图数据库初探——7. 以红楼梦数据集为例进行Nebula Graph使用
0. 关键命令
管理Nebula Service的命令
# 启动所有服务(一般都是启动所有,也可以单独启动某个服务)
sudo /usr/local/nebula/scripts/nebula.service start all
# 停止所有服务
sudo /usr/local/nebula/scripts/nebula.service stop all
# 查看服务状态
sudo /usr/local/nebula/scripts/nebula.service status all
先连接Nebula Graph
cd C:\shaiic_work\nebula_console\
./nebula-console.exe -addr 127.0.0.1 -port 9669 -u root -p 123456
启动 Nebula Studio和关闭的,访问ip:7001
```bash
kill $(lsof -t -i :8080)
cd nebula-graph-studio
npm run stop # stop nebula-graph-studio
cd nebula-http-gateway
nohup ./nebula-httpd &
cd ../nebula-graph-studio
npm run start
以红楼梦数据集为例,跑一边流程。(这个数据集似乎更新了,和网上大部分红楼梦知识图谱的内容都不一样)
全流程
- 创建图
(root@nebula) [(none)]> create space if not exists HouLou(partition_num=5,replica_factor=1,vid_type =int) Execution succeeded (time spent 1089/29335 us) Thu, 23 Dec 2021 12:47:05 CST
1. 基本操作
1. 图的操作
关于创建图的语句,参考这里
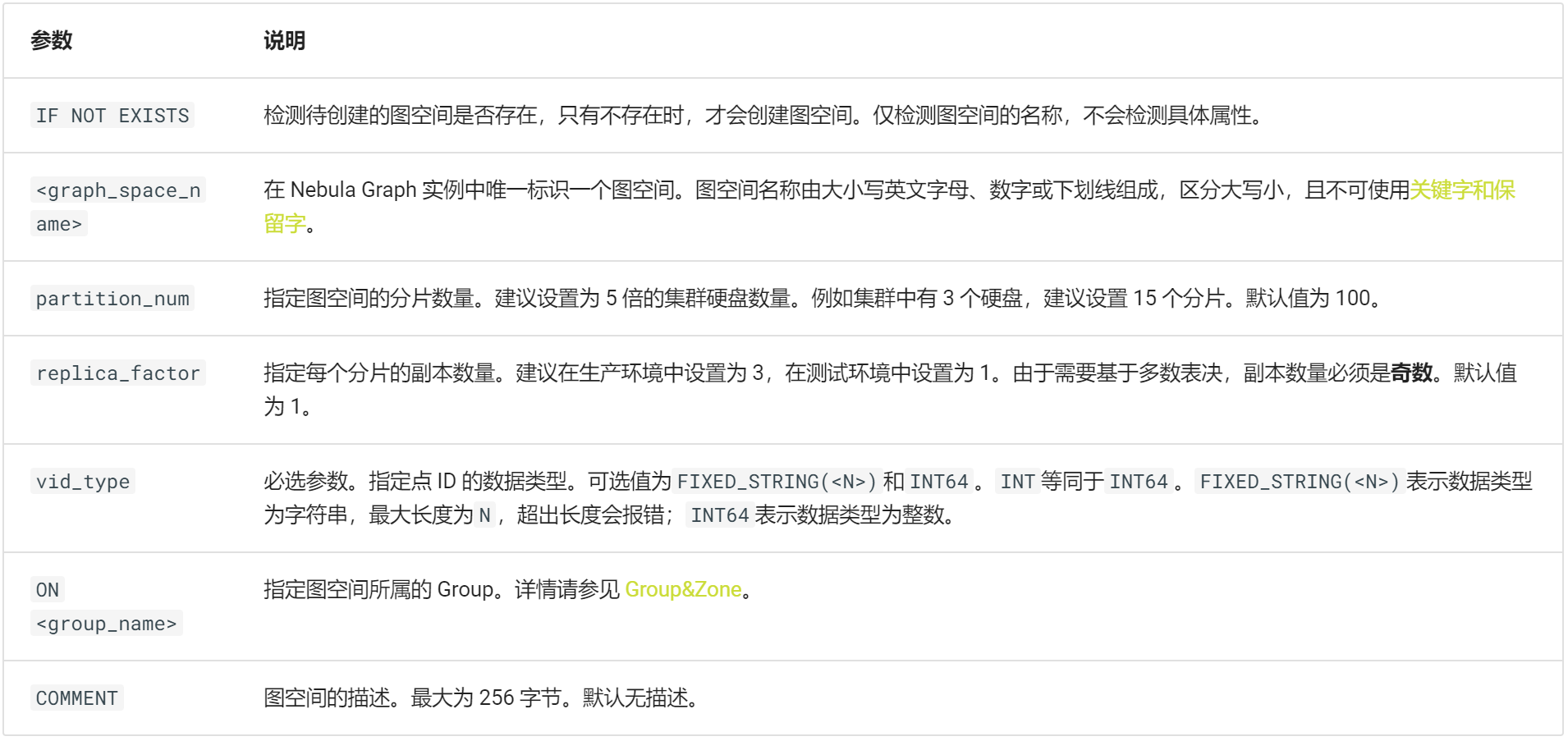
# 完整语法
CREATE SPACE [IF NOT EXISTS] <graph_space_name> (
[partition_num = <partition_number>,]
[replica_factor = <replica_number>,]
vid_type = {FIXED_STRING(<N>) | INT[64]}
)
[ON <group_name>]
[COMMENT = '<comment>'];
# 示例
CREATE SPACE basketballplayer(partition_num=15, replica_factor=1, vid_type=fixed_string(30))
对于我来说,我其实就是单机部署,所以硬盘就1个。。。所以我使用的语句类似:
create space if not exists Persona(partition_num=5,replica_factor=1,vid_type =int)
- Persona:用户画像的英语名。。。
- partition_num=5:因为只有1个硬盘,建议设置为5倍的集群硬盘数量
- replica_factor=1:每个分片的副本数量,建议测试环境中设置为1
- 如果将副本数设置为 1,用户将无法使用 BALANCE 命令为 Nebula Graph 的存储服务平衡负载或扩容。
- vid_type:
- VID表示点(Vertex) ID。在 Nebula Graph 2.0 中支持字符串和整数,需要在创建图空间时设置
- INT64,也就是 2 64 2^{64} 264,约等于1.8亿亿,所以可以存很多很多的点。。。
- neo4j中每个节点也有vid

另外,还有一些额外注意事项
graph_space_name,partition_num,replica_factor,vid_type,comment设置后就无法改变。除非DROP SPACE,并重新CREATE SPACE。- 关于大小写的问题,参考这里:
- 标识符区分大小写(比如space名称,节点名称等,用户定义的东西)
- 关键字不区分大小写,函数不区分大小写
2. 插入节点和关系数据
- 在 Nebula Graph 中,+ 想使用nebula studio的可视化的方式直接导入数据,用户必须先有 Schema,再向其中写入点数据和边数据
- 可以使用 Nebula Studio 的 控制台 或 Schema 功能创建 Schema
2.0 scheme概念设计
大致会使用两个csv文件:
第一个是:relation_refined
"","人物1","人物2","关系","家族1","家族2"
"1","贾演","贾代化","父亲","贾家宁国府","贾家宁国府"
"2","贾代化","贾演","儿子","贾家宁国府","贾家宁国府"
"3","贾敬","贾代化","儿子","贾家宁国府","贾家宁国府"
"4","贾代化","贾敬","父亲","贾家宁国府","贾家宁国府
第二个是:name_use
"","文中名字","标准姓名"
"1","宝钗","薛宝钗"
"2","宝二爷","贾宝玉"
"3","宝哥哥","贾宝玉"
- 设置人物和家族两种节点类型,人物的属性主要是别名和人物名,家族的属性就只有家族名称。
- 其中,人物和人物之间具有亲属关系;人物和家族之间具有属于关系。
2.1 创建schema
参考:创建 Schema
边和节点的类型都不支持中文!
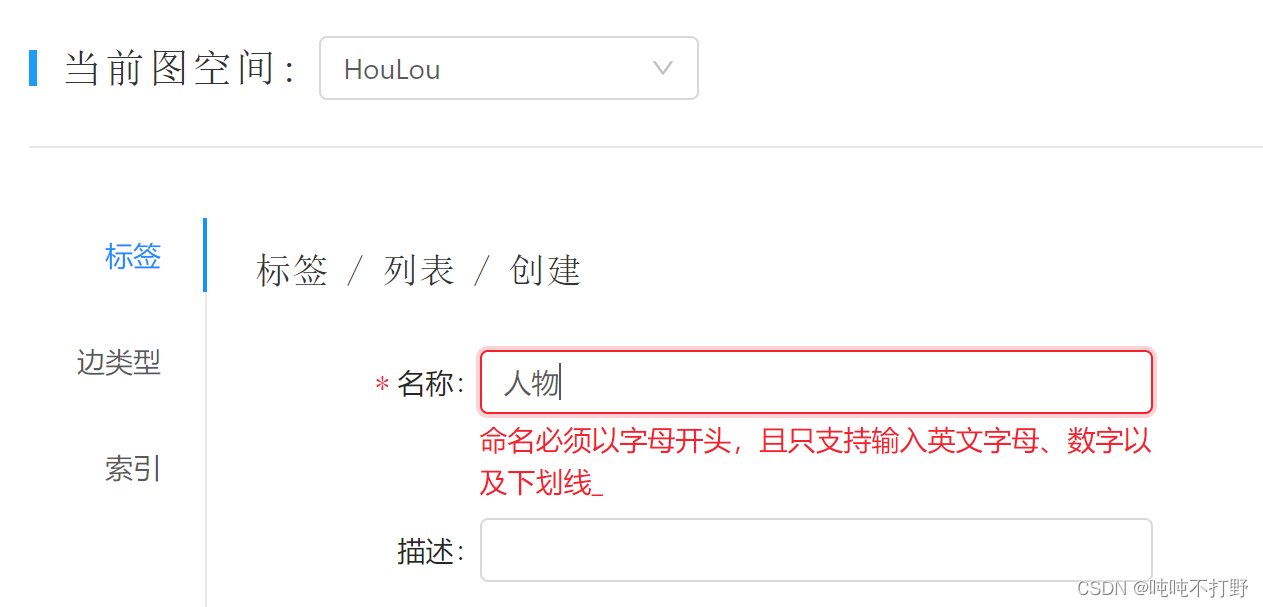
但是属性的值是支持中文的,属性名称也不支持中文

2.1.1 控制台创建
create edge if not exists no_property();
2.1.2 Schema创建
参考:
看图点点,没啥难度,重点是schema的设计。。如果点类型和边类型很多,那就考虑用API去使用python或者C++之类的语言去连接操作。
2.2 上传数据
可以看下示例,csv文件不许有标题行(表头),是在上传之后,选择每一列对应的内容的。
但是报错了,
- 如果
csv文件不是很整齐的三元组之类的数据,要么整理一遍格式之后再去上传。- 建议的形式是,一个实体/节点类型,一张表,第一列是节点名称,后面列是属性
- 一个关系一张表,头节点,尾节点,可能后面还有边的属性。
- 要么直接用nSQL语言去上传,或者使用python等语言接口去上传。
我整理之后的红楼梦数据类似:
人物角色实体

家族实体
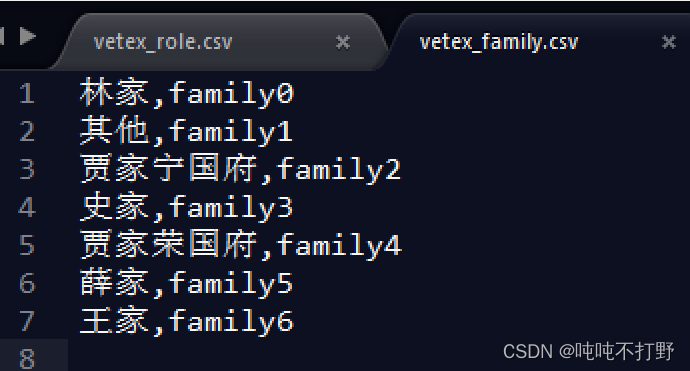
人物属于家族关系
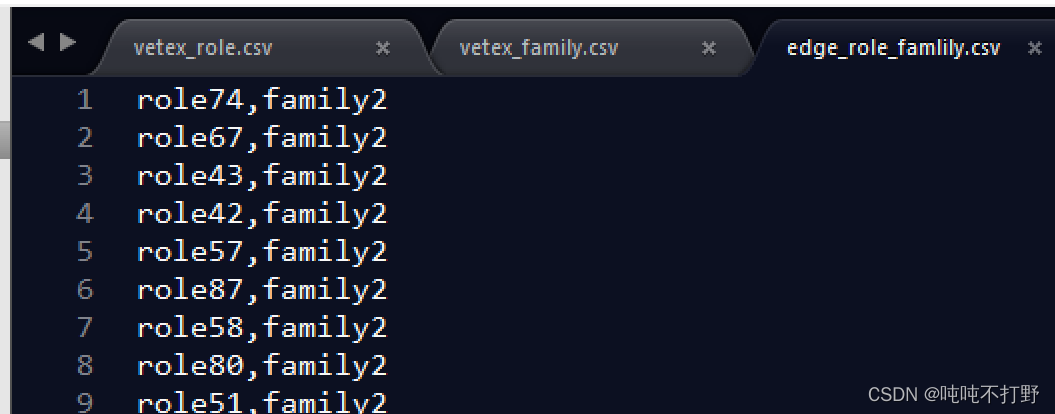
人物之间亲属关系
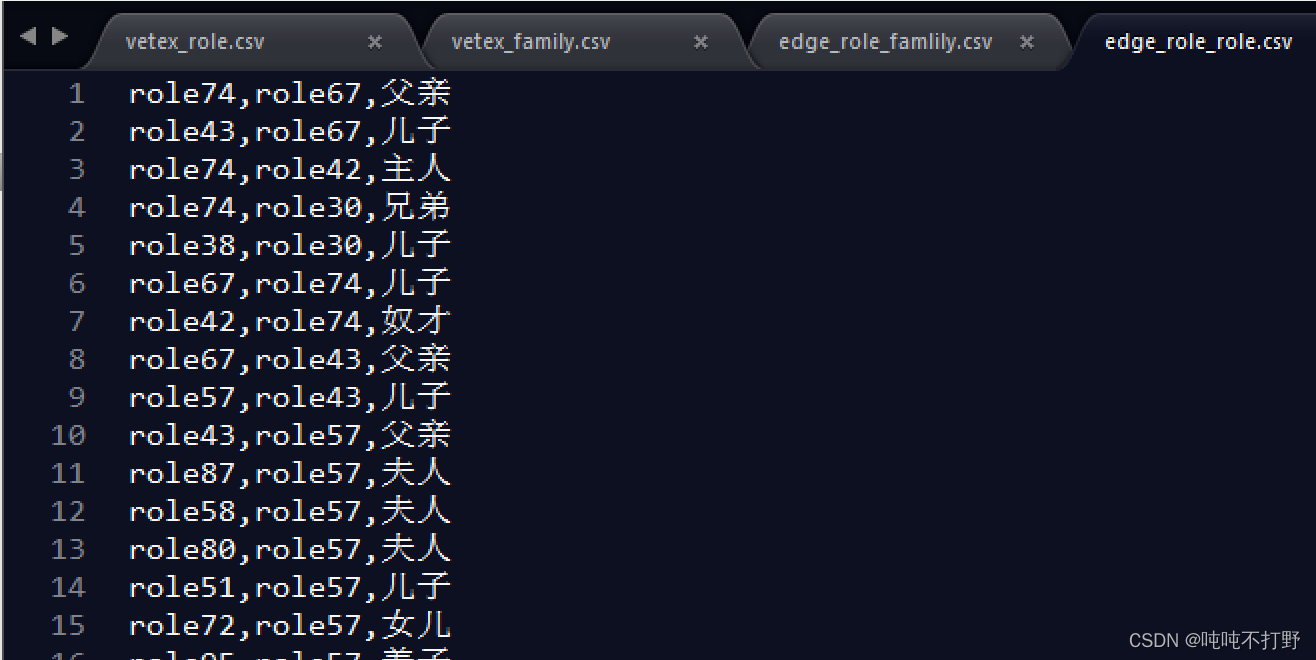
2.3 插入数据
schema虽然使用nebula studio创建很快,但是如果传数据有问题(数据格式不太好的话)。可以考虑直接使用语句进行插入
2.3.1 插入节点
参考:https://docs.nebula-graph.com.cn/2.6.1/3.ngql-guide/12.vertex-statements/1.insert-vertex/
INSERT VERTEX [IF NOT EXISTS] <tag_name> (<prop_name_list>) [, <tag_name> (<prop_name_list>), ...]
{VALUES | VALUE} VID: (<prop_value_list>[, <prop_value_list>])
prop_name_list:
[prop_name [, prop_name] ...]
prop_value_list:
[prop_value [, prop_value] ...]
例如:创建family类型的节点。一次插入多个这种类型的节点。
insert vertex if not exists family (type) VALUES "family1":("其他"),"family2":("史家"), "family3":("林家"),"family4":("王家"),"family5":("薛家"),"family6":("贾家宁国府"),"family7":("贾家荣国府")
2.3.1 插入关系(边)
INSERT EDGE语句可以在 Nebula Graph 实例的指定图空间中插入一条或多条边。边是有方向的,从起始点(src_vid)到目的点(dst_vid)。INSERT EDGE的执行方式为覆盖式插入。如果已有 Edge type、起点、终点、rank 都相同的边,则覆盖原边。
语法:
INSERT EDGE [IF NOT EXISTS] <edge_type> ( <prop_name_list> ) {VALUES | VALUE}
<src_vid> -> <dst_vid>[@<rank>] : ( <prop_value_list> )
[, <src_vid> -> <dst_vid>[@<rank>] : ( <prop_value_list> ), ...];
<prop_name_list> ::=
[ <prop_name> [, <prop_name> ] ...]
<prop_value_list> ::=
[ <prop_value> [, <prop_value> ] ...]
例如:创建人物和人物之间的亲属关系类型的边。
insert edge if not exists BelongToFamily (type) values "role13"->"role18":("父子")
# 类似的,如果想一次插入两条边
insert edge if not exists BelongToFamily (type) values "role13"->"role18":("父子"),"role1"->"role8":("母女")
2.4 经验
- nebula有点奇葩。。。neo4j的VID是插入时自动生成的,对用户不可见。但是这个nebula是对用户可见的,需要用户自己管理。
- 所以从这个角度来说,创建space时VID类型使用string类型更好一些,这样就可以 实体类型+序号,起码不用自己记序号。。。无语。
3. Nebula Studio的图探索使用
这里其实需要掌握一些nSQL语句,因为这个图探索仅仅是可视化检索后结果的内容。
3.1 建立索引
MATCH语句使用原生索引查找起始点或边,起始点或边可以在模式的任何位置。
即一个有效的MATCH语句,必须有一个属性、Tag 或 Edge type 已经创建索引,或者在WHERE子句中用 id() 函数指定了特定点的 VID。
所以VID是检索时直接定位的,但是想要检索更广泛的内容还是必须要建立索引。(这不是很垃圾????耍流氓????)
所以我需要对上面两种节点类型,以及两种边类型都建立索引。
创建原生索引的语法,参考:CREATE INDEX
CREATE {TAG | EDGE} INDEX [IF NOT EXISTS] <index_name> ON {<tag_name> | <edge_name>}
([<prop_name_list>]) [COMMENT = '<comment>'];
如果要创建tag索引(这里其实就是对VID建立了索引),例如对role类型的节点
create tag index if not exists role_index on role()
如果要对role.csv中的人物姓名这一属性建立索引,可以
create tag index if not exists name on role(name(10))
- prop_name_list:
- 为变长字符串属性创建索引时,必须用
prop_name(length)指定索引长度; - 为 Tag 或 Edge type 本身创建索引时,忽略<prop_name_list>。
- 为变长字符串属性创建索引时,必须用
- 对Tag类型为role的所有节点创建属性name的索引,索引长度为 10。即只使用属性name的前 10 个字符来创建索引。
如果是创建边的索引,例如,对人物属于某家族的关系,可以
create edge index BelongToFamily_index on BelongToFamily()
所以整体建立了6个索引(2个节点类型索引,2个边索引,2个属性索引)
# 先建立索引
create tag index if not exists role_index on role();
create tag index if not exists family_index on family();
create edge index BelongToFamily_index on BelongToFamily();
create edge index kinship_index on kinship();
# 创建单属性索引
create tag index if not exists role_name_index on role(name(10))
create edge index if not exists kinship_type_index on kinship(type(10))
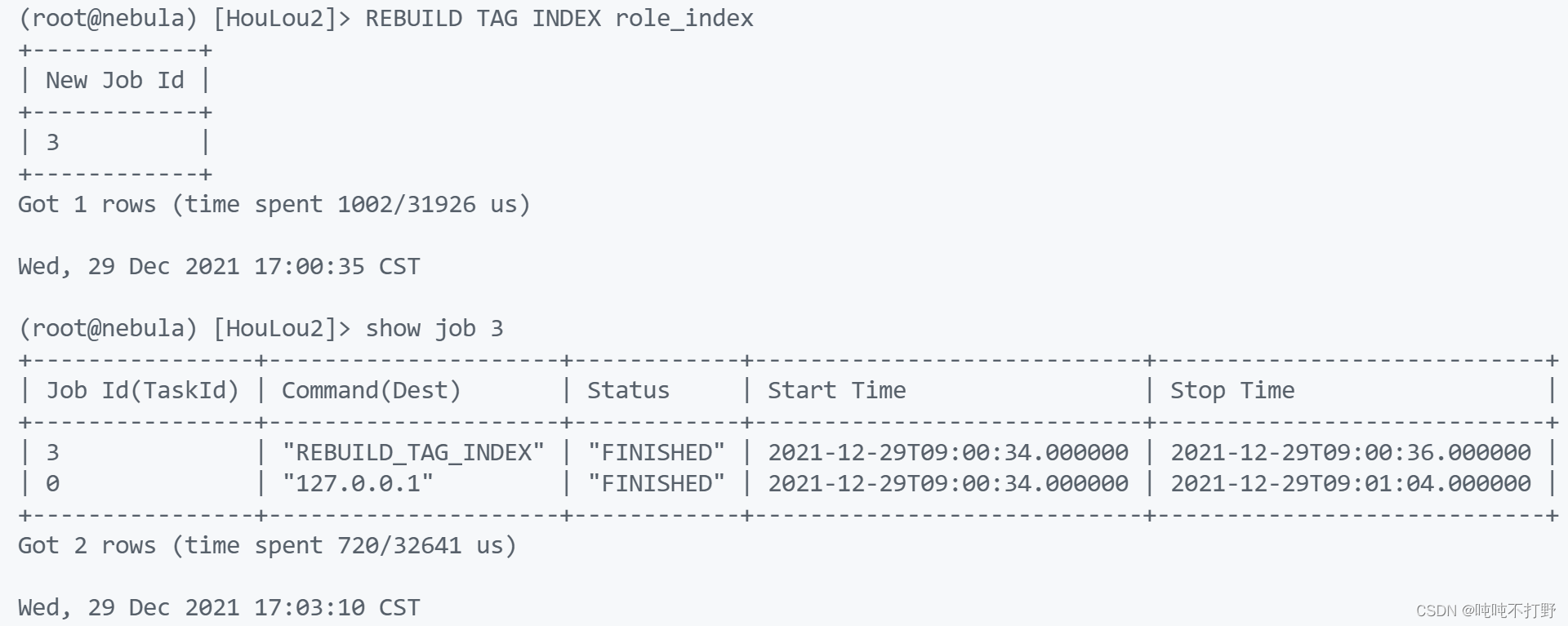
# 再重构索引
REBUILD TAG INDEX role_index
# 会提示这是一个NEW JOB 可以使用SHOW JOB 121 查看任务进度
REBUILD TAG INDEX family_index
REBUILD TAG INDEX role_name_index
REBUILD edge INDEX BelongToFamily_index
REBUILD edge INDEX kinship_index
REBUILD edge INDEX kinship_type_index
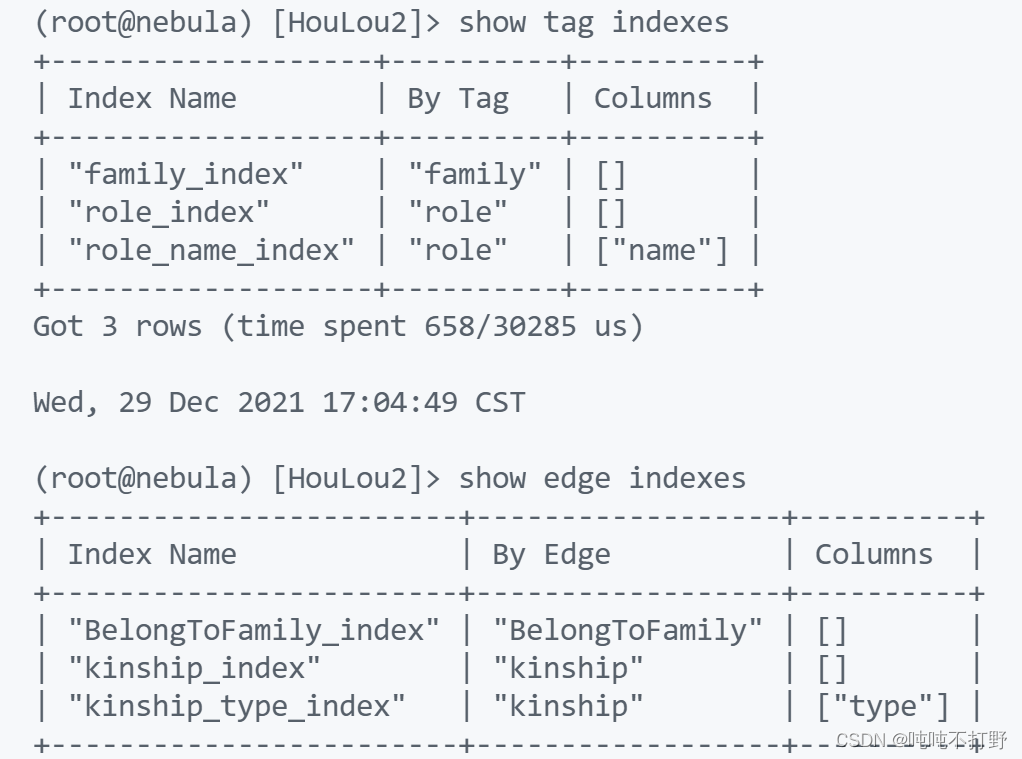
也可以在构建之前先查看下有没有索引,或者构建完看看建立好了没
# 记得先切换到特定的图空间
use SPACE
# 查看节点索引
SHOW TAG INDEXES
# 查看边索引
SHOW EDGE INDEXES
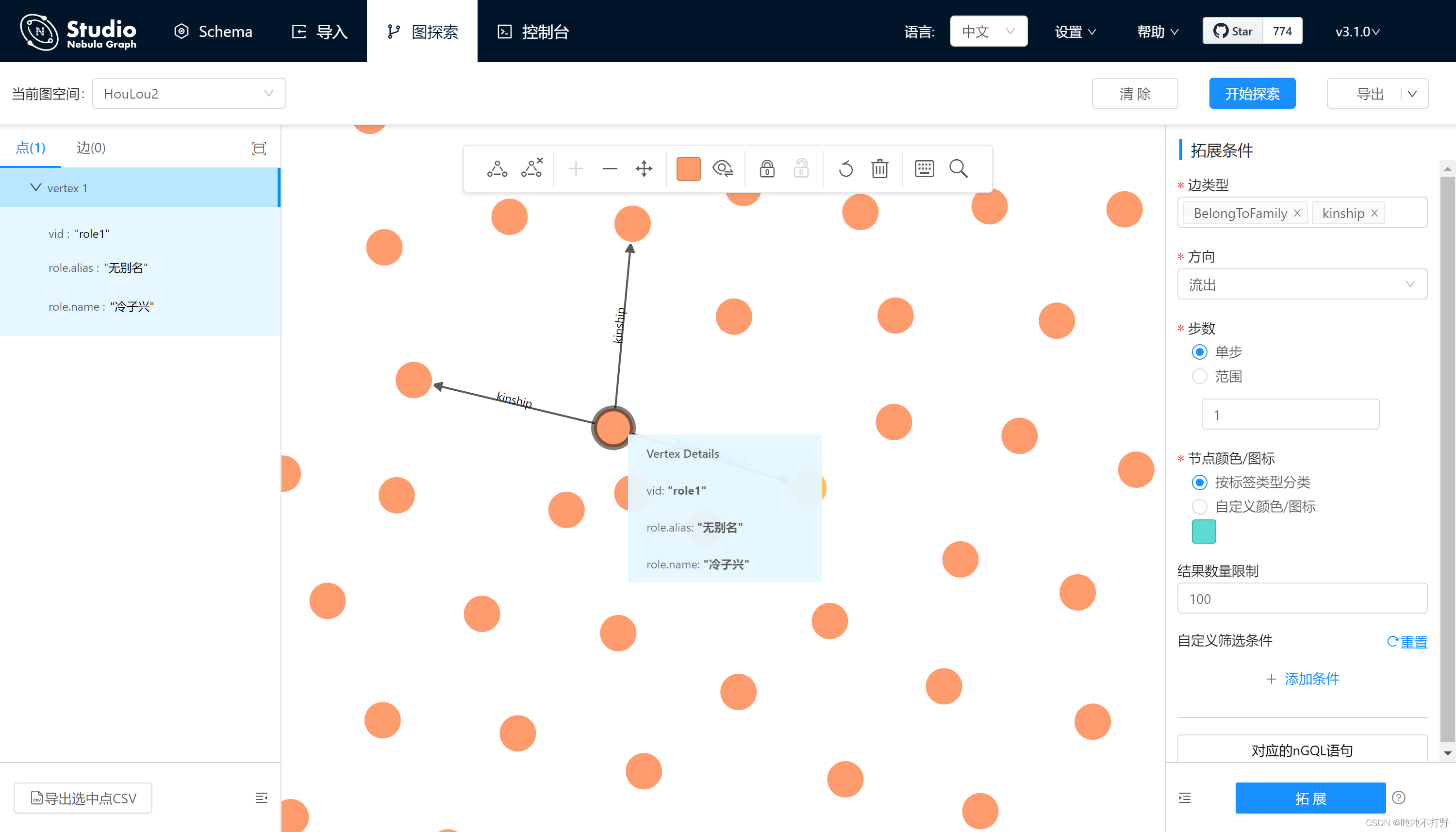
3.2 查询
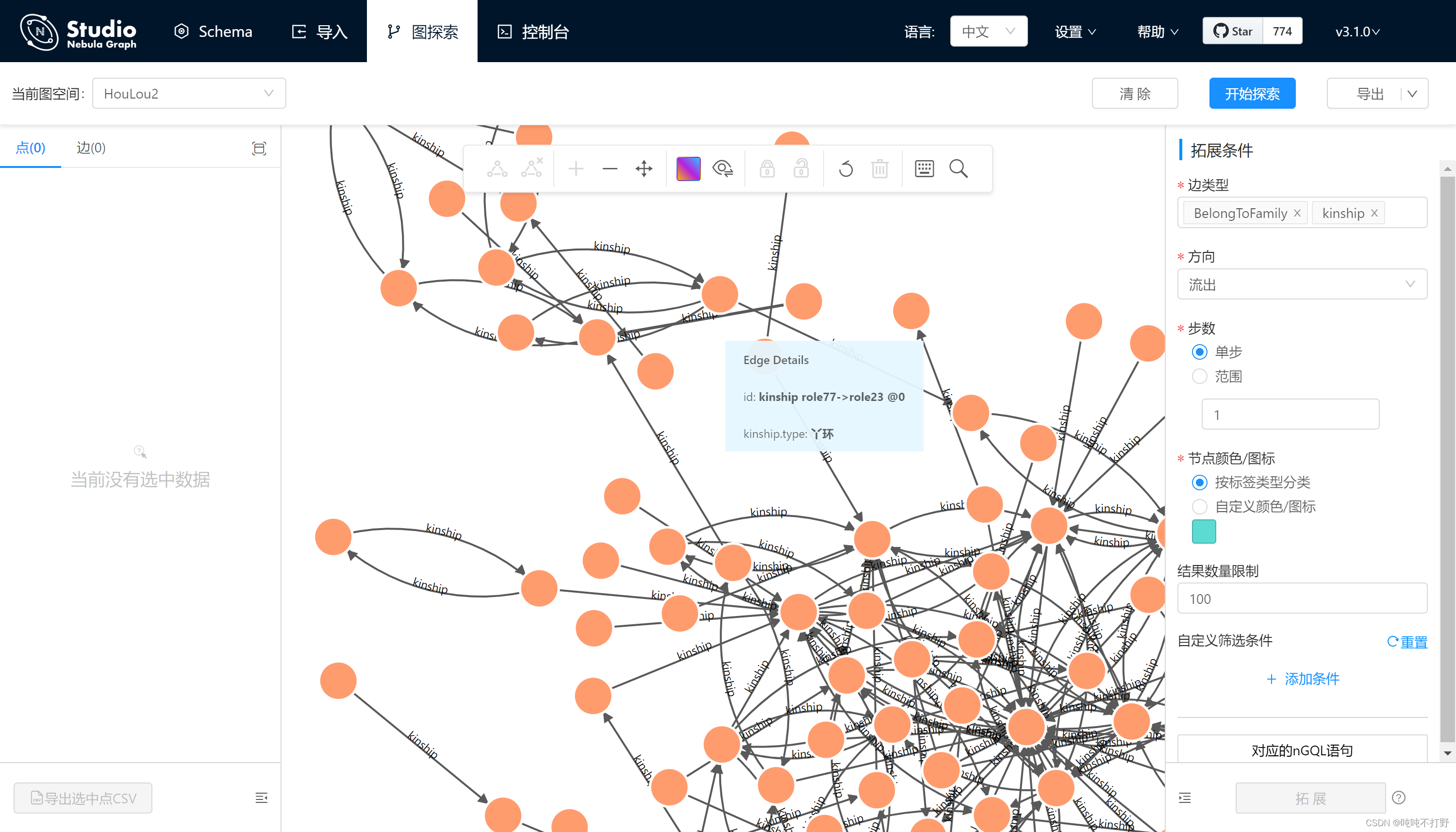
返回所有节点和边
如果数据比较少的话,可以暴力一点,直接展示全部数据
match (v:role)
return v

3.3 查看图探索
# 查看关系
match (v:role)-[rel:kinship]->(o:role) return v,rel,o
match (v:role)-[rel:kinship{type:"奴才"}]->(o:role) return v,rel,o
match (v:role)-[rel:BelongToFamily]->(o:family) return v,rel,o
# 查看节点
match (v:role) return v
报错排查
1. Studio连接数据库504 gateway timeout
参考:
其实解决方案就是重启就行。。。
kill $(lsof -t -i :8080)
cd nebula-graph-studio
npm run stop # stop nebula-graph-studio
cd nebula-http-gateway
nohup ./nebula-httpd &
cd ../nebula-graph-studio
npm run start
2. SemanticError: Can’t solve the start vids from the sentence: MATCH (v:role) RETURN v
- 无法解析vid(也可以认为,是建立了索引查不出来数据)
- 参考:建立了索引查不出数据
- 参考:已针对tag属性创建索引,但match匹配不到数据
有一点需要注意的是:创建索引之前的数据需要rebuild一下才能查出来
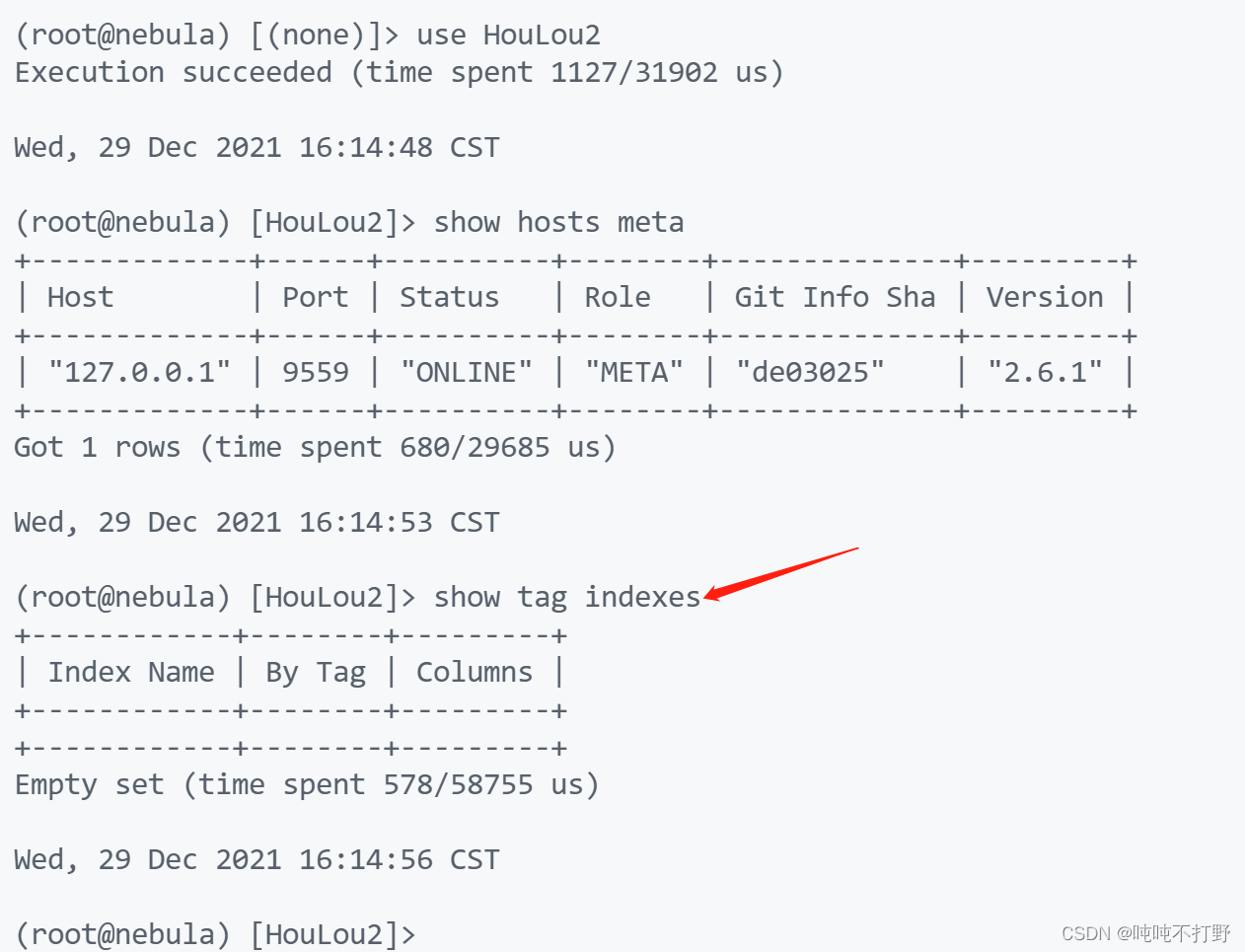
可以看到,我这里是没有进行过rebuild。(如果rebuild过,但是删除了索引,那么也会报这个错误,此时还是需要重新rebuild)
索引功能不会自动对其创建之前已存在的存量数据生效————在索引重建完成之前,无法基于该索引使用LOOKUP和MATCH语句查询到存量数据。
重建索引期间,所有查询都会跳过索引并执行顺序扫描,返回结果可能不一致。
参考:CREATE INDEX
索引配合LOOKUP和MATCH语句使用
- 不要任意在生产环境中使用索引,除非很清楚使用索引对业务的影响。索引会导致写性能下降 90%甚至更多。
- 索引并不用于查询加速。只用于:根据属性定位到点或边,或者统计点边数量。
- 长索引会降低 Storage 服务的扫描性能,以及占用更多内存。建议将索引长度设置为和要被索引的最长字符串相同。索引长度最长为 255,超过部分会被截断。
鉴于上述文字,那就不使用lookup和match语句了,不建立索引了。使用其他的查询语句好了。
但是看了一下,这东西不建立索引根本用不了,无语😒😒😒
3. 返回结果只有三个
解决
一个很大的乌龙,因为没有点击导入按钮,所以每次查询的时候只有预览里的三个值。。。(无语)
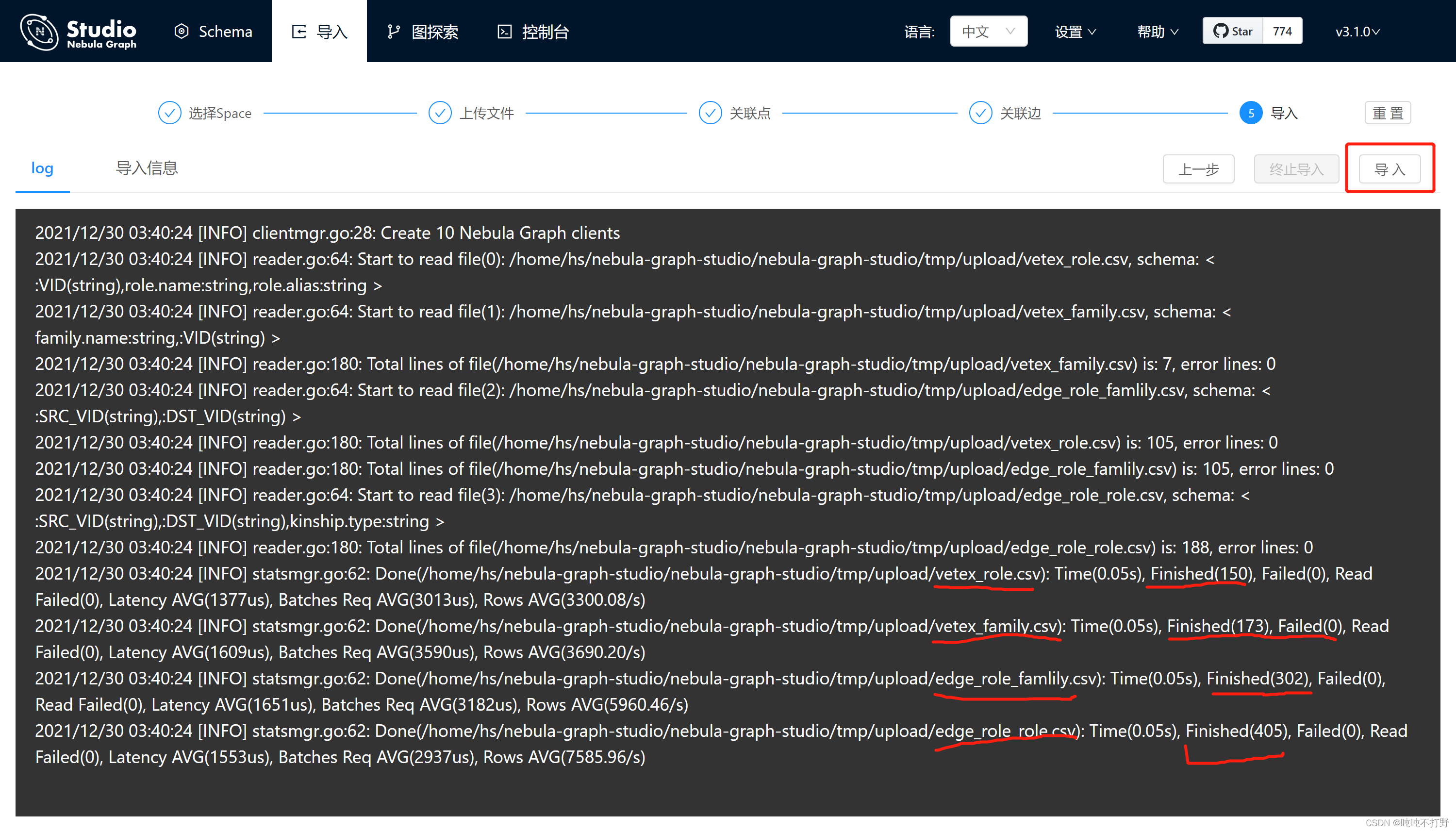
查看存储数据日志,没看到什么有用的信息
尝试使用别的语句:
match (v:role)-[rel:kinship]->(o:role) return v,rel,o
match (v:role)-[rel:BelongToFamily]->(o:family) return v,rel,o
返回空(没有关系。。。无语)
参考:
-
不靠谱,除了自己的论坛,别的地方基本没有博客写问题解决方案,太小众了,这东西没啥人用;
-
另外,版本更新似乎有些问题,待修复的bug不少,不稳定,很容易出错,广告打得挺多。
-
只有nebula自己在知乎,博客园,CSDN的官方账号最活跃,其他基本没见到什么文章,就算有,也基本就是官方文档的复现,没什么用。
反正我的索引都建立好了,难不成是因为建立的少了???
参考下图:
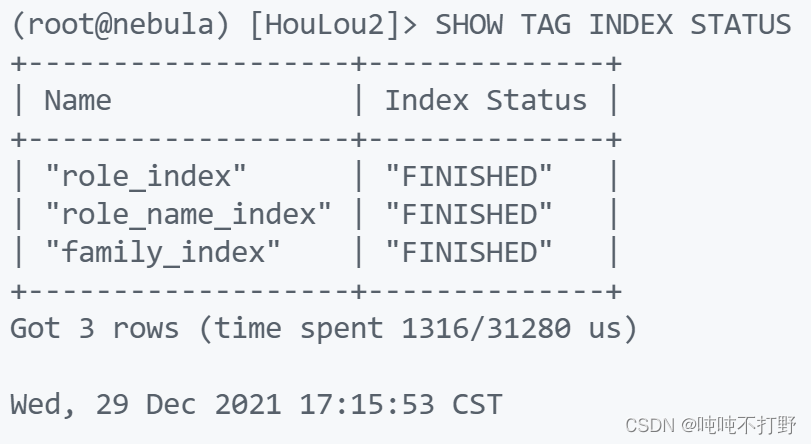

那干脆试试重启一下好了。。。
想起之前:异步实现创建和修改
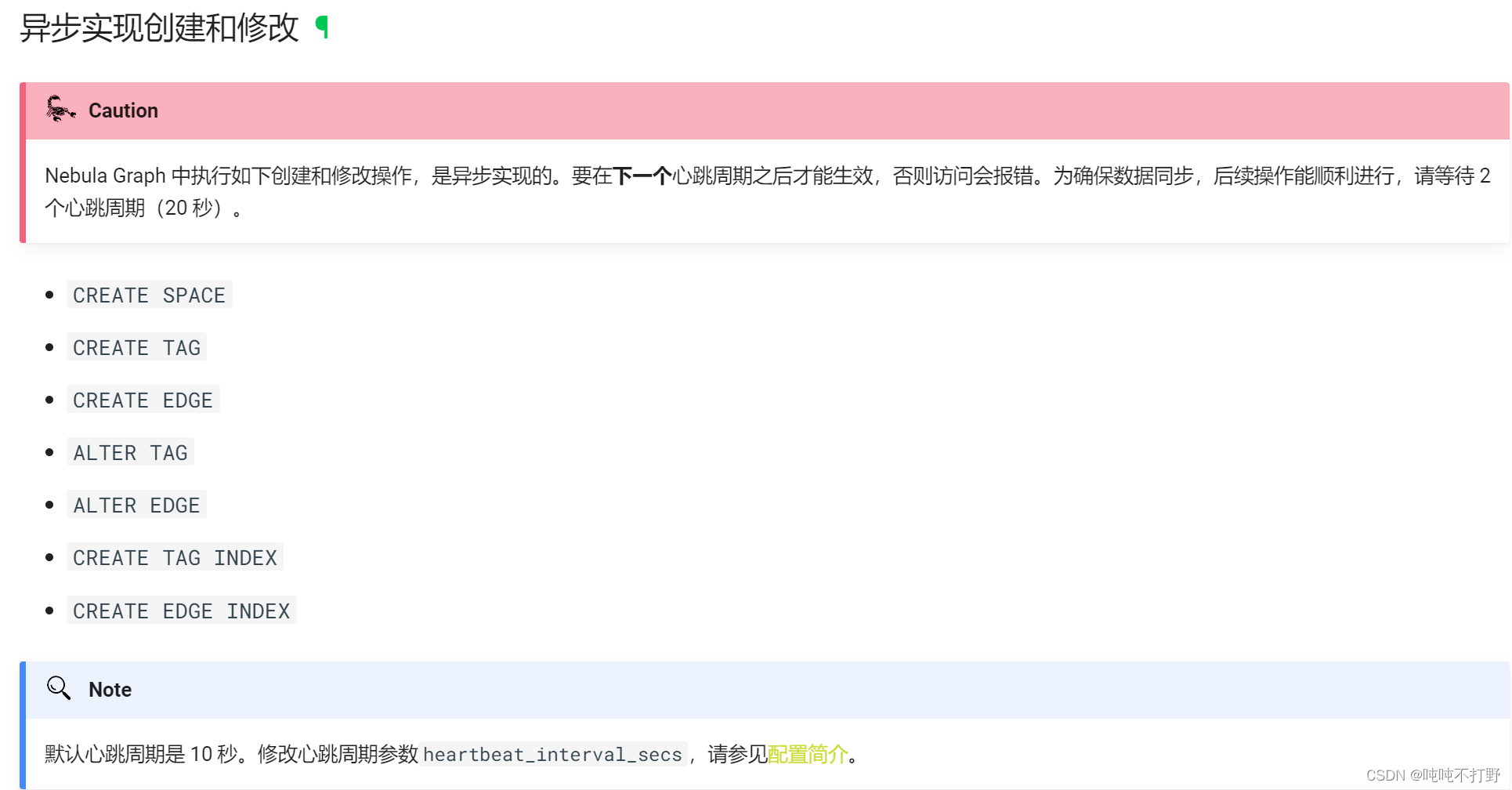
不行就重启咯,关闭Nebula服务之后重启,依然无效。
参考:MATCH 工作流程

所以重新建立一次索引好了???
有些疑问的地方
关于nebula的API,似乎还不是非常完善,参考:生态工具概览
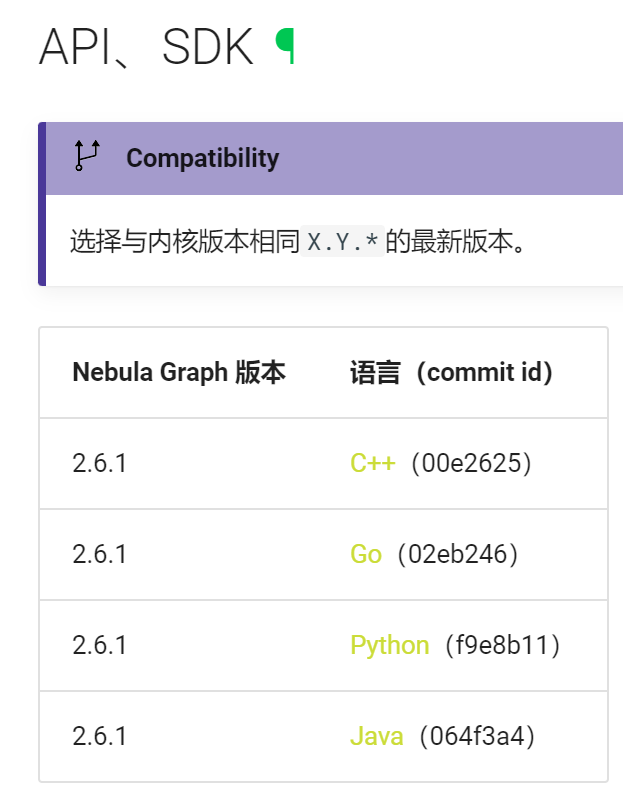
https://github.com/vesoft-inc/nebula-python/tree/v2.6.0