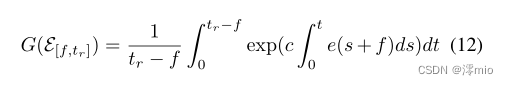
t
r
t_r
tr表示参考时间。根据上述定义,我们可以用LDI网络近似Eq.(12)即Eq.(9)来计算
E
(
f
,
T
)
E(f, \mathcal{T})
E(f,T),对于
t
r
−
f
≥
0
t_r−f≥0
tr−f≥0的情况,
G
(
⋅
)
G(·)
G(⋅)可以直接近似为
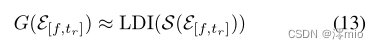
其中
S
(
E
[
f
,
t
r
]
)
≜
S(\mathcal{E}_{[f,t_r]})\triangleq
S(E[f,tr])≜{
e
(
t
+
f
)
,
t
∈
[
0
,
t
r
−
f
]
e(t + f), t∈[0,t_r−f]
e(t+f),t∈[0,tr−f]}表示时移事件算子。对于
t
r
−
f
<
0
t_r−f < 0
tr−f<0的情况,
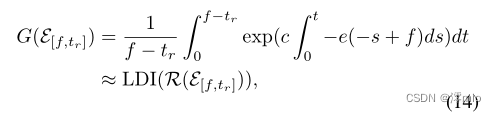
式中
R
(
E
[
f
,
t
r
]
)
≜
R(\mathcal{E}_{[f,t_r]})\triangleq
R(E[f,tr])≜{
−
e
(
−
t
+
f
)
,
t
∈
[
0
,
f
−
t
r
]
-e(-t + f), t∈[0,f-t_r]
−e(−t+f),t∈[0,f−tr]}表示由时移、翻转和极性反转组成的事件算子;如图2所示。为简单起见,我们定义一个统一的预处理运算符
P
(
⋅
)
P(·)
P(⋅)如下:
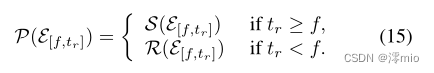
因此,Eq.(11)可以重新表述为
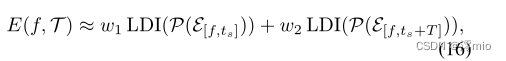
这意味着任意$E(f, \mathcal{T})可以通过LDI输出的加权组合来近似,其中LDI网络只需要训练一次就可以满足Eq.(9)的情况。
对于LDI网络的输入,我们引入了一种时空事件表示。使用一个预定义的数字,例如 N N N,我们从 t = 0 t = 0 t=0到 t = T i + 1 i t = T^i_{i +1} t=Ti+1i公平地划分 N N N个时间箱,其中 T i + 1 i T^i_{i +1} Ti+1i表示 T i + 1 i \mathcal{T}^i_{i +1} Ti+1i的总持续时间。然后,我们将 P ( ⋅ ) P(·) P(⋅)预处理后的事件累积在每个时间bin内,形成 2 N × H × W 2N × H × W 2N×H×W张量作为LDI输入,其中 2 、 H 、 W 2、H、W 2、H、W分别表示事件极性、图像高度和宽度。因此,我们的事件表示可以在保持固定输入格式的同时灵活选择目标时间戳 f f f,这使得网络可以在任意 f ∈ T i + 1 i f∈\mathcal{T}^i_{i +1} f∈Ti+1i处恢复潜在图像 L ( f ) L(f) L(f),而无需对网络进行任何修改或重新训练。
Fusion Network.
从LDI网络中得到
E
(
f
,
T
)
E(f, \mathcal{T})
E(f,T)后,可以用Eq.(7)粗还原潜像
L
(
f
)
L(f)
L(f)。我们将
B
i
、
B
i
+
1
B_i、B_{i+1}
Bi、Bi+1重构的潜像分别表示为
L
i
(
f
)
、
L
i
+
1
(
f
)
L_i(f)、L_{i+1}(f)
Li(f)、Li+1(f),并手动生成一个额外的结果
L
i
+
1
i
(
f
)
L^i_{i+1}(f)
Li+1i(f) 通过
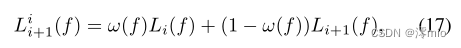
其中,
f
∈
[
0
,
T
i
+
1
i
]
f∈[0,T^i_{i+1}]
f∈[0,Ti+1i]的权重函数
ω
(
f
)
ω(f)
ω(f)定义为
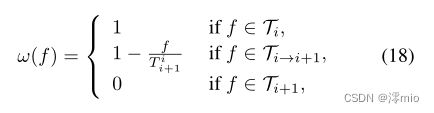
在我们的观测中,加权重构有助于帧插值。最后,我们的融合网络接收
L
i
(
f
)
,
L
i
+
1
(
f
)
,
L
i
+
1
i
(
f
)
,
E
(
f
,
T
i
)
,
E
(
f
,
T
i
+
1
)
L_i(f), L_{i+1}(f), L^i_{i+1}(f), E(f, \mathcal{T}_i), E(f, \mathcal{T}_{i+1})
Li(f),Li+1(f),Li+1i(f),E(f,Ti),E(f,Ti+1),并产生最终的潜在图像
L
~
(
f
)
\widetilde{L}(f)
L
(f),如图3所示。
4.2. Self-supervised Learning Framework
提出的自监督学习框架由三种不同的损失组成,这些损失是基于模糊帧、锐隐图像和事件流之间的相互约束而制定的。
Blurry-event Loss.
事件
E
(
f
,
T
)
E(f, \mathcal{T})
E(f,T)的二重积分对应于模糊帧与清晰潜像之间的映射关系。对于多个模糊输入,我们建议将不同模糊帧重建的潜在图像之间的一致性表述为
L
i
(
f
)
=
L
i
+
1
(
f
)
L_i(f) = L_{i+1}(f)
Li(f)=Li+1(f)。考虑到可能在
E
(
f
,
T
)
E(f, \mathcal{T})
E(f,T)中积累的量化误差,我们将一致性重写为
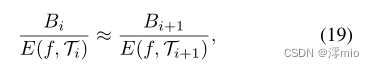
式中
E
(
f
,
T
i
)
E
(
f
,
T
i
+
1
)
E(f, \mathcal{T}_i)E(f, \mathcal{T}_{i+1})
E(f,Ti)E(f,Ti+1)由LDI网络生成。我们将Eq.(19)转换为对数域,并将其重写为模糊事件损失
L
B
−
E
\mathcal{L}_{B-E}
LB−E,
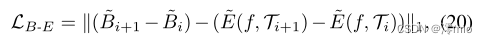
其中顶部波浪表示对数,例如,
B
‾
i
=
l
o
g
(
B
i
)
\overline{B}_i = log(B_i)
Bi=log(Bi)。在模糊事件约束下,LDI网络可以学习利用模糊帧之间的亮度差进行事件二重积分。
Blurry-sharp Loss.
假设重构的隐像
L
‾
(
t
)
\overline{L}(t)
L(t)
t
∈
T
i
t∈T_i
t∈Ti,则模糊过程Eq.(6)可以重新表述为离散版本,即
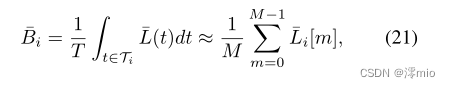
式中
L
‾
i
[
m
]
\overline{L}_i[m]
Li[m]表示
B
i
B_i
Bi曝光时间内的第
m
m
m张潜影,
m
m
m为重建总次数。以前的尝试通过假设潜在帧之间的线性[3]或分段线性运动[34]并插入更多的中间帧来减少离散化误差,而在现实场景中,特别是在复杂的非线性运动的情况下,这种假设可能会被违反。相比之下,我们利用我们的网络还原了
L
‾
i
[
m
]
\overline{L}_i[m]
Li[m],以利用嵌入在事件流中的真实运动,并将重新模糊的图像
B
‾
i
,
B
‾
i
+
1
\overline{B}_i,\overline{B}_{i+1}
Bi,Bi+1与原始模糊输入
B
i
,
B
i
+
1
B_i, B_{i+1}
Bi,Bi+1之间的模糊锐利损失
L
B
−
S
\mathcal{L}_{B-S}
LB−S表示为
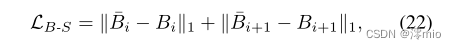
它通过从模糊输入中学习来保证亮度的一致性。
Sharp-event Loss.
除了上述约束外,还可以利用锐隐图像与事件之间的关系来监督连续隐帧的重建。根据式(5),我们有
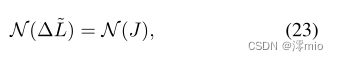
式中,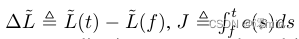
N
(
⋅
)
N(·)
N(⋅)为[23]中采用的最小/最大归一化算子。因此,我们可以避免阈值
c
c
c的估计,将突发事件损失
L
S
−
E
\mathcal{L}_{S-E}
LS−E表示为
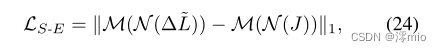
其中
M
(
⋅
)
\mathcal{M}(·)
M(⋅)表示
M
(
⋅
)
=
0
\mathcal{M}(·)= 0
M(⋅)=0时逐像素的掩码算子,只有在没有事件的情况下。最后,整个自我监督框架可以总结如下。
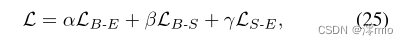
用α, β, γ表示平衡参数。
5. Experiments and Analysis
5.1. Experimental Settings
Datasets.
我们用三种不同的数据集来评估所提出的方法,包括合成数据集和真实数据集。
**GoPro:**我们在REDS数据集的基础上构建了一个纯合成数据集[16]。我们首先对图像进行采样并裁剪为160 × 320的大小,然后通过使用RIFE在连续帧之间插值7个图像来提高帧率[6]。最后,我们基于高帧率序列生成模糊帧和事件,其中模糊帧是通过平均特定数量的清晰图像得到的,事件通过ESIM进行模拟[24]。
HQF: HQF数据集[26]包含由DAVIS240C相机同时捕获的真实事件和高质量帧,其中图像被最小化地模糊。我们采用与GoPro数据集相同的方式对帧率进行上转换并合成模糊帧,形成一个半合成的模糊视频数据集。
RBE: RBE数据集[34]使用了一个DA VIS346摄像头来收集真实世界的模糊视频和相应的事件流,这些视频和事件流可用于使用所提出的自监督学习框架进行训练,并验证我们的方法在真实场景中的性能。
Implementation details.
我们实现了包含5个卷积层的LDI网络和包含6个卷积层、2个残差块和1个CBAM[33]块的融合网络,形成了一个轻量级的网络架构(详见补充资料)。我们的网络使用Pytorch实现,并在默认批处理大小为4的NVIDIA GeForce RTX 2080 Ti gpu上进行训练。Adam优化器[12]与SGDR[15]调度一起使用,其中参数Tmax设置为100(每100个epoch重置学习率)。我们设置LDI输入的时间桶数N = 16,并将图像随机裁剪为128 × 128块进行训练。训练过程分为两个阶段:首先在去模糊设置下训练模型,权重因子[α, β, γ] = [512, 1, 1×10−1],初始学习率1×10−3为100次,然后在去模糊和插值统一设置下继续训练,权重因子[α, β, γ] = [128, 1,1 ×10−1],初始学习率为1×10−4为100次。我们为每个数据集训练一个模型,并在相应的数据集上对其进行评估,这很方便,因为我们不需要真实图像来进行监督。

5.2. Results of Deblurring
对于去模糊的设置,我们在GoPro和HQF数据集上使用49帧合成了1张模糊图像,并通过每个模糊图像恢复7帧(在帧率上转换之前)来评估性能。我们比较了最先进的基于帧的去模糊方法LEVS[11]和基于事件的方法,包括EDI[22]、LEDVDI[14]、eSL-Net[31]、RED[34],并通过指标PSNR、SSIM[32]和LPIPS[36]来评估结果。
如表1所示,与最先进的方法相比,所提出的方法取得了显著的去模糊效果。由于运动模糊,LEVS在高动态场景下的性能受到限制,如图4所示。对于基于事件的方法,模型驱动的方法EDI通过利用嵌入在事件中的精确运动,提供了与LEVS相当的性能。通过引入基于学习的技术,LEDVDI在GoPro数据集上进一步增强了这一优势,但由于数据集之间的不一致性,这种压倒性的性能在HQF数据集上无法保持。RED在半监督学习中取得了最具竞争力的结果,但它仍然要付出性能损失来平衡不同的数据分布。我们的EVDI方法通过用自监督框架拟合特定的数据分布来解决这一问题,从而在每个数据集上实现最佳性能。同时,我们的模型只包含0.393万个网络参数,比除eSL-Net之外的其他方法少一个数量级。请注意,由于eSL-Net的递归结构,推断160 × 320的图像需要122.8G FLOPs,而我们的模型只需要13.45G FLOPs,保持整体效率。
5.3. Results of Interpolation
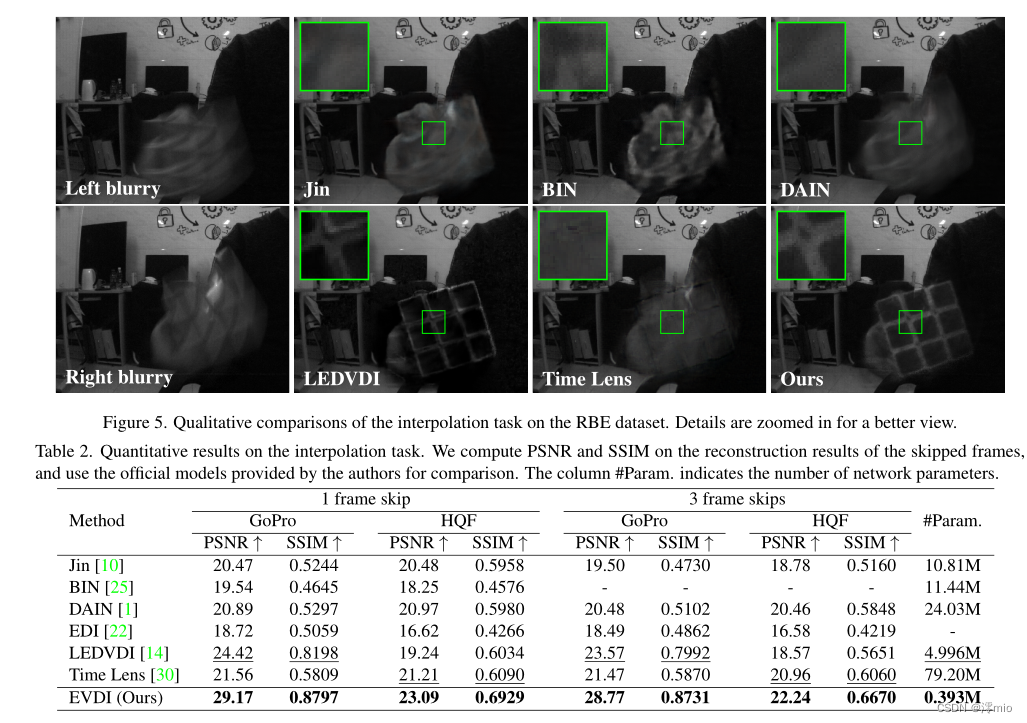
对于插值任务,我们收集连续97帧(上转换前的13帧原始帧)作为一组输入,并在两端使用41帧合成1个模糊图像,中间留下1个潜在的原始帧用于评估(记为1帧跳过)。同样,我们设计了另一种3帧跳过的情况,将1张模糊图像合成为33帧,留下3张原始中间帧。比较了基于帧的插值方法Jin 's work[10]、BIN[25]、DAIN[1]和基于事件的插值方法EDI[22]、LEDVDI[14]、Time Lens[30]。
图5和表2的结果表明,基于帧的方法难以实现模糊视频插值。DAIN中使用的光流通常会将运动模糊投影到插值结果中,如图5所示。Jin的工作采用级联方案进行去模糊和插值,这倾向于将去模糊误差传播到插值阶段。BIN虽然实现了去模糊和插值的联合,但由于帧间信息缺失,难以合成准确的中间帧。对于基于事件的方法,LEDVDI和Time Lens能够利用事件内部的精确运动来正确估计中间帧。然而,Time Lens的性能高度依赖于参考帧的质量,LEDVDI在对其他数据集进行推断时经常会因为数据不一致而导致性能下降。提出的EVDI方法利用帧和事件相结合的方法来保证插值质量,并利用自监督框架学习目标场景来解决不一致问题,从而获得更好的插值效果。
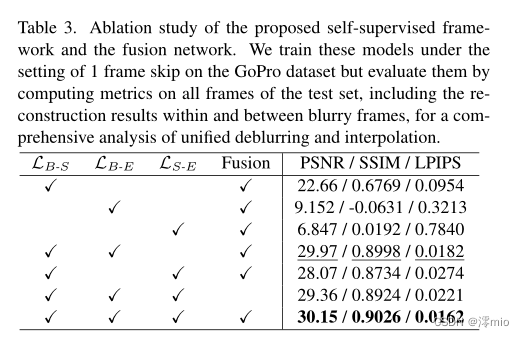
5.4. Ablation Study
我们研究了自监督框架中每个损失的重要性,并研究了融合网络的贡献。得出以下结论:
损失合并的必要性。 如图6所示,模糊锐度损失LB-S有助于亮度一致性,但不能产生锐度结果。模糊事件损失LB-E和锐利事件损失LS-E能够分别通过从模糊帧和事件中获得监督来处理运动模糊,但不约束亮度。结合损失函数,利用LB-S和LB-E、LS-E的互补优势,可以同时解决亮度不一致和运动模糊问题。
信息融合的重要性。 虽然LB-E和LS-E都能够处理运动模糊,但它们的监督来自不同的信息源:LB-E利用模糊帧Bi, Bi+1来监督E(f, Ti), E(f, Ti+1)的估计,而LS-E利用事件来约束¯L(f)的生成。因此,将LB-E和LS-E结合使用将获得最佳性能,如表3所示。此外,融合网络还通过融合来自不同模糊帧和事件的信息来改善结果。
6. Conclusion
本文介绍了一种基于事件的视频去模糊和插值的统一框架,该框架可以从低帧率模糊的输入生成高帧率清晰的视频。通过分析模糊帧、锐隐图像和事件之间的相互约束,提出了一种自监督学习框架,使网络在没有任何标记数据的真实场景下进行训练。对合成数据集和真实数据集的评估表明,我们的方法在保持高效网络设计的同时,与最先进的技术相竞争,显示出实际应用的潜力。
References
[1] Wenbo Bao, Wei-Sheng Lai, Chao Ma, Xiaoyun Zhang,
Zhiyong Gao, and Ming-Hsuan Yang. Depth-aware video
frame interpolation. In CVPR, pages 3703–3712, 2019. 1, 2,
3, 7, 8
[2] Ryad Benosman, Charles Clercq, Xavier Lagorce, Sio-Hoi
Ieng, and Chiara Bartolozzi. Event-based visual flow. IEEE
Transactions on Neural Networks and Learning Systems,
25(2):407–417, 2013. 1
[3] Huaijin Chen, Jinwei Gu, Orazio Gallo, Ming-Yu Liu, Ashok
Veeraraghavan, and Jan Kautz. Reblur2deblur: Deblurring
videos via self-supervised learning. In 2018 IEEE International Conference on Computational Photography (ICCP),
pages 1–9. IEEE, 2018. 4, 6
[4] Senyou Deng, Wenqi Ren, Yanyang Yan, Tao Wang, Fenglong Song, and Xiaochun Cao. Multi-scale separable network for ultra-high-definition video deblurring. In ICCV,
pages 14030–14039, October 2021. 3
[5] Guillermo Gallego, Tobi Delbruck, Garrick Michael Orchard, Chiara Bartolozzi, Brian Taba, Andrea Censi, Stefan
Leutenegger, Andrew Davison, Jorg Conradt, Kostas Daniilidis, and Davide Scaramuzza. Event-based vision: A survey. IEEE TPAMI, 2020. 1, 4
[6] Zhewei Huang, Tianyuan Zhang, Wen Heng, Boxin Shi,
and Shuchang Zhou. Rife: Real-time intermediate flow
estimation for video frame interpolation. arXiv preprint
arXiv:2011.06294, 2020. 6
[7] Tae Hyun Kim, Kyoung Mu Lee, Bernhard Scholkopf, and
Michael Hirsch. Online video deblurring via dynamic temporal blending network. In ICCV, pages 4038–4047, 2017.
2
[8] Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper,
Alexey Dosovitskiy, and Thomas Brox. Flownet 2.0: Evolution of optical flow estimation with deep networks. In CVPR,
pages 2462–2470, 2017. 2
[9] Huaizu Jiang, Deqing Sun, Varun Jampani, Ming-Hsuan
Yang, Erik Learned-Miller, and Jan Kautz. Super slomo:
High quality estimation of multiple intermediate frames for
video interpolation. In CVPR, pages 9000–9008, 2018. 2, 3
[10] Meiguang Jin, Zhe Hu, and Paolo Favaro. Learning to extract
flawless slow motion from blurry videos. In CVPR, pages
8112–8121, 2019. 1, 2, 3, 7, 8
[11] Meiguang Jin, Givi Meishvili, and Paolo Favaro. Learning to
extract a video sequence from a single motion-blurred image.
In CVPR, pages 6334–6342, 2018. 1, 2, 6, 7
[12] Diederik P Kingma and Jimmy Ba. Adam: A method for
stochastic optimization. arXiv preprint arXiv:1412.6980,
2014. 7
[13] Patrick Lichtsteiner, Christoph Posch, and Tobi Delbruck.
A 128×128 120 dB 15 µs Latency Asynchronous Temporal
Contrast Vision Sensor. IEEE Journal of Solid-state Circuits,
43(2):566–576, 2008. 1
[14] Songnan Lin, Jiawei Zhang, Jinshan Pan, Zhe Jiang,
Dongqing Zou, Yongtian Wang, Jing Chen, and Jimmy Ren.
Learning event-driven video deblurring and interpolation. In
ECCV, pages 695–710. Springer, 2020. 1, 3, 6, 7, 8
[15] Ilya Loshchilov and Frank Hutter. SGDR: Stochastic Gradient Descent with Warm Restarts. In ICLR, 2017. 7
[16] Seungjun Nah, Sungyong Baik, Seokil Hong, Gyeongsik
Moon, Sanghyun Son, Radu Timofte, and Kyoung Mu Lee.
Ntire 2019 challenge on video deblurring and superresolution: Dataset and study. In CVPRW, pages 1974–1984,
2019. 6
[17] Seungjun Nah, Sanghyun Son, and Kyoung Mu Lee. Recurrent neural networks with intra-frame iterations for video
deblurring. In CVPR, pages 8102–8111, 2019. 2
[18] Simon Niklaus and Feng Liu. Softmax splatting for video
frame interpolation. In CVPR, pages 5437–5446, 2020. 2
[19] Simon Niklaus, Long Mai, and Feng Liu. Video frame interpolation via adaptive convolution. In CVPR, pages 670–679,
2017. 2
[20] Simon Niklaus, Long Mai, and Feng Liu. Video frame interpolation via adaptive separable convolution. In ICCV, pages
261–270, 2017. 2
[21] Liyuan Pan, Richard Hartley, Cedric Scheerlinck, Miaomiao
Liu, Xin Yu, and Yuchao Dai. High frame rate video reconstruction based on an event camera. IEEE TPAMI, 2020. 1,
2, 4
[22] Liyuan Pan, Cedric Scheerlinck, Xin Yu, Richard Hartley,
Miaomiao Liu, and Yuchao Dai. Bringing a blurry frame
alive at high frame-rate with an event camera. In CVPR,
pages 6820–6829, 2019. 1, 2, 4, 6, 7, 8
[23] Federico Paredes-Vall´es and Guido CHE de Croon. Back to
event basics: Self-supervised learning of image reconstruction for event cameras via photometric constancy. In CVPR,
pages 3446–3455, 2021. 6
[24] Henri Rebecq, Daniel Gehrig, and Davide Scaramuzza.
Esim: an open event camera simulator. In Conference on
Robot Learning, pages 969–982. PMLR, 2018. 6
[25] Wang Shen, Wenbo Bao, Guangtao Zhai, Li Chen, Xiongkuo
Min, and Zhiyong Gao. Blurry video frame interpolation. In
CVPR, pages 5114–5123, 2020. 1, 2, 3, 7, 8
[26] Timo Stoffregen, Cedric Scheerlinck, Davide Scaramuzza,
Tom Drummond, Nick Barnes, Lindsay Kleeman, and
Robert Mahony. Reducing the sim-to-real gap for event cameras. In ECCV, pages 534–549. Springer, 2020. 6
[27] Maitreya Suin and A. N. Rajagopalan. Gated spatio-temporal
attention-guided video deblurring. In CVPR, pages 7802–
7811, June 2021. 3
[28] Deqing Sun, Xiaodong Yang, Ming-Yu Liu, and Jan Kautz.
Pwc-net: Cnns for optical flow using pyramid, warping, and
cost volume. In CVPR, pages 8934–8943, 2018. 2
[29] Jacob Telleen, Anne Sullivan, Jerry Yee, Oliver Wang, Prabath Gunawardane, Ian Collins, and James Davis. Synthetic shutter speed imaging. In Comput. Graph. Forum, volume 26, pages 591–598. Wiley Online Library, 2007. 1
[30] Stepan Tulyakov, Daniel Gehrig, Stamatios Georgoulis,
Julius Erbach, Mathias Gehrig, Yuanyou Li, and Davide
Scaramuzza. Time lens: Event-based video frame interpolation. In CVPR, pages 16155–16164, 2021. 1, 2, 3, 7, 8
[31] Bishan Wang, Jingwei He, Lei Yu, Gui-Song Xia, and Wen
Yang. Event enhanced high-quality image recovery. In
ECCV, pages 155–171. Springer, 2020. 1, 2, 6, 7
[32] Zhou Wang, Eero P Simoncelli, and Alan C Bovik. Multiscale structural similarity for image quality assessment. In
IEEE Asilomar Conf. Sign. Syst. Comput., volume 2, pages
1398–1402, 2003. 7
[33] Sanghyun Woo, Jongchan Park, Joon-Young Lee, and In So
Kweon. Cbam: Convolutional block attention module. In
ECCV, pages 3–19, 2018. 7
[34] Fang Xu, Lei Yu, Bishan Wang, Wen Yang, Gui-Song Xia,
Xu Jia, Zhendong Qiao, and Jianzhuang Liu. Motion deblurring with real events. In ICCV, pages 2583–2592, 2021. 1,
2, 6, 7
[35] Tianfan Xue, Baian Chen, Jiajun Wu, Donglai Wei, and
William T Freeman. Video enhancement with task-oriented
flow. IJCV, 127(8):1106–1125, 2019. 2
[36] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman,
and Oliver Wang. The unreasonable effectiveness of deep
features as a perceptual metric. In CVPR, pages 586–595,
2018. 7
[37] Shangchen Zhou, Jiawei Zhang, Jinshan Pan, Haozhe Xie,
Wangmeng Zuo, and Jimmy Ren. Spatio-temporal filter
adaptive network for video deblurring. In ICCV, pages 2482–
2491, 2019. 2